Что такое наземное лазерное сканирование, и как с ним бороться?
Пост будет длинным, и откроет собой серию постов о практическом применении технологии наземного лазерного сканирования. Для основы буду брать исключительно те проекты, которые делал сам. Никаких идеальных примеров из методичек производителей. Для затравки, сразу фото современного Наземного Лазерного Сканера.


Красавец на фото - прибор Leica RTC360, мося на первом плане моя.
В одной из тем, в комментариях, попросили подробнее рассказать о довольно, на мой взгляд, интересной измерительной технологии. Технология называется Наземное Лазерное Сканирование (далее - НЛС). На основе того же лазерного сканирования существуют еще МЛС (Мобильное Лазерное Сканирование, а в МЛС есть ВЛС - Воздушное Лазерное Сканирование) и Ручное Лазерное Сканирование. Но об этих технологиях, если будет желание, в следующих постах. Сегодня расскажу конкретно про НЛС.
Технология не самая новая, но бурно развивающаяся. Изначально пришла в геодезию, но сейчас используется во многих смежных областях - строительство, обследование, деформационный мониторинг, реставрация и сохранение памятников исторического наследия, археология, дизайн, маркшейдерия (если рассматривать данную дисциплину отдельно от геодезии), создание цифровых 3D-туров. Возможно, что-то еще упустил.
Небольшой дисклейм. Уже предвижу, как набегут в тему "знатоки", которые с радостью объяснят, что данная технология зло, фигня и как они с ней обожглись. А еще наверняка будут тошнотики, которые вставят свои 5 коп., про мои неточности в описании физики процесса и т.п. Поэтому сразу расскажу вкратце о себе и как я столкнулся с НЛС. Я геодезист и большую часть времени проработал техническим специалистом в одном из филиалов российского представительства концерна Hexagon group (широко известный в узких кругах в первую очередь брендом Leica Geosystems). Сейчас данный концерн ушел из России, а клоуны остались. То есть моя специальность разобраться в приборе на столько, чтобы можно было учить на нем работать других. А также разбираться в разных тонкостях, аксессуарах, настройках, багах, мелком ремонте. Начинал свою карьеру в 2008г. с классической уже связки тахеометр - спутниковое оборудование, ну и всякая мелочевка, типа нивелиров и т.п. За свою продолжительную карьеру успел даже преподавать геодезию в одном из ВУЗов. НЛС-ом наш филиал заинтересовался практически сразу, как данная технология появилась в России, это год 2010г. кажется был (имеется в виду именно коммерческие продажи, а то найдется тип, который будет кричать, как в их институте сканер был уже в году 2008). Итого с НЛС я работаю уже лет 15. В первую очередь, НЛС появился для нужд строительной и промышленной геодезии, а вскоре и для маркшейдерии.
Объяснить принцип работы с НЛС наверно проще через тахеометр. Тахеометр - это тема, заслуживающая отдельного поста. Но объясню вкратце. Тахеометр это прибор, совмещающий в себе теодолит, лазерный дальномер и компьютер для обработки полученных данных. В историю тахеометров углубляться не буду. Вы наверняка могли встречать такие штуки на улицах, в них всегда на что-то смотрят серьезные небритые дядьки (это и есть геодезисты), а рядом бегают другие такие же небритые дядьки с палкой. Вот так выглядят современные тахеометры.



Первое фото мое - тахеометр Leica MS60, две другие взял из интернета, там Trimble и Sokkia, тоже очень популярные бренды.
Очень кратко о принципе работы тахеометра. Он ставится на точку с известными координатами (необязательно, но пока опустим), ориентируется на другую точку с известными координатами, компьютер внутри понимает, где находится прибор в координатной сетке X,Y, Z (для душнил, Z можно заменить h - высотой). Далее прибор наводится на интересующую геодезиста точку (если она на земле, в траве, как раз используется палка - вешка) и делается замер. Прибор испускает фазовый (или импульсный. тоже углубляться отдельно не стоит) сигнал, тот отражается от препятствия, возвращается в прибор и вычисляется расстояние до данной точки. А так как тахеометр получил часть ген своего предка теодолита в виде горизонтального (лимб) и вертикального (алидада) кругов, то может высчитать положение своей зрительной трубы относительно ориентирования, а следовательно, высчитывает и направление, куда был направлен данный луч. Итого, прибор вычисляет положение данной точки в той же координатной сети, что и прибор - то есть ее положение, относительно осей X, Y, Z. Вот так все просто.
При помощи данного прибора геодезисты выполняют всего два набора задач. Они так и называются - прямая геодезическая задача и обратная геодезическая задача. В первом случае мы видим точку и хотим узнать ее координаты, во втором наоборот - мы знаем координаты и хотим найти точку, соответствующую данным координатам, на местности. Все остальные задачи геодезии вырастают из различных комбинаций этих двух.
