


От PoC к масштабу — как превратить пилот в повседневную реальность
📖 Введение
Generated by Copilot
Когда речь идет о серьезной инициативе, командам нужен общий язык и предсказуемая, и известная последовательность шагов.
Главный риск в крупных инициативах — не технологии, а координация людей и ожиданий. Поэтому разумнее сначала подтвердить ценность на ограничённой зоне и лишь потом масштабироваться: короткие волны, явные критерии выхода и решения go/no-go на каждом этапе. Такая этапная модель снимает организационный шум и позволяет безопасно двигаться к целевому состоянию без попытки сразу строить «идеал».
Эта статья — про стадии реализации крупной инициативы: как перейти от замысла к широкому запуску с минимальными рисками и оптимизированными усилиями.
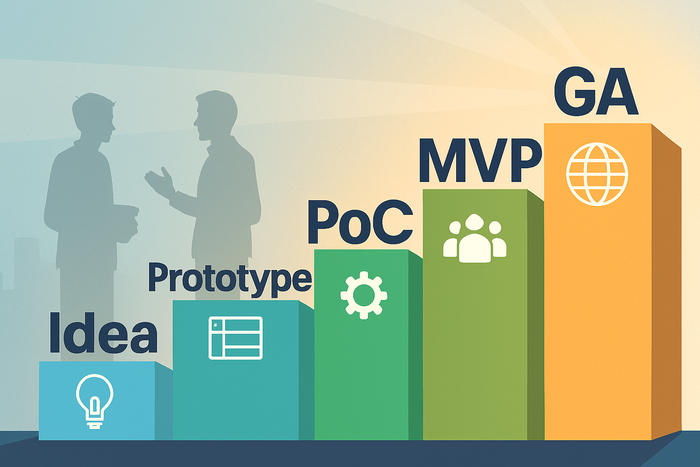
📝 Коротко о различиях в этапах
💡 Idea — формулировка проблемы и "гипотезы ценности".
🧠 Prototype — быстрый способ показать как это будет выглядеть/работать (макет, кликабельная демка, «волшебник из страны Оз»; быстрая сборка из подручных средств).
⚙️ PoC (Proof of Concept) — техническая проверка реализуемости в приближённых к реальности условиях.
👥 MVP (Minimum Viable Product) — минимальный продукт для проверки "ядра ценности" на реальных пользователях.
💼 Pilot — частичное внедрение в production; доказательство, что решение может и будет жить в эксплуатации; финальный approval перед масштабированием.
🌍 GA (General Availability) — довнедрение и доступность для всей целевой аудитории.
Сводную таблицу по всем этапам смотрите в Приложении в конце статьи.
🔍 Пример на этапах: миграция баз данных с on-prem в облако (повествовательно)
💡 Idea

Generated by Copilot
Реализация крупной инициативы начинается с "Идеи".
Наша идея проста и амбициозна: перенести около ста баз данных — вперемешку prod и non-prod — в облако.
Важно не «как», а «зачем» — и стоит ли игра свеч? Анализируем возможности, плюсы и минусы, считаем TCO, проводим встречи со стейкхолдерами (бизнес, безопасность, эксплуатация, финансы). Здесь же можно остановиться, если «игра не стоит свеч» — самое время закончить проект без убытков 🙂.
🧠 Prototype
Generated by Copilot
Дальше нужна «картинка будущего», чтобы все говорили об одном и том же. И чтобы инициатива не зашла в ситуацию, когда кажется, что обсуждаем одно и то же, а на деле каждый понимает своё, — как можно быстрее переходим в практическую плоскость. Нужен рабочий стенд — это и есть прототип.
Поднимаем экземпляр базы данных (или несколько) в облаке. Загружаем анонимизированные данные. Например, можно собрать отдельную БД с аудит-логами разных систем на сотни гигабайт, предварительно их анонимизировав.
Теперь у нас есть рабочее черновое решение. На его основе можно строить реальные демо и убеждать стейкхолдеров эффективнее. Кроме того, на следующих стадиях мы сможем оттачивать гипотезы уже на реальном продукте, пусть ещё в форме набросков.
⚙️ PoC (Proof of Concept)

