Всем привет это ролик с подборками интересных инструментов которые пригодятся как для ремонта так и для строительства. Очень удобные, упрощает работу.
Если вам интересны новости из мира технологий, а также подборка прикольных и интересных изобретений, и гаджетов которые существуют на данный момент то тогда добро пожаловать в сообщество.
А так же оставлю ссылки на другие платформы где тоже много всего интересного:
Hypnovel это новый способ создать первую главу романа. (Повествование, изображение и движение, созданные искусственным интеллектом, объединяются в великолепное повествование, менее буквальное, чем традиционная анимация (отсюда и "гипно"), и более сенсорное, чем аудиокнига, в стиле, который делает главу уникальной и убедительной.
Система использует возможности искусственного интеллекта, чтобы разработать новую форму творческого самовыражения для авторов.
Писатели, издатели и читатели также смогут создать и/или насладиться бесконечным количеством художественных - и нехудожественных - произведений в форме "Гипнороманов".
Под капотом уникальный «комбайн», использующий сразу несколько форм ИИ, объединенных в одну:
• GPT4 — для перевода
• Stable Diffusion — для анимации
• Eleven Studios — для озвучивания
Вводите текст из главы, кратко описываете место действия книги, выбираете визуальный стиль и голос диктора. Рендеринг ролика занимает всего несколько часов.
Так авторы проекта намерены помочь писателям познакомить со своим творчеством потенциальных читателей, которые иначе даже не узнали бы об их книгах.
В системе представлены следующие стили:
Рисунок шариковой ручкой:
Графический роман
Нуар
Смешанная техника
Так же в системе можно выбрать голос, который будет повествовать о вашем гипноромане.
Есть и такие функции, как вступление и музыка. Вы можете легко добавить эффекты постпродакшена, чтобы сделать ваше творение еще более захватывающим.
Будет очень интересно посмотреть, что у вас получится в комментариях!
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? Подпишитесь на мой телеграм канал. Там я рассказываю, как можно использовать нейросети для бизнеса.
Появление передовых технологий на основе искусственного интеллекта открыло новые горизонты для творчества и редактирования видео. Одним из последних достижений в этой области является нейросеть GoEnhance AI, позволяющая преобразовывать видео в различные стили с впечатляющей легкостью.
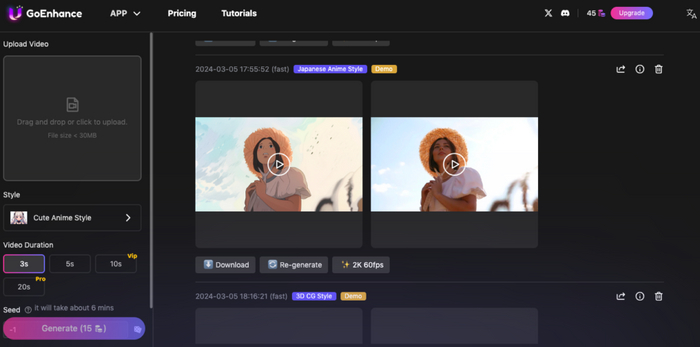
GoEnhance AI предлагает пользователям простой и доступный способ полностью изменить внешний вид их видео. С помощью этого инновационного инструмента вы можете преобразовать обычное видео в захватывающее произведение искусства, используя широкий спектр стилей, включая пиксельный вид, анимацию и даже стиль аниме.
Одно из главных преимуществ GoEnhance AI заключается в его удобстве и доступности. Независимо от уровня ваших навыков в редактировании видео, нейросеть предлагает простой и интуитивно понятный интерфейс, который позволяет легко загрузить видео и выбрать желаемый стиль. Это делает GoEnhance AI отличным выбором как для профессионалов, так и для новичков, желающих экспериментировать с видео-трансформацией.
GoEnhance AI может стать достойной альтернативой другим инструментам на рынке, таким как DomoAI. Хотя DomoAI предлагает впечатляющие функции, GoEnhance AI идет дальше, предоставляя дополнительные уникальные возможности. Одним из основных преимуществ GoEnhance AI является наличие бесплатной пробной версии, что позволяет пользователям экспериментировать с ее функциями без каких-либо финансовых рисков.
