В китайском Гуанчжоу прошёл дождь из дронов
Из-за помех более 600 аппаратов, поднятых для шоу дронов, упали в реку.
Показать полностью
Из-за помех более 600 аппаратов, поднятых для шоу дронов, упали в реку.
Прошла первая неделя учебного года. Пришла пора волшебных слов: «достаём двойные листочки».
Drivee поймет вас несмотря на ни на какие ошибки. Предлагайте цену, выбирайте лучшее для вас предложение, и отправляйтесь в путь. А ошибки — лишь повод узнать что-то новое или повторить хорошо забытое старое.
Реклама ООО «ИН14», ИНН: 1435308804

Изображение сгенерировано нейросетью ideogram
Когда видишь огромные ветряки, редко задумываешься о том, что удерживает их лопасти от разрушения под напором ветра. На самом деле перед установкой они проходят серьезные стресс-тесты.
В немецком Бремерхафене институт Fraunhofer IWES есть испытательный стенд длиной 115 метров. Здесь лопасти проверяют буквально "на излом".
Испытания проходят сразу в двух направлениях — вдоль и поперек лопасти. Такой метод называют биаксиальным тестированием. Он позволяет максимально точно воссоздать условия настоящих штормов и сильных ветров, а значит, проверка становится быстрее и эффективнее.
Подключены и цифровые технологии. Система MoveInspect HF следит за каждым движением лопасти с точностью до миллиметра — все в реальном времени.
Это не просто эксперимент ради науки, а полноценная система контроля качества. Лопасти испытывают до предела, чтобы на ветропарках они работали без риска поломок.
Больше интересной информации про топливо, нефть, энергию и энергетику в телеграм-канале ЭнергетикУм
Я просто смотрю функционал площадки, не судите строго.
Проблема заключается в том, что большие языковые модели (LLM) имеют ограниченную глубину рассуждений, а техника Chain-of-Thought (CoT) требует много данных, медленная и хрупкая.
Для решения этого предложена HRM (https://arxiv.org/abs/2506.21734) рекуррентная архитектура, вдохновленная иерархической организацией мозга.
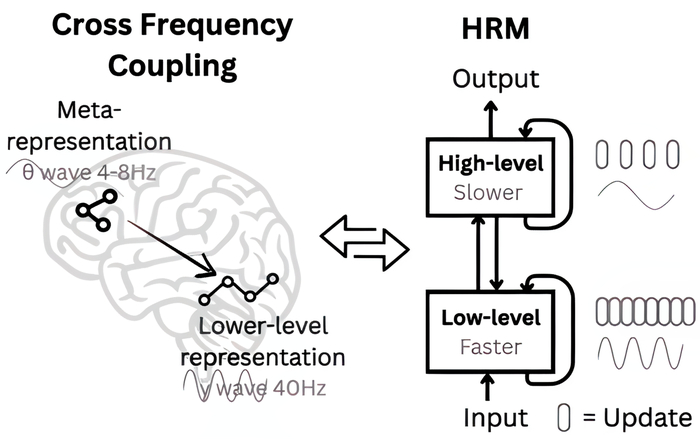
Она состоит из двух модулей. Первый модуль это высокоуровневый (медленный, абстрактное планирование), а второй это низкоуровневый (быстрый, детальные вычисления). Между модулями есть иерархическая сходимость, благодаря которой модули работают на разных временных масштабах, предотвращая преждевременную сходимость. Эффективность здесь в двух вещах это экономное использование памяти (обучение с приближённым градиентом) и гибкость так как система сама решает, сколько вычислений ей нужно для конкретной задачи (адаптивное время вычислений, ACT).
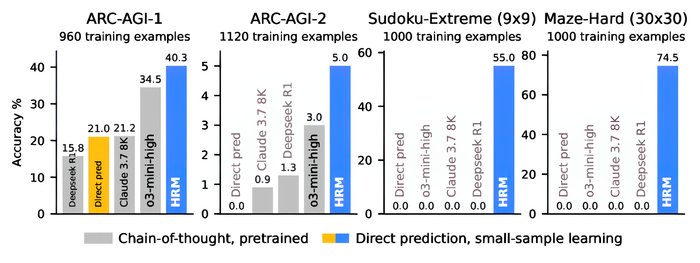
В результате модель с всего 27 млн параметров, обученная на 1000 примерах без предобучения и CoT превосходит большие LLM (Claude, o3-mini) на сложных задачах:
ARC-AGI (индуктивные рассуждения): 40.3% vs 34.5% и 21.2%.
Судоку и лабиринты: Почти 100% точность, где CoT-модели показывают 0%.