Нейросети уже настолько хороши, что сами устраиваются на работу. Так почему бы им не замолвить за вас словечко? Они напишут вам резюме, сопроводительное и подготовят к собеседованию.
kickresume — мощный сервис на основе GPT-3 сможет соорудить для вас как резюме, так и сопроводительное письмо. Попробовать тут.
Сover Letter AI — составит сопроводительное на основе вашего резюме. Попробовать тут.
InterviewGPT AI — имитирует разговор на собеседовании, поможет подготовиться. Попробовать тут.
Resume Worded — просканирует ваше резюме и профиль на LinkedIn и посоветует, как его прокачать. Попробовать тут.
Interview Warmup — разогреет айтишников, дизайнеров и проджект-менеджеров перед собеседованием, задав вопросы о специальности и выборе работы. Попробовать тут.
EditGPT — исправит грамматические ошибки в резюме на английском. Попробовать тут.
И не забывайте про базовую ChatGPT — при нужном запросе она сможет имитировать собеседование, улучшит резюме и восполнит пробелы в знаниях. Ссылка тут.
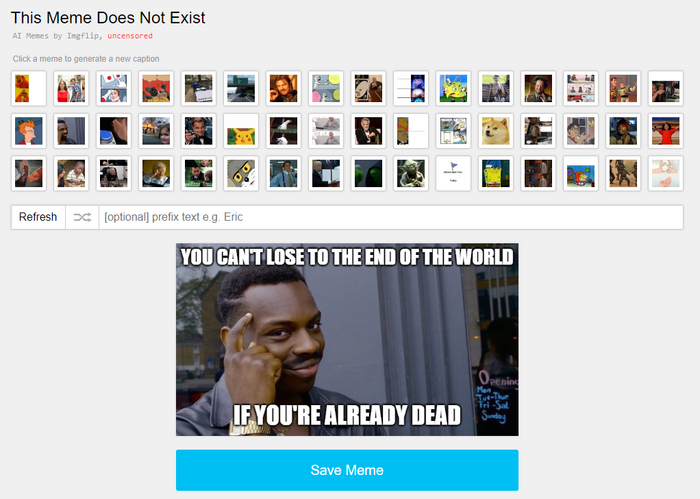
Создатель хостинга imgflip Дилан Уэнзлу натренировал искусственный интеллект на создание мемов и назвал генератор This Mem Does Not Exist («Этого мема не существует»).
Генератор работает следующим образом: нужно выбрать картинку из популярного мема, а алгоритм придумает к ней смешную, по его мнению, подпись. Получившийся мем можно сохранить себе на память.
Иногда вам может потребоваться преобразовать растровые изображения в векторные, и Vectorizer.AI - идеальный инструмент для этой задачи. Это приложение предоставляет бесплатный доступ во время бета-тестирования и не требует VPN.
1. Преобразование Растровых Изображений в Векторы:Vectorizer.AI позволяет вам быстро и легко конвертировать растровые изображения в векторные форматы, такие как SVG. Это открывает новые возможности для редактирования и использования ваших изображений.
2. Простота и Удобство: Использование Vectorizer.AI просто и удобно. Вам нужно всего лишь загрузить свое растровое изображение в приложение, и оно автоматически выполнит конвертацию в вектор.
3. Бесплатно во время бета-тестирования:Vectorizer.AI доступен бесплатно во время бета-тестирования, что делает его доступным для всех желающих.
Vectorizer.AI - это мощный инструмент для тех, кто работает с изображениями и хочет получить больше возможностей для их редактирования и использования. Преобразуйте ваши растровые изображения в векторы быстро и легко с этим удобным онлайн-инструментом.
Кстати, мы сделали бесплатного тг-бота для генерации изображений и бесплатный гайд по генерациям изображений - ПОПРОБУЙТЕ
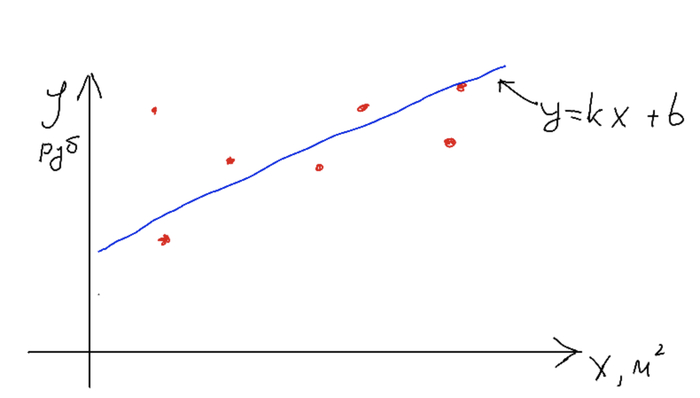
Простите поклонники лучика, но не мог пройти мимо. Я не буду разбирать каждый абзац этой статьи и комментировать его, только в конце приведу цитаты и свои комментарии к ним. На мой взгляд статья очень размыто отвечает на главный вопрос, поставленный в заголовке: как работает нейросеть? Я не в курсе на какую возрастную аудиторию рассчитан материал, но с учетом того, что в статье приведена функция y = kx + b, полагаю, я могу использовать немного математики.
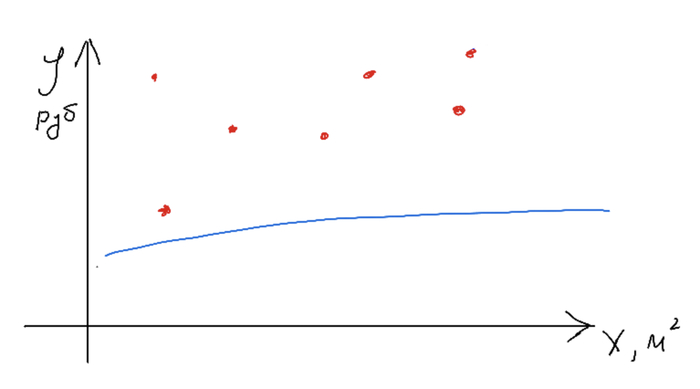
Авторы предлагают аналогию вроде такой: нейросеть - это набор нейронов-чисел, а учатся они, если им показать много примеров. Прежде чем переходить к нейронам, я расскажу как они учатся. Это может показаться странным, но просто принцип обучения что в нейросетях, что в простых моделях машинного обучения одинаков. Для примера рассмотрим как раз уже приведенную функцию y = kx + b. Перенося ее на реальный мир можно взять в качестве примера задачу расчета стоимости жилья в зависимости от площади квартиры. Тогда y - стоимость, x - площадь квартиры, а решаем мы задачу т.н. линейной регрессии (это для сильных духом, постараюсь обходиться без терминов). Далее слайды, которые рисовал сам, простите.
