
0 просмотренных постов скрыто



Про венгров и терема
Лучше того факта, что венгры заимствовали славянское слово "terem" как "зал", только тот факт, что они стали активно использовать его в разных сочетаниях, например, "koncertterem" ("концертный зал"), "bálterem" ("бальный зал"), "konditerem" ("спортзал"), - тут первая часть "kondi" происходит от слова "kondíció" ("состояние, кондиция").




Какие странные звонки и сообщения вам приходилось принимать - 1
1. Мне позвонила взрослая женщина и обвинила меня в многочисленных интрижках с её парнем, от которого у неё двое детей. Я заверила её, что это неправда, но она мне не поверила.
Она обозвала меня шлюхой и разлучницей. Мне тогда было тринадцать.
2. «Фрэнк, это мама. Ты будешь дома к ужину?»
Звонок пришёл с номера моей мамы. Только вот две проблемы: меня зовут не Фрэнк, и мама умерла много лет назад.
Видимо, тот, кто узнал старый номер мобильного телефона моей мамы, по ошибке вписал туда мой номер.
Меня это напугало.
3. Однажды мне пришло сообщение с просьбой быть готовой к 8:00, потому что «мама Салли ведёт нас в кино».
Я ответила «?», на что она ответила: «Ой, извините, ошиблась номером», на что я ответила: «Но мне нравятся фильмы». Она отключилась.
4. Мой друг, который работает в пиццерии, не сказав мне об этом, положил мой номер в коробку с пиццей со словами: «Напиши на этот номер, если хочешь хорошо провести время».
Всё прошло хорошо.
5. Мне позвонили поздно ночью как раз в годовщину смерти матери. Я ответил, но никто ничего не сказал. Я спросил: «Алло, кто там?»
Голос сказал: «Это твоя мать». И повесил трубку. Я решил перезвонить, и получил сообщение: «Набранный вами номер не обслуживается».
На самом деле это был голос моей матери.
6. В День благодарения позвонил маленький ребенок, я ответила, и он закричал: «Мама, это белая женщина!»
Другой ребенок хватает телефон и говорит: «Мэм, простите, пожалуйста, моего младшего брата, он думал, что он звонит нашей бабушке».
7. Раньше я постоянно получала ночные сообщения от мужчин… видимо, девушка, у которой был мой старый номер до меня, пользовалась популярностью.
«Я знаю, что прошло уже несколько лет, но что случилось!?»
«Привет, детка, помнишь меня?»
«Привет, меня зовут (имя), мы познакомились в (место) в прошлом году. Как дела?»
Буквально все время.
В конце концов, я сменила номер, и это прекратилось. Похоже, тот, у кого он был раньше, никому не нравился.
8. В канун Нового года, когда мне было около 10 лет, было уже за полночь, и я ответил на телефонный звонок, сказав: «С Новым годом!»
Парень на другом конце провода сказал то же самое, но с немецким акцентом. Я спросил, с кем он хочет поговорить, и он ответил, что с кем-то из США.
Мы пообщались около 30 минут, обменялись почтовыми адресами и стали друзьями по переписке на многие годы.
9. Какая-то женщина позвонила на домашний телефон и тут же начала кричать, чтобы я открыла заднюю дверь, ведь идёт дождь, у неё куча покупок, и она уже долго стучится. Я сказала ей, что она ошиблась номером.
Она обозвала меня маленькой сучкой и велела мне подбежать, открыть дверь и впустить её, иначе мне достанется. Я сказала «ладно», повесила трубку и вернулась к своим делам.
Интересно, что случилось с тем реальным человеком, которого она пыталась заставить открыть ей дверь.
Подборки, которые вы больше нигде не найдете, можете прочитать на моем канале https://t.me/realhistorys
Мой канал «Клубничный переполох» https://t.me/erosstoris
Мой канал с подборками интересных фактов https://t.me/actualfacts
Мой канал о кошках https://dzen.ru/o_koshkah
Мой канал с переводами рассказов зарубежных писателей https://boosty.to/webstrannik
Всем удачного дня!
Показать полностью


Почему я опоздал на работу1
Кому интересно, ссылка на такую игрушку

Головоломки для разума: Как оценить логику больших языковых моделей?
Автор: Денис Аветисян
Новый бенчмарк RiddleBench выявляет слабые места в способности ИИ к сложным рассуждениям и исправлению ошибок.
