Многие люди которые не пишут посты, а просто читают их и оставляют комментарии, замечают маленькую деталь, в разделе Горячее попадаются посты которые, имеют очень мало плюсов для того чтобы появится в соответствующем разделе.
Так всё-таки, как?
Всё дело в одной функции, называется она Пикабуст
эта кнопка позволяет авторам, сразу помещать свои посты в ленту Горячее
21 мая 2013 года меня позвали на работу в издательский дом Академия. Контора делала и делает учебники для вузов и ПТУ. Моя задача была.... Завести благородных европейских оленей из Великобритании в Россию. Вот такое было хобби у владельца. Первое знакомство показало что это невозможно сделать. Приглашённые компании сливались, министерство сельского хозяйства написало что это невозможно, мои знакомые сообщили что это невозможно сделать! Спустя 8 месяцев работы, после того как я задолбал Россельхознадзор и ветеринарную службу её Величества Королевы Великобритании, я привез оленей. Получил на них разрешение. Через 4 месяца разрешение на ввоз из Соединённого Королевства в Таможенный Союз диких, зоопарковых, охотничьих и экзотических животных, было отозвано. Ну чтобы вы поняли объём работы. После ввоза животных, начальник дал задание "раструбить" об этом везде. Я стал вести соц сети, возить туристов и журналистов на ферму, показывать животных и надо было написать серию статей в охотничьи журналы.
И начался ад. Начальник регулярно придирался к тексту, ну как некоторые комментаторы тут. Им не структурированно, непонятно и прочее. Я один раз не выдержал и сказал: у вас тут полная контора редакторов, корректоров и прочих писак, каждый из них с легкостью напишет любой текст. Уж учебники они править научились, так дайте им это задание, это по их профилю. Что-то никто не смог договориться с Англией о провозе оленей, там их управление структурой текста и запятыми не помогло. Красиво пишущих в конторе десятки, в стране тыщщи, а оленей вам приволок лишь один я со своим корявым языком. Так что я спокойно соглашаюсь что писать тексты это не моё, но вас заменить можно, а меня, как оказалось, нет. Наслаждайтесь вашим умением грамотно писать, я в другом силён.
Лет восемь тому назад пытался отредактировать одно произведение.
"Он подошел к ней в самолёте, чтобы освидетельствовать".
Автор до усирачки стоял на своём. Это была новая пытка Мюллера.
"Это я написал верно! Имеется в виду — вежливо поздороваться!". И вопил: да я 30 лет назад защитил кандидатскую по филологии! "Как вы смеете меня править!!!111".
(Я сразу подумал о степени деградации.)
Я уже даже ехидно переспрашивал у него: «А сей эксперт имел лицензию, и, кстати, какую — на освидетельствование? Фразеологический оборот такой: "засвидетельствовать почтение"».
Нет, не пробиваемо...
Ещё жутко ругался, как это я вношу ТАК МНОГО правок в его нетленное творение! Ведь он сам как-то перечитывал своё произведение и много чего исправил!
...Едва ли не впервые в своей деятельности вернул ему аванс. А на следующий день мне пришло электронное письмо от того, кто исходный текст присылал. Там значилось: "По ошибке я вам отправил не самый актуальный текст. Есть уже откорректированный...". Я безмолвствовал.
Но чемпионом по правкам был один не автор, а составитель. Он ничтоже сумняшеся искал в Сети инфу по своей тематике. Распечатывал сии страницы из Интернета. Видимо, зачёркивал ненужное.
И ЗАНОВО НАБИРАЛ с таких распечаток.
В итоге на 200 страницах я выявил примерно 2500 (Две тысячи пятьсот) ошибок.
Этот тоже вопил: "Откуда?! Откуда столько?!". Но при виде напрочь исчёрканных красной пастой страниц успокоился.
Причём я отдал первую корректуру, её внесли в фирме, которая взялась распечатать ему небольшой тираж. И я попросил распечатку и снова ещё нашёл ошибки, включая ошибки внесения моих первых правок. И отвергнутые автором мои первые правки.
Запомнил того автора по противодействию слову "комендор". Он написал "командор". А речь шла о кораблях и их артиллерии. Что-то вроде "комендоры уверенно распоряжались...".
Так вот комендор — это старший артиллерийской палубы (или орудия), а командор — военачальник в общем. Я дважды правил на "е", всё равно книга вышла с "а".
