
Google drive
Добрый день всем!
Заканчивается свободное место на 2х-терабайтном хранилище на Google Drive, но я не вижу способов увеличить объём памяти. Кто-то сталкивался с таким?
Добрый день всем!
Заканчивается свободное место на 2х-терабайтном хранилище на Google Drive, но я не вижу способов увеличить объём памяти. Кто-то сталкивался с таким?
Если вы давно искали, где бесплатно хранить бэкапы важной информации, то в «Макс» можно загружать файлы до 4 ГБ, возможно, даже без ограничений! (не проверял, на офсайте про лимит тоже ничего не сказано).
Осталось только взять любой архиватор, сделать зашифрованный архив с разбиением на файлы нужного размера и загрузить их себе в сохранёнки.
Пользуйтесь на здоровье!
Источник: «Жиза ИТ руководителя»
Решение для безопасного управления секретами Deckhouse Stronghold от компании «Флант» получило сертификат соответствия ФСТЭК России № 5038 от 10 февраля 2026 года. Документ подтверждает, что новая редакция продукта — Deckhouse Stronghold Certified Security Edition — соответствует требованиям технических условий и приказа ФСТЭК России № 76 от 2 июня 2020 года по 4-му уровню доверия.
Сертифицированную редакцию Deckhouse Stronghold смогут внедрять организации, для которых обязательно использование продуктов, прошедших сертификацию ФСТЭК России. Речь идёт о государственных компаниях и госкорпорациях, банках, федеральных и региональных органах исполнительной власти, а также об организациях, работающих с объектами критической информационной инфраструктуры.
Deckhouse Stronghold — решение для централизованного хранения и безопасного управления жизненным циклом секретов. Продукт обеспечивает защищённую доставку секретов, централизованный аудит и управление доступами, а также контроль над созданием, ротацией и отзывом секретов. Решение может использоваться в любых инфраструктурах, включая публичные и частные облака, а также закрытые контуры с повышенными требованиями к информационной безопасности. Deckhouse Stronghold полностью совместим с API HashiCorp Vault, имеет интерфейс на русском языке и работает на российских операционных системах.
Deckhouse Stronghold Certified Security Edition реализует функциональные возможности уровня HashiCorp Vault Enterprise, включая межкластерную репликацию данных, пространства имён, автоматическое резервное копирование данных по заданному расписанию, встроенное безопасное автоматическое распечатывание хранилища без использования внешних сервисов или KMS, поддержку внешних аппаратных модулей безопасности и двойное шифрование данных. В том числе поддерживаются российские криптографические алгоритмы «Кузнечик» и «Магма» в соответствии с ГОСТ Р 34.12-2018.
«Мы ставили перед собой задачу создать не просто сертифицированное решение, а полноценное enterprise-хранилище секретов, которое можно использовать в реальных production-средах с повышенными требованиями к информационной безопасности. Deckhouse Stronghold Certified Security Edition изначально разрабатывался в соответствии с требованиями безопасной разработки программного обеспечения по ГОСТ Р 56939-2024. Сертификация ФСТЭК России подтверждает, что продукт полностью соответствует требованиям регулятора и предлагает заказчикам функциональные возможности уровня HashiCorp Vault Enterprise», — отметил Владимир Девятайкин, менеджер продукта Deckhouse Stronghold компании «Флант».
Сертифицированная редакция Deckhouse Stronghold позволяет использовать продукт для защиты информации на значимых объектах критической инфраструктуры до 1-й категории значимости включительно, обеспечения безопасности персональных данных в информационных системах до 1-го уровня защищённости включительно, защиты информации в государственных информационных системах до 1-го класса защищённости, а также защиты информации в автоматизированных системах управления производственными и технологическими процессами на критически важных и потенциально опасных объектах.
В дальнейшем планируется активное развитие редакции Certified Security Edition, включая расширение функциональности performance-репликации, а также прохождение оценки влияния среды функционирования на средство криптографической защиты информации в рамках встраивания СКЗИ в Deckhouse Stronghold.
