
Закреплено

Искусственный интеллект
4 818 постов
•
11 398 подписчиков
0 просмотренных постов скрыто


Репозиторий TAPNet
👩💻TAPNet — это модель для сверхточного отслеживания движения любой точки в видео, даже скрытой.
Полезно для анимации, анализа спорта и реалистичных визуальных эффектов.
Подходит для робототехники, 3D-моделирования, создания видео и других задач.
Языки: Jupyter Notebook 75.9% Python 24.0% Shell 0.1%
⭐ 1.7k stars
➡ Ссылка на GitHub - https://github.com/google-deepmind/tapnet
➡ телеграмм канал - EasyProger - https://t.me/easyprogers
Показать полностью
Как создать QR-Код на примере ЯП C# (в слайдах)



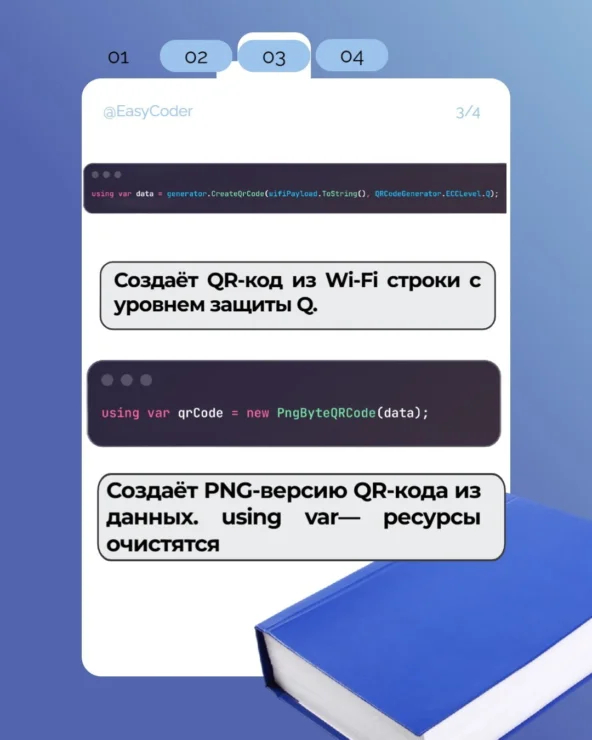


Показать полностью
6
Закономерности в движении: целостный подход к генерации многокадровых видео
Автор: Денис Аветисян

Этот подход раскрывает закономерности в визуальном повествовании, позволяя создавать последовательные и логичные видеофрагменты.
Долгое время создание связных, продолжительных видеоисторий оставалось недостижимой целью, поскольку существующие методы генерации видео концентрировались на коротких, изолированных фрагментах, неспособных передать повествовательную целостность кинематографического произведения. Прорыв, представленный в ‘HoloCine: Holistic Generation of Cinematic Multi-Shot Long Video Narratives’, заключается в принципиально новом подходе к генерации видео, объединяющем все кадры в единую модель для обеспечения согласованности и повествовательной логики. Но сможет ли эта целостная генерация не просто воспроизвести визуальный ряд, но и вдохнуть жизнь в настоящие, эмоционально насыщенные истории, способные по-настоящему захватить зрителя?
Разрыв в Повествовании: Преодоление Ограничений Генерации Видео
Современные системы преобразования текста в видео (T2V) демонстрируют впечатляющие результаты в генерации коротких видеоклипов, однако сталкиваются с существенной проблемой поддержания связности и последовательности при увеличении длительности. Это выявляет так называемый "разрыв в повествовании" – принципиальное ограничение, препятствующее созданию полноценных, многоплановых визуальных историй. Несмотря на значительный прогресс в области диффузионных моделей и диффузионных трансформаторов, позволивших достичь высокого качества генерации, эти системы часто оказываются неспособными к осмыслению и воспроизведению сложной структуры повествования и развитию персонажей.
