

А как ты себя ощущаешь? Пиши в комментах
Материалы о секретах продуктивности и личной эффективности вы найдете в нашем сообществе RISE: Ноотропы и Биохакинг и группе ВКонтакте. Подписывайтесь, чтобы не пропустить свежие статьи!
Материалы о секретах продуктивности и личной эффективности вы найдете в нашем сообществе RISE: Ноотропы и Биохакинг и группе ВКонтакте. Подписывайтесь, чтобы не пропустить свежие статьи!
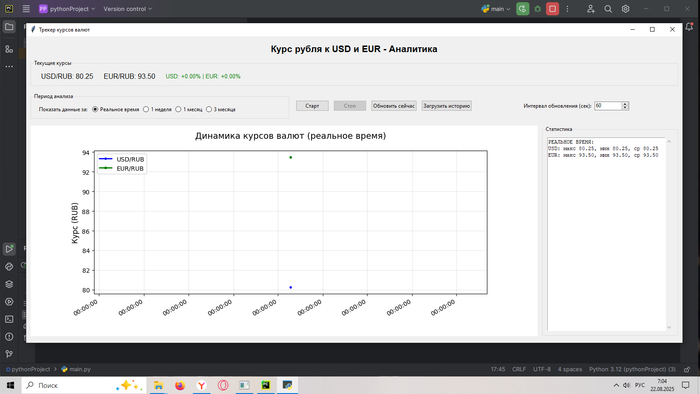
Попросил DeepSeek написать программу, для отслеживания курса валют и что бы в этой программе был график изменений с течением времени. По ходу создания программы, было интересно узнать, что точные бесплатные данные от ЦБ доступны, только в реальном времени, одна неделя, месяц и максимум 3 месяца. Первые попытки приводили к произвольным графикам, независящие от реального курса и истории, почему-то DeepSeek думал, что мне нужен демо режим, а не реальные данные сразу. Программа работает следующим образом:
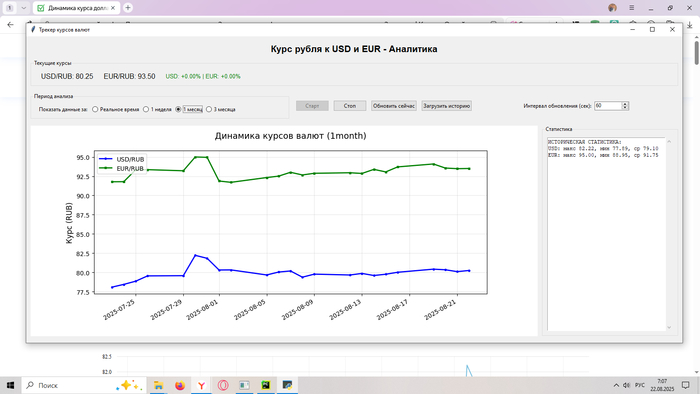
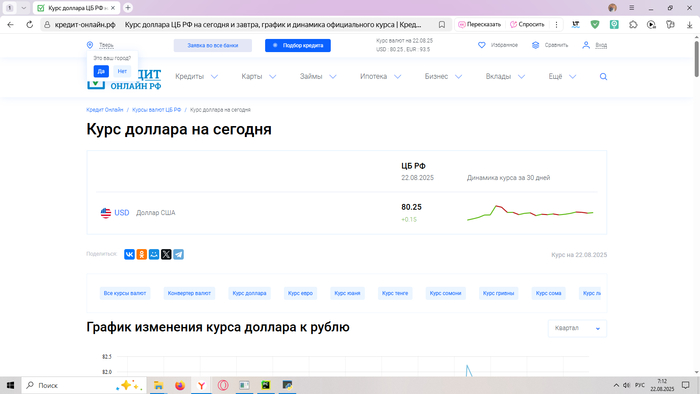
Запускаем саму программу, жмём "Загрузить исторические данные" ждём немного времени, программа синхронизируется с ними и оповещает нас, о том, что данные загружены, жмём "Старт" и видим графики изменений за разный период времени. Для сравнения проверял графики на разных сайтах и полученные графики соответствуют действительности, но возможно есть небольшие погрешности. Вывод кода этого приложения в exe файл, составил 108 мегабайт.