Таким образом, если вы ищете мощный и доступный инструмент для преобразования видео, GoEnhance AI предлагает захватывающее путешествие в мир творческих возможностей. С его впечатляющими функциями и удобством использования он может стать вашим идеальным выбором для создания захватывающих видео-произведений.
Кажется, что рекомендательный движок музыкального сервиса - это черный ящик. Берет кучу данных на входе, выплевывает идеальную подборку лично для вас на выходе. В целом это и правда так, но что конкретно делают алгоритмы в недрах музыкальных рекомендаций? Разберем основные подходы и техники, иллюстрируя их конкретными примерами.
Начнем с того, что современные музыкальные сервисы не просто так называются стриминговыми. Одна из их ключевых способностей - это выдавать бесконечный поток (stream) треков. А значит, список рекомендаций должен пополняться новыми композициями и никогда не заканчиваться. Нет, безусловно, собственноручно найти свои любимые песни и слушать их тоже никто не запрещает. Но задача стримингов именно в том, чтобы помочь юзеру не потеряться среди миллионов треков. Ведь прослушать такое количество композиций самостоятельно просто физически нереально!
Так как они это делают?
Если ваши музыкальные алгоритмы не похожи на это, то даже не предлагайте мне скачивать приложение!
Чтобы сделать годную рекомендацию, сервису нужны три сита…
Первое сито - это так называемые рекомендации на основе знаний (knowledge-based). Это значит, что сервис аккумулирует всю доступную информацию об одном пользователе - что он слушает (например, каких артистов или жанр), как часто, что лайкает, что дослушивает, что проматывает дальше и т.д. Учитываются сотни или даже тысячи факторов. Разумеется, собираемые данные анонимны.
После этого сервис делает рекомендацию. Причем она может даваться безотносительно общих предметных знаний сервиса. Например, если мы видим, что Вася добавил в плейлист Metallica “Nothing Else Matters”, то с большой вероятностью ему понравится и “Unforgiven”. Для такого вывода нам не нужна дополнительная информация.
Помимо прочего, рекомендации на основе знаний помогают решить проблему “холодного старта” (это когда свеженький и тепленький юзер только-только зарегался), предлагая новому пользователю тот контент, который соответствует его требованиям с самого начала использования.
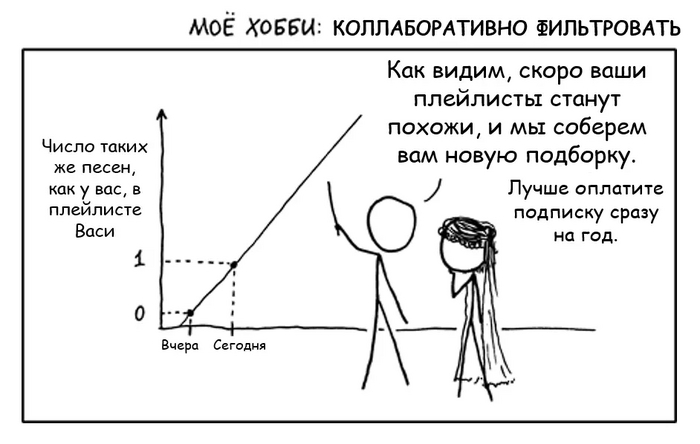
Второе сито - коллаборативная фильтрация. Пожалуй, это самый главный прием и краеугольный камень любого стриминга. Хотя коллаборативная фильтрация и может издалека походить на анализ предпочтений пользователей, на самом деле это совсем другая техника и технология - гораздо более продвинутая и математически точная.
Работает она на следующем допущении:
Пользователи, которые одинаково оценили какие-либо композиции в прошлом, склонны давать похожие оценки другим композициям в будущем.
Давайте разберем на примере, очень упрощенно:
Допустим, у Васи затерты до дыр треки:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Scooter “How much is the fish?”
Валерий Леонтьев “Мой дельтаплан”
Какую закономерность можно выявить на основе этого набора? Да никакую. Просто мешанина из разных жанров, артистов и эпох.
Тем не менее, у сервиса также есть пользователь Петя, чей плейлист по удивительному совпадению похож на Васин, а именно:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Dua Lipa “Swan Song’’
Валерий Леонтьев “Мой дельтаплан”
Все треки одинаковые, кроме одного. У Васи это Scooter, у Пети - Dua Lipa.
