Закреплено

Искусственный интеллект
4 818 постов
•
11 398 подписчиков
0 просмотренных постов скрыто


Лучшие советы по созданию эффективных промптов для ChatGPT: инструкции и шаблоны
Хотите узнать, как задать ChatGPT такой вопрос, чтобы получить максимально точный и полезный ответ? В этом материале собраны практические способы составления промптов для нейросети ChatGPT — даны инструкции и советы для работы, учебы, личных проектов и бизнеса. Поговорим о структуре промптов, правильной подаче информации, ограничениях, типичных ошибках, а также я приведу шаблоны, которые можно легко применить под свои задачи.

Лучшие советы по созданию эффективных промптов для ChatGPT: инструкции и шаблоны
Промпт — это текстовая инструкция или запрос, которую отправляют ChatGPT с целью получить ответ:
Чем подробнее и точнее составлен промпт, тем выше качество результата.
Промпт может быть лаконичным ("Поделись шуткой") или развернутым — с контекстом, указаниями, ограничениями и ролями.
Не допускайте двусмысленности, обязательно задавайте желаемый стиль, формат, длину ответа.
Системные промпты настраивают правила работы и общения ChatGPT.
Ролевые промпты помогают создавать нужные сценарии, например: "Представь, что ты профессиональный маркетолог", "Представь себя преподавателем английского", "Твоя роль - дизайнер с многолетним опытом работы".
10 лучших советов для работы с ChatGPT: шаблоны промтов
Совет 1. Четко формулируйте цель и задачу
Чем яснее и конкретнее задача, тем выше вероятность получить релевантный и развернутый ответ.
Шаблон:
Напиши краткую инструкцию по [теме] для [аудитории] с понятными примерами и простыми объяснениями.
Совет 2. Уточняйте формат и размер ответа
Указание формата (например, список, эссе, поэтапное руководство) помогает получить логичный результат.
Шаблон:
Составь перечень из [количество] пунктов по теме [тема], в каждом пункте — короткое описание и пример.
Совет 3. Добавляйте контекст и важные детали
Контекст позволяет ChatGPT лучше вникнуть в суть задачи и подобрать подходящие примеры.
Шаблон:
Объясни [термин] для [группы пользователей], используя современные примеры из [сферы дизайна].
Совет 4. Сужай или расширяй границы ответа
Четкое ограничение помогает избежать воды или, наоборот, получить подробную информацию.
Шаблон:
Опиши плюсы и минусы [решения/темы] в рамках [3-5 предложений] для [целевой аудитории/широкой аудитории].
Совет 5. Используй системные промпты для контроля стиля
Системные промпты определяют стиль, тональность, уровень официальности и даже "характер" ChatGPT.
Шаблон:
Ты — опытный [профессия], который разъясняет сложные вопросы простыми словами. Напиши материал на тему [вопрос/дизайна] для широкой аудитории.
Совет 6. Запускай ролевые промпты для создания сценариев
Ролевые промпты превращают ChatGPT в эксперта, наставника, интервьюера и других персонажей.
Шаблон:
Вообрази, что ты журналист, берущий интервью у профессионала по [теме]. Придумай 5 интересных вопросов и ответы к ним.
Совет 7. Запрашивай примеры "до и после" для наглядности
Сравнение "до/после" помогает понять, как меняется стиль, структура или решение.
Шаблон:
Покажи пример неудачного и удачного [описания вакансии для менеджера по продажам], поясни различия.
Совет 8. Ограничивай стиль, язык, объем
Ограничения делают ответ лаконичным и удобным для применения.
Шаблон:
Сделай краткое описание товара (до 100 символов) для онлайн-магазина в доброжелательном тоне.
Совет 9. Спрашивай о типичных ошибках и способах их избежать
ChatGPT способен не только решать задачи, но и предупреждать частые промахи.
Шаблон:
Опиши 5 наиболее распространенных ошибок при [старте рекламной кампании в соцсетях] и способы их предотвратить.
Совет 10. Проси чек-лист или последовательность действий
Чек-листы помогают упорядочить задачи и ничего не упустить.
Шаблон:
Сделай чек-лист из 7 этапов для подготовки презентации по теме [тема] для [аудитории].
Личный опыт: как работа с ChatGPT влияет на повседневную работу и креатив
Когда впервые познакомилась с ChatGPT, все выглядело немного загадочно и даже магически. Иногда ответы поражали точностью, а иногда — были совершенно не по теме. Со временем стало ясно: результат зависит почти полностью от того, насколько четко и понятно задан промпт. Например, когда возникла необходимость в свежих идеях для оформления упаковки, была сформулирована следующая просьба: "Предложи 5 вариантов минималистичного дизайна коробки для чая, ориентированных на молодых покупателей, с учетом экостиля". Ответы оказались настолько интересными, что стали основой реального проекта. В случае размытых запросов, таких как "Придумай дизайн упаковки", результаты зачастую носили скучный и шаблонный характер.
Часто использую системный промт, чтобы ChatGPT сразу работал в нужном русле: "Ты — специалист по нейросетям, объясняешь всё простыми словами". Также запрашиваются детальные инструкции, чтобы не забыть важное. Благодаря ролевым промтам легко проигрывать деловые переговоры или готовиться к собеседованиям, моделируя различные сценарии.
Распространенные ошибки при работе с ChatGPT и пути их избежать
Слишком абстрактные промты.
Пример: "Расскажи про маркетинг."