Нужно получить модель, которая по набору иксов (метраж квартиры) дает правдоподобную стоимость. Точки на графике - наши реально существующие данные. Прямая - наша функция. Обучив модель, мы можем подать ей на вход один x и получить ожидаемый y.
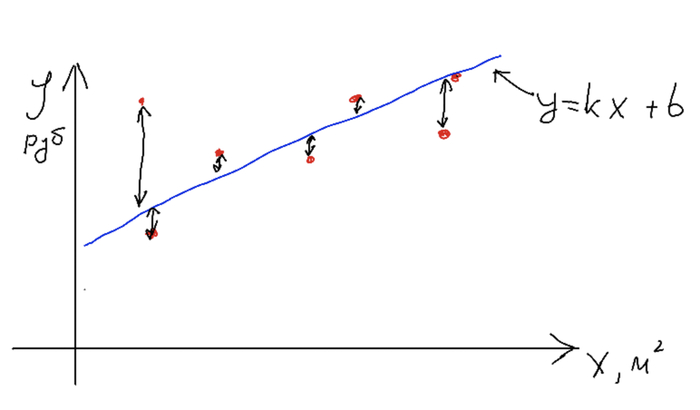
В случае применения машинного обучения мы должны просто настроить неизвестные параметры нашей функции (k и b), чтобы получить оптимальную прямую. Главный вопрос - как? Для этого мы должны ввести понятие ошибки модели, чтобы понять, хороши ли она выполняет свою задачу. В нашем примере ошибка - это разность между предсказаниями и реальной стоимостью.
Ошибка модели - средняя разность между реальными значениями и предсказанными по модулю или в квадрате. Формальным языком: L = (y' - y)^2 / n, где n - количество примеров в данных, y' - предсказания, а y - реальные значения y для наших x).
Назовем функцию вычисления ошибок функцией потерь (точнее, она так и называется). Оптимальная модель будет выдавать минимальную среднюю разность, т.е. значение функции потерь будет минимальным. С оценкой определились, теперь переходим к процессу обучения. Для этого мы строим одну случайную прямую, считаем разность между предсказаниями и данными, определяем в какую сторону нам нужно сдвинуть нашу прямую, и сдвигаем, меняя наши k и b на небольшое значение. На какое - задается параметрами модели, обычно этот шаг небольшой, чтобы не перескочить наше оптимальное положение.
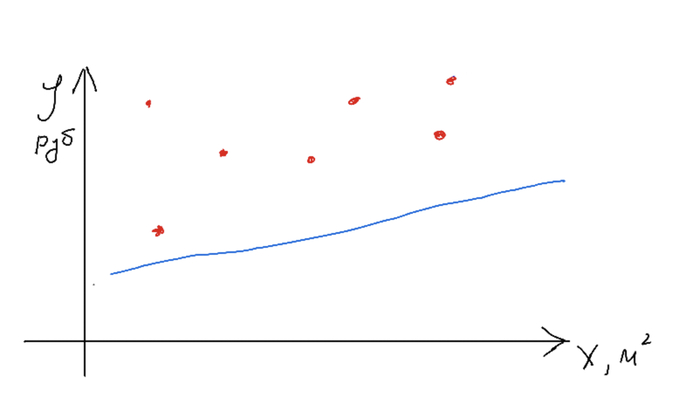
Случайная прямая
Один шаг обучения
Второй шаг обучения ( и так далее)
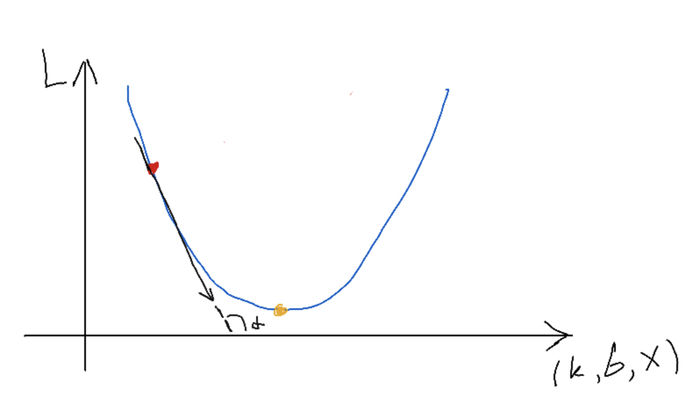
Небольшое отступление, которое можно пропустить. Пытливый ум спросит меня, а как мы определяем в какую сторону двигаться на каждом шаге? Отвечаю - просто смотрим на знак. Раньше я упомянул, что для расчета мы используем квадрат или модуль разностей для каждого отдельно взятого примера и усредняем их. Но тогда все наши расчеты будут положительными. Трюк в том, что при обучении мы используем не саму функцию потерь, а производную от нее или т.н. градиент (блин, обещал же без терминов). Геометрически производную можно изобразить так:
Производная - это тангенс угла наклона касательной к функции потерь в выбранной точке. Производная показывает направление роста функции.
На графике изображена функция потерь при разных значениях для нашей задачи - это парабола. Причем левая ветвь соответствует ситуации, когда мы задаем случайную прямую ниже наших точек, правая - выше. Наша задача попасть из красной точки в желтую, т.е. в минимум функции. Определив градиент, мы двигаемся в сторону уменьшения функции, достигая минимума. Математически, при расчете производной (dL = (2 / n) * (y' - y) * x) мы избавляемся от квадрата и можем получать отрицательные значения (и получаем в нашем примере) и тогда двигаемся в противоположную от знака сторону, прибавляя небольшие значения к нашим коэффициентам k и b.