По логике коллаборативной фильтрации, есть вероятность, что если Вася и Петя “обменяются” этими песнями, то обоим понравится. Поэтому такие рекомендации и называются “коллаборативными” - пользователи как бы сотрудничают, обмениваясь предпочтениями друг с другом.
Коллаборативная фильтрация in a nutshell.
Понятное дело, что коллаборативная фильтрация работает не на двух пользователях, и даже не на двух тысячах. А вот на паре миллионов юзеров, у которых удается найти критическую массу одинаковых композиций - уже вполне. Также очевидно, что я привожу примеры карикатурно непохожих песен “из разных миров”. Я это делаю намеренно, чтобы подчеркнуть, что подход помогает делать рекомендации на основе данных, в которых, казалось бы, не за что зацепиться в поисках общего паттерна. Понятное дело, что в реальности между прослушанными и рекомендуемыми треками скорее всего будет больше схожести.
Так почему этот способ дает хороший результат, когда между наборами треков может не быть ничего общего?
Ну смотрите. Музыкальные предпочтения зависят от целого множества факторов - ваш вкус в целом, ваше настроение сегодня, работаете вы или же чиллите, болит ли у вас голова, с какой ноги вы сегодня встали, что конкретно на завтрак ели и многое-многое другое. Запихивать все эти переменные в строгое правило с четкими “если Х, то У” - дело неблагодарное. А вот если ИИ эмпирически прошерстит огромную выборку и найдет в ней похожие участки, то это совсем другое дело.
Здесь примерно та же логика, по которой если нейросетке скормить кучу картинок с котиками, а потом попросить её нарисовать котика, то она скорее всего изобразит туловище, к которому будут приделаны 4 лапы, хвост, шерсть и мордочка с усами и треугольными ушками. То есть нюансы изображения могут различаться, но основные свойства котика (назовем их “котиковость”) будут переданы. А значит, концептуально результат будет верный.
Так же и с рекомендациями в рамках коллаборативной фильтрации. Разве можно рационально объяснить, почему одна группа любителей Slipknot вдруг слушает песни Димы Билана (наверно, чтобы вкус перебить, такой себе имбирь между разными роллами), а другая группа - Леди Гагу? Вряд ли. Однако, если такие два паттерна существуют, то это значит, что слушающим Леди Гагу металлистам можно попробовать включить Билана, а их визави, наоборот, протолкнуть в поток Poker Face или Alejandro. Ведь точный эмпирический анализ большой выборки попадает в яблочко как минимум очень часто.
Наконец, третье сито, которое отлично дополняет первые два. Это рекомендации на основе контента (content-based). Здесь уже анализируется непосредственно сама композиция. Сервис берет песню, разбивает её на куски, отрезки или даже отдельные “квадраты”, после чего анализирует каждый отдельный элемент звука и ищет песни, технически похожие на анализируемую. Есть вероятность, что если Васе нравится песня Х с определенным звучанием и ритмом, то ему понравится и песня Y с похожими музыкальными свойствами.
Здесь есть важный нюанс. Звучание песни анализирует машина по каким-то техническим критериям, которые понятны ей, машине. А вот мы, люди, можем кайфовать от песни иррационально. Например, не только благодаря ритму мелодии, аранжировке или тембру голоса исполнителя, а еще и благодаря вайбу композиции, а то и символическому капиталу вокруг неё (например, если песня культовая или просто трендовая и модная-молодежная).
Поэтому, content-based рекомендации не всегда дают хороший эффект сами по себе, но служат отличным дополнением других способов фильтрации.
Также, такой способ - рабочий вариант для так называемых “холодных треков”. Это композиции, которые только-только выложили на стриминг. Допустим, новая песня известного исполнителя, либо же неизвестный трек совсем нового певца-ноунейма, которому тоже хочется славы. В таком случае плясать от самой композиции - полезное умение. Ведь трека еще нет в плейлистах тысяч и миллионов пользователей, а значит, порекомендовать его с помощью коллаборативной фильтрации или через knowledge-based вряд ли получится.
