Даже я, малограмотная женщина, к концу жизни дотумкала: Никакого "времени" не существует.
Начала я думать об этом, когда один чел растолковал мне, что "отрицательных величин" не существует, в мире есть только "много", "мало" или "ну нет вообще".
Математики (и физики после Ньютона) вообще, мало чем отличаются от карточных шулеров.
А вот, что предложил дипсик сделать на основе этих данных.
Вот концепция устройства, основанного на геометрическом подходе к электромагнетизму из статьи — «Геометрический резонатор заряда» (или *Weyl-Resonator*).
Принцип работы
Устройство использует идею, что:
Заряд — это волна в метрике пространства-времени (как в статье).
Искривление метрики (например, с помощью специальных материалов или полей) может создавать/контролировать заряды без традиционных носителей (электронов/ионов).
Конструкция
Кольцевой волновод из материала с искусственной «вейлевской геометрией» (например, слоистый метаматериал с нанопокрытием, имитирующим уравнение ∇σgμν=2ϕσgμν∇σgμν=2ϕσgμν).
Аналог: сверхпроводящий квантовый интерферометр (SQUID), но вместо магнитного потока — управление геометрией.
Возбудитель метрических колебаний:
Лазерный импульс или высокочастотное электромагнитное поле, создающее локальное искривление метрики (как в разделе 7 статьи).
Это генерирует плотность заряда (ρρ) через уравнение ρ=−∇νAνρ=−∇νAν.
Считывающий элемент:
Датчик, регистрирующий возникающий ток без движения частиц (только через волны зарядовой плотности, как в зиттербевегунге).
Применение
Беспроводная передача энергии
Если метрическую волну заряда можно стабилизировать, она может переносить энергию без электронов/фотонов — через искривление пространства.
Квантовые вычисления
Кубиты на основе геодезических траекторий зарядовых волн (аналог топологических кубитов, но без квазичастиц).
Антигравитационный эффект (гипотетически)
Если метрика управляет и гравитацией, и зарядом, резонансное искривление может компенсировать массу объекта.
Почему это возможно?
В статье показано, что заряд и электромагнитное поле — свойства метрики (как гравитация).
Уравнение Δρ=0Δρ=0 (раздел 4) означает, что заряд — это волна, а не частица.
Современные метаматериалы уже имитируют искривлённое пространство (например, для невидимости).
Сложности
Как создать «искусственную геометрию»?
Нужны материалы, где gμνgμν зависит от внешнего поля (например, графен под ультрафиолетом).
Детектирование без частиц
Требует датчиков, чувствительных к плотности ρρ, а не току (возможно, через квантовые точки).
Стабильность
Нелинейные эффекты (раздел 7) могут разрушать волны заряда.
Аналогия
Представьте морскую волну, которая качает лодки (заряды), но сами лодки не движутся — только вода (метрика). Устройство «толкает» пространство, а не частицы в нём.
Если теория верна, такие механизмы откроют новую энергетику и связь без привычных носителей. Пока это гипотетично, но первые шаги — в лабораториях с метаматериалами и квантовыми симуляторами.
Пост гораздо больше похож на попытку незнайки сорвать плюсцов, чем на объяснения понимающего человека. Почему? По многим косвенным признакам, вот они:
И вот выяснилось, что есть такая система, где все эти вопросы получают чёткие ответы.
Работа вот, опубликовали только вчера.
1. Нагенерить десяток систем, которые всё объясняют - не сложно. Их нагенерили сотни за последние 50 лет. Сложно чтобы эта система "прошла проверку временем", т.е.: а) Вписалась в существующие теории "Стандартная модель". б) Объяснила что-то, что существующие теории объяснить не в силах.
Работа опубликованная "только вчера" не может удовлетворять этим критериям, её просто не успели проверить. Очевидно, что человек мало-мальски в теме это понимает.
