С миру по нитке
Распределённые вычисления: как собрать с миру по гигафлопсу на развитие науки Автор: Андрей Васильков 06 декабря 2012, ресурс КомпьюТерра.
Вот уже более шестнадцати лет у каждого пользователя есть хорошая возможность внести посильный вклад в развитие науки. Не нужны денежные пожертвования и даже профессиональный интерес к выбранному предмету исследований. Имеет значение лишь то, какими чертами характера обладает человек и насколько современные компьютеры есть в его распоряжении. При удачном сочетании этих факторов появляются надёжные узлы сетей распределённых вычислений – одного из самых мощных инструментов компьютерной обработки данных. Благодаря совместным усилиям обычных пользователей удалось сделать множество значимых открытий. Только за последние три года они отыскали 53 пульсара, причём последние семь нашлись совсем недавно — в конце августа 2012 г.
Результаты выполненных исследований используются при разработке лекарственных препаратов для лечения сахарного диабета второго типа, болезней Альцгеймера и Паркинсона, других тяжёлых заболеваний. По материалам выполненных работ опубликованы сотни научных статей. Суперкомпьютеры и распределённые сети Мощные суперкомпьютеры – это капля в море. Машин, которые представляют собой предмет гордости целых стран и занимают первые строчки рейтинга TOP 500, не так уж много, и на всех их не хватает.
Чтобы получить доступ к суперкомпьютеру, требуется сначала обосновать необходимость выбранной задачи, а потом, если доводы оказались убедительными, дождаться очереди и успеть оптимизировать код для выполнения на своеобразной суперкомпьютерной архитектуре. Лидеры списка TOP 500 на ноябрь 2012 г. Несмотря на внушительные значения пиковой производительности, требуемое время работы суперкомпьютеров может измеряться месяцами. Очевидно, что монополизировать ценную машину на столь долгий срок не позволят. К тому же организаций, которым по карману счета за сотни мегаватт-час, съедаемых вычислениями, прямо скажем, немного. Решение этой проблемы существует.
Поскольку многие научные задачи поддаются параллелизации, «объять необъятное» можно по частям — поделив их между энтузиастами. Сети распределённых вычислений получили широкую известность в 1996 году в ходе командных соревнований по поиску чисел Мерсенна. Другим заметным проектом того времени стал SETI@home — коллективный поиск сигналов внеземных цивилизаций в данных, собранных с помощью радиотелескопов. Найти инопланетян так и не вышло, но этот опыт не был бесполезным.
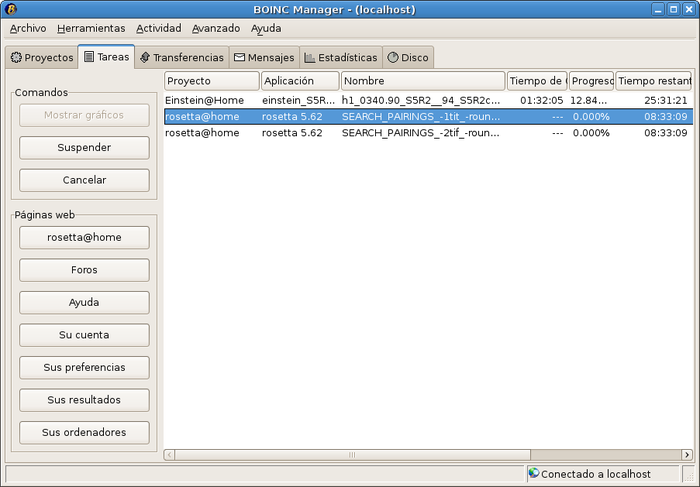
Он показал, что проекты таких масштабов могут успешно работать даже на добровольных началах. А наработки SETI@Home пригодились при подготовке исследовательских программ для поиска радиопульсаров. Сегодня любому пользователю компьютера, работающего под управлением Windows, Linux или OS X, потребуется не больше десяти минут, чтобы присоединиться к одной из глобальных научных инициатив. Для этого в 2002 году Калифорнийским университетом в Беркли была разработана платформа с единым клиентским приложением BOINC Manager. По состоянию на конец 2012 г. BOINC применяется в 87 открытых проектах распределённых вычислений (ещё 24 обходятся без него). Для удобства они разделены по научным дисциплинам, а их краткая характеристика доступна также и на русском языке. Некоторые проекты распределённых вычислений на платформе BOINC Общее количество участников на конец 2012 года составляет около 2,5 миллионов. При этом число компьютеров, ведущих вычисления, перевалило за семь миллионов, а суммарная производительность оценивается в семь петафлопс — это мощнее, чем суперкомпьютер JUQUEEN, занимающий пятую строчку ноябрьского рейтинга TOP 500. Использование BOINC Нецелевое использование BOINC эффективно пресекается.
