В 2000-х, когда компы массово стали одомашниваться (как медиацентры и для игр) интересовался железом и софтом. Уровень знаний - эникейщик (даже подрабатывал этим). Сейчас интерес поугас и мне, иной раз, просто страшно с нового поколения IT и его подхода. Ладно, хрен с ним, что программа меньше 100 Мб - не программа, даже если это калькулятор. Хреново, что тестировщики вымерли как класс (как, например, сценаристы в большом кино) и всё ПО сейчас тестируется на юзерах, даже в очень платных программах. Но что, скажите мне, случилось с банальной логикой? Отменили? Например: в одной из крупнейших американских компаний (которая от нас уходила-уходила, но так и решила остаться) на внутреннем сайте для сотрудников есть разделы: HR, MyHR, IT, MyIT и куча других. И у каждого куча подразделов. Документооборот электронный, часто приходится взаимодействовать. Так вот: чтобы составить заявку на отпуск - это в MyHR, больничный - HR, пройти какое-то очередное обучение - в любом разделе/подразделе может быть, заявку на новую клавиатуру - в IT, если что-то не работает - в MyIT, твой аккаунт вообще хрен пойми где (их два - как страница и как "карточка сотрудника" и перекрестных ссылок между ними нет). Логично же? Запомнили? А теперь, раз в 3 месяца, всё поменяем - исключительно ради оптимизации. Ну и добавим ещё разделов - для наглядности. И это сейчас повсеместно! "Носки в нижнем ящике комода. Но только не для среды - для среды в шкафу. Левый на верхней полке, правый - на вешалке. Если нужны черные носки, то они в карманах брюк, висящих в прихожей под пальто, на пальто сверху пуховик и т.п.". При этом я пол года бился, чтобы отключили второй антивирус на рабочих ПК - довольно бодрая конфига офисных ПК дико тормозила из-за конфликта встроенного и стороннего антивируса - невозможно было работать, браузер запускался 10 минут. Потому что придумывать винегрет из разделов на корпоративном сайте, видимо интереснее, чем настраивать Винду (Винда вообще "из коробки" ни настроек ни оптимизации, а пользователю запрещено всё, даже обои поменять). Повторюсь - примеров миллион. Раньше такое было только на сайтах госучреждений. И у меня вопрос. Как люди, работающие в сфере ноля и единицы, где логика и конкретика - краеугольный камень отрасли, могут творить такую херню? Что в голове у них? И постоянные обновления! - Надо же имитацию бурной деятельности явить. Каждое второе обновление - к ухудшению (раньше работало плохо - теперь не работает совсем). Ннннахрена? Псдец, бесит.
По роду деятельности приходится одновременно работать с самыми разными программами и постоянно между ними переключаться. И что очень сильно выбешивает тормозит работу, так это использование разных комбинаций клавиш клавиатуры и мышки при выполнении банальных операций даже в рамках одного пакета. Пример: в Adobe Photoshop зажимаем Ctrl + прокрутка колеса (вверх или вниз) и получаем увеличение или уменьшение рабочего пространства (той же картинки) , но в Indesign эта же функция выполняется при помощи Alt+колесо, а если по привычке использовать Ctrl, то получим прокрутку по горизонтали. А если в Photoshop нажать Alt+колесо, то сработает прокрутка по вертикали. Конечно, можно потратить время и переназначить, но почему нельзя сразу по людски сделать?
