Сначала ты носишь свой код в коробках и борешься с коллегами за возможность сесть за клавиатуру (одну на всех), а потом ты просто говоришь машине, что делать. Или всё не так просто? Если присмотреться, то так ли много изменилось? Меняют ли что-то сегодня нейросети в работе, например, джуна или синьора?
Эта статья состоит из трех частей. Первая и вторая написаны по воспоминаниям программистов из Швеции и СССР: Марианны Эрнерфельд и Владимира Николаевича Орлова. И третья — из опыта работы с нейросетями.
Первые коды для дейтинга и железной дороги
Интервью с Марианной Эрнерфельд было опубликовано в июле 2019 в блоге ее сына. Оно более полное, особенно версия на шведском языке.
Девушка решила стать программистом в 1965 году. Тогда не было ни одного университета, обучающего программированию, но существовал годовой курс в Сольне (коммунна в Швеции), и на него могли выдать студенческий займ.
В то же время SJ (шведская государственная железнодорожная компания, на то время монополист) рекламировала годовую программу стажёрства, на которой можно было учиться работе в разных отделах компании. У SJ был компьютерный отдел, поэтому Марианна подала заявление и в эту программу, надеясь оказаться в нем.
На каждое место было по 14 кандидатов, а компания не хотела нанимать соискателей женского пола, но у Марианны (и нескольких других женщин) получилось успешно пройти все тесты.
Во время обучения студенты обучались всему: от поездов и путей и до того, как работали электрические и телефонные линии. В 1969 году SJ начинает программу внутреннего обучения программированию, и Марианна попадает в нее.
Компьютерный отдел SJ состоял примерно из 40 программистов и системных инженеров. Больше никаким другим образом научиться программированию в Швеции было нельзя — совершенно новая профессия. Некоторые из программистов раньше были машинистами локомотивов, и у большинства даже не было аттестатов о полном среднем образовании.
Обучение началось с объяснения, что такое компьютеры. Затем они прошли курсы в IBM, у которой в огромном здании в Стокгольме находилась «машина для обучения».
Одновременно на одном курсе было примерно 50-100 человек, но нас разделили, так что в каждом кабинете присутствовало по 8 студентов. Там мы смотрели на телеэкраны в передней части класса. Преподаватель и его доска транслировались на экраны из другого кабинета. У каждого преподавателя было примерно по 10 кабинетов со студентами, и каждый кабинет мог задавать вопросы при помощи микрофона, обращая на себя внимание нажатием кнопки. Это было сверхсовременно!
Сначала студенты узнали об IBM OS, а затем изучили собственный язык программирования IBM под названием PL/I. Это была более современная версия Кобола, обладавшая возможностями, которых у Кобола пока не было (но они появятся позже), например, создание таблиц и запросов.
После первого курса IBM Марианна вернулась в SJ для выполнения своих первых практических программ. Она и трое обучающихся создали программу для дейтинга — оператор вводит данные мужчин и женщин, их черты, а затем генерирует пары между ними при помощи изобретённого алгоритма. Позже программистка прошла ещё несколько курсов, например, изучала ассемблер (язык программирования).
Как же тогда кодили? Сначала рисовали блок-схемы, а затем писали карандашом код. Его передавали в отдел перфорирования, где код вбивали в перфокарты. Перфокарты состояли из 80 столбцов (72 под программу и 8 для последовательности), поэтому строка кода не могла содержать больше 72 символов.
Программисты должны были писать код чётко, чтобы работавшие на перфораторе женщины могли его читать. Спустя несколько лет работы в SJ им выделили человека для чтения кода. В остальном они по большей мере перфорировали карты данных: отчёты об отработанных часах в SJ, пробег каждого железнодорожного вагона (чтобы их можно было отправлять на обслуживание). Перфоратор выглядел как обычная печатная машинка, пробивающая отверстия с картах. Кроме того, над каждым столбцом она печатала обычным текстом букву.
«А ещё мы носили на перфокартах пирожные, так что они были довольно удобны»
Когда Марианна только начинала работу, программы были маленькими, но позже каждая могла занимать несколько коробок длиной по метру. Одна строка кода превращалась в одну перфокарту. Отдел перфорирования возвращал готовую программу (тысячи карт). Кроме того, приходилось создавать «контрольные карты», в которых кодировалось: должны ли перфокарты компилироваться или исполняться, на каком языке они были написаны и т.д. Контрольные карты имели собственный цвет. Первая карта была рабочей картой с именем на ней, чтобы отдел знал, кому их возвращать.
Еще карты возвращались вместе с «пижамной бумагой», содержащей списки кодов ошибок и номеров строк. У сотрудников был доступ к паре дыроколов, они могли вносить небольшие изменения самостоятельно.
Пижамная бумага с ошибками
Затем создавали тестовые файлы и смотрели, даёт ли программа ожидаемый результат. Если нет, то начинали «настольное тестирование» (с карандашом и бумагой), пытаясь разобраться, в чём ошибка. Для создания правильной программы требовалось много времени.
В машинном зале было примерно 10 операторов машин. Все они носили белые халаты, работали с ленточными накопителями, дисками и вставляли перфокарты. На входе висела табличка «Магазин закрыт», а программистам редко разрешалось посещать огромный машинный зал. Первые машины (IBM 1400) занимали 10-20 квадратных метров, а более новые были размером с холодильник.