Generated by Copilot
Теперь — практика. Цель PoC — доказать, что инициатива будет работать. Делаем внедрение, максимально приближённое к реальности.
Если в прототипе мы прежде всего убеждали СЕБЯ 🧑, что всё ВООБЩЕ 🤔может работать, то теперь настало время убедить БИЗНЕС 💼 И речь не только о работоспособности целевого решения, но и о самом методе движения к нему: последовательности шагов, повторяемости процедуры, понятных входах/выходах и критериях качества.
Берём non-prod базу (с данными, максимально приближёнными к prod) и клонируем её в облако. Прогоняем процесс миграции, фиксируем шаги, пишем первичную документацию, проводим замеры. Приглашаем реальных пользователей и владельцев приложений потестировать. Master-копия остаётся on-prem.
Результат: у нас есть продукт (или его часть), который работает и потенциально приносит value — это подтверждают замеры. Есть повод вынести на очередной approve (go/no-go).
👥 MVP (Minimum Viable Product)

Generated by Copilot
Первая настоящая эксплуатация — но в управляемом контуре. Цель MVP — доказать, что продукт может эксплуатироваться. Конечные реальные пользователи пробуют продукт и дают обратную связь. Они — главные тестировщики, а не специалисты поддержки и разработчики. Продукт может не иметь всех заявленных фич, но core-фичи на месте. Если до этой стадии мы тянули с трудом сани в гору, то после MVP уже катимся с ветерком с горы. Остальные стадии (Pilot, GA) с точки зрения приёмки уже выглядят как sanity-checks.
Два практичных сценария для переноса баз данных в облако (в идеале оба):
1) Частичный перенос в облако значимых для бизнеса БД, но ещё non-prod — например, UAT-серверы (User Acceptance Testing) с серьёзной нагрузкой.
2) Частично переносим некритичный prod.
Перенесённое в рамках MVP — с вероятностью ~99% остаётся в облаке.
Если мы всё делали как надо, объём проекта (scope) уменьшается: то, что уже переехало в рамках MVP, повторно переносить не придётся.
Что получаем?
Подтверждённая жизнеспособность решения в эксплуатации.
Переключение/откат проверены и описаны.
Есть опорный контур для масштабирования.
Документация и рутины (чек-листы, runbook, окна) в рабочем состоянии.
Сопротивление стейкхолдеров должно значительно упасть.
💼 Pilot

Generated by Copilot
К началу Pilot, как правило, уже понятно, что проекту «быть»: утверждён бюджет, подписаны контракты с поставщиками, согласованы сроки и объём. Теперь задача — организовать плавное и максимально безопасное «приземление» План по дням/неделям/месяцам есть — осталось начать. Чтобы снизить риск, выбираем лояльных заказчиков и приложения, сбой которых не остановит бизнес, но эффект будет заметен; одновременно в пилоте проверяем и подтверждаем бизнес-ценность (метрики результата, экономия/затраты, отклик пользователей, готовность владельцев процессов).
Pilot — это работа с реальными пользователями и PROD-нагрузками. Здесь в последний раз оттачиваем процессы и доводим документацию.
Например, выбираем две базы: одну с OLTP-нагрузкой и одну с DWH. Они не критичны, но и не самые лёгкие — влияние видно. Переносим их в облако и делаем все нужные измерения.
Что получаем?
Работает у реальных пользователей без сюрпризов.
Переключение/откат отрепетированы, шаги и ответственные понятны.
Мониторинг даёт нужные сигналы без лишнего шума.
Инструкции и чек-листы готовы, контакты дежурных назначены.
Интеграции проверены; скрытые зависимости сняты или в плане.
Затраты подтверждены реальными счетами.
Есть чемпионы-пользователи и референсы.
Короткий список что доделать до GA с приоритетами.
🌍 GA (General Availability)

