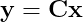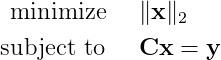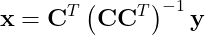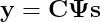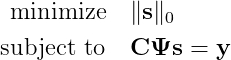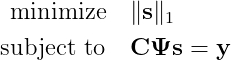Как актуализировать нормативно-справочную информацию на предприятии?
По запросу @SerLev решил расписать кейс по приведению в порядок нормативно-справочной информации (НСИ). Поделюсь этой информацией со всеми бесплатно – может кому-то пригодится в работе, может где-то сделают еще один шажок в сторону цифровизации, адептом которой я являюсь. В общем, работайте братья! //для тех, кто не хочет читать всю портянку целиком: мотайте вниз – там будет алгоритм действий.
Так сложилось исторически на постсоветских предприятиях, что НСИ по большей части на все изделия есть, есть разработанные техпроцессы, но времена на операции не актуальны вследствие разных причин. Например, для повышения ЗП рабочему, работающему на «сделке», просто увеличивали норму времени на операцию, при этом оставляя старой стоимость нормо-часа. Хотя надо было делать наоборот, но…
Или, например, увеличивали нормы времени на операции (и как следствие, увеличивали трудоемкость изготовления продукции) для обоснования высокой стоимости изделий перед госзаказчиком. Есть, конечно, предприятия, которые в своих информационных системах хранят два вида времен: одни реальные, а другие для начисления ЗП. Но сейчас не про такие предприятия рассказ.
Также в этой истории оставлю за рамками предприятия, на которых всяких внедренцев-цифровизаторов воспринимают как инфоцыган )) На таких предприятиях работают суровые специалисты, которые не верят таким инфоцыганам и просто «шлют их лесом»… Такие предприятия мне попадались преимущественно на Урале, например, в Магнитогорске )) Правда, в Челябинске на одном предприятии видел «сильно допиленную» 1С:УПП, в которой было занесено технологическое (а не только конструкторское) дерево ДСЕ (деталей и сборочных единиц) и все сборочные этапы были представлены диаграммой Ганта, к каждому подэтапу составлен сборочный комплект, и запуск в работу деталей идет этими сборочными комплектами. Ну, и вишенка на торте: поскольку вся продукция предприятия «кастомная», то сначала все НСИ рождается в PDM-системе, а потом уже передается в 1С. Это самое правильное решение для поддержания актуальности НСИ. И только так.
Вернемся к нашему рассказу про неактуальное НСИ и неправильные нормы времени в частности:
Норма времени на операцию рассчитывается по формуле: Тнв = Тшт +Тпз/n, где Тшт – норма штучного времени; Тпз – подготовительно-заключительное время; N – размер изготавливаемой партии, в шт.
Рассчитывает Тнв обычно Отдел труда и заработной платы (ОТиЗ) по старым советским справочникам, т.е. оборудование стало более высокопроизводительное, а нормы времени остались советскими. Иногда ОТиЗ (если у них есть время или кто-то в цехе недоволен нормами времени) выходит в «поля» и проводит реальные замеры Тшт, но в целом это не меняет картины на предприятии – нормы остаются в большинстве своем старыми, ибо замерить времена миллиона операций просто невозможно. Для понимания приведу пример: консоль крыла планера Ил-76 – это более 780 тыс. операций! И это всего лишь консоль – просто два крыла, а есть еще фюзеляж… А пять путевых машин, составляющих основу номенклатуры машиностроительного предприятия, – тоже почти 1 млн. операций.
Так что имеем то, что имеем: например, расточник закрывает за месяц 450-460 нормо-часов. Он конечно, ебошит как проклятый: задерживается после работы, ест на ходу, выходит в субботу на работу, но по факту он на предприятии присутствует (с вычетом обеденных и технологических перерывов) только 210-220 часов в месяц (блядь, это при 167 часах по Трудовому Кодексу!). Т.е. мы имеем в этом случае завышение норм времени как минимум в два раза! В этой статье я рассматриваю корректировку Тнв только с точки зрения приведения к достоверности, а не с точки зрения снижения ЗП расточника.
Также здесь надо отметить, что актуальное НСИ должно содержать не только верные нормы времени, но информацию на каком рабочем центре (РЦ) выполняется конкретная информация. А вот такой информации зачастую на постсоветских предприятиях нет.
И вот перед предприятием ставится задача в духе сегодняшнего времени: реализовать проект по цифровизации предприятия – внедрить систему класса APS (сокр. от англ. Advanced Planning & Scheduling – программное обеспечение для производственного планирования, главной особенностью которого является возможность построения расписания работы оборудования в рамках всего предприятия).
Т.е. необходимо построить цифровой двойник производственной системы предприятия – имитационную модель со всеми ресурсами, связями и правилами организовывания для построения оптимального расписания работы оборудования в рамках всего предприятия или проверки на модели гипотез типа «а что будет если…».
