Часть 4. Аналитика и поддержка — ваш секретный козырь в сезонной гонке
Мониторинг ключевых метрик
Вы стоите у прилавка магазина в самый разгар школьного сезона. Вокруг суета, родители с детьми выбирают тетради и рюкзаки, кассы работают на пределе. Но что происходит в это время с вашим онлайн-магазином? Сколько человек сейчас на вашем сайте? Какие товары они просматривают? Сколько бросают в корзину и уходят?
Без четкого мониторинга вы упускаете золотую жилу данных, которые могут удвоить ваши продажи уже в этом сезоне.
Вот что вы должны отслеживать ежедневно:
Динамику продаж по категориям — не просто общую выручку, а как меняется спрос на каждую группу товаров. Если вы заметите всплеск спроса на какую-то категорию раньше конкурентов, вы сможете оперативно скорректировать ассортимент и рекламу.
Эффективность акций в реальном времени — не ждите конца сезона, чтобы понять, что работает. Создайте систему быстрого тестирования: запускайте параллельно 2-3 разных оффера и через 3-5 дней анализируйте, какой дает лучший результат.
Поведенческие паттерны аудитории — используйте Яндекс.Метрику и CRM, чтобы понять, как разные сегменты аудитории взаимодействуют с вашим сайтом. Например, родители первоклассников проводят больше времени на страницах с формой и канцелярией, а родители старшеклассников чаще ищут учебные пособия и репетиторов. Настройте персонализированные предложения именно для этих сегментов!
Оперативная корректировка стратегии
Школьный сезон длится не год, а считанные недели. У вас нет времени на долгие совещания и многостраничные отчеты. Нужна система быстрого реагирования, которая превратит ваши ошибки в конкурентное преимущество.
Вот как это работает на практике:
Тестирование в режиме реального времени — забудьте про "мы всегда так делали". Каждую неделю меняйте что-то в своей стратегии: креативы, таргетинги, офферы. Например, если вы заметили, что реклама с упором на "экономию" работает хуже, чем ожидалось, попробуйте акцентировать внимание на качестве или удобстве.
Конкурентный сканер — установите систему мониторинга, которая будет отслеживать действия ваших основных конкурентов. Что они рекламируют? Какие скидки предлагают? Какие креативы используют? Это не для того, чтобы копировать их, а чтобы найти свою нишу. Например, если все делают акцент на дешевизну, вы можете выделиться, сделав ставку на экологичность или персонализацию.
Гибкое управление бюджетом — не фиксируйте рекламный бюджет на весь сезон. Создайте систему, где 20% бюджета выделяется на эксперименты, 70% — на проверенные инструменты, и 10% — на оперативную корректировку. Если вы заметите, что какой-то канал дает неожиданно высокую отдачу (например, TikTok-реклама среди подростков), оперативно перераспределите средства.
Пост-сезонный анализ
Многие бизнесы, едва пережив сезонный пик, вздыхают с облегчением и забывают про анализ. Это ошибка! Самый ценный момент — когда сезон только закончился, а данные еще "свежие".
Вот как провести пост-сезонный анализ, который даст результат в следующем году:
Создайте "сезонный дневник" — соберите все данные в одном месте: статистику продаж, отзывы клиентов, результаты рекламных кампаний, заметки сотрудников. Не просто цифры, а контекст: что происходило в эти дни? Какие внешние факторы влияли на продажи? Погода? Каникулы? События в городе?
Проведите "вскрытие" неудач — не ограничивайтесь анализом того, что сработало. Изучите детально, почему не сработало то, что должно было работать. Например, если ваши скидки на канцелярию не привлекли ожидаемого числа покупателей, возможно, проблема была не в цене, а в том, что вы не учли, что родители предпочитают онлайн-покупки, и ваш сайт был неудобен для мобильных пользователей.
Создайте "дорожную карту" на следующий сезон — на основе полученных данных разработайте четкий план действий на следующий год. Укажите конкретные даты, ответственных, бюджет. Например:
15 июня — запуск рекламной кампании в Instagram с таргетингом на родителей первоклассников
20 июля — обновление баннеров на главной странице
1 августа — запуск акции 'Собери школьный набор'.
Ваша аналитика — это ваше будущее
Знаете, в чем главная разница между бизнесом, который выживает в сезонные пики, и бизнесом, который процветает? Не в бюджете, не в ассортименте, а в том, насколько быстро и точно он учится на своих ошибках и успехах.
Аналитика — это не скучные таблицы и графики. Это ваш личный детектив, который каждый день рассказывает вам истории о том, что нравится вашим клиентам, что их раздражает, как они принимают решения. И чем лучше вы научитесь "слушать" эти истории, тем больше клиентов будет возвращаться к вам снова и снова.
Школьный сезон 2026 года начнется задолго до 1 сентября. Он начнется в тот момент, когда вы откроете отчеты за этот сезон и начнете планировать следующий. Не упустите свой шанс стать тем самым бизнесом, к которому родители будут возвращаться из года в год, потому что вы точно знаете, что им нужно.
Здравствуйте! Это второй пост на Пикабу из серии про ЗАЙЦа.
В первом посте состоялось общее знакомство с уникальным устройством, а в данном посте прилагаем видео непосредственной его работы - таймлапс для наглядности)
Здравствуйте! Разрешите с вами поделиться оригинальным решением, как бороться с негативными моментами, работая удаленно.