Существующие подходы, как правило, рассматривают каждый кадр как независимое целое, что приводит к фрагментированным видео, не способным рассказать убедительную историю. Истинное кинематографическое повествование требует поддержания согласованности на протяжении нескольких кадров, создания визуального ритма и логичной связи между событиями. Отсутствие этой целостности лишает видео глубины и эмоционального воздействия. Это особенно заметно при попытке воссоздать сложные сюжетные линии или динамичные сцены действия.
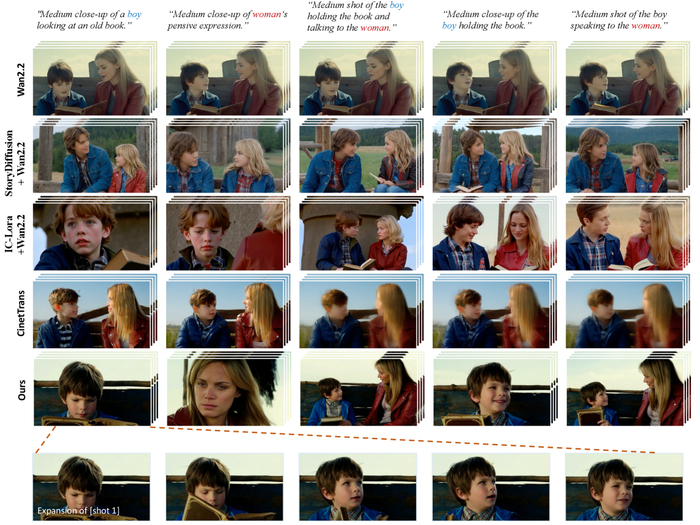
Качественное сравнение на сложном многокадровом запросе.
Таким образом, задача создания связных, многокадровых видео представляет собой значительный вызов для современных систем искусственного интеллекта. Недостаточно просто генерировать красивые картинки – необходимо уметь объединять их в единое повествование, поддерживать согласованность персонажей и окружения, а также создавать динамичные переходы между кадрами. Если закономерность нельзя воспроизвести или объяснить, её не существует. Только преодолев этот "разрыв в повествовании", мы сможем приблизиться к созданию систем, способных автоматически генерировать полноценные кинематографические произведения.
HoloCine: Целостная Генерация Видео и Взаимосвязь Кадров
В стремлении к созданию кинематографических повествований, исследователи обращаются к принципам целостности и взаимосвязанности, подобно тому, как нейронные сети моделируют сложные биологические системы. Традиционные подходы к генерации видео часто рассматривают отдельные кадры как изолированные единицы, упуская из виду критически важные связи между ними. В результате, возникает фрагментация повествования и потеря визуального опыта. В данной работе представлен HoloCine – новый подход к генерации многокадрового видео, который явно моделирует взаимосвязи между кадрами, обеспечивая тем самым нарративную когерентность и так называемую “целостную генерацию”.
Ключевым элементом архитектуры HoloCine является механизм Window Cross-Attention. Подобно тому, как живые организмы фокусируют свои ресурсы на определенных участках для выполнения конкретных задач, данный механизм позволяет выровнять текстовые подсказки с конкретными сегментами видео. Это обеспечивает семантическую согласованность внутри каждого кадра и гарантирует, что визуальный контент точно соответствует намерениям режиссера. Представьте себе оркестр, где каждый инструмент играет свою партию в гармонии с другими – именно так Window Cross-Attention обеспечивает слаженность и согласованность визуального повествования.
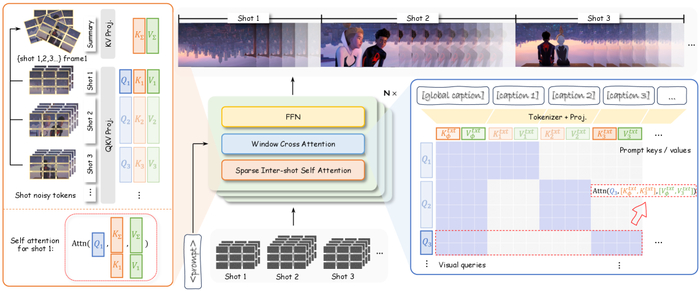
Sparse Inter-Shot Self-Attention значительно снижает вычислительные затраты, сохраняя при этом долгосрочную согласованность.