Как быть? — Сужай запрос: "Опиши методы продвижения малого бизнеса в Instagram."
Недостаток информации.
Пример: "Сделай описание."
Как поступить? — Добавь подробности: "Сделай описание сервиса по доставке еды для лендинга, ориентированного на молодых специалистов."
Неуказанный формат.
Пример: "Объясни процесс."
Что делать? — Поясни, в каком виде нужен ответ: "Объясни регистрацию пользователя шаг за шагом с примерами."
Отсутствие ограничений.
Пример: "Напиши статью."
Как действовать? — Определи рамки: "Напиши статью не длиннее 500 слов, с дружелюбным тоном, для широкой аудитории."
Слишком сложные термины.
Пример: "Опиши MVP с точки зрения юнит-экономики."
Рекомендация — Попроси объяснить проще: "Объясни, что такое MVP, без профессионального жаргона, для студентов."
Некорректное применение ролей.
Пример: "Представься профессионалом."
Что делать? — Сформулируй точнее: "Ты — маркетолог, рассказываешь, как продвигать новый стартап на платформе TikTok."
Нет четких рамок по объему задания.
Пример: "Поделись советами по продажам."
Что делать? — Уточни: "Приведи 7 рекомендаций по увеличению продаж в онлайн-магазине электроники."
Отсутствие контроля результата.
Пример: Использовать ответ без доработки.
Что делать? — Проведи проверку, внеси коррективы, измени промпт и повтори запрос при необходимости.
Чек-лист: Создание эффективных промптов для ChatGPT
Поставь цель и обозначь задачи
Раскрой детали и контекст
Определи желаемый формат и размер
Укажи ограничения или пожелания
Используй системные либо ролевые промты
Проверь результат, при необходимости измени промпт
Не стесняйся пробовать новые подходы и учиться на своем опыте!
Как нейросети меняют наш мир: взгляд в будущее
Уверена, что развитие нейронных сетей — это не просто автоматизация рутинных дел, а творческое партнерство между человеком и ИИ. Искусственный интеллект не заменит настоящую креативность, но даст каждому возможность быстрее находить идеи, придумывать необычные решения, учиться и развиваться. Всё больше людей применяют нейросети для анализа информации в разных отраслях, придумывают новые продукты, оптимизируют рабочие процессы. В обычной жизни ChatGPT помогает осваивать новое, составлять планы, писать тексты, поддерживать настрой даже в сложных ситуациях. Ключ к ChatGPT — уметь правильно составлять промпты, ведь это превращает ИИ из инструмента в надежного помощника и соавтора. Уже в ближайшем будущем, нейросети станут неотъемлемым элементом бизнеса и творчества, а навык создания грамотных промптов — одним из самых востребованных.
Показать полностью
1

10 эффективных приемов для работы с ChatGPT в дизайне: советы, шаблоны, идеи
В этой статье мы рассмотрим 10 эффективных приемов для работы с ChatGPT в дизайне, включая советы, шаблоны и идеи, которые помогут вам раскрыть потенциал этого инструмента. ChatGPT может служить отличным помощником на всех этапах процесса дизайна: от генерации идей до создания текстов для презентаций. Используя возможности ChatGPT, можно быстро создавать прототипы, получать обратную связь и адаптировать существующие проекты под новые условия. Важно помнить, что ChatGPT не заменяет дизайнера, а представляет собой мощный инструмент, который при правильном использовании может значительно повысить продуктивность и креативность.

10 эффективных приемов для работы с ChatGPT в дизайне: советы, шаблоны, идеи
Как нейросети открывают новые возможности для дизайнеров
ChatGPT — это не просто виртуальный собеседник: при осознанном подходе искусственный интеллект становится для дизайнера настоящим соавтором идей.
Рутинные задачи легко автоматизировать, освобождая время для поиска вдохновения и реализации творческих планов.
Четкие и подробные запросы — ключ к продуктивному диалогу с ИИ и получению интересных решений.
Нейронные сети полезны не только для поиска идей, но и для обучения, анализа, а иногда и для поддержки во время творческих кризисов.
Эксперименты и проработка новых концепций с помощью ИИ позволяют взглянуть на дизайн под другим углом и выработать свой узнаваемый стиль.
10 практических советов по использованию ChatGPT для дизайнеров
Я подготовила подборку шаблонов промтов для ChatGPT, которые помогут выстроить эффективное взаимодействие с искусственным интеллектом для разных задач в сфере дизайна.
Совет 1. Генерация свежих идей для проектов
Если творческий запал иссяк, ChatGPT в считанные минуты предложит массу необычных и креативных концепций. Неважно, работаете ли вы над фирменным стилем, созданием сайта или иллюстрациями — нейросеть всегда предложит интересные варианты развития проекта.
Пример структуры запроса:
Разработай 10 оригинальных идей логотипа для компании, работающей в [название отрасли]. Для каждой идеи опиши ключевой замысел, используемые цвета и возможные визуальные образы-ассоциации.
Совет 2. Как быстро создавать тексты для презентаций и портфолио
Бывает, что в голове дизайнера крутится масса картинок, а нужные слова не складываются. ChatGPT помогает легко составлять привлекательные описания проектов, презентаций и портфолио, подстраиваясь под целевую аудиторию.
Пример структуры запроса:
Сделай короткое и интересное описание (до 150 слов) для портфолио по теме [тематика проекта]. Сделай акцент на особенностях и преимуществах для заказчика.