Возвращаясь к объяснению на пальцах. В реальной жизни параметров, влияющих на стоимость квартиры больше, чем просто ее метраж. Тогда мы переходим в многомерное пространство. В реальной жизни у нас есть другие задачи, например то же отделение фотографий кошек от фотографий собак (задача классификации). Или генерация изображений. Но во всех этих задачах используется один и тот же принцип: мы должны определить функцию потерь - определить как мы вычисляем ошибки предсказаний модели и посчитать разницу между предсказаниями и реальными значениями и изменить значения коэффициентов, в зависимости от смещения предсказаний. Для задачи классификации животных (кошек и собак) мы на самом деле строим точно такую же прямую, просто эта прямая не проходит через точки в пространстве, а старается разделить их. Точками в этом случае могут выступать значения пикселей наших картинок, в таком случае, для обычного изображения кошечки, например, разрешением 512х512, мы работаем в 786432-мерном пространстве (потому что 3 (если используем цветное изображение RGB) * 512 * 512 = 786432) и подбираем в этом пространстве не прямую, а плоскость. И уравнение этой плоскости будет таким y = b + k1 * x1 + k2 * x2 + ... + k786432 * x786432. А функция потерь будет другая, но об этом я уже не буду говорить.
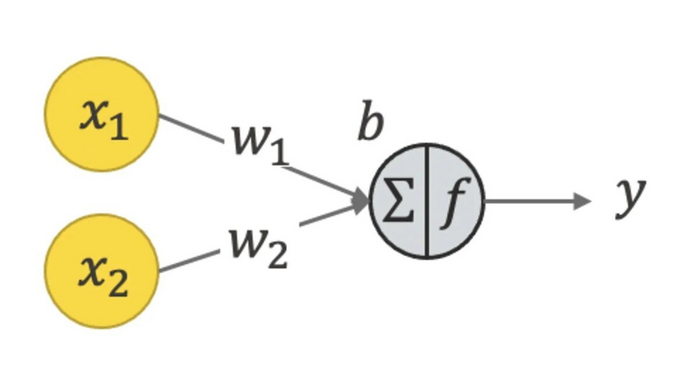
Теперь, когда мы поняли как мы учим, можно понять, что такое нейрон в нейросетях. На самом деле, ответ уже понятен. В процессе обучения мы настраиваем коэффициенты некой функции, нейрон тогда - это просто математическая функция от входных данных. Возвращаясь к статье лучика, на этой картинке нейрон - это как раз таки серый кружочек. А желтые - это значения входных данных. Они могут быть в то же время выходными данными с нейронов предыдущего слоя нейросети.
x1, x2 - значения входных данных, w1, w2, b - коэффициенты (я использовал выше k и b)
А сколько нейронов в нейросети? Много и зависит от архитектуры. Входной слой просто принимает данные и вычисляет взвешенную сумму, передавая результат на внутренние слои. На примере тех же изображений - количество нейронов на первом слое будет зависеть от параметров изображения, а именно от количества пикселей, но количество нейронов скрытых (внутренних) слоев мы устанавливаем сами. Мы можем поставить один нейрон на первый скрытый слой, который будет суммировать все данные, но толку от такой сети будет мало. На выходном слое количество нейронов зависит от нашей задачи. Для генерации нам нужно в каждом пикселе сетки предсказать реальное значение цвета, значит нейронов будет столько же, сколько пикселей нам надо получить. Если мы говорим о задаче классификации, то на выходном слое будет столько нейронов, сколько у нас классов - т.е. 2 для кошек/собак, например. Рассматривать необычные слои, вроде сверток, не будем, но они есть.
А зачем вообще нужны нейросети? Я уже выше описал, что все задачи так или иначе формализуются в набор известных функций. Но преимущество нейросетей в том, что они универсальны как раз за счет общих принципов построения. А взаимодействие нейронов на разных слоях позволяет расширить пространство настраиваемых параметров, что в свою очередь позволяет уловить связи в данных на разных уровнях. Например, разные слои нейросети, обученной на задаче классификации изображений, могут улавливать разные паттерны: например контуры, формы или цвета. Что как раз-таки используется для передачи стиля - мы замораживаем глубинные веса обученной нейросети (те, которые отвечают за пространство, форму и т.д.) и дообучаем на одном стилевом изображении только те слои, которые отвечают за "мазки кисти" и цвета.
Несколько примеров современных нейросетей и как они обучены:
Генерация изображений. Существует множество архитектур сетей для генерации. Причем я говорю о генерации без текстового описания. Например, т.н. GAN-ы. Они обучены генерировать изображения из шума, как и сказано в статье. Но они не обучаются специально запоминать формы, объемы, углы, цвета. Они обучаются генерировать изображение так, чтобы результат не отличался от данных, с которыми мы его сравниваем.
Векторизация текстов - я выделил этот пункт отдельно, т.к. все сети, работающие с текстами, должны уметь переходить от тестов к точкам в пространстве - векторам чисел. Описывать, как это происходит примерно так же долго, как я описывал линейную регрессию. Но для простоты скажем, что нейросети учатся предсказывать пропущенные в тексте слова, настраивая при этом числа в пространстве векторов, где каждый вектор соответствует отдельному слову. Это классическая задача классификации, а значит мы снова строим разделяющие плоскости.
Генерация текстов. И снова множество архитектур. Есть даже не нейросетевые (смотрите цепи Маркова, которые просто считают попарные вероятности слов в тексте). Нейросетевые пытаются предсказать одно следующее слово на основе предыдущих.
Генерация изображений по тексту. Здесь мы объединяем известные подходы и идея такая: раз мы уже знаем, как векторизовать текст, то будем использовать вектора текста как входные данные, а готовые изображения, как идеал, который нужно научится генерировать из шума. Для обучения таких моделей используется огромное количество картинок с описаниями к ним. Кстати, поэтому было много претензий к русскоязычным генеративным моделям, которые генерировали, например, американские флаги по запросу "Родина". Просто сложно создать большой датасет размеченных изображений своими силами, все используют открытые датасеты, и, например, переводят тексты и всячески обогащают данные.
Теперь можно перейти к самому интересному - цитаты из статьи.
Компьютерный нейрон – это просто... число!