Изначально у железнодорожной компании имелась IBM 360, а также более старые машины. Позже они получили IBM 370.
Ближе к концу 70-х появились терминалы. Все работали в общем зале с терминалами. Когда нужно было внести изменения в программу, приходилось сражаться за терминальное время. В компании пользовались жёлто-коричневыми терминалами Alfaskop. До самого увольнения из SJ в 1979 году у Марианны не было персонального терминала.
Alfaskop
Системные инженеры в основном работали со спецификациями, входными и выходными данными программ. Программисты были решателями задач, рисовали блок-схемы и думали, как выполнять задачи.
Какие коды писали? Например, онлайн-бронирование SG, работавшее 24/7. Это было современно по тем временам, а система целиком была написана на ассемблере. Благодаря этому SJ выделялась — ни одна другая компания в Швеции к этому и близко не стояла. Программисты создавали коды, а после завершения и тестирования отдавали их другим отделам. Их поддержкой занимались другие, отдел Марианны только писал новые.
В блоге Владимира Николаевича Орлова есть порядка 7 частей (и несколько отступлений) его автобиографичного рассказа о советском программировании. Дальше наш пересказ одного отрывка.
В 1976 году Владимир служил в Латвийском военном городе Вентспилс-8. Он был в числе первых, кто прошёл полный курс обучения по специальности «военный инженер-программист». Подготовка специалистов по ЭВМ и программированию велась с 1956 года.
Учились тогда прикладному программированию. Из студентов готовили IT-специалистов широкого профиля со знанием теории построения операционных систем, систем программирования, информационно-поисковых систем.
Обучение программированию начиналось с посещения машинного зала ЭВМ М-220.
За пультом ЭВМ М-220 старший лейтенант.
В те годы неотъемлемым атрибутом любого машинного зала (а для размещения ЭВМ М-220 требовалось не менее 100 квадратных метра) было присутствие в нем на стене портрета Джоконды (вспомните кинофильм «Служебный роман»):
Тогда Владимиру и другим обучающимся показали, как рождается портрет. В устройство для чтения перфокарт поставили колоду перфокарт, набрали команду на пульте управления ЭВМ и на АЦПУ стал появляться портрет Джоконды.
«Я окончательно понял, что поступил правильно, выбрав специальность программиста, а ЭВМ М-220 на ближайшие 7 лет стала моей рабочей лошадкой»
Это не означает, что Орлов не работал на других ЭВМ : к концу обучения в академии он был «на ты» с М-220, Минск-32, ЭВМ «Весна», СПЭМ-80, а также имел навыки работы на ЕС ЭВМ. Но главной машиной до 1979 года в Советском Союзе оставалась ЭВМ М-220.
Как тогда кодили? Программирование на М-220 серьёзно отличается от сегодняшнего программирования. Нужно обязательно знать машинные команды. Хотя бы те, которые позволяли загрузить программу с перфокарт, магнитных ленты и барабана в память машины и передать ей управление, чтобы она начала выполняться.
После Вентспилса я на всю жизнь запомнил команды ЭВМ М-220 для работы с внешними устройствами – 50 и 70. Все программы, которые я в итоге напишу в Вентспилсе, будут написаны в машинных кодах, никаких языков высокого уровня или даже автокода.
Одним из рабочих заданий была автоматизация кассы взаимопомощи.
Сначала информация по новым членам кассы взаимопомощи записывалась на бумажные бланки. С бланков данные набивались на перфокарты. Затем перфокарты вручную сортировались. Запускалась небольшая программа, которая данные с перфокарт записывала на магнитную ленту. После всего этого начинался процесс добавления новых членов в базу данных кассы взаимопомощи.
Для этого в лентопротяжки ставились три бобины, одна с новыми данными, вторая с данными, подготовленными ранее или текущей базой данных, и чистая, на которую переносилась информация, получаемая слиянием.
Неочевидное обучение программированию
Спустя 55 лет развития сферы программирования писать код можно даже не своими пальцами. Не работать на громоздких и медленных машинах, не запоминать команды. Можно и читерить: искусственный интеллект уже хорошо справляется со многими задачами. Вот модель GPT 4 — стандарт по умолчанию для создания контента, анализа, машинного перевода и, конечно, для решения задач.
GPT 4 можно использовать и для обучения программированию. Скормите чату условие своей задачки, а на выходе будет код программы на требуемом языке, часто еще и с объяснениями основных моментов в коде. Так можно создать себе персонального учителя.
Как можно использовать нейронку? Например, отправить в чат фрагмент или готовый код программы и промпт к нему:
расскажи, какую задачу решает код
объясни код по строкам
добавь комментарии в код
найди в коде синтаксические ошибки
найди в коде логические ошибки
оптимизируй код (уменьши расход памяти или ускорь выполнение)
уменьши сложность алгоритма
Не всегда, правда, код без глюков, а решения полные :( Главная проблема ИИ типа ChatGPT в том, что многие считают их универсальными. Из-за этого нередко либо результат не устраивает (завышенные ожидания), либо понимаешь, что проще и быстрее сделать самому.Чтобы апгрейднуть результат и сэкономить время, достаточно сделать очевидное: для каждой задачи использовать профильную нейронку.
В рамках API ограничения по получению ответа у GPT-4 составляет 4096 токенов, а у Claude 3 Opus около 128к токенов, в связи с этим и ответ получаемый от Claude 3 Opus будет больше. Плюс модели Claude 3 показывают себя более вдумчивыми.