PDF-файлы широко используются для хранения структурированных документов, но программное извлечение их содержимого может быть сложной задачей. К счастью, библиотеки Python для работы с PDF, такие как PyPDF2, pdfplumber и Spire.PDF, предоставляют мощные решения для чтения PDF, позволяя разработчикам легко извлекать текст, изображения, таблицы и метаданные.
В этом блоге мы рассмотрим, как извлекать различные типы содержимого из PDF с помощью библиотеки Spire.PDF.
Библиотека Python для чтения PDF-файлов
Извлечение текста из поисковых PDF
Извлечение изображений, внедренных в PDF-файлы
Сбор табличных данных из PDF-документов
Доступ к метаданным в PDF-файлах
Заключение
Spire.PDF для Python — это всесторонняя библиотека, которая позволяет разработчикам программно манипулировать PDF-файлами. Она поддерживает:
Генерацию PDF с нуля
Редактирование существующих документов
Объединение или разделение PDF-документов
Конвертацию PDF в другие форматы файлов
Чтение содержимого PDF-документов
Чтобы установить библиотеку, выполните команду:
pip install spire.pdf
Примечание: Spire.PDF для Python — это коммерческая библиотека, которая добавляет сообщения об оценке в сгенерированные документы. Доступна бесплатная версия, но она ограничивает загрузку PDF до 10 страниц на документ.
Вы также можете установить бесплатную версию через pip:
pip install freespire.pdf
Теперь давайте погрузимся в различные техники извлечения.
Поисковые PDF содержат выделяемый текст, что делает извлечение простым. Класс PdfTextExtractor в Spire.PDF предоставляет методы для извлечения текста со специфических страниц, в то время как класс PdfTextExtractOptions позволяет настраивать процесс извлечения, например, задавать прямоугольную область для извлечения.
Следующий пример демонстрирует, как извлечь текст со всех страниц PDF и сохранить его в отдельные .txt файлы. Метод ExtractText() извлекает содержимое, сохраняя структуру документа, что обеспечивает сохранение оригинального макета извлеченного текста.
from spire.pdf.common import *
from spire.pdf import *
# Создаем объект PdfDocument
doc = PdfDocument()
# Загружаем PDF-документ
doc.LoadFromFile("C:/Users/Administrator/Desktop/Input.pdf")
# Перебираем страницы документа
for i in range(doc.Pages.Count):
# Получаем конкретную страницу
page = doc.Pages[i]
# Создаем объект PdfTextExtractor
textExtractor = PdfTextExtractor(page)
# Создаем объект PdfTextExtractOptions
extractOptions = PdfTextExtractOptions()
# Устанавливаем IsExtractAllText в True
extractOptions.IsExtractAllText = True
# Извлекаем текст со страницы
text = textExtractor.ExtractText(extractOptions)
# Записываем текст в файл txt
with open('output/TextOfPage-{}.txt'.format(i + 1), 'w', encoding='utf-8') as file:
lines = text.split("\n")
for line in lines:
if line != '':
file.write(line)
doc.Close()
PDF-файлы часто содержат встроенные изображения, которые можно извлекать программно с помощью класса PdfImageHelper. Этот утилитный класс предоставляет метод GetImagesInfo(), который извлекает все данные изображений с заданной страницы, включая размеры и информацию о пикселях.
Извлеченные изображения можно сохранить в различных форматах, таких как PNG или JPEG. Следующий пример демонстрирует, как просканировать каждую страницу PDF, идентифицировать встроенные изображения и сохранить их как отдельные файлы.
from spire.pdf.common import *
from spire.pdf import *
# Создаем объект PdfDocument
doc = PdfDocument()
# Загружаем PDF-документ
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.pdf")
# Создаем объект PdfImageHelper
imageHelper = PdfImageHelper()
# Объявляем переменную int
index = 0
# Перебираем страницы
for i in range(0, doc.Pages.Count):
# Получаем конкретную страницу
page = doc.Pages.get_Item(i)
# Получаем всю информацию об изображениях с конкретной страницы
imageInfos = imageHelper.GetImagesInfo(page)
# Перебираем информацию об изображениях
for imageInfo in imageInfos:
# Задаем имя выходного файла изображения
imageFileName = "C:\\Users\\Administrator\\Desktop\\Extracted\\Image-{0:d}.png".format(index)
# Получаем конкретное изображение
image = imageInfo.Image
# Сохраняем изображение в файл png
image.Save(imageFileName)
index += 1
# Освобождаем ресурсы
doc.Dispose()
Извлечение структурированных табличных данных из PDF является распространенной задачей для анализа данных. Spire.PDF предоставляет класс PdfTableExtractor, который идентифицирует таблицы в PDF и позволяет извлекать данные на уровне ячеек.
Метод ExtractTable() возвращает список таблиц, каждая из которых может быть обработана построчно. Следующий пример демонстрирует, как извлечь таблицы из PDF и сохранить их в структурированном текстовом формате.
from spire.pdf.common import *
from spire.pdf import *
# Создаем объект PdfDocument
doc = PdfDocument()
# Загружаем PDF-файл
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf")
# Создаем список для хранения извлеченных данных
builder = []
# Создаем объект PdfTableExtractor
extractor = PdfTableExtractor(doc)
# Извлекаем таблицы с конкретной страницы (индекс страницы начинается с 0)
tableList = extractor.ExtractTable(0)
# Проверяем, что список таблиц не пуст
if tableList is not None:
# Перебираем таблицы в списке
for i in range(len(tableList)):
# Получаем конкретную таблицу
table = tableList[i]
# Получаем количество строк и столбцов
row = table.GetRowCount()
column = table.GetColumnCount()
# Перебираем строки и столбцы
for m in range(row):
for n in range(column):
# Получаем текст из конкретной ячейки
text = table.GetText(m, n)
# Добавляем текст в список
builder.append(text + " ")
builder.append("\n")
builder.append("\n")
# Записываем содержимое списка в текстовый файл
with open("output/Table-{}.txt".format(i + 1), "w", encoding="utf-8") as file:
file.write("".join(builder))
Метаданные PDF включают свойства документа, такие как заголовок, автор, тема и ключевые слова. Свойство DocumentInformation класса PdfDocument предоставляет доступ к этим деталям.
Следующий пример демонстрирует, как извлечь и отобразить метаданные PDF.
from spire.pdf import *
from spire.pdf.common import *
# Создаем объект PdfDocument
doc = PdfDocument()
# Загружаем PDF-файл
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf")
# Получаем информацию о документе
properties = doc.DocumentInformation
# Инициализируем строку для хранения информации о документе
information = ""
# Извлекаем стандартные свойства документа
information += "\nTitle: " + properties.Title
information += "\nAuthor: " + properties.Author
information += "\nSubject: " + properties.Subject
information += "\nKeywords: " + properties.Keywords
# Печатаем свойства документа
print(information)
# Освобождаем ресурсы
doc.Dispose()
Статья демонстрирует, как извлекать текст, изображения, таблицы и метаданные из PDF-документа с помощью Python. Следуя примерам в этом руководстве, вы можете эффективно обрабатывать PDF для анализа данных, управления документами и автоматизации.