Вот теперь наконец перейдем к лазерному сканированию, как его понимает геодезия (просто по запросу "лазерное сканирование" в гугле, вы скорее всего попадете на услуги по изготовлению зубных имплантов (да, там таже технология). Умные ученые придумали, а инженеры воплотили в жизнь, что вращение по вертикальному и горизонтальному кругам необязательно выполнять в ручную. Можно заставить прибор автоматом раскрутить головку, испускающую луч дальномера и придать ей постоянную высокую скорость. Направление головки, испускающей луч можно вычислить, зная скорость ее вращения, точку начала вращения и нужную временную точку. Так почему же не создать такой прибор, который будет просто вращаться по кругам и измерять с максимальной скоростью, получая все точки препятствий, что его окружают?
Первый наземный лазерный сканер изготовила компания Cyrex (это как меня учили гуру из Leica Geosystems. Возможно, могу ошибаться, но другой информации не встречал), которую очень быстро перекупил концерн Leica Geosystems, и стал изготавливать уже свои приборы. Первый прибор, который попал к нам в руки был Leica ScanStation (он же HDS3000). Вот его основные характеристики, попытайтесь запомнить, дальше я выложу характеристики современных сканеров. Почувствуете разницу, как за ~20 лет продвинулась технология. Скорость измерений 4000 точек в секунду. Вес 16кг + 2 внешних аккумулятора по 8кг каждый + ноутбук для управления. Дальность 170 метров, точность одной точки 4мм (В точность в этом посте углубляться не буду. Просто запомните, что довольно точно для большинства задач).

Leica ScanStation. По габаритам он был размером с пивную кегу. И весил 16кг. Его постоянно нужно было поднимать на штатив и опускать с него.
И этот прибор был "бомба". Без преувеличений. Когда мы демонстрировали результат его работ тертым геодезистам, снимающим промышленные заводы, они были в восторге. На выходе получалась не кучка координированных точек в пространстве, как в случае с тахеометрами, а "облако точек" (термин мигом вошел в обиход и сейчас результат лазерного сканирования официально именуется - облако точек). Для примера, как работает классический геодезист с тахеометром? Наводит зрительную трубу на нужную точку, жмет точку измерить, прибор делает измерение (примерно секунд занимает), наводится на следующую и т.д. сколько можно отснять точек за час? При съемке фасада, то есть не нужно переставлять прибор, не нужно гонять человека с вешкой - наводись и снимай, у меня выходило максимум 150 точек. И после этого у меня болели глаза, спина и тряслись руки. Сканер делал 4000 измерений в секунду! Конечно, максимальной скорости достигнуть можно было лишь в идеальных условиях, на практике получалось за 10 минут съемки облако из 1 000 000 точек. Сканеру нужно было только задать нужные границы съемки (сразу скажу, это занимало значительную часть времени), указать через какой шаг нужно записывать точки и нажать точку старт.
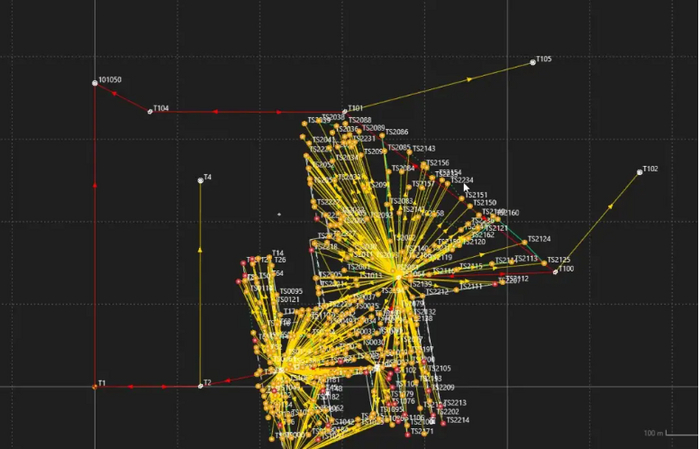


Для примера. Первое фото, так выглядит обычная тахеометрическая съемка. На второй облако точек, полученное с лазерного сканера. На третьем совмещенно в одном проекте съемка тахеометра и облако точек.
Все упиралось в стоимость прибора. Она была такая же космическая, как и полученный результат. Позволить себе такое оборудование могли лишь самые богатые предприятия. А потратить такие огромные деньги на новую, еще толком не обкатанную, технологию и вовсе решались единицы. Для примера, стоил прибор, на сколько я помню, столько же, сколько два Лэнд Крузера 200 в полном фарше.
Отпугивал потенциальных клиентов еще и сам результат сканирования. Красиво, в 3Д можно повращать, любые расстояние измерить за секунду прямо в компьютере. А что дальше с этим делать? На то время уже существовали программы для трехмерного проектирования, но с облаками точек они начнут работать ой, как не скоро. Было ПО от самой Leica Geosystems, позволявшее по облакам выстроить твердотельные трехмерные модели и после перевести их в любой CAD продукт. Но все справедливо опасались, а что если не зайдет? Опыта тогда практически ни у кого не было, а становиться первопроходцами и собирать на себя все шишки, чтобы своим конкурентам проторить дорогу никто не спешил.
