



Stabble Diffusion от Stability AI
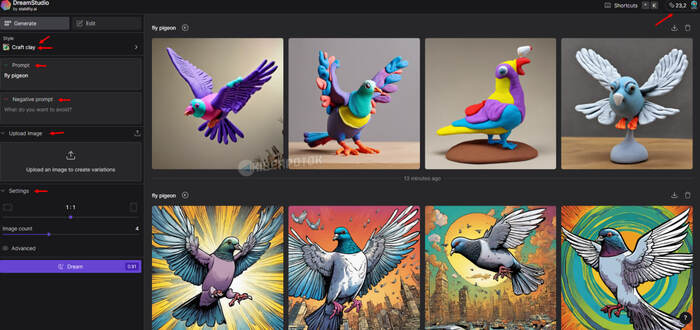
Stabble Diffusion от Stability AI
Эта нейросеть позволяет создавать изображения по текстовому описанию. На платформе можно настроить несколько дополнительных параметров для генерации изображений.
Нюансы:
- Услуги предоставляются компанией Stability AI.- ИИ платный (есть ограничение на 25 запросов).
- ВПН не нужен.
- Русский язык не поддерживается.
Функционал:
- Генерация изображений.- Редактирование изображений с помощью ИИ.
- Выбор стиля изображения.
- Промт / Запрос.
- Негативный промт / запрос.
- Возможность загрузить свою картинку и сгенерировать её в определённом стиле.
- Настройка параметров генерируемого изображения.
Мое мнение:
Можно использовать на английском языке, умный ИИ, мне понравился. Понимает с двух слов, стили корректные и интересные. 25 запросов вполне достаточно. Любителей халявы обрадую: если закончились кредиты, можно залогиниться под другой учёткой. Интерфейс простой и удобный.
Больше интересных статей вы можете найти на моем Telegram-канале.
Источник: КиберПоток
Показать полностью


3д против ИИ
Наконец-то! Из чтения комментариев этот материал по созданию иллюстраций был подготовлен специально для публики пикабу! Поздравляю вас с этим!)

Сегодня многие думают, что любое необычное искусство "нарисовала" нейросеть. Но сразу скажем, что неросеть, ничего странного создавать не умеет. Все её базы подготавливаются со среднего/общего визуального достояния для получения нейросетью больших данных об окружающем популярном мире. Искусство, например, сложнее создавать по запросу, так как нейросеть может "применить" разве, что "эффект" искусства, который был внесен на какой то фотографии в её память.
И если это кажется вам понятным, то при работе с нейросетью существуют такие интересные детали, о каких и не подумаешь...
Если в 3D, вы делаете "всё", до нажатия последней кнопки (снимка, рендера), то в нейросети, вы делаете "всё", после.
Наши небезисзвестные с первых дей работы девушки, послужат прекрасным примером для погружения в ряд поклонников и ценителей создания искусства изнутри.