Резюмирую принципы рекомендательных движков музыкальных стримингов с помощью классического мема.
Итак, мы разобрали три основных техники, с помощью которых стриминги рекомендуют звуковой контент нашим ушкам. Разумеется, современные продвинутые сервисы обычно используют их все (получаются “гибридные рекомендации”), прикручивая к каждому из них свои авторские фишки.
Как конкретно это работает. Разбираю на примере гибридного подхода Яндекс Музыки
Теперь предлагаю показать на практике, как конкретно описанные выше техники работают. Для иллюстрации я буду использовать пример Яндекс Музыки. Потому что сам давно пользуюсь этим сервисом (думаю, уже лет 10), а также по той причине, что недавно у них прошло большое обновление алгоритма, которое внесло важные изменения в механизм рекомендаций. Ну и еще потому что всегда приятнее разбирать глобальные лучшие практики на отечественном сервисе, который в полной мере им соответствует.
Итак:
Базово рекомендательный движок Яндекс Музыки реализован через Мою волну, которая появилась на главной странице сервиса пару-тройку лет назад. По умолчанию этот поток сбалансированный - это значит, что он комбинирует любимые и привычные треки (которые пользователь и так активно слушает) с новыми композициями, причем в комфортной пропорции. По своему опыту скажу, что микс между добавленными и новыми треками по умолчанию примерно 50:50. При этом 30-40% новых я лайкаю, чтобы сохранить к себе. За счет этого алгоритм дообучается и адаптируется.
Однако Мою волну можно дополнительно кастомизировать через настройки. Нажимаем кнопку под плеером и проваливаемся вот в такое меню.
Как видим, параметров кастомизации вроде бы немного, но при этом изменения могут быть весьма существенными. К тому же, из скриншота видно, что настройки потока можно включать и отключать в разных комбинациях. Используя свои знания наивысшей математики, я перемножил 5 (Занятия) на 3 (Характер) на 4 (Настроение) и на 3 (Языки) и получил примерно 180. Ну ладно, пришлось использовать калькулятор, подловили…
Так что, внутри одной Моей волны на самом деле сидят очень много разных Моих волн.
Остановимся детальнее на настройке под названием “Характер”. Можно попросить движок делать больше акцента на моих залайканных треках (“Любимое”), или же наоборот чуть абстрагироваться от знаний о пользователе и поддаться общим трендам (“Популярное”).
Но поскольку статья все же о рекомендательном функционале, то остановимся подробнее на настройке “Незнакомое”. Ведь именно глядя на способность подбирать релевантные треки из всего внешнего многообразия можно оценить движок. Итак, если включить “Незнакомое”, то алгоритм сделает серьезный крен в сторону ранее незнакомых композиций.
Кстати, недавнее обновление касалось именно этой настройки. “Незнакомое” получила новый ранжирующий алгоритм, благодаря чему стала более смело предлагать новые композиции, которые, тем не менее, должны соответствовать музыкальным вкусам пользователя.
С обновленной настройкой юзер получает новый аудиоконтент, при этом не ощущая особенно сильных скачков и перепадов. То есть, даже если алгоритм решит выйти за пределы рекомендационного пузыря, дабы расширить музыкальные горизонты пользователя, то он все равно будет оставаться в рамках его предпочтений и смежных жанров. Проще говоря, несмотря на экспериментирование, подбрасывание неактуальной музыки будет сведено к минимуму.
Уважаемые газеты пишут, что теперь пользователи сервиса добавляют к себе в “Коллекцию” примерно на 20% больше новых треков. Для артистов (в том числе молодых и начинающих) это тоже важный ништяк, поскольку повышается вероятность, что их творчество распространится и взлетит среди новой аудитории.
Так вот, для поиска этих самых новых композиций сервис как раз и применяет гибридный подход, объединяющий коллаборативную фильтрацию, анализ контента и фильтрацию на основе знаний о пользователе. Поговорим о нем детальнее.
Начнем с пользователя
Для начала, машина кушает все “долгосрочные” (очень условно их так назову, дорогие технари, не ругайтесь) данные о пользователе. Какие жанры и исполнителей он указывал как любимых, когда регистрировался? Что у него лежит в плейлисте? Что там лежит давно, а что недавно? Что удалялось? Что из лежащего давно он слушает регулярно или иногда, а что лежит мертвым балластом? И еще 100500 факторов и паттернов.