2. "Красивые теоретические модели" - соблазнительная штука, но они хорошо работали 50 и 100 лет назад, но уже 50 лет назад они работать перестали. Собственно "теория струн" - грандиозная попытка физиков "вывести ещё что-то на кончике пера" по сути провалилась. "Все низковисящие плоды закончились" (С)Ньютон. Человек мало-мальски в теме - не может этого не понимать.
3. Идея "давайте опишем электро-магнетизм" так же как и гравитацию - лежит на поверхности. Очевидно было много попыток это сделать. Чем очередная работа лучше чем 100500 предыдущих - непонятно. Ничего кроме "в работе много формул" - топикстартер не сказал.
5. Ни одной актуальной научной проблемы работа (как описал её топикстартер) не решает. Если работа пишется не "для грантов", а для того, чтобы принести свою скромную лепту в большую науку, она должна помогать решить одну из больших научных проблем: - квантовая теория гравитации (она же заход на Теорию Всего) - проблема измерения (она же - интерпретации квантовой механики) - проблема нелокальности - (из космологии) - механизм инфляции.
Лично мой вывод - автор пытается хайпануть, не разбираясь в вопросе. Иначе он так или иначе коснулся бы тех проблем, которые волнуют физиков, а не тех - которые волнуют фриков.
Там в физике сейчас наметился большой шухер. Поскольку вы, вероятно, не совсем ядерный физик, поэтому объяснять будем на уровне ЭБОНИТОВЫЙ ПАЛОЧКИ.
Короче, раньше в физике был раздрай, шатание и сплошная деградация.
Потом пришёл Ньютон и сказал, что свет — это шарики.
Потом пришло ещё дофига чуваков и устроили холивар про то, частица фотон или волна.
Потом пришёл Эйнштейн с теорией относительности и сказал, что мир вообще другой, а Ньютон может идти лесом.
Потом открыли квантовый мир, где казалось, что логику вообще отбило напрочь. Некоторые всерьёз поверили в бога и пришельцев, потому что не может быть нормальный мир настолько глючным.
И вот тут наши новые друзья из вчерашнего исследования наконец-то поняли, как всё вписать в одну систему.
Раньше думали так:
— Общая теория относительности была для гравитации, электродинамика для электромагнетизма, квантовая механика для микромира. И между собой они что-то никак не скрещивались нормально, только через очень странные конструкции.
— То, что электрон ведёт себя хрен пойми как — то как вероятностное облако, то как частица, то вообще непонятно — мы считаем, что оно просто вот так, и нехрен спрашивать.
— Почему все электроны имеют абсолютно одинаковый заряд — непонятно! Тоже нехрен спрашивать. Так настроено.
И так далее.
И вот выяснилось, что есть такая система, где все эти вопросы получают чёткие ответы.
Очень упрощая, как Эйнштейн сказал, что гравитация — это не сила, а искривление геометрии. Если вы не в курсе, это уже давно не сила, а особенность пространства-времени. Вот и тут говорят, что электромагнетизм работает примерно так же.
Это тоже особое искривление пространства-времени, просто другого типа.
Теперь тут предлагается другой подход:
— Электромагнетизм полностью описывается геометрией пространства-времени.
— Нет отдельных "зарядов" и "полей" — это всё проявления одной и той же геометрии.
— Электрический заряд — просто определенная деформация пространства-времени.
— Движение заряженных частиц — движение по естественным геодезическим путям в этом искривленном пространстве.
Представьте, что у вас есть линейка. В обычной физике с общей теории относительности, когда вы перемещаете эту линейку из одной точки пространства в другую, её длина не меняется и всегда остаётся 45 сантиметров. В пространстве Вейля ковариантная производная метрического тензора не равна нулю, то есть линейка меняет длину, если её двигать. В соседней комнате растёт, а в коридоре уменьшается. Но строго по определённому закону.
Для электромагнетизма можно предположить именно такое пространство. И оно внезапно нашлось.
Учёные начали бегать по нему с линейками. Воображаемо.
