День добрый! Кто шарит в установке программ и разработкой ПО, объясните пожалуйста – программа или приложение должно ли спрашивать разрешение, путь и папку для установки? Или тут что-то не так? Скачал ЯндексМузыка, просто нажал на EXE, и на рабочем столе оно… так и должно быть?
Далее вопрос самому Яндекс –
- Почему приложение ЯндексМузыка установилось автоматом на ВИН10? почему не было при установке приложения, вопросов что, и куда ставить? и соглашения тоже не заключалось? Куда оно ставится по умолчанию? Почему пользователю не показывают путь установки и не сообщают о правах приложения/программы?
На вопрос Яндекс пока не ответил)
Стало просто интересно , раньше не замечал просто что, проги, могли по EXE прописать путь и все себе разрешения по умолчанию… кроме вирусов… но я думаю все же хорошо? Яндекс
Кажется, что рекомендательный движок музыкального сервиса - это черный ящик. Берет кучу данных на входе, выплевывает идеальную подборку лично для вас на выходе. В целом это и правда так, но что конкретно делают алгоритмы в недрах музыкальных рекомендаций? Разберем основные подходы и техники, иллюстрируя их конкретными примерами.
Начнем с того, что современные музыкальные сервисы не просто так называются стриминговыми. Одна из их ключевых способностей - это выдавать бесконечный поток (stream) треков. А значит, список рекомендаций должен пополняться новыми композициями и никогда не заканчиваться. Нет, безусловно, собственноручно найти свои любимые песни и слушать их тоже никто не запрещает. Но задача стримингов именно в том, чтобы помочь юзеру не потеряться среди миллионов треков. Ведь прослушать такое количество композиций самостоятельно просто физически нереально!
Так как они это делают?
Если ваши музыкальные алгоритмы не похожи на это, то даже не предлагайте мне скачивать приложение!
Чтобы сделать годную рекомендацию, сервису нужны три сита…
Первое сито - это так называемые рекомендации на основе знаний (knowledge-based). Это значит, что сервис аккумулирует всю доступную информацию об одном пользователе - что он слушает (например, каких артистов или жанр), как часто, что лайкает, что дослушивает, что проматывает дальше и т.д. Учитываются сотни или даже тысячи факторов. Разумеется, собираемые данные анонимны.
После этого сервис делает рекомендацию. Причем она может даваться безотносительно общих предметных знаний сервиса. Например, если мы видим, что Вася добавил в плейлист Metallica “Nothing Else Matters”, то с большой вероятностью ему понравится и “Unforgiven”. Для такого вывода нам не нужна дополнительная информация.
Помимо прочего, рекомендации на основе знаний помогают решить проблему “холодного старта” (это когда свеженький и тепленький юзер только-только зарегался), предлагая новому пользователю тот контент, который соответствует его требованиям с самого начала использования.
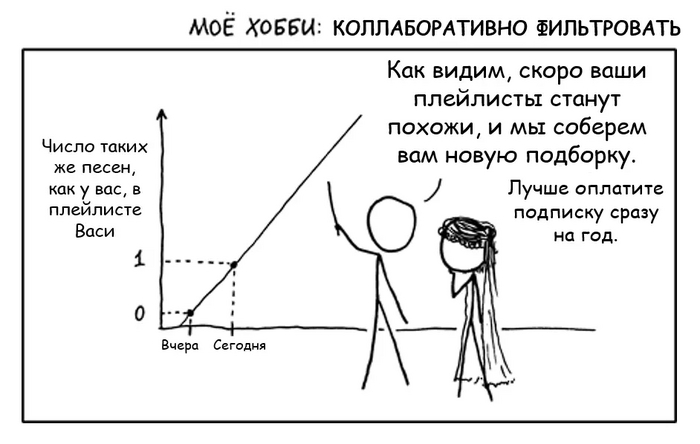
Второе сито - коллаборативная фильтрация. Пожалуй, это самый главный прием и краеугольный камень любого стриминга. Хотя коллаборативная фильтрация и может издалека походить на анализ предпочтений пользователей, на самом деле это совсем другая техника и технология - гораздо более продвинутая и математически точная.
Работает она на следующем допущении:
Пользователи, которые одинаково оценили какие-либо композиции в прошлом, склонны давать похожие оценки другим композициям в будущем.
Давайте разберем на примере, очень упрощенно:
Допустим, у Васи затерты до дыр треки:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Scooter “How much is the fish?”
Валерий Леонтьев “Мой дельтаплан”
Какую закономерность можно выявить на основе этого набора? Да никакую. Просто мешанина из разных жанров, артистов и эпох.
Тем не менее, у сервиса также есть пользователь Петя, чей плейлист по удивительному совпадению похож на Васин, а именно:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Dua Lipa “Swan Song’’
Валерий Леонтьев “Мой дельтаплан”
Все треки одинаковые, кроме одного. У Васи это Scooter, у Пети - Dua Lipa.
По логике коллаборативной фильтрации, есть вероятность, что если Вася и Петя “обменяются” этими песнями, то обоим понравится. Поэтому такие рекомендации и называются “коллаборативными” - пользователи как бы сотрудничают, обмениваясь предпочтениями друг с другом.
Коллаборативная фильтрация in a nutshell.
Понятное дело, что коллаборативная фильтрация работает не на двух пользователях, и даже не на двух тысячах. А вот на паре миллионов юзеров, у которых удается найти критическую массу одинаковых композиций - уже вполне. Также очевидно, что я привожу примеры карикатурно непохожих песен “из разных миров”. Я это делаю намеренно, чтобы подчеркнуть, что подход помогает делать рекомендации на основе данных, в которых, казалось бы, не за что зацепиться в поисках общего паттерна. Понятное дело, что в реальности между прослушанными и рекомендуемыми треками скорее всего будет больше схожести.