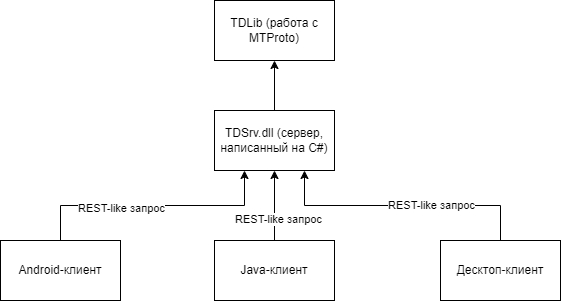
С момента выхода первой части статьи из рубрики «сам себе экосистема» прошёл уже практически год! За это время, мы успели с вами реализовать клиенты VK и YouTube, которые работают на Android 2.2+, а также на Windows Phone 8, написать небольшую 2D-игру с нуля весом менее 1Мб, которая работает практически везде и довести существующее приложение до ума, дабы оно работало даже на смартфоне с дисплеем 240x320! Но на дворе 2024 год, люди стремительно переходят из соц. сетей в продвинутые мессенджеры и уже сложно себе представить современного человека, который не пользовался бы «телегой» или даже «вайбером» в качестве основного средства общения. Поэтому я решил реализовать клиент Telegram на смартфоне 14-летней давности на базе официальной реализации MTProto от команды Telegram — TDLib. Сегодня мы с вами: узнаем новые причины мотивации вернуть в строй смартфоны прошлых лет, напишем на C# реле-сервер, который обрабатывает пакеты MTProto и кодирует их в простой текстовый формат датасетов, который можно моментально обработать даже при нестабильном GPRS-соединении на 21-летнем Siemens C60, а также узнаем о разработке миниатюрных Android-приложений на базе «голого» API-системы, которые не тянут за собой никаких зависимостей, в том числе и AppCompat/androidx. Интересно? Тогда жду вас под катом!
На дворе уже стукнул 2024 год, современные смартфоны предлагают какие-то немыслимые мощности относительно тех, которые когда-то были в первых Android-девайсах. Сейчас за сотню баксов можно купить смартфон с хорошей 1080p IPS-матрицей, 4Гб ОЗУ и 8-ядерным шустрым чипсетом, который вполне способен плавно тянуть даже стремительно «жиреющие» на ресурсы клиенты социальных сетей, банков и прочие необходимые в повседневной жизни приложения. И казалось бы: всё хорошо, покупай себе редмик раз в год или айфон раз в несколько лет и наслаждайся всеми прелестями работы современных приложений…
Для многих людей смартфон — это лишь инструмент, повседневный компаньон, который помогает облегчить выполнение каких-то задач. Им совершенно не важно, как он выглядит, как ощущается в руках, какой у него дисплей и железо «под капотом», лишь бы работал да и нормально. Но есть и другая категория людей, для которых телефоны, смартфоны и любые портативные гаджеты — это не просто утилитарный девайс, а настоящее инженерное произведение искусства, с которого буквально сдувают пылинки и стараются до последнего пользоваться ими как повседневными устройствами. Хотите пример? Смотрите ниже:
Фактически, среди современных смартфонов по сути и нет представителей такого нынче вымершего форм-фактора, как сайдслайдеры с физической QWERTY-клавиатурой, боковые раскладушки с двумя дисплеями и даже из QWERTY-моноблоков есть только смартфоны от Unihertz. Даже среди моноблоков с тачскринами нет никакого разнообразия, лишь без-рамочные одинаковые девайсы за исключением устройств от Sony.
Galaxy S Plus
Раньше меня часто спрашивали, мол, да как ты вообще можешь пользоваться смартфоном 10-летней давности, на котором давно нет официальных клиентов популярных сервисов и только недавно, с развитием блога, мне перестали задавать этот вопрос, поняв, что это бесполезно — ведь это дело принципа и порыва энтузиазма! Смотрите сами: у нас уже есть простенькие, но вполне рабочие клиенты ВК, YouTube, сейчас я допиливаю клиент «Сбера» на СМСках, реализую карты OpenStreetMap (правда пока без адекватной навигации), а в будущем планирую написать приложение для мониторинга погоды и трекинга посылок. Кроме того, в рамках этой статьи мы реализуем с вами клиент Telegram: так чем же это не функционал современного смартфона?
Но хорошо, с функционалом разобрались, однако для многих читателей слова «старый смартфон» это прямые синонимы «тормозной смартфон», мол «фуу, да как можно пользоваться этим тормозным кирпичом, он же лагает в последней версии моей ВКшечки!». Но давайте поставим вопрос ребром: может, это не столько девайсы немощные, сколько сами приложения, с кодовой базой, которая тянется более 10 лет, откровенно жиреют, обрастают костылями и хаками после далеко не одного поколения программистов, которые над ними работали? :) Один, вот, предпочитал пользоваться чистым AppCompat'ом, другой решил притащить зависимость, которая, например, оптимизирует виртуализацию ListView, третий решил заменить всю сериализацию Json со встроенных классов в Android на что-то стороннее и реализовал это костылями и вот так, по чуть-чуть изначально оптимальный и шустрый код превращается в неповоротливое УГ, которое не рефакторили кучу лет.