Для ЛЛ – это пост об устройстве, которое обходит программы слежения за рабочим компьютером, имитируя работу пользователя. Все ссылки, описание и т.д. внизу, пролистывайте!
Для неленивых немного предыстории.
В 2020 году население нашей планеты познакомилось с таким явлением, как COVID-19 и массовым выводом сотрудников предприятий из офисов по домам. Обустроившись дома, люди оценили немалые преимущества – не нужно тратить время на поездку на работу и обратно домой (экономия на проезде/топливе), не нужно одеваться в соответствии с корпоративным стилем (одежда меньше изнашивается, духи вообще можно не использовать), даже обед можно выбрать не только тот, с чем пришел на работу и тем более, можно делать зарядку, не стесняясь других коллег (попробуйте это сделать в офисе в пиджаке и рубашке!).
Бесследно, к сожалению, эпидемия не прошла – здоровья поубавилось, по отзывам коллег они стали уставать больше, а одновременно с удобствами на удаленке пришли и недостатки – рабочий день у многих стал не привычные 8 часов, а растянулся до позднего вечера (у многих сказывается разница в часовых поясах, и бывает даже так, что кто-то еще спит, а кто-то уже))))), а на рабочий компьютер работодателем стали устанавливаться программы слежения, отвечающие за контроль рабочего времени и эффективность сотрудников.
Но удаленка на то и удаленка, что порой возникают ситуации, когда нужно отойти от ПК ненадолго (например, покормить и потискать любимого кота, помедитировать, сделать зарядку), но при этом не хочется, чтобы программа слежения записала простой в работе. Где есть спрос – значит, там будет и предложение. На рынке появились различные устройства, имитирующие элементарные функции мыши – джиглеры, кликеры и USB-флешки. Со временем увы, работодатель научился с ними бороться: порты USB, как правило, заблокированы, а вышеозвученные джиглеры и кликеры легко обнаруживаются программами слежения.
Чтобы обойти современные программы слежения за рабочим компьютером необходимо умное устройство, работающее так, словно человек сам работает за своим ПК, чтобы даже на скриншотах и видеозаписи экрана было видно работу пользователя. И таким устройством является ЗАЯЦ (ZAYAC). Когда необходимо, ЗАЯЦ эмулирует чтение любого текстового документа в формате PDF, делая это так, словно сам пользователь читает данный документ, задумчивая прокручивая вверх-вниз страницы и выделяя слова для каких-то своих целей, и главное, не повторяясь при этом не требую подключения к USB.
Всем привет, я Михаил Шпаков, руковожу отделом разработки. Захотелось поработать над каким-то проектом для души. В результате родилась платформа Statuser.
В этой статье я расскажу, как вечерами и на выходных делал Statuser (и продолжаю делать): с какими проблемами сталкивался, как выбирал стек, как не бросил проект на полпути — и что получилось в итоге.
Последние несколько лет в работе стало больше менеджмента: процессы, планирование, встречи, координация команд. Со временем я начал ловить себя на мысли, что очень хочется что-то поделать руками. Вернуться к коду, попробовать собрать продукт от начала и до конца, пройти путь не как менеджер, а как разработчик и автор идеи. Заодно — погрузиться в продуктовую часть, потрогать всё: интерфейсы, фичи, маркетинг, пользовательский опыт.
Так родился простой сервис для мониторинга доступности сайтов и серверов. Я хотел сделать его:
с минималистичным и понятным интерфейсом;
ориентированным в первую очередь на разработчиков, девопсов, админов;
с набором действительно нужных фич, ничего лишнего.
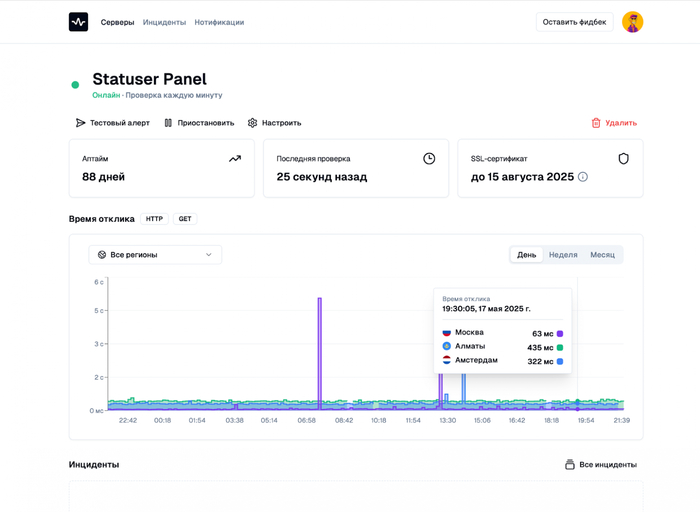
Как сейчас выглядит страница сервиса в мониторинге
❯ Идея проекта и первые шаги
Я довольно быстро определился с тем, что именно хочу сделать. Мониторинг — тема мне близкая: и по работе в облаке, и по личному опыту. Падения, медленные отклики, истёкшие SSL-сертификаты, забытые домены — всё это встречал в жизни не раз. Хотелось иметь простой и надёжный инструмент, который работает «из коробки», не требует заморочек и настройки Prometheus + Grafana + alertmanager, и понятен сразу.