Люди, которые стоят за платформой, внимательно следят за соблюдением условий лицензии. Проекты, которые нарушают правила, отклоняют и закрывают — особенно в том случае, если под видом фундаментальных исследований добровольцам пытаются подсунуть коммерческие задачи. Это происходит не так уж редко: идея бесплатно воспользоваться чужим трудом прельщает многих. Отклонённые проекты из списка поддерживающих ускорение на ГП. Это не значит, что BOINC принципиально настроен против коммерции. Организации (в том числе коммерческие) могут использовать платформу BOINC и свои компьютеры для решения практически любых задач. Правила лишь запрещают привлекать волонтёров к проектам, подразумевающим извлечение прибыли. Варианты использования платформы BOINC Участники распределённых вычислений Большая часть проектов – международные. Активнейшее участие принимают Германия и Евросоюз в целом.
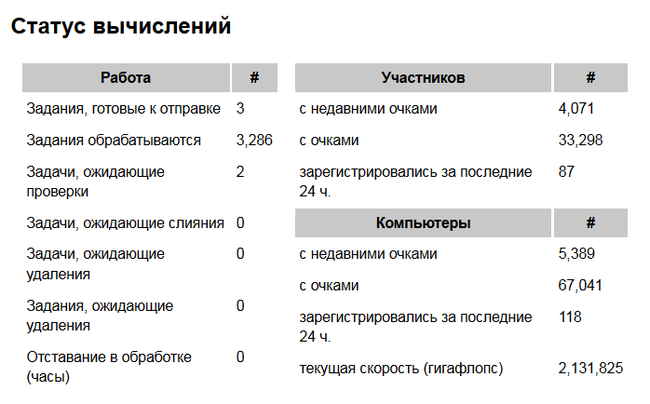
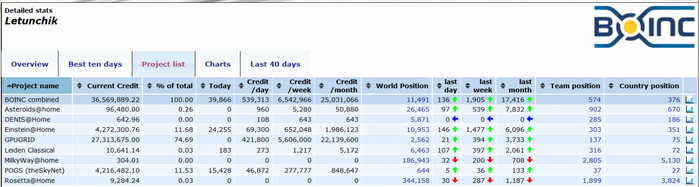
Вклад научных учреждений России пока сравнительно мал, однако за счёт обычных пользователей российский сегмент участников BOINC в мировом масштабе выглядит солидно. Суммарная производительность узлов сети на платформе BOINC в мире Хорошим способом привлечь внимание и увеличить производительность сетей распределённых вычислений считается проведение всевозможных конкурсов. Эта таблица с результатами участников соревнования BOINC по правилам чемпионата «Формулы-1″ говорит сама за себя (синим цветом отмечены международные команды). Соревнования по правилам «Формулы-1″ в области распределённых вычислений Если не считать конкурсов, то даже в популярных проектах львиную долю работы выполняет горстка активных пользователей. Посмотрите хотя бы статистику проекта Einstein@home по состоянию на начало декабря 2012 г. Общее число и доля активных участников проекта Einstein@home В последней строке учитываются те участники, которые за последние две недели выполнили расчёт хотя бы одного присланного задания. Как видим, их доля составляет всего 7,5 процента. Остальные — полумёртвые души. Программа поощрений Такая динамика отчасти объясняется малой отдачей, которую пользователи ощущают от проекта. Кроме осознания факта, что они внесли некоторый вклад в развитие науки, и таких вот «сертификатов», они обычно не получают ничего.
