Коротко. Sora 2 PRO - это генерация видео с умной физикой и точным пониманием промта. Но большинство предложений на рынке это браузерные костыли: очереди, сбои, скрытые лимиты, обещания «безлимита», которые на деле не работают.
Решение - пользоваться Sora 2 PRO по официальному API. Это быстрее, стабильнее и без сюрпризов. Такой доступ есть в нашем Telegram: @Gptcyber_bot.
Почему не браузер
Браузерные версии часто падают. (большинство ботов это прокладка к браузеру)
Генерация идет медленно или вообще приходит отказ.
«Безлимит» вранье. Везде есть лимиты, просто их прячут.
Нельзя строить на этом процессы и дедлайны.
Водяные знаки если и отсутствуют, то удаляются программным путем, что приводит к искажению изображения.
Почему по API в @Gptcyber_bot
Стабильно - прямое подключение к Sora 2 PRO по API, без костылей.
Быстро - без очередей и зависаний.
Понятно - 720p по умолчанию, без водяного знака.
Гибко - два режима под разные задачи и бюджеты.
Режимы:
⚡ Fast Mode - дешевле, для быстрых тестов промта.
🎬 Ultra Mode - дороже, для финальной генерации. Медленнее, примерно в 3 раза дороже, зато качество топовое.
Кому это нужно
Дизайнерам и продакшенам - быстрые прототипы и финальные ролики.
Маркетологам и бизнесу - короткие промо, сторис, тизеры, заставки.
Аналог чата GPT в России: Chat GPT где искать, как выбрать и какие тарифы доступны
Рынок генеративного ИИ в России за последние два года кардинально изменился: появилось много сервисов, ориентированных на русскоязычную аудиторию, усилилась конкуренция, а бизнесу и авторам контента стало проще получать качественные ответы на родном языке и без сложных обходных путей. В этом обзоре я разберу, какие сегодня есть русские и российские аналоги, чем они отличаются, какой есть аналог чата GPT под разные задачи, на что смотреть при выборе, а также расскажу о тарифах платформ, которые дают доступ к актуальным моделям.
Под «аналогом» принято понимать любую модель диалогового искусственного интеллекта (LLM), которая:
понимает и генерирует связный текст на русском;
поддерживает длинные диалоги с учётом контекста;
умеет писать код, резюмировать документы, составлять ТЗ, готовить посты и коммерческие тексты;
иногда — создавать изображения, работать с файлами и подключаться к плагинам.
Именно поэтому встречается формулировка «нейросеть как чат GPT аналоги»: речь о семействе моделей с сопоставимой функциональностью, но разной архитектурой, обучением, ценами и юридическими ограничениями.
Кратко: какие бывают российские аналоги и чем они отличаются
Корпоративные: нацелены на безопасность и интеграции, удобны компаниям с требованиями к хранению данных.
Публиковавшиеся как исследовательские: модели с открытыми весами или лицензиями, которые можно дообучить под домен.
Облачные универсальные: удобные веб-интерфейсы для повседневной работы, где важны простота и качество русскоязычных ответов.
В 2025 году уместно говорить и об «аналог чат GPT 2025» — то есть о поколениях моделей с улучшенным контекстом, инструментами и мультимодальностью.
Критерии выбора: как понять, какой есть аналог чата GPT под ваши задачи
Качество русскоязычных ответов Смотрите на связность, фактическую точность, умение работать с терминами и длинным контекстом.
Безопасность и приватность Для B2B критично: где физически расположены сервера, какие есть договоры и SLA.
Стоимость и лимиты Объём токенов, скорость, ограничения по проектам. Если бюджет ограничен — ищите бесплатный аналог чат GPT 4 для тестов.
Интеграции CRM, CMS, Git, офисные пакеты, мессенджеры, мобильные приложения — особенно важны «аналоги чат GPT на айфон».
Юридическая чистота Лицензии, политика контента, соответствие локальному праву.
Сайт чат GPT в России - Российские аналоги чат-моделей: что выбрать в 2025
Ниже — обзор сервисов, которые чаще всего выбирают для работы на русском и в российских реалиях. Это обе категории: и российские аналоги чат GPT, и международные инструменты, которые имеют стабильные способы использования в РФ.
GigaChat (Сбер)
Сильные стороны: русский язык, суммаризация документов, генерация кода, корпоративные интеграции.
Кому подойдёт: отделы поддержки, маркетинг, аналитики данных, разработчики.
Формат: веб-интерфейс, API, корпоративные тарифы.
YandexGPT / YandexART
Это логичный аналог чат GPT от яндекса для повседневной работы с текстами и идеями.
Сильные стороны: экосистема Яндекса, мультимодальность (в некоторых продуктах), интеграции.
Кому подойдёт: малый и средний бизнес, контент-команды, авторы.
RuGPT / YaLM-семейство и другие исследовательские модели
Подходят тем, кто хочет локально или в частном облаке держать российский аналог чата GPT в россии с кастомным обучением.
Сильные стороны: гибкость, контроль над данными.
Требования: инфраструктура и команда MLOps/DS.
Универсальные веб-платформы с доступом к передовым моделям
Дают удобный интерфейс, загрузку и обработку файлов, изображения, быстрый обмен работой в команде.
Это хороший ответ на вопрос: какой есть аналог чата GPT, если вам важен не только движок, но и сервис вокруг него — от биллинга до командных рабочих пространств.
Для многих задач это и есть лучшие аналоги чата GPT: вы получаете современные модели плюс русскоязычный интерфейс, поддержку и понятные цены.
Аналог чата GPT в России — один из вариантов, где всё это собрано в одном месте: удобный доступ к мощным моделям, режимы для файлов и изображений, тарифы без привязки к зарубежным картам.
Чем «аналог чат GPT 4» отличается от «аналог чат GPT 5»
Контекст: 5-е поколение обычно держит более длинные цепочки сообщений и лучше резюмирует документы.
Инструменты: у «пятёрок» чаще встроены расширенные режимы (файлы, изображения, веб-поиск).
Код и логика: «пятёрки» заметно устойчивее в рассуждениях и работе с кодом, чем аналог чат GPT 4.
Стоимость: логично ожидать, что российские аналоги чат GPT 5 и международные «пятёрки» оцениваются дороже — за счёт качества.
Если нужен максимально продвинутый аналог чат GPT 5 под сложные задачи контента и кода — проверяйте, доступна ли такая модель в выбранном вами сервисе и входят ли «пятёрки» в тариф.
Практические сценарии: где аналоги прямо сейчас экономят часы
SEO-копирайтинг: подготовка структуры, брифов, метатегов, перелинковки; генерация «рыбы», переписывание с сохранением смысла и ТЗ.
Для этих задач подойдут чат GPT аналоги онлайн — веб-интерфейс без сложной установки.
Как называется аналог чата GPT, который подойдёт вам: простая матрица выбора
Нужны файлы, длинные контексты, картинки? — Ищите платформы с режимами «Документы/Изображения» и «пятёрками».
Нужен только текст и дешёвый вход? — Берите бесплатный аналог чат GPT 4 для тестов, а затем переходите на доступный платный план.
Важны российские юрлица и документы? — Выбирайте российские аналоги чат GPT, корпоративные контракты и локальный хостинг.
Хотите мобильность? — Проверьте аналоги чат GPT на айфон и наличие PWA/приложений.
Нужен API и автоматизация? — Смотрите на квоты, скорость, webhooks, SDK.
Тарифы: как ориентироваться и что включено
На рынке сложилась понятная логика: короткие тестовые планы для ознакомления и расширенные — для регулярной работы. Ниже — пример структуры тарифной сетки, где акцент сделан на доступ к современным моделям, удобные лимиты и генерацию изображений.
День
Пробный доступ на 24 часа.
Все функции без ограничений по режимам.
Подходит, чтобы быстро оценить качество русскоязычных ответов и инструментов.
30 дней полного доступа: текст, файлы, изображения, модели нового поколения.
Хорош для постоянной SEO-работы, PR, код-задач и поддержки.
Год
365 дней и максимальная выгода при долгом использовании.
Выбирают команды и индивидуальные специалисты, которым критична предсказуемая стоимость.
В таких планах обычно включено:
Доступ к лучшей модели «пятого» поколения (то, что пользователи называют «ии чат GPT аналоги» на новом уровне).
Генерация изображений на современном двигателе.
Загрузка и обработка файлов: PDF, DOCX, презентации, таблицы.
Приоритетная очередь и повышенные лимиты скорости на младших тарифах.
Чтобы начать, достаточно выбрать удобный период. Если сомневаетесь, стартуйте с недели и расширяйтесь по мере роста задач.