Лично нам помог случай. Проходила реконструкция одного из крупных заводов, на который мы ездили с демонстрацией этого сканера. И во время реконструкции была задача разобрать один аппарат (величиной с пятиэтажный дом), снять все размеры коммуникаций, заказать по этим размерам другой аппарат на это место и смонтировать его. Делали классическими тахеометрами. Все разобрали, размеры отправили на завод в 300км от места установки. Там эту штуку собрали и потащили на двух КРАЗах обратно. Тащили медленно, по ночам, даже пришлось местами провода поднимать, чтобы пролезло. Привезли, а эта штука не лезет! Забыли отснять одну трубу, а труба важная. Чтобы перенести эту трубу нужно ползавода разобрать. Что делать? Повезли эту штуку обратно на завод изготовления и там переделывали и везли обратно... чувствуете затраты? Сколько ланд крузеров можно было купить на эти деньги? Приобрети они сканер, он бы уже дважды окупился. Фишка сканера в том, что он снимает все вокруг себя. Данные избыточные. Он просто не может пропустить какую-то там деталь. Бывают конечно слепые зоны, но их довольно быстро учишься устранять при работе со сканером. Просто чаще переставляешь прибор и не экономишь на станциях. Вот так мы поставили наш первый сканер.
А всего за 15 лет, при непосредственно моем содействии, было поставлено чуть более 100 сканеров для различных задач и работ. Был и неудачный опыт. Смотрели, все нравилось, приобретали, а работ не было... валялся без дела. Но тут не в приборе дело. Такие приборы нужно брать уже под конкретные работы, а не в надежде, что они появятся. И прежде, чем приобрести такой прибор себе на склад, лучше пригласить специалистов на свой объект и попросить их выполнить работы, если конечный результат (не красивое облако точек, а готовая 3Д-модель или отчеты о деформации, или план фасада) устроил заказчика - брать. Сейчас рынок НЛС в России довольно неплохо наполнен. Есть компании, которые уже полностью ушли от классической геодезии и занимаются чисто лазерным сканированием. Практически на каждом крупном заводе есть свой сканер, либо они часто обращаются к сторонним проектным институтам, у кого есть такой прибор.
Сканеров на рынке сейчас появилось множество. На любой вкус, цвет и кошелек. Ситуация напоминает авторынок. Есть зарекомендованные игроки с качественными моделями, такие как Leica, Faro, Z+F, Trimble... есть много марок из поднебесной, обычно просто копирующих какую-либо удачную модель перечисленных брендов. Отличаться могут по точности, скорости, удобству...
Буду закругляться. В следующем посте я опишу конкретный вид работ с наземным лазерным сканером и обработкой данных.
Для окончания напишу характеристики одного из самых популярных наземных лазерных сканеров на сегодня (у нас именно такой) Leica RTC360. Прибор вышел на рынок уже 5 лет назад и совершил переворот в НЛС настолько, что и сегодня по характеристикам его кажется никто не обошел, возможно подобрался вплотную. Информации актуальной по всем сканерам, которые производятся в мире у меня к сожалению нет. Так вот, скорость сканирования 2 млн. измерений в секунду (напомню у ScanStation было 4 тысячи), вес 8 кг (это с установленными аккумуляторами), дальность 170 метров (существют специальные горные сканеры, которые могут снимать до 2км, но с значительно меньшей скоростью), управление все на борту через сенсорную панель. Температурный диапазон работы от -20 до 50 (практически все сканеры до него работали исключительно от 0 градусов). Встроенный датчик наклона (не нужно при установке каждый раз выставлять уровень. Можно даже перевернуть вверх ногами, чтобы сканировать например резервуары через люк). Автоматическая сшивка станций (очень полезная технология, которая отслеживает положение прибора во время движения от станции к станции, очень ускоряет время дальнейшей обработки). Возможность подключения планшета или телефона, для удаленного запуска или просмотра прямо в поле полученного результата. Вот так продвинулась технология за 20 лет. По мне, это все равно, что сравнивать паровоз с современным поездом, типа Сапсан. Или первый смартфон HTC с последним iPhone.
Как будто меня в рекламу потянуло. Справедливости ради оговорюсь, то что я описал выше, есть у многих современных сканеров других производителей. Возможно есть фишка, которой нет в Leica. Опять же прибор не самый дешевый, и существуют проблемы с ввозом их на территорию РФ.
На этом наверно и закончим для начала. Слишком уж длинно получилось. Примеры работ будут в следующих постах. Либо, если кому не терпится посмотреть, погуглите на ютубе - наземное лазерное сканирование и работа с облаками точек. Роликов предостаточно. Еще есть серия фильмов "Невидимые города Италии" 2016 года, там при помощи НЛС, а также МЛС снимают красивейшие объекты культурного наследия, например Собор во Флоренции и много другого красивого.
Благодарю за внимание.