Так почему этот способ дает хороший результат, когда между наборами треков может не быть ничего общего?
Ну смотрите. Музыкальные предпочтения зависят от целого множества факторов - ваш вкус в целом, ваше настроение сегодня, работаете вы или же чиллите, болит ли у вас голова, с какой ноги вы сегодня встали, что конкретно на завтрак ели и многое-многое другое. Запихивать все эти переменные в строгое правило с четкими “если Х, то У” - дело неблагодарное. А вот если ИИ эмпирически прошерстит огромную выборку и найдет в ней похожие участки, то это совсем другое дело.
Здесь примерно та же логика, по которой если нейросетке скормить кучу картинок с котиками, а потом попросить её нарисовать котика, то она скорее всего изобразит туловище, к которому будут приделаны 4 лапы, хвост, шерсть и мордочка с усами и треугольными ушками. То есть нюансы изображения могут различаться, но основные свойства котика (назовем их “котиковость”) будут переданы. А значит, концептуально результат будет верный.
Так же и с рекомендациями в рамках коллаборативной фильтрации. Разве можно рационально объяснить, почему одна группа любителей Slipknot вдруг слушает песни Димы Билана (наверно, чтобы вкус перебить, такой себе имбирь между разными роллами), а другая группа - Леди Гагу? Вряд ли. Однако, если такие два паттерна существуют, то это значит, что слушающим Леди Гагу металлистам можно попробовать включить Билана, а их визави, наоборот, протолкнуть в поток Poker Face или Alejandro. Ведь точный эмпирический анализ большой выборки попадает в яблочко как минимум очень часто.
Наконец, третье сито, которое отлично дополняет первые два. Это рекомендации на основе контента (content-based). Здесь уже анализируется непосредственно сама композиция. Сервис берет песню, разбивает её на куски, отрезки или даже отдельные “квадраты”, после чего анализирует каждый отдельный элемент звука и ищет песни, технически похожие на анализируемую. Есть вероятность, что если Васе нравится песня Х с определенным звучанием и ритмом, то ему понравится и песня Y с похожими музыкальными свойствами.
Здесь есть важный нюанс. Звучание песни анализирует машина по каким-то техническим критериям, которые понятны ей, машине. А вот мы, люди, можем кайфовать от песни иррационально. Например, не только благодаря ритму мелодии, аранжировке или тембру голоса исполнителя, а еще и благодаря вайбу композиции, а то и символическому капиталу вокруг неё (например, если песня культовая или просто трендовая и модная-молодежная).
Поэтому, content-based рекомендации не всегда дают хороший эффект сами по себе, но служат отличным дополнением других способов фильтрации.
Также, такой способ - рабочий вариант для так называемых “холодных треков”. Это композиции, которые только-только выложили на стриминг. Допустим, новая песня известного исполнителя, либо же неизвестный трек совсем нового певца-ноунейма, которому тоже хочется славы. В таком случае плясать от самой композиции - полезное умение. Ведь трека еще нет в плейлистах тысяч и миллионов пользователей, а значит, порекомендовать его с помощью коллаборативной фильтрации или через knowledge-based вряд ли получится.
Резюмирую принципы рекомендательных движков музыкальных стримингов с помощью классического мема.
Итак, мы разобрали три основных техники, с помощью которых стриминги рекомендуют звуковой контент нашим ушкам. Разумеется, современные продвинутые сервисы обычно используют их все (получаются “гибридные рекомендации”), прикручивая к каждому из них свои авторские фишки.
Как конкретно это работает. Разбираю на примере гибридного подхода Яндекс Музыки
Теперь предлагаю показать на практике, как конкретно описанные выше техники работают. Для иллюстрации я буду использовать пример Яндекс Музыки. Потому что сам давно пользуюсь этим сервисом (думаю, уже лет 10), а также по той причине, что недавно у них прошло большое обновление алгоритма, которое внесло важные изменения в механизм рекомендаций. Ну и еще потому что всегда приятнее разбирать глобальные лучшие практики на отечественном сервисе, который в полной мере им соответствует.
Итак:
Базово рекомендательный движок Яндекс Музыки реализован через Мою волну, которая появилась на главной странице сервиса пару-тройку лет назад. По умолчанию этот поток сбалансированный - это значит, что он комбинирует любимые и привычные треки (которые пользователь и так активно слушает) с новыми композициями, причем в комфортной пропорции. По своему опыту скажу, что микс между добавленными и новыми треками по умолчанию примерно 50:50. При этом 30-40% новых я лайкаю, чтобы сохранить к себе. За счет этого алгоритм дообучается и адаптируется.
Однако Мою волну можно дополнительно кастомизировать через настройки. Нажимаем кнопку под плеером и проваливаемся вот в такое меню.
Как видим, параметров кастомизации вроде бы немного, но при этом изменения могут быть весьма существенными. К тому же, из скриншота видно, что настройки потока можно включать и отключать в разных комбинациях. Используя свои знания наивысшей математики, я перемножил 5 (Занятия) на 3 (Характер) на 4 (Настроение) и на 3 (Языки) и получил примерно 180. Ну ладно, пришлось использовать калькулятор, подловили…
Так что, внутри одной Моей волны на самом деле сидят очень много разных Моих волн.
Остановимся детальнее на настройке под названием “Характер”. Можно попросить движок делать больше акцента на моих залайканных треках (“Любимое”), или же наоборот чуть абстрагироваться от знаний о пользователе и поддаться общим трендам (“Популярное”).