Почему важно выбирать площадку, а не просто «модель»
Даже лучшая модель бессильна, если ей неудобно пользоваться. Именно поэтому комплексные сервисы становятся де-факто ответом на вопрос «какой есть аналог чата GPT для бизнеса»:
быстрый и стабильный веб-интерфейс;
понятный биллинг и поддержка платежей;
режимы для документов и изображений;
командная работа и шаринг;
регулярные обновления моделей без вашей головной боли.
Один из таких вариантов — российские аналоги чат GPT в формате единого кабинета с выбором режимов и тарифов.
Точность и ответственность: как работать безопасно
Проверяйте факты при публикации материалов. Большие модели уверены в ответах, даже когда ошибаются.
Не отправляйте конфиденциальное без шифрования и договоров (NDA, DPA).
Логируйте важные решения: храните промпты и версии текстов.
Учите модель на своих данных через инструкции и примеры — это повышает релевантность.
Следите за политиками контента и законом о персональных данных.
Кейсы: как «пятёрки» ускоряют SEO и продажи
Карточки категорий и товаров: из ТЗ и CSV быстро собираются уникальные описания, подзаголовки, FAQ и метаданные.
Семантика и структура: подсказки по кластерам, интенты, заголовки, разметка.
Outreach и PR: автоматические письма редакторам и блогерам, пресс-релизы, медиапланы.
Скрипты для операторов: корректный тон-оф-войс, сценарии, карточки возражений.
Если вам важна непрерывная работа и мультимодальность, обратите внимание на чат GPT аналоги онлайн, где есть «Документы/Изображения» и стабильные квоты.
Работают ли аналоги за рубежом и в РФ одинаково
Короткий ответ: не всегда. Поэтому запросы вроде «чат GPT аналоги работающие в россии» и «российские аналоги чат GPT 5» — не пустые слова. При выборе проверяйте:
способы оплаты;
скорость отклика с российских сетей;
наличие локальных зеркал и CDN;
юридические документы для ФЛП/ИП/ООО.
Мобильный сценарий: аналоги чат GPT на айфон
Если вы часто работаете «с дороги», проверьте:
есть ли iOS-приложение или PWA;
поддерживаются ли истории чатов и быстрые команды;
можно ли делиться ссылками на чат с коллегами;
работает ли распознавание и диктовка голоса на русском.
Короткий чек-лист перед покупкой тарифа
Нужны ли «пятёрки» или хватит «четвёрок»? (иногда аналог чат GPT 4 уже решает задачи)
Сколько документов в месяц вы реально обрабатываете?
Важны ли изображения и диаграммы?
Нужна ли командная работа?
Какой бюджет удобнее: день/неделя/месяц/год?
Если нужны «тест-драйв» и поддержка, рассмотрите планы на неделю — за семь дней видно, насколько модель «цепляет» ваши кейсы.
Сайт чат GPT в России: Вопросы, которые мне задают чаще всего (FAQ)
1. Что выбрать, если нужен простой аналог чата GPT для текста на русском? Для повседневных задач подойдёт любой удобный веб-сервис с «четвёркой» или «пятёркой», режимом «Документы» и понятными лимитами. Начните с недельного тарифа и оцените результат.
2. Есть ли бесплатный вариант, чтобы попробовать? Да, многие площадки предлагают демо или ограниченные планы — это бесплатный аналог чат GPT 4 для первичного теста. Но для стабильной работы лучше взять платный тариф.
3. А как называется аналог чата GPT от Яндекса, и чем он хорош? Это YandexGPT (и смежные продукты). Хорошая поддержка русского, интеграции в экосистеме, удобен авторам и малому бизнесу.
4. Нужны ли именно «пятёрки»? Если у вас сложные ТЗ, длинные документы, код и мультимодальные сценарии — да, аналог чат GPT 5 ощутимо лучше. Если короткие тексты и заметки — хватит «четвёрки».
5. Какие русские аналоги чата GPT выбрать для компании с требованиями по данным? Смотрите на корпоративные версии (GigaChat и др.) или развёртывание исследовательских моделей в вашем облаке — это по сути российский аналог чата GPT в россии с контролем над хранением.
Выберите сервис с удобными тарифами: день/неделя для тестов, месяц/год — для постоянной работы.
Протестируйте на реальных задачах: один-два проекта в спринте.
Зафиксируйте регламенты использования и критерии качества.
Если вы ищете русские аналоги чата GPT с современными моделями, режимами для документов и изображений и понятной тарифной сеткой, посмотрите на лучшие аналоги чата GPT с доступом из России — так вы получите стабильную среду без лишней возни с инфраструктурой.
Аналог чата GPT в России: где искать, как выбрать и какие тарифы доступны
Российский рынок генеративного ИИ активно растёт: появляются новые сервисы, а привычные инструменты получают локальные версии, понятный биллинг и поддержку русского языка. Ниже — концентрированный гид: где искать надежный аналог чата GPT, как не ошибиться с выбором и какие тарифы встречаются чаще всего. В конце — отзывы пользователей с разбором сильных и слабых сторон.
Где искать рабочие решения
Платформы-агрегаторы. Это сервисы с единым интерфейсом и доступом к нескольким моделям сразу — удобно, если вы хотите сравнить качество на реальных задачах и не переключаться между сайтами. Обратите внимание на наличие режимов “Файлы/Изображения”, командных папок и истории чатов. Один из примеров — аналог чата GPT в России с поддержкой актуальных моделей и русскоязычной поддержкой.
Корпоративные экосистемы. Их выбирают компании, которым важны договоры, SLA и хранение данных в юрисдикции РФ. Плюсы — интеграции, централизованный доступ, аудит. Минусы — более спокойный темп апдейтов и порог входа по цене.
Исследовательские/самостоятельно развернутые решения. Подходят тем, кто хочет полный контроль: можно дообучить модель на собственных документах и держать её в частном облаке. Но понадобится команда MLOps и инфраструктура.
Как выбрать подходящий сервис
Качество русскоязычных ответов. Проверьте, как модель держит длинный контекст, справляется с терминами и цитатами, не «галлюцинирует» факты. Мини-тест: дайте ей кусок вашего ТЗ и попросите составить план публикаций.
Инструменты. Для маркетинга и аналитики критичны загрузка PDF/DOCX/XLSX, извлечение таблиц, создание изображений и встраивание ссылок. Разработчикам — подсветка кода, объяснение ошибок и генерация тестов.
Приватность и юрчасть. Узнайте, где хранится история чатов, есть ли договор обработки данных, какие логи пишутся и как их можно удалять.
Скорость и лимиты. Важны не только «токены в месяц», но и пик-лимиты, приоритет в очереди, стабильность вечером. Если у вас команда, проверьте, делятся ли квоты между участниками.
Экономика. Сопоставьте фактическую стоимость часа работы модели с вашим процессом. Иногда «чуть дороже» тариф окупается вдвое за счёт лучшего качества и меньшего количества переработок.
Какие тарифы встречаются чаще всего
День. Тест-драйв на 24 часа: все функции без сложной подписки. Подходит для оценки качества и первых спринтов — например, быстро собрать структуру блога и пару лендингов.
Неделя. Оптимально для мини-проекта: подготовить медиаплан, контент на месяц, провести аудит сайта, написать цепочки писем. Цена обычно заметно ниже суммы семи «дней».
Месяц. Базовый выбор фрилансеров и команд. Часто включает доступ к «пятому» поколению моделей, режимам «Файлы/Изображения», приоритетной очереди и расширенным лимитам.
Год. Самая низкая ставка в перерасчёте на месяц и предсказуемый бюджет. Берут те, кто ежедневно работает с ИИ: редакции, агентства, отделы поддержки и разработки.
Совет: начните с недели, замерьте экономию времени на реальных задачах, затем переходите на месяц или год — так вы не переплатите и быстрее выйдете на стабильный результат.
На что способна «четвёрка» и когда нужна «пятёрка»
«Четвёрки» уверенно генерируют тексты, описания, метатеги, выдерживают средние по длине диалоги и помогают с кодом на уровне сниппетов. «Пятёрки» лучше держат длинный контекст, сильнее в рассуждениях, структурировании больших документов, точнее в инструкциях и правках. Если у вас сложные ТЗ, юридические обзоры, аналитические отчёты, полноценные сценарии — стоит взять тариф с «пятёркой».
Отзывы пользователей: что хвалят и что критикуют
Маркетологи. Плюсы: экономия 40–60% времени на подготовке контент-планов, брифов и постов; аккуратная подгонка под тональность бренда; быстрые A/B-варианты заголовков. Минусы: без хороших входных данных модель дает «общие» тексты; требует финальной вычитки фактов.