Однако, создание целостной системы требует преодоления значительных вычислительных сложностей. Подобно тому, как мозг оптимизирует свои энергетические затраты, HoloCine использует Sparse Inter-Shot Self-Attention. Этот механизм позволяет эффективно рассуждать на протяжении всей видеопоследовательности, не прибегая к чрезмерным вычислительным ресурсам. Вместо того, чтобы обрабатывать каждый кадр независимо, система фокусируется на ключевых взаимосвязях, обеспечивая тем самым масштабируемость и эффективность. Представьте себе паутину, где каждая нить соединяет важные узлы – именно так Sparse Inter-Shot Self-Attention обеспечивает связь и согласованность между кадрами.
В итоге, HoloCine представляет собой новый шаг в развитии генеративных моделей для видео. Преодолевая ограничения традиционных подходов, система открывает новые возможности для создания кинематографических повествований, обладающих как визуальной красотой, так и нарративной целостностью. Это подобно созданию сложной экосистемы, где каждый элемент играет свою роль в поддержании общего равновесия и гармонии.
Иерархическая Аннотация Данных и Оценка Согласованности Повествования
В основе HoloCine лежит принцип иерархической аннотации данных, позволяющий создать набор данных, обогащенный как глобальными описаниями сюжета, так и детальными инструкциями для каждого кадра. Такой подход обеспечивает богатый контекст, необходимый для обучения модели пониманию повествовательной структуры и визуального языка. Каждый кадр рассматривается не как изолированное изображение, а как звено в цепи повествования, требующее осмысленной интерпретации.
Точное определение границ кадров играет критическую роль в обеспечении согласованности между текстовым описанием и визуальным контентом. Для этого используются современные методы обнаружения границ кадров, такие как TransNet V2, позволяющие добиться высокой точности выравнивания. Это выравнивание не только необходимо для корректной аннотации данных, но и является ключевым фактором при оценке качества генерируемых видео.

Для оценки семантической согласованности между текстовыми подсказками и генерируемыми кадрами используется ViCLIP – модель, способная извлекать и сопоставлять визуальные и текстовые представления. Этот подход позволяет количественно оценить, насколько хорошо сгенерированное видео соответствует заданному описанию. Помимо семантической согласованности, особое внимание уделяется плавности переходов между кадрами.
Для количественной оценки качества переходов между кадрами разработан показатель – точность определения границ кадров (Shot Cut Accuracy, SCA). SCA позволяет оценить, насколько точно модель определяет моменты смены кадра и насколько плавно происходит переход между ними. Этот показатель не только отражает техническое качество видео, но и влияет на восприятие повествования зрителем. Каждый кадр – это не просто визуальное изображение, а часть динамичного повествования, требующая точной и согласованной визуализации.
Таким образом, HoloCine стремится к созданию не просто визуально привлекательных видео, но и повествовательно согласованных и логичных сцен. Использование иерархической аннотации, точного определения границ кадров и количественных метрик оценки позволяет оценить и улучшить качество генерируемых видео, приближая нас к автоматическому созданию полноценных киноповествований.
Преодолевая Границы: Будущее Автоматизированного Кинематографа
Преодолевая ограничения существующих систем преобразования текста в видео, HoloCine открывает двери для широкого спектра применений, включая создание персонализированного контента и автоматизированное кинопроизводство. В основе этого прогресса лежит способность модели генерировать последовательные, длинные видеофрагменты, что принципиально важно для повествования. Традиционные подходы часто сталкиваются с проблемой накопления ошибок и потери связности, особенно при создании видео продолжительностью в несколько минут. HoloCine, напротив, демонстрирует устойчивость и связность, что позволяет создавать сложные повествования с достоверными персонажами и захватывающими сюжетными линиями.