На рынке таких решений много. Среди самых известных — UptimeRobot, Pingdom, BetterStack. Они полезны, и каждый по-своему хорош, именно благодаря им у меня сформировался свой вижн: я хотел собрать инструмент, который:
максимально простой и лаконичный — чтобы даже человек без технической подготовки мог разобраться;
при этом — удобный и функциональный для разработчиков, девопсов и админов — тех, кто работает с продакшеном каждый день;
визуально приятный и быстрый;
делает немного, но делает это хорошо.
В приоритете были:
простота запуска, без конфигурационных YAML-джунглей;
максимальная наглядность: статус виден сразу, без лишних графиков и переключений;
фокус на разработчиков и админов, которые хотят видеть, жив ли сайт или API, и быстро понять, что пошло не так.
Я начал с минимального функционала: одна проверка по HTTP. Сервис каждую минуту отправлял запрос и, если сайт недоступен, слал письмо на указанный емейл. Это уже было полезно — я подключил несколько своих доменов и убедился, что всё работает.
Первую версию — простое приложение с базовой логикой — я собрал буквально за пару дней, используя NestJS на бэке и Next.js на фронте. Использовал ChatGPT для генерации шаблонов кода, моделей, простых обработчиков — и это сильно ускорило старт.
Когда появилась необходимость как-то управлять проверками, стал набрасывать простую админку. Захотелось: добавить новую проверку, отредактировать, отключить. Но быстро понял, что нужна уже настоящая панель управления, с аккаунтами, входом, настройками и нормальным интерфейсом.
Так минимальная идея постепенно начала обрастать логикой, интерфейсами и дополнительными фичами. Всё это делалось по вечерам и выходным — без дедлайнов, но с удовольствием.
❯ Функциональность: как Statuser развивался и становился удобнее
Я запустил проект в декабре 2024 года. Сначала Statuser просто «тихо жил» — я подключил свои проекты, наблюдал за метриками, отлаживал систему. Но довольно быстро начали появляться первые реальные пользователи: кто-то приходил из поисковиков, кто-то по прямым ссылкам, которые я отправлял своим друзьям и знакомым. Люди пробовали сервис, подключали свои сайты, и, что особенно приятно — начинали задавать вопросы. Где посмотреть статистику за месяц? А можно уведомления в Telegram-группу? А как насчёт ping или проверки порта?
Так появилась первая настоящая обратная связь — сигнал, что продукт кому-то нужен. Стало ясно, что нужно двигаться дальше: развивать функциональность, давать больше гибкости, расширять возможности настроек. Вопросы пользователей стали естественным роадмапом, и я начал добавлять фичи — по мере приоритетов и доступного времени. Это стало хорошим двигателем развития.
Сначала появилась возможность отправлять уведомления не только на email, но и в Telegram — как в личные чаты, так и в группы. Это сильно улучшило скорость реакции и сделало сервис удобнее для команд.
Потом начал расширять сами типы проверок:
добавил ping и опрос TCP-портов;
возможность выбрать HTTP-метод (GET, POST, HEAD и др.);
задать заголовки и тело запроса — удобно для проверки API;
настроить таймаут;
отключить следование за 3xx-редиректами, если это важно для логики проверки.
Отдельно добавился блок контроля SSL-сертификатов и доменов. Сервис сам следит за сроком действия и присылает уведомления заранее:
— по SSL за 14, 7, 3 и 1 день до окончания,
— по домену — за 30, 14, 7, 3 и 1 день.
Это помогает избежать тех самых «вдруг всё упало из-за просроченного сертификата», которые случаются неожиданно, но регулярно. Или ситуации вроде: «домен оказался не продлён, сайт теперь уводит на парковку с рекламой» — и ты узнаёшь об этом не первым, а после клиента.
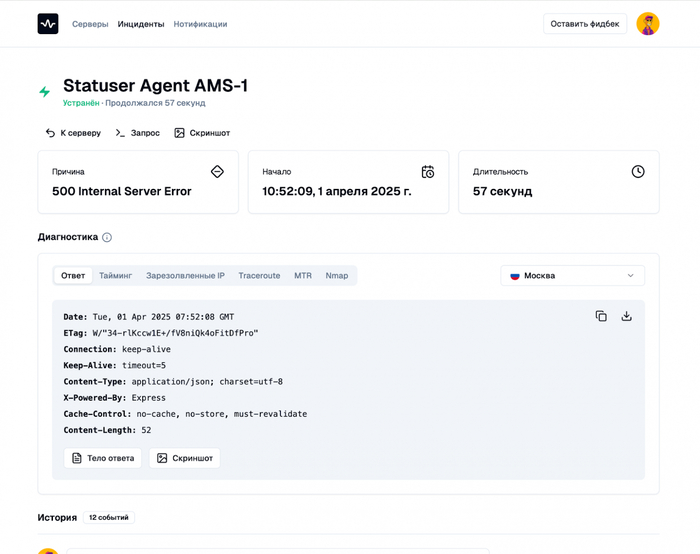
Каждую недоступность я стал оформлять в отдельный инцидент — с полной диагностикой из всех регионов, откуда шли проверки. В карточке инцидента в зависимости от типа проверки отображаются:
код ошибки;
тайминг запроса от curl;
зарезолвленные IP;
результаты выполнения mtr, traceroute и nmap;
SSL-сертификат, полученный через openssl;
скриншот страницы;
заголовки и тело ответа HTTP.
Внутри инцидента можно посмотреть таймлайн событий, оставить комментарий или постмортум — удобно, если сервисом пользуется команда и нужно зафиксировать, что случилось и почему.