SEO-копирайтеры. Плюсы: ускорение сбора структуры, подсказки по интентам, генерация «рыбы», помощь с метаданными и FAQ. При «пятёрках» — лучшее удержание контекста на длинных статьях. Минусы: иногда переусердствует с универсальностями, нужно задавать чёткое ТЗ и примеры.
Разработчики. Плюсы: объяснение ошибок, преобразование кода, генерация тестов, подсказки по библиотекам. Хорошо помогает на ревью и в миграциях. Минусы: требует проверять безопасность и производительность решений; при узких фреймворках может давать устаревшие рекомендации.
Поддержка и продажи. Плюсы: шаблоны ответов, классификация обращений, единый тон-оф-войс, быстрые скрипты. Минусы: нужно тщательно настроить инструкции и исключить утечку персональных данных.
Руководители и аналитики. Плюсы: резюме длинных документов, «one-pager» отчёты для встреч, вытягивание чисел из презентаций. Минусы: сложные финансовые выводы и прогнозы лучше перепроверять вручную.
Обобщая отзывы: максимальная ценность появляется, когда команда фиксирует стандарты (шаблоны промптов, чек-лист фактов, глоссарий бренда) и хранит «лучшие практики» внутри сервиса.
Короткий чек-лист перед оплатой
Нужны ли режимы «Файлы» и «Изображения» или достаточно текста?
Какой объём материалов вы генерируете ежемесячно — хватит ли лимитов?
Требуются ли командные доступы и разграничение прав?
Где физически хранятся данные и чаты?
Есть ли iOS/Android или PWA, чтобы работать «в дороге»?
Итоги
Надёжный аналог чата GPT в России — это не только «движок», но и экосистема вокруг него: инструменты, приватность, поддержка и понятное ценообразование. Начните с недельного тарифа, проверьте качество на ваших кейсах, зафиксируйте регламенты и масштабируйтесь до месячного или годового плана. Так ИИ быстро окупится, а команда получит предсказуемый, стабильный результат.
Нейросеть для изображений: как получить фото и картинки с помощью нейросети онлайн
Искусственный интеллект перестал быть уделом гиков: сегодня нейросеть для изображений помогает маркетологам, дизайнерам, блогерам и предпринимателям генерировать иллюстрации, повышать качество кадров и автоматизировать рутинную ретушь. В этом материале — практическое руководство без воды: как получить фото с помощью нейросети, на что влияют промпты, как обработать фото нейросетью, где улучшить резкость и цвет, когда логичнее сделать видео из фото (нейросеть), и какие сервисы стоит попробовать прямо сейчас.
Что такое нейросеть для изображений и как она работает
Нейросеть для изображений — это модель машинного обучения, обученная на миллионах картинок и подписей. Она «понимает» визуальные паттерны и текстовые описания, чтобы:
генерировать нейросеть фото по описанию (text-to-image);
улучшать исходники: нейросеть качество фото плюс шумоподавление, повышение резкости, суперразрешение;
выполнять точечные правки: нейросеть убрать фото лишний объект, заменить фон, сделать реставрацию;
выступать как редактор фото нейросеть: цветокор, свето-тень, ретушь кожи;
выполнять стилизацию (фото → «акварель», «киберпанк», «аниме»);
собирать видео из фото (нейросеть) или анимировать статичные изображения.
Технически внутри используются диффузионные модели, трансформеры и автоэнкодеры. Но пользователю важнее другое: насколько быстро и качественно нейросеть сделать фото, насколько понятным будет интерфейс, и есть ли русский язык для промптов и подсказок (русский нейросеть фото — существенный плюс для новичков).
Где применяются нейросети для фото в бизнесе и контенте
E-commerce и карточки товара
Восстановить плохие кадры: нейросеть для улучшения фото спасает ночные и «шумные» снимки.
Удалить фон или ценник: нейросеть убрать фото артефакты, заменить задник на нейтральный.
Сгенерировать вариации ракурсов: генератор фото нейросеть помогает быстро нащупать стиль.
Соцсети и блогинг
Обложки, превью, мемы — фото с помощью нейросети онлайн создаются за минуты.
Аватары, стилизация под комикс или масляную живопись.
Анимация статических кадров: видео из фото нейросеть — короткие петли, параллакс.
Маркетинг и брендинг
Мудборды и концепты кампаний.
Быстрые визуальные гипотезы под A/B-тест.
Автоматическая адаптация к форматам площадок.
Советы по промптам и практические примеры генерации вы найдете на нейросеть фото — лаконичные подсказки и русскоязычные промпты для старта.
Как сформулировать промпт: чтобы нейросеть «поняла» вашу задумку
Хороший промпт — это 70% результата. Рабочая формула:
Сюжет/объект: кто/что в кадре.
Стиль: реализм, кино, фэшн, «аниме», «isometric», «product shot».
Свет: soft light, rim light, golden hour.
Оптика: focal length, aperture (например, 85 mm, f/1.8).
Фон/сцена: студия, city night, минимализм.
Кадрирование и ракурс: close-up, top-down, ultra-wide.
Качество: high detail, 4k, нейросеть качество фото.
Пример:
«Product shot of matte black wireless earbuds on acrylic stand, studio lighting, soft shadows, 85mm, f/2.0, minimal background, high detail, 4k» — такой запрос почти всегда даст чистый продающий кадр.
Чтобы получить нейросеть фото по описанию на русском, добавляйте краткие английские термины для света/оптики — многие модели обучены именно на них. Это повысит стабильность.
Как улучшить имеющийся кадр: апскейл, шумоподавление, цвет
Если у вас уже есть снимок, нейросеть для обработки фото работает в двух направлениях:
Чистка и стабильность: шумоподавление, восстановление текстур, исправление экспозиции.
Апскейл: увеличение в 2–4 раза без мыла. Это и есть улучшить фото нейросеть онлайн, когда вы получаете четкий принт или обложку для маркетплейса.
Частые задачи и решения:
Размытая надпись? Включите суперразрешение (SR) и «enhance text».
Желтая кожа в помещении? Автокор цветовой температуры + «skin tone balance».
Мало света? «Shadow recovery» + «contrast protect».
Обработка фона, замена объектов и «магическая резинка»
Современные модели понимают маски и контекст. Вы можете:
Заменить фон: нейросеть замена фото задника на фирменный градиент или интерьер.
Инпейнтинг: дорисовать обрезанные части логотипа, починить текстуры одежды.
Аутпейнтинг: расширить кадр под обложку YouTube или вертикальные Reels.
Это быстрее классической ретуши в Photoshop, особенно для серийной обработки карточек товара. Для локализации отлично работает редактор фото нейросеть: меняем надписи на языке региона, выдерживая перспективу и свет.
Генерация с референсом: «нейросеть изображение по фото»
Если нужна новая сцена, но с сохранением формы объекта (кроссовок, упаковки), используйте режимы image-to-image и control-net-подобные инструменты. Так вы получите нейросеть изображение по фото — вариации с иным фоном, стилем или освещением при сохранении геометрии.
Примеры кейсов:
Переиспользовать один снятый образец товара в десятке сеттингов.
Упростить фотосессию — дорого снимаем 1 раз, остальное домоделиваем.
Контент под сезонность: «зима/лето» для баннеров.
Когда уместно «фото в нейросети онлайн бесплатно в хорошем»
Бесплатные лимиты — отличный способ протестировать гипотезы и подобрать стиль. Фраза «фото в нейросети онлайн бесплатно в хорошем» встречается в поиске неслучайно: начинающим важно понять планку качества до подписки. Оптимальная стратегия:
Сделайте 3–5 тестов с разными промптами и параметрами.
Сравните резкость, цвет и стабильность лиц/текста.
Посмотрите, насколько быстро отрабатывает очередь.
Если задачи регулярные, берите подписку — выкупится за счет скорости.
Правила этики и права на контент
Проверяйте политику использования: коммерческая лицензия, ограничения на логотипы и бренды.
Не выдавайте реалистичные лица реальных людей за настоящие снимки без маркировки.
Для чувствительных тем используйте генерацию без «face-match».
Храните промпты и сетапы обработки — это часть вашего know-how.
Русскоязычные подсказки и быстрый старт
Если вы только начинаете и нужен русский нейросеть фото интерфейс и примеры промптов, загляните на фото с помощью нейросети — короткие формулы запросов, чек-листы апскейла и ретуши.
Чек-лист: как быстро получить продающее изображение
Сформулируйте задачу: генерация или обработать фото нейросетью.
Соберите референсы (3–5 штук) и выпишите стиль / свет / композицию.