Так мы справились с громоздкой задачей по программированию, сохранив себе пару часов для отдыха или другой задачи. Возьмем за пример задание из типовых курсов по программированию: написать мобильное приложение для сети клиник.
Возьмем эту задачу и декомпозируем ее. Разбить на более легкие шаги — это заведомо хорошая стратегия, чтобы нейронка не разваливалась и не отвлекалась.
У нас вышли такие шаги:
Составь функциональные требования, основанные на следующем описании: [полное описание из задания].
Теперь распиши полученные функциональные требования в виде User stories.
На основе полученных данных (Функциональных требований и user stories) составь сущности и атрибуты к ним с выделением первичных ключей.
Теперь на основе полученной информации составь plantUML.
Теперь составь BPMN TO-BE в виде кода.
Теперь составь полную спецификацию требований к этому ПО.
Теперь распиши каждый пункт спецификации подробнее, мне нужна готовая заполненная спецификация.
Составь документацию API с описанием всех методов системы на базе swagger.
И на все у Opus был ответ. Теперь проверим, исправим баги, если они есть — и готово! Конечно, не все так легко, как здесь читается, но работа над этими 8 пунктами своими руками была бы дольше в много-много раз.
Мы постарались сделать каждый город, с которого начинается еженедельный заед в нашей новой игре, по-настоящему уникальным. Оценить можно на странице совместной игры Torero и Пикабу.
С момента выхода первой части статьи из рубрики «сам себе экосистема» прошёл уже практически год! За это время, мы успели с вами реализовать клиенты VK и YouTube, которые работают на Android 2.2+, а также на Windows Phone 8, написать небольшую 2D-игру с нуля весом менее 1Мб, которая работает практически везде и довести существующее приложение до ума, дабы оно работало даже на смартфоне с дисплеем 240x320! Но на дворе 2024 год, люди стремительно переходят из соц. сетей в продвинутые мессенджеры и уже сложно себе представить современного человека, который не пользовался бы «телегой» или даже «вайбером» в качестве основного средства общения. Поэтому я решил реализовать клиент Telegram на смартфоне 14-летней давности на базе официальной реализации MTProto от команды Telegram — TDLib. Сегодня мы с вами: узнаем новые причины мотивации вернуть в строй смартфоны прошлых лет, напишем на C# реле-сервер, который обрабатывает пакеты MTProto и кодирует их в простой текстовый формат датасетов, который можно моментально обработать даже при нестабильном GPRS-соединении на 21-летнем Siemens C60, а также узнаем о разработке миниатюрных Android-приложений на базе «голого» API-системы, которые не тянут за собой никаких зависимостей, в том числе и AppCompat/androidx. Интересно? Тогда жду вас под катом!
На дворе уже стукнул 2024 год, современные смартфоны предлагают какие-то немыслимые мощности относительно тех, которые когда-то были в первых Android-девайсах. Сейчас за сотню баксов можно купить смартфон с хорошей 1080p IPS-матрицей, 4Гб ОЗУ и 8-ядерным шустрым чипсетом, который вполне способен плавно тянуть даже стремительно «жиреющие» на ресурсы клиенты социальных сетей, банков и прочие необходимые в повседневной жизни приложения. И казалось бы: всё хорошо, покупай себе редмик раз в год или айфон раз в несколько лет и наслаждайся всеми прелестями работы современных приложений…
Для многих людей смартфон — это лишь инструмент, повседневный компаньон, который помогает облегчить выполнение каких-то задач. Им совершенно не важно, как он выглядит, как ощущается в руках, какой у него дисплей и железо «под капотом», лишь бы работал да и нормально. Но есть и другая категория людей, для которых телефоны, смартфоны и любые портативные гаджеты — это не просто утилитарный девайс, а настоящее инженерное произведение искусства, с которого буквально сдувают пылинки и стараются до последнего пользоваться ими как повседневными устройствами. Хотите пример? Смотрите ниже:
Фактически, среди современных смартфонов по сути и нет представителей такого нынче вымершего форм-фактора, как сайдслайдеры с физической QWERTY-клавиатурой, боковые раскладушки с двумя дисплеями и даже из QWERTY-моноблоков есть только смартфоны от Unihertz. Даже среди моноблоков с тачскринами нет никакого разнообразия, лишь без-рамочные одинаковые девайсы за исключением устройств от Sony.
Galaxy S Plus
Раньше меня часто спрашивали, мол, да как ты вообще можешь пользоваться смартфоном 10-летней давности, на котором давно нет официальных клиентов популярных сервисов и только недавно, с развитием блога, мне перестали задавать этот вопрос, поняв, что это бесполезно — ведь это дело принципа и порыва энтузиазма! Смотрите сами: у нас уже есть простенькие, но вполне рабочие клиенты ВК, YouTube, сейчас я допиливаю клиент «Сбера» на СМСках, реализую карты OpenStreetMap (правда пока без адекватной навигации), а в будущем планирую написать приложение для мониторинга погоды и трекинга посылок. Кроме того, в рамках этой статьи мы реализуем с вами клиент Telegram: так чем же это не функционал современного смартфона?