Совет 3. Составление брифов и технических заданий
Грамотное взаимодействие с клиентами и командой начинается с продуманного брифа. ChatGPT помогает быстро создавать чек-листы для сбора информации и шаблоны ТЗ, облегчая рутинную работу.
Пример структуры запроса:
Составь детальный шаблон брифа для заказчика, желающего получить [вид дизайнерских услуг: сайт, логотип, упаковку]. Внеси основные вопросы о стиле, палитре, целевой аудитории и ожиданиях от проекта.
Совет 4. Выбор цветовых сочетаний и создание мудбордов
Создание гармоничных цветовых решений и мудбордов — тонкое мастерство. ChatGPT может выступать в роли цветового консультанта, предлагая палитры и описывая атмосферу для проектов разного направления.
Пример структуры запроса:
Подбери 5 цветовых схем для [формата проекта, например, эко-бренда, мобильного приложения]. Для каждой палитры опиши настроение и чувства, которые она вызывает у зрителя.
Совет 5. Анализ и доработка дизайн-концепций
ИИ способен стать требовательным советчиком: оценить эскиз или идею, выделить недочеты и порекомендовать, как усовершенствовать композицию, подобрать цвета или шрифты.
Пример структуры запроса:
Разбери следующую дизайн-концепцию: [подробно изложите вашу задумку]. Отметь плюсы и минусы и предложи три конкретных способа улучшить работу.
Совет 6. Придумываем идеи для контента в соцсетях
Управлять персональным или корпоративным профилем — это постоянный креатив. ChatGPT помогает находить свежие темы для постов, сторис, а также подбирать хэштеги для социальных платформ.
Пример структуры запроса:
Придумай 7 оригинальных вариантов публикаций для Instagram-аккаунта ландшафтного дизайнера, работающего в стиле хай-тек или сканди-дизайн. Предложи тексты для постов и подходящие русскоязычные хэштеги.
Совет 7. Оформление описаний для товаров в интернет-магазине
Краткое описание товара — это не только перечисление характеристик, но и способ заинтересовать покупателя. ChatGPT пригодится для создания ярких, понятных и мотивирующих текстов.
Пример структуры запроса:
Составь интересное и подробное описание [товара, например, керамической кружки ручной работы, уникального ежедневника]. Укажи сильные стороны, основные достоинства и предложи короткий рекламный слоган.
Совет 8. Разработка сценариев для обучающих роликов и курсов
Искусственный интеллект помогает структурировать мысли и писать сценарии для мастер-классов или видеоуроков, делая их последовательными и доступными для зрителей.
Пример структуры запроса:
Создай сценарий для пятиминутного обучающего видео о создании визитки в [программе, например, CorelDRAW]. Включи вступление, пошаговые действия и финальный call-to-action.
Совет 9. Получение отзывов и запуск опросов
Чтобы сервис был полезен, важно слушать пользователей. ChatGPT помогает составлять анкеты, собирать мнения и быстро анализировать обратную связь для выявления новых идей.
Пример структуры запроса:
Сделай опрос с 10 вопросами для оценки нового интерфейса сайта. Добавь вопросы о юзабилити, визуальной стороне и пожеланиях по усовершенствованию.
Совет 10. Осваиваем новые знания и прокачиваем умения
Нейросети могут быть не только помощниками в работе, но и наставниками в обучении. С помощью ChatGPT можно тренировать новые навыки, разбираться в сложных вопросах и получать советы по дальнейшему развитию.
Пример структуры запроса:
Изучаю [название программы или направление, например, Photoshop, основы UI/UX] и хочу прокачать практические умения. Подскажи, какие упражнения попробовать и задай вопросы для самопроверки.
Личный опыт работы с ChatGPT
Пару месяцев назад я работала над айдентикой уютного эко-бистро и неожиданно столкнулась с творческим тупиком. Заказчик мечтал о чем-то "естественном и динамичном", а мои варианты казались ему слишком шаблонными. Тогда я решила применить первый совет — попросила ChatGPT придумать концепции логотипа, указав акцент на экологичности и природных оттенках. Искусственный интеллект предложил несколько эскизов, среди которых был логотип с силуэтом листа и каплей воды. Эта задумка меня вдохновила, и я доработала ее до финального варианта. Заказчик остался доволен, а я убедилась на практике, как ИИ помогает находить свежие идеи, когда креатив иссяк.
Типичные ошибки при работе с ChatGPT и как их избежать
Многие рассчитывают, что нейросеть сразу даст идеальный ответ и поймет все нюансы без пояснений. Главная ошибка — слишком общие или неясные промты. Например, просьба "Подбери цвета" без описания задачи и нужного настроения часто выдает случайные и бесполезные предложения. Еще одна ошибка — не перепроверять и не дорабатывать генерации: иногда ИИ может придумать несуществующие детали или использовать заезженные шаблоны.
Чтобы не допускать таких промахов:
Старайтесь писать промты максимально чётко и с деталями.
Обязательно указывайте задачи, целевую аудиторию и нужный итог.
Редактируйте и адаптируйте сгенерированный текст под ваши задачи и стиль.
Не бойтесь экспериментировать: меняйте формулировки, задавайте дополнительные вопросы, комбинируйте разные идеи от ИИ.