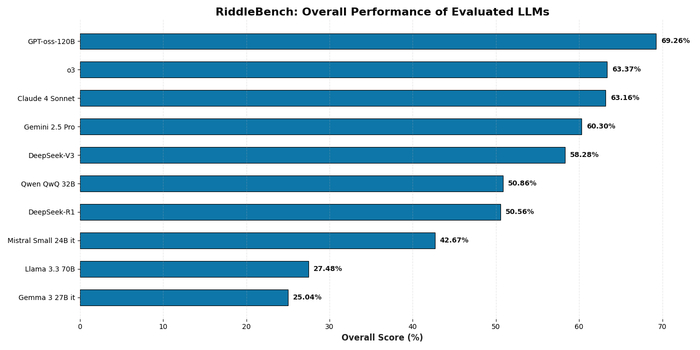
Оценка производительности различных языковых моделей на RiddleBench демонстрирует, что процент правильно решенных задач варьируется между моделями, что позволяет количественно оценить их способность к логическому мышлению и решению головоломок.
Исследователи представляют RiddleBench, критерий для оценки логического мышления, пространственного анализа и удовлетворения ограничений в больших языковых моделях.
Несмотря на успехи больших языковых моделей в решении структурированных задач, оценка их гибких и многоаспектных способностей к рассуждению остается сложной задачей. В данной работе представлена новая методика оценки – 'RiddleBench: A New Generative Reasoning Benchmark for LLMs' – включающая 1737 сложных головоломок, предназначенных для выявления слабых мест в логическом мышлении, пространственном воображении и соблюдении ограничений. Анализ показал, что даже передовые модели, такие как Gemini 2.5 Pro и Claude 4 Sonnet, демонстрируют точность чуть выше 60%, подвержены каскадам галлюцинаций и демонстрируют слабую самокоррекцию. Способны ли новые подходы к обучению языковых моделей преодолеть эти ограничения и приблизиться к человеческому уровню рассуждений?
Пределы Масштабирования: За Гранью Поверхностных Закономерностей
Большие языковые модели (LLM) демонстрируют впечатляющие возможности, однако часто испытывают трудности при решении задач, требующих глубокого логического мышления, а не просто сопоставления с образцом. Исследования показывают, что LLM допускают ошибки почти в трети случаев при решении головоломок RiddleBench, подчеркивая необходимость специализированных бенчмарков для оценки глубины рассуждений. Оценка LLM в задачах, требующих надежных рассуждений, имеет решающее значение для понимания их истинного потенциала.
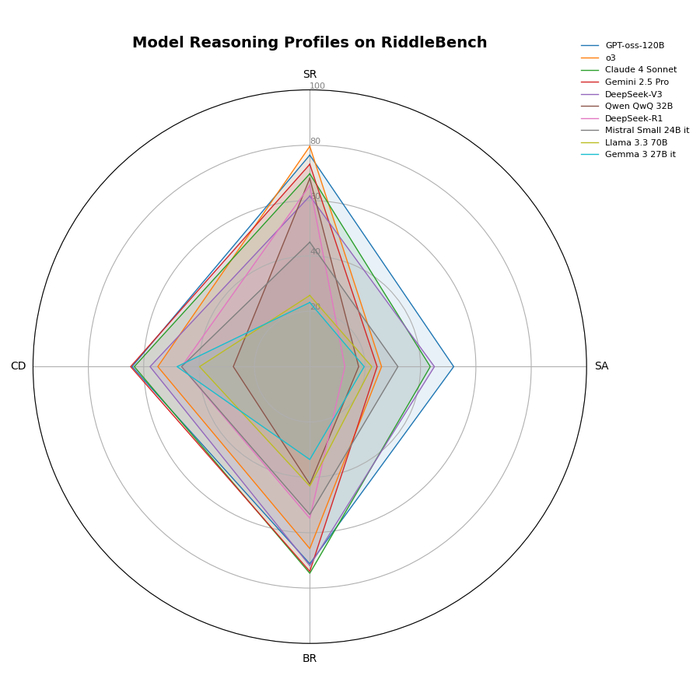
Оценка производительности различных больших языковых моделей (LLM) по четырем категориям логического мышления RiddleBench показывает, что каждая модель демонстрирует свои сильные и слабые стороны в задачах SR, SA, BR и CD.
Подобно тому, как безупречный алгоритм выявляет скрытые закономерности, так и глубокое мышление раскрывает истинную суть интеллекта.