Страница инцидента с диагностикой
❯ Технологии, стек и архитектура
Когда стало понятно, что сервис будет расти, я решил подойти к нему как к настоящему продукту — с нормальным бэкендом, фронтендом, базой, деплоем и инфраструктурой.
Я на запуске выбрал те технологии, которые, с одной стороны, были мне хорошо знакомы, а с другой — позволяли быстро двигаться и без лишних затрат запускать фичи. Хотелось сфокусироваться на продукте, а не тратить время на борьбу с конфигурацией или непривычным стеком. Поэтому получился баланс между удобством разработки, гибкостью и возможностью масштабирования в будущем.
Для бэкенда — NestJS. Удобный, хорошо масштабируемый фреймворк с архитектурой, которая мне близка: контроллеры, DTO, модули, строгая структура.
Для фронтенда — Next.js. Он позволяет быстро собирать современные интерфейсы, поддерживает SSR, тёмную/светлую тему, роутинг, статику — всё, что нужно для продакшена.
Компоненты собирал на ShadCN — они аккуратные, легко настраиваются и визуально мне очень нравятся. Без перегруза, со здравыми дефолтами, и при этом остаётся возможность быстро их подстроить под нужды интерфейса. Отличный вариант, когда хочется быстро собрать удобный UI без кастомизации на старте.
Я давно работаю в облаке и, естественно, для проекта тоже выбрал облачную инфраструктуру — это удобно, надёжно и позволяет сосредоточиться на продукте.
Приложение развёрнуто в Kubernetes: фронтенд и бэкенд оформлены как отдельные деплойменты, у каждого — свои поды, конфигурации и переменные окружения.
Снаружи доступен только один балансировщик — он обслуживает домен, автоматически выпускает и обновляет SSL-сертификаты и направляет трафик в Ingress кластера.
Все внутренние сервисы общаются по приватной сети, наружу не торчит ничего, кроме самого балансировщика.
Доступ ограничен через облачный Firewall — чтобы лишнего не светилось.
База данных — PostgreSQL в облаке. Проверки выполняются каждую минуту, и данных со временем становится всё больше: нужно хранить как текущие статусы, так и полную историю — для графиков, отчётов, анализа инцидентов. Облачная база берёт на себя бэкапы, мониторинг и отказоустойчивость, но я дополнительно настроил ежедневные резервные копии на S3 — потому что, как показывает опыт, бэкапов много не бывает.
S3 используется для хранения бэкапов и артефактов: результатов проверок в инцидентах, пользовательских аватарок, статических файлов.
Для отправки писем — обычный облачный SMTP-сервис. Просто, стабильно и без лишних забот.
Для проверок из разных регионов я написал отдельного агента, который развёртывается на VDS в нужной географии. Он выполняет проверки и отправляет результаты в основной сервис по HTTP. Агент упакован в Docker, благодаря чему легко масштабируется и позволяет быстро запускать инстансы в новых локациях — сейчас это Москва, Амстердам и Алматы.
На каждой VDS настроено несколько IP-адресов, чтобы снизить вероятность блокировок со стороны проверяемых ресурсов. Конфигурация агента унифицирована: все настройки хранятся в Git, что упрощает развёртывание, обновление и поддержку.
Процессы сборки и выката я сразу автоматизировал. Использую GitHub Actions: настроен пайплайн, который по тегу собирает контейнер, пушит его в реестр и деплоит в кластер или на VDS с агентом. Это удобно, предсказуемо и даёт гибкость — можно легко разносить staging и production, запускать preview-версии и тестировать отдельные фичи из веток.
❯ Что дальше?
Я продолжаю развивать Statuser — добавляю новую функциональность, улучшаю интерфейс и стараюсь сделать сервис максимально полезным для тех, кто работает с инфраструктурой, сайтами и продакшеном. Хочется не только писать код, но и рассказывать о проекте: делиться опытом, выходить на профильные площадки, писать статьи и просто быть в диалоге с сообществом.
В ближайшее время появятся несколько новых крупных функций:
Создание собственных статус-страниц — с возможностью объединять серверы в группы, настраивать индексацию в поисковиках, ограничивать доступ по паролю, включать вайт-лейблинг и многое другое. Первая версия уже готова примерно на 60%.
Публичное API — чтобы можно было автоматизировать управление мониторингом.
Появится Passkey для входа, а также двухфакторная авторизация через Telegram и email, просто потому что мне самому нравится этим пользоваться.
Сейчас Statuser — это pet-проект, и мне по-прежнему нравится заниматься им в свободное время. Такой формат даёт гибкость, позволяет экспериментировать и не перегореть. Но при этом у проекта уже появилась аудитория, и стало понятно, что он может быть полезен не только как личный инструмент, но и как продукт с коммерческой ценностью.
Поэтому в будущем Statuser станет условно-бесплатным сервисом с несколькими тарифами — по модели, близкой к тому, как это реализовано в UptimeRobot.
План такой:
бесплатный тариф останется навсегда — в нём будет всё необходимое для небольших личных и пет-проектов: HTTP-проверки, уведомления, статус инцидентов и другие возможности. В нём можно будет добавить до 10 серверов, этого хватит для большинства базовых сценариев;
платный тариф будет включать расширенные возможности: больше серверов в мониторинге, короткие интервалы мониторинга, диагностика инцидентов и многое другое;
в перспективе, возможно, появятся несколько уровней тарифов — для команд, фрилансеров, бизнеса.