Девушки
Дело в том, что при работе с нейросетью необходимо сначала получить базу, на которой вы будете достраивать детали и то, что вы планировали. Если кто то считает, что можно сказать нейросети, (даже при использовании сложного промпта, от анлг. prompt - заказ, запрос) необходимое и получить готовое, то это всегда не так. Вам, как минимум, нужно убрать кляксы, ошибки и прибавить деталей/разрешения (что займет ещё час на каждые рисунок) для получения готового изображения.
К тому же, если вы искушенный в искусстве человек (например, как мы по формам) и желаете создавать нечто оригинальное, то, скорее всего, вам потребуется создать отдельные микропрограммы, контролирующие те нюансы, которых нужно добиваться. Даже грудь большого размера (считается, что ничего особенно сложного) сделать без дополнительных программ (Лоры, в основном; КонтролНета,...) не получится. Но можно попробовать сделать сложный промпт и тут очень интересно!
Можно стать действительно большим мастером, которого будут уважать, создавая одни лишь текстовые заготовки.
Говоря о фигурах...
Как вы уже знаете нейросеть ничего делать не будет, чего нет в её алгоритмах. Никаких сложных в форм и несуществующих миров она не сделает без ваших усилий. Но чтобы её обмануть, например, заставить "сочинить" форму тела, что очень хорошо будет обрисовывать общую ситуацию, можно выдумать такой запрос, который будет описывать грудь, как "планеты" на груди, или сферы. Нейросеть будет сначала рисовать огромные сферы/планеты где то около груди и потом дорисовывать на них кожу, если главным запросом был человек. Что очень удивительно! Пишется это так: "a girl with [big planets|Breasts] on her chest". Знаки ["первое"|"второе" ] нужны, чтобы разделять и совмещать формы нескольких объектов в один объект. Примеров текстовых трюков есть множество. Бывают хитрости для поз. Как поставить человека на четвереньки? – нужно написать что то вроде "[лошадь|человек]" и при удачном стечении обстоятельств, на какой-то из итераций может оказаться, что тело примет именно человеческий вид, но будет стоять на четвереньках. Можно играть с этим очень долго. Жду ваших комментов и примеров! Натренированные Лоры для этого не потребуются.
Конечно, сразу понятно, что не каждая нейросеть нарисует, что то красивое из странных запросов. Нарисует, но так ли эти формы будут сочитаться, как вам хотелось? (К вопросу о том, как "каждый даун сможет всё..."). Избегая далее глубинных разделов процесса с описанием деталей КонтролНета, который делает коррективы и более ясный/предсказуемый итог картины, нужно для понимания работ любой тематики в нейросети затронуть только inpaint режим. Без него не объходится ни один шедевр (это когда, как в фотошопе, обводится часть полученной "базы" по запросу и начинается улучшение – обводится платье и меняется его цвет, или заменяется вся одежда, или применяется нужный эффект живых кистей (если нейросеть была обучена такому эффекту). А лучше расскажем об этом по-больше, в разделе о процессе создания.
Детали процесса создания
Нейросеть создаёт изображение на основе входных данных, таких как текст или образец. Это может быть быстрый и автоматизированный процесс. А 3D-приложение требует более сложного процесса создания, который включает в себя моделирование, текстурирование и освещение объектов. Это более трудоёмкий, с первого взгляда, процесс.
Начнем и создадим "девушку" (что у нас не получится, потому-что нейросеть знает только одно лицо. Для другого вам тоже нужно создавать коррективы)!
Каждый создатель на нейросетях имеет свои секреты в "искусстве" – это его промпт
Что нам ещё было бы нужно? Что может быть проще, чем нарисовать девушку? А у нас будет очень много сложностей и провал в итоге по многим аспектам. И, если уж, нейросеть с таким простым делом не справится, как нарисовать девушку с немного нестандартными формами, то что говорить о чем-то более сложном (в любом плане)?

Создали, используя промпт и хитрости, на которые потратили электричество поселка, что очень глупо
Были применены лоры персонажа Касуми из Dead or Alive. Лицо, волосы рисовались из сторонней микропрограммы.
А теперь , когда мы нашли промпт, который немного работает, пробуем фотографировать эту девушку в разных позах. И у нас не получится!!!


Каждый раз, при каждом новом повороте головы, девушка меняется, её одежда меняется, окружение – тоже! Вот так подстава, друзья!

Ребята, это не серьезно.... Фон так же плох, как и девушка.
Теперь каждый из нас начал уважать создателей красивых картин на нейросетях, не правда ли?😁
А теперь — работа в 3д, которая не занимает никакого времени в создании после того, как вы создали девушку за 50 часов и одели её за 2:



Вот она, Кисуми! Неросети - дерьмо!
Какая же необычная, очень живая и играющая красотка!



И вдобавок! Мы без "планет на груди" от нейросети вас не отпустим!
Правда, работать с этими фото не получится никак, как и использовать в дальнейшем. Зато информативно!