Но поскольку статья все же о рекомендательном функционале, то остановимся подробнее на настройке “Незнакомое”. Ведь именно глядя на способность подбирать релевантные треки из всего внешнего многообразия можно оценить движок. Итак, если включить “Незнакомое”, то алгоритм сделает серьезный крен в сторону ранее незнакомых композиций.
Кстати, недавнее обновление касалось именно этой настройки. “Незнакомое” получила новый ранжирующий алгоритм, благодаря чему стала более смело предлагать новые композиции, которые, тем не менее, должны соответствовать музыкальным вкусам пользователя.
С обновленной настройкой юзер получает новый аудиоконтент, при этом не ощущая особенно сильных скачков и перепадов. То есть, даже если алгоритм решит выйти за пределы рекомендационного пузыря, дабы расширить музыкальные горизонты пользователя, то он все равно будет оставаться в рамках его предпочтений и смежных жанров. Проще говоря, несмотря на экспериментирование, подбрасывание неактуальной музыки будет сведено к минимуму.
Уважаемые газеты пишут, что теперь пользователи сервиса добавляют к себе в “Коллекцию” примерно на 20% больше новых треков. Для артистов (в том числе молодых и начинающих) это тоже важный ништяк, поскольку повышается вероятность, что их творчество распространится и взлетит среди новой аудитории.
Так вот, для поиска этих самых новых композиций сервис как раз и применяет гибридный подход, объединяющий коллаборативную фильтрацию, анализ контента и фильтрацию на основе знаний о пользователе. Поговорим о нем детальнее.
Начнем с пользователя
Для начала, машина кушает все “долгосрочные” (очень условно их так назову, дорогие технари, не ругайтесь) данные о пользователе. Какие жанры и исполнителей он указывал как любимых, когда регистрировался? Что у него лежит в плейлисте? Что там лежит давно, а что недавно? Что удалялось? Что из лежащего давно он слушает регулярно или иногда, а что лежит мертвым балластом? И еще 100500 факторов и паттернов.
На эти “долгосрочные” знания о юзере накладываются конкретные действия.
Например, обычно Вася слушает треки в одной последовательности, а вчера решил включить в другой. Алгоритм тоже это примет к сведению. Возможно, учтет сразу, а, может быть, посмотрит на динамику последовательности при парочке ближайших использований (кто ж знает, как эта “черная коробка” решит там у себя внутри).
Не забываем, что алгоритмом все-таки заведует продвинутая ML-моделька, которая любит сама себя дообучать и всячески развивать. Так что, хотя человеки и знают принципы её мироустройства, точно предсказать результаты из “черного ящика” решительно нельзя.
Разумеется, движок учитывает, дослушал ли песню наш лирический герой, смахнул её или вовсе влепил ей лайк.
Далее - анализ контента
Вторая составляющая годной рекомендации - это анализ самой композиции. Для этого сервис преобразует трек в специальный формат - цифровой аудиовектор.
Для этого сервис разворачивает трек во времени и раскладывает его на частотные диапазоны, получая спектрограмму. Она передается специальной аудиомодели с нейросетью-энкодером, которая сворачивает спектрограмму в аудиовектор, или аудиоэмбеддинг (это когда сервис прячет в аудиофайле специальные метки - о песне, исполнителе, жанре и т.д.).
У похожих по звучанию треков такие векторы расположены близко друг к другу в многомерном векторном пространстве. У разных треков, соответственно, наоборот.
За счет таких манипуляций алгоритм может разложить трек буквально на атомы, чтобы потом сравнить каждую “элементарную музыкальную частицу” с аналогичными частицами других композиций.
Алгоритм сервиса преобразует трек в аудиовектор, расщепляя его на мельчайшие музыкальные элементы, чтобы проанализировать каждый из них. Вижу так.
Этот прием дополнительно повышает точность рекомендаций.
Наконец, коллаборативная фильтрация
Залезть в глубинные сущности этой техники конкретного сервиса непросто. Но каждый уважающий себя продвинутый стриминг старается довести эту технологию до высокого уровня.
За основу берется принцип, который я описал в первой части статьи. Но реализуется он, само собой, на предпочтениях миллионов слушателей. Алгоритм анализирует обезличенные данные массы пользователей, после чего прогнозирует музыкальные интересы конкретного человека, добиваясь максимально точных попаданий. В основе всего этого движа лежит матрица взаимодействия, составленная из различных оценок пользователей. Если упрощенно, то это такая табличка (ооочень большая), где отображаются все взаимодействия юзера с сервисом. Потом с матрицей работают алгоритмы машинного обучения - они уже обрабатывают данные и передают их в обобщенную модель, которая и отвечает за рекомендации.
Три типа фильтрации в итоге объединяются в единый machine-learning алгоритм под названием CatBoost, который уже генерирует для каждого юзера персональную последовательность треков с учетом множества вышеописанных факторов.
В итоге в алгоритмическом магическом котле заваривается тот самый вуншпунш, который мы готовы потреблять ушами в течение часов и дней, поддерживая свой энергичный рабочий настрой, умиротворенный расслабленный вайб либо же вызывая внезапный эмоциональный порыв. Подчеркнуть нужное в зависимости от ваших текущих целей, настроения и самочувствия.
Теперь вы знаете чуть больше про рекомендательные системы стриминга, особенно музыкального. Надеюсь, было интересно и полезно. Есть что добавить или с чем поспорить? Пишите в комменты.