Будущее искусственного интеллекта и дизайна
Наблюдая за стремительным ростом нейросетей, представляю время, когда искусственный интеллект станет важным участником творческого пути. Нейросети не заменяют дизайнеров — они превращаются в партнеров, освобождая время для поиска новых идей и самовыражения вместо выполнения однообразных задач. Новые технологии открывают двери для быстрых экспериментов, индивидуального обучения и поиска вдохновения. Благодаря ИИ появляется шанс создавать работы, которые находят отклик и запоминаются, ведь технические детали и анализ переходят к интеллектуальным помощникам. Самое важное — не бояться пробовать новое, учиться задавать точные вопросы и относиться к нейросетям как к союзникам. Будущее дизайнерской сферы — это сотрудничество между фантазией человека и искусственным интеллектом, и этот этап уже наступил.
Показать полностью
1
Мультимодальный RAG: когда контекста недостаточно, чтобы понять документ
Автор: Денис Аветисян
Все давно устали от того, что извлечение осмысленных знаний из сложных, неструктурированных документов остаётся непосильной задачей, тормозящей доступ к информации. Но, когда мы уже думали, что знаем всё о методах улучшения понимания документов, появляется "Scaling Beyond Context: A Survey of Multimodal Retrieval-Augmented Generation for Document Understanding", и внезапно оказывается, что дело не только в масштабировании языковых моделей, но и в умении интегрировать знания из разных источников. И главный вопрос: действительно ли ключ к настоящему пониманию документов лежит в сложном симбиозе текста, изображений и таблиц, или это очередная технологическая иллюзия, приправленная модными словечками?
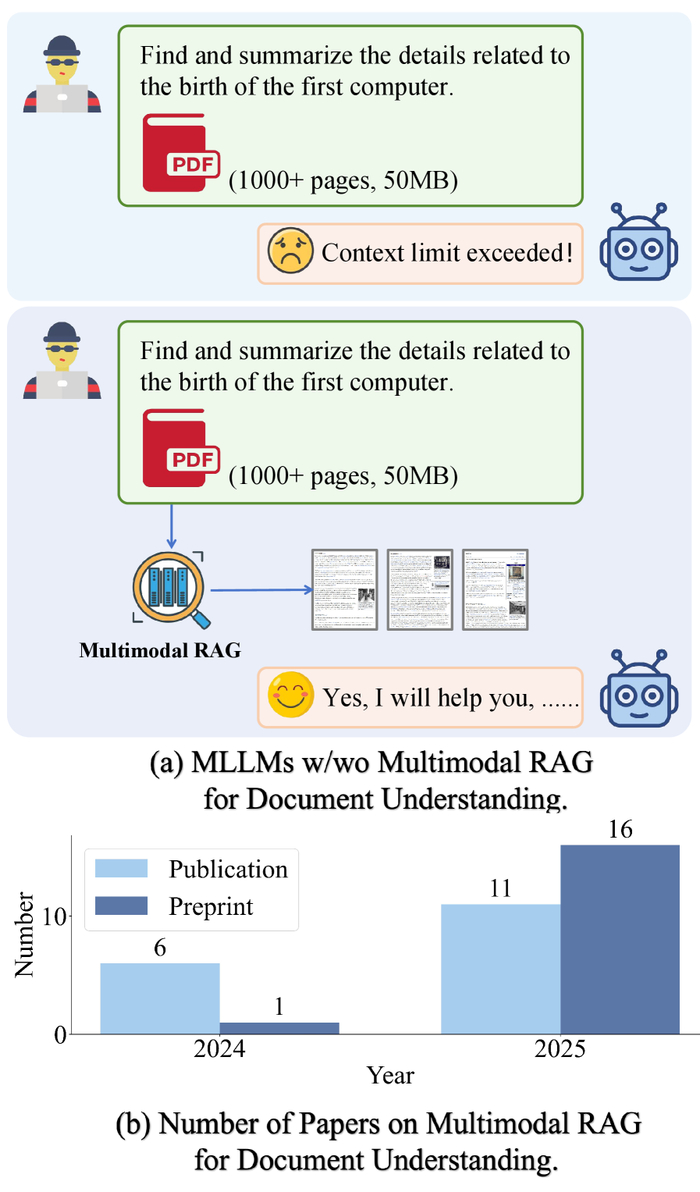
Мультимодальный RAG – пока ещё элегантная теория понимания документов, но уже сейчас видно, как растёт интерес к ней. Судя по количеству публикаций, скоро станет понятно, где эта технология действительно работает, а где – нет.
Пазл из Обрывков: О Челленджах Понимания Документов
Традиционные методы извлечения знаний из документов, особенно сложных и неструктурированных, неизменно наталкиваются на ограничения. Они как попытки собрать пазл из обрывков, где большая часть деталей утеряна. Знания, запертые в этих документах, остаются недоступными, а потенциал – нереализованным. Это как построить дорогу к сокровищам, но потерять карту.
Большие языковые модели (LLM), несомненно, впечатляют своей мощью, но и они не лишены недостатков. Их способность к интерпретации ограничена отсутствием надлежащего контекста, необходимого для точного и надёжного понимания. Они как блестящие инструменты в руках умельца, но без понимания принципов работы.
Простое увеличение масштаба LLM не решает проблему. Это как пытаться поднять тяжёлый груз, увеличивая количество рук, но не улучшая технику. Требуется более тонкий подход к интеграции знаний, чтобы действительно понять содержание документа. Недостаточно просто обработать текст – нужно понять его смысл, контекст и взаимосвязи.