Начнём с того, что Python – это не просто язык для веб-разработки или data science. Благодаря множеству специализированных библиотек, мы можем творить настоящие чудеса. И нет, я не шучу – на Python создано немало крутых инди-игр!
Самое крутое в разработке игр на Python – низкий порог входа. Если вы уже знаете основы языка, то буквально за пару дней сможете создать свой первый платформер или "змейку". А дальше – только ваша фантазия и упорство!
Pygame - самая популярная библиотека:
—Простой и понятный синтаксис
—Огромное комьюнити
—Отличная документация
—Ограниченные возможности для 3D
—Не самая высокая производительность
Arcade - современная альтернатива:
—Современный и чистый API
—Встроенная физика
—Хорошая производительность
—Меньше обучающих материалов
—Относительно молодая библиотека
Kivy - для кроссплатформенной разработки:
—Работает на всех платформах, включая мобильные
—Поддержка мультитач
—Сложнее в освоении
—Больше подходит для приложений
Из личного опыта могу сказать – начните с Pygame. Эта библиотека как конструктор LEGO: простая, понятная и при этом мощная. Вот что можно сделать уже на старте:
—2D-платформеры
—Аркады
—Головоломки
—Карточные игры
—Шутеры с видом сверху
Но есть и подводные камни (куда же без них?). Python не самый быстрый язык, поэтому для создания масштабных 3D-игр лучше выбрать что-то другое. Зато для прототипирования или создания небольших игр – самое то!
Прокачай свои хард-скиллы на максимум - клик
Привет пикабушники!
Сегодня мы создадим и обучим модель инверсионной диффузии для генерации изображений.
Требования - python, conda/rocm, pytoch, torchvision matplotlib(для визуализации)
1 Скачайте и установите python, на GNU/Linux установите uv , а затем uv python install python3.12
2 Создайте и активируйте виртуальное окружение.
Что такое виртуальное окружение(venv)? venv это изолированная среда python для установки зависимостей
1 Вариант (для uv, очень простой)
uv venv .venv --python python3.12, выполните команду, которую выдаст uv,
установка зависимостей в окружении uv pip install datasets torch torchvision matplotlib (для cpu, для gpu ниже).
Внимание!! Вам нужна особая команда для установки torch с поддержкой gpu.
Полный список здесь -
uv pip install torch torchvision --index-url https://download.pytorch.org/whl/cu128, это для nvidia
uv pip install torch torchvision --index-url https://download.pytorch.org/whl/rocm6.4 amd rocm(только на GNU/Linux).
2 Вариант для python venv.
На винде - py -3.12 -m venv .venv, дальнейшие этапы аналогичные, только команды для установки зависимостей без uv, просто pip.
3 Этап создайте файл, назовите его как хотите, но с расширением py , например model.py.
Скопируйте туда данный код, запустите через python вашфайл.py и начнется скачивание mnist датасет с рукописными цифрами и затем обучение в 20 эпох.
Если у вас слабый gpu или его нет, то, к сожалению, ждать нужно будет очень долго.
С gpu +- час - 2 часа. В результате у вас отобразится результат генерации, а также поле для ввода цифры, чтобы сгенерировать. Чем больше эпох при обучении, тем лучше результат. Но не стоит ставить огромные значения, модель может переобучиться.
Для тех у кого нет gpu можете загрузить пред обученную модель с моего гитхаба.