Надо хоть что-то забэкапить... Переписку, адреса, пароли, явки...
Если кто не знает, Телега позволяет экспортнуть историю групп, чатов, со всеми сообщениями, картинками, стикерами, видео и файлами в виде HTML страниц.
Единственное, эта опция должна быть включена в группе/канале/чате.
Клик по топику/имени группы и далее по порядку.
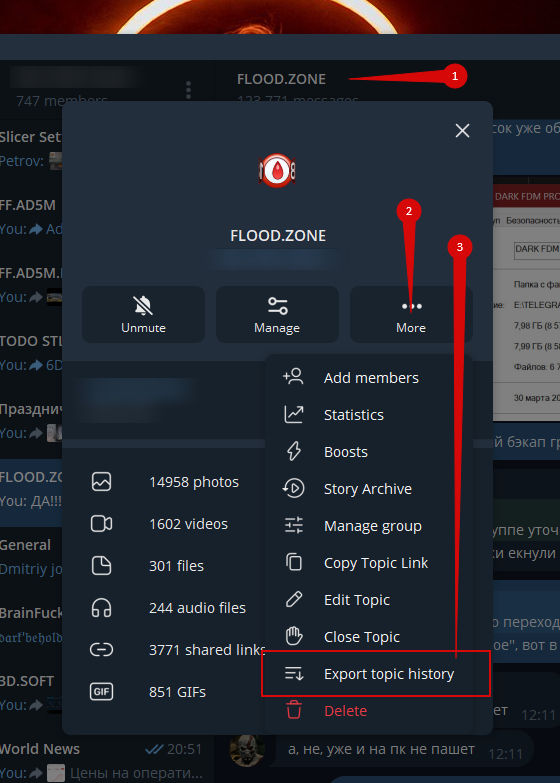
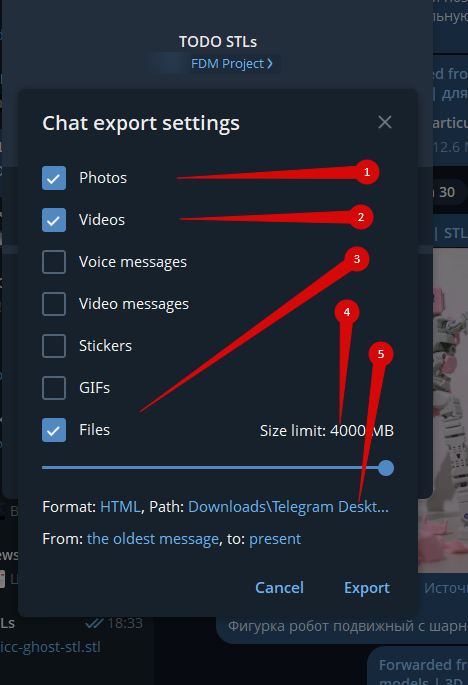
1 - ну понятно
2 - опционально. ОЧЕНЬ медленно, сами понимаете
3 - самое ценное. Можно смотреть за процессои скачивания и скипать ненужное
4 - ограничение на размер скачиваемых файлов
5 - куда сохранять....
Сидим, курим....
Шесть или семь часов спустя:
Все файлы на диске.
Оффлайн версия....
Хэв э найс день....
Гриф: РАССЕКРЕЧЕНО
Статус: для внутреннего пользования.
Приложения: выдержки из переговоров, показания свидетеля, реконструкция, памятки на полях, экспертное заключение.
Часть материалов: [ФРАГМЕНТ СКРЫТ]
— Вы новенький? — женщина за столом не поднялась. Только лениво перевела взгляд на вошедшего в дверь мужчину.
Он остановился у порога на несколько секунд. Оценил кабинет, штампы, папку, и то, как уверенно хозяйка этого пространства держит паузу.

— Формально — да, — сказал он наконец. — По документам я оперативник по сбору мифов.