Как вы понимаете, сия имитационная модель будет основываться на НСИ предприятия, которое лежит в какой-то информационной системе (ИС), например, 1С:УПП или 1С:ERP. Какое расписание построит модель при недостоверных Тнв? Есть известное выражение в ИТ-индустрии: «Shit in – shit out», т.е. «дерьмо на входе – дерьмо на выходе». Вот…
И вот на предприятие приезжает команда цифровизаторов… На совещании у генерального директора сидят: технический директор, коммерческий директор, главный конструктор, главный технолог, начальник планово-диспетчерского отдела, начальник ИТ-службы… Цифровизаторы говорят: «Мы вам построим цифровой двойник предприятия, вы сможете управлять всеми ресурсами на новом уровне, сможет рассчитать сроки выполнения заказов, расписание работы рабочих центров (РЦ) будет построено из учета управления «узкими местами». Генеральный директор говорит: «О! Отлично!», а технический директор спрашивает: «А на каких данных вы построите сие чудо?» Цифровизаторы отвечают: «Так на ваших данных, мы их из ИС выгрузим!». И тут происходит немая сцена как у Гоголя: гендир еле сдерживает улыбку, техдир тихонько «прыскает в кулачок», главный технолог отводит глаза, главный конструктор выходит поговорить по телефону… и только начальник ИТ-службы смотрит на тебя прямо своими грустными усталыми еврейскими глазами… «На наших данных?! Ну, стройте…»
И цифровизаторы побегут строить имитационную модель, которая потом покажет «узкие места», которые вовсе, при ближайшем рассмотрении, таковыми не являются. Ну, вы помните: «Shit in – shit out».
Вот здесь мы прервем наш рассказ и перейдем к решению проблемы по актуализации НСИ.
Рассмотрим три варианта решения данной задачи:
1-й вариант (простой): На всех предприятиях сейчас уже внедрены электронные системы допуска сотрудников – АСКУД (автоматизированная Система контроля и управления доступом). В этой системе собирается информация, когда работник зашел на предприятие и когда вышел, т.е. мы знаем время фактического нахождения работника на предприятии. И так:
- шаг 1: из фактического нахождения работника на предприятии за месяц (несколько месяцев или год) вычитаем время технологических и обеденных перерывов;
- шаг 2: делаем связку «рабочий – РЦ». Эта информация есть у мастера участка – он знает какой рабочий за каким станком работает.
- шаг 3: делаем связку «рабочий – операция – РЦ». Информация «рабочий – операция» есть в ОТиЗ: по всем выполненным операция работнику начисляется ЗП, все есть в ИС.
- шаг 4: Делим суммарное время выполненных операций конкретным рабочим за месяц (несколько месяцев или год) на суммарное время его присутствия на предприятии (за минусом технологических и обеденных перерывов), получаем коэффициент приведения Тнв для конкретного РЦ
- шаг 5: Зная связку «рабочий – операция – РЦ», делим на коэффициент приведения все Тнв операций, выполняемых на данном РЦ. Получаем актуальные Тнв в первом приближении
- шаг 6: делаем замеры Тнв для нескольких операций на особо загруженных РЦ. Смотрим соотнесение с рассчитанным Тнв, делаем корректировки.
2-й вариант (сложный): Похож на Вариант 1, но более точный, но сука сложный. Надеваем на себя личину DataScientist’а: нам потребуется выгрузка из ИС факта выполнения всех операций за год по всем рабочим. Выполняем первые три шага из Варианта 1.
- шаг 4: На основе выгрузки из ИС факта выполнения всех операций за год по всем рабочим составляем управления по каждому рабочему за каждый день (будет 248 уравнений по одному рабочему – по количеству рабочих дней в году):
К1Х1 + К2Х2+ …+… КNХN = Y/Z
Где ХN – Тнв на N-ую операцию, КN – коэффициент приведения для N-ой операции, Y – суммарное время всех выполненных операций в этот день, Z – время нахождения на рабочем месте в этот день.
- шаг 5: Полученную систему из 248-ми уравнений упрощаем, исключая повторяющиеся
- шаг 6: Полученную систему из 248-ми уравнений решаем методом наименьших квадратов и получаем коэффициенты приведения для каждой операции на данном РЦ.
- шаг 7: Делим на коэффициент приведения все Тнв операций, выполняемых на данном РЦ. Так делаем по каждому рабочему/РЦ. Получаем актуальные Тнв. Пусть теперь ОТиЗ отсосёт!
3-й вариант (для случая, когда надо актуализировать не только Тнв, но и всё НСИ требует корректировки):
- шаг 1: внедряем на предприятии систему диспетчеризации через «тонкий клиент» к 1С УПП или ERP (где взять «тонкий клиент» спросите у меня – у нас дешевле всех, ну или возьмите у других ))).
- шаг 2: всем рабочим, всем РЦ, всем деталям присваиваем штрих-коды.
- шаг 3: начинаем сбор данных через ТСД (терминалы сбора данных) на которых стоит мобильное приложение («тонкий клиент»): рабочий авторизуется на РЦ считывая ТСД свой штрих-код и штрих-код РЦ, начиная операцию рабочий считывает ТСД штрих-код детали, по окончании операции рабочий снова считывает штрих-код. Таким образом в систему заносится фактическое время исполнения операции на конкретном РЦ. Время, которое потребуется на актуализацию НСИ зависит от длительности ваших производственных циклов - надо чтобы все детали прошли через все РЦ. Получаем актуальные Тнв с маршрутами и привязкой к РЦ.
И самое важное: после того как вы выбрали и согласовали с Заказчиком вариант актуализации НСИ, нужно это зафиксировать протоколом, в котором будет сказано, как вы достигаете актуальности данных, какие есть допущения при их актуализации, и что на этих данных будет построена имитационная модель. И вот тогда Заказчик уже не скажет: «А я вот не верю этим данным»!