Но хорошо, с функционалом разобрались, однако для многих читателей слова «старый смартфон» это прямые синонимы «тормозной смартфон», мол «фуу, да как можно пользоваться этим тормозным кирпичом, он же лагает в последней версии моей ВКшечки!». Но давайте поставим вопрос ребром: может, это не столько девайсы немощные, сколько сами приложения, с кодовой базой, которая тянется более 10 лет, откровенно жиреют, обрастают костылями и хаками после далеко не одного поколения программистов, которые над ними работали? :) Один, вот, предпочитал пользоваться чистым AppCompat'ом, другой решил притащить зависимость, которая, например, оптимизирует виртуализацию ListView, третий решил заменить всю сериализацию Json со встроенных классов в Android на что-то стороннее и реализовал это костылями и вот так, по чуть-чуть изначально оптимальный и шустрый код превращается в неповоротливое УГ, которое не рефакторили кучу лет.
На видео Galaxy Pocket Neo — очень дешёвый Android-смартфон из 2011 года с 1-ядерным чипсетом на ~800МГц и 256Мб ОЗУ. При этом всём, Android софтварно рисует все анимации на процессоре, без участия GPU.
А значит у стареньких девайсов всё равно есть шанс быть полезными и стать полноценными повседневными смартфонами даже спустя более чем десять лет после выхода! И в сегодняшнем материале, я вам расскажу об особенностях разработки самопального клиента Telegram с собственным прокси-сервером, которое концептуально допускает реализацию даже на кнопочном Siemens C60 2003 года. Как? Читаем ниже!
❯ Принцип работы
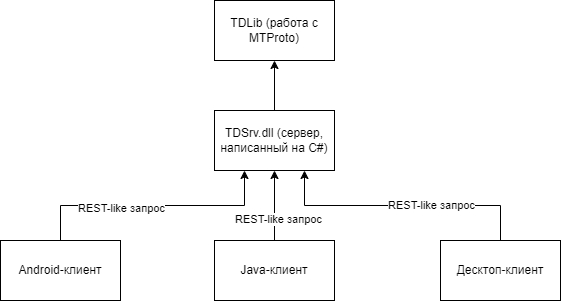
В отличии от ВК (который разрабатывали те же самые люди, что и Telegram), API которого построено на базе REST-запросов и концепции Longpolling'а для моментального получения событий с сервера, Telegram построен на базе собственного протокола под названием MTProto, который может работать поверх любого «транспорта» (протокола нижнего уровня) — TCP, HTTP, WebSocket и т.п. Сам по себе MTProto в современном виде, разработка прожженного математика Николая Дурова и его команды — протокол относительно сложный для реализации «на коленке» и в первую очередь требует довольно серьезного понимания принципов работы современной криптографии, да и документирован он всё ещё не особо хорошо. Кроме того, у MTProto весьма интересный бинарный формат пакетов, эдакий велосипед Protobuf. В долгосрочной перспективе поддерживать свой велосипед MTProto может быть весьма проблематично, учитывая не самую лучшую документацию.
Но городить велосипед и не нужно, поскольку у команды Telegram есть официальная реализация MTProto — библиотека TDLib, которая инкапсулирует в себе не только детали реализации протокола, но и сетевой ввод/вывод и выбор транспорта, хранение базы данных сообщений и авторизации, автоматическую загрузку фото и видео, конвертация объектов из бинарного формата MTProto в JSON и полная многопоточность и частичная потоко-безопасность. С одной стороны это плюс — уже готовое решение для реализации клиента на новой поддерживаемой платформе, где есть OpenSSL (можно статически слинковать), zlib (линкуется статически), сокеты и файловый ввод/вывод, а также довольно неплохой механизм JSON-based API, которое позволяет использовать библиотеку в любом языке, который поддерживает вызов C-функций, а с другой и минус — библиотека довольно много весит, в одиночку прибавляя ~20Мб веса приложения для каждой архитектуры, у неё течёт память и у нее странный механизм получения данных с сервера (например, нельзя ответить на сообщение, зная его ID, если сообщение предварительно не загружено, при том что на сервере весь ответ — это просто ID, на какое сообщение прилетел ответ).
Понятное дело, что на стареньком смартфоне использовать оригинальный TDLib будет проблематичным — даже если собрать либы современным NDK и запилить JNI-интерфейс, библиотека «жрёт» много ОЗУ (20-100Мб «вхолостую», в зависимости от числа диалогов и частоты прилетающих событий, плюс со временем течет до 1-2Гб, если не использовать базу данных сообщений. Скорее всего, это косяк в реализации пулов, объекты из которых выгружаются при сбросе в базу, но не выгружаются при высоком потреблении ОЗУ) и уж тем-более TDLib не запустить на любимых кнопочных Java-сонериках! Поэтому я решил написать прокси-сервер, который отправляет команды, слушает ивенты TDLib и предоставляет REST-like API для клиентских программ, которые просто вызывают какой-либо метод, а в ответ получают простой и короткий строковой датасет только с необходимыми полями, весом до 10Кб (что позволяет его быстро загрузить даже с GPRS-интернетом), который можно быстро распарсить даже на преусловутом Siemens C60!
К сожалению, поскольку TDLib прожорлив, я не смогу захостить на своём сервере инстансы для читателей, которые хотят поюзать приложение, поэтому вам придется ставить и запускать сервер на своём VDS/компьютере с белым IP/роутере, если под него есть .NET Core :)
Клиентом же будет выступать Android-смартфон, где приложение будет фронтэндом данных с сервера. Ничего сложного на первое время нет: первое окно — это список диалогов, второе окно — список сообщений в диалоге + поле для написания сообщения, третье окно — информация о пользователе. Всё это я реализовал за три дня не-напряжной работы «на коленке».