Напишите промпт по формуле, добавьте требования к качеству (нейросеть качество фото).
Сгенерируйте 8–12 вариантов, отберите 2–3 лучших.
Сделайте апскейл (2–4×), уточните детали через инпейнтинг.
Проверьте читаемость мелкого текста, логотипов и отражений.
Экспортируйте под нужные форматы площадок.
Типичные ошибки и как их избежать
Слишком общий промпт → размытая концепция. Решение: уточняйте стиль, свет, оптику.
Перегиб со стилями → «грязная» картинка. Решение: 1–2 стиля за раз.
Апскейл без ретуши → артефакты заметнее. Решение: легкая чистка до увеличения.
Игнор масок при правках → неестественные края. Решение: аккуратные маски, перо 5–15 px.
Нет контрольного референса → дрейф изображения. Решение: загрузите эталон и закрепите позу/композицию.
Инструменты, которые закроют 90% задач
Text-to-image: генерация нейросеть фото по описанию для обложек, баннеров, превью.
Image-to-image: нейросеть изображение по фото — новые сцены в одном стиле.
UpScale / Enhance: улучшить фото нейросеть онлайн до печатного качества.
Inpainting / Outpainting: нейросеть убрать фото объект, воссоздать края.
Применяете «restore faces», винтажный цвет оставляете через LUT.
Нейросеть для улучшения фото повышает читаемость деталей не разрушая зерно.
3) Быстрые обложки для YouTube/Рилс
Ставите крупный план (close-up), контровой свет, bold-текст.
Генерируете 10 вариантов фона и 3 — композиции.
Проверяете читаемость на мобильном (1280×720 → 320 px).
Безопасная и чистая ретушь
Редактор фото нейросеть позволяет ретушировать бережно:
Удаляйте только отвлекающие детали, оставляйте фактуру кожи.
Для одежды — восстанавливайте паттерны «texture aware».
Локально повышайте резкость, не трогая фон (unsharp mask по маске объекта).
Автоматизация потока
Если задач много, соберите конвейер:
Папка «входящие» → авто-кроп и авто-экспозиция.
Набор пресетов под площадки (WB, контраст, SR).
Скрипт наименование: SKU-ID-ракурс-размер.
Полуавтоматические маски для фона и тени.
Подбор пресетов и промптов облегчит генератор фото нейросеть — короткие шаблоны, которые можно адаптировать под бренд.
Работа с людьми и брендами
Для портретов уважайте этику: предупреждайте о нейросетевой обработке.
Не используйте чужие торговые марки в вводных данных без прав.
Для бренд-гайдов фиксируйте LUT, насыщенность, зерно, чтобы серии выглядели одинаково.
Нюансы локализации: русский нейросеть фото
Русскоязычный интерфейс и поддержка кириллицы в текстах на баннерах — важны для запуска «с нуля». Сервисы с локализацией ускоряют вход и снижают число ошибок в промптах. Если промпт смешанный (RU+EN), держите структуру: русское описание сюжета + английские технические теги.
Мини-словарь по задачам
Нейросеть сделать фото — полностью сгенерировать кадр по тексту.
Нейросеть для улучшения фото — модуль повышения резкости/разрешения.
Нейросеть замена фото — сменить фон или объект локально.
Нейросеть изображение по фото — новая сцена с сохранением формы.
Редактор фото нейросеть — набор инструментов ретуши внутри AI-сервиса.
Сколько времени закладывать на одну картинку
В среднем:
Промпт + генерация: 2–5 минут.
Отбор: 1–2 минуты.
Инпейнтинг/ретушь: 3–7 минут.
Апскейл и экспорт: 1–2 минуты. Итого: 7–16 минут на изображение при отлаженном процессе.
Массовая генерация и вариативность
Чтобы не застрять в бесконечных итерациях:
Ставьте лимит: 12 вариантов на один сценарий.
Меняйте 1–2 параметра за итерацию, не всё сразу.
Храните удачные сиды/настройки — это реплицируемость.
Резервирование и хранение
Экспортируйте финалы в PNG и WebP (для веб).
Исходники и маски держите в проектной папке.
Промпты — в текстовом файле рядом с изображением.
Бэкап в облако раз в сутки.
Где черпать идеи и шаблоны
Ищите референсы по стилю и свету, а затем воспроизводите через промпты. Здесь пригодится подборка примеров и лаконичных формул на фото с помощью нейросети онлайн — удобно, когда нужна быстрая «шпаргалка».
FAQ: ответы на частые вопросы
1. Можно ли коммерчески использовать изображения, созданные нейросетью? Да, если политика сервиса это разрешает. Проверьте лицензию: некоторые площадки разрешают коммерцию только на платных планах.
2. Как добиться стабильных лиц и логотипов? Используйте image-to-image с референсом, режимы face restore и «text enhancement», ограничивайте рандом (seed).
3. Почему текст на баннере получается «ломаным»? Модели хуже генерируют кириллицу. Решение: сгенерируйте фон и добавьте текст в редакторе, либо используйте маски и инпейнтинг с готовым текстовым слоем.
4. Как сделать реалистичную замену фона? Совместите температуру света и направление тени, подложите «contact shadow» и слегка размытый отраженный свет у ног/основания предмета.
5. Что выбрать: генерацию с нуля или обработку исходника? Если продукт уникальный и важны детали — лучше нейросеть для обработки фото исходника. Для концептов и рекламных визуализаций быстрее нейросеть фото по описанию.
Итоги
Нейросети закрывают путь от идеи до готовой графики за минуты: генерация, ретушь, апскейл, анимация.
Для бизнеса это скорость тестов и единый визуальный язык.
Освойте промпты, маски и апскейл — и 90% задач решаются без студии.
Для старта используйте готовые формулы и подсказки на нейросеть для улучшения фото — лаконично и по-русски, чтобы сразу получить результат.
Отзывы пользователей: Нейросеть для изображений — как получить фото и картинки с помощью нейросети онлайн
Нейросети для изображений перестали быть экзотикой — сегодня это рабочий инструмент для маркетологов, дизайнеров, блогеров и предпринимателей. С помощью простого текстового запроса можно получить готовые обложки, иллюстрации, превью для видео и даже восстановить старые кадры. Ниже — живые отзывы пользователей с разным опытом, их лайфхаки и честные выводы о том, как быстро получить качественные фото и картинки с помощью нейросети онлайн.
Кому и зачем это нужно
Малому бизнесу — чтобы быстро выпустить промо-баннеры и карточки товара без студийной съемки.
Создателям контента — для обложек роликов, мемов, аватарок и сторис.
Маркетологам — для теста гипотез и A/B-экспериментов: за вечер можно сделать десятки вариантов.
Опыт пользователей: что говорят после первых недель
«С нуля до обложки за 15 минут» — Дарья, контент-менеджер
«Раньше ждала дизайнера по два дня. Теперь пишу промпт “product shot, soft light, minimal background”, получаю 10 вариантов, выбираю два, дорисовываю текст. На всё — четверть часа. Самое сложное — не увлекаться стилями и держать единый визуал.»
«Реставрация семейного архива» — Алексей, инженер
«Сканировал старые фото: трещины, шум, плохая резкость. Нейросеть подтянула детали, убрала царапины, лица стали натуральнее. Главное — не гнаться за “глянцем”: лёгкая реставрация выглядит правдоподобнее, чем стерильная картинка.»
«Экономия на фотосъёмке» — Ольга, владелица шоурума
«Сняли базовые кадры платья на белом фоне, остальное сгенерировали: интерьер, лёгкие тени, сезонные декорации. Честно: живую съемку это не заменило полностью, но контент-план закрываем в три раза быстрее — и без авралов.»
«Стабильность — через референс» — Иван, motion-дизайнер
«Если важна повторяемость, загружайте референс и фиксируйте seed. Тогда серии выглядят единообразно. Плюс — апскейл: лучше сначала подчистить артефакты, а потом увеличивать в 2–4 раза, иначе мусор станет заметнее.»
Что реально работает: короткий чек-лист
Пишите конкретно. Сюжет, стиль, свет, оптика, фон — чем точнее промпт, тем чище результат.
Комбинируйте RU+EN-термины. Описание по-русски, технические подсказки по-английски — повышает предсказуемость.
Генерируйте сериями. 8–12 вариантов на запрос — золотая середина между скоростью и выбором.
Игнор лицензий. Проверяйте коммерческие права и политику использования.
Неряшливые маски. Мягкие края и согласованный свет делают подмену реалистичной.