Если вам понравилось, то подписывайтесь на мои тг-каналы. На основном канале - Дизрапторе - я простым человечьим языком и с юмором разбираю разные интересные штуки из мира бизнеса, инноваций и технологических новшеств (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили). А на втором канале под названием Фичизм я регулярно пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.
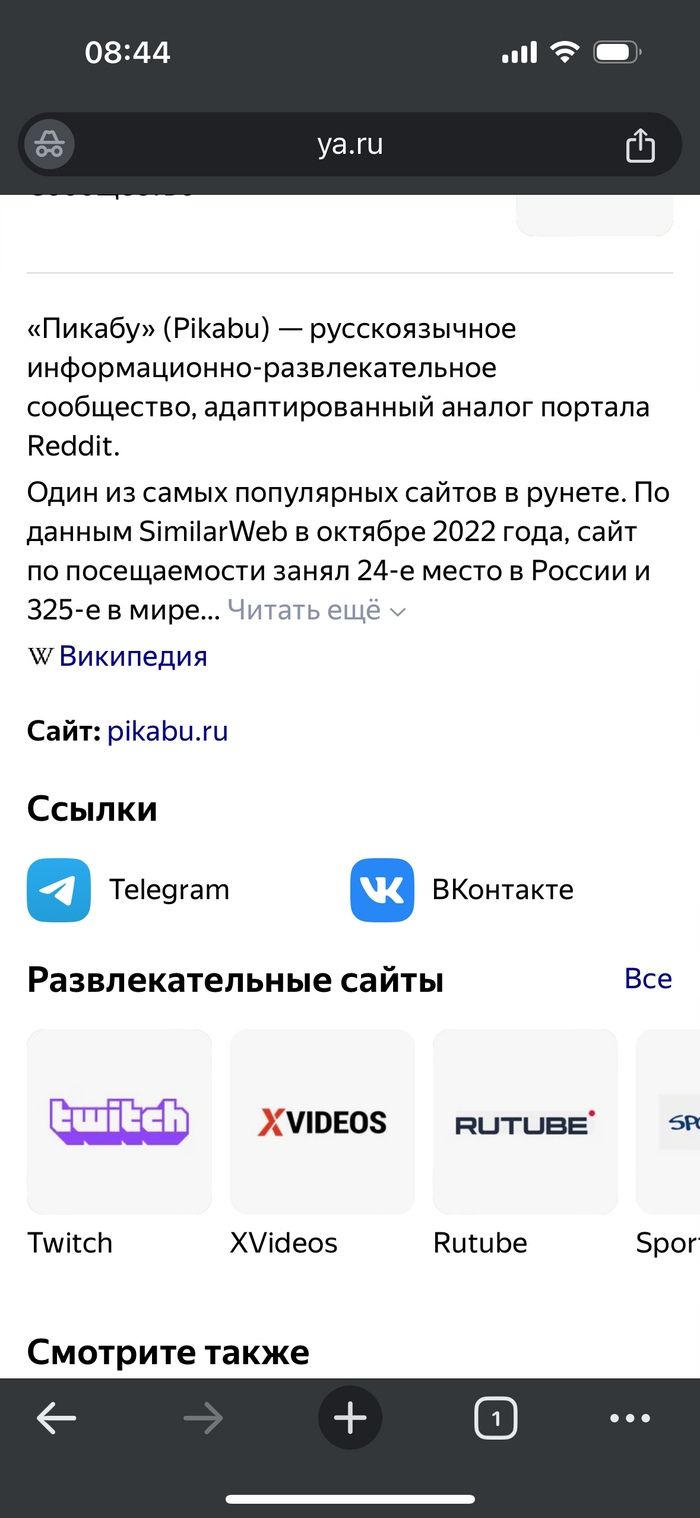
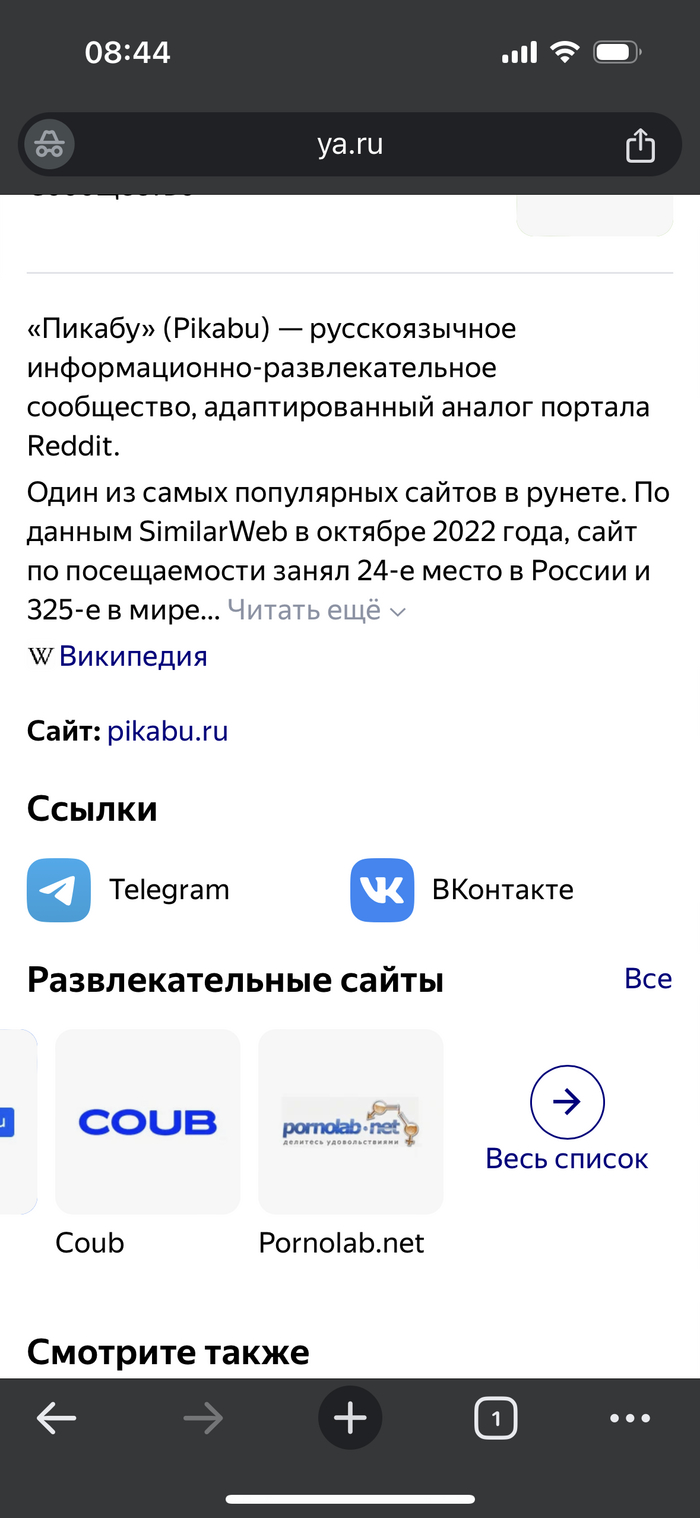
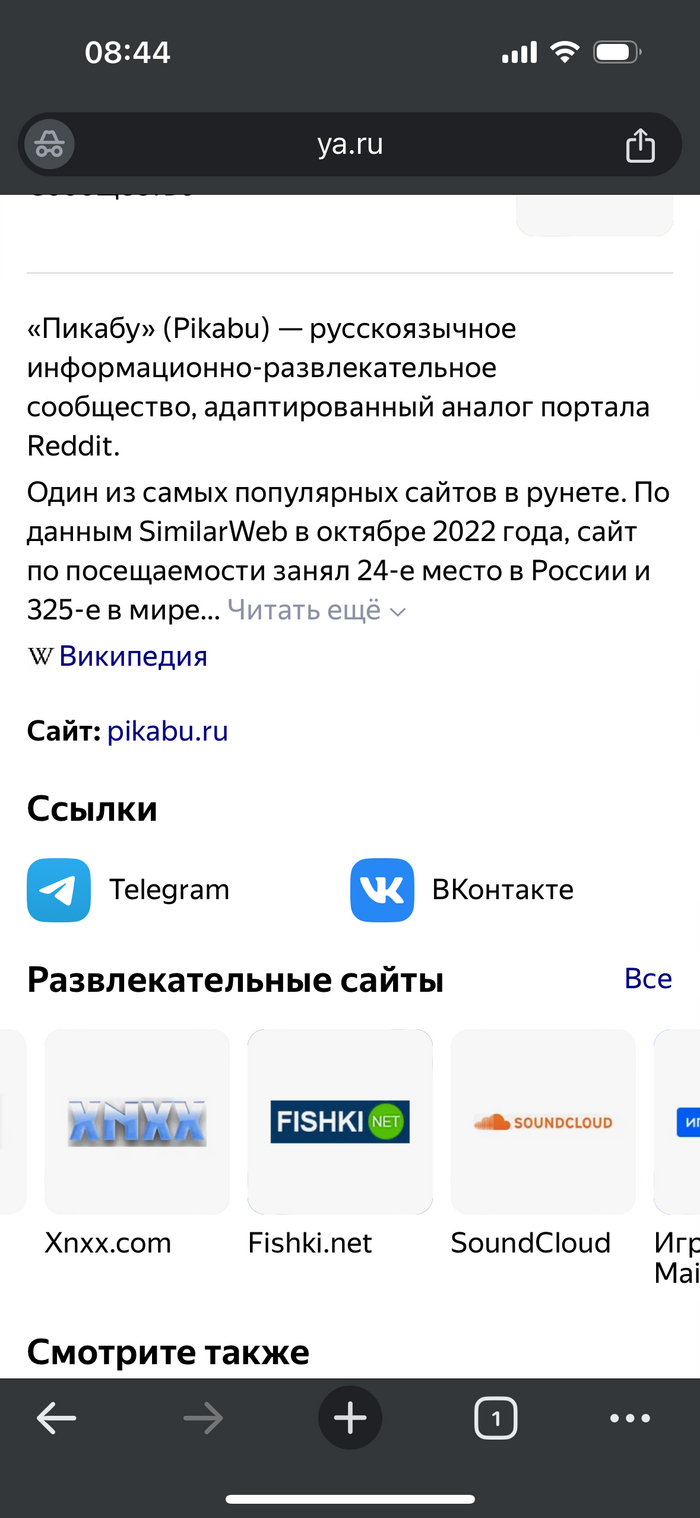
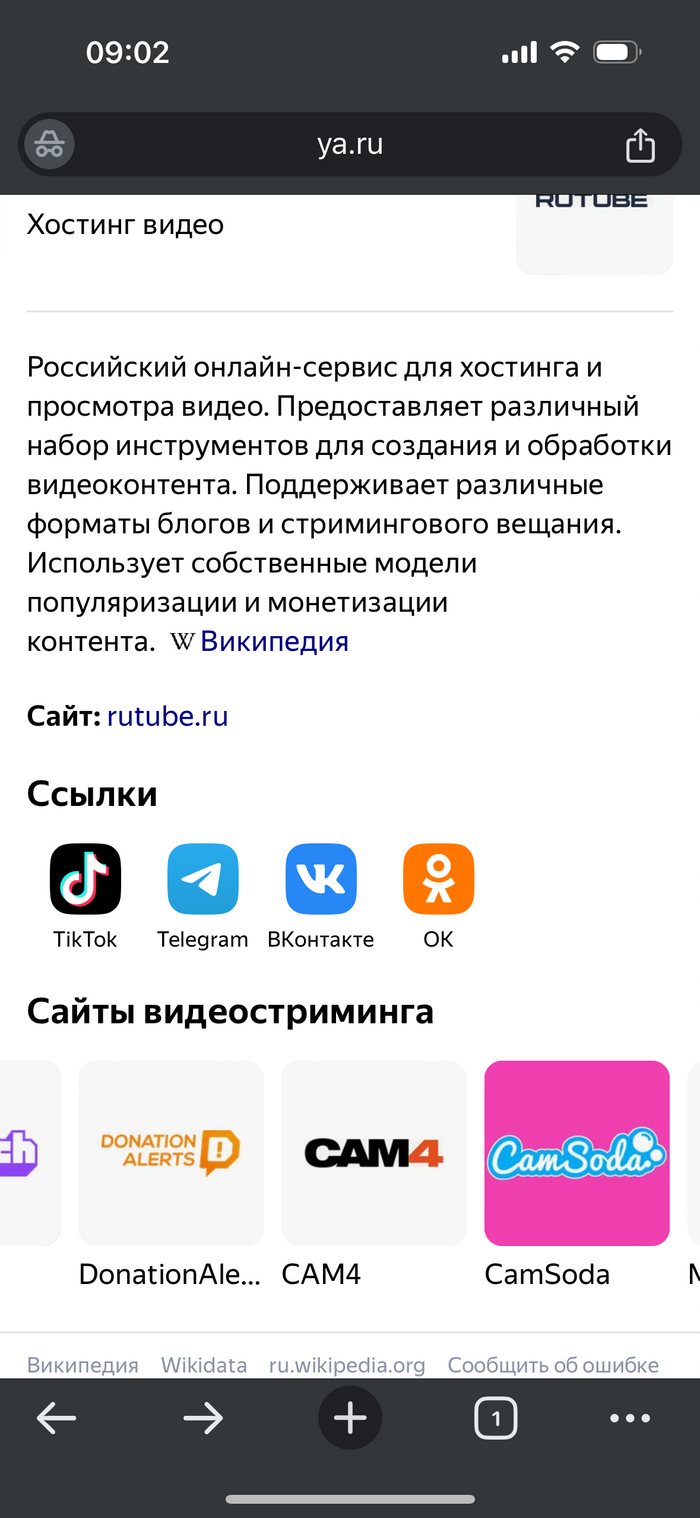