Давайте же перейдем к реализации сервера!
❯ Прокси-сервер
Сервер я решил писать на C#, поскольку у .NET Core сейчас всё очень хорошо с кроссплатформенностью и производительностью. Его можно даже на Raspberry Pi запустить :)
Итак, какая-же архитектура такого сервера может быть? Программа инициализирует TDLib, начинает слушать её события в отдельном потоке, пока в основном потоке крутится HTTP-сервер, который обрабатывает каждый отдельный запрос с клиентского приложения. Почему синхронно? Потому что TDLib фактически не возвращает никаких идентификаторов для возвращаемых датасетов, дабы их можно было отличить друг от друга. Приведу пример: у нас есть метод getChatHistory, который возвращает n-сообщений. При этом TDLib сам определяет, сколько хочет сообщений вернуть (и в первый вызов возвращает одно сообщение вне зависимости от настрое и отправляем пакет message n-раз. При этом в пакете message нет какого-либо ID, который позволял бы ассоциировать текущий объект с какой-либо операцией. Увы!
Начинаем с коммуникации с TDLib. Для работы с библиотекой, мы будем использовать json-интерфейс. Для .NET есть биндинги через C++/CLI, но в таком случае, сервер не будет работать на Linux. Для работы с библиотекой хватит лишь три функции: CreateClientID, которая аллокейтит новый инстанс клиента, Send, которая асинхронно отправляет JSON-объект с командой, которую затем обработает TDLib и Receive, которая ждёт N-секунд и возвращает в виде ASCII-строки (!) JSON-объект с описанием события или данными после одного из запросов. За это у нас отвечает класс TDLibInterface, который объявляет PInvoke-методы для вызова нативных методов из библиотеки. .NET Core сам подгрузит библиотеку tdjson (причём на Linux он добавит ей префикс а-ля libtdjson.so, а на Windows загрузит tdjson.dll) и сам разберется с маршаллингом аргументов функций: например, string автоматически преобразует в const char*. Тем не менее, с const char* возвратами нужно быть аккуратнее — у меня был SIGSEGV, пока я ручками не конвертировал их в обычную строку.
З.Ы: На Пикабу нет отдельного тега для кода, а вставить листинги картинками я не могу из-за ограничения на 25 медиаэлементов. Так что листинги будут совсем без табов, но алгоритм их работы понять можно :)
Позволю себе чуточку критики в сторону TDLib. Во первых, почему нет s-версии функции с возможностью указать длину входной строки, а tdjson полагается исключительно на \0 в конце строки? Во вторых, почему const char*, а не wchar_t*? Сейчас юникод во входной строке приходится escape'ами превращать в \u-последовательности. После этого, нам нужно написать обёртку над TDLib, которая будет вызывать для зарегистрированных событий специальные функции, называемые коллбэками. При этом закомментированный WriteLine снизу — это «дебаг» для того, чтобы узнать названия неизвестных мне ивентов :)
В каждом объекте, полученном с помощью receive, есть поле "@type", которое содержит в себе имя класса возвращаемого объекта. Первый же вопрос от читателей — почему я использую JObject с ручным дерганьем нужных полей и вручную пишу JSON в виде строковых литералов вместо нормальной сериализации/десериализации? Ответ прост: во-первых, для актуализации Data-классов придется писать кодогенератор из TL-схемы, а во-вторых иногда TDLib может возвращать немного разные объекты в JSON, из-за чего приходится мудрить с атрибутами на этих самых Data-классах, иначе десериализатор выбросит исключение. Это решается нормальными юнит-тестами на всех вариантах данных, но зачем себе в колени стрелять, если нужен конкретный фиксированный функционал и лишь малое число от всех полей, возвращаемых TDLib?
string recv = NativeInterface.Receive(10.0d);
if (recv != null) { JObject json = JObject.Parse(recv);
if (!handlers.ContainsKey(type)) { //Console.WriteLine("Unknown event type: {0}", type); continue; }
handlers[type](recv, json); }
Теперь переходим к самому интересному — обработке событий и реализации синхронного клиента, который позволяет без async/await просто запросить список сообщений и сразу же его получить (такой подход может быть полезен и юзерботам, которые не хотят размазывать стейты по всей программе). Почему без асинков? Честно сказать, мне они просто не нравятся: как привык к концепции wait/notify и коллбэков из Java, так их и юзаю всю жизнь :)
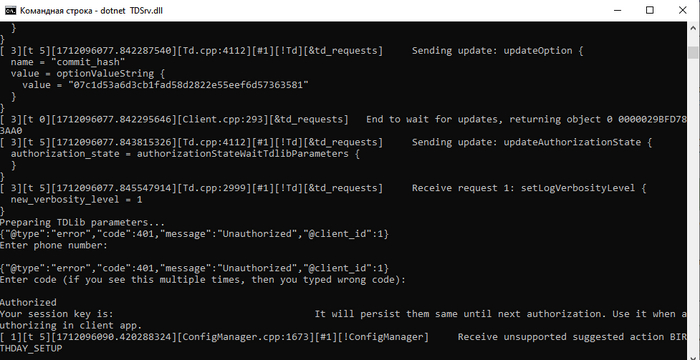
Сначала TDLib запрашивает параметры инициализации (стейт authorizationStateWaitTdlibParameters), затем если пользователь не авторизован — запрашивает номер телефона и код подтверждения (плюс дополнительные шаги для авторизации если они есть). В конце, TDLib возвращает стейт Ready, что означает готовность библиотеки к работе:
После этого, можно начать работу с данными. Обратите внимание, мой подход потоко-небезопасен, его нельзя дергать из нескольких потоков одновременно! В коде ниже, я вызываю метод для фетча сообщений, а затем в соответствующем коллбэке от TDLib обрабатываю данные (дабы статья не разрасталась на 20+ минут, я чуть урезал все листинги).