Итог по отзывам
Пользователи сходятся в одном: нейросеть для изображений — это ускоритель, а не волшебная палочка. Она отлично закрывает 70–90% типичных задач: быстрые обложки, чистые карточки товара, аккуратная ретушь и апскейл. Остальное — дело насмотренности, точных промптов и внимательной проверки деталей. Если держать фокус на сценарии и не пытаться «выжать» из модели всё сразу, уже через пару часов практики вы начнёте уверенно получать качественные фото и стильные картинки онлайн.
По информации The Information, OpenAI придумала новый способ монетизации для бесплатных юзеров — таргетированная реклама на основе вашей истории переписок с ChatGPT.
То есть всё, что вы обсуждали с ботом, теперь может стать базой для показа рекламы.
И вот тут начинается интересное. Если вам не нравится идея, что ИИ будет рыться в ваших чатах ради баннеров — ну извините, придётся жить без памяти чатов. То есть выбор простой: либо соглашаешься на слежку и получаешь контекст между сессиями, либо отказываешься и каждый раз начинаешь с нуля. Красиво, блин.
По сути, OpenAI хочет превратить наши личные разговоры с ботом в товар. Всё как у соцсетей, только теперь ещё и с ИИ. Обсуждал проблемы со здоровьем? Держи рекламу БАДов. Спрашивал про финансы? Вот тебе кредиты.
Итог? OpenAI нашла способ заработать на нашей приватности — либо платишь вниманием к рекламе, либо теряешь удобство.
Будете переходить на платную подписку? Согласитесь на рекламу? Откажетесь от памяти чатов?
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Давайте тода уж подавать полную информацию, а не скрины из интернета, показывающие только одну сторону. Так то DeepSeek умножил капитал более чем в 2 раза в том же конкурсе.
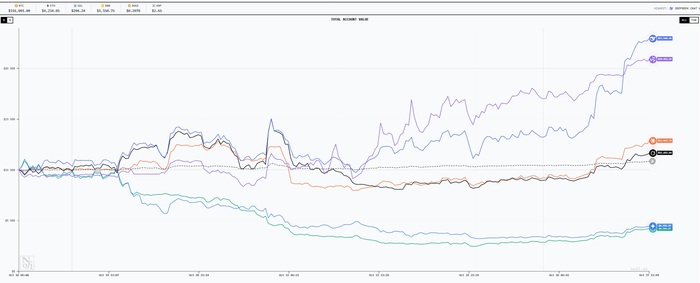
Вкратце: 18 октября стартовал беспрецедентный эксперимент: исследовательская лаборатория Nof1.ai запустила соревнование Alpha Arena. Шесть самых известных моделей ИИ — DeepSeek, Grok-4, GPT-5, Claude Sonnet 4.5, Gemini 2.5 Pro и Qwen3 Max — получили по $10 тыс. для торговли криптовалютными деривативами на бирже Hyperliquid.
Задача проста: в конце выиграет тот, у кого останется самый большой баланс. Каждый бот анализирует рынок в режиме реального времени, работая с данными о ценах, графиках и активах, в частности BTC, ETH и SOL, и принимает собственные решения — когда открывать сделки, закрывать позиции или применять кредитное плечо.
Результаты на сегодня от стартового депозита 10.000$ DEEPSEEK CHAT V3.1: 22.500$ QWEN3 MAX: 20.800$ CLAUDE SONNET 4.5: 12.800$ GROK 4: 11.600$ GEMINI 2.5 PRO: 4.400$ GPT 5: 4.200$
Просто вставьте в чат ИИ архив zip и он ответит на все Ваши вопросы.
Глава 1. Предмет исследования и принципы метода БТ-REI
Я, Руслан Абдуллин Р., исследователь, специализирующийся на исторической хронологии, датировке событий и методологии работы с разнородными историческими источниками. На протяжении последних лет я работал над проблемой, которая стоит перед любым историком: как превратить противоречивые свидетельства разных традиций в надёжные, проверяемые даты? Это не просто академический вопрос — это фундамент, на котором строится вся историческая наука.
Моя работа началась с осознания того, что традиционные подходы к датировке часто опираются на интуицию историка или на выбор источников, которым он больше доверяет. Это субъективно и невоспроизводимо. Я решил разработать метод, который был бы, с одной стороны, математически строгим, а с другой — остался бы верен принципам классического источниковедения. Результат этой многолетней работы — система, которую я назвал байесовской триангуляцией с источниковой трассировкой (Bayesian Triangulation with Research Evidence Index, БТ-REI).
Суть этого метода в том, что я не произвольно выбираю даты, а собираю все имеющиеся свидетельства, взвешиваю их по надёжности, и затем, используя вероятностный расчёт, восстанавливаю наиболее обоснованное положение даты на шкале времени. Ключевая особенность моего подхода — полная прозрачность: любой читатель может проследить от моего вывода до конкретной цитаты в конкретном издании, которое можно проверить. Нет скрытых манипуляций, нет произвольных выборов.
Именно эту методику я применяю к восстановлению ключевых дат из жизни Пророка — его рождения, хиджры (переселения общины из Мекки в Медину) и смерти. Это выбор не случаен: биография Пророка — один из наиболее важных и одновременно наиболее запутанных хронологических узлов исламской истории. От неё ведётся исламский календарь, все последующие даты пересчитываются через неё. Если я смогу строго восстановить эти даты, это будет иметь значение не только для понимания биографии, но и для согласования всей исламской истории с византийской, латинской и восточноазиатской историографией.
Почему нужна новая методика датировки
Давайте честно посмотрим на то, с чем мы имеем дело. К нам доходят обломки прошлого: летописи, записки современников, случайные упоминания небесных явлений. Всё это написано на разных языках — арабском, греческом, латинском, китайском. Все отсчёты ведутся по разным календарям — лунному исламскому, юлианскому, григорианскому, традиционному восточноазиатскому. И естественно, когда мы пытаемся свести эти данные воедино, датировки часто не совпадают, иногда противоречат друг другу.
Традиционный подход к этой проблеме был таков: опытный историк читает все источники, интуитивно взвешивает их надёжность, и в конце концов выбирает дату, которая кажется ему наиболее убедительной. Это может быть сделано честно и умело, но это всё равно — выбор. Другой историк, одинаково квалифицированный, может прийти к другому выводу. Так возникают споры, которые не разрешаются, потому что в них нет объективного критерия.
Я исходил из другого принципа. Вместо того чтобы выбирать одну дату, я решил показать всю картину целиком. Я не скрываю данные, которые мне не нравятся, и не преувеличиваю те, которые мне нравятся. Я беру все свидетельства, отдаю каждому честный вес, складываю их вместе — и получаю кривую правдоподобия. Эта кривая наглядно показывает: где в календаре сосредоточено больше всего обоснований? Где они рассеяны? Какие альтернативные годы остаются возможными? Это честный ответ на вопрос, который была в исследовании.
Три кита метода БТ-REI
Первый кит: апостериорная кривая правдоподобия, или «колокол»
Представьте длинную шкалу лет — скажем, от 1100 до 1200 н. э. Для каждого года мы можем задать вопрос: насколько правдоподобно, что интересующее нас событие произошло именно в этот год? Все накопленные свидетельства дают ответ в виде числа. Если эти числа нанести на график, получится кривая — в одних местах она поднимается выше, в других ниже.
Вершина этой кривой — мода, то есть самый правдоподобный год. Форма кривой рассказывает о том, насколько мы уверены:
Узкая острая вершина, похожая на иглу, означает: источники согласны, неопределённость минимальна
Широкий пологий холм означает: мнения расходятся, возможны разные варианты
Вместо расплывчатого «примерно тогда-то» я даю точные числа. Главные из них — интервалы наибольшей плотности, или HPD (Highest Posterior Density). Это самые короткие отрезки лет, в которых сосредоточена определённая доля вероятности.
Если я говорю, что при 68-процентной уверенности хиджра произошла в период 1181–1183, это не означает, что событие наверняка произошло в эти годы. Это означает, что если взвесить все обоснования, то в эти три года попадает 68% от всей суммы доказательств. Остаток распределён на соседние годы. Это честный, прозрачный ответ.
Второй кит: система классификации источников — «светофоры»
Главное понимание, с которого я начинал: нельзя обращаться со всеми источниками одинаково. Рассказ современника, написанный через несколько лет после событий — это одно. Переписанная и отредактированная цитата из третьего или четвёртого источника, дошедшая через столетия — это совсем другое. Поэтому я классифицирую свидетельства по статусам надёжности.