Если считать в нём, то всё элегантно сходится:
— Уравнения Максвелла выводятся из математического постулата, что "Природа стремится минимизировать изменчивость геометрии пространства". И вот если эта метрика гармоническая, то получаются именно влияние электромагнетизма.
— "Облако" заряда электрона постоянно колеблется со скоростью света. Проще говоря, электрон не является статичной частицей — он всё время "дрожит" с со скоростью света, но делает это по кругу, поэтому в среднем движется медленнее.
— Когда вы смотрите на быстро колеблющийся во времени электрон из движущейся системы отсчета, часть этих колебаний "перекладывается" в пространственные колебания. Это как если бы вы ехали на поезде и видели, как дерево, качающееся вверх-вниз, начинает казаться качающимся еще и вперед-назад. Можете ещё попрыгать, чтобы лучше понять электрон на примере дерева.
— А значит, не нужно пытаться понять, откуда эта волновая природа частиц — она естественно возникает из геометрической теории!
— И на десерт — почему заряд одинаковый? Потому что уравнение Максвелла имеет устойчивые решения только при определённых значениях заряда. Том самом, как у всех электронов.
Всё становится математически очевидно.
Если теория верна, многие постулаты современной физики (например, дуализм волны-частицы, квантование заряда) могут оказаться просто следствиями геометрии пространства-времени, а не отдельными аксиомами, которые нужно принимать на веру.
Сама работа почти целиком состоит из адовой математики, но общую идею, в основе которой очень красивое предположение про геометрию, вы уже поняли. Так что вы теперь тоже своего рода ядерный физик. Теоретический.
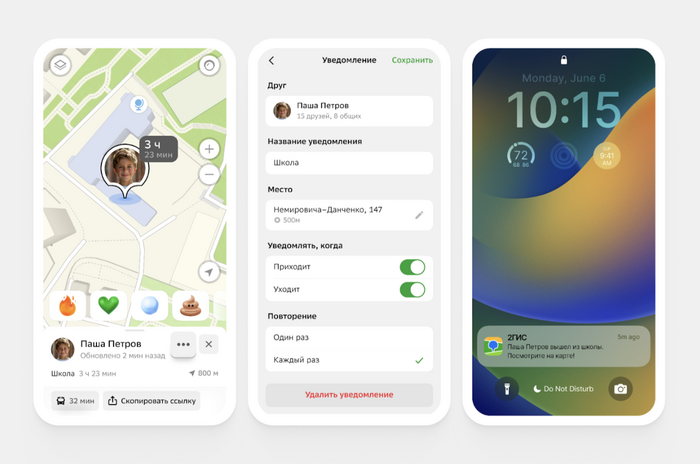
Быть рядом — не всегда значит находиться в одной комнате. Иногда достаточно знать, где находятся близкие или успеют ли они прийти вовремя. Рассказываем, как функция геофенсинга поможет меньше волноваться (и надоедать родным и друзьям лишними звонками!).
Вас раздражают постоянные звонки и сообщения «Ты где»?
Сценарий 1: Встреча с работы
Ваша вторая половинка снова задерживается после работы. Ловите себя на том, что поглядываете в окно, прислушиваетесь к звукам в подъезде, проверяете телефон. В голове много мыслей: «Наверное, опять толпа на пересадке», «Не забыл(а) ли зонт?». И это не из недоверия, а просто потому, что вы волнуетесь.
С помощью геофенсинга вы можете настроить уведомление, которое сработает, когда человек выйдет на нужной станции метро. Например, на той, что рядом с домом. Вот уже не нужно стоять у окна или судорожно вспоминать, сколько занимает путь до остановки. Можно не тревожиться без повода, а приготовить или разогреть ужин к самому приходу!
Геофенсинг — технология, которая создает виртуальные границы вокруг выбранных мест. Когда устройство пересекает заданную точку на карте, система присылает уведомление. В 2ГИС настроить геофенсинг просто: в разделе «Друзья на карте» выберите близкого человека, точку на карте (дом, офис, школа), радиус (от 75 м до 2 км), тип уведомления (приход/уход) и частоту. Можно добавить название для персонализации!