В рамках данного исследования авторы не просто демонстрируют технические возможности новой архитектуры, но и задают вопросы о том, как визуальные закономерности отражают внутреннюю логику модели. Эксперименты, направленные на подтверждение или опровержение выдвинутых гипотез, позволяют глубже понять принципы работы HoloCine и выявить факторы, влияющие на качество генерируемого видео. Особое внимание уделяется долгосрочной согласованности, что достигается за счет использования механизма Window Cross-Attention и Sparse Inter-Shot Self-Attention. Эти инновационные подходы позволяют модели поддерживать целостность визуального повествования на протяжении всей сцены, избегая распространенных проблем, связанных с потерей идентичности персонажей или несоответствием фоновых элементов.

(a) Масштаб кадра: модель точно генерирует длинные, средние и крупные планы. (b) Угол обзора камеры: она правильно интерпретирует команды низкого, на уровне глаз и высокого угла. (c) Движение камеры: модель производит плавные и точные движения камеры.
В дальнейшем авторы планируют исследовать возможности интеграции метрик оценки эстетического качества, таких как LAION Aesthetic Predictor, для дальнейшего повышения художественного уровня генерируемых видео. Эта работа позволит не только улучшить визуальную привлекательность контента, но и создать более выразительные и эмоционально насыщенные повествования. Интеграция таких метрик позволит модели адаптировать свои параметры к предпочтениям зрителей и создавать контент, который будет не только технически совершенным, но и эстетически привлекательным. Это открывает новые горизонты в области автоматизированного кинопроизводства и создания персонализированного контента.
Исследование демонстрирует, что HoloCine представляет собой значительный шаг вперед в области генерации видео, открывая новые возможности для создания захватывающих и убедительных визуальных повествований. Оно подтверждает, что с помощью инновационных архитектур и продуманных подходов можно преодолеть ограничения существующих систем и создать модели, способные генерировать контент, который будет не только технически совершенным, но и художественно выразительным.
В HoloCine мы видим воплощение идеи о том, что понимание системы – это исследование её закономерностей. Авторы демонстрируют, как внимание к деталям, в данном случае – к механизмам внимания в диффузионных моделях – позволяет создавать целостные и длинные видео-нарративы. Как сказал Ян ЛеКюн: «Машинное обучение – это поиск закономерностей в данных». Эта фраза прекрасно отражает суть работы: HoloCine использует sparse inter-shot self-attention для выявления скрытых зависимостей между кадрами, позволяя модели эффективно генерировать длинные видео, сохраняя при этом согласованность и повествовательную логику. Каждое отклонение от ожидаемого результата, каждый артефакт – это возможность выявить скрытые зависимости в структуре данных и улучшить модель.
Что дальше?
HoloCine, безусловно, демонстрирует впечатляющий шаг вперёд в генерации длинных видео, но давайте не будем обольщаться. Мы научились создавать иллюзию повествования, но понимаем ли мы само повествование? Решение проблемы вычислительной сложности через разреженное внимание – это, конечно, элегантно, но это лишь технический трюк. Настоящий вызов – не в скорости, а в осмысленности. Генерация когерентных видео – это не просто соединение кадров, это создание системы визуальных закономерностей, которые вызывают у зрителя определённые эмоции и ассоциации.
Следующим шагом видится не столько увеличение длины генерируемых видео, сколько углубление контроля над смысловым содержанием. Необходимо разработать механизмы, позволяющие задавать не просто текстовое описание сюжета, а более сложные параметры – например, эмоциональную окраску сцены, темп повествования, визуальный стиль. И, что особенно важно, тщательно проверять границы данных, чтобы избежать ложных закономерностей и не создавать "видео-галлюцинации".
Возможно, мы приближаемся к моменту, когда компьютер сможет "рассказать" историю, но стоит помнить: даже самая совершенная визуальная иллюзия – это лишь отражение нашей собственной потребности в нарративах. И прежде чем учить машины рассказывать истории, нам следует лучше понять, зачем мы сами их слушаем.