Сейчас Statuser находится в режиме публичного тестирования — все функции доступны бесплатно. Можно подключить свои проекты, посмотреть, как сервис работает на практике, и при желании оставить обратную связь — это очень ценно и поможет мне сделать проект лучше и удобнее для пользователей.
❯ Заключение
Этот проект для меня — возможность оставаться в практике, развивать инженерное мышление и делать что-то полезное своими руками. Он начался как простая идея, и постепенно вырос в полноценный сервис, которым пользуются другие люди. Это вдохновляет продолжать работу.
Если вы прочитали до этого места — спасибо!
Буду рад любым вопросам, обратной связи и идеям. Возможно, вы сталкивались с похожими задачами в мониторинге или запускали свои pet-проекты — расскажите.
И если хочется, чтобы я подробнее раскрыл какую-то часть — стек, архитектуру, процесс разработки или, например, работу с обратной связью — просто напишите в комментариях, обязательно отвечу.
А сервер для мониторинга можно взять у нас в Timeweb Cloud :)
За последние годы многие компании и даже целые отрасли перевели свои процессы в цифру. Ритейл, как одна из наиболее перспективных сфер, обладает огромным потенциалом для внедрения современных технологий. Традиционные методы контроля и анализа постепенно уступают место решениям на базе искусственного интеллекта. Как именно ИИ меняет ритейл, какие задачи он уже решает и какие перспективы открывает?
Рынок ИИ в ритейле
Согласно данным Mordor Intelligence, в 2024 году мировой объем рынка технологий искусственного интеллекта в ритейле достиг порядка $9,65 млрд, к 2029 году он возрастет до $38,92 млрд.
В России интерес к ИИ также растёт. По данным СберИндекса, объёмы розничной торговли увеличились на 15% за год, несмотря на рост издержек по всей цепочке поставок. Это создаёт спрос на инструменты, которые помогают повысить управляемость и снизить потери. ИИ всё чаще становится таким помощником.
Архитектура ИИ-систем в магазинах
Искусственный интеллект в ритейле применяется для оптимизации различных процессов, от улучшения взаимодействия с клиентами до повышения эффективности бизнес-операций и управленческих решений.
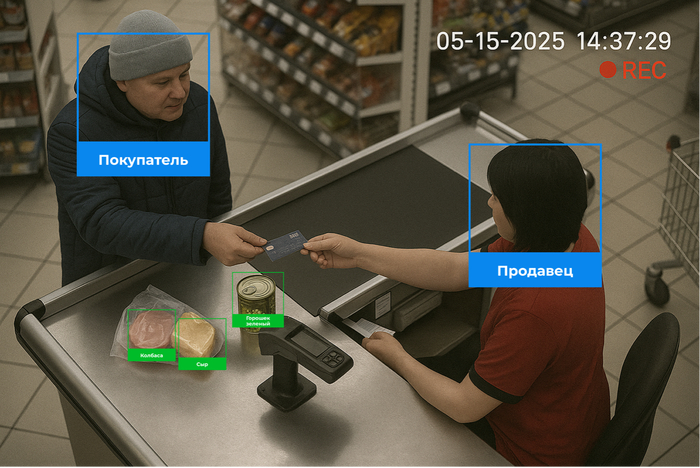
Системы мониторинга в ритейле строятся на базе данных, полученных с объекта. Одним из основных источников информации — это камеры видеонаблюдения. С их помощью технологии компьютерного зрения позволяют решать широкий круг задач: от контроля сотрудников и анализа очередей до мониторинга целевой аудитории и построения тепловых карт маршрутов покупателей.
Например, тепловые карты позволяют визуализировать поведение клиентов — где они чаще останавливаются, какие зоны обходят стороной, где проводят больше времени. Это помогает понять востребованность товарных полок и эффективность планировки торгового пространства.
Пример тепловой карты магазина: чёрные прямоугольники — стеллажи и прилавки, красно-жёлтое облако между ними — тепловая карта перемещений сотрудников. Зоны с наибольшим количеством перемещений подсвечены красным, менее активные — жёлтым и зелёным.
Контроль работы сотрудников
Искусственный интеллект помогает отслеживать эффективность и производительность персонала. Системы компьютерного зрения фиксируют, насколько качественно сотрудники выполняют свои обязанности, например, правильно ли они выкладывают товары и своевременно ли обслуживают клиентов. Это позволяет выявлять области для улучшения и повышать общий уровень клиентоориентированности.
ИИ способен различать сотрудников и клиентов с помощью обучения на униформу или использования специальных меток. После определения типа человека (сотрудник или покупатель) система отслеживает действия. При определении работника магазина ИИ-решение может классифицировать, например, такие действия, как: выкладка товара, помощь покупателям, установка ценников, нахождение в определённой зоне без активности. Это позволяет собирать объективную статистику по качеству и интенсивности работы персонала.
Для повышения точности в систему могут дополнительно встраиваться модули анализа движения для увеличения количества классов различаемых действий.
Один из кейсов применения такой технологии — распознавание разницы между активной работой сотрудника и использованием телефона в личных целях.
Интеграция с кассовыми и аудиосистемами
В дополнение к данным ИИ использует другие источники информации:
• данные с чеков и кассовых аппаратов позволяют определить, какие товары наиболее востребованы и из чего состоит структура покупательской корзины;
• аудиоданные применяются для оценки работы кассиров, в частности — соблюдение регламентов и скриптов продаж (например, предлагаются ли карты лояльности, упоминаются ли акции);
• RFID-метки, прикреплённые к дорогостоящим товарам, отслеживают их перемещение и предотвращают фрод (кражи);
Однако в этом направлении компании действуют осторожно: видео– и аудиомониторинг требует строгого соблюдения законодательства и этики.