Уже выяснили, что нет.
«А если собаки и кошки раскиданы вперемешку, а?» – спросите вы. Ну что ж, тогда нам может потребоваться не одна линия. И возможно не две и не три, а целый десяток или даже сотня. Важно понять, что рано или поздно мы сможем с помощью обыкновенных чисел и прямых «поделить» наш лист так, чтобы нейросеть уже знала наверняка – что именно она «видит», кошку или собаку, в чью именно область она «ткнула пальцем».
Я зацепился за это определение. Потому что если нам известно только 2 класса, то будет только одна "линия" на выходе. Да, каждый нейрон строит свое собственное решение, но он во-первых, не видит какую-то свою область данных, а во-вторых, его решение агрегируется с решениями всех остальных нейронов на выходном слое. То, что описано - это скорее работа классических деревьев решений, которые действительно нарезают пространство на сколько угодно областей.
Проблема номер один – для обучения нейросети нужно очень много информации. Чтобы научить нейросеть отличать кошку от собаки, ей нужно показать тысячи (лучше миллионы) самых разных кошек и собак. Воспитанник детского садика в возрасте трёх лет кошку с собакой не спутает, даже если видел их всего лишь пару раз в жизни...
С миллионом явный перебор. Кроме того, существуют техники дообучения, позволяющие переиспользовать обученные модели с гораздо меньшим набором данных.
Проблема номер два: нейросети совершенно не умеют анализировать собственные творения, объяснять, «что здесь нарисовано и почему», в частности, они не умеют считать! Из-за этого компьютерные изображения постоянно рисуют людей то с шестью, то с восемью пальцами. Или кошек то с тремя, то с пятью лапами.
Вообще-то, объяснять уже умеют. Но только узкий класс мультимодальных сетей (если мы обучим модель генерировать текст по изображению - обратная задача генерации изображения по тексту - то сможет). А с пальцами проблема в общем тоже пофикшена улучшениями архитектур и увеличением количества параметров моделей. Были бы деньги обучать такие модели.
Проблема номер четыре: нейросеть не умеет работать при нехватке информации, «достраивать недостающее». Скажем, человеческий детёныш, даже малыш, увидев кошачий хвост, торчащий из-под дивана, тут же уверенно «распознает» спрятавшегося котёнка и побежит ловить его! Нейросеть такое «неполное» изображение понять не в состоянии. Человек, исказивший внешность (скажем, надевший маску или загримированный) для современной нейросети опять же становится неузнаваемым.
Умеет и достраивает. И распознает и людей в масках узнает. Опять же, на это влияют как архитектура, так и способ получения данных. Всегда можно аугментировать изображения (например в части тренировочных изображений кошек и собак обрезать все, кроме хвостов и тогда такая нейросеть сможет по хвосту определить животное).
Проблема номер пять: нейросеть совершенно не понимает законов нашего мира – скажем, тех же законов оптики. Она никогда не сможет различить на картине человека – и его отражение в зеркале (для живого человека – задачка пустяковая). Она никогда не сможет различить человека или его лицо в кривом зеркале (как это делаем мы на аттракционе «Комната смеха» в городском парке, или когда разглядываем самих себя в новогодние шарики).
Аналогично - аугментация данных решает проблемы с кривыми зеркалами.
Проблема номер шесть: нейросети чрезвычайно чувствительны к разного рода помехам, дефектам, «шуму». Скажем, если на старой фотографии часть изображения залита грязью, чернилами, испорчена пятнами или царапинами, сильно выцвела, если карточка разорвана или разрезана напополам – уверенное узнавание тут же становится неуверенным и вообще ошибочным. Для человека сломанная на части кукла – всё равно кукла; для нейросети – это уже совершенно другой, неизвестный объект
Формально - да. Именно поэтому при обучении специально добавляют шум, аугментируют данные, выключают часть нейронов. И тогда модель справляется.
Проблема номер семь: нейросети на текущий момент ужасающе «однопрограммны». Если нейросеть настроена на распознавание лиц – она будет уметь только распознавать лица. Переучить её на написание текстов или музыки будет чрезвычайно сложно, часто вообще проще написать и обучить совершенно новую сеть. Если она умеет отличать квадраты от треугольников – даже не пробуйте попросить её отличить кошку от собаки или самолёт от парусной лодки...
В целом верно, но не совсем. В рамках одной моды и архитектуры - работа с текстом, или изображениями, или музыкой - переучить нейросеть не проблема. И даже мультимодальные модели существуют и активно развиваются. Но да, архитектура генератора музыки и генератора изображений и данные для этих сетей настолько разные, что просто в тупую подменить данные нельзя. Удивительно.
Проблема номер восемь: связи между компьютерными нейронами случайны, поэтому нейросети лишены запоминания созданных образов. На приказ «нарисуй мне дерево» нейросеть охотно откликнется и будет рисовать деревья снова и снова, но... каждый раз это будет «другое дерево». И если вы напишете команду «нарисуй мне такое же дерево, как в прошлый раз, только на берегу реки», нейронная сеть не поймёт вас. Она опять нарисует «новое случайное дерево».
Связывать случайность (кстати, они не случайны, а заданы архитектурой) связей между нейронами и неспособность запоминать созданный образ - максимально некорректно. То, что здесь описано, на самом деле решаемо. Но это решение за пределами архитектуры нейросети. Это как предъявлять претензии микроволновке, за то, что она не включила сама кнопку, типа, могла бы и запомнить. У нее нет инструментов запоминания результата, как нет у голой нейросети - она получает данные на вход, генерирует выход и все.
В целом, я догадываюсь, что изначальная статья была рассчитана на детей младшего школьного возраста. И я по размышлению выкинул из моего разбора несколько цитат, которые на самом деле оказались верны, просто сильно упрощают представление. И то, что я описал может быть не всем понятно и требует более глубокого погружения.