Ещё правил текст для автора из соседнего областного города. Её упросили передать на корректуру, так как ошибки выпрыгивали из распечатки. Решительно утверждала: "Да что там МОЙ ТЕКСТ править, там вряд ли и три ошибки найдутся". Я стал править, мне сразу передали вопрос автора: "Есть ли ошибки?". Я честно умножил в среднем штук 7 ошибок на количество страниц А4 формата (120) и сообщил, что их как минимум 800 штук. Мне передали, что автор взвилась: "Такого не может быть!!!111". По получении исчёрканной распечатки притихла.
О, я помню, как первую книжку отдал в издательство. Сижу, жду предпечатную версию на согласование. Жду. Жду. Не выдерживаю, иду к своему... ну допустим, агенту. Задаю глупые вопросы. В ответ получаю: "А зачем тебе?" Пришлось немножко повысить капс: "НАДО". Откуда-то из недр издательского процесса мне выцарапывают и присылают файл. Я открываю...
Вот чес-слово, друзья знают меня как человека вежливого, тихого и незлобивого. Но в тот день я орал, заплетал в три загиба и лупил стенку. Человек-редактор выкинул из текста все лор-специфичные термины (жанр книги — городское фэнтези со своей мифологией), переврал половину имён и надругался над манерой речи персонажей, лишив каждого из них тщательно продуманной личности. По сути, это уже была не моя книжка, это был тот самый мертвец, подвергнутый макияжу.
Я откатил всё, как было — естественно, согласившись с правками грамматики. По каждому кейсу приложил обильные примечания, почему автор сделал так, а не иначе. Отправил этому человеку-редактору, вежливо попросив принять во внимание. В ответ получил: "Ой, иди нахуй, писака доморощенный. Ты не Толстой, увянь и не пахни". Насладился, переслал переписку товарищу агенту. И тот, похоже, сам проникся настолько, что призвал в чат главреда проекта.
Главред, как ни удивительно, согласилась с большинством моих претензий. Мы в атмосфере сотрудничества и дружелюбия пришли к общему знаменателю, отправили текст в печать, пожали руки. На прощание я получил предложение самому пойти к ним редактором в штат. Вежливо отказался: в то время меня занимали иные проекты.
Но к профессии "редактор" я теперь отношусь с бо-о-ольшим предубеждением. Ибо нефиг из живого текста делать намарафеченного покойника.
Перед отпуском всегда пытаюсь подшабашить и беру рукописи на редактуру. Начинающие авторы не могут приткнуться к приличному человеку, который посмотрит на них добрыми глазами, широко раскроет объятия, поцелует в макушку и скажет: «Сожги эту дрянь, письменность придумана не для тебя». Поэтому попадают ко мне.
Я никого не мучаю в вопросами о добре и зле. Читаю присланное по диагонали, потом убегаю в рощу, инфернально хохоча, поостыв, сажусь за редактуру и начинаю прилежно портить чужой труд. Нахожу дыры в сюжете, недоработанность образов, бедность диалогов и недостатки стиля. Предлагаю исправления. Нет, я не льщу себе сравнениями с докторами, которые могут пришить кому-то новую ножку. Я скорее патологоанатом, который пишет заключение, отчего скончался, не приходя в сознание, очередной самодельный рассказ или повесть. Патологоанатом не пишет «пить надо было меньше». И в моих выводах нет рекомендаций убиться об стену. Я трудолюбиво описываю, какой макияж улучшит внешний вид дорого покойника.
Так произошла моя очередная встреча с прекрасным. А поскольку я сначала пару лет жду, не получит ли рукопись Букера или хотя бы приз зрительских симпатий на фестивале в деревне Концы, то новые перлы будут позже, когда время нас рассудит, а пока – бережно сохраненная консерва прошлых лет. Жанр – повесть. Сюжет – служебный роман.
«Похолодело в нутре», - пишет тот начинающий автор предпенсионного возраста. Предлагаю поправить на «почувствовал холод внутри». Отказывается! Мол, есть прекрасное слово «нутро». Видимо, оно точно отражает то место, где в главного героя засунут термометр его богатых эмоций.
«Она впилась в нервы, струящиеся из его глаз». Уточняю: «Штоблять А что хотел сказать автор?» «Это она так внимательно на него посмотрела, а он был напряжен», - недоуменно отвечает автор. Типа, девушка, вам бы подучить биологию прежде, чем браться за чужой литературный труд, второй раз приходится объяснять простейшие вещи.