Сертификаты участника проектов BOINC Иногда бывают предусмотрены и другие поощрения. Пользователям, на чьих компьютерах был обработан пакет данных, позволивший сделать открытие, могут прислать подтверждающий этот факт документы. Правда, даже в этом случае всё, как правило, ограничивается поздравлением в электронной форме – даром что человек, возможно, участвовал в распределённых вычислениях годами.
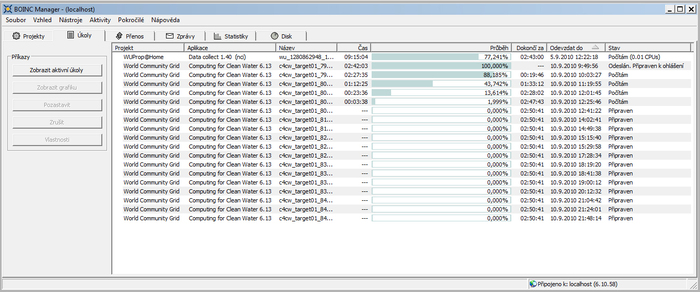
Денежные вознаграждения и вовсе редкость, несмотря на то что их эффективность очевидна. Не последнюю роль в успехе проекта поиска чисел Мерсенна сыграли денежные призы, выплачиваемые Фондом электронных рубежей (EFF) за нахождение простого числа, состоящего из более чем N десятичных цифр. Впрочем, распределённые вычисления не останавливаются. Людей, которые считают, что будущее куда интереснее творить, чем просто ждать его, пока хватает. Разделяющие эту точку зрения могут прямо сейчас отправиться на страницу загрузки BOINC и попробовать внести свой малый, но реальный вклад в науку. Множество проектов, ведущих распределённые вычисления, используют платформу BOINC, которую разработали около десяти лет назад в Калифорнийском университете в Беркли. Первый шаг к участию в одном из них — установка программы BOINC Manager. Установка и настройка клиента BOINC После скачивания и установки клиентской программы можно указать один или несколько проектов, к которым есть желание присоединиться. Начиная с шестой версии клиент BOINC поддерживает гибкие настройки вычислений, позволяющие точно указать, какой частью аппаратных ресурсов человек готов пожертвовать для нужд науки. Кроме того, можно задать в BOINC Manager автоматическую пазу при запуске некоторых программ или вести вычисления лишь в определённые часы. Расчёты можно в любой момент полностью или выборочно приостановить вручную и так же легко возобновить.