Предыдущие мои посты привлекли внимание к этой нейросети, а у меня появилось аж 10 подписчиков, поэтому продолжим обсуждения. Один из самых частых вопросов в комментах - какие описания я использую для своих "картин". Поэтому этот пост будет построен по принципу - вот вам полный запрос, вот результат. Предупреждаю сразу - даже скопировав запрос, у вас не будет точно такого же результата, сеть сгенерирует другой вариант, но, возможно, часть картинок будет похожа, ибо первоначально рендерится сразу 4 варианта, а вы уже выбираете, какой из них улучшать дальше. И да, все запросы должны в начале содержать /imagine promt, но в самих запросах я их не указал.
И вот, у вас первые 4 картинки в так себе качестве, мало деталей, мутноватые. Дальше можно выбирать, какую хотите "улучшить". Все следующие примеры уже будут итоговые результаты в виде 1-2 работ.
Запрос №2:
Alien mushroom field, at sunrise, magical atmosphere, photorealism, high detail, unreal engine, 4k, --ar 16:9 --quality 2
Запрос №3:
Batman selfies, Giger-style portrait, photorealism, volumetric lighting, high detail, unreal engine, 4k, --ar 16Ж9 --quality 2
Запрос №4:
Detailed Mechanical Skull, based on Leonardo da Vinci's drawings, photorealism, volumetric lighting, octane render, high detail, unreal engine, 4k, --ar 16:9 --quality 2
Запрос №5:
Roman legion on the road, in a valley in the middle of the hills, sunrise, photorealism, volumetric lighting, high detail, unreal engine, 4k, --ar 16:9 --quality 2
Запрос №6:
Nightmare seeps through the window, semi-darkness, photorealism, volumetric lighting, high detail, unreal engine, 4k, --ar 16:9 --quality 2
Запрос № 7:
The demon of gluttony lies on the bed, semi-darkness, photorealism, volumetric lighting, high detail, octane render, 4k, --ar 16:9 --quality 2
Ну и финальный запрос №8:
Superman looks out the window with a nuclear explosion on the horizon, photorealism, volumetric lighting, high detail, unreal engine, 4k, --ar 16:9 --quality 2
Как видите, сети под силам многое, поэтому не бойтесь экспериментировать, но помните, что она не всемогущая. Ну и как обычно, по мере сил и возможностей отвечу в комментариях на вопросы.
Нашел похожую девушку через сёрчфэйс (ссылку публиковать низя!)
Пробил её фотографию через Яндекс, узнал страницу в ВК. Можно знакомиться.)
А говорят, сложно найти идеальную пару. Пфффф... Сиди да генерируй. ;)
*** https://thispersondoesnotexist.com – Филипп Ванг, инженер-программист Uber, запустил сайт, генерирующий лица с помощью алгоритма генеративных нейронных сетей StyleGAN, разработанного Nvidia. Сайт можно обновлять хоть каждую секунду, и на странице будут появляться новые лица.
Друзья, всем привет! Сегодня я хочу рассказать вам про самую простую и доступную для понимания нейросеть, которая создает изображения по вашему текстовому описанию. Она называется Fooocus и основана на знаменитой Stable Diffusion XL. Это идеальное решение в качестве вашей первой нейросети, и необходимый инструмент для любого дизайнера или контент мейкера.
Автор Fooocus не случайный разработчик, а сам создатель ControlNet, очень важной подсистемы для Stable Diffusion, которая изменила все в мире генерации изображений, позволив художникам и дизайнерам полностью контролировать создаваемый арт. Создатель сравнивает свой проект с Midjourney по качеству арта и удобству использования. И действительно порог входа в эту нейросеть очень низкий, а результаты отличные с первой генерации. Установим, изучим, сделаем выводы, поехали.
Что нам понадобится:
Компьютер или ноутбук с видеокартой минимум на 8GB видеопамяти.
Около 25GB свободного места на диске для одного режима и 40GB для всех трех.
Или Google аккаунт для запуска в облаке.
Fooocus пока еще не забанен в Google Colab, а это значит, что если у вас нет подходящего компьютера вы можете запустить приложение на серверах гугла совершенно бесплатно. ПК бояре могут спускаться к следующему заголовку. Поговорим про запуск в облаке.
Запуск в Google Colab
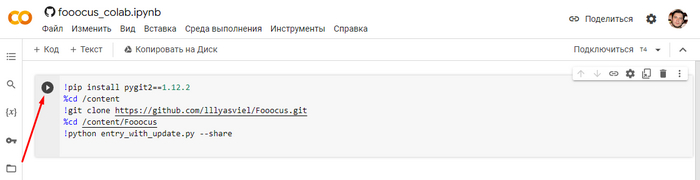
Открываем вот эту ссылку, и нажимаете на кнопку плей, соглашаетесь с гуглом и жмите кнопку Выполнить. Ждите пока произойдёт скачивание и установка на сервер Google Colab, это может занять до 10 минут.
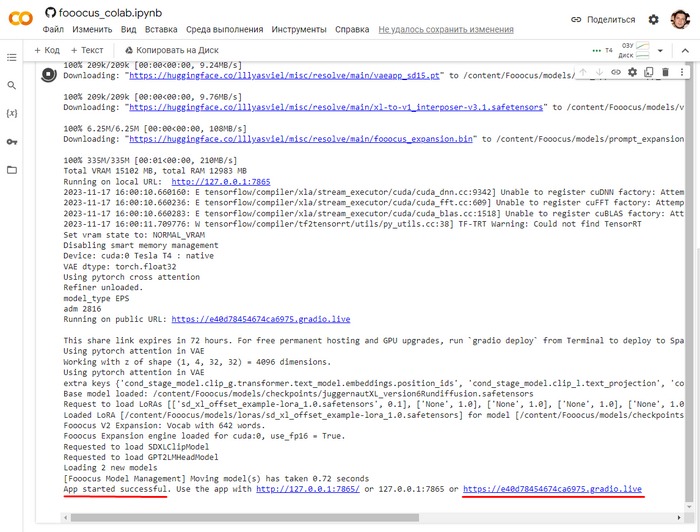
Вы поймете что установка завершена и программа готова к работе когда внизу консоли увидите App started successful.и рядом будет ссылка вида https://какие-то-цифры.gradio.live, вот на неё и надо будет кликнуть. Программа откроется готовая к работе.