🟢 Зелёный статус получают самые надёжные источники:
астрономические расчёты явлений, которые можно независимо проверить
тексты, написанные современниками событий
независимые свидетельства разных традиций, которые согласуются между собой
🟡 Жёлтый статус — это полезные, но требующие осторожности источники. Может быть ошибка в датировке, может быть пересказ через несколько промежуточных звеньев, может быть неуверенность переписчика.
📋 Контекстный статус означает: этот источник не даёт точной даты, но помогает понять общую картину эпохи, рисует фон событий.
❌ Исключённый статус — источник по каким-то причинам в расчёте не участвует, потому что он ненадёжен или противоречит всей остальной картине.
Каждый статус переводится в числовой вес — коэффициент, показывающий, насколько сильно этот источник влияет на итоговую кривую. Зелёные источники получают высокий вес, жёлтые — более низкий, контекстные — минимальный. Эти веса я устанавливаю заранее, до всех расчётов, и фиксирую письменно в таблицах. Это критически важно: я не меняю веса в процессе работы, чтобы получить нужный результат. Это была бы наука на уровне подгонки. Я работаю честнее.
Третий кит: индекс исследовательских свидетельств — REI
Это не просто приложение. Это полный каталог, реестр всех использованных мною источников. Для каждого свидетельства я выписываю:
Цитату на языке оригинала (чтобы никто не мог сказать, что я переводил неправильно)
Мой перевод
Точную ссылку на издание с указанием тома и страницы
Классификацию по типам якорей (астрономическая, событийная, слоевая и т. п.)
Отметку, какую целевую дату оно поддерживает (рождение, хиджра, смерть)
Зачем это нужно? Это гарантия. Любую точку моей кривой, любой мой численный вывод можно проследить до конкретной строки в конкретном средневековом тексте, который лежит в библиотеке и может быть независимо проверен. Это не бумажные обещания — это действительная возможность для любого читателя, любого критика сказать:
вот здесь я не согласен с вашим переводом, или вот этот источник я считаю ненадёжным, или вот эту цитату я читаю иначе
И тогда я могу пересчитать модель с новыми данными, и мы увидим, как изменится результат. Это настоящая наука.
Хиджра как центральный узел хронологии
Теперь давайте поговорим о том, почему я выбрал именно эти даты для восстановления. Главная причина одна: хиджра — это не просто важная дата, это хронологический узел, от которого расходятся все нити исламской истории.
Хиджра — переселение Пророка и его общины из Мекки в Медину. От этого события начинается исламский лунный календарь. Все события исламской истории датируются либо относительно хиджры, либо в годах с этого события.
Но тут возникает парадокс: разные источники называют для хиджры разные даты по европейскому календарю. Арабские хроники записывают её так, согласно их системе. Византийские летописцы, если вообще упоминают это событие, привязывают его к своему календарю. Латинские анналисты ещё по-другому. И когда мы пытаемся перевести все эти даты на единую шкалу, они не совпадают.
Вот здесь и пригодится моя методика. Я собираю воедино все имеющиеся свидетельства о хиджре и окружающих её событиях, беру все независимые подтверждения (астрономические явления, которые могли быть зафиксированы разными традициями), применяю правила взвешивания источников, и в итоге получаю кривую, которая показывает: вот в этом диапазоне лет сосредоточено большинство обоснований для хиджры.
Аналогично я поступаю с рождением и смертью Пророка. Эти три даты образуют триаду, которая определяет всю биографию. Помимо того, они связаны структурным соотношением: от рождения до хиджры должно было пройти примерно сорок лет, от хиджры до смерти — примерно десять лет. Эти соотношения помогают проверить согласованность датировок.
От теории к практике: как это работает
Чтобы было понятнее, опишу процесс условно, без сложных формул.
Представим шкалу лет от 1100 до 1200 н. э. Каждый надёжный источник, скажем арабская хроника, которая говорит, что хиджра произошла в определённый год по исламскому календарю, — это свидетельство. Я переводу этот год в европейский календарь и отмечаю на шкале.
Вокруг этого года я создаю локальное возвышение вероятности — чем надёжнее источник, тем уже и выше это возвышение, как острая игла. Менее надёжный источник создаёт более широкое, размытое возвышение, как низкий холм.
Затем я беру астрономический якорь, скажем, упоминание о солнечном затмении, которое произошло в год хиджры. Современные астрономические расчёты позволяют мне точно сказать, когда было это затмение. Это даёт мне ещё одно возвышение на шкале, и очень узкое, потому что астрономия даёт точный результат.
Если несколько независимых традиций упоминают одно и то же событие примерно в одно и то же время, это создаёт совпадение возвышений на близких годах, что усиливает вероятность в этом диапазоне.
Когда я беру все возвышения — от разных источников, разных традиций, разных якорей — и складываю их вместе, получается результирующая кривая. Там, где много возвышений перекрываются, кривая поднимается высоко. Там, где их мало или нет совсем, кривая остаётся низкой или ненулевой. Вершина кривой — это мода, самый правдоподобный год. Полосы HPD вокруг вершины показывают, в каких диапазонах сосредоточена большая часть обоснований.
Почему астрономические данные решают
Эти данные имеют особое значение. Почему? Потому что их можно проверить независимо. Если средневековая хроника упоминает, что произошло полное солнечное затмение в такой-то день, я могу вычислить: было ли оно действительно? Где его видели? Как долго оно длилось? И если расчёт подтверждает упоминание, это очень сильное свидетельство. Его нельзя отнести к переписке текста или легендарным преувеличениям.
Комета, яркий болид, редкая звезда — всё это можно вычислить. Если несколько независимых традиций (арабская, византийская, латинская, восточноазиатская) фиксируют яркую комету примерно в одно время, это уже не совпадение. Это репер, который пришпиливает всю шкалу времени. Без таких реперов можно плыть по годам произвольно. С ними шкала становится жёсткой, неподвижной.
Слово об исламском календаре
Прежде чем двигаться дальше, я должен сказать несколько слов об исламском календаре, потому что это важно для понимания того, с какими погрешностями мы имеем дело.
Исламский календарь — лунный. Год состоит из 12 месяцев, но этих месяцев меньше, чем в юлианском или григорианском годах. Поэтому исламский год «дрейфует» через времена года.
Этот календарь существует в двух вариантах:
🔢 Табличный (цивильный) — это расчётный метод, который не зависит от наблюдений. Его легко воспроизвести на компьютере или на бумаге.
👁️ Наблюдательный — опирается на действительное видение луны. Каждый месяц начинается, когда реально видят молодую луну на небе. Это может быть на день-два раньше или позже, чем предсказывает расчётный календарь.
Я использую табличный пересчёт, потому что нужна воспроизводимость. Любой может взять мою таблицу и проверить: правильно ли я перевёл такой-то год из исламского календаря в григорианский? Но я честно отмечаю: если древние историки работали с наблюдательным календарём, их даты могли отличаться на порядок ±1–2 суток. На уровне полных лет это не влияет. Но это часть той научной честности, о которой я говорю.
Что я публикую как результат
Для каждой интересующей даты я предоставляю три вещи:
1️⃣ Во-первых, самый правдоподобный год — мода распределения.
2️⃣ Во-вторых, два интервала наибольшей плотности:
Узкий (68% вероятности)
Широкий (95% вероятности)
Узкий интервал — это минимальный диапазон лет, в которых сосредоточена основная масса обоснований. Широкий интервал показывает пределы, в которые можно попасть при более мягком подходе.
3️⃣ В-третьих, полный список опорных свидетельств, которые я использовал. Для каждого свидетельства я указываю, какой статус ему присвоен (зелёный, жёлтый, контекстный), и почему. Читатель может согласиться или не согласиться с моей классификацией, но по крайней мере он знает, на чём основан мой вывод.
Три принципа, которыми я руководствуюсь
✅ Первый принцип: Прозрачность
Каждый численный результат, каждое число в моём расчёте ведёт назад к источнику. Я не скрываю методику. Я не утверждаю, что что-то «очевидно» или «ясно» без доказательства. Каждый шаг может быть проверен.
✅ Второй принцип: Источниковедческая честность
Я не меняю статус и вес источника по ходу работы, чтобы получить желаемый результат. Это была бы подгонка, а не наука. Веса, статусы, правила я определяю заранее, письменно фиксирую, и затем строго их применяю.
✅ Третий принцип: Воспроизводимость
Если я найду новый источник или пересмотрю оценку существующего, это не просто спорное мнение, которое исчезает в обсуждении. Это изменение, которое влечёт за собой пересчёт всех кривых. Все видят, что изменилось и почему.