RiddleBench: Новая Испытательная Платформа для LLM
RiddleBench — это набор данных из 1737 головоломок, разработанный для оценки сложных навыков рассуждения в LLM. Набор данных охватывает кодирование-декодирование, родственные связи, последовательное рассуждение и расстановку по местам, обеспечивая всестороннюю оценку. Оценка производительности моделей осуществляется посредством zero-shot подхода, позволяя оценить способность к обобщению знаний без предварительного обучения.
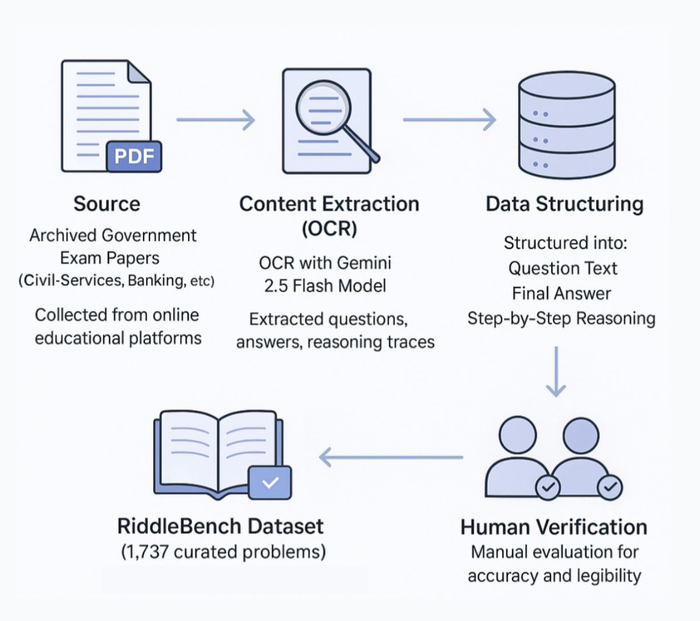
Разработанная методология создания RiddleBench сочетает в себе автоматизированное извлечение данных и тщательную ручную оценку, обеспечивая высокое качество полученных данных.
Для стандартизированной оценки производительности различных LLM был использован доступ к API через платформу DeepInfra. Общая стоимость API-запросов составила 314 долларов США.
Каскад Галлюцинаций: Когда Модели Усиливают Ошибки
Анализ показал эффект «каскада галлюцинаций», при котором LLM распространяют неверные рассуждения, приводя к цепочке ошибок. Это указывает на отсутствие внутренних механизмов критической оценки достоверности информации. Эксперименты с задачами на родственные связи продемонстрировали снижение производительности на 6.70 процентных пункта при перестановке ограничений, что свидетельствует о чувствительности к вариациям входных данных.
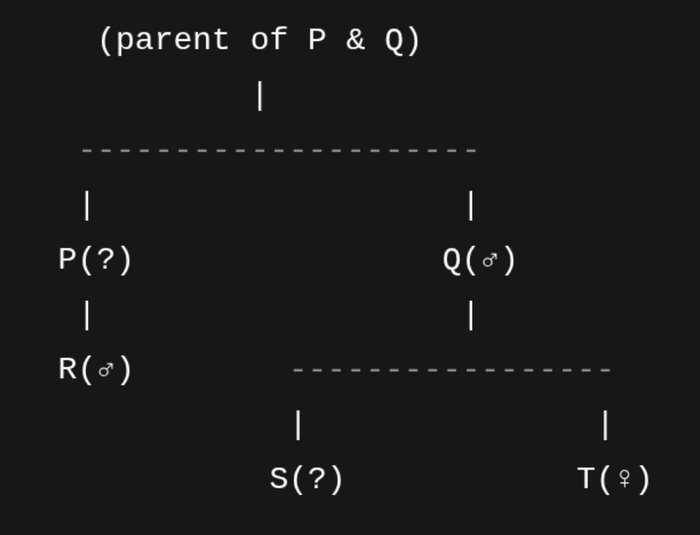
Модель Gemini сгенерировала ASCII-представление генеалогического древа для задачи на родственные связи, демонстрируя уникальную стратегию визуального рассуждения.
Полученные результаты подчеркивают важность разработки механизмов проверки и коррекции рассуждений в LLM, а не только увеличения их вычислительных ресурсов.