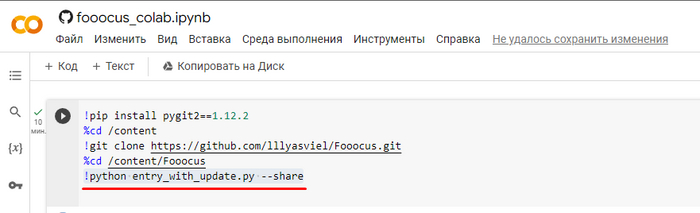
Если вы хотите запустить в режиме Realistic или в режиме Anime замените строку кода !python entry_with_update.py --shareна строку !python entry_with_update.py --preset anime --shareдля режима Аниме, или на !python entry_with_update.py --preset realistic --shareдля режима Реализма. Про режимы я еще расскажу ниже.
Помните, что Google Colab еще весной прикрыл возможность использовать свои мощности для генерации в Automatic 1111, другом интерфейсе нейросети, скорее всего скоро прикроют и этот, поэтому не рассчитывайте на него слишком сильно. Кроме того по итогам моих тестов, вижу что контейнер с фокусом вылетает если сильно грузить его, например если несколько раз подряд отправлять изображение на аутпеинтинг каждый раз с увеличением разрешения. Так, что только локальная версия вас не подведет, к ней и перейдем.
Локальная установка
Если у вас ПК на Windows и видео карта NVidia, все что вам нужно сделать, это скачать архив с этой страницы, нажав на >>> Click here to download <<<. Архив распакуйте в любую удобную папку не содержащую в путях кириллицы.
После того как архив распакован у вас в папке будет три файла run.bat, run_anime.bat и run_realistic.bat, каждый из файлов запускает соответствующий режим, про режимы я покажу наглядно чуть ниже, а пока можете выбрать то, к чему больше душа лежит, я запущу режим по умолчанию - run.bat.
Для установки на Mac, AMD, Linux и т.д. переходите на гитхаб проекта и изучайте способы самостоятельно, поддержка заявлена, но у меня протестировать не на чем, а рассказывать о том, что я сам не протестировал я по понятным причинам не могу.
Если вы все сделали правильно, не важно локально или в гугле, то у вас уже открыт интерфейс фокуса и выглядит он примерно так, попробуем написать какой-нибудь простенький промпт и посмотрим что получится. У меня это будет "Leonardo DiCaprio as a mechanic in a garage with oil effect in a rugged style". Первая генерация будет дольше чем последующие, потому что еще скачиваются дополнительные файлы. Вот что получилось у меня.
Leonardo DiCaprio as a mechanic in a garage with oil effect in a rugged style
По моему отличный результат, кстати, если у вас так же как у меня не выбирается автоматически темная тема, просто добавьте в конце адреса в адресной строке ?__theme=dark, тогда будет установлена темная тема. Работает и локально и в гугл коллабе.
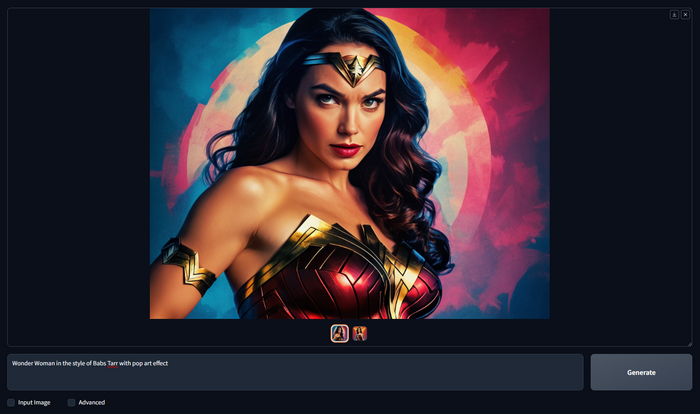
Wonder Woman in the style of Babs Tarr with pop art effect. Согласитесь, темная тема гораздо приятнее
Как писать запросы
Чтобы нейросеть вас понимала, важно научиться правильно писать запросы. В фокусе у нас работают SDXL модели, которые отлично понимают человеческий язык, а дополнительный GPT движок улучшает ваши текстовые запросы самостоятельно, поэтому каких-то особых знаний вам не понадобится. Просто опишите то что хотите видеть следуя такой структуре: Вид изображения, объект, описание внешности, дополнительные элементы, место, эффект, стиль.
Например: Фотография красивой девушки 28 лет, красные волосы заплетенные в косы, большие голубые глаза. Одета в красивое голубое платье с белыми цветами. День, лето, сидит в кафе, пьет кофе. Современная цифровая иллюстрация, рекламный постер. Затем я просто перевожу текст в любом переводчике и получаю отличный результат, который соответствует моим ожиданиям. Вот что вышло у меня.
Photo of a beautiful girl 28 years old, red hair braided in braids, big blue eyes. Dressed in a beautiful blue dress with white flowers. Day, summer, sitting in a cafe, drinking coffee. Modern digital illustration, advertising poster.
По моему отличный результат, но не расстраивайтесь, если у вас что-то не вышло сразу, написание запросов - это навык, потренируйтесь всего недельку и у вас будет получаться уже гораздо лучше.
В этом руководстве я использую готовые запросы из моего списка 100 промптов для новичков, по которым всегда получается хороший результат, подписчики могут скачать список запросов на Бусти. Подпишитесь и вы,ведь на Бусти видео выходят раньше и много эксклюзивных материалов, записи обучающий стримов, а так же доступ в наш секретный чат.Только благодаря поддержке подписчиков у меня есть возможность создавать такие исчерпывающее инструкции и все свое время посвящать изучению нейросетей, чтобы потом делиться информацией с вами друзья. А мы продолжаем изучать Fooocus и переходим к режимам.
Режимы запуска
Режимы отличаются значительно, в разных режимах используются разные модели (в моделях содержится информация обо всем что может создать нейросеть), подходящие под эти модели настройки, разные дополнительные лоры (дополнительные мини-модели) и различные стили включены по умолчанию, ниже я перечислил основные отличия и сгенерировал изображения с одинаковым сидом и запросом, но в разных режимах, чтобы вы лучше понимали разницу и смогли выбрать подходящий для себя. Но обязательно попробуйте их все. Дополнительно я указал ссылки на модели и лоры, на сайте civitai, так вы сможете самостоятельно посмотреть изображения которые на них можно создать и запросы к ним.