public List<Message> QueryMessagesInChat(long chatId, long lastMessage, int count) { messages.Clear();
public User QueryUser(long userId) { string json = Utils.Format("{\"@type\": \"getUser\", \"user_id\": \"{0}\" }", userId); NativeInterface.Send(InstanceID, json);
waitHandle.WaitOne(); return user; }
Переходим к реализации самого сервера, для наших целей хватит обычного HttpListener. Сначала мы зарегистрируем все поддерживаемые методы и занесем их в ассоциативный список ключ-значение. Сами методы реализованы в виде делегатов, которые принимают лишь один аргумент — список параметров из строки запроса, а возвращают строку — все ответы, за исключением особых (связанных с загрузкой вложений) — текстовые.
Переходим к обработке запроса. Метод ищет, зарегистрирован ли запрошенный метод и если да, то парсит строку запроса, которая начинается с "?", которую затем передаёт в виде коллекции ключ->значения обработчику метода:
А сами методы, в свою очередь, дергают соответствующие функции из клиента и формируют на их основе датасет в примитивном формате:
public staticstring QueryChats(Dictionary<string, string> args) { if(args.ContainsKey("count")) { int count = int.Parse(args["count"]); StringBuilder ret = new StringBuilder();
В результате получаем вот такой простой датасет, который, как я и говорил, легко распарсить и на Siemens C60, и на Atmega328 — да где угодно! В целом, такой сервер можно использовать для реализации бота в телеграме, который будет передавать показания каких-то датчиков, сигнализацию и прочие клевые штуки!
Переходим к реализации клиента, т.е. приложения на Android. Здесь будет не менее интересно!
❯ Пилим для Android
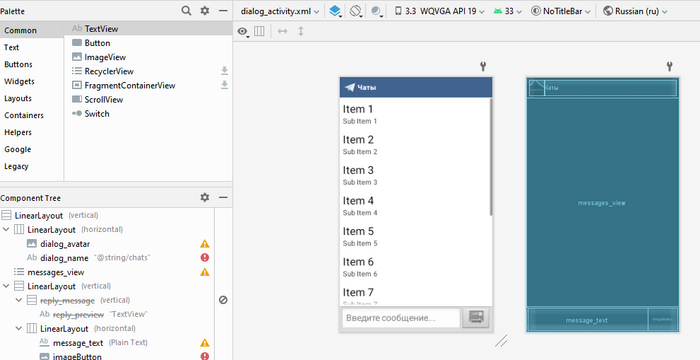
В геймдеве есть своеобразный мем — некоторые инди-разработчики сначала начинают делать меню, вместо основного геймплея, что становится предметом насмешек среди других разработчиков. Но в разработке приложений для смартфонов всё по другому — здесь как-раз таки хорошо заранее продумывать макет будущего приложения!
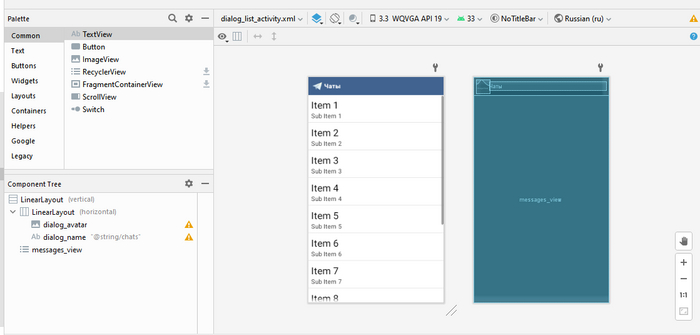
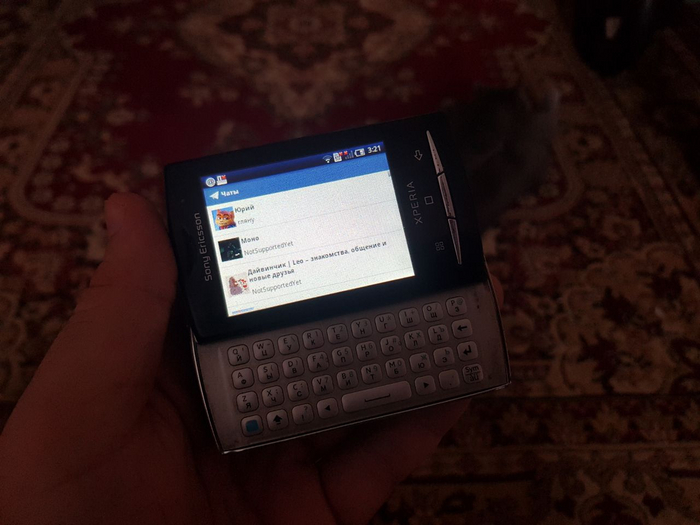
Поскольку у нас с вами мессенджер, то главный экран должен представлять из себя список чатов (ListView) и верхнюю панельку, где в будущем могут разместиться настройки и свайп-менюшка:
Такой вот простой макет.