Показать полностью
4

В ИИ реально “пашут”, киборги от Amazon, ИИ в космосе
Сегодня в выпуске про ИИ:
Исследователи ИИ работают по 100 часов в неделю ради прогресса
Amazon заменила инженеров на ИИ и через пару дней все рухнуло
Глава Airbnb заявил что ChatGPT пока не годится для них
Топ менеджер Anthropic открыла модный дом
OpenAI купила стартап до релиза продукта
Китай не смог скопировать ASML и обратился за ремонтом
В браузере ChatGPT Atlas нашли уязвимости
Дата-центры для ИИ переносят в космос
OpenAI уберет избыточную модерацию в Sora
Amazon решил превратить своих курьеров в киборгов
Смотреть весь выпуск на VK Видео
Смотреть весь выпуск на YouTube
Приятного просмотра!
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Показать полностью
2
Какие из нейросетей для клонирования голоса доступны в России по состоянию на октябрь 2025 г?
Нужно мне, чтобы никому не мешать при записи озвучки к своим видосам. Только без "зачем тебе это?", "даже и не думай"...
В Copilot "поселили" анимированный шарик Mico с эмоциями
Microsoft представила Mico — виртуального помощника для голосового режима Copilot в виде анимированного шара, который корчит рожи в реальном времени. По данным The Verge, персонаж несколько месяцев тестировали, а теперь включат по умолчанию для всех. Хотите — отключайте.
В Microsoft заявляют, что Mico показывает "живые эмоции" и меняет выражение "лица" в зависимости от темы разговора. То есть шарик теперь будет сочувствовать вам или радоваться вместе с вами. Плюс помощник запоминает информацию о пользователе через функцию памяти в Copilot — для "персонализированного взаимодействия".
Также Microsoft добавила режим Learn Live, где Mico превращается в интерактивного репетитора — не даёт готовые ответы, а "направляет к пониманию концепций" через визуальные подсказки и доски.
Но есть минус - Mico пока доступен только в США, Великобритании и Канаде. Остальной мир - через пару недель.
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Показать полностью

Анимация фото онлайн: как сделать портрет живым с помощью искусственного интеллекта
Анимация фото онлайн открывает новые горизонты в создании визуального контента. В этой статье мы рассмотрим, как сделать статичный портрет живым с помощью искусственного интеллекта. Динамичные анимации, в свою очередь, способствуют привлечению внимания широкой аудитории.
Анимация портретов: как искусственный интеллект оживляет фотографии
Впервые увидев, как на старой фотографии сестра улыбается и кивает, испытал восторг и удивление. Еще недавно такие технологии казались фантастикой — теперь же любой желающий может буквально за пару минут вдохнуть жизнь в старый снимок, добавив мимику, эмоции и даже легкое движение. Рассказываю, как устроен процесс и где получить по-настоящему впечатляющий результат без сложностей.
Современные технологии оживления фото: что изменилось в 2025 году
За последний год сфера анимации портретов совершила настоящий прорыв. Если раньше требовались навыки работы с графикой и мощный компьютер, сейчас достаточно смартфона и пары тапов по экрану.
Главная идея проста: нейросеть сканирует портрет, определяет характерные черты, а затем создает правдоподобную анимацию выражений, движений головы, иногда даже фона. Самые современные сервисы умеют добавлять объем, звук, а также настраивать движения по короткому текстовому описанию.
Однако качество зависит от сервиса: одни сервисы выдают неестественные эмоции или странные движения, другие могут сильно портить исходное фото.
Для своих проб и тестов чаще всего использую бота с поддержкой Kling AI — здесь анимация портретов занимает считаные минуты и не требует обхода блокировок, что очень удобно в российских условиях.
Как быстро сделать анимацию фотографии за 5 минут
Если хочется попробовать оживить портрет ради интереса, вот пошаговая инструкция:
Найдите хороший снимок с четким лицом (лучше, если это классический портрет без аксессуаров и с нейтральной мимикой)
Загрузите изображение в выбранный онлайн сервис (список сервисов ниже)
Выберите вид анимации или опишите желаемое действие ("улыбнуться", "повернуть голову", "подмигнуть")
Подождите 20-60 секунд — готово!