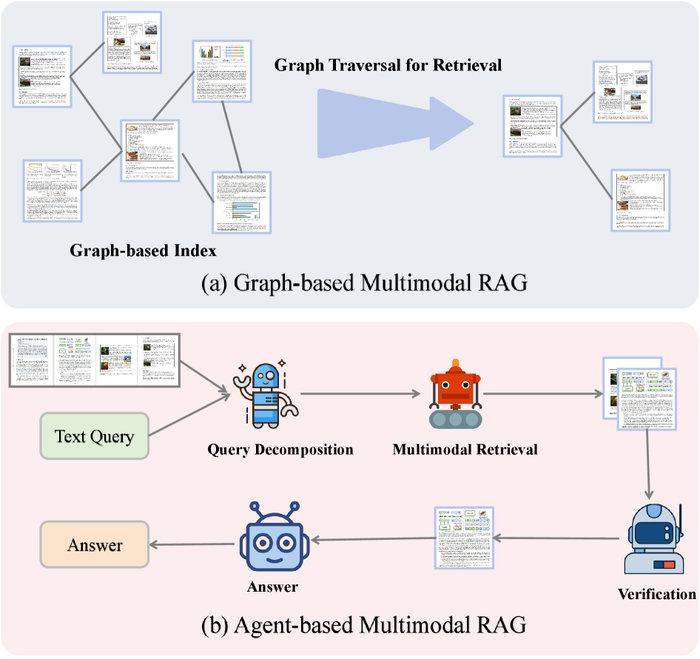
Гибридные улучшения для мультимодального RAG.(a) На основе графов: документы/элементы формируют индекс графа, и поиск осуществляется путём обхода графа для обнаружения соответствующих окрестностей.
Необходим более глубокий анализ, учитывающий структуру документа, взаимосвязи между его элементами и контекст, в котором он был создан. Это не просто задача обработки естественного языка, а комплексная проблема, требующая междисциплинарного подхода. Иначе говоря, мы не просто автоматизируем чтение – мы пытаемся воссоздать процесс понимания.
Иногда кажется, что все эти новые технологии – лишь способ усложнить и без того сложную задачу. Но, возможно, именно в этой сложности и кроется ключ к решению. В конце концов, идеальных решений не бывает. Всегда приходится идти на компромисс. И, как показывает опыт, архитектура – это не схема, а компромисс, переживший деплой.
RAG: Шпаргалка для LLM или Реальный Прорыв?
Идея Retrieval-Augmented Generation (RAG) – это, конечно, не откровение. Просто способ заставить большие языковые модели (LLM) меньше гадать и больше опираться на проверенные факты. Вместо того, чтобы хранить все знания внутри параметров модели (что, как мы все знаем, быстро становится невозможным), RAG позволяет LLM "подглядывать" в внешние базы данных. Это как дать студенту шпаргалку – снижает зависимость от памяти, но повышает шанс выдать правильный ответ. В сущности, RAG дополняет параметрическую память LLM, предоставляя доступ к актуальной информации и улучшая точность и фактическую согласованность ответов.
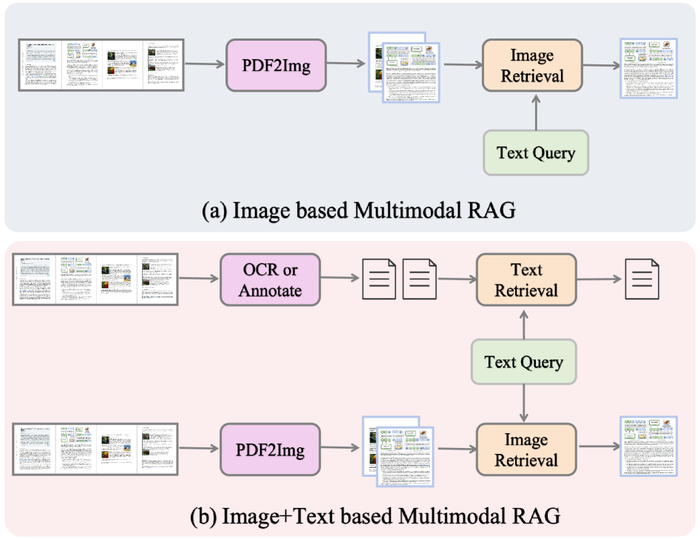
(a) поиск на основе изображений извлекает информацию исключительно из изображений страниц, предлагая эффективность, но ограниченные текстовые детали; (b) поиск на основе изображений и текста интегрирует OCR/аннотации с визуальными функциями
Однако, если копнуть глубже, то стандартные подходы RAG часто рассматривают документы как монолитные блоки текста. Игнорируется потенциал мультимодальных данных – таблиц, графиков, изображений. Это как пытаться понять финансовый отчет, читая только сплошной текст – можно упустить важные детали. Авторы, конечно, уверяют, что это "революционный подход", но мы-то знаем, что всё уже было в 2012-м, только называлось иначе. Важно понимать, что простое добавление OCR – это лишь первый шаг. Нужно научиться извлекать смысл из структуры документа, а это, поверьте, задача нетривиальная.
В итоге, задача состоит не только в том, чтобы найти релевантную информацию, но и в том, чтобы представить её в формате, понятном для LLM. Иначе, всё это превращается в ещё один источник шума. Если тесты зелёные – значит, они ничего не проверяют. Нужно искать способы повысить эффективность и точность мультимодального поиска, и тогда, возможно, мы сможем приблизиться к действительно разумной системе.