На фото рекомендации из карусели в поисковой выдаче яндекса при запросе «Пикабу» и «Пикабу горячее». «Порно в массы» это новый лозунг Яндекса?
1/3
Прикольно еще, что по запросу «рутуб», выдает сервисы взрослого стриминга как аналоги, рутуб у него в этой категории? :
А как вам описание, сгенерированное YAGPT для одного из сайтов взрослого стриминга:
Для взрослых, да и не для взрослых.
При этом «для взрослых и не для взрослых» он выдрал из Википедии.
Кстати по запросу «ютуб» таких рекомендаций нет:
Такое ощущение, что Яндекс взялся за продукт и сильно поспешил, и пока что не в силах его отточить. Тем самым изрядно добавил мусора в поисковике, нарушая же свои собственные правила под припиской «создано yaGPT, результаты могут быть не точными», а что еще может порекомендовать такая система, сняв с себя ответственность?
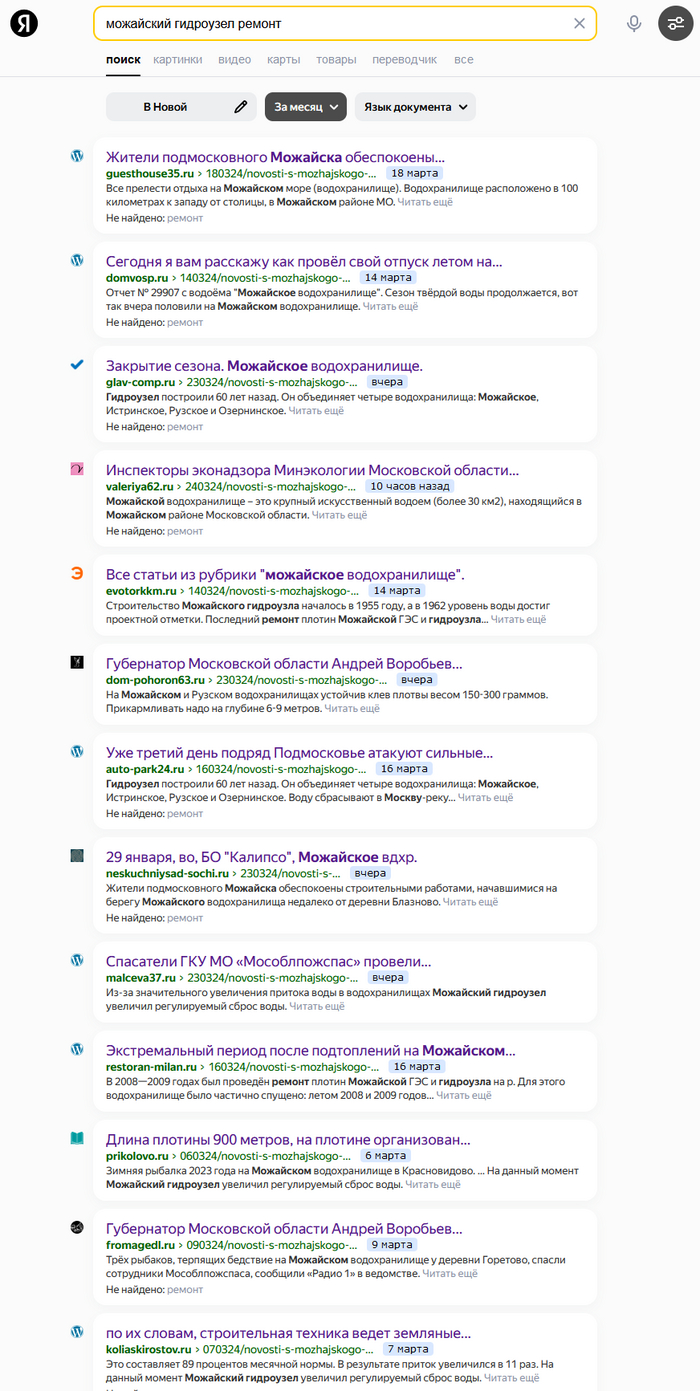
Набрал в Яндексе поисковую строку "можайский гидроузел ремонт", "за месяц". Вывалился результат. На первой странице 14 результатов. На второй 9. На третьей 9. ВСЕ 32 найденных - однотипные сайты с автогенерацией бессмысленного, мусорного текста. Сайты, сделанные с непонятными целями, содержащие компиляцию фрагментов текстов по разным темам. Абсолютно бессмысленные.