Постулаты Надежного Проектирования LLM
Результаты исследований подчеркивают важность разработки LLM с надежными внутренними способностями к рассуждению и механизмами самокоррекции. Простое увеличение размера модели недостаточно для обеспечения логической последовательности и обнаружения ошибок. Модель GPT-oss-120B достигла общей точности 69.26% на RiddleBench, демонстрируя текущие ограничения даже самых современных моделей.

Пример задачи на родственные связи из эталонного набора данных RiddleBench иллюстрирует сложность установления связей между членами семьи.
Модель Qwen QwQ 32B продемонстрировала точность обнаружения ошибок в рассуждениях 44.1% и частоту успешной самокоррекции 17.3%, что свидетельствует о потенциале, но и о трудностях обеспечения моделей способностью выявлять и исправлять собственные ошибки. Стремление к оптимизации без предварительного анализа — это самообман.
Исследование, представленное в статье, акцентирует внимание на выявлении слабых мест больших языковых моделей в задачах, требующих последовательного логического вывода и исправления ошибок. Это особенно заметно в контексте пространственного мышления и удовлетворения ограничений, где даже небольшая неточность на одном этапе может привести к каскаду галлюцинаций. Как однажды заметил Клод Шеннон: «Теория коммуникации должна учитывать не только передачу информации, но и ее надежность». Данное наблюдение напрямую соотносится с сутью RiddleBench, поскольку надежность вывода является критически важным аспектом оценки способности модели к рассуждениям. Бенчмарк RiddleBench, по сути, проверяет, насколько «надежно» модель передает логическую информацию от начала до конца решения задачи.
Что дальше?
Представленный бенчмарк RiddleBench, безусловно, обнажил уязвимости в логических цепочках больших языковых моделей. Однако, констатация слабости – лишь первый шаг. Истинная сложность заключается не в создании всё более изощренных тестов, а в разработке принципиально новых архитектур, способных к доказуемо корректному выводу. Наблюдаемые "каскады галлюцинаций" – не баг, а закономерное следствие статистической природы существующих моделей. Они предсказуемо спотыкаются там, где требуется не просто распознавание паттернов, а построение непротиворечивой логической структуры.
Особое внимание следует уделить задачам, требующим пространственного мышления и удовлетворения ограничений. Недостаточно просто "угадать" правильный ответ; модель должна уметь верифицировать его, исключая противоречия. Это требует интеграции методов формальной логики и теории доказательств непосредственно в структуру нейронной сети. Иначе, мы обречены на бесконечную гонку вооружений, где каждый новый тест лишь временно маскирует фундаментальные недостатки.
В хаосе данных спасает только математическая дисциплина. Недостаточно строить модели, которые "хорошо работают на тестах"; необходимо стремиться к созданию моделей, которые работают правильно по определению. Будущее развития больших языковых моделей видится не в увеличении количества параметров, а в повышении строгости и формальной обоснованности их работы.
Оригинал статьи: denisavetisyan.com
Связаться с автором: linkedin.com/in/avetisyan
Показать полностью
4

Пойду поною. Или МЛЯ, хотя наверняка мъдак
Сегодня на меня обиделась жена. Потому, что я сказал, что не готов бежать рыдать вместе с "сыном" и ему чем-то срочно помогать. Что сделал сын? Написал сообщение - "Мама покончила с собой в тюрьме".
И вот я не понимаю, а что должен сделать я? Расскажите? Сыну 20 лет, за все эти 20 лет он ни разу не назвал меня папой. Никогда не поинтересовался как у меня дела. Иногда, когда его пинали родственники поздравлял меня с праздниками. При этом - нормально принимал подарки и всегда ждал алименты.
Бывшая жена бросила меня когда ему было 2 года, переехала в Питер и занялась проституцией, наверное так интереснее, я хз что об этом думать. Потом занималась тем, что пыталась сожительствовать со странными типами, то у нее бывший зек, оформляющий на нее кредит, то какой-то безумный художник-наркоман, которого она всем селом хоронила после передоза. То пыталась наркотики в пизде возить. Я это должен поддерживать?
Ну может быть "сын" и не виноват. Его убедили, что так и должно быть. Бабушка должна давать деньги, "папа" должен платить, а в остальном на них плевать. Отлично. Скажите мне одно - а что я вот этому должен?
Комиссарский ИРП Warhammer 40K от BROADAXE
Рекомендую подписаться, очень интересный контент)