На видео Galaxy Pocket Neo — очень дешёвый Android-смартфон из 2011 года с 1-ядерным чипсетом на ~800МГц и 256Мб ОЗУ. При этом всём, Android софтварно рисует все анимации на процессоре, без участия GPU.
А значит у стареньких девайсов всё равно есть шанс быть полезными и стать полноценными повседневными смартфонами даже спустя более чем десять лет после выхода! И в сегодняшнем материале, я вам расскажу об особенностях разработки самопального клиента Telegram с собственным прокси-сервером, которое концептуально допускает реализацию даже на кнопочном Siemens C60 2003 года. Как? Читаем ниже!
❯ Принцип работы
В отличии от ВК (который разрабатывали те же самые люди, что и Telegram), API которого построено на базе REST-запросов и концепции Longpolling'а для моментального получения событий с сервера, Telegram построен на базе собственного протокола под названием MTProto, который может работать поверх любого «транспорта» (протокола нижнего уровня) — TCP, HTTP, WebSocket и т.п. Сам по себе MTProto в современном виде, разработка прожженного математика Николая Дурова и его команды — протокол относительно сложный для реализации «на коленке» и в первую очередь требует довольно серьезного понимания принципов работы современной криптографии, да и документирован он всё ещё не особо хорошо. Кроме того, у MTProto весьма интересный бинарный формат пакетов, эдакий велосипед Protobuf. В долгосрочной перспективе поддерживать свой велосипед MTProto может быть весьма проблематично, учитывая не самую лучшую документацию.
Но городить велосипед и не нужно, поскольку у команды Telegram есть официальная реализация MTProto — библиотека TDLib, которая инкапсулирует в себе не только детали реализации протокола, но и сетевой ввод/вывод и выбор транспорта, хранение базы данных сообщений и авторизации, автоматическую загрузку фото и видео, конвертация объектов из бинарного формата MTProto в JSON и полная многопоточность и частичная потоко-безопасность. С одной стороны это плюс — уже готовое решение для реализации клиента на новой поддерживаемой платформе, где есть OpenSSL (можно статически слинковать), zlib (линкуется статически), сокеты и файловый ввод/вывод, а также довольно неплохой механизм JSON-based API, которое позволяет использовать библиотеку в любом языке, который поддерживает вызов C-функций, а с другой и минус — библиотека довольно много весит, в одиночку прибавляя ~20Мб веса приложения для каждой архитектуры, у неё течёт память и у нее странный механизм получения данных с сервера (например, нельзя ответить на сообщение, зная его ID, если сообщение предварительно не загружено, при том что на сервере весь ответ — это просто ID, на какое сообщение прилетел ответ).
Понятное дело, что на стареньком смартфоне использовать оригинальный TDLib будет проблематичным — даже если собрать либы современным NDK и запилить JNI-интерфейс, библиотека «жрёт» много ОЗУ (20-100Мб «вхолостую», в зависимости от числа диалогов и частоты прилетающих событий, плюс со временем течет до 1-2Гб, если не использовать базу данных сообщений. Скорее всего, это косяк в реализации пулов, объекты из которых выгружаются при сбросе в базу, но не выгружаются при высоком потреблении ОЗУ) и уж тем-более TDLib не запустить на любимых кнопочных Java-сонериках! Поэтому я решил написать прокси-сервер, который отправляет команды, слушает ивенты TDLib и предоставляет REST-like API для клиентских программ, которые просто вызывают какой-либо метод, а в ответ получают простой и короткий строковой датасет только с необходимыми полями, весом до 10Кб (что позволяет его быстро загрузить даже с GPRS-интернетом), который можно быстро распарсить даже на преусловутом Siemens C60!
К сожалению, поскольку TDLib прожорлив, я не смогу захостить на своём сервере инстансы для читателей, которые хотят поюзать приложение, поэтому вам придется ставить и запускать сервер на своём VDS/компьютере с белым IP/роутере, если под него есть .NET Core :)
Клиентом же будет выступать Android-смартфон, где приложение будет фронтэндом данных с сервера. Ничего сложного на первое время нет: первое окно — это список диалогов, второе окно — список сообщений в диалоге + поле для написания сообщения, третье окно — информация о пользователе. Всё это я реализовал за три дня не-напряжной работы «на коленке».