Сохраните результат и расскажите о нем в соцсетях
На первый взгляд все просто, но в деталях кроются важные моменты, напрямую влияющие на итог. Например, именно правильный выбор начального изображения часто определяет успех.
Что действительно дает эффект: подбор лучших сервисов для оживления фото
За последние месяцы попробовал почти все актуальные платформы для анимации фото. Делюсь подборкой инструментов, которые реально заслуживают внимания.
Kling AI
В 2025 году Kling AI стал одним из ведущих решений для превращения снимков в видеоролики. Особенно хорошо подходит для учебных проектов за счет точной передачи движений и физики.
Преимущества:
Картинка в FullHD (до 1080p)
Длина ролика до 10 секунд
Реалистичная физика движения
Поддержка сложных промтов на английском
Идеален для технических презентаций
Недостатки:
Меню только на английском
Бесплатных генераций немного
Время обработки: 2–5 минут
Для стабильной работы нужен VPN из России
Воспользоваться сервисом можно на официальном сайте или через бота с поддержкой Kling AI.
Veo 3
Один из самых быстрых сервисов для анимации изображений, популярен у специалистов по соцсетям.
Преимущества:
Мгновенная обработка (от 10 до 15 секунд)
Прямая интеграция с соцсетями
Возможность добавить музыкальное сопровождение
Качественная анимация
Недостатки:
После тестового доступа сервис становится платным
Часть функций заблокирована в базовой версии
Доступен на официальном сайте Veo 3, а также через российский бот с поддержкой VEO 3.
Luma AI Dream Machine
Этот сервис выделяется созданием ярких 3D-эффектов и объемного параллакса.
Преимущества:
Эффектная глубина 3D
Высокая четкость анимации
Гибкие настройки
Профессиональный уровень результата
Недостатки:
Освоить сервис сложнее
Требуется мощное оборудование
Стоимость выше средней
Потестировать можно на официальном сайте Luma AI.
Runway (Gen-2 / Motion Brush)
Передовой инструмент для работы с анимацией, созданный специально для авторов контента, отличающийся возможностью анимировать отдельные элементы изображения.
Преимущества:
Полный контроль над движением: можно самостоятельно выбрать, какие детали изображения будут оживать
Высокий уровень проработки
Возможность сочетания с другими профессиональными сервисами
Результаты, максимально приближенные к реальности
Недостатки:
Дорогой доступ
Осваивать не так просто — потребуется время на обучение
Необходимы знания в цифровых технологиях
Инструмент доступен на официальном сайте Runway.
Эффективные приемы для создания "живых" анимаций
Хотите, чтобы ваша анимация выглядела максимально натурально? Вот несколько советов, которые реально работают:
Грамотная подготовка фотографии
База успеха — качественная исходная картинка. Обратите внимание на такие параметры:
Размер — минимум 1024×1024 точек
Свет — мягкий, без сильных контрастов
Эмоции — спокойное или приветливое выражение лица
Задний план — однотонный или без излишеств
Положение — взгляд прямо в объектив, без резких поворотов
Кстати, восстановленные черно-белые снимки иногда дают неожиданный вау-эффект, особенно если ими заняться в фоторедакторах до загрузки.
Смешивание движений
Почерпнул этот подход у опытных пользователей. Делайте несколько вариантов анимации одной фотографии с разными движениями, а после объединяйте их в видеоредакторе. Итог — более продолжительное и живое видео.
Добавление звука
Музыка или голос делают анимацию правдоподобнее. Сервис Luma Ray умеет автоматически накладывать фоновые звуки, но можно добавить их и самостоятельно в редакторе.
Применение текстовых промтов
Чем точнее сформулируете желаемое действие, тем интереснее получится результат. Например, вместо туманного "пусть двигается" дайте четкое указание:
"Плавно поворачивает голову вправо, слегка улыбаясь"
"Моргает и чуть кивает, подтверждая согласие"
"Глядит вдаль с задумчивым лицом"
Типичные ошибки и способы их избежать
Проводя работу с множеством снимков, часто сталкивался с типичными трудностями. Кратко расскажу, что важно учитывать:
Искажение лица
Проблема: На анимации черты лица выглядят непривычно или даже пугают.