Противодействие мошенничеству и контроль на кассах
Системы компьютерного зрения и машинного обучения анализируют видеопотоки с камер наблюдения, распознавая необычные действия посетителей и сотрудников.
Такие алгоритмы могут фиксировать:
• попытки спрятать товар, не оплатив его;
• подозрительное поведение, например, длительное нахождение в одной зоне без явной цели;
• резкие движения, которые могут свидетельствовать о краже;
• манипуляции с упаковками или антикражными метками.
При обнаружении аномальных действий система отправляет сигнал сотрудникам службы безопасности, позволяя им быстро реагировать. В некоторых случаях ИИ интегрируется с POS-терминалами, анализируя соответствие чека и фактически вынесенных товаров.
Такие технологии уже активно используются в крупных торговых сетях, помогая снижать потери и обеспечивать безопасность магазинов.
Особое внимание уделяется зонам самообслуживания, где часто происходят попытки краж. Камеры с широким углом обзора устанавливаются так, чтобы отслеживать действия рук покупателя — пробивает ли он товар, корректно ли перемещает его на весы и кладёт ли в пакет тот самый продукт, который пробил. Это позволяет выявлять распространённые нарушения, связанные с подменой товаров или обходом весового контроля.
Контроль качества товара с помощью компьютерного зрения
Помимо мониторинга персонала ИИ-агенты расширяют аналитические сценарии на оценку качества и соответствия товара. На приёмке и выкладке используются нейросетевые модели, способные:
• считать и проверять ценники — детектировать наличие, правильность привязки и актуальность ценников к позиции.
• классифицировать состояние продукции — отличать спелые и вялые фрукты, выявлять брак или повреждения упаковки.
• контролировать полноту выкладки — сравнивать фактическое размещение товара с эталонной выкладкой и своевременно сигнализировать о недостаче.
Пример распознавания недостающих ценников компьютерным зрением
Приватность и соответствие законодательству
В России с недавних пор действует жёсткий регламент на работу с биометрическими данными: сбор и хранение отпечатков пальцев, распознавание лиц или голос возможны только при прямом согласии сотрудников и обязательной регистрации в уполномоченных органах. В ответ на это большинство компаний в ритейле переходит на другие способы идентификации. Например, мы разработали систему небиометрической идентификации через невидимые маркеры. Подобные решения позволяют контролировать рабочие процессы и передвижения персонала, не нарушая законодательства и защищая права сотрудников.
Как ИИ-технологии работают в ритейле: процесс сбора и анализа данных
Процесс сбора и анализа данных включает три основных этапа:
1. Сбор данных. На этом этапе определяется пул источников: уже установленные или дополнительные камеры (общего вида и широкоугольные для зон самообслуживания, точечные над кассами), направленные микрофоны для контроля регламентов общения с посетителями, данные с POS-терминалов и учётных систем (1С и др.). Все источники данных, используемые для обучения модели ИИ, должны соответствовать ряду важных требований. Во-первых, обеспечивать одномоментность — то есть фиксировать события с точными и согласованными временными метками, что необходимо для корректного анализа последовательностей и временных взаимосвязей. Во-вторых, поддерживать постоянное обновление — данные должны поступать в реальном или близком к реальному времени, особенно если модель планируется применять в динамичных бизнес-процессах. И, наконец, источники должны отличаться высокой надёжностью: быть доступны круглосуточно, обеспечивать стабильную передачу и хранение данных без потерь и сбоев, что критично для качества ИИ-системы.
2. Анализ информации. На втором этапе платформа объединяет поступающие видеозаписи, звук и данные продаж, чтобы автоматически выделить в них ключевые события и аномалии. Система «видит» и классифицирует действия сотрудников и одновременно «слушает» зал, отмечая важные фразы даже в условиях повышенного уровня шума. Параллельно проверяется, совпадают ли данные с касс и складского учёта с тем, что показывают камеры: есть ли расхождения в продажах или остатках. Если выявляются подозрительные или нерабочие моменты, например отсутствие ценников — платформа автоматически формирует уведомление и структурированный отчёт. В результате магазин получает готовую картину работы по ключевым показателям без ручного просмотра часов видео и таблиц.
3. Обработка и отчетность. Агрегированные выводы по всем источникам данных сохраняются в системе и визуализируются в дашборде. Менеджмент получает оперативную сводку по ключевым метрикам и имеет возможность посмотреть данные как в реальном времени, так и за выбранный период.
Эффекты от внедрения и влияние на бизнес-процессы
Основной эффект от внедрения ИИ в ритейле — это повышение прозрачности процессов. Бизнес получает доступ к объективной информации о том, как работает персонал, какие зоны магазина наиболее загружены, и где возможны потери. Особенно это важно для оценки KPI, ротации персонала и принятия решений по премированию.
Системы также позволяют уточнять профиль покупателей, определять пол и возраст аудитории, анализировать поведенческие паттерны. Это помогает не только в планировке торгового пространства, но и в персонализации маркетинга.