На эти “долгосрочные” знания о юзере накладываются конкретные действия.
Например, обычно Вася слушает треки в одной последовательности, а вчера решил включить в другой. Алгоритм тоже это примет к сведению. Возможно, учтет сразу, а, может быть, посмотрит на динамику последовательности при парочке ближайших использований (кто ж знает, как эта “черная коробка” решит там у себя внутри).
Не забываем, что алгоритмом все-таки заведует продвинутая ML-моделька, которая любит сама себя дообучать и всячески развивать. Так что, хотя человеки и знают принципы её мироустройства, точно предсказать результаты из “черного ящика” решительно нельзя.
Разумеется, движок учитывает, дослушал ли песню наш лирический герой, смахнул её или вовсе влепил ей лайк.
Далее - анализ контента
Вторая составляющая годной рекомендации - это анализ самой композиции. Для этого сервис преобразует трек в специальный формат - цифровой аудиовектор.
Для этого сервис разворачивает трек во времени и раскладывает его на частотные диапазоны, получая спектрограмму. Она передается специальной аудиомодели с нейросетью-энкодером, которая сворачивает спектрограмму в аудиовектор, или аудиоэмбеддинг (это когда сервис прячет в аудиофайле специальные метки - о песне, исполнителе, жанре и т.д.).
У похожих по звучанию треков такие векторы расположены близко друг к другу в многомерном векторном пространстве. У разных треков, соответственно, наоборот.
За счет таких манипуляций алгоритм может разложить трек буквально на атомы, чтобы потом сравнить каждую “элементарную музыкальную частицу” с аналогичными частицами других композиций.
Алгоритм сервиса преобразует трек в аудиовектор, расщепляя его на мельчайшие музыкальные элементы, чтобы проанализировать каждый из них. Вижу так.
Этот прием дополнительно повышает точность рекомендаций.
Наконец, коллаборативная фильтрация
Залезть в глубинные сущности этой техники конкретного сервиса непросто. Но каждый уважающий себя продвинутый стриминг старается довести эту технологию до высокого уровня.
За основу берется принцип, который я описал в первой части статьи. Но реализуется он, само собой, на предпочтениях миллионов слушателей. Алгоритм анализирует обезличенные данные массы пользователей, после чего прогнозирует музыкальные интересы конкретного человека, добиваясь максимально точных попаданий. В основе всего этого движа лежит матрица взаимодействия, составленная из различных оценок пользователей. Если упрощенно, то это такая табличка (ооочень большая), где отображаются все взаимодействия юзера с сервисом. Потом с матрицей работают алгоритмы машинного обучения - они уже обрабатывают данные и передают их в обобщенную модель, которая и отвечает за рекомендации.
Три типа фильтрации в итоге объединяются в единый machine-learning алгоритм под названием CatBoost, который уже генерирует для каждого юзера персональную последовательность треков с учетом множества вышеописанных факторов.
В итоге в алгоритмическом магическом котле заваривается тот самый вуншпунш, который мы готовы потреблять ушами в течение часов и дней, поддерживая свой энергичный рабочий настрой, умиротворенный расслабленный вайб либо же вызывая внезапный эмоциональный порыв. Подчеркнуть нужное в зависимости от ваших текущих целей, настроения и самочувствия.
Теперь вы знаете чуть больше про рекомендательные системы стриминга, особенно музыкального. Надеюсь, было интересно и полезно. Есть что добавить или с чем поспорить? Пишите в комменты.
Если вам понравилось, то подписывайтесь на мои тг-каналы. На основном канале - Дизрапторе - я простым человечьим языком и с юмором разбираю разные интересные штуки из мира бизнеса, инноваций и технологических новшеств (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили). А на втором канале под названием Фичизм я регулярно пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.
🧑💻 Вы наверняка уже заметили, что многие компании стараются быстрыми темпами внедрить в свои приложения AI инструменты. Однако на сегодняшний день их уже настолько много, что порой огромная куча функций и кнопочек лишь отталкивает новых пользователей.