Небольшая ремарка: качество изображений на нейросетях, при работе мастера, не имеет границ. Именно мастер и будет главной силой уровня и финала картины. Мы нейросети не используем, поэтому не доводили некоторые аспекты до идеала. А творцы — молодцы!
На этом на сегодня все. Оставайтесь на связи, не стесняйтесь подписываться и писать хорошие комментарии! Будьте осторожны с плохими – из них могут получаться новые статьи!
Контента и девушек уже создано на несколько жизней марио! Около 250 персонажей. Что является научным "уровнем фанатского голода в разнообразии" в психологии. По некоторым данным, мужчины, какие бы девушки "ему" не нравились, сможет различать или создать, примерно 250 образов! Потом, поймет, что они все одинаковые.😁😁😁
Показать полностью
15

Заброшенный боевой робот

Других роботов и прочую фантастику смотрите тут
Показать полностью
1

Первый музыкальный клип, созданный нейросетью Sora от OpenAI, революция или баловство? Как работает?
Представьте, что вы смотрите музыкальный клип, в котором каждая сцена, каждый персонаж и каждое движение камеры созданы искусственным интеллектом. Звучит как научная фантастика? Что ж, будущее уже наступило. Встречайте The Hardest Part - первый в истории музыкальный клип, полностью сгенерированный нейросетью Sora от OpenAI.
Этот новаторский проект - плод совместных усилий инди-музыканта Washed Out (настоящее имя - Эрнест Грин) и режиссера Пола Трилло. Клип на песню “The Hardest Part” демонстрирует впечатляющие возможности генеративных моделей в создании реалистичных и захватывающих визуальных образов. Но как именно работает эта технология, и какое влияние она окажет на индустрию развлечений? Давайте разберемся.
Под капотом Sora: Как нейросеть создает видео
Примечание: Следующее описание основано на рассуждениях Итана Хи (Ethan He), исследователя ИИ из NVIDIA, бывшего сотрудника FAIR и выпускника CMU, с более чем 6000 цитирований и 5000 звезд на GitHub. Оригинальная статья доступна на LinkedIn Pulse. Реальные технологии являются коммерческой тайной OpenAI и еще не были обнародованы.
Предполагается, что в основе Sora лежит DiT (диффузионный трансформер) - архитектура, которая использует возможности масштабирования трансформеров наряду с итеративным процессом уточнения диффузионных моделей, я уже рассказывал про AnimateDiff, который позволяет генерировать видео на моделях Stable Diffusion, тут этот принцип многократно улучшен.
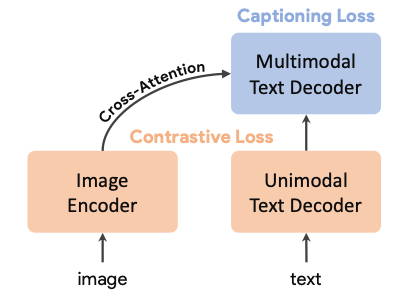
Схема работы диффузионного трансформера
Трансформеры известны своей эффективностью в обработке последовательных данных и обеспечивают надежную архитектуру для моделирования временной динамики видео. Процесс диффузии, в свою очередь, итеративно уточняет выходные данные, начиная с зашумленного начального состояния и двигаясь к желаемому видеовыходу, повышая качество и согласованность сгенерированных видео.
Для сжатия видео Sora использует векторный квантованный вариационный автоэнкодер (VQ-VAE) на основе трехмерной сверточной нейронной сети (3D CNN). Эта архитектура сети состоит из энкодера, который уменьшает размерность визуальных данных до скрытого пространства, и декодера, который реконструирует видео из этого сжатого представления.
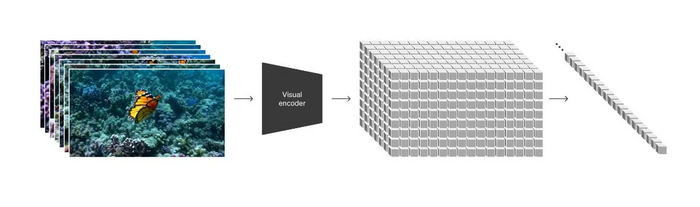
Схема работы VQ-VAE для сжатия видео
Использование 3D CNN позволяет захватывать временную динамику видео, что важно для создания согласованного и плавного движения в сгенерированных клипах. Симметричная конструкция энкодера и декодера обеспечивает эффективное сжатие и реконструкцию видео, сохраняя высокую точность исходного контента.
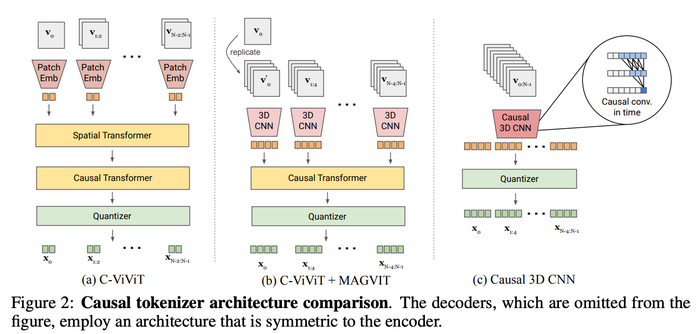
Процесс обучения Sora
Во время обучения к видеотокенам добавляется случайный шум. Трансформер получает на вход текстовое условие, временной шаг диффузии и зашумленные видеотокены.