Как это работает и что это такое
Это условная диффузионная модель (Conditional Diffusion Model), которая генерирует изображения цифр MNIST (0–9) с контролем над классом (например, можно запросить генерацию именно цифры "5"). Модель сочетает:
Диффузионный процесс — постепенное добавление/удаление шума.
Условную генерацию — зависимость от целевого класса (цифры).
Архитектуру U-Net — для обработки изображений на разных уровнях детализации.
Как это работает?
1. Прямой диффузионный процесс (заражение шумом)
Цель: Постепенно превратить изображение в случайный шум за T=1000 шагов.
Математика:
xt=αˉt
⋅x0+1−αˉt
⋅ϵ
где:
x0 — исходное изображение,
ϵ — случайный шум (Gaussian noise),
αˉt=∏s=1t(1−βs) — кумулятивное произведение коэффициентов "чистоты" сигнала.
В коде:
python
1
2
3
4
⌄
def forward_diffusion(self, x0, t):
noise = torch.randn_like(x0)
xt = sqrt_alphas_cumprod[t] * x0 + sqrt_one_minus_alphas_cumprod[t] * noise
return xt, noise
2. Обратный процесс (генерация из шума)
Цель: Восстановить изображение из шума, шаг за шагом уменьшая шум.
Как учится модель?
На каждом шаге t модель предсказывает шум ϵθ(xt,t,y) , где y — целевой класс (цифра).
Функция потерь: MSE между предсказанным и реальным шумом:
L=Ex0,ϵ,t[∥ϵ−ϵθ(xt,t,y)∥2]
В коде:
def forward_diffusion(self, x0, t):
noise = torch.randn_like(x0)
xt = sqrt_alphas_cumprod[t] * x0 + sqrt_one_minus_alphas_cumprod[t] * noise
return xt, noise
1
2
noise_pred = self.model(xt, t, y) # Предсказание шума
loss = F.mse_loss(noise_pred, noise) # Расчет потерь
3. Условная генерация (ключевая особенность)
Модель генерирует изображение конкретного класса (например, цифру "7") благодаря:
Встраиванию класса:
Класс y преобразуется в эмбеддинг через nn.Embedding(num_classes, class_emb_dim).
Эмбеддинг проходит через MLP для нелинейного преобразования.
Интеграция в U-Net:
В каждом блоке U-Net информация о классе добавляется к промежуточным активациям:
noise_pred = self.model(xt, t, y) # Предсказание шума
loss = F.mse_loss(noise_pred, noise) # Расчет потерь
1
h = h + t_emb[..., None, None] + c_emb[..., None, None]
Это позволяет модели адаптировать обработку изображения под целевую цифру.
4. Архитектура модели: Условный U-Net
Структура:
Downsampling: 2 уровня уменьшения размерности (с сохранением skip-соединений).
Bottleneck: Обработка на низком разрешении.
Upsampling: 2 уровня увеличения размерности (с использованием skip-соединений).
Особенности:
Позиционное кодирование времени: timestep_embedding преобразует шаг t в вектор, чтобы модель "понимала", на каком этапе диффузии она работает.
Групповая нормализация (GroupNorm): Улучшает стабильность обучения.
SiLU активации: Нелинейность, улучшающая градиентный поток.
Этапы работы модели
1. Обучение
Загружаем данные MNIST (нормализованные в диапазон [-1, 1]).
Для каждого батча:
Случайно выбираем шаг диффузии t∈[0,T−1] .
Добавляем шум к изображению: xt=f(x0,t) .
Модель предсказывает шум ϵθ(xt,t,y) .
Обновляем веса через MSE-потерю.
Каждую эпоху генерируем образцы для всех классов (0–9) и сохраняем их.
2. Генерация (сэмплирование)
Начинаем с случайного шума xT∼N(0,I) .
Итеративно уменьшаем шум от t=T−1 до t=0 :
Предсказываем шум ϵθ(xt,t,y) .
Обновляем изображение:
xt−1=αt
1(xt−1−αˉt
βtϵθ)+σtz
где z — новый шум (если t>0 ).
На выходе получаем чистое изображение x0 нужного класса y .
Скачать пред обученную модель
https://github.com/Karag0/simple-diffusiuion-model/releases/...
А на этом всё!
Многим разработчикам сегодня интересно, какая нейросеть для программирования считается лучшей, ведь инструментов становится всё больше и каждый обещает упростить работу. Современный ИИ для программистов умеет не только писать код, но и анализировать проекты, предлагать оптимальные решения и комплексно помогать в создании приложений.
С развитием технологий ИИ для написания кода вышел на новый уровень: теперь он генерирует функции на Python, работает с проектами на C++ и даже интегрируется в редакторы. Выбирая лучшую нейросеть для программистов, важно учитывать не только точность, но и удобство использования — особенно если хочется протестировать сервисы бесплатно. Выбор подходящей нейросети для написания кода требует внимательности: мы отобрали лучшие решения не по рекламным обещаниям, а по реальной практике использования.

При составлении рейтинга учитывались такие параметры, как поддержка языков (Python, C++ и других), качество автодополнения, работа с отладкой и интеграция в IDE вроде VS Code и JetBrains. Кроме того, мы проверяли скорость генерации, наличие бесплатных тарифов и возможности локального развёртывания. Такой подход позволяет выделить не просто модные сервисы, а действительно лучшие нейросети для написания кода, которые дают ценность программисту на разных этапах разработки.
Все ИИ для создания кода из нашей подборки работают в РФ без ограничений через специализированные платформы. Переходите по ссылкам.
💻 Code Generator – одна из лучших нейросетей для программирования, создаёт рабочие решения с пояснениями и помогает понять алгоритмы, идеально подходит для учебных задач и быстрого прототипирования без сложной регистрации и VPN.
💻 ChatGPT-5 – самая популярная ИИ для программирования, работает из РФ без сложностей через наш шлюз, помогает отлаживать и улучшать код, автоматически переключаясь между быстрым и глубоким режимом мышления, отлично подходит тем, кто ищет нейросеть для профессиональной разработки.
💻 Grok 4 – нейросеть для программистов от Илона Маска, ускоряющая генерацию кода и исправление ошибок, сохраняя контекст больших фрагментов и объясняя алгоритмы простым языком, идеально для изучения Python, Java и C++.
💻 Claude Opus 4.1 – входит в ТОП нейросетей для программирования, эксперт в проектировании сложных приложений, объяснении логики кода и адаптации алгоритмов под нестандартные задачи, идеально подходит для создания прототипов и серьёзной разработки.
💻 GPTunneL Code – агрегатор более сотни моделей для программирования и обработки различных данных, позволяющий гибко выбирать ИИ под проект, создавать, анализировать и отлаживать код.
💻 Gemini 2.5 Pro – бесплатная ИИ для написания кода от Google, который помогает оптимизировать, улучшать читаемость и адаптировать решения под разные задачи, поддерживает быстрый прототипинг и универсально подходит для учебных и рабочих проектов.