Generated by Copilot
Финальный поворот — не эффектный «большой релиз», а аккуратная дораскатка и переход к обычной жизни. Планируем волны, заранее коммуницируем freeze-периоды, делаем cutover по чек-листам, усиливаем дежурства и связь с бизнесом. Путь отката должен быть реальным*а не «на бумаге» — проверен на репетициях. Параллельно доводим наблюдаемость и эксплуатацию до стандартов: дашборды, алерты, runbook’и, регламенты эскалации, расписания on-call.
Через какое-то время, когда новый ритм стабилизируется, аккуратно выводим из эксплуатации старые ресурсы — чтобы не платить дважды и убрать путаницу в контурах.
Что получаем?
Продукт доступен всей целевой аудитории и стабильно работает.
Эксплуатация ведётся по устойчивым процедурам (мониторинг, алерты, on-call, регламенты).
Предсказуемые затраты*и прозрачный биллинг; legacy выключен.
Метрики стабильности/производительности/стоимости под контролем, риски локализованы.
📌Заключение
В больших инициативах хаос возникает не из-за нехватки умных людей, а из-за отсутствия общего языка и последовательности. Шесть этапов — это простой контракт ожиданий между бизнесом, инженерами, безопасностью и эксплуатацией. Каждый шаг «сжигает» конкретный класс рисков:
💡 Idea — риск «делаем ли мы то, что нужно»; 💡 Prototype — риск непонимания решения; ⚙️ PoC — риск технической реализуемости; 👥 MVP — риск жизнеспособности в реальной среде; 💼 Pilot— риск эксплуатационной готовности; 🌍 GA — риск операционной устойчивости и масштабирования.
Почему нельзя «перепрыгнуть»? Потому что ускорение без снятия рисков — это долг с высокой ставкой. Типичные антипаттерны:
⚙️ Вечный PoC: нет мостика к эксплуатации и критериям выхода.
👥 MVP как конечная остановка: «временное» становится постоянным без наблюдаемости и отката.
💼 Пилот без exit-критериев: бесконечная бета, в которой всё «почти готово».
🌍 GA без плана вывода legacy: двойная оплата и путаница в контурах.
Не бойтесь останавливаться: если данные на любом этапе говорят «нет», это тоже результат. Вы экономите бюджет, сокращаете риск и оставляете после себя полезные наработки — документацию, скрипты, метрики, выводы.
И наконец, этот каркас работает не только для миграций: платформенные изменения, интеграции, запуск новых сервисов, крупные рефакторинги — везде, где много участников и высока цена ошибки. Сила подхода в том, что он делает сложное управляемым и социально приемлемым: все понимают, где мы находимся, какой следующий шаг, чем меряем успех и как откатываемся, если что-то пойдёт не так. Определите свой текущий этап, назовите следующий инкремент и договоритесь о критериях — и «большая гора» превратится в серию коротких, понятных подъёмов.
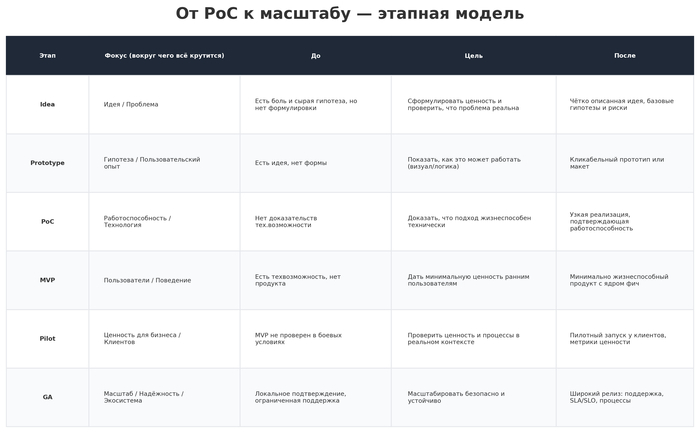
📎 Приложение: Сводная таблица по этапам
Читайте мою серию: Усталый Босс
Прошлые статьи:












