
Вкатиться в IT
Добрый человек выкладывал ссылку на телегу где обучает как вкатиться в АйТи. Простые уроки для среднего разума как я. Помогите найти, а то опостылела жизнь без зп в 300к 😄
Добрый человек выкладывал ссылку на телегу где обучает как вкатиться в АйТи. Простые уроки для среднего разума как я. Помогите найти, а то опостылела жизнь без зп в 300к 😄
В воскресенье, 5 мая, Ренд Фишкин (известный во всем мире как основатель популярного сервиса Moz.com) получил электронное письмо от человека, утверждающего, что у него есть доступ к массивной утечке документации API из внутреннего подразделения поиска Google. В письме также утверждалось, что эти утекшие документы были подтверждены как подлинные бывшими сотрудниками Google, и что эти бывшие сотрудники и другие лица поделились дополнительной, приватной информацией о работе поиска Google.

Один из скринов "слитой" базы Google
Многие из их заявлений прямо противоречат публичным заявлениям сотрудников Google, сделанным за последние годы. В частности многократным отрицаниям компании о том, что сигналы пользователя, связанные с кликами, используются, что субдомены рассматриваются отдельно в ранжировании, отрицаниям существования песочницы для новых сайтов, отрицаниям того, что возраст домена собирается или учитывается, и многому другому.
"Сливщиком" информации оказался Эрфан Азими (ссылка на Линкедин). В его профиле указана Грузия как страна проживания. Именно он показал Ренду саму утечку: более 2,500 страниц документации API, содержащей 14,014 атрибутов (функций API), которые, по-видимому, происходят из внутреннего "Content API Warehouse" Google. Судя по истории коммитов документа, этот код был загружен на GitHub 27 марта 2024 года и не удален до 7 мая 2024 года.
Что интересного в этих документах?
Ложные Утверждения Google, Опровержения которых обнаружены в Документации API
Утечки документации API Google раскрыли значительные противоречия между публичными заявлениями Google и их реальными
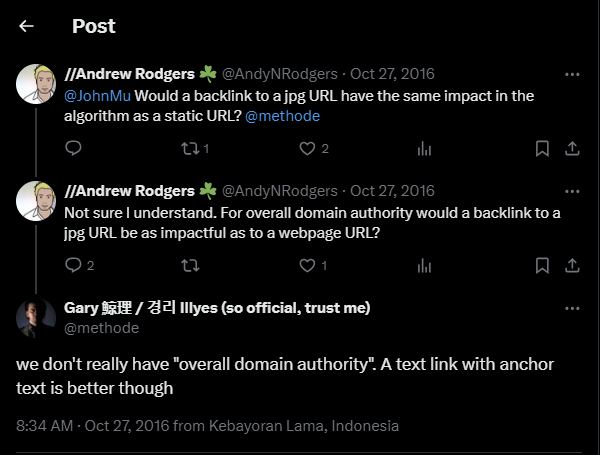
Авторитет домена: Google неоднократно отрицал использование "авторитета домена", утверждая, что они не используют метрику для измерения авторитета сайта в целом. Однако утекшие документы показывают существование метрики под названием "siteAuthority", используемой в внутренних системах Google, что противоречит их публичным заявлениям. Такие известные личности, как Гэри Илш и Джон Мюллер, неоднократно заявляли, что Google не использует метрику авторитета сайта, что теперь кажется вводящим в заблуждение.
Использование кликов для ранжирования: Представители Google давно отрицают, что клики влияют на ранжирование в поиске. Несмотря на эти утверждения, свидетельства из антимонопольного процесса Министерства юстиции США и различных патентов указывают на существование систем, таких как NavBoost и Glue, которые используют данные о кликах для влияния на результаты поиска. Эти системы существуют с 2005 года и используют обновляемые данные для настройки результатов поиска на основе кликов пользователей. Эта практика противоречит публичным отрицаниям Google и подчеркивает их попытки ввести в заблуждение сообщество SEO.
Эти открытия подчеркивают разницу между публичными заявлениями Google и их внутренними операциями, вызывая вопросы об их искренности.
Что будет дальше?
Пожалуй, ничего. Google наверняка будет открещиваться и утверждать, что все это фейк. Признавать свои ошибки никому не хочется:) В любом случае мир SEO теперь не умрет совсем, но людям, которые работают в этой сфере будет наверняка интересно сопоставить свои знания с тем, что упоминается в слитых документах.
Что лично почерпнул для себя автор этих строк
Даты публикаций очень важны - Google ориентирован на свежие результаты, и документы иллюстрируют многочисленные попытки ассоциировать даты со страницами.

Фрагмент с упоминанием про важность упоминания дат изменений контента
Лучший подход – указать дату и быть последовательным в ее использовании в структурированных данных, заголовках страниц, XML-картах сайта. Указание дат в URL, которые противоречат датам в других местах на странице, скорее всего, приведет к ухудшению ранжирования контента. Что ж попробую протестировать полученные знания в своем блоге :)
Где почитать первоисточники?
Источники на английском языке.