«Природа дала ему поджаристое телосложение». В третий раз уточнять не буду. Просто сразу дайте два, блин.
«…и черты его стухли». Посмотрела бы я на автора, если бы ему сначала жарили телосложение.
«Она бросала на него злостные взгляды». Так он в нее струячил нервами! (Сразу вспомнилось из не-моих находок: «Я дал кобыле шекелей, и она таки поскакала на врага»).
«Она обрабатывала крупную рыбу сладким голосом». Из серии «Украла этот рецепт у инопланетного шеф-повара и готовлю каждый день! Соседи вешаются!».
«Бумага на ее глазах бредила непонятными цифрами». А на моих – буквами. К слову сказать, там бумага бредила еще и жопами. В прямом, граждане, смысле: в кульминационной сцене герой и героиня совокупляются на принтере, который от этой страсти не разваливается, а начинает самопроизвольно работать и распечатывает задницу героини с характерной татуировкой. Этот лист потом нашла в принтере жена лиходея.
Редактуру я тогда, конечно, сделала. При мысли о новой у меня, как обычно, похолодело в нутре, но глаза боятся – а руки хотят на море.
Нашла суперкрутой сервис для апскейла изображений на сайте!
Tost AI - бесплатный сервис, который позволяет прямо в браузере увеличить качество ваших изображений до 8к. Помимо этого на сайте полно всего - синтез речи, генерация музыки, текстов и изображений, даже 3D модели можно там же сделать.
Как улучшить качество изображения до 8k в Tost AI
Вот исходное изображение, которое я сгенерировала в Midjourney, оно весит 1,9 Мб, в самом Midjourney изображение не улучшала:
Изображение итак довольно хорошего качества, выделены даже поры.
2. В Tost AI из выпадающего списка выбираем именно апскейл. Сразу хочется отметить, что самому писать ничего даже не нужно и исправлять, тут даже негативные промпты прописаны и правильные позитивные, так что результат получится предсказуемо хорошим.
3. Дальше я столкнулась с проблемой загрузки изображения. Так как сервис бесплатный, у них нет возможности загрузки изображений, сервис принимает только ссылки. Мою ссылку из Дискорда (напомню, я сгенерировала изображение в Midjourney) не принял. Но любезно предложил альтернативы - litterbox и tutorial
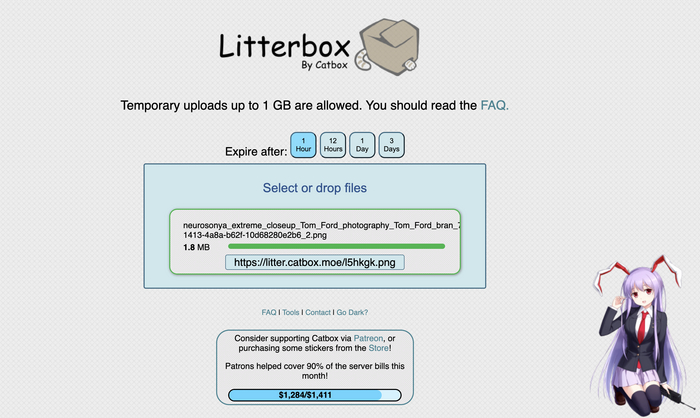
4. Я выбрала первый вариант и меня перенесло на сайт, где загрузив изображение, получаешь ссылку на выходе:
Собственно, это я и сделала - загрузила изображение, получила ссылку, скопировала ее и вернулась в Tost AI.
Это изображение уже весит 20,3 Мб, качество очень детализированное! Сайт может сжимать, поэтому рекомендую скачать эти два изображения и сравнить - для чистоты эксперимента. Если увеличить изображения - видна разница в качестве. Обучаю работать в Midjourney в Закрытом клубе.
Плюсы и минусы апскейлера Tost AI
Плюсы:
Регистрация занимает меньше минуты
Каждый день дают 100 кредитов — этого вполне хватит не только поиграться
В общем, полезно, и в одном месте
Минусы:
Из минусов - долго обрабатывает, придется запастись терпением, но это того стоит. Сервис может не отображать ваше изображение
Больше о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни в телеграм канале НейроProfit. Подписывайтесь, там я рассказываю, как можно использовать нейросети для бизнеса.