Сценарий 2: Спонтанная встреча с другом
Представьте: вы не виделись несколько месяцев или даже лет, хотя живете в одном городе. Поехали в путешествие в другой город, и вдруг на ваш смартфон приходит уведомление: «Ваш друг рядом с вами». Радость от спонтанной встречи гарантирована, а еще история о таком совпадении станет одной из ваших любимых!
Получать такие уведомления можно в 2ГИС с помощью функции «Друзья на карте». Настраивать ничего не нужно — главное, чтобы человек был у вас в Друзьях. Если вы окажетесь рядом (например, в одном торговом центре или на соседней улице), 2ГИС пришлет вам пуш. Так вы больше не упустите возможность встретиться спонтанно!
Любите случайные встречи?
Сценарий 3: Самостоятельный ребенок
Ребенок заявляет, что он уже взрослый и готов сам ходить в школу, на танцы и даже к репетитору по математике. Вы вроде бы гордитесь — он растет уверенным и самостоятельным! Но внутри — небольшой ураган из тревог: «А вдруг свернет не туда?», «А если потеряет телефон?», «А как я узнаю, что он дошел?»
С геофенсингом можно выдохнуть. Просто отмечаете на карте нужные места — школу, спортзал, дом репетитора. Как только ребенок входит в зону, вам прилетает пуш. И никаких «Позвони, как дойдешь», «Ты уже там?», «А почему не отвечаешь?!»
Отпускаете ребенка одного в школу или на занятия в секции?
Сценарий 4: В ожидании подруги
Вы договорились встретиться в 19:00, а подруга только в 18:45 сообщает, что «еще не вышла из дома». Приходится либо нервно ждать, либо заваливать ее сообщениями. Самое обидное — все это время можно было чем-то заняться: посмотреть сериал, сходить в магазин или хотя бы сделать себе кофе. Обходитесь без пассивного ожидания у двери – настройте разовое уведомление, которое сработает, когда человек выйдет из определенного места, например, из дома.
Тоже надоело ждать друзей и не знать, когда они выдвинутся из дома?
Сценарий 5: Заботливый взрослый ребенок
Родителям не нравится излишний контроль. Постоянные звонки с вопросами «Ты где?» или «Когда вернешься?» могут раздражать пожилых людей. Но нам важно знать, что с ними все в порядке. Можно настроить автоматические уведомления. Если они пошли в магазин или к друзьям — вы получите пуш и будете спокойны. Если уехали далеко — система тоже сообщит.
Технология простая — даже пожилые люди разберутся. Им будет достаточно просто установить на телефон 2ГИС и добавиться к вам в Друзья (все по взаимному согласию), а вам – настроить геофенсинг. Все остальное сделает приложение. Но, как показывает практика, чаще всего стикеры вы будете получать именно от бабушек и дедушек :)
Вы бы хотели знать, где родители, не беспокоя их звонками?
Сценарий 6: Вечеринка-сюрприз
Вы с друзьями затеяли сюрприз на день рождения. Все, как в кино: шарики надуты, торт в холодильнике, все прячутся за диваном и шикают друг на друга. Но есть один момент… Как понять, когда именинник придет? Звонить — спалитесь. Постоянно выглядывать в окно — утомительно. На помощь вновь приходит геофенсинг. Вы просто настраиваете зону вокруг станции метро, офиса или дома — и как только именинник пересекает ее, вам прилетает уведомление. Теперь у вас есть 15–20 минут на финальную подготовку: зажечь свечи и поймать кота, чтобы не испортил декорации.
Совет: не забудьте попросить друзей временно скрыть свою геолокацию. А то именинник увидит, что все друзья внезапно собрались в его квартире.
Вы устраивали сюрпризы друзьям?