Рекомендация: Используйте четкие и яркие фотографии, где лицо хорошо видно и оно обращено прямо к объективу. Старайтесь избегать необычных выражений и сложных углов съемки.
Резкость движений
Проблема: Анимация кажется дерганой и неестественной.
Рекомендация: Выбирайте сервисы, позволяющие устанавливать плавность движений. В промтах добавляйте слова "плавно" или "медленно". Некоторые платформы дают возможность управлять скоростью и мягкостью движений.
Ошибки с прической и задним планом
Проблема: Волосы либо фон искажаются при анимации.
Рекомендация: Для ответственных задач выбирайте профессиональные решения, например Runway с масками или частичной анимацией. Хорошо помогают и снимки на простом фоне.
Неестественный взгляд
Проблема: При анимации глаза выглядят "стеклянными" или пустыми.
Рекомендация: В промтах акцентируйте внимание на глазах: "живой взгляд", "естественное моргание". В некоторых сервисах есть отдельные настройки для проработки глаз.
Важные вопросы этики и права при анимации фото
Технологии анимации фото вызывают серьезные вопросы этики. Вот правила, которыми стоит руководствоваться:
Получайте разрешение, если работаете с фотографиями реальных людей, особенно при публикации.
Будьте внимательны с историческими персонажами — ряд сервисов ограничивает создание контента, способного ввести в заблуждение.
При публикации обязательно указывайте, что использован искусственный интеллект, особенно если ролик может быть воспринят как настоящий.
Соблюдайте авторские права на исходные фото.
Большинство платформ имеют системы проверки, не допускающие создание вводящего в заблуждение или оскорбительного материала.
Примеры использования созданных анимаций с помощью ИИ
Технология анимации фотографий активно внедряется в разные сферы:
Личное применение
Воссоздание движущихся портретов из архивных семейных снимков
Создание оригинальных поздравлений
Генерация персональных аватаров для социальных платформ
Профессиональные задачи
Разработка маркетинговых материалов (анимация изображений товаров)
Создание обучающих материалов (оживление исторических личностей)
Музейные проекты (интерактивные выставки)
Подготовка визуализаций для кино (эскизные анимированные сцены)
Вспоминаю пример, когда музей современного искусства провел выставку цифровых портретов, которые оживали и следили за посетителями. Эффект был поразительный — картины словно вступали в диалог с аудиторией.
Фото модели, созданной по промту в нейросети Midjourney было анимировано по промту в Kling:
Девушка медленно идёт по подиуму, плавно покачивая бедрами, останавливается, поднимает правую руку вверх, ладонью проводит по щеке, ладонь мягко скользит вниз по шее, по груди, ладонью медленно проводит по талии и бедру
Вывод:
ИИ-анимирование фотографий за короткое время прошло путь от малодоступных экспериментов до массовых решений. Сегодня воспользоваться подобными инструментами может практически каждый, не имея специальных знаний или больших вложений.
Итоги могут быть как веселыми интернет-экспериментами, так и серьезными творческими или бизнес-проектами. Всё определяется задачами, выбранными платформами и стараниями.
Главное — подобрать качественный исходник и ясно сформулировать запрос. А дальше не бойтесь пробовать, сравнивайте сервисы и делитесь своими находками.
И правда, самые яркие результаты достигаются, когда сочетаются разные современные технологии. Например, можно сначала восстановить старое фото с помощью нейросетей для реставрации, затем вдохнуть в него жизнь, а после подобрать гармоничную озвучку или добавить музыку.
Экспериментируйте, создавайте необычное и не забывайте: именно за этими решениями — будущее визуального контента.
Еще больше полезного о нейросетях на нашем форуме.
Показать полностью
1

Вот как должен работать общий ИИ (AGI)
Из доклада Ричарда Саттона об архитектуре OaK: взляд на путь к сверхразуму через опыт. Reinforcement Learning Conference.
Перевод полной лекции смотрите здесь https://www.youtube.com/watch?v=tIkygr96Dg4