Давайте же перейдем к реализации сервера!
❯ Прокси-сервер
Сервер я решил писать на C#, поскольку у .NET Core сейчас всё очень хорошо с кроссплатформенностью и производительностью. Его можно даже на Raspberry Pi запустить :)
Итак, какая-же архитектура такого сервера может быть? Программа инициализирует TDLib, начинает слушать её события в отдельном потоке, пока в основном потоке крутится HTTP-сервер, который обрабатывает каждый отдельный запрос с клиентского приложения. Почему синхронно? Потому что TDLib фактически не возвращает никаких идентификаторов для возвращаемых датасетов, дабы их можно было отличить друг от друга. Приведу пример: у нас есть метод getChatHistory, который возвращает n-сообщений. При этом TDLib сам определяет, сколько хочет сообщений вернуть (и в первый вызов возвращает одно сообщение вне зависимости от настрое и отправляем пакет message n-раз. При этом в пакете message нет какого-либо ID, который позволял бы ассоциировать текущий объект с какой-либо операцией. Увы!
Начинаем с коммуникации с TDLib. Для работы с библиотекой, мы будем использовать json-интерфейс. Для .NET есть биндинги через C++/CLI, но в таком случае, сервер не будет работать на Linux. Для работы с библиотекой хватит лишь три функции: CreateClientID, которая аллокейтит новый инстанс клиента, Send, которая асинхронно отправляет JSON-объект с командой, которую затем обработает TDLib и Receive, которая ждёт N-секунд и возвращает в виде ASCII-строки (!) JSON-объект с описанием события или данными после одного из запросов. За это у нас отвечает класс TDLibInterface, который объявляет PInvoke-методы для вызова нативных методов из библиотеки. .NET Core сам подгрузит библиотеку tdjson (причём на Linux он добавит ей префикс а-ля libtdjson.so, а на Windows загрузит tdjson.dll) и сам разберется с маршаллингом аргументов функций: например, string автоматически преобразует в const char*. Тем не менее, с const char* возвратами нужно быть аккуратнее — у меня был SIGSEGV, пока я ручками не конвертировал их в обычную строку.
З.Ы: На Пикабу нет отдельного тега для кода, а вставить листинги картинками я не могу из-за ограничения на 25 медиаэлементов. Так что листинги будут совсем без табов, но алгоритм их работы понять можно :)
Позволю себе чуточку критики в сторону TDLib. Во первых, почему нет s-версии функции с возможностью указать длину входной строки, а tdjson полагается исключительно на \0 в конце строки? Во вторых, почему const char*, а не wchar_t*? Сейчас юникод во входной строке приходится escape'ами превращать в \u-последовательности. После этого, нам нужно написать обёртку над TDLib, которая будет вызывать для зарегистрированных событий специальные функции, называемые коллбэками. При этом закомментированный WriteLine снизу — это «дебаг» для того, чтобы узнать названия неизвестных мне ивентов :)
В каждом объекте, полученном с помощью receive, есть поле "@type", которое содержит в себе имя класса возвращаемого объекта. Первый же вопрос от читателей — почему я использую JObject с ручным дерганьем нужных полей и вручную пишу JSON в виде строковых литералов вместо нормальной сериализации/десериализации? Ответ прост: во-первых, для актуализации Data-классов придется писать кодогенератор из TL-схемы, а во-вторых иногда TDLib может возвращать немного разные объекты в JSON, из-за чего приходится мудрить с атрибутами на этих самых Data-классах, иначе десериализатор выбросит исключение. Это решается нормальными юнит-тестами на всех вариантах данных, но зачем себе в колени стрелять, если нужен конкретный фиксированный функционал и лишь малое число от всех полей, возвращаемых TDLib?