Генерация текста в видео
Универсальность Sora распространяется на различные приложения, включая анимацию статических изображений и создание идеально зацикленных видео. Анимация статического изображения достигается путем кодирования изображения как первого токена и использования шума для остальных токенов. Для создания бесшовно зацикленных видео Sora обеспечивает идентичность первого и последнего токенов на каждом шаге диффузии, улучшая эстетическую привлекательность сгенерированного контента.
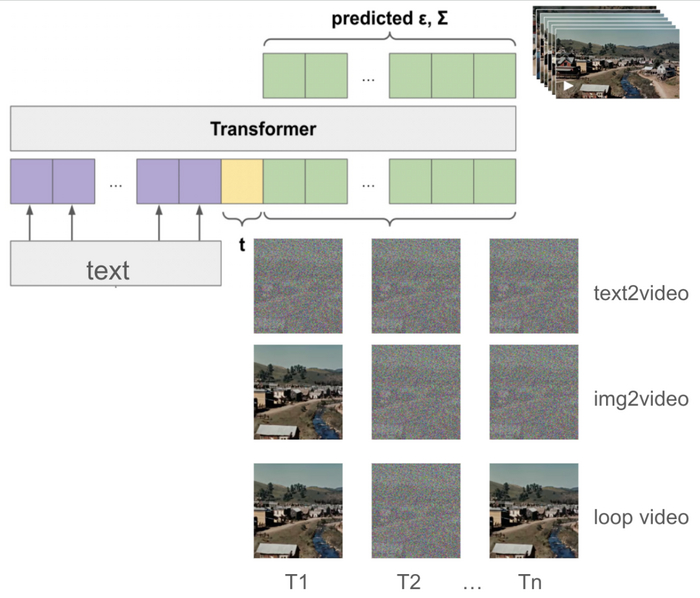
Генерация видео из изображения
Одним из самых замечательных аспектов Sora является ее способность демонстрировать такие возникающие возможности, как 3D-согласованность и постоянство объектов, без явного программирования. Традиционно для достижения 3D-согласованности в сгенерированных видео требовались специальные функции потерь. Однако Sora показывает, что при масштабировании эти возможности могут возникать естественным образом, позволяя генерировать видео, точно имитирующие реальную динамику и взаимодействия.
Таким образом, Sora представляет собой значительный скачок в области генерации видео с помощью ИИ, объединяя несколько передовых технологий для создания высококачественных видеороликов из текстовых описаний.
Создание клипа “The Hardest Part”: Сложности и уроки
Несмотря на впечатляющий результат, процесс создания клипа The Hardest Part с помощью Sora был далеко не простым. Режиссеру Полу Трилло пришлось сгенерировать более 700 видеофрагментов, чтобы отобрать из них 55 лучших для финального клипа. Каждый фрагмент требовал детального текстового описания, учитывающего не только визуальные элементы, но и движения камеры, ракурсы и действия персонажей.