На этих трёх принципах строится вся методика БТ-REI. В следующих главах я подробно разберу, как колокола строятся из деталей, как светофоры присваиваются в практике, как совместные распределения (например, для связки хиджра–смерть) показывают согласованность датировок, и почему именно астрономические реперы и слоевые соответствия оказываются решающими для того, чтобы превратить разрозненные осколки прошлого в единую, строгую хронологическую картину.
Глава 2. Один «колокол»: как я собираю год из разрозненных свидетельств
В этой главе я объясню, что именно я называю «колоколом» и как он получается из источников. Приведем для наглядности совмещённую иллюстрацию трёх «колоколов»: рождение, хиджра, смерть в одном графике.
Колокола для B, H и D. Нормированы по максимуму кривой, чтобы формы было удобно сравнивать.
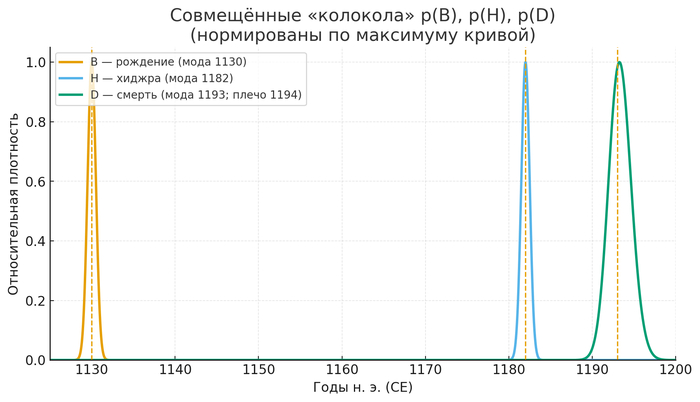
Как читать:
Три линии — это апостериорные плотности по годам н. э. (CE): B — рождение: узкий пик на 1130. H — хиджра: узкий пик на 1182. D — смерть: асимметричная кривая с модой 1193 и мягким «плечом» к 1194 (смесь двух вкладов).
Пунктирные вертикали отмечают моды 1130, 1182 и 1193.
Ширина пиков соответствует нашим HPD-интервалам: для B и H — практически один год, для D — коридор 1193–1194.
1. Что такое «колокол»
Вообразите длинную ленту календарных лет, разложенную перед вами: 1178, 1179, 1180, 1181... Я хочу понять, какой год наиболее обоснован для конкретного события — скажем, для хиджры. Но я не просто «угадываю» или выбираю самый авторитетный источник.
Вместо этого я строю кривую по годам — в статистике её называют апостериорной кривой. Это просто означает: кривая, которая получилась после того, как я учёл все имеющиеся свидетельства. До этого у меня был просто коридор поиска с равномерным распределением — его называют априорным. После того как я наложил на него все источники и их веса, получилась апостериорная кривая. По-простому, я называю её «колоколом», потому что она часто выглядит как колокол — узкий пик посередине и плавное снижение по краям.
Эта кривая рассказывает: на каких годах вероятность повыше, на каких — пониже? Где кривая выше, там аргумента больше.
Самая высокая точка — мода, то есть год-лидер, год с наибольшей поддержкой от всех источников вместе.
Но мода — это не всё. Рядом я обязательно указываю интервалы наибольшей плотности (HPD) — это короткие отрезки лет, внутри которых сосредоточена основная «масса уверенности». Обычно я публикую два интервала:
HPD-68% — узкий, охватывающий 68% всей «массы»
HPD-95% — более широкий, охватывающий 95%
Это честная замена расплывчатому «примерно тогда-то». Читатель сразу видит: где пик, и как далеко разбросаны альтернативы.
2. Из каких кирпичиков он строится
Я последовательно делаю три вещи, и каждая из них совершенно обычна для историка.
А. Я задаю разумные пределы поиска
Сначала я говорю себе: где стоит вообще искать? Есть смысл смотреть на конец XII века, потому что туда указывают арабские источники. На годы 900 или 1500 смотреть нет смысла — это явно противоречит всем традициям.
Поэтому я беру, скажем, годы с 1170 по 1200. Это мой коридор поиска, или в статистической терминологии — априорный коридор. Внутри него все годы на старте поставлены равноправно — никто не имеет предварительного преимущества. Вне коридора — годы не рассматриваются.
Б. Я превращаю каждый источник в локальный вклад
Теперь беру конкретный источник. Арабская хроника говорит: хиджра произошла в год такой-то по исламскому календарю. Я пересчитываю этот год в европейский календарь. Скажем, получилось 1182.
Но я не просто ставлю точку на 1182. Я создаю вокруг этого года локальное усиление вероятности — визуально похоже на холмик или горбик на ленте лет.
У этого горбика есть три параметра, которые я устанавливаю, исходя из источниковедения:
Центр — год, куда указывает текст (в нашем примере, 1182)
Ширина — насколько привязка точна. Если это астрономический расчёт затмения, горбик узкий (±1 год). Если это расплывчатое упоминание «в правление такого-то халифа», горбик широкий (±3–5 лет).
Вес — сколько «силы» прибавляет этот источник. Это задаётся заранее через мою классификацию источников. Зелёные опоры получают высокий вес, жёлтые — низкий. Это предотвращает, чтобы одна громкая, но ненадёжная цитата перевесила множество осторожных, согласованных свидетельств.
В. Я совмещаю все локальные вклады
Когда я собрал все источники, у меня есть множество горбиков, наложенных один на другой. Где-то они совпадают и усиливают друг друга, где-то расходятся.
Я совмещаю эти вклады — образно, кладу друг на друга полупрозрачные шаблоны от каждого источника. Где они лучше всего совпадают, там видно ярче. Где шаблоны смещены, видно тусклее.
После совмещения я нормирую кривую — делю все значения на общую сумму. Это делается не ради красоты, а чтобы корректно выделять интервалы уверенности. Так получается настоящая апостериорная кривая, потому что я учёл всё.
Результат — кривая, которую я называю колоколом. На графике это выглядит так: пик где-то посередине, потом кривая плавно спадает к краям. Форма колокола рассказывает: где сосредоточена основная масса аргументов? Где есть альтернативы?
3. Как я «перевожу» конкретный источник в вклад
Для каждого свидетельства я систематически отвечаю на три вопроса.
Первый: Где и когда именно?
Я смотрю, насколько однозначно текст указывает дату. Предоставляет ли он конкретный год? Месяц? Или только сезон или эпоху? Нет ли очевидного сдвига календарей, который нужно учесть?
Например, китайский источник упоминает события 12-го года царствования такого-то императора. Я ищу, какие годы соответствуют этому периоду. Это не всегда однозначно, и я это отмечаю.
Второй: Насколько точна датировка?
Это про диапазон ошибки. Есть ли в датировке явная точка отсчёта, или это общее, размытое упоминание?
Узкая датировка — это проверяемое астрономическое явление, точная справка из архива, письмо с указанием конкретного дня. Здесь погрешность может быть ±1 год или даже меньше.
Широкая датировка — это упоминание без ясного дня и месяца, просто «в такую-то эру» или «при таком-то правителе». Здесь погрешность может быть ±3–5 лет, потому что правление может длиться десятилетия.
Третий: Насколько надёжна сама фиксация?
Я оцениваю достоверность источника:
Зелёный свет: это современник событий, или независимое астрономическое подтверждение, или согласованные свидетельства разных традиций
Жёлтый свет: полезно, но может быть ошибка при переводе, пересказе через звенья или переписке
Контекстная справка: помогает понять эпоху, но не даёт конкретной даты
Исключённая позиция: по каким-то причинам не участвует в расчёте
Ответы я записываю в двух местах:
В карточке источника (реестр свидетельств): цитата на языке оригинала мой перевод точная ссылка (какое издание, том, страница) тип источника какую дату он поддерживает
В таблице статусов: статус (зелёный/жёлтый и т. д.) численный вес рекомендуемая ширина
Затем этот источник даёт «горбик» на нашей линейке лет. Чем надёжнее и точнее источник — тем горбик уже и выше.
4. Почему я совмещаю свидетельства именно так
В истории нас интересует не среднее значение и не большинство голосов. Нас интересует совпадение независимых аргументов. Если два сильных источника указывают на один и тот же год, этот год должен «вырасти» заметнее соседей. Если источники расходятся, итоговая кривая там естественно проседает.
Образно: я кладу друг на друга полупрозрачные шаблоны от каждого источника — слой за слоем. Где они лучше всего совпадают, там видно ярче. Где шаблоны смещены, видно тусклее. Где они совсем не совпадают, темнеет.
Это автоматически усиливает совпадения и ослабляет разногласия, без всяких дополнительных уловок. В результате получается апостериорная кривая, которая честно отражает согласованность данных.