Все, всё - бессмысленные компиляции!
При этом сайты, вероятно, генерятся динамически - если перейти, то у всех одинаковый заголовок ("Новости с можайского водохранилища на сегодня"). Дизайн [пока] однотипный и сразу позволяет распознать подделку.
В самом же списке найденных результатов из отличить от нормальных трудно.
Что происходит? Какая-то атака клонов? Всего лишь сбрендившие ловцы кликов, или сложная атака с неясными целями?
В текущей ситуации инструмент поиска Яндекса внезапно стал бесполезным... Совсем... Это для меня довольно странное открытие - Яндекс больше не способен искать...
Тема старая, но до сих пор приводит в недоумение - зачем вы так делаете??? В своем блоге вы пишете (речь о рекламных банерах):
Начиная с первой недели февраля 2018 года Яндекс прекращает использование этих форматов на своих площадках, а также будет фильтровать их в Яндекс.Браузере. Это означает, что ни один из перечисленных форматов не будет появляться на сайтах Яндекса и любых ресурсах, открываемых в Яндекс.Браузере. Мы также прекратим продажу таких форматов на площадках-партнёрах Рекламной сети Яндекса.
При этом просто впендюриваете рекламу на полэкрана
SEO (Search Engine Optimization) развивался как процесс оптимизации веб-сайтов для улучшения их позиций в результатах поиска. Он начал развиваться вместе с появлением поисковых систем, таких как Google, Yahoo, Bing и другие. SEO появилось как реакция на появление поисковых систем и развитие интернета как информационного пространства. Сайтов становилось все больше и владельцы начали осознавать необходимость выделить свой ресурс среди конкурентов и привлечь больше посетителей.
В результате стали появляться стратегии для оптимизации сайтов под поисковые системы, чтоб выйти на первые позиции в выдаче. SEO как и многие инструменты был создан естественным путем и по потребностям рынка.
Первые поисковые системы:
Яндекс Дата создания: 23 сентября 1997 г.
Rambler Дата создания: 1996 г.
Yahoo! Дата создания: 2 марта 1995 г.
Google Дата создания: 2 октября 1998 г.
Погрузимся в историю:
Первая SEO стратегия, которую можно назвать успешной и популярной, была разработана в середине 1990-х годов. Один из первых и самых известных SEO специалистов - Джастин Стейнер - создал методы оптимизации сайтов для поисковых систем, которые впоследствии стали основой для современных SEO стратегий.
Примером первого SEO специалиста в истории можно назвать Алана Эмтейджа, который в 1996 году создал первый поисковый движок под названием "Archie". Он позволял пользователям найти информацию в интернете по ключевым словам.
Он разработал сценарий, который автоматизировал процесс поиска и копирования данных с FTP-серверов на локальные файлы. Это позволило быстро находить нужную информацию с помощью стандартной grep-команды Unix. Таким образом, Алан создал первую в мире поисковую систему под названием Archie, что является сокращением от слова Archive (архив).
Далее SEO прошел через несколько этапов развития:
Начало 2000-х годов: первые шаги в области SEO были связаны с использованием метатегов, ключевых слов и других техник для повышения видимости в поисковых системах.
В 2000-х годах Google начал развиваться, как основная поисковая система в мире. Компания выпустила ряд новых алгоритмов, чтобы повысить качество поисковой выдачи, включая алгоритм PageRank, который оценивает веб-страницы на основе количества и качества ссылок на них.
Середина 2000-х годов: с развитием алгоритмов поисковых систем появились новые методы оптимизации, такие как контент-маркетинг, backlinking и улучшение пользовательского опыта.Уже тогда контент-маркетинг стал одним из ключевых инструментов для привлечения посетителей на сайты и улучшения их позиций в поисковых результатах. Это означало создание качественного и ценного контента, который был бы интересен для пользователей.
Конец 2000-х - начало 2010-х годов: с появлением социальных сетей и мобильных устройств SEO изменился, став более ориентированным на пользователей и адаптивным.