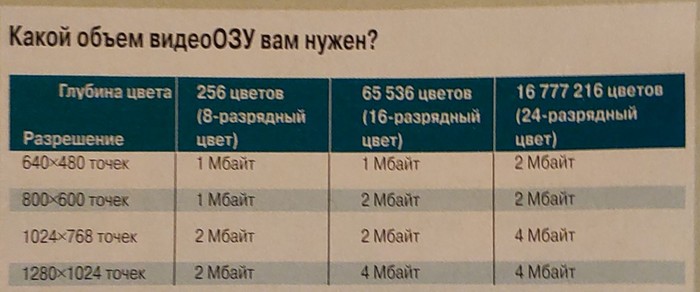
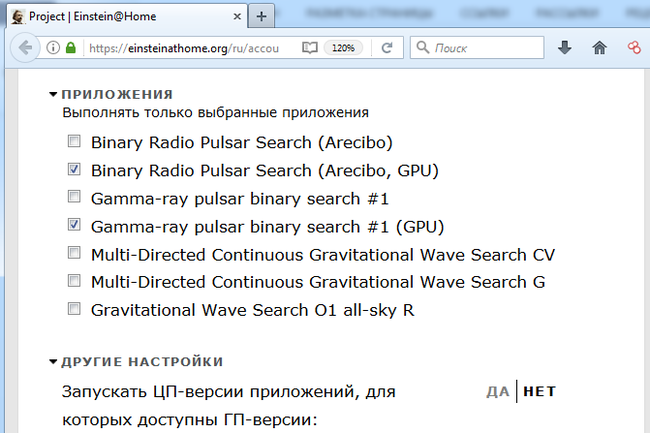
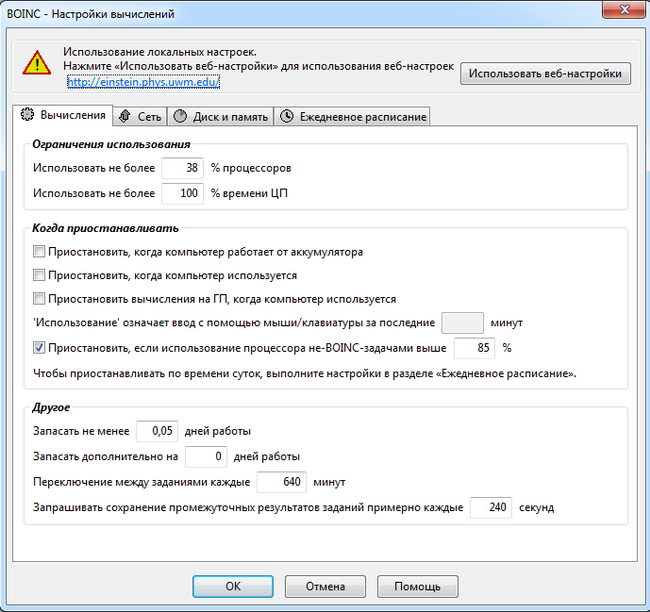
Настройки вычислений на центральном и графическом процессоре в клиенте BOINC Помимо опций самого клиентского приложения, для каждого проекта предусмотрены настройки через веб- интерфейс на личной странице участника. Настройки проекта BOINC через веб-интерфейс Оценить вычислительную мощность компьютера можно встроенным бенчмарком BOINC. Он же иногда используется для сравнения реальной производительности различных конфигураций. Встроенный тест производительности клиента BOINC Выбор проектов с учётом доступных ресурсов При выполнении научных расчётов важную роль играет производительность блоков FPU, осуществляющих вычисления с плавающей запятой.
Точность вычислений может быть разная. Обычно говорят о трёх реализованных на практике типах: FP16 (Half Precision) — половинная точность вычислений с плавающей запятой; FP32 (Single Precision) — одинарная точность вычислений с плавающей запятой; FP64 (Double Precision) — двойная точность вычислений с плавающей запятой. Именно последний тип вычислений (FP64, или binary64 по стандарту IEEE 754) наиболее востребован в расчётах BOINC и других научных программах, поскольку он позволяет оперировать значениями в диапазоне от ≈ 10-308 до 10308 с точностью до 15 знака (в десятичном выражении) после запятой. Однако доля вычислений с одинарной точностью тоже весьма велика и даже достаточна для отдельных проектов. Современные видеокарты поддерживают технологии вычислений общего назначения. Любой видеочип, выпущенный после 2007 года, справится с научными расчётами лучше, чем сопоставимый по цене центральный процессор близкого поколения.