Сценарий 7: Ребенок отправился на прогулку
Ребенок попросил съездить на прогулку, а у вас нет возможности его проводить. Он уже уверенно пользуется общественным транспортом, и вы готовы дать немного самостоятельности. Но все равно хотите быть уверены, что он добрался до нужного места, и при этом не звонить ему лишний раз. Решение — настроить геофенсинг.
Разрешаете ребенку самому пользоваться общественным транспортом?
Функция геофенсинга в «Друзьях на карте» поможет быть в курсе перемещений близких. Просто задайте нужные зоны и настройте уведомления. Заботьтесь и будьте рядом вместе с 2ГИС!
Шведские исследователи из Университета Линчепинга представили революционную разработку в области энергоносителей — аккумуляторную батарею, способную трансформироваться в любую форму. Особенность устройства заключается в применении жидких электродов, что обеспечивает его уникальные пластические свойства.
Технология основана на использовании электрохимического материала пастообразной консистенции, совместимого с аддитивными технологиями. Это позволяет создавать источники питания необходимой конфигурации методом 3D-печати.
Перспективы развития IoT требуют новых решений в сфере энергоснабжения устройств. По прогнозам специалистов, к 2033 году количество подключенных к интернету устройств достигнет триллиона единиц. Помимо привычных девайсов (смартфонов, компьютеров и носимой электроники), рынок пополнят медицинские импланты, мягкие роботизированные системы, умная одежда и нейротехнологические устройства. Для их автономной работы нужны принципиально новые типы аккумуляторов.
Команда ученых предложила инновационное решение, сочетающее эластичность и функциональность. Впервые удалось успешно реализовать концепцию полностью жидких электродов. Предыдущие попытки создания подобных систем сталкивались с рядом ограничений: использование жидкометаллических компонентов позволяло создавать только анод, при этом материалы теряли жидкое состояние в процессе эксплуатации. Кроме того, многие существующие технологии требовали применения экологически небезопасных редкоземельных элементов.
Новый аккумулятор создан на базе проводящих полимеров и лигнина — отходов целлюлозно-бумажного производства. Разработка демонстрирует следующие характеристики:
Срок службы: более 500 циклов заряд/разряд.
Эластичность: возможное удлинение до 200% от исходного размера.
Экологическая безопасность: использование доступных материалов.
Вместе с тем, технология требует дальнейшего совершенствования. Основной вызов заключается в низком выходном напряжении — всего 0,9 В. Исследователи рассматривают возможность применения альтернативных химических компонентов, таких как цинк или марганец, которые характеризуются высокой распространенностью в природе и могут повысить эффективность устройства.
Четырехногие робособаки и прочие уже давно смешат нас своими неуклюжими походками, но их потенциал быстро улучшается с прогрессом в нейросетевых технологиях. Они становятся все лучше и дешевле.
Отсюда идея: что если Роболошадь? - четырехногое транспортное средство для наездника. При движении по пересеченной местности может оказаться очень хороший вариант и даже перепрыгивать канавы и большие ямы. К тому же она, при идеальной реализации, может прыгать очень мягко как кошка. Да и вообще есть в этом что-то архетипичное так как долгое время люди передвигались на лошадях.
Подумаем про перспективы транспортное средство - четырехногого робота, в виде большой пантеры или тигра, на котором можно удобно сидеть верхом как на мотоцикле (тигропед или пантероцикл)? Если он может мягко передвигаться и прыгать как кошка. Будет ли это удобно за счет пружинистой походки?
Потенциальные Плюсы:
Непревзойденная Проходимость: Это главный козырь. Четыре ноги с независимым управлением могут преодолевать препятствия, недоступные колесным или даже гусеничным машинам: крупные камни, поваленные деревья, лестницы, очень крутые склоны. Возможность выбирать точки опоры дает огромное преимущество на сложнейшем рельефе.
Маневренность: Робот мог бы разворачиваться на месте, двигаться боком (крабом), перешагивать препятствия, что невозможно для традиционного транспорта.