Сайт Ренда Фишкина: https://sparktoro.com/blog/an-anonymous-source-shared-thousands-of-leaked-google-search-api-documents-with-me-everyone-in-seo-should-see-them/
Сайт Майка Кинга: https://ipullrank.com/google-algo-leak
Ребята, всем привет. Ситуация SOS! Прошу вашей помощи и советов.
Я работаю в ит компании -интеграторе
Мне поставлена задача до конца мая найти ит заказчика с большим и постоянным ит бюджетом, которого можно взять в проработку. Все бы ничего я взял на примету нескольких, но после детального изучения и аналитики по ним, понимаю, что вряд ли смогу их защитить перед руководством.
Нужны предприятия, которые закупают компы, серверы, мультимедийные системы в объеме от 10 млн.руб в месяц.
Справились? Тогда попробуйте пройти нашу новую игру на внимательность. Приз — награда в профиль на Пикабу: https://pikabu.ru/link/-oD8sjtmAi

Всегда был только читателем, но пришла ситуация, когда нужна ваша помощь
Ищу владельца сайта онлайн генератора паролей!
Конекретно onlinepasswordgenerator
Писал в форме обратной связи через хост провайдера, но ответа нет(
Если это ваш сайт, пожалуйста, дайте обратную связь, последняя надежда, найдись)
Если вы увидели мой пост, и вас это не затруднит, нажмите плюсик чтобы на время поднять пост. Без рейтинга. Спасибо!
Продолжаем репортаж из нашего сумасшедшего дома на Урале.
Пару недель назад, на HeadHunter-e лежала вакансия на сис. админа в ПГНИУ
(Пермский Государственный Национальный Исследовательский Университет).
Откликаюсь, жду.
Через пару дней, пишет мне в Телегу некий Дмитрий Басов.
Я сначала подумал, что это руководитель тех. подов, оказалось, местный и ЕДИНСТВЕННЫЙ сис. админ.
Так мол и так, приходите на собес в главное здание универа такого-то числа в такое-то время.
Я говорю: «Ок, буду.»
Приезжаю специально на пару часов пораньше.
Нахожу нужный кабинет, стучусь, говорю: «Здравствуйте. Я на собеседование. Можно?»
В ответ слышу нечленораздельным, полусонным: «Подождите немного. Я занят». Времени было около 12 часов дня.
Ну, думаю, занят человек, подожду полчаса, пофиг. Сажусь на стул в коридоре, залипаю в телефон. Время идёт. Проходит час. Я всё сижу. На собес приходит ВТОРОЙ чувак.
Стучится в дверь, говорит ровно тоже самое что и я: «Здравствуйте. Я на собеседование. Можно?»
Его точно также просят подождать в коридоре. Он стоит, ждёт. Проходит ещё где-то полчаса.
Басов, уже, видимо, забыв про меня, но, каким-то чудом, вспомнив про второго чувака приглашает его зайти. Я всё сижу. Спустя ещё примерно час, дверь наконец-то открывается, чувак выходит из кабинета и уходит восвояси. Меня никто не приглашает. «Йобаныйврот» - думаю я, «откуда вы такие только лезете?»
Стучусь второй раз, повторяю трюк с вопросом о собеседовании и О ЧУДО, меня наконец-таки приглашают.
Дмитрий Басов, этот сверхчеловек, несколько минут ищет моё резюме,
а после того как находит, начинает спрашивать то, что в нём и так написано.
Басов: «Где учились? А, вот вижу! Ага, ага…»
# Все названия мест учёбы произносит неправильно. Я сижу, молчу.
Басов: «Тааак, места работы… Ыгы…»
# Все названия мест работы также произносит неправильно.
Басов: «Это что за организации?»
# Здесь становится понятно, что Басов, этот отбитый профессионал мирового уровня, видит моё резюме впервые в жизни, то есть он никогда его не открывал и не пытался даже вчитываться в то, что там написано.
Я говорю: «Аутсорсинговые компании, тех. поддержка, занимаются тем-то, и тем-то.»
Здесь Басов чисто Табаки из Маугли Киплинга выдаёт: «Чё-то вы как-то не уверенно отвечаете! Ы-хы-хы-хы, ги-ги-ги, хр, фм, и-хи-хи-хи. А? Чё это, вам не нужна работа, да?»
# Я сижу с абсолютным стоунфейсом, смотрю на него и думаю: «У тебя действие препарата на исходе, или что?»
Говорю: «Да нет, нужна. Иначе бы я, наверное, не пришёл на собеседование.»
Басов: «Ну лаааднааа, так… Сейчас нада будет пройти небольшой тест на (внимание!) адекватность.»
# Видели когда-нибудь как змея смотрит на мышь? Примерно так я смотрел на Басова в тот день…
Неведомо откуда, представитель цивилизации, опередившей время и, судя по всему пространство, достаёт (хорошо хоть не из жопы) какой-то жёваный папирус с тестом.
Тесту лет эдак 20. Почему? Потому что там были вопросы на тему FAT16, FAT32,
Windows Server 2003 и тому подобная лешая дичь.