Режим General
Cat with a bowtie in a coffee shop with steam effect in a cozy style
Harley Quinn as a waitress in a diner with hammer effect in a playful style, photographed by Juergen Teller
Универсальный режим подойдет для всего и для арта и для реалистичных работ, хорошо следует стилям.
Стили по умолчанию: Fooocus V2, Fooocus Photograph, Fooocus Negative
Негативный запрос: unrealistic, saturated, high contrast, big nose, painting, drawing, sketch, cartoon, anime, manga, render, CG, 3d, watermark, signature, label
Режим Anime
Cat with a bowtie in a coffee shop with steam effect in a cozy style
Harley Quinn as a waitress in a diner with hammer effect in a playful style, photographed by Juergen Teller
Режим подойдет для Аниме и художественного арта. Обратите внимание, что запрос всегда начинается с 1girl, корректируйте если требуется, а то будете получать анимешных девочек.
Надеюсь теперь вы лучше понимаете на что способен Фокус в каждом из режимов и сможете сознательно выбирать режим под задачу. А я же останусь сидеть на режиме General, на мой взгляд самый универсальный.
Дополнительные настройки
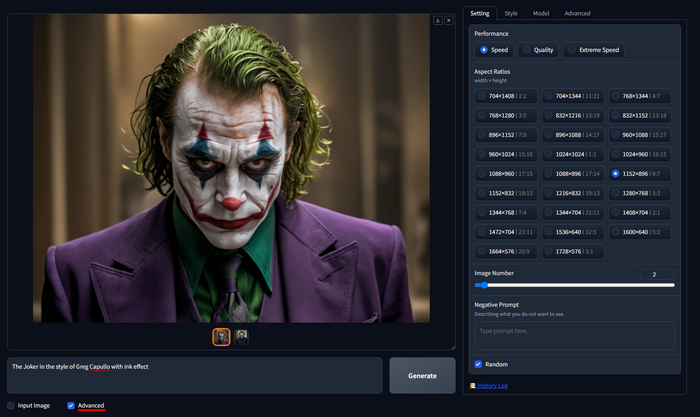
The Joker in the style of Greg Capullo with ink effect
Если вы думали, что в самом простом интерфейсе для создания изображений с помощью SDXL моделей больше нет настроек, он же простой, то вы ошибаетесь, настроек много. Скрывают их две галочки. Начнем с галочки Advanced.
Раздел Setting
В этой вкладке находится все, что непосредственно касается настроек генерации.
Performance - позволяет задать производительность, на выбор три режима Speed - 30 шагов, Quality - 60 шагов и Extreme Speed, между первыми двумя режимами вы разницу скорее всего даже не заметите, а вот последний режим появился совсем недавно, он конечно делает качество хуже, но работает невероятно быстро за счёт использования новой технологии рендеринга LCM. Меня обычно устраивает режим Speed.
Aspect Ratios - соотношение сторон, позволяет вам выбрать разрешение для вашего изображения, выбор фиксированный не случайно, тут только те разрешения на которых обучались SDXL модели, а значит вы при всем желание не сможете сделать что-то не правильно. Первая цифра это ширина, вторая высота. Для удобства рядом еще написано соотношение сторон. Можно сделать как ультра широкое изображение, например 1728×576, в стиле кино-кадров.
The Joker in the style of Greg Capullo with ink effect
Так и ультра высокое, например в 704×1408, в обоих случаях результат отличный, так что выбирайте размер под ваши задачи.
The Joker in the style of Greg Capullo with ink effect
Image Number - позволяет задать количество изображений которые нужно сгенерировать, по умолчанию 2, но вы можете указать вплоть до 32 изображений, но конечно это займет длительное время.
Negative Prompt - негативная подсказка позволяет указать то, чего на изображении быть не должно.
Seed - все изображения создаются из белого шума, как помехи в телевизоре, Seed и есть ид конкретного уникального шума, по умолчанию стоит галочка Random, задавая случайный шум для каждой генерации, но если вы её снимите, то увидите ид по которому была создана текущая картинка. Использовать один и тот же Seed бывает полезно если вы экспериментируете с запросом, или проверяете как работают разные лоры, или просто хотите воспроизвести то изображение, которое уже создавали ранее.
History Log - содержит информацию обо всем, что вы ранее создавали, тут как раз можно увидеть Seed для каждого изображения, запрос и другие настройки. В отличии от Automatic 1111, ComfyUI и прочих Фокус не хранит информацию о генерации внутри самого изображения, а значит вы не сможете воспроизвести информацию о генерации через png info. Сохраняйте лог генераций или промпты отдельно. А мы переходим на следующую вкладку.
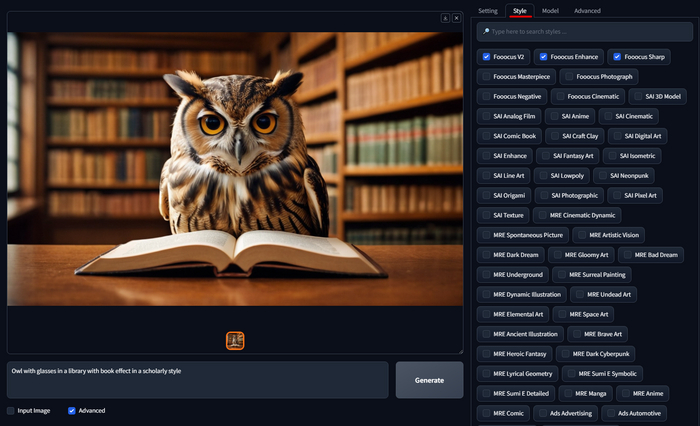
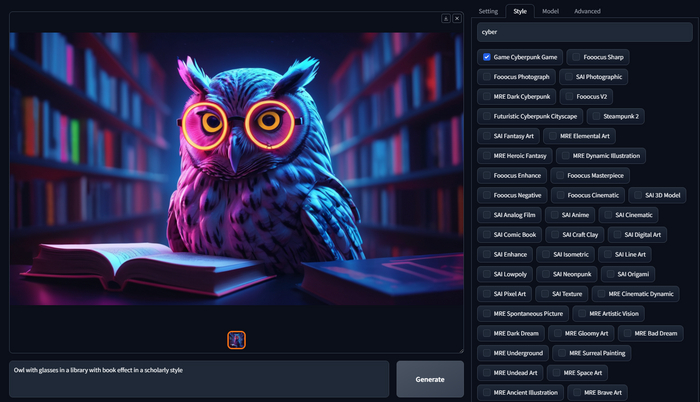
Раздел Style
Owl with glasses in a library with book effect in a scholarly style
По умолчанию всегда включено несколько стилей, Fooocus V2, это тот самый стиль который активирует GPT модель улучшающую ваши запросы, имейте это ввиду, когда будете переключать стили. Стилей очень много, поэтому можно воспользоваться поиском. Для примера я выключу два стиля следующие за Fooocus V2, и вместо них включу Steampunk 2 и SAI Fantasy Art, не изменяя промпт и даже Seed. И получаю отличную фентези сову.