Она чуть приподняла бровь, но улыбки на ее лице не появилось. Если бы женщина не умела хорошо контролировать эмоции, то в Агентстве она бы надолго не задержалась.
— По факту, — продолжил он, — я тот, кто приносит сюда всё, что люди пересказывают друг другу так, будто это законы природы. Форумы, чаты, «знакомый админ сказал», советы из прошлого века, которые почему-то не умирают.
— Хорошо вы устроились — женщина хмыкнула. — Получается, что вы главный по сплетням?
— Если бы всё ограничивалось слухами, — он не обратил внимания на издевку и кивнул на папку на столе, — вы бы не держали такие штампы.
Женщина немного расслабилась, откинулась на спинку стула и решили представиться первой, чтобы немного разрядить обстановку и закрыть все формальности.
— Алина Ветрова. Эксперт отдела. В наших отчетах мифы обычно заканчиваются простоями и деньгами. Иногда репутацией. Реже судами. Она посмотрела на него внимательнее.
— Теперь ваша очередь — как мне к вам обращаться?
— Илья Горин, — представился он. — Можно просто Илья.
— Хорошо, значит будем работать так. Вы приносите легенду, как обычно ее подают люди. Я разбираю, где в этом правда, где подмена терминов, а где просто страхи вперемешку с неуверенностью. И потом мы пишем отчёт так, чтобы его понял любой, кто отвечает за проект. Итак, что у нас сегодня на повестке дня?
Илья положил на край стола тонкую папку — как будто стеснялся её объёма. На обложке был номер и короткая надпись, от которой у Алины в глазах появилось что-то похожее на усталое узнавание.
— Дело №001. “Бэкап на том же сервере”.
Алина медленно выдохнула.
— Ну, это классика, куда без кривых бэкапов, — сказала она, уже перелистывая первые страницы. — Хотя простой эту тему язык не повернется назвать.
На сервере размещен проект, включающий веб-сайт, базу данных, фоновые задачи, административную панель и вспомогательные сервисы. На определённом этапе эксплуатации принимается решение о внедрении процедуры резервного копирования. Настраивается регламент: копии создаются регулярно, по расписанию, с указанием даты в наименовании файлов. В отдельных случаях дополнительно реализуется механизм уведомлений об успешном выполнении операции.
Распространённой практикой является хранение резервных копий на том же сервере, где размещены исходные данные. Копии могут располагаться в отдельном каталоге, под учётной записью с расширенными правами доступа или на ином разделе диска, однако физически остаются в пределах того же вычислительного контура. Формально процедура выполнена, что создает ощущение закрытого риска.
При возникновении нештатной ситуации выявляется ограниченность такого подхода. Инцидент, как правило, затрагивает не отдельные файлы, а доступность и целостность всей системы. В условиях компрометации сервера, утраты доступа или повреждения файловой системы резервные копии, размещенные на том же узле, либо утрачиваются вместе с основными данными, либо становятся недоступными для восстановления.
[ФРАГМЕНТ РАЗГОВОРА | 08:29]
— Знаешь, что самое частое? — Игорь с легкой усмешкой отвернулся от ноутбука, — Люди искренне гордятся папкой самим фактом существования папки backups. Показывают её почти с облегчением. Мол, вот, мы не из тех, кто забывает про резервные копии.
Алина не отрывалась от распечатки, но слушала внимательно.
— Хотя бы они делают шаги в правильную сторону, — сказала она спокойно. — Проблема не в папке. Делом в том, что на этом шаге большинство останавливается.
Игорь повернулся к ней.
— Потому что считают, что вопрос закрыт?
— Потому что слово «бэкап» звучит как нечто завершеное, — ответила Алина. — Сделал копию и значит застраховался. А дальше начинаются нюансы. Ведь создать копию и обезопасить файлы — это не одно и то же.
Игорь задумчиво кивнул.
— Обеспечить безопасность — значит поселить копию отдельно на другом сервере?
Алина наконец подняла взгляд.