Каждый пункт меню — это тоже отдельный layout, в котором мы по шаблону строим внешний вид будущего элемента списка. На немолодых устройствах есть смысл использовать как можно меньше контейнеров в layout'е, поскольку пересчет позиций и размеров элементов — одна из самых «тяжелых» операций в UI-фреймворке вообще. Кроме того, не стоит использовать кучу картинок и drawable — в Android 2.x всё 2D рисуется софтварно, аппаратное ускорение появилось только в 3.0 (частично).
Но дабы в списке диалогов что-то появилось, нужно сначала реализовать фетчинг (получение) этих самых диалогов с сервера! Сам объект, который занимается обработкой запросов называется ClientManager и является синглтоном — он в единственном экземпляре на все время работы программы. Помимо менеджмента «ноды» (т.е. прокси-сервера), токена для авторизации и обработчика ошибок, ClientManager реализует метод для асинхронного запроса информации с сервера и, собственно, формирует строки запросов с помощью соответствующих методов:
Подгрузка чатов и сообщений реализована через Adapter — концепция «виртуальных» списков, которая предполагает что система создаст не 50 элементов интерфейса на каждую кнопку чата, а только 5 и будет их виртуально «мотать по кругу», обновляя только данные в уже существующих элементах. Это позволяет значительно ускорить отрисовку, учитывая то, что Android 2.x Canvas рисуется программно.
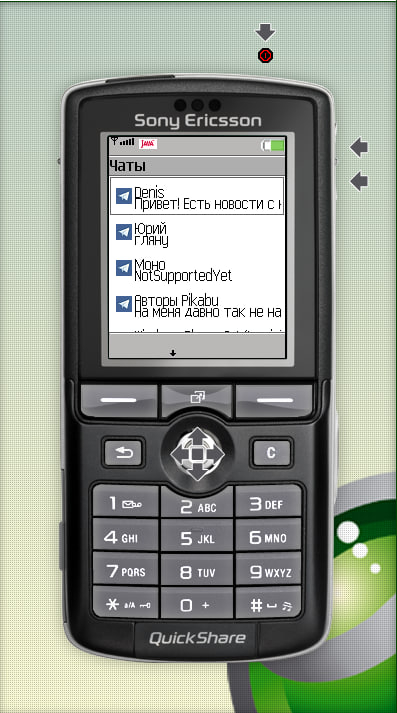
Ну вы уже явно замучились видеть простыни кода, давайте посмотрим что у нас вышло!
Шустренько, да? А ведь это ультрабюджетник Alcatel OT-916D, один из последних массовых дешевых QWERTY-смартфонов за 5 000 рублей из 2012 года. Кстати, смартфон подарил мне читатель chuvakoff с Хабра!
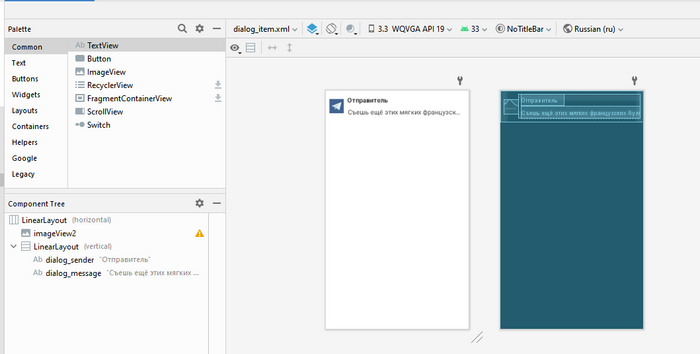
Переходим к окну чата. Основной макет почти такой-же, как и у основного окна: только добавилась панелька для ввода сообщения снизу.
Концептуально, всё тоже самое — запрашиваем данные с сервера, парсим их и загружаем в адаптер, благодаря чему мы сможем листать наш диалог. Однако в сообщения я добавил контекстное меню с стандартными фишками типа копирования, ответа и прочих подобных действий. Поскольку у нас нет ни пушей, ни еще каких-либо средств для поулчения данных о новых сообщениях, я раз в определенный интервал просто получаю сообщения — и если новый датасет отличается от старого — обновляю окошко чата.
Переходим к реализации поля для ввода сообщения. Здесь всё просто — на серверсайде за это отвечает метод SendMessage. Однако для того, чтобы с нашего клиента можно было ответить на другие сообщения, я ввёл также «контекст ответа», в котором запоминается сообщение, на которое мы хотим ответить. Telegram также поддерживает Markdown, однако его полная поддержка пока не реализована.
В остальном же, функционал конечно пока совсем базовый, однако клиент работает очень шустро даже бюджетной X10 Mini Pro и позволяет чатится с моими читателями в Telegram. В будущем хотелось бы допилить:
Поддержка картинок: Сейчас уже есть кривоватый механизм кэширования изображений на стороне сервера, который позволяет загружать аватарки чатов. В будущем, я добавлю поддержку «галерей» с картинками!
Поддержка голосовых сообщений: Не все их любят, но они порой удобны и выручают. Реализую как прослушивание, так и запись!
Подробный просмотр профилей и менеджмент чатов: Удаление сообщений, чатов и прочие фишечки из официальных клиентов.
Казалось бы — до официальных клиентов ещё очень далеко. Но сам факт, чтобы всё это работало достаточно шустро на девайсах, которым уже более 10 лет!