По данным опроса, проведенного Nvidia, ритейлеры отмечают ряд значительных преимуществ от внедрения нейросетей в свою работу. Среди главных эффектов — снижение операционных расходов: у 28% компаний они сократились на 5–15%, а у 23% — более чем на 15%. Кроме того, 28% опрошенных зафиксировали рост выручки в пределах 5–15%, а 15% сообщили об увеличении доходов свыше 15%.
Что сложно автоматизировать, и куда движется рынок
Несмотря на успехи, остаются задачи, которые ИИ пока решает неидеально. Например, определение факта кражи требует комплексного анализа — только видео недостаточно. Необходимо сопоставление данных с кассы, движения покупателя и товарного учёта. Также ИИ не всегда может корректно интерпретировать сложное социальное поведение, особенно в нестандартных ситуациях. Система может фиксировать, что товар взят с полки, но не пробит. Однако покупатель мог просто временно отложить его или не дойти до кассы.
Тем не менее рынок развивается. В ближайшие годы можно ожидать появления решений, способных не только фиксировать события, но и предсказывать их: например, автоматическое прогнозирование пиков нагрузки, адаптация выкладки под спрос, автономное управление персоналом в реальном времени. Больше про ИИ пишу здесь
ИИ в ритейле — это уже не эксперимент, а рабочий инструмент. Его внедрение требует системного подхода, но при правильной реализации он даёт бизнесу ощутимые результаты. Современные решения позволяют ритейлерам контролировать процессы, сокращать потери и повышать эффективность без прямого давления на персонал. ИИ становится не надзором, а помощником — и это главное изменение, которое он приносит в индустрию.
Нам часто пишут пользователи, которые хотят мониторить качество каналов связи — не просто проверять “доступен ли хост”, а действительно оценивать стабильность сети и реагировать на деградации. Один из таких пользователей недавно подключил мониторинг для нескольких регионов, и его запрос дал нам полезный импульс для доработок.
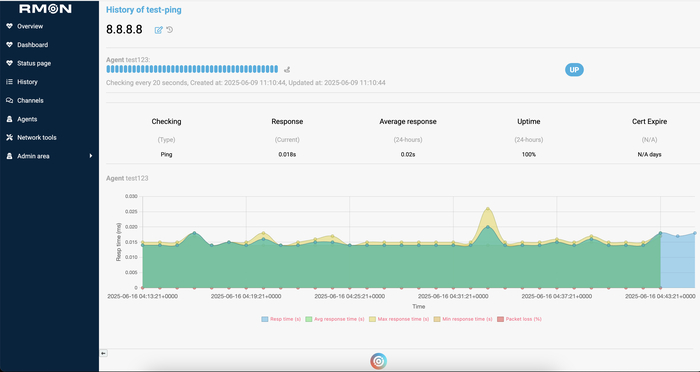
Раньше проверка ping в RMON отправляла один пакет — это было достаточно для грубой оценки, но плохо отражало реальное состояние канала. Теперь всё иначе:
Можно указать количество ICMP-пакетов в настройках проверки.
Система собирает и отображает:
min RTT
max RTT
avg
mean
Это особенно полезно, если канал нестабилен: одиночный ping может случайно показать “всё хорошо”, хотя на деле теряются пакеты или резко плавает задержка.
| Проверки из нескольких точек| ❌ (1 сервер) | ✅ Геораспределённые агенты |
| Telegram/Slack уведомления | Только через внешние скрипты | ✅ Встроено |
| API | ❌ Ограничен | ✅ Полноценный REST API |
SmokePing — отличный инструмент для исторического анализа задержек. Но он устарел в архитектуре, плохо масштабируется по регионам и требует обвесов для алертов.
RMON же изначально создавался с упором на:
простую установку;
удобный интерфейс;
встроенные нотификации и API;
и главное — распределённый мониторинг из разных географий.
Группировка алертов
Пользователи с несколькими агентами в разных регионах сталкивались с таким сценарием:
"Падает один хост — и мы получаем 5+ одинаковых алертов от каждого региона".
Теперь алерты по одному хосту автоматически агрегируются:
Вы получаете единое уведомление со списком всех регионов, где обнаружена проблема.
Упрощается логирование, снижается "шум" в системах алертинга (Telegram, Slack и т.п.)
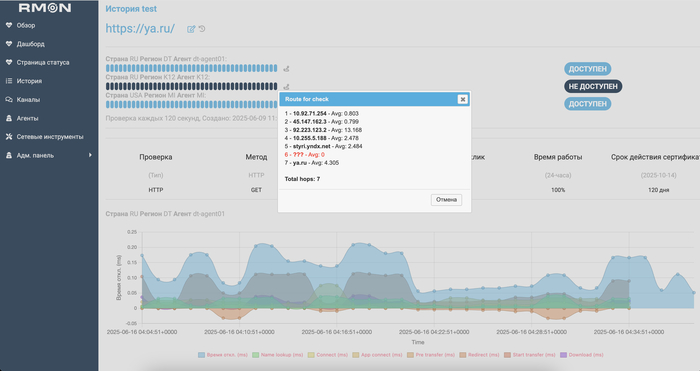
MTR на месте
Мы добавили возможность запускать MTR (traceroute с расширенной статистикой) из конкретного региона:
Прямо из веб-интерфейса или API
Можно быстро проверить маршрут от нужного агента до целевого хоста
Это особенно удобно при отладке проблем между регионами, в CDN, или при работе с провайдером.
Что дальше
Мы продолжаем развивать RMON как инструмент для распределённого мониторинга, ориентированный на:
телеметрию от агентов из разных регионов;
гибкую конфигурацию проверок;
удобную интеграцию с Telegram, Slack, Prometheus, Zabbix и другими системами.
