
Закономерности в движении: целостный подход к генерации многокадровых видео
Автор: Денис Аветисян

Этот подход раскрывает закономерности в визуальном повествовании, позволяя создавать последовательные и логичные видеофрагменты.
Долгое время создание связных, продолжительных видеоисторий оставалось недостижимой целью, поскольку существующие методы генерации видео концентрировались на коротких, изолированных фрагментах, неспособных передать повествовательную целостность кинематографического произведения. Прорыв, представленный в ‘HoloCine: Holistic Generation of Cinematic Multi-Shot Long Video Narratives’, заключается в принципиально новом подходе к генерации видео, объединяющем все кадры в единую модель для обеспечения согласованности и повествовательной логики. Но сможет ли эта целостная генерация не просто воспроизвести визуальный ряд, но и вдохнуть жизнь в настоящие, эмоционально насыщенные истории, способные по-настоящему захватить зрителя?
Разрыв в Повествовании: Преодоление Ограничений Генерации Видео
Современные системы преобразования текста в видео (T2V) демонстрируют впечатляющие результаты в генерации коротких видеоклипов, однако сталкиваются с существенной проблемой поддержания связности и последовательности при увеличении длительности. Это выявляет так называемый "разрыв в повествовании" – принципиальное ограничение, препятствующее созданию полноценных, многоплановых визуальных историй. Несмотря на значительный прогресс в области диффузионных моделей и диффузионных трансформаторов, позволивших достичь высокого качества генерации, эти системы часто оказываются неспособными к осмыслению и воспроизведению сложной структуры повествования и развитию персонажей.
Существующие подходы, как правило, рассматривают каждый кадр как независимое целое, что приводит к фрагментированным видео, не способным рассказать убедительную историю. Истинное кинематографическое повествование требует поддержания согласованности на протяжении нескольких кадров, создания визуального ритма и логичной связи между событиями. Отсутствие этой целостности лишает видео глубины и эмоционального воздействия. Это особенно заметно при попытке воссоздать сложные сюжетные линии или динамичные сцены действия.
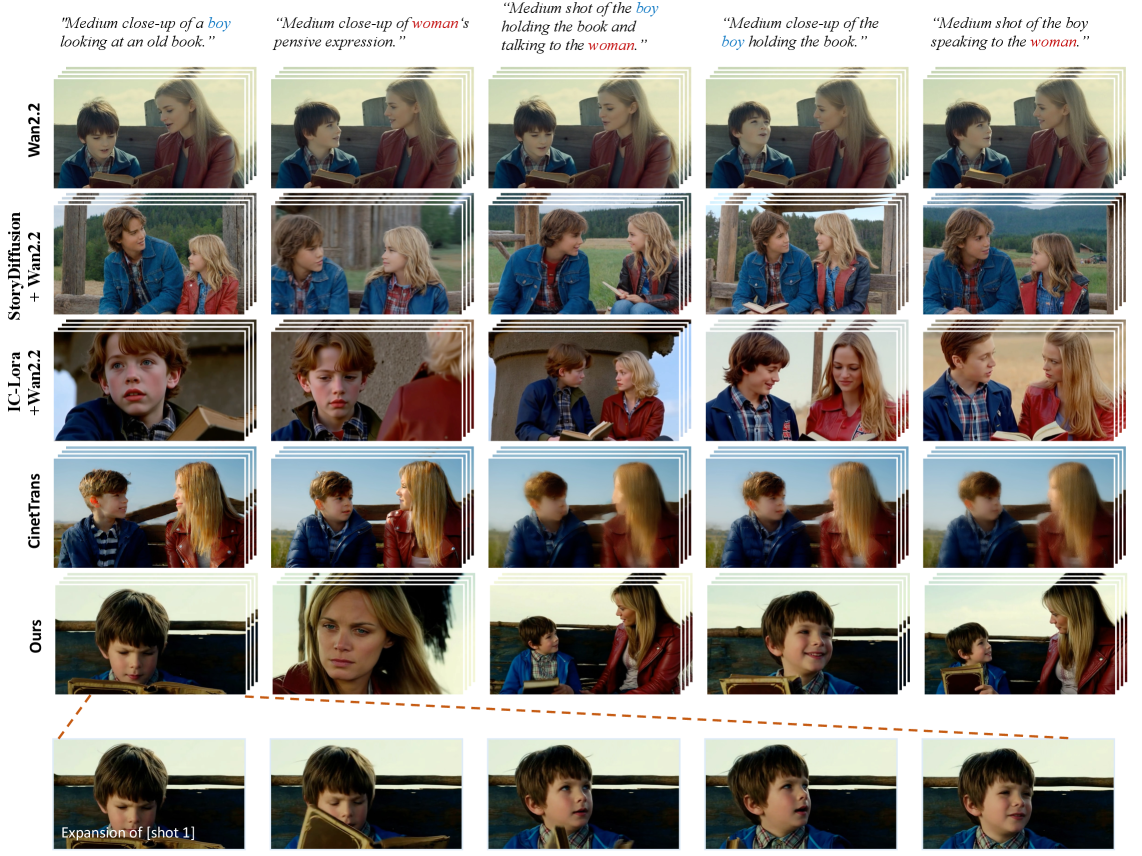
Качественное сравнение на сложном многокадровом запросе.
Таким образом, задача создания связных, многокадровых видео представляет собой значительный вызов для современных систем искусственного интеллекта. Недостаточно просто генерировать красивые картинки – необходимо уметь объединять их в единое повествование, поддерживать согласованность персонажей и окружения, а также создавать динамичные переходы между кадрами. Если закономерность нельзя воспроизвести или объяснить, её не существует. Только преодолев этот "разрыв в повествовании", мы сможем приблизиться к созданию систем, способных автоматически генерировать полноценные кинематографические произведения.
HoloCine: Целостная Генерация Видео и Взаимосвязь Кадров
В стремлении к созданию кинематографических повествований, исследователи обращаются к принципам целостности и взаимосвязанности, подобно тому, как нейронные сети моделируют сложные биологические системы. Традиционные подходы к генерации видео часто рассматривают отдельные кадры как изолированные единицы, упуская из виду критически важные связи между ними. В результате, возникает фрагментация повествования и потеря визуального опыта. В данной работе представлен HoloCine – новый подход к генерации многокадрового видео, который явно моделирует взаимосвязи между кадрами, обеспечивая тем самым нарративную когерентность и так называемую “целостную генерацию”.
Ключевым элементом архитектуры HoloCine является механизм Window Cross-Attention. Подобно тому, как живые организмы фокусируют свои ресурсы на определенных участках для выполнения конкретных задач, данный механизм позволяет выровнять текстовые подсказки с конкретными сегментами видео. Это обеспечивает семантическую согласованность внутри каждого кадра и гарантирует, что визуальный контент точно соответствует намерениям режиссера. Представьте себе оркестр, где каждый инструмент играет свою партию в гармонии с другими – именно так Window Cross-Attention обеспечивает слаженность и согласованность визуального повествования.
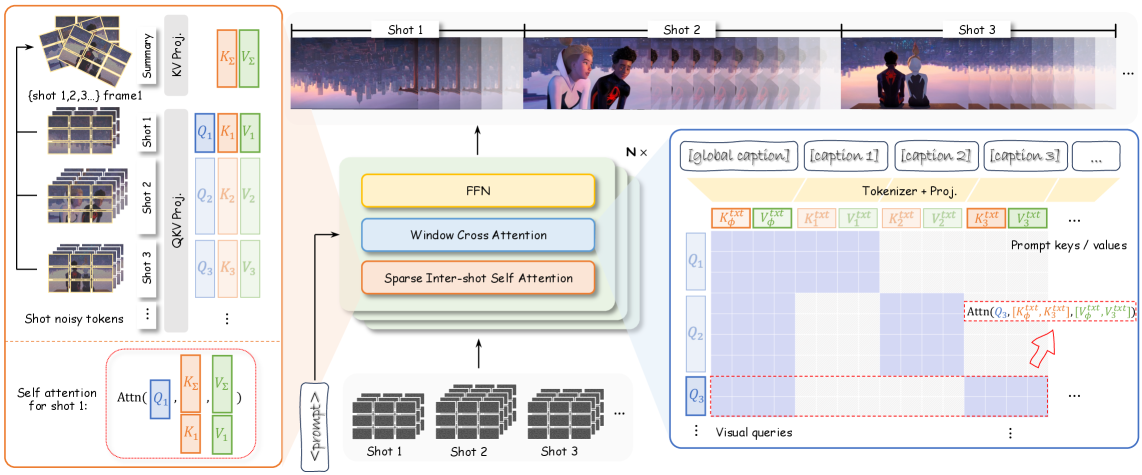
Sparse Inter-Shot Self-Attention значительно снижает вычислительные затраты, сохраняя при этом долгосрочную согласованность.
Однако, создание целостной системы требует преодоления значительных вычислительных сложностей. Подобно тому, как мозг оптимизирует свои энергетические затраты, HoloCine использует Sparse Inter-Shot Self-Attention. Этот механизм позволяет эффективно рассуждать на протяжении всей видеопоследовательности, не прибегая к чрезмерным вычислительным ресурсам. Вместо того, чтобы обрабатывать каждый кадр независимо, система фокусируется на ключевых взаимосвязях, обеспечивая тем самым масштабируемость и эффективность. Представьте себе паутину, где каждая нить соединяет важные узлы – именно так Sparse Inter-Shot Self-Attention обеспечивает связь и согласованность между кадрами.
В итоге, HoloCine представляет собой новый шаг в развитии генеративных моделей для видео. Преодолевая ограничения традиционных подходов, система открывает новые возможности для создания кинематографических повествований, обладающих как визуальной красотой, так и нарративной целостностью. Это подобно созданию сложной экосистемы, где каждый элемент играет свою роль в поддержании общего равновесия и гармонии.
Иерархическая Аннотация Данных и Оценка Согласованности Повествования
В основе HoloCine лежит принцип иерархической аннотации данных, позволяющий создать набор данных, обогащенный как глобальными описаниями сюжета, так и детальными инструкциями для каждого кадра. Такой подход обеспечивает богатый контекст, необходимый для обучения модели пониманию повествовательной структуры и визуального языка. Каждый кадр рассматривается не как изолированное изображение, а как звено в цепи повествования, требующее осмысленной интерпретации.
Точное определение границ кадров играет критическую роль в обеспечении согласованности между текстовым описанием и визуальным контентом. Для этого используются современные методы обнаружения границ кадров, такие как TransNet V2, позволяющие добиться высокой точности выравнивания. Это выравнивание не только необходимо для корректной аннотации данных, но и является ключевым фактором при оценке качества генерируемых видео.

Для оценки семантической согласованности между текстовыми подсказками и генерируемыми кадрами используется ViCLIP – модель, способная извлекать и сопоставлять визуальные и текстовые представления. Этот подход позволяет количественно оценить, насколько хорошо сгенерированное видео соответствует заданному описанию. Помимо семантической согласованности, особое внимание уделяется плавности переходов между кадрами.
Для количественной оценки качества переходов между кадрами разработан показатель – точность определения границ кадров (Shot Cut Accuracy, SCA). SCA позволяет оценить, насколько точно модель определяет моменты смены кадра и насколько плавно происходит переход между ними. Этот показатель не только отражает техническое качество видео, но и влияет на восприятие повествования зрителем. Каждый кадр – это не просто визуальное изображение, а часть динамичного повествования, требующая точной и согласованной визуализации.
Таким образом, HoloCine стремится к созданию не просто визуально привлекательных видео, но и повествовательно согласованных и логичных сцен. Использование иерархической аннотации, точного определения границ кадров и количественных метрик оценки позволяет оценить и улучшить качество генерируемых видео, приближая нас к автоматическому созданию полноценных киноповествований.
Преодолевая Границы: Будущее Автоматизированного Кинематографа
Преодолевая ограничения существующих систем преобразования текста в видео, HoloCine открывает двери для широкого спектра применений, включая создание персонализированного контента и автоматизированное кинопроизводство. В основе этого прогресса лежит способность модели генерировать последовательные, длинные видеофрагменты, что принципиально важно для повествования. Традиционные подходы часто сталкиваются с проблемой накопления ошибок и потери связности, особенно при создании видео продолжительностью в несколько минут. HoloCine, напротив, демонстрирует устойчивость и связность, что позволяет создавать сложные повествования с достоверными персонажами и захватывающими сюжетными линиями.
В рамках данного исследования авторы не просто демонстрируют технические возможности новой архитектуры, но и задают вопросы о том, как визуальные закономерности отражают внутреннюю логику модели. Эксперименты, направленные на подтверждение или опровержение выдвинутых гипотез, позволяют глубже понять принципы работы HoloCine и выявить факторы, влияющие на качество генерируемого видео. Особое внимание уделяется долгосрочной согласованности, что достигается за счет использования механизма Window Cross-Attention и Sparse Inter-Shot Self-Attention. Эти инновационные подходы позволяют модели поддерживать целостность визуального повествования на протяжении всей сцены, избегая распространенных проблем, связанных с потерей идентичности персонажей или несоответствием фоновых элементов.

(a) Масштаб кадра: модель точно генерирует длинные, средние и крупные планы. (b) Угол обзора камеры: она правильно интерпретирует команды низкого, на уровне глаз и высокого угла. (c) Движение камеры: модель производит плавные и точные движения камеры.
В дальнейшем авторы планируют исследовать возможности интеграции метрик оценки эстетического качества, таких как LAION Aesthetic Predictor, для дальнейшего повышения художественного уровня генерируемых видео. Эта работа позволит не только улучшить визуальную привлекательность контента, но и создать более выразительные и эмоционально насыщенные повествования. Интеграция таких метрик позволит модели адаптировать свои параметры к предпочтениям зрителей и создавать контент, который будет не только технически совершенным, но и эстетически привлекательным. Это открывает новые горизонты в области автоматизированного кинопроизводства и создания персонализированного контента.
Исследование демонстрирует, что HoloCine представляет собой значительный шаг вперед в области генерации видео, открывая новые возможности для создания захватывающих и убедительных визуальных повествований. Оно подтверждает, что с помощью инновационных архитектур и продуманных подходов можно преодолеть ограничения существующих систем и создать модели, способные генерировать контент, который будет не только технически совершенным, но и художественно выразительным.
В HoloCine мы видим воплощение идеи о том, что понимание системы – это исследование её закономерностей. Авторы демонстрируют, как внимание к деталям, в данном случае – к механизмам внимания в диффузионных моделях – позволяет создавать целостные и длинные видео-нарративы. Как сказал Ян ЛеКюн: «Машинное обучение – это поиск закономерностей в данных». Эта фраза прекрасно отражает суть работы: HoloCine использует sparse inter-shot self-attention для выявления скрытых зависимостей между кадрами, позволяя модели эффективно генерировать длинные видео, сохраняя при этом согласованность и повествовательную логику. Каждое отклонение от ожидаемого результата, каждый артефакт – это возможность выявить скрытые зависимости в структуре данных и улучшить модель.
Что дальше?
HoloCine, безусловно, демонстрирует впечатляющий шаг вперёд в генерации длинных видео, но давайте не будем обольщаться. Мы научились создавать иллюзию повествования, но понимаем ли мы само повествование? Решение проблемы вычислительной сложности через разреженное внимание – это, конечно, элегантно, но это лишь технический трюк. Настоящий вызов – не в скорости, а в осмысленности. Генерация когерентных видео – это не просто соединение кадров, это создание системы визуальных закономерностей, которые вызывают у зрителя определённые эмоции и ассоциации.
Следующим шагом видится не столько увеличение длины генерируемых видео, сколько углубление контроля над смысловым содержанием. Необходимо разработать механизмы, позволяющие задавать не просто текстовое описание сюжета, а более сложные параметры – например, эмоциональную окраску сцены, темп повествования, визуальный стиль. И, что особенно важно, тщательно проверять границы данных, чтобы избежать ложных закономерностей и не создавать "видео-галлюцинации".
Возможно, мы приближаемся к моменту, когда компьютер сможет "рассказать" историю, но стоит помнить: даже самая совершенная визуальная иллюзия – это лишь отражение нашей собственной потребности в нарративах. И прежде чем учить машины рассказывать истории, нам следует лучше понять, зачем мы сами их слушаем.
Искусственный интеллект
5K постов11.5K подписчика
Правила сообщества
ВНИМАНИЕ! В сообществе запрещена публикация генеративного контента без детального описания промтов и процесса получения публикуемого результата.
Разрешено:
- Делиться вопросами, мыслями, гипотезами, юмором на эту тему.
- Делиться статьями, понятными большинству аудитории Пикабу.
- Делиться опытом создания моделей машинного обучения.
- Рассказывать, как работает та или иная фиговина в анализе данных.
- Век жить, век учиться.
Запрещено:
I) Невостребованный контент
I.1) Создавать контент, сложный для понимания. Такие посты уйдут в минуса лишь потому, что большинству неинтересно пробрасывать градиенты в каждом тензоре реккурентной сетки с AdaGrad оптимизатором.
I.2) Создавать контент на "олбанском языке" / нарочно игнорируя правила РЯ даже в шутку. Это ведет к нечитаемости контента.
I.3) Добавлять посты, которые содержат лишь генеративный контент или нейросетевой Арт без какой-то дополнительной полезной или интересной информации по теме, без промтов или описания методик создания и т.д.
II) Нетематический контент
II.1) Создавать контент, несвязанный с Data Science, математикой, программированием.
II.2) Создавать контент, входящий в противоречие существующей базе теорем математики. Например, "Земля плоская" или "Любое действительное число представимо в виде дроби двух целых".
II.3) Создавать контент, входящий в противоречие с правилами Пикабу.
III) Непотребный контент
III.1) Эротика, порнография (даже с NSFW).
III.2) Жесть.
За нарушение I - предупреждение
За нарушение II - предупреждение и перемещение поста в общую ленту
За нарушение III - бан