Мультимодальный RAG: Больше, чем Просто Объединение Текста и Изображений?
Разумеется, авторы утверждают, что мультимодальный RAG открывает новые горизонты в понимании документов. Что ж, посмотрим, как долго продлится этот оптимизм, прежде чем столкнёмся с реальными ограничениями масштабируемости. В целом, идея проста: объединить текст и изображения, чтобы получить более полное представление о содержании и структуре документа. Звучит красиво, но всегда есть нюансы.
Они описывают, как кодирование изображений и текста создаёт единые векторные представления, улавливающие связи между визуальными и текстовыми элементами. Единые векторные представления… Как будто это решит все проблемы. В реальности, получение этих представлений требует ресурсов, а поддержка их актуальности – постоянных усилий. Но, ладно, предположим, что это работает.
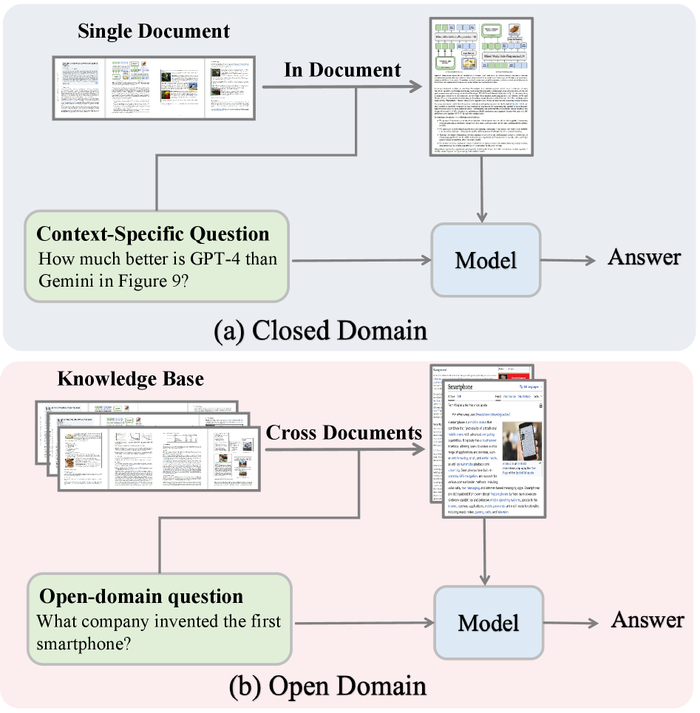
(a) В закрытом домене модель использует извлечение документов из одного документа для ответа на вопросы (b) В открытом домене модель полагается на извлечение документов из нескольких документов для ответа на вопросы с открытым концом
Авторы утверждают, что такой подход значительно улучшает производительность в задачах визуального вопросно-ответного анализа (VQA) и комплексного анализа документов. VQA… ещё один модный термин, который, вероятно, станет бесполезным через год. Тем не менее, если это действительно работает, это может быть полезно, хотя бы временно. Они приводят примеры, как их система может отвечать на вопросы о сложных диаграммах и таблицах, которые раньше были недоступны для автоматического анализа. Обычно, такие системы либо терпят неудачу, либо выдают нелепые ответы. Но, видимо, в этот раз что-то получилось.
В общем, они описывают некий “прорыв”, который, по их мнению, изменит мир. Посмотрим, как это всё будет выглядеть в реальности. В любом случае, это ещё один шаг на пути к автоматизации анализа документов. И, если честно, это хоть какая-то надежда в этом потоке бесполезных инноваций.
Уточнение и Расширение Мультимодального RAG: Теория или Практика?
Развернутые исследования в области Multimodal RAG не остались без внимания к практической применимости. Методы, такие как Closed-Domain RAG и Open-Domain RAG, расширяют возможности применения к как отдельным документам, так и к крупным корпусам. Это, конечно, не решает всех проблем, но позволяет хотя бы попытаться выжать хоть какую-то пользу из существующих данных.
Дальнейшее развитие не обошлось без попыток усложнить архитектуру. Graph-Based Retrieval и Agent-Based RAG призваны улучшить процесс поиска, обеспечивая более эффективное обнаружение знаний и рассуждения. В теории – да, звучит неплохо. На практике же, часто это приводит лишь к увеличению кодовой базы и усложнению отладки. Но, как говорится, попытка не пытка.
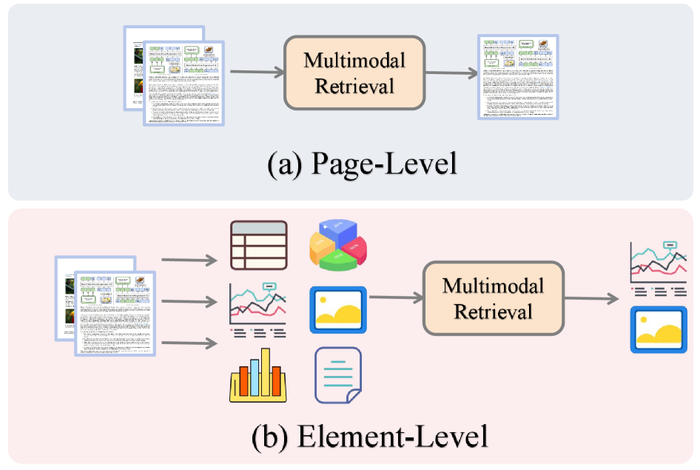
(a) Уровень страницы: целые страницы кодируются и ранжируются как единые целые. (b) Уровень элемента: страницы декомпозируются на таблицы, диаграммы, изображения и текстовые блоки
Однако, реальная проблема, как обычно, кроется в деталях. Решение таких задач, как обработка длинных документов, снижение вероятности галлюцинаций и обеспечение детального представления документов, остаются критически важными для развертывания надежных и эффективных систем RAG. Каждая "революционная" технология рано или поздно становится техническим долгом. Мы не нуждаемся в большем количестве микросервисов — нам нужно меньше иллюзий. В конечном счете, необходимо помнить, что даже самая изящная архитектура станет анекдотом, если её не поддерживать и не адаптировать к реальным условиям эксплуатации.