string recv = NativeInterface.Receive(10.0d);
if (recv != null) { JObject json = JObject.Parse(recv);
if (!handlers.ContainsKey(type)) { //Console.WriteLine("Unknown event type: {0}", type); continue; }
handlers[type](recv, json); }
Теперь переходим к самому интересному — обработке событий и реализации синхронного клиента, который позволяет без async/await просто запросить список сообщений и сразу же его получить (такой подход может быть полезен и юзерботам, которые не хотят размазывать стейты по всей программе). Почему без асинков? Честно сказать, мне они просто не нравятся: как привык к концепции wait/notify и коллбэков из Java, так их и юзаю всю жизнь :)
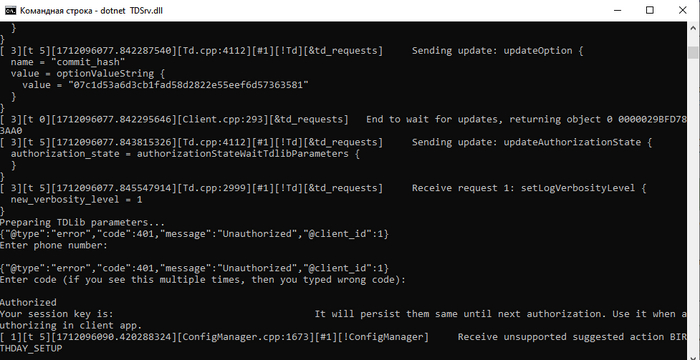
Сначала TDLib запрашивает параметры инициализации (стейт authorizationStateWaitTdlibParameters), затем если пользователь не авторизован — запрашивает номер телефона и код подтверждения (плюс дополнительные шаги для авторизации если они есть). В конце, TDLib возвращает стейт Ready, что означает готовность библиотеки к работе:
После этого, можно начать работу с данными. Обратите внимание, мой подход потоко-небезопасен, его нельзя дергать из нескольких потоков одновременно! В коде ниже, я вызываю метод для фетча сообщений, а затем в соответствующем коллбэке от TDLib обрабатываю данные (дабы статья не разрасталась на 20+ минут, я чуть урезал все листинги).
public List<Message> QueryMessagesInChat(long chatId, long lastMessage, int count) { messages.Clear();
public User QueryUser(long userId) { string json = Utils.Format("{\"@type\": \"getUser\", \"user_id\": \"{0}\" }", userId); NativeInterface.Send(InstanceID, json);
waitHandle.WaitOne(); return user; }
Переходим к реализации самого сервера, для наших целей хватит обычного HttpListener. Сначала мы зарегистрируем все поддерживаемые методы и занесем их в ассоциативный список ключ-значение. Сами методы реализованы в виде делегатов, которые принимают лишь один аргумент — список параметров из строки запроса, а возвращают строку — все ответы, за исключением особых (связанных с загрузкой вложений) — текстовые.
Переходим к обработке запроса. Метод ищет, зарегистрирован ли запрошенный метод и если да, то парсит строку запроса, которая начинается с "?", которую затем передаёт в виде коллекции ключ->значения обработчику метода:
А сами методы, в свою очередь, дергают соответствующие функции из клиента и формируют на их основе датасет в примитивном формате:
public staticstring QueryChats(Dictionary<string, string> args) { if(args.ContainsKey("count")) { int count = int.Parse(args["count"]); StringBuilder ret = new StringBuilder();
В результате получаем вот такой простой датасет, который, как я и говорил, легко распарсить и на Siemens C60, и на Atmega328 — да где угодно! В целом, такой сервер можно использовать для реализации бота в телеграме, который будет передавать показания каких-то датчиков, сигнализацию и прочие клевые штуки!
Переходим к реализации клиента, т.е. приложения на Android. Здесь будет не менее интересно!
❯ Пилим для Android
В геймдеве есть своеобразный мем — некоторые инди-разработчики сначала начинают делать меню, вместо основного геймплея, что становится предметом насмешек среди других разработчиков. Но в разработке приложений для смартфонов всё по другому — здесь как-раз таки хорошо заранее продумывать макет будущего приложения!