Нейросеть от Study AI умеет быстро генерировать рабочий код на Python, C++, Java и других языках, объясняя логику и помогая в отладке. Вы избавитесь от тупика в программировании: описали задачу на русском или английском — и получили решение вместе с пояснениями. Эта нейросеть для программистов работает онлайн, без VPN и регистрации, с базовым бесплатным доступом.
⚡ Преимущества для программистов:
Поддержка нескольких языков программирования — Python, C++, Java и других легко переключаться между ними
Генерирует код вместе с пояснениями — логика понятна и прозрачна
Работает без установки и VPN — просто зайти и писать код
Подходит и новичкам, и опытным — универсальный инструмент для обучения и практики
Базовая генерация кода бесплатна — удобно пробовать без оплаты
Служит отличным помощником студентам и тем, кто решает учебные задачи. Когда нужно быстро получить код — этот ИИ-бот идеально подойдёт. Однако для крупных коммерческих проектов или глубокой настройки алгоритмов обратитесь к локальным или интегрируемым генераторам кода — тут больше подход именно для прототипов и учебной практики. Особенность: объяснения к коду упрощают понимание, а бесплатный доступ без регистрации снижает барьер входа.
==========================

Новейшая AI для кодинга доступна из РФ
Один из лучших и умнейший генератор кода ChatGPT-5 по мнению абсолютного большинства рейтингов в обзоров. Доступен через нашу платформу, работает без VPN. Автоматически переключается между быстрым и глубоким режимами мышления. Он помогает создавать и отлаживать код на Python, C++, Java, обеспечивая точность и эффективность. Поддерживает сложные запросы, идеален для уверенных пользователей и тех, кто ищет ИИ для программирования с минимальными ограничениями.
⚡ Преимущества для программистов:
Автопереход между режимами — быстрый и «thinking» для сложных задач
Улучшено понимание структуры и дизайна кода — особенно в интерфейсе и логике
Высокая точность и снижение ошибок благодаря мощному ИИ-движку
Работает через браузер без VPN — доступно и удобно для отечественных разработчиков
Обширный контекст — справляется с большими фрагментами кода и проектами
Этот бот-генератор отлично подойдёт тем, кто хочет использовать ИИ-помощника без сложной настройки и ограничений. Если нужно быстро прототипировать UI, исправить баг или объяснить архитектуру — GPT-5 проявит себя. Но если хочется локальной установки или полного контроля над моделью — лучше рассмотреть локальные ИИ-решения. Дополнительно стоит отметить, что автоматическая маршрутизация между режимами делает его одной из самых удобных нейросетей для программирования на Python и Java.
==========================

Grok 4 — это продвинутая нейросеть для программистов от Илона нашего Маска, ориентированная на генерацию и оптимизацию кода. Она поддерживает Python, Java, C++ и другие языки, умеет анализировать ошибки и предлагать рабочие исправления. Отличается умением объяснять алгоритмы простым языком и помогает быстрее осваивать новые технологии. Работает напрямую из браузера, без VPN.
⚡ Преимущества для программистов:
Понимает большие запросы и сохраняет контекст диалога
Генерирует код с комментариями и пояснениями к алгоритмам
Подходит для Python, C++ и Java — охватывает популярные языки
Встроенная проверка и исправление ошибок кода
Не требует VPN и работает быстро через браузер
Этот ИИ для программирования подходит студентам и разработчикам, которым важно получить не только готовый фрагмент кода, но и разъяснение логики. Grok 4 помогает писать учебные проекты, ускорять прототипирование и разбирать сложные алгоритмы. Для больших коммерческих решений он уступает локальным нейросетям, зато в обучении и разработке прототипов проявляет себя как одна из лучших нейросетей для написания кода. Удобно использовать, когда нужно понять, как работает программа, а не просто скопировать готовый результат.
==========================

Claude Opus 4.1 — мощный ИИ для программирования, созданный с упором на глубокое понимание логики и структуры кода. Он не просто генерирует готовые куски программ, а помогает проектировать архитектуру решений и адаптировать алгоритмы под разные языки. Сервис способен анализировать большие фрагменты и давать развернутые пояснения, что делает его удобным как для практикующих разработчиков, так и для студентов. (≈440 символов)
⚡ Преимущества для программистов:
Умеет объяснять решения простым языком, что полезно для обучения
Справляется с длинными запросами и большим объёмом кода
Может переписывать проект с одного языка на другой
Помогает находить ошибки на раннем этапе разработки
Поддерживает структурное планирование сложных систем
Claude Opus 4.1 подойдёт тем, кто ищет не только генератор кода, но и умного ассистента для проектирования приложений. Он хорош для создания прототипов, отработки алгоритмов и написания программ с нуля, когда важно не просто получить готовый кусок, а понять, почему он работает именно так. Для быстрых однотипных задач есть более простые нейросети, но если нужно качественное объяснение и гибкость в работе с логикой — эта модель будет одним из лучших вариантов.
==========================

GPTunneL Code — это агрегатор-бот, объединяющий более ста моделей ИИ, включая GPT-4o, Claude и другие. Он позволяет автоматически генерировать, анализировать и отлаживать программы для игр или приложений. Работает по модели pay-as-you-go, удобный интерфейс на русском и API-доступ без подписки делают этот инструмент одним из лучших ИИ для кодинга. (≈420 символов)
⚡ Преимущества для программистов:
Широкий выбор моделей ИИ под любые языки и задачи
Создание, рефакторинг и отладка кода из одного окна
Плата только за фактическое использование — без абонплаты
Интерфейс доступен на русском, понятен новичкам и специалистам
API-интеграция облегчает автоматизацию рабочих сценариев
Этот генератор кода особенно подойдёт тем, кто ищет нейросеть для программистов с гибкостью и разнообразием выбора. Можно быстро переключаться между моделями и подбирать ту, что оптимально пишет код или делает анализ. Для тех, кто не готов платить за подписки, модель оплаты по использованию — существенный плюс. Если нужно глубокое сравнение производительности моделей на конкретных задачах — придётся тестировать вручную, но для универсального кода и прототипов GPTunneL Code — отличное решение.
==========================