Попытки решить эти проблемы, безусловно, важны, но не стоит забывать о здравом смысле. В конечном итоге, успех любой системы зависит не от сложности её архитектуры, а от её способности решать реальные задачи в реальных условиях. И, как обычно, самое сложное – это не написать код, а заставить его работать в продакшене.
Вся эта история с Multimodal RAG напоминает старый анекдот. Мы строим сложные системы, чтобы LLM "помнили" больше, но забываем, что продакшен всегда найдёт способ всё сломать. Как говорил Блез Паскаль: “Все великие дела требуют времени”. Только в нашем случае, “время” – это скорость, с которой появляется новый техдолг, связанный с обслуживанием этих самых “великих” систем для визуального понимания документов. Мы не просто извлекаем информацию, мы создаём новую сложность, которую потом будем героически рефакторить… то есть, реанимировать надежду.
Что дальше?
Итак, мы построили красивые мосты из LLM и визуальных документов. И что? Каждая «революционная» техника RAG рано или поздно столкнётся с реальностью продакшена. Бумажные сканеры будут давать косяки, OCR — галлюцинировать, а пользователи — задавать вопросы, которые эти системы просто не смогут обработать. Это не критика, это… закономерность. Всё, что можно задеплоить — однажды упадёт.
Настоящий вызов – не в увеличении точности на benchmark-ах, а в создании систем, которые изящно обрабатывают неопределенность. Нужны методы, позволяющие моделям не просто "находить" информацию, а понимать, что они её не знают, и уметь корректно отвечать: «Извините, я не уверен». И, конечно, любая абстракция умирает от продакшена, поэтому нас ждёт бесконечная гонка за устойчивостью к шуму и искажениям реальных документов.
Агентские системы и графы знаний – это, конечно, интересно, но давайте признаем: это просто попытки усложнить проблему, чтобы хоть как-то её контролировать. В конечном счёте, успех будет зависеть от того, насколько хорошо мы сможем смириться с несовершенством и научим модели красиво умирать. Но зато красиво умирает.
Показать полностью
5

Google Gemini совершает рывок: трафик платформы удвоился, пока ChatGPT теряет лидерство

ИИ: Google Gemini за год увеличил свою долю почти вдвое — с 6,4% до 12,9%, стремительно догоняя ChatGPT
Историческая рокировка на рынке генеративного ИИ: Google Gemini за год увеличил свою долю почти вдвое — с 6,4% до 12,9%, стремительно догоняя ChatGPT, который еще недавно казался недостижимым лидером. Что стоит за этим феноменальным ростом, и почему эпоха монополий в ИИ, похоже, уходит в прошлое?
За последний год рынок генеративного искусственного интеллекта переживает настоящую перезагрузку. Согласно свежим данным SimilarWeb, больше всех на этом поле преуспел Google Gemini: трафик платформы за год вырос более чем в два раза, что делает её главным претендентом на роль драйвера будущих перемен. В это время некогда непререкаемый ChatGPT постепенно теряет позиции, сократив свою долю с 87,1% до 74,1%. Несмотря на баснословную аудиторию — до 800 миллионов пользователей еженедельно — давление со стороны конкурентов нарастает едва ли не на глазах.
Венчурные инвесторы, включая Чамата Палихапитию, уже предрекают: борьба в генеративном ИИ закончится в пользу технологических гигантов, способных в один клик доносить новые продукты до миллиардов пользователей. Так, Google, благодаря своей распределённой экосистеме и непрерывному обновлению моделей, сегодня смотрит на ближайшие годы с явным оптимизмом.
Вирусный успех Nano Banana: как один апдейт дал ускорение всему продукту
В августе 2025 года Gemini получил главный драйвер роста: выпуск инструмента Nano Banana — новой ИИ-модели для редактирования изображений. Этот релиз устроил настоящий вирусный взрыв, мгновенно подхваченный соцсетями, и принёс платформе дополнительные 2,1 процентных пункта за один месяц. Приложение Gemini тут же вытеснило ChatGPT с позиции главного бесплатного приложения в App Store.
Статистика не лжёт: по данным Appfigures, за август–октябрь скачивания Gemini увеличились на 331%. Для сравнения, Adobe Firefly за тот же период потеряла 68% загрузок. Особенно заметен был отрыв на рынке США: скачивания Gemini выросли на 88%, а Firefly обрушилась на 82%. Для конкурентов — холодный душ, для Google — подтверждение правильной стратегии.
Рынок больше не делится на “Google против OpenAI”: фрагментация ускоряется
Текущий расклад доказывает: эпоха дуополии уходит, а рынок больше напоминает пеструю мозаику новых и старых платформ. Perplexity уже занимает 6,6% рынка, Claude — 3,6%, другие игроки тоже не застаиваются. Всего за прошлый год пользователи совершили почти 100 миллиардов визитов более чем к 10 000 инструментов на базе ИИ, а темп роста сегмента превышает 120% в год.