— Безопасность — это когда копия переживает потерю сервера. Когда она существует независимо от него. И когда ты уже хотя бы один раз восстановился из неё. Всё остальное — это удобство. Полезно, но ничего не гарантирует
Игорь тихо выдохнул.
— То главная ошибка в том, что папку backups почти на каком-то религиозном уровне считают последней линией обороны.
— Именно, — сказала Алина. — И это мы и должны объяснить. Чтобы человек после прочтения задал себе один неприятный вопрос.
— Какой?
— Если сервер исчезнет сегодня, что у тебя останется завтра?
Первый фактор риска — отсутствие фактического доступа к резервной копии в момент инцидента. При недоступности сервера, обрыве сетевого соединения, утрате доступа к административной панели или временных ограничениях со стороны провайдера резервная копия, размещенная на том же узле, не может быть оперативно использована для восстановления. Формальное наличие архива не обеспечивает его практическую доступность.
Второй фактор риска — одновременная утрата рабочих данных и резервных копий. В случае компрометации системы, в том числе при несанкционированном доступе или шифровании файлов, воздействие распространяется на всю файловую систему в пределах доступных прав. Разделение по каталогам или логическое разграничение не гарантируют сохранности резервных архивов.
Третий фактор риска — неполнота или некорректность резервной копии. Формальное наличие архивов не означает их пригодность к восстановлению. Возможна утрата отдельных компонентов (дампов баз данных, конфигурационных файлов, ключей доступа), повреждение архивов или отсутствие регулярной проверки процедуры восстановления. В таких условиях процесс восстановления требует ручной доработки и не гарантирует результат.
Четвертый фактор риска — несоответствие временного горизонта хранения. При позднем обнаружении инцидента ежедневные копии могут уже содержать поврежденные или искаженные данные. При отсутствии более ранних версий восстановление к корректному состоянию становится невозможным.
Потерпевший начал говорить сразу, будто заранее готовился к этому разговору.
— Я сразу скажу: бэкапы у нас были, честное слово. Я сам их настраивал.

Игорь молча кивнул, давая понять, что услышал. Алина сделала пометку в блокноте, не поднимая головы.
— Где вы их хранили? — спросила она ровно.
— На сервере в отдельной папке, под рутом. Мне казалось, так безопаснее: веб-сервер туда не полезет, права другие.
Он сказал это почти с облегчением, как человек, который нашёл логичное объяснение своему решению и до последнего верил, что оно правильное.
— Что произошло дальше? — Алина всё ещё не смотрела на него.
Потерпевший на секунду замолчал, будто прокручивал события заново.
— Сначала всё стало вести себя странно. Медленно, с ошибками. Потом я потерял доступ к админке. Через некоторое время сервер просто перестал отвечать. Провайдер сказал, что идет проверка, попросили подождать.
Игорь заметил, как в этот момент у человека дернулся уголок рта.
— И вы решили восстановиться из копии, — констатировал оперативник.
— Да. Это было первое, что пришло в голову, — кивнул потерпевший. — Я подумал: ладно, неприятно, но у нас же есть бэкапы. Сейчас зайду и…
Он запнулся и коротко выдохнул.
— И понял, что мне некуда заходить. Копия есть, но она внутри сервера. А сервер для меня закрытая дверь. Это было… — он запнулся, пытаясь подобрать подходящее, — неприятно. Очень.
Алина наконец подняла взгляд.
— Что в итоге помогло?
Потерпевший горько усмехнулся,.
— Случайность. Старый дамп базы на ноутбуке. Я когда-то скачал его на всякий случай и забыл. Он был недельной давности, но это было единственное, что оказалось снаружи.
В кабинете повисла пауза.
Игорь закрыл папку и посмотрел на Алину.
— Этого будет достаточно. Я думаю, что можем закругляться и переходить к выводам.