❯ Звучит интересно! Как заюзать твой клиент?
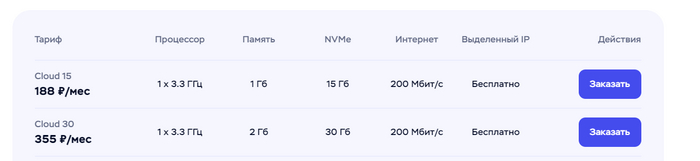
Тут всё очень и очень просто! В первую очередь, нам понадобится ПК с белым IP, роутер (если под него есть сборка dotnet), либо VDS. Виртуальные сервера сейчас стоят копейки, у ТаймВеба есть тариф за 188 рублей в месяц, которого с головой хватит для нашего сервера.
Такая вот рекламная интеграция (к слову, прокси для всех приложений уже более года крутятся именно на мощностях TimeWeb Cloud)!
Программа сначала запросит номер телефона, а затем код подтверждения Telegram. После этого будет создана папка tdlib/, где будут хранится данные вашей сессии, а также файл authkey.txt, где хранится случайный ключ для сессии (md5 phone_number + response code + псевдослучайное число). Не оставляйте его в /var/www/!
Если всё нормально, программа начнёт слушать порт 13377 на всех сетевых интерфейсах, в т.ч и в локальной сети. После этого, ставим уже предварительно собранный, либо собираем сами в Android Studio APK и в окне авторизации пишем адрес ноды и ключ авторизации. Если всё настроено верно — программа запомнит сервер и будет работать без проблем! Вот так всё легко :) Как видите — всё очень и очень просто!
Кроме того, буквально за пару дней до публикации статьи я сел вечерком из интереса что-нить под Java-телефоны попилить… и, как и обещал, реализовал Proof of Concept возможности работы Telegram даже на сонериках, которым скоро 20 лет стукнет! А ведь если ещё чуть заморочится, можно запустить приложение даже на преусловутых монохромных сименсах!
❯ Заключение
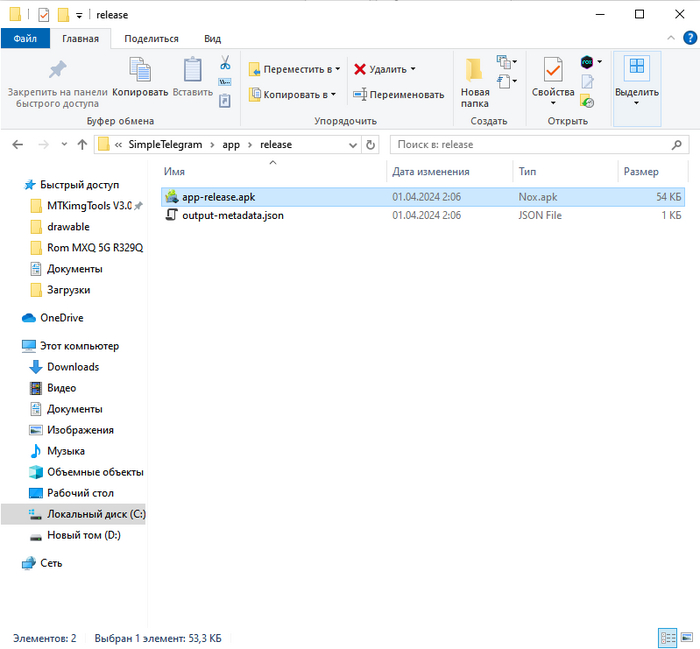
Вот такой у нас получился проект с реализацией лёгкого, примитивного, но тем не менее рабочего клиента Telegram, который на клиентской части вообще не использует никаких зависимостей. Вес собранного APK в release-версии — всего 54 килобайта! Понятное дело что с ростом функционала, вес программы будет увеличиваться, но я обещаю — больше 1Мб он не вырастет :)
Ну а вам, моим читателям, надеюсь было интересно прочитать такой «двойной материал» не только о разработке сетевой части без использования Apache/nginx/IIS, но и UI-фронтэнда для Android-смартфонов, которым уже более 10 лет! Исходный код проекта можно найти на моём GitHub: как приложения, так и сервера, а также убедиться в отсутствии каких либо закладок и, если совсем не доверяете, собрать бинарники сами! Для сборки понадобится VS2017 или свежее, а также Android Studio 2.3.2 (если собираете для Android 2.1 и ниже).
Друзья! Сейчас на Хабре опросы сломаны, поэтому если у вас есть желание, вы можете проголосовать в комментариях: какой стиль статей вам больше нравится — где больше конкретики и кода с пояснением как конкретно работает та или иная часть программы, или наоборот стиль ближе к научпопу, где фрагментов кода нет, или их значительно меньше? Пишите своё мнение о проекте в комментариях!
Кроме того, у меня есть канал в Telegram, куда я публикую бэкстейдж статей, ссылки на новый материал, свои наработки, а также посты о ремонте девайсов и различные мысли.
Статья подготовлена при поддержке TimeWeb Cloud. Подписывайтесь на меня и @Timeweb.Cloud, чтобы не пропускать новые статьи каждую неделю!
«Получается твоя работа - писать текст, используя рандомные английские слова и символы причудливых цветов? Не знаю, почему тебе за это хорошо платят. Этот текст даже нормально не выровнен по левому краю»