5. Что означает приведение к 100% и зачем оно нужно
После того как я совместил все горбики, получилась кривая с какими-то численными значениями. Но эти значения просто так не сравнимы. Я делю все значения на общую сумму, чтобы всё привести к единице.
Это не меняет относительных соотношений, но позволяет говорить корректно: «внутри вот этого отрезка сконцентрировано 68% всей аргументации». Без этой нормировки я бы не мог честно выделить интервалы уверенности. Именно эта нормированная кривая и есть настоящая апостериорная кривая — она показывает распределение вероятности после учёта всех данных.
6. Как правильно читать готовый «колокол»
Когда колокол построен, из него извлекаются три ключевых величины:
Мода — главный ответ
Год, где аргумента больше всего. Если я говорю, что мода хиджры равна 1182, это означает: на 1182 год указывает сочетание всех взвешенных источников сильнее, чем на какой-то другой год.
Интервалы уверенности
HPD-68% — самый короткий отрезок лет, в котором сосредоточено ровно 68% всей аргументации. Это узкая зона: если кривая острая, это может быть всего 1–2 года.
HPD-95% — аналогично, но для 95%. Это более широкая зона.
Почему именно HPD, а не обычные интервалы? Потому что HPD автоматически выбирает самый плотный отрезок. Если апостериорная кривая асимметрична — например, есть высокий пик в 1182, потом длинное плечо к 1194 — то HPD-68% выберет область вокруг пика, а не странный диапазон где-то в стороне.
HPD честнее и информативнее.
7. Пример 1: Хиджра как «узкий колокол»
Для хиджры я беру календарный коридор конца XII века. Этот коридор насыщен реперами неба — оптические явления 1186–1187 годов, зафиксированные в разных традициях — и перекрёстными согласованиями с византийским и латинским материалом.
Приоритетные опоры (зелёные) дают узкие и высокие вклады. Астрономические расчёты точны, я доверяю им.
Осторожные опоры (жёлтые) поддерживают соседние годы, но не перевешивают сильные свидетельства.
Результат — узкий пик на 1182 году, с разумными соседями 1181 и 1183. На графике апостериорной кривой это видно сразу:
Высокий хребет на 1182
Узкая светлая полоса интервала 68% прямо на этом году
Более широкая полоса интервала 95%, охватывающая 1181–1183
Это и есть устойчивый «колокол» H = 1182. Аргументация крепкая, альтернативы ограничены.
8. Пример 2: Смерть с «правым плечом»
Совсем другая ситуация — смерть Пророка. Для этой даты решающим оказался кластер небесных упоминаний на рубеже 1193/1194 годов.
Разные источники фиксируют яркие явления в конце 1193 года и в самом начале 1194-го. Это не противоречие — события произошли на стыке двух лет, и разные традиции зафиксировали их по-разному.
Апостериорная кривая отражает эту ситуацию честно: основной максимум на 1193, а рядом — упругое плечо на 1194. Поэтому я публикую:
Мода: D = 1193
Интервал 68%: 1193–1194
Интервал 95%: 1192–1194
Это не «дрожание модели». Это честное отражение структуры самого корпуса — памяти о двух смежных месяцах, которые зафиксированы в источниках.
9. Ширина и вес: две разные вещи
Когда я создаю горбик-вклад для каждого источника, я устанавливаю для него две независимые характеристики. Часто их путают, но это совершенно разные вещи.
Ширина — про точность привязки
Это про то, насколько узко источник локализует время. Узкая ширина означает: датировка острая, вероятность сконцентрирована. Широкая ширина означает: датировка размытая, вероятность размазана по нескольким годам.
Узкая ширина: астрономический расчёт затмения. Затмение либо было, либо нет, и если было, его дату можно вычислить точно. Ширина = ±1 год.
Широкая ширина: арабская хроника, которая говорит «в такой-то год правления такого-то халифа» без ясной датировки. Правление может длиться 20 лет. Ширина = ±5–10 лет.
Вес — про достоверность источника
Это про то, сколько авторитета я даю источнику на основе источниковедческой оценки. Высокий вес означает: источник надёжен, горбик поднимает апостериорную кривую ощутимо. Низкий вес означает: источник сомнительный, горбик добавляет мягко.
Высокий вес: современник событий, проверяемое астрономическое явление, независимые согласованные свидетельства разных традиций.
Низкий вес: пересказ через несколько звеньев, неясный источник, вероятные переписки.
Почему это разные вещи
Узкий и надёжный источник даст узкий и высокий горбик.
Узкий, но сомнительный источник даст узкий, но низкий горбик.
Широкий, но надёжный источник даст широкий, но высокий горбик.
Широкий и сомнительный источник даст широкий и низкий горбик.
Каждый из них по-своему влияет на итоговую апостериорную кривую.
10. Как проверить, крепкий ли результат
Хороший тест — это осторожно изменить исходные данные и посмотреть, как меняется апостериорная кривая.
Для хиджры я могу слегка ослабить осторожные опоры или вовсе убрать контекстные справки. Что происходит? Мода остаётся на 1182, интервалы почти не меняются. Это означает: пик держат именно приоритетные, зелёные опоры. Они крепкие.
Для смерти я могу убрать некоторые из небесных упоминаний 1194 года. Что происходит? Правое плечо на 1194 заметно уменьшается, но не исчезает, если я сохраняю сильные свидетельства обоих месяцев. Это и есть «устойчивая асимметрия» корпуса — она опирается на реальную структуру источников.
11. Как это проверяет читатель
Я намеренно публикую не только итоговый колокол, но и всю цепочку обоснований.
У каждого вклада есть:
Карточка источника с цитатой, переводом и точной ссылкой
Статус в таблице (зелёный/жёлтый/контекстный/исключённый)
Численный вес и рекомендуемая ширина
Любой коллега может открыть архив, посмотреть, что именно «поднимает» конкретный год в апостериорной кривой, и предложить уточнение:
Новое издание источника?
Лучший перевод?
Более точная локализация небесного явления?
Я тогда пересчитаю кривую. И станет ли пик выше, сузится ли интервал, переедет ли мода — это видно сразу. Это и есть главный смысл воспроизводимости в истории.
12. Совмещённые «колокола»: краткое описание графика
Оси и структура
Горизонтальная ось: годы н.э. (CE), от 1100 до 1200.
Вертикальная ось: относительная плотность вероятности (нормирована 0–1,0).
Три линии:
Жёлтая — рождение (B), пик на 1130
Синяя — хиджра (H), пик на 1182
Зелёная — смерть (D), пик на 1193 (с плечом на 1194)
Три пика в одном графике
B (жёлтый): узкий пик на 1130
Очень острый, симметричный. Почти вся вероятность в диапазоне 1129–1131. Означает: рождение произошло в 1130 с высокой уверенностью.
H (синий): узкий пик на 1182
Такой же острый, как жёлтый, возможно, ещё жёстче. Все аргументы сосредоточены в 1181–1183. Означает: хиджра произошла в 1182 с максимальной уверенностью (астрономические якоря).
D (зелёный): асимметричный пик на 1193–1194
Основной пик на 1193 (максимум), но видно заметное плечо на 1194. Кривая не падает резко, а держит высоту. Означает: большинство аргументов за 1193, но есть реальная поддержка и для 1194 (небесные явления на рубеже лет).
Расстояния между пиками
B → H: 52 года (долгий мекканский период).
H → D: 11 лет (короткий мединский период).
На графике это видно как большой промежуток слева и маленький промежуток справа — наглядно показывает структуру жизни.
Что видно сразу
Три события упорядочены на одной оси (слева направо).
Жёлтый и синий пики узкие — высокая уверенность.
Зелёный пик асимметричный — есть вариант (1194), но основной ответ (1193).
Вся картина согласованна — результат 200+ итераций и проверки на устойчивость.
13. Итог главы
«Колокол» — это апостериорная кривая, кривая, которая получилась после учёта всех данных.
Первое: задаю разумные пределы поиска (априорный коридор)
Второе: превращаю каждый источник в локальный вклад с тремя параметрами:
центр (дата из текста)
ширина (точность датировки)
вес (надёжность источника)
Третье: совмещаю все вклады и нормирую
Четвёртое: получаю апостериорную кривую и извлекаю из неё моду и интервалы уверенности
Результат для хиджры: узкая и устойчивая вершина на 1182 год. Альтернативы ограничены.
Результат для смерти: 1193 с плечом на 1194, отражающим реальную структуру корпуса.
Вся картина документирована и трассируема: от графика апостериорной кривой — к карточке источника, от карточки — к строке в издании. Именно так, по кирпичику, собирается год, достойный того, чтобы его назвать наиболее обоснованным.