⚙️ Важно соблюдать баланс между пользой и удобством применения, важно быть — эффективным. Так вот, мне удалось найти хорошую новую нейросеть, которая называется 💎Recraft.ai - нейро-арт приложение по редактированию картинок. Думаю вам очень понравится.
🧩 Нейросеть намного нативнее и проще своего конкурента Playground AI и к тому же абсолютно бесплатна.
P.S просто решил написать о полезной нейросетке, которая пока еще не популярна.
Используя опыт написания текстов песен на английском языке и современные достижения науки удаётся создать то, что раньше было возможно лишь в звукозаписывающей студии при наличии соответствующего бюджета. Поражает то, насколько современные технологии упрощают процесс реализации себя в творческом направлении... А ведь дальше-больше. Есть еще больше примеров, если будет интересно.
Пикабушники, сегодня поговорим о еде! Нет, не о том, что вы там себе на ужин заказали. Поговорим о том, как нейросети влезли и в эту сферу нашей жизни. Да-да, эти умные алгоритмы теперь не только картинки рисуют и тексты пишут, но и в кулинарии шарят.
Начнём с рецептов. Представьте: заходите вы в приложение, говорите ему, какие продукты у вас завалялись в холодильнике, а нейросеть вам – бац! – и выдаёт оригинальный рецепт блюда, которое можно из этого состряпать. Никаких вам больше скучных макарон с сосисками! Только кулинарные шедевры от искусственного интелекта.
А ещё нейросети могут анализировать миллионы рецептов со всего мира и создавать совершенно новые, такие, каких ещё никто не видел. Например, нейросеть уже придумала такие шедевры, как "пицца с ананасами и мармеладными мишками" или "суп из шоколада и сельдерея". Звучит стрёмно, но кто знает, может, это будущее высокой кухни?
Но нейросети не останавливаются на достигнутом. Они уже помогают шеф-поварам в ресторанах. Например, анализируют предпочтения гостей и советуют, какие блюда добавить в меню, чтобы угодить всем. А ещё нейросети могут контролировать качество продуктов и даже управлять роботами-поварами, которые готовят еду. Так что, возможно, скоро мы будем ходить в рестораны, где нас будут обслуживать исключительно роботы.
А вы бы рискнули попробовать блюдо, приготовленное нейросетью? Или доверили бы роботу приготовить вам ужин? Пишите в комментариях, что думаете о нейросетях в кулинарии!
Если не хочешь отстать от прогресса подпишись на наш тг- https://t.me/Neiroseti_AI_promt (новости из сферы ии и всё про нейронные сети)
Пикабушники, сегодня у нас в ринге схватка века! В красном углу – нейросети, машины-писатели, которые штампуют тексты быстрее, чем вы успеваете сказать "SEO-оптимизация". В синем углу – копирайтеры, люди-креативщики, властелины слова и повелители внимания читателей. Кто победит в этой эпичной битве за контент? ��
Нейросети, конечно, молодцы. Они могут генерировать тексты на любую тему, в любом стиле и объёме. Хотите новость, стих или даже сценарий для фильма? Пожалуйста! Нейросеть напишет вам всё это за пару минут. Но есть один нюанс... Иногда эти тексты выглядят так, будто их писал пьяный ёжик на клавиатуре. ��
Вспомните хотя бы те нейросетевые статьи, где "Пушкин – наше всё" превращается в "Пушкин – это вообще кто?". Или те стихи, где рифмы настолько кривые, что даже Гуф заплакал бы. В общем, нейросетям ещё учиться и учиться. ��
А что же копирайтеры? Они, конечно, не такие быстрые, как нейросети. Зато они умеют думать, чувствовать и создавать тексты, которые цепляют за душу. Копирайтер может понять вашу целевую аудиторию, подобрать нужные слова и написать текст, который не только информирует, но и развлекает, вдохновляет, убеждает. ��
Так что, пикабушники, кто же победит? Пока что счёт 1:1. Нейросети берут количеством, копирайтеры – качеством. А что думаете вы? Давайте устроим баттл: человек vs. нейросеть!
Если не хочешь отстать от прогресса подпишись на наш тг- https://t.me/Neiroseti_AI_promt (новости из сферы ии и всё про нейронные сети)