Архитектура и скорость вычислений типа FP32 и FP64 некоторых видео карт. Если раньше в этом сегменте доминировала nVidia (в том числе за счёт выпуска ускорителей Tesla той же архитектуры), то сейчас всё больше проектов смотрят в сторону AMD (ATI). Пример выполнения проектов BOINC на видео карте AMD Появились и такие проекты, которые поддерживают ускорение на видео картах AMD, но не работают с продуктами nVidia. Проекты BOINC с эксклюзивной поддержкой видео карт AMD Предположительно это связано с тем, что при высокой скорости вычислений FP32 видео карты nVidia на чипе GK104 демонстрируют сильное падение производительности в расчётах типа FP64. К примеру, если Radeon HD 6930 выполняет вычисления с двойной точностью в четыре раза медленнее, чем с одинарной (480 и 1920 гигафлопс соответственно), то GeForce GTX 680 – в двадцать четыре (128 и 3090 гигафлопс). Когда «последний» не означает «лучший» Само по себе использование более современных чипов далеко не всегда означает прирост в скорости. Например, HD 6850 не способен считать с двойной точностью, а HD 5850 выполняет вычисления FP64 со скоростью до 418 гигафлопс. Топовые видеокарты часто обладают производительностью многопроцессорного сервера. Например, видеокарта с чипом HD 7970 содержит 2048 вычислительных ядер, объединённых в 32 блока. Её теоретическая производительность составляет 3789 гигафлопс при операциях с одинарной и 947 гигафлопс — с двойной точностью. Для сравнения: арифметическая часть процессора Core-i5 3570K обеспечивает 122 гигафлопса (FP32) и 61 гигафлопс (FP64) в турборежиме, а Intel HD Graphics 4000 даёт прирост ещё на 147 гигафлопс (FP32). У AMD A10- 5800K расчётная производительность арифметической части также находится на уровне 122 гигафлопса (FP32) и 61 гигафлопс (FP64), но видеоядро Radeon HD 7660D обеспечивает четырёхкратный прирост — на 614 гигафлопс (FP32). Сейчас определённо есть смысл выбирать те проекты, которые могут быть обсчитаны с использованием видеокарт или хотя бы встроенных графических ядер. Однако между теоретическим пределом производительности и практически достигаемым результатом часто наблюдается разница не на проценты, а в разы. Она обусловлена квалификацией программистов и оптимизационными пределами для каждой конкретной задачи. Например, задания проекта Einstein@home на компьютере с Core-i3 2100 и видеокартой Radeon HD 6850 обсчитываются со скоростью 49,5 гигафлопса, а POEM@home — 71,4 гигафлопса с теми же настройками. Оба проекта декларируют поддержку ускорения вычислений видеокартами AMD.
Затраты электроэнергии Важным моментом является энергоэффективность разных систем. Сейчас она составляет от 1 до 20 гигафлопс на ватт, и этот параметр напрямую влияет на то, как увеличится ваш счёт за электроэнергию. С точки зрения экономичности привлекательны не только специализированные ускорители и серверные решения, но также APU и отдельные массовые видеочипы. У AMD наиболее интересные чипы расположены ближе к началу ценового диапазона, а у nVidia – преимущественно в его верхней трети. К примеру, эффективность недорогой видеокарты Radeon HD 7770 составляет 16 гигафлопс на ватт в расчётах FP32, однако её использование для выполнения FP64 расчётов неоправданно — здесь она продемонстрирует результат всего в 1,0 гигафлопс на ватт. Даже у выпущенного в 2009 году чипа HD 4750 данный показатель был гораздо лучше – 2,5 гигафлопса на ватт. GeForce GTX 660Ti принадлежит к верхней границе среднего ценового диапазона, но тратит энергию эффективнее: 16,4 гигафлопса на ватт в расчётах FP32 и 2,1 гигафлопса на ватт при вычислениях с двойной точностью.
Если (теоретически) держать BOINC в режиме постоянной обработки и не выключать компьютер, то при потребляемой мощности ≈ 200 Вт он добавит за месяц менее 150 кВт*ч к показаниям счётчика. В типичном сценарии использования (когда BOINC активен только в простое, а компьютер работает по несколько часов в день и выключается на ночь) — менее десяти киловатт-час. Возможно, эти незначительные затраты в поддержку исследовательских команд ведущих университетов мира многим покажутся более оправданными, чем перечисление пожертвований сомнительным благотворительным организациям.