[ПАМЯТКА | ГРИФ: «ДЛЯ ВНУТРЕННЕГО ПОЛЬЗОВАНИЯ»]
Резервная копия рассматривается не как сам по себе файл, а как подтвержденная возможность восстановления системы. При отсутствии хотя бы одной успешной процедуры тестового восстановления резервное копирование следует считать непроверенным. В этом случае оно существует формально, но не подтверждено как рабочий инструмент.
[ПАМЯТКА | ПОМЕТКА ЭКСПЕРТА]
Размещение копий в различных директориях одной и той же машины не снижает совокупный риск. Использование разных физических дисков в пределах одного сервера также не исключает критические сценарии отказа. Отдельная точка хранения требуется не из соображений удобства, а для обеспечения независимости от инцидентов, затрагивающих доступность и целостность основной среды.
[ПАМЯТКА | СЛУЖЕБНАЯ ФОРМУЛИРОВКА]
Термин отдельное хранение означает способность резервной копии сохраниться при полной утрате сервера. Если копия утрачивается или становится недоступной одновременно с основным узлом, она классифицируется как локальная и не может рассматриваться в качестве полноценного механизма страхования рисков.
[ПАМЯТКА | К ПРОТОКОЛУ РАССЛЕДОВАНИЯ]
Контрольный вопрос при оценке стратегии резервного копирования формулируется следующим образом: возможно ли восстановление проекта в течение следующего рабочего дня при полной утрате текущего сервера и отсутствии доступа к нему? При отрицательном ответе обсуждение деталей размещения архивов теряет приоритетное значение.
[ПАМЯТКА | ПРО ВРЕМЯ]
Резервное копирование должно обеспечивать достаточную глубину хранения для отката к корректному состоянию. Ошибки и искажения данных часто выявляются с задержкой. При ограниченной истории копий существует риск сохранения исключительно актуальных, но уже повреждённых версий данных.
Локальная копия на том же сервере — полезная привычка и нормальный первый уровень защиты от мелких ошибок. Её не нужно высмеивать и не нужно отменять просто ради принципа. Её нужно правильно назвать, чтобы она не подменяла собой настоящую страховку.
Но когда речь заходит о более серьезной защите от рисков, то полагаться на локальную копию уже нельзя. Компрометация и шифрование, недоступность сервера как объекта, скрытая порча данных — все эти сценарии либо уничтожают локальные архивы, либо лишают вас доступа к ним, либо делают невозможным откат к предыдущему состоянию.
Поэтому базовый критерий для этого дела звучит просто и проверяемо: если сервер исчезнет или станет недоступным сегодня, останется ли у вас свежая копия вне сервера, и сможете ли вы на её основе восстановить проект?
Бэкап на том же сервере удобен, но не является полноценной страховкой от инцидента, потому что находится в той же зоне риска. Полноценная страховка начинается там, где копия живёт вне сервера.
Отдельно отмечено: выбор инфраструктуры и подхода к размещению сервера напрямую влияет на реализацию стратегии резервного копирования. Наличие стабильного провайдера, предсказуемой среды и возможности гибко организовать хранение данных за пределами основного узла — не вопрос удобства, а часть общей системы защиты.
В рамках текущего расследования рекомендуется использовать инфраструктуру, позволяющую без ограничений выносить резервные копии за пределы основного сервера и выстраивать независимые сценарии восстановления.
Приобрести сервер, подходящий для подобных задач, а также развернуть собственную инфраструктуру с учётом требований к безопасности и отказоустойчивости можно на сайте UFO.Hosting.
Доброго времени суток уважаемые обитатели Пикабу! Интересная проблема настигла меня. Краток не буду, но постараюсь! Попросил тут меня недавно давний знакомый с компьютером ему помочь, в плане сборки. Я не великий специалист, но там ничего сложного. Без ярких подсветок, аквариумов и прочей красоты. В общем все собрал, но у меня загвоздка вышла вот такого плана.