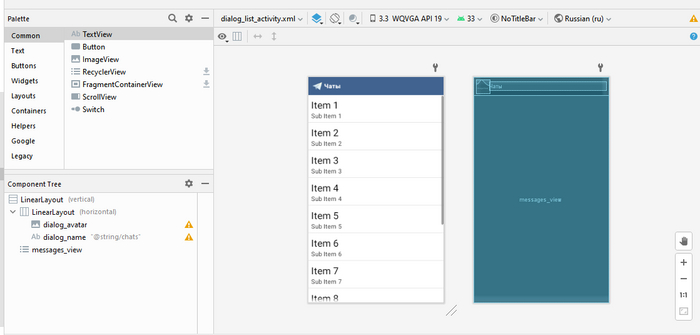
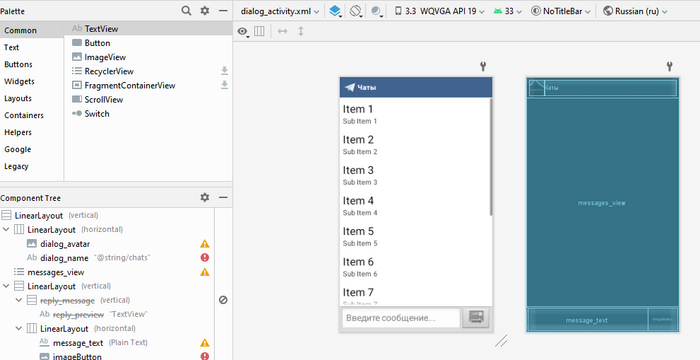
Поскольку у нас с вами мессенджер, то главный экран должен представлять из себя список чатов (ListView) и верхнюю панельку, где в будущем могут разместиться настройки и свайп-менюшка:
Такой вот простой макет.
Каждый пункт меню — это тоже отдельный layout, в котором мы по шаблону строим внешний вид будущего элемента списка. На немолодых устройствах есть смысл использовать как можно меньше контейнеров в layout'е, поскольку пересчет позиций и размеров элементов — одна из самых «тяжелых» операций в UI-фреймворке вообще. Кроме того, не стоит использовать кучу картинок и drawable — в Android 2.x всё 2D рисуется софтварно, аппаратное ускорение появилось только в 3.0 (частично).
Но дабы в списке диалогов что-то появилось, нужно сначала реализовать фетчинг (получение) этих самых диалогов с сервера! Сам объект, который занимается обработкой запросов называется ClientManager и является синглтоном — он в единственном экземпляре на все время работы программы. Помимо менеджмента «ноды» (т.е. прокси-сервера), токена для авторизации и обработчика ошибок, ClientManager реализует метод для асинхронного запроса информации с сервера и, собственно, формирует строки запросов с помощью соответствующих методов:
Подгрузка чатов и сообщений реализована через Adapter — концепция «виртуальных» списков, которая предполагает что система создаст не 50 элементов интерфейса на каждую кнопку чата, а только 5 и будет их виртуально «мотать по кругу», обновляя только данные в уже существующих элементах. Это позволяет значительно ускорить отрисовку, учитывая то, что Android 2.x Canvas рисуется программно.
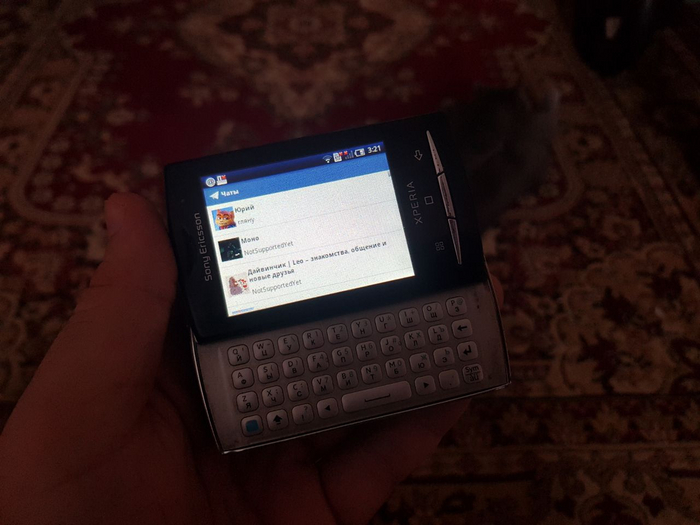
Ну вы уже явно замучились видеть простыни кода, давайте посмотрим что у нас вышло!