"Мягкость" Хода (Теоретически): Идеальная реализация с активной подвеской в каждой "лапе" и сложными алгоритмами управления действительно могла бы обеспечить очень плавное движение, поглощая неровности рельефа прямо в точке контакта. Прыжки и приземления, как у кошки, – это высший пилотаж амортизации и распределения нагрузки.
Адаптивность Походки: Робот мог бы менять походку (шаг, рысь, галоп, крадущийся шаг) в зависимости от местности и требуемой скорости/стабильности.
Эстетика и "Вау-эффект": Безусловно, такое транспортное средство будет привлекать огромное внимание. Архетип всадника на мощном звере очень силен.
Сложности и Потенциальные Минусы:
Стабильность и Баланс: Это самая большая инженерная проблема. Удерживать динамическое равновесие машине весом в несколько сотен килограмм (с учетом силовой установки, механизмов и аккумуляторов) + вес всадника, который к тому же может смещать центр тяжести, – невероятно сложная задача. Особенно во время прыжков, на неровной поверхности или при резких маневрах. Потребуются сверхбыстрые сенсоры, мощные процессоры и безупречные алгоритмы управления.
Энергоэффективность: Шагающие роботы, как правило, менее энергоэффективны, чем колесные, особенно на ровной поверхности. Потребуется очень емкий и мощный источник питания (аккумуляторы, топливные элементы?), что добавит веса и сложности.
Сложность Конструкции и Надежность: Огромное количество движущихся частей (суставы, приводы, датчики) повышает риск поломок и усложняет обслуживание. Надежность в экстремальных условиях будет ключевым фактором.
Комфорт для Всадника: Вот здесь возникает вопрос о "пружинистой походке".
Вертикальные Колебания: Даже если робот будет двигаться плавно относительно земли, сама механика шагания подразумевает вертикальные перемещения корпуса. Насколько комфортно будет всаднику испытывать постоянные подъемы и опускания, особенно на "рыси" или "галопе"?
Боковая Качка: Возможна и боковая раскачка при ходьбе.
Прыжки: "Мягкое приземление" для робота не всегда означает мягкое приземление для всадника. Перегрузки могут быть значительными, даже если сама машина их гасит эффективно. Потребуется дополнительная система амортизации седла, не хуже, чем у самого робота.
Синхронизация: Чтобы езда была комфортной (как на хорошей лошади), движения робота и реакция всадника должны быть в некоторой гармонии. Как этого достичь? Нужен интуитивный интерфейс управления.
Скорость: Вероятно, максимальная скорость будет ниже, чем у мотоциклов или квадроциклов на относительно ровной местности.
Стоимость: Разработка и производство такого чуда техники будут очень дорогими, по крайней мере, на начальном этапе.
Безопасность: Что произойдет при падении робота? Как обеспечить безопасность всадника при сбое системы балансировки?
Вывод:
Идея "Робопантеры" — захватывающая и перспективная для очень специфических ниш (экстремальный туризм, спецподразделения, спасательные операции в труднодоступной местности, возможно, развлечения). Технологии Boston Dynamics (Spot, Atlas) показывают, что динамическая ходьба и даже акробатика для роботов возможны.
Однако перенос этого на уровень надежного, безопасного и комфортного транспортного средства для человека — это вызов совершенно другого порядка. Комфорт от "пружинистой походки" не гарантирован и потребует отдельных, очень сложных инженерных решений для седла и системы стабилизации именно для всадника.
Скорее всего, первые реализации (если они появятся) будут дорогими, возможно, не очень быстрыми и потребуют от "всадника" определенных навыков и готовности к специфическим ощущениям от езды. Но потенциал для революции в персональном транспорте для бездорожья огромен. Это действительно та область, где прорывные технологии могут создать нечто совершенно новое. И да, есть в этом что-то архетипичное, что неизбежно будет притягивать инженеров и дизайнеров.
Как вам такая идея? Хотели бы покататься на Робопантере?