Без динамики сцены смотрятся откровенно странно
“Мы пролетаем сквозь пузырь, он лопается, мы пролетаем сквозь жвачку и выходим на открытое футбольное поле”, - так Трилло описывал одну из сцен клипа.
Пока у Пола Трилло был доступ к Сора он так же сделал промо заставку для TED Talks, со столь полюбившимися ему пролетами камеры. Как по мне, получилось интереснее чем в клипе.
Этот опыт показывает, что даже с использованием передовых алгоритмов ИИ создание качественного видеоконтента требует значительных усилий и творческого подхода. Сора, безусловно, открывает новые возможности, но она не заменяет человеческий талант, а дополняет его.
Барьеры на пути к массовому использованию
Несмотря на огромный потенциал Sora и подобных технологий, их широкое применение в индустрии развлечений пока сталкивается с рядом препятствий. Главным из них является высокая стоимость генерации видео.
Для создания согласованных и реалистичных видеопоследовательностей Sora требуется огромное количество вычислительных ресурсов и объем памяти. По оценкам экспертов, генерация даже короткого клипа может обходиться в сотни или тысячи долларов. Для сравнения, другие мультимодальные модели, такие как LLaVA и CogVLM, которые работают только с изображениями и текстом, уже требуют существенных затрат на GPU и электроэнергию.
Еще одним барьером является вопрос авторских прав и интеллектуальной собственности. Модели вроде Sora обучаются на огромных массивах видеоданных, принадлежащих различным правообладателям и в том числе открытых. Использование сгенерированного ИИ контента в коммерческих проектах может привести к юридическим спорам и конфликтам интересов.
OpenAI и Голливуд: Стратегия внедрения

Сгенерированный Сэм Альтмен на фоне сгенерированных голливудских холмов
OpenAI, разработчик Sora, активно продвигает свою технологию в киноиндустрии. В марте 2024 года генеральный директор компании Сэм Альтман и другие представители провели серию встреч с голливудскими студиями, режиссерами и продюсерами. Цель этих встреч - найти партнеров для дальнейшего развития и внедрения Sora в кинопроизводство.
Для крупных киностудий использование генеративных моделей может означать существенное сокращение затрат на производство визуальных эффектов и ускорение процесса создания фильмов. OpenAI рассчитывает, что партнерство с Голливудом поможет не только улучшить Sora, но и продемонстрировать ее возможности широкой аудитории.
Однако не все в киноиндустрии разделяют энтузиазм по поводу внедрения ИИ. Многие актеры, режиссеры и другие творческие работники опасаются, что генеративные модели могут лишить их работы и нивелировать ценность человеческого таланта. Поэтому OpenAI предстоит найти баланс между технологическим прогрессом и интересами профессионального сообщества.
Sora и будущее развлечений
Первый музыкальный клип, созданный с помощью Sora, - это лишь начало большого пути. По мере развития генеративных моделей и снижения стоимости их использования, мы увидим все больше примеров применения ИИ в киноиндустрии, музыке, видеоиграх и других сферах развлечений.
Однако важно помнить, что технологии вроде Sora - это инструменты, а не замена человеческого творчества. Они открывают новые горизонты и позволяют воплощать самые смелые идеи, но за каждым успешным проектом по-прежнему стоят талантливые люди - режиссеры, сценаристы, художники и многие другие.
Первая короткометражка сделанная в Sora называется Air Head by Shy Kids
Будущее индустрии развлечений - это симбиоз творчества и технологий, в котором ИИ дополняет и усиливает человеческие способности. И клип “The Hardest Part” - это лишь первый шаг на пути к этому будущему.
А что вы думаете о потенциале генеративных моделей вроде Sora? Как они повлияют на индустрию развлечений и творческие профессии? Поделитесь своим мнением в комментариях!
Показать полностью
7
5
Робот Нарисовал

Показать полностью
1

Время розоволосых русалок



Люблю я розоволосых русалок генерировать. Особенно в космическом пространстве. Такие красивые и нежные. Прям хочется прикоснуться к ней. Есть ещё желание картину написать в таком стиле и игрушку сделать! Но это всё в планах.
Сколько раз пересмотрели?)) я много!))
Показать полностью
3