Преимущество крупных экосистем становится всё очевиднее: Google с лёгкостью интегрирует новый ИИ в поиск, Android, сервисы и гаджеты, давая Gemini доступ к миллиардам пользователей по всему миру. Такой “network effect” размывает преимущества стартапов и делает продукт Google всё более массовым, пока рынок всё больше фрагментируется, а пользовательская аудитория становится разношерстной и требовательной.
Открытый вопрос для рынка: что дальше — рост конкуренции или новое корпоративное доминирование?
Означает ли этот рост Gemini начало конца доминирования одного игрока на рынке ИИ?
Станет ли следующий виток “ИИ-войны” историей технологических империй, или независимые стартапы всё ещё смогут удивить всех?
Как изменится пользовательский опыт, если столь мощная экосистема как Google начнет диктовать стандарты всей индустрии?
Развитие событий обещает быть непредсказуемым — подписывайтесь, чтобы не пропускать новые повороты на этом высокотехнологичном поле!
Показать полностью

Илон Маск предложил устроить бой Grok против человека
Илон Маск решил устроить шоу — предложил Андрею Карпаты, одному из топовых ИИ-исследователей, посоревноваться в программировании с его будущим Grok 5.
Типа новый "Каспаров против Deep Blue", понимаешь.
Напоминаю, Андрей был директором по ИИ в Tesla, а также бывшим сооснователем OpenAI.
Андрей Карпаты вежливо отказал. Сказав, что предпочтёт работать с Grok, а не драться с ним.
Но Маск не просто так это предложил. В сегодняшнем выпуске я рассказал, что вышло интервью Карпаты, где он заявил, что AGI появится только через 10 лет, а пока что ИИ-агенты — так себе.
По его мнению, для настоящего AGI нужна постоянная память и способность учиться на опыте. Звучит разумно, правда?
А Маск в ответ выдал, что Grok 5 имеет 10% шанс достичь AGI — и эта цифра якобы растёт. Под AGI он понимает систему, которая "делает всё, что может человек с компьютером", но при этом не умнее всех людей вместе. А ещё Grok 5 будет учиться мгновенно, как люди.
Вот вам и PR-дуэль века.
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Показать полностью
"Википедия" за год потеряла почти 10% трафика из-за ИИ, ботов и коротких видео

Фонд Викимедиа опубликовал свежую статистику: за март–август 2025 года реальный, «человеческий» трафик Википедии оказался примерно на 8% ниже, чем в те же месяцы 2024-го. После обновления системы детекции в сентябре фонд пересчитал данные и обнаружил, что весенний всплеск трафика (особенно из Бразилии) был во многом работой ботов, маскирующихся под пользователей. Теперь цифры честнее — и грустнее.
Почему падает органика
Авторы поста на официальном блоге Diff связывают тренд с изменением самого поведения пользователей: всё больше людей получают ответ на вопрос прямо в поиске или в ИИ-помощнике, не переходя по ссылке. Сюда же добавились короткие видео и рефреймы на YouTube, TikTok и Reels — часто на основе вики-материалов, но без клика на саму статью. Так постепенно формируется новая норма: «ответ без визита».
Что с ботами и нагрузкой
Ещё в апреле 2025-го Фонд писал, что до 65 % самого дорогого трафика к дата-центрам дают боты и краулеры. Обновление детектора в сентябре позволило лучше отсеивать запросы, которые притворяются «человеческими». Результат — меньше мнимых просмотров и более реалистичная картина того, кто на самом деле читают Википедию. Это ударило по цифрам, но помогло освободить часть ресурсов.
Как выглядит картина шире
Та же проблема в других медиа — от новостных порталов до справочных площадок. ИИ-сниппеты и автоматические резюме в поиске снижают трафик всем, кто жил за счёт переходов с Google. Издатели теряют рефералов, а пользователи привыкают не кликать — ответ уже перед глазами. «Интернет становится меньше, потому что мы всё меньше по нему ходим», — иронизируют журналисты TechCrunch.
Что делает Фонд
Викимедиа пытается адаптироваться: развивает канал Wikimedia Enterprise для официального и платного реиспользования данных, ужесточает доступ для ботов, и экспериментирует с форматами для молодой аудитории — от коротких роликов до интерактивных объяснялок в Roblox и Instagram.
P.S. Поддержать меня можно подпиской на канал «сбежавшая нейросеть», где я рассказываю про ИИ с творческой стороны.
Показать полностью
Скандал с OpenAI, ИИ найдёт СДВГ - 92%, отец ИИ про тупик в ИИ
Сегодня в выпуске про ИИ:
Экс-основатель OpenAI разнёс текущие ИИ-модели
OpenAI опозорилась дважды на одних граблях
Какой ИИ заработал 800 долларов за сутки на крипте
Как с ИИ определить СДВГ за минуты вместо месяцев
Самые защищенные профессии от ИИ по мнению родителей
ИИ от Google получил доступ к картам всей планеты
Отец ИИ заявил что эпоха нейросетей заканчивается
Будущее где люди летают на работу - уже не фантастика
Первая утечка агентского режима в Gemini App
Заказов больше, платят меньше: кошмар переводчиков
Смотреть весь выпуск на VK Видео
Смотреть весь выпуск на YouTube
Приятного просмотра!
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Показать полностью
2