Owl with glasses in a library with book effect in a scholarly style
Или например мне нужна сова с книгами в Киберпанк стиле, для этого выключаете все стили и включаете Game Cyberpunk Game.
Owl with glasses in a library with book effect in a scholarly style
А возможно вам нужная черно-белая драматичная сова? Тоже не проблема, для примера ниже я выбрал стили Photo Film Noir, Dark Fantasy, Dark Moody Atmosphere и SAI Line Art. Мне результат очень нравится.
Owl with glasses in a library with book effect in a scholarly style
Экспериментируйте со стилями и комбинируйте их, в Фокусе работа со стилями улучшена по сравнению с A1111 и другими, это позволяет применять одновременно 3-5 стилей для получения отличного результата, а не парочку как в аналогах. А мы двигаемся в следующую вкладку.
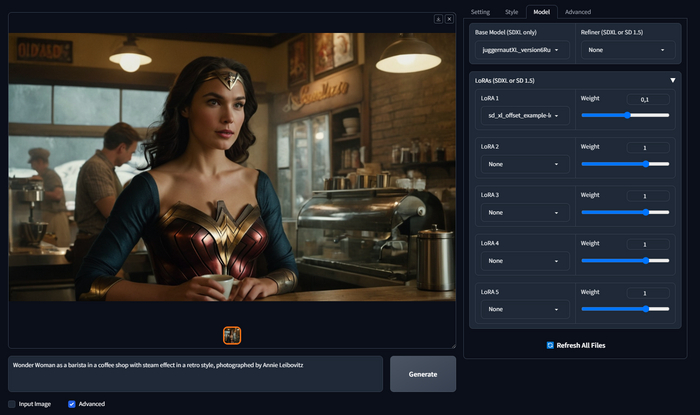
Раздел Model
Wonder Woman as a barista in a coffee shop with steam effect in a retro style, photographed by Annie Leibovitz
На вкладке Model можно переключить модель, выбрать рефайнер, или добавить дополнительные лоры. Сила лор может регулироваться от -2 до 2, в большинстве случаев оптимально ставить 0.5, всего можно добавить до пяти лор.
Скачиваем лоры и модели с https://civitai.com, лоры кладем в папку Fooocus\models\loras. Модели кладем в папку Fooocus\models\checkpoints. Какие лоры могут вам понадобиться и зачем? Смотрите в моем большом обзоре сервисных лор для SDXL на YouTube, я сравнил 12 самых популярных, рассказал что они делают и как их использовать.
Если у вас уже есть своя папка с моделями или лорами, например в A1111, то вы можете подключить её отредактировав пути до папки с моделями в файле Fooocus\config.txt, кстати, там же в конфиге можно указать и настройки по умолчанию, с которыми будет запускаться Фокус. Используйте файл config_modification_tutorial.txtв качестве пособия по возможным настройкам, он лежит рядом.
Раздел Advanced
На вкладке Advanced находится всего пара настроек, первая Sampling Sharpness отвечает за добавочный шум при создании изображения, чем больше шума, тем больше деталей будет на вашем изображении, но избыток шума может привести к артефактам и замусоренности, это отлично видно на гифке ниже. Мне обычно нравится значение 5-7.
Raccoon with a mask in a trash can with garbage effect in a mischievous style.
Guidance Scale отвечает за то, насколько сильно нейросеть должна пытаться следовать запросу, высокое значение приведет к артефактом, а на низком все будет блеклое, смотрите рекомендуемое значение CFG в описании модели, или оставляйте по умолчанию.
Developer Debug Mode открывает меню для тонкой настройки, но настройки там настолько тонкие, что покрутить их и ничего не сломать, а сделать лучше у вас вряд ли получится, так что этот раздел исследовать не будем.
Друзья, поскольку количество медиа файлов в этом руководстве уже переваливает за 20, а для рассказа про оставшуюся галочку Input Image мне нужно еще как минимум столько же, я сделаю это в следующей публикации.
Из второй части вы узнаете как в Фокусе работают вариации, чтобы создать похожее изображение на то, что вы загружаете. Узнаете как работает качественное увеличение ваших изображений. Расскажу про местную вариацию ControlNet которая позволяет скопировать и стиль и содержимое с любого изображения добавив в вашу генерацию. И про местный дипфейк, который позволяет перенести ваше лицо на создаваемое изображение. И конечно же про инпеинтинг и аутпеинтинг, с помощью которого можно расширить или изменить любое изображение как в тех роликах с фотошопом, генеративной заливкой и мемами.
close-up of baby Groot bye-bye hand shake in the space, surrounded with firefly and blue sparkles
А на сегодня у меня все, вы узнали про нейросеть Fooocus, которая создает изображения по текстовому запросу и научились в ней работать. Теперь вы знаете за что отвечает каждая из настроек и сможете осмысленно создавать красивый арт который пригодится в работе или учебе, и конечно, порадует друзей и близких. Генерация изображений с помощью нейросетей очень интересный и увлекательный процесс, делитесь своими работами в нашем чате с такими же увлеченными энтузиастами.
Я рассказываю больше про нейросети у себя на YouTube, в телеграм, на Бусти, буду рад вашей подписке и поддержке. До скорого.