Если вы хотите точно знать, где и когда у вас реально деградирует сеть — попробуйте RMON: https://rmon.io
Что за бред я прочитал под видом длинопоста месячной давности? И почему не надо хоститься в Git In Sky, судя по этому посту.
Для лиги лени: опять на Пикабу тащат старье с выродившегося в маркетинг хабра
стал DevOps-тимлидом Вместо трелей будильника мой телефон издает тревожный звон сообщений из системы мониторинга и экстренных звонков от клиента.
На телефон лида никогда, ни при каких обстоятельствах, не идут ни данные мониторинга, ни звонки от клиентов. Вообще никогда. И то, и другое, идет на первую линию, максимум на вторую.
вижу, что сломалась база данных. В такой ранний час из кластера предательски вывалилась одна нода.
База данных не "ломается" просто так. Кроме случаев, когда в нее кто-то кривыми руками полез, и что-то в ней удалил. И ни в каком случае это не связано с выпадением ноды из кластера. Есть два основных сценария: 1 База данных не очень важна, не очень нужна, и можно положиться на работу сервиса High availability (HA). Ну умерла одна физическая нода, да и ладно, через 2-5 минут система перезагрузится на другой 2 База данных важна, нужна, и очень нужна. В таком случае строится или RAC или Always on, в разных вариантах, по бедности, и когда база все же нужна, но не очень, можно обойтись Pacemaker&Corosync, или Patroni . Stolon может быть. Если вы смелый и старый - Galera.
При любых условиях выпадение ноды из кластера порождает только алерты, которые закрываются первой линией.
Как мне подсказывают, еще такое "отсутствие HA" бывает при внедрении "типа-импортозамещения" методом далее-далее, там HA отсутствует, в привычном понимании.
Инициализировав новую ноду и добавив ее в кластер
Чего чего там происходит? Достав со склада холодный резерв? И за 5 минут его подготовив к работе, прямо из дома в ЦОД? Что я только что прочитал? И при чем тут девопс лид?
Подъем по тревоге” ночью или в выходные происходит не часто (один-два раза в месяц).
Это значит, что система абсолютно не настроена, и построена из говна и свиста. Нет резервов, нет кластера, нет людей. Все задачи свалены на как-бы лида, но по фактическим задачам - инженера, ответственного за физическую инфраструктуру.
Как и у многих хостинговых компаний на рынке, у нас сложилась “многоярусная” система реагирования на проблемы с инфраструктурой.
Но при чем тут девопс, если речь про хостинг? Где тут в схеме "вышел из строя физический сервер" - CI или CD ?
Мы сознательно отказались от полностью автоматической системы и поставили между инфраструктурой и инженерами людей. Автоматика бы отзванивалась на любой чих в системе.
То есть автоматика не просто не настроена, ее вообще нет.
Сегодня инженер, ответственный за проект, не подошел к телефону
Как легко увидеть, налицо экономия на качестве и кадрах. Нормальная система слежения требует 2 (двух) людей на уровне, и только потом эскалацию на уровень выше. Опять же, совершенно не поняна иерархия - почему заявлены проблемы в железной части, но звонок ушел на девопс-инженера и девопс-лида?
Умываюсь и иду на дейлик в 10:00 по Москве, где мы отчитываемся о наших задачах.
Собери совещание
Обязательно присутствуют проджекты, которые приносят обратную связь от заказчиков - допустим, клиент приходил в пятницу и просил побыстрее что-то сделать. Мы оцениваем срочность и, если это необходимо, раздвигаем очередь задач, чтобы сфокусироваться на самом важном.
то есть спринтов нет, метод "бегаем туда - бегаем сюда".
Классика.
В общей сложности на опрос 20 с лишним человек уходит 18-20 минут.
20 человек в девопс команде на одного лида, но при этом один дежурный инженер? Цифры не сходятся. Никак.
Как выяснилось, тот поставил телефон на зарядку в соседней комнате и не услышал звонка. Обсудили ситуацию, договорились больше так не делать.
Исправлять ситуацию, конечно, никто не собирался. Но это уже другая история
Послеобеденное время — период, когда можно тет-а-тет обсудить задачи коллег. Сегодня, например, минут 40 проводил плановый performance-аудит баз данных одного из проектов.
Какое отношение perf аудит, который зависит еще и от запросов, не говоря про оптимизацию внутри базы, чем занимаются DBA, имеет к devops ? Да, observability находится на мониторинге, в том числе, у devops команды, но в реальном мире devops инженер обычно не лезет в план запросов.
Помимо встреч, мне с разных сторон прилетают задачки. Например, приходят коллеги из отдела маркетинга с заявками от клиентов. Они ждут совета, как и в какой пакет обернуть требуемую услугу, какую сделать презентацию. Будучи архитектором,
только что был девопс лидом, а стал архитектором. Волшебная трансформация. Маркетолог, писавший текст, забыл о чем писал?
Вечером, уже дома, могу посмотреть кино с женой или сажусь за свой пет-проект.
После подьема по алерту в 4 утра, два раза в месяц, к 20 человек падает в кровать. Какой уж тут пет-проект.
Впрочем, удивляться нечему. Если текст размещен на Хабре в 2025 - значит, это обычное маркетинговое творение. Накрыть пленкой, весной закопать в грядки перед посадкой картошки.