Это время было отмечено значительными изменениями в подходах к SEO. Новые соц.сети стали активно появляться, а старожилы в виде “Facebook” закрепляли свои позиции. Таким образом, SEO приобрел новые аспекты, включающие в себя социальные сети, мобильную оптимизацию и пользовательский опыт.
В свете этого поисковые системы начали учитывать не только ключевые слова на странице, но и поведенческие факторы, такие как время пребывания на сайте, отказы и т.д.
Современность: сегодня мы пришли к тому, что SEO-оптимизация включает в себя множество аспектов, таких как оптимизация контента, техническая оптимизация, работа с ссылочной массой, аналитика и мониторинг результатов.
Благодаря использованию искусственного интеллекта и машинного обучения SEO специалисты могут более точно анализировать данные, определять тренды и предсказывать изменения в алгоритмах поисковых систем.
Современное SEO требует от специалистов глубоких знаний и навыков в области аналитики, технологий и маркетинга. Они должны быть готовы к постоянным изменениям и обновлениям в индустрии, чтобы эффективно продвигать сайты и улучшать их позиции в поисковой выдаче.
Более того, во многих компаниях SEO уже стало работать в симбиозе с маркетингом и PR. SEO продолжает развиваться и приспосабливаться к изменяющимся требованиям поисковых систем и пользователям.
Как вы думаете, в какую сторону будут меняться поисковые системы в будущем и как это повлияет на поисковую оптимизацию?
Видимо недовольства на тему прошлой капчи учли и поигрались с цветами. Теперь вот такая капча постоянно вылазит. Яндекс, за что? Как это вообще решать?
«Сайт в топ за 3 дня! Результат уже через 24 часа!» - подобные объявления наверняка видели все, кто интересовался SEO – продвижением. Знакомьтесь, это накрутка ПФ (поведенческих факторов).
Появилась данная услуга благодаря тому, что поисковики, в особенности Яндекс, при ранжировании сайтов в поиске большое внимание уделяют поведению посетителей на этих сайтах.
Логика примерно такая:
Пользователь открыл сайт из поиска, провёл там 10-15 секунд, закрыл, и смотрит другие сайты по тому же запросу? Считаем, что сайт плохой, не удовлетворил запрос, опускаем его ниже.
Пользователь открыл сайт, изучал его приличное время, походил по разным страницам, положил товар в корзину, и другие сайты по этому запросу дальше не смотрел? Сайт хороший, удовлетворил запрос пользователя, ставим на позицию выше.
Если когда-то можно было сделать подобную накрутку самому, просто меняя ip и браузеры, то со временем алгоритмы сильно усложнились. Так и появились ботофермы, которые используются для накрутки. Боты «нагуливаются» по разным сайтам, чтобы создать историю поиска и притвориться живыми людьми, а по команде админа посещают нужный сайт по нужному запросу, проводят там нужное время, осуществляют нужные действия.
Таким образом нужный сайт притворяется хорошим для посетителей, и поисковик ставит его на первые места.
Обсуждение этой темы идёт давно, и Яндекс уже не раз обещал решить эту проблему. Но накрутка работает до сих пор. Чисто теоретически, в Яндекс метрике есть показатель «роботность», который должен отделять реальных пользователей от ботов. Но по факту работает он хрен знает как, и нормальных ботов не определяет. При этом, у меня был сайт, по которому точно ничего не накручивали, но роботность определялась аж в 70%.
Большинство открытых сервисов по накрутке (то есть тех, куда может зайти любой желающий и заказать накрутку) работают очень слабо, или не работают вовсе. Заказы реальным людям на сервисах по типу «выполни простое задание за 3 копейки» аналогично.
А вот приватные фермы и закрытый софт, которые владельцы используют только напрямую для своих клиентов, или дают доступ либо по знакомству, либо за большие деньги – работают очень хорошо. И да, эти ребята вполне могут за 3 дня запулить сайт из топ-50 в топ-3.
Пример рекламы накрутчиков.
Однако, даже если накрутка работает хорошо, есть ряд возможных проблем.
Классическое SEO направлено на то, чтобы повысить авторитет сайта, сделать лучше и удобнее для пользователя, подстроившись под требования поисковиков. Накрутка ПФ – это прямой обман поисковых систем. Соответственно, за такой обман сайт может получить фильтры и санкции, опустившись на дно выдачи. Хотя, на данный момент такая ситуация редкость.
С другой проблемой ко мне недавно обратился клиент. Он пользовался услугами накрутчиков, был чуть ли не в топ-1 по своей нише. Но в какой-то момент спец по накрутке просто перестал выходить на связь, накрутка остановилась, и сайт быстренько сполз на свои 20-30 места, вполне соответствующие уровню оптимизации сайта без накруток.
Поэтому, используя ПФ, стоит быть готовым, что в любой момент результат может превратиться в тыкву. При этом накрутка практически не имеет долгосрочного эффекта, и начав крутить ПФ, нужно регулярно отдавать за неё деньги.
Я однозначно против накрутки ПФ. И как пользователь, который не хочет видеть накрученные сайты на первых места, и как сеошник, к которому обращаются клиенты, уверенные, что «SEO за 3 дня» это норма, и крутящие пальцем у виска, когда я говорю про 3+ месяца.
Однако, в самых конкурентных нишах, в той или иной степени крутят почти все, кто есть в топе. И чтобы побороться за этот топ, приходится подключать ПФ. Но это делается в небольшом объёме, и только на уже хорошо оптимизированных сайтах, которым требуется дополнительный пинок. Использовать накрутку как основное и единственное средство продвижения точно не стоит.