Gemini 2.5 Pro — это интеллектуальный помощник для программистов, который умеет не только писать рабочий код, но и оптимизировать его под конкретные задачи. Он одинаково уверенно работает с высокоуровневыми языками вроде Python и Java и с низкоуровневым C++. Сервис доступен без ограничений и открывает доступ к современному ИИ для написания кода бесплатно и без технических барьеров. (≈414 символов)
⚡ Преимущества для программистов:
Разбирается в синтаксисе разных языков и корректно адаптирует решения
Помогает улучшать читаемость и производительность кода
Полностью бесплатный доступ без дополнительных настроек
Может преобразовать алгоритм из одного языка в другой
Даёт понятные комментарии и объяснения к сгенерированным решениям
Gemini 2.5 Pro будет полезен тем, кто ищет нейросеть для программирования, способную быстро подсказать альтернативный способ реализации или найти слабые места в логике. Особенно хорошо он показывает себя в задачах обучения, при написании лабораторных и создании учебных проектов. Для крупных коммерческих систем возможностей может не хватить, зато как бесплатный ИИ для программистов он уверенно входит в топ нейросетей для написания кода и анализа алгоритмов.
==========================

Это специализированный ИИ-ассистент, заточенный под нужды разработчиков. Он способен генерировать код, разъяснять фрагменты, помогать оформлять логику и исправлять ошибки. Управляется через интуитивный интерфейс GPTunneL и работает без подписки — подходит для тех, кто ищет бесплатное и гибкое решение в среде кода. (≈397 символов)
⚡ Преимущества для программистов:
Обучен на языковом GPT-ядре — хорошо справляется с формулировкой задач и пояснений
Разбирает фрагменты логики и подсказывает, как правильно написать или улучшить код
Бесплатен и работает без VPN — доступен сразу через платформу
Можно использовать как генератор кода и как сопровождающий инструмент обучения
Интерфейс на русском — удобно для локального контекста
Это решение отлично подойдёт тем, кто ищет генератор, способный сразу ответить на вопросы о логике или подсказать реализацию. Особенно полезен для учебных проектов и отладки. Но если нужно сравнить разные модели или провести глубокое сравнение языков (например, Python vs C++ vs Java), придётся прибегать к эксперименту с другими ИИ-ботами. GPT-ассистент для программистов хорошо закрывает задачу понимания кода, но не заменяет глубокое сравнение разных нейросетей.
==========================

GigaChat — мощный ИИ для программирования, который умеет генерировать, отлаживать и комментировать код на Python, Java, HTML и SQL. Нейросеть помогает быстро создавать прототипы, анализировать код и ускоряет процесс разработки сложных приложений.
⚡ Преимущества для программистов:
Поддержка нескольких языков программирования
Возможность отладки и форматирования кода
Генерация комментариев и пояснений к коду
Интуитивно понятный интерфейс
Подходит разработчикам, которые хотят ускорить создание и проверку кода, работать с базами данных и веб-приложениями. Меньше подходит тем, кто ищет исключительно локальные нейросети для программирования.
==========================

Cursor — это мощный AI-редактор кода, построенный на основе Visual Studio Code, с интеграцией ИИ для ускорения разработки. Он предлагает интеллектуальное автодополнение, поддержку многократных правок, автоматическое исправление ошибок и возможность редактирования с помощью естественного языка. Cursor позволяет обновлять целые классы или функции с помощью простых команд, значительно повышая продуктивность разработчиков.
⚡ Преимущества для программистов:
Интеллектуальное автодополнение, предсказывающее следующие изменения в коде.
Поддержка многократных правок, позволяющая одновременно изменять несколько строк кода.
Автоматическое исправление ошибок и предложение улучшений кода.
Возможность редактирования кода с помощью естественного языка, упрощая взаимодействие с кодовой базой.
Поддержка импорта расширений, тем и горячих клавиш, обеспечивая знакомую среду разработки.
Режим конфиденциальности, гарантирующий, что код не сохраняется удаленно без согласия пользователя.
Cursor идеально подходит для профессиональных разработчиков, стремящихся ускорить процесс написания и редактирования кода. Он особенно полезен при работе с большими кодовыми базами, где требуется быстрое внесение изменений и исправлений. Однако для начинающих программистов или тех, кто предпочитает более традиционные IDE, освоение всех возможностей Cursor может потребовать времени.
==========================

Visual Studio IntelliCode — бесплатная нейросеть от Microsoft для программистов, интегрированная в VS. ИИ помогает писать код быстрее и качественнее, предоставляя интеллектуальные рекомендации и исправления ошибок.
⚡ Преимущества для программистов:
Интеграция с Visual Studio
Интеллектуальные рекомендации по коду
Поддержка множества языков программирования
Автоматическое исправление ошибок
Идеально для разработчиков, работающих в Visual Studio, особенно на C#, C++ и Python. Меньше подойдет тем, кто предпочитает работать без интеграции с IDE.
==========================

CodeT5 и CodeT5+ — нейросети, обученные на больших репозиториях GitHub, включая комментарии. Они помогают генерировать код, автозавершать функции, а также оптимизировать и рефакторить проекты.
⚡ Преимущества для программистов:
Генерация кода по описанию на естественном языке
Автозавершение функций и методов
Рефакторинг и оптимизация кода
Поддержка множества языков программирования
Подходит разработчикам, работающим с большими проектами и сложными алгоритмами. Меньше эффективна для простых учебных задач или одноязычных проектов.
==========================

AskCodi — нейросеть для программистов, помогающая писать код, рефакторить и объяснять сложные фрагменты. Поддерживает разные языки и интегрируется с популярными IDE, делая процесс кодинга проще и быстрее.
⚡ Преимущества для программистов:
Поддержка множества языков программирования
Рефакторинг и оптимизация кода
Объяснение сложных фрагментов кода
Интеграция с различными средами разработки
Подходит новичкам и опытным разработчикам, которым нужна помощь в создании и улучшении кода. Меньше подходит тем, кто работает исключительно с локальными инструментами без подключения к облаку.
Понятие «лучшая нейросеть для программирования» зависит от целей: кто-то ищет инструмент для ускорения рутинного кодинга, кто-то — помощника для архитектурных решений или рефакторинга. При выборе ориентируйтесь на ключевые критерии: поддерживаемые языки (Python, C++ и прочие), точность автодополнения, контекстное понимание репозитория, интеграция с вашей IDE (VS Code, JetBrains), безопасность и политика конфиденциальности кода. Тестируйте модель на реальных задачах — попросите определить функцию, провести рефакторинг и объяснить сложный участок кода. Обратите внимание на наличие бесплатного тарифа или демо: это даст быстрый практический опыт без финансовых рисков. Наконец, важно учитывать workflow команды — «лучшая» нейросеть для одного разработчика может не подойти для команды с CI/CD и строгими правилами безопасности.
Современная нейросеть для программистов — это не просто продолжение текущей строки: это модель, которая анализирует контекст файла, историю коммитов, зависимостей и иногда даже тесты, чтобы генерировать осмысленные блоки кода. В отличие от простых автодополнений, ИИ для программирования умеет предлагать целые функции, писать тесты, преобразовывать комментарии в код и объяснять решения на естественном языке. Качество таких предложений измеряется не только минимизацией синтаксических ошибок, но и соответствием архитектурным требованиям — разделение логики, обработка исключений, безопасность. Также продвинутые модели умеют подстраиваться под стиль проекта (code style) и могут работать локально, если конфиденциальность критична.
При сравнении учитывайте: поддерживаемые языки (важно наличие качественных промптов и шаблонов для Python и C++), latency (скорость ответа), качество контекстного понимания (умение читать весь файл/проект), интеграцию с IDE/CI, поддержку языков документации, возможность локального развёртывания и опции приватности. Отдельно проверьте наличие функций для тестирования результата — автогенерация unit-тестов и проверок статической аналитики. Важны также экономические параметры: есть ли бесплатный тариф, как считаются запросы (по токенам/запросам), и насколько предсказуемы расходы. Наконец, обратите внимание на экосистему — плагины, сообщества, готовые шаблоны и примеры использования.
Для простых задач и пробного использования бесплатные нейросети или бесплатные тарифы продвинутых сервисов часто вполне достаточны: можно опробовать автодополнение, генерацию функций и базовую рефакторинговую помощь. Однако для серьёзных проектов платные планы обычно дают более высокую точность, расширенный контекст (чтобы модель «видела» больше файлов), гарантию SLA, приватность и поддержку командных функций. Если ваш код содержит коммерческую или приватную информацию, обратите внимание на опции локального развёртывания и контрактные условия — многие бесплатные сервисы обрабатывают данные на своих серверах. Выбор зависит от масштаба: для хобби — бесплатно, для продакшна и корпоративных R&D — чаще платно.
Некоторые инструменты показывают отличные результаты на Python за счёт богатых датасетов и простоты синтаксиса; другие сильны в C++ благодаря учёту типизации и шаблонов. Универсальные решения (например, коммерческие ассистенты и крупные LLM-провайдеры) стараются покрыть оба языка, но качество может отличаться по языкам. При выборе тестируйте конкретные кейсы: генерация классов с шаблонами и шаблонной метапрограммой в C++, работа с асинхронностью и дата-фреймами в Python. Уточняйте также поддержку специфичных библиотек (PyTorch/NumPy для Python, STL/Boost для C++). Практический тест на реальном проекте даёт наиболее объективную оценку.
Вопрос безопасности критичен: многие облачные сервисы обрабатывают код на своих серверах, что может быть неприемлемо для закрытых проектов. Ищите варианты с локальным развёртыванием или гарантией неиспользования кода клиентов в обучении модели. Проверьте политику поставщика по хранению и ретенции данных, возможность отключения логирования и шифрование трафика. Также учитывайте риск утечки секретов: никогда не отправляйте в промпт реальные ключи или пароли — используйте механизмы redaction или секрет-менеджеры. Для корпораций часто выбирают локальные модели или привилегированные корпоративные планы с контрактными гарантиями.
Интеграция возможна на нескольких уровнях: плагин в IDE (VS Code, JetBrains) для интерактивного автодополнения; CI-пайплайн для автогенерации шаблонов, тестов и проверок кода; инструменты для ревью, которые помогают писать комментарии и улучшать PR; и CLI-утилиты для массовой трансформации кода. Практический сценарий — использовать ИИ для создания черновика функции и генерации соответствующих unit-тестов, затем прогонять статанализ и выполнять ревью человеком. В командах эффективен рабочий процесс, где ИИ ускоряет рутинную часть, а разработчики занимаются дизайном и валидацией архитектуры.
Локальные модели разворачиваются на вашей инфраструктуре и не отправляют данные в облако — это важно для соблюдения комплаенса и защиты интеллектуальной собственности. Такие нейросети особенно полезны в финтехе, медицине и других областях с жёсткими требованиями к безопасности. Минусы: нужны ресурсы (GPU/CPU), настройка и поддержка модели, а также возможные ограничения по качеству по сравнению с крупнейшими облачными LLM. Тем не менее, для многих команд компромисс между приватностью и стоимостью делает локальные решения оптимальным выбором.
Генерация кода должна сопровождаться верификацией: запускайте unit-тесты, интеграционные тесты и статическую проверку (linters, sanitizers). Автоматизируйте прогон тестов в CI после вставки сгенерированного блока. Проводите ревью кода человеком — ИИ может допускать логические ошибки или небезопасные конструкции. Проверяйте производительность и профиль памяти, особенно для C++-модулей, и используйте fuzz-тестирование для критичных частей. Для повторяемости сохраняйте промпты и контекст, чтобы можно было воспроизвести результат и откатиться при необходимости.
Нейросети хорошо помогают в быстром прототипировании приложений: генерация CRUD-эндпойнтов, создание моделей данных, написание тестов и документации. В стартапах ИИ ускоряет MVP-разработку; в больших компаниях — автоматизирует рутинные задачи, даёт подсказки по оптимизации и рефакторингу. Специфичные кейсы: миграция кода между фреймворками, написание адаптеров, генерация API-клиентов и тестов. Особенно полезны ИИ-ассистенты при работе с библиотеками (например, преобразование numpy-кода в векторизованные операции или оптимизация циклов в C++). Главное — комбинировать ИИ с инженерами: модель сокращает время на рутинную работу, а специалист проверяет архитектуру и безопасность.
У меня за плечами приличный опыт разработки ботов разной сложности. Но недавно я взялся за задачу, которая в мыслях выглядела настолько лёгкой, что я планировал уложиться за час. В общем переоценил свои навыки)))). При этом, в разработке мне всегда активно помогает нейросеть. Понятно, что если не владеешь Питоном никакая нейронка ситуацию не спасет.
Нужно было:
бот, который каждое утро в наш общий чат с друзьями кидает сообщение:
прогноз погоды на день,
курс валют,
курс крипты.
Хотел порадовать друзей, себя проверить на скорость реализации, ну и так чисто поржать!))
И вот началось.
Я сел и понял: просто сделать /weather мало. Нужно автоматическое сообщение в определённое время.
Значит, придётся подключать планировщик задач. Варианты:
apscheduler — классика для Python;
cron на сервере (но я хотел, чтобы бот оставался автономным);
или костыль с asyncio.sleep(), но тут надо файл багов клепать.
Сделал проще, использовал планировщик pythonanywhere - ту да же и деплой бота).
Я думал: «Да что там, подключу API и готово».
В реальности пришлось:
зарегаться на OpenWeather,
получить API-ключ (а он еще и не сразу активируется),
настроить обработку ошибок (а то погода иногда не грузится),
форматировать сообщение так, чтобы не было унылым набором цифр.
В итоге бот пишет что-то вроде:
📊 Прогноз на день:
09:00 — 14.9°C, Облачно с прояснениями 🌤️
12:00 — 18.6°C, Облачно с прояснениями 🌤️
15:00 — 17.8°C, Переменная облачность 🌤️
18:00 — 18.6°C, Небольшая облачность 🌤️
21:00 — 20.0°C, Облачно с прояснениями 🌤️
И вот именно эта «мелочь с автоподстановкой смайликов» меня реально заморочила, перебрал кучу вариантов всяких смайлов))).

Валюты я тянул через ЦБ РФ (официальный XML-API).
Крипту — через coingecko API.
Тут все просто:
курсы пришлось парсить;
coingecko иногда выдаёт ошибку 429 (ограничение по запросам), пришлось ставить задержку и кэширование (это я уже на опыте схавал, когда в качестве эксперимента писал бота по автоматическим сигналам торговли на криптобирже).
потом сижу думаю "какие нафиг запросы если запрос всего один в 07:00 утром))", стер код и упростил все до невозможости.

В какой-то момент я ловил себя на мысли: «Что сижу с этим мини ботом уже весь вечер, сам себе мозги вскипятил».
Это самое простое:
нужно chat_id;
бот должен быть админом, иначе он не может писать в группу;
И в путь!
Локально всё работало идеально.
На pythonanywhere — нет.
Классика: timezones, конфликты библиотек.

В итоге всё заработало только после танцев с бубном.
Теперь каждое утро бот отправляет сообщение в чат:

Пара доделок и готово! Бот запущен! Мне приятно, друзья довольны, ну и так в целом было занятно заморочиться на вечер)).
Нет «простых» ботов. Даже самая мелкая идея рождает кучу нюансов.
Автоматизация всегда сложнее, чем кажется. Написать команду — легко, а вот заставить бота стабильно работать — совсем другое.
Опыт — это вообще не гарантия скорости. Иногда мелкая бытовая задача высасывает больше времени, чем серьёзный проект.
И главное не надо увлекаться и усложнять проект! А то я в черновом варианте еще хотел добавить новости прошедшего дня к сообщению о погоде))).
И хоть я потратил целый вечер, ощущение приятное, сделал маленький сервис, который реально работает на благо. Я к стати веду тг канал в котором бесплатно публикую всякие разборы, кейсы и гайды по работе с нейросетями Ум + AI = Доход
Попросил Deepseek написать код игры 2D космической стрелялки, на Android телефон. Для простоты, попросил изобразить примитивных врагов и кораблик игрока, в виде геометрических фигур, квадратные враги и треугольник-кораблик игрока. Получилась неожиданно приятная для глаз игра с эффектами взрыва врагов и мигание кораблика при столкновении с врагами.