Могу честно сказать, с таким старым софтом я никогда не работал, только читал про него. Моё знакомство с серверным оборудованием началось с Windows Server 2012 R2. Файловые системы типа FAT я застал в далёком детстве на Windows 98 и немножко на XP. Да и то, когда у меня появилась первая версия XP, я по совету старших товарищей, быстренько переставил её на NTFS, так как уже тогда, в далёкие нулевые, они сказали мне, что FAT32 – это каменный век.
В общем, тест, в силу своих познаний и опыта я сдал, молча положил Басову на стол и точно также молча вышел за двери этого «прекрасного» учреждения.
Больше мы с этим левитириующим объектом, увы, не встречались.
Может быть оно и к лучшему, хотя, как говорится, I WANT TO BELIEVE.
Конец второй серии.
Я пробую заниматься разработкой игр на Unity. Получается как попало. А хочется по хорошему. Научиться разбивать проект на модули, встраивать отдельные системы, снизить связанность, понять как устанавливать зависимости, научиться делать тесты, разобраться с атрибутами. Делать код расширяемым!
В общем - ищу наставника.
1. DuckDuck Go
Предпочтительная альтернатива Google в dark web. Эта частная поисковая система не отслеживает историю посещений и другие данные, а значит, предлагает неперсонализированные результаты поиска.
https://duckduckgogg42xjoc72x3sjasowoarfbgcmvfimaftt6twagswzczad.onion/
2. ProPublica
ProPublica - первый крупный новостной ресурс, у которого появилась dark web-версия. Присутствие этой некоммерческой организации, занимающейся журналистскими расследованиями, в Tor позволяет сохранять анонимность и обходить блокировки стран, а также способствует свободе слова.
http://p53lf57qovyuvwsc6xnrppyply3vtqm7l6pcobkmyqsiofyeznfu5uqd.onion/
3. KeyBase
По своей функциональности Keybase похож на такие приложения для обмена сообщениями, как WhatsApp, и позволяет обмениваться файлами с друзьями и другими контактами. Ваши данные шифруются end-to-end с использованием криптографии с открытым ключом для обеспечения конфиденциальности и анонимности.
http://keybase5wmilwokqirssclfnsqrjdsi7jdir5wy7y7iu3tanwmtp6oid.onion/
4. Riseup
Безопасный сервис электронной почты, предназначенный в первую очередь для групп активистов. Этот сайт, управляемый добровольцами, не ведет записей о вашей деятельности, а также защищен от вредоносных атак и государственного вмешательства.
http://vww6ybal4bd7szmgncyruucpgfkqahzddi37ktceo3ah7ngmcopnpyyd.onion/
5. Библиотека комиксов
Если вы фанат комиксов, то вам стоит заглянуть на этот сайт в Dark Web. Comic Book Library предоставляет доступ к тысячам комиксов различных жанров и изданий, а также позволяет скачивать их.
http://nv3x2jozywh63fkohn5mwp2d73vasusjixn3im3ueof52fmbjsigw6ad.onion/
6. Ahmia
Ahmia - это поисковая система, с помощью которой можно найти полезные сайты в dark web. Также с его помощью можно просматривать новости, информацию и статистику о сети Tor.
http://juhanurmihxlp77nkq76byazcldy2hlmovfu2epvl5ankdibsot4csyd.onion/
7. Императорская библиотека
Этот сайт называется Императорская библиотека; на нем можно скачать более 500 000 книг и статей, и это, возможно, одна из крупнейших электронных библиотек.
https://kx5thpx2olielkihfyo4jgjqfb7zx7wxr3sd4xzt26ochei4m6f7tayd.onion/
источник https://t.me/itmozg/9678


Такую задачу поставил Little.Bit пикабушникам. И на его призыв откликнулись PILOTMISHA, MorGott и Lei Radna. Поэтому теперь вы знаете, как сделать игру, скрафтить косплей, написать историю и посадить самолет. А если еще не знаете, то смотрите и учитесь.
На приведенной ниже диаграмме показана схема работы поисковой системы.
▶️ Шаг 1 - Краулинг
Веб-краулеры сканируют интернет в поисках веб-страниц. Они переходят по ссылкам URL с одной страницы на другую и сохраняют URL в хранилище URL. Краулеры ищут новый контент, включая веб-страницы, изображения, видео и файлы.
▶️ Шаг 2 - Индексирование
После того как веб-страница просмотрена, поисковая система анализирует ее и индексирует содержимое, найденное на странице, в базе данных. Содержимое анализируется и классифицируется. Например, оцениваются ключевые слова, качество сайта, свежесть контента и многие другие факторы, чтобы понять, о чем эта страница.
▶️ Шаг 3 - Ранжирование
Поисковые системы используют сложные алгоритмы для определения порядка результатов поиска. Эти алгоритмы учитывают различные факторы, включая ключевые слова, релевантность страниц, качество контента, вовлеченность пользователей, скорость загрузки страниц и многие другие. Некоторые поисковые системы также персонализируют результаты, основываясь на истории поиска пользователя, его местоположении, устройстве и других личных факторах.
▶️ Шаг 4 - Запрос
Когда пользователь выполняет поиск, поисковая система просматривает свой индекс, чтобы предоставить наиболее релевантные результаты.
источник https://t.me/itmozg/9667