Сам же подсоветовал человеку купить ssd М2 под систему, сам же на эти грабли и наступил. А проблема вот в чем. Я установил ему его фирменную 11, мы вошли с учетной записью майкрософт, установили драйвера, немного программ. И попросил он меня резервную копию системы сделать программой Акронис 2021 и скинуть ему на файлопомойку. Что бы потом если, что без проблем восстановить. Ну вот незадача, образ Акрониса на диск М.2 накатывается, но при загрузке системы возникает пшик, в виде синих экранов. Причем на обычный, сатовский SSd развернулась система прекрасно, как раз из образа, который был сделан из М2. То есть образ не битый.
Я понял, что Акронис, который не раз меня выручал начиная с HDD и заканчивая SATA SSD для NVME M.2 дисков мягко говоря не подходит. Покурил Гугл, у многих такая проблема.
Я очень прошу помощи у сообщества, какая софтина больше всего подходить для таких задач.
А именно - установить виндовс на NVME M2, потом с помощью программы создать резервную копию со всеми настройками, паролями, и сбросить этот образ на файлопомойку. А в случае форсмажора быстренько из образа восстановить систему. Как раньше на жестком диске я делал с помощью старого доброго Акронис. Так вот подытожу - чем заменить мне для этой задачи проверенный временем Акронис?
Нашел я свой старый аккаунт в ЖЖ, почитал, порадовался, решил с вами поделиться стареньким. Текст авторский, из 2010-го года, основан на реальных событиях.
В нашей компании есть База Данных.
Когда-то, в староглинянные времена это была соль земли, стержень и оплот, вокруг которого жила вся фирма. Потом эпоха сменилась, пришли новые люди и с ними новая База Данных. А старая осталась доживать где-то на задворках, заброшенная и неумытая. Но в те самые староглинянные времена было написано множество Инструкций. Подписанных Самим. Того Самого уже тоже давно нет, а инструкции есть. Их никто не посмел отменить, ибо Святое. А раз их никто не посмел отменить, значит надо выполнять. Ибо есть великая и могучая Служба Безопасности, вечная и непобедимая, как бухгалтерская отчетность, которая Бдит.
Одна из этих инструкций предписывает Базу Данных ежедневно бэкапить. Для этого есть специальный человек. Имеет он чин Заместителя Директора Департамента, ибо больше ничего не умеет - только быть Заместителем и бэкапить Базу Данных.
И тут случилось страшное - Заместитель ушел в ежегодный оплачиваемый отпуск в связи с тем, что перетрудился на ответственной работе, и встал Вопрос: А кто же будет бэкапить Базу Данных?
Неосторожно попался Ваш покорный слуга. По этому случаю был написан приказ Самого, о том что покорный слуга назначается ответственным за Базу Данных.
Коллеги посоветовали "ничему не удивляться".
И вот я теперь, с понедельника начиная, трачу время на высокоинтеллектуальный процесс.
Сначала утром со своего компьютера копирую Базу Данных с Сервера, стоящего в одном чулане (ибо в серверной это древнее говно мамонта нафиг никому не нужно) на диск, стоящий в другом чулане. Скопировать я могу ее хоть куда, хоть на свою личную флэшку, но тот диск должен стоять обязательно в том чулане, где Положено. За Железной дверью с Печатью.
Потом беру ключи в охране, вскрываю Железную дверь, беру диск и несу его в Приемную. Захожу в кабинет самого главного начальника всея Службы Безопасности, приветствую его по уставу, вскрываю его личный сейф, кладу туда диск, беру другой и расписываюсь в Журнале. Потом снова вскрываю Железную дверь, вставляю новый диск и проникшись важностью момента отдаю честь. Потом измученный тяжким трудом иду на свое рабочее место и отдыхаю. Прямо как Заместитель, которого я замещаю.
Очень важная и нужная работа. На таких как мы (с Заместителем) и держится наша цивилизация.
Если, скажем, завтра Заместителя уволят, с меня снимут почетную обязанность, а Сервер отправят в пункт приема цветных металлов (где его еще с прошлой пятилетки заждались), то вмиг наступит Тлен, Мор, и Оптимизация бизнес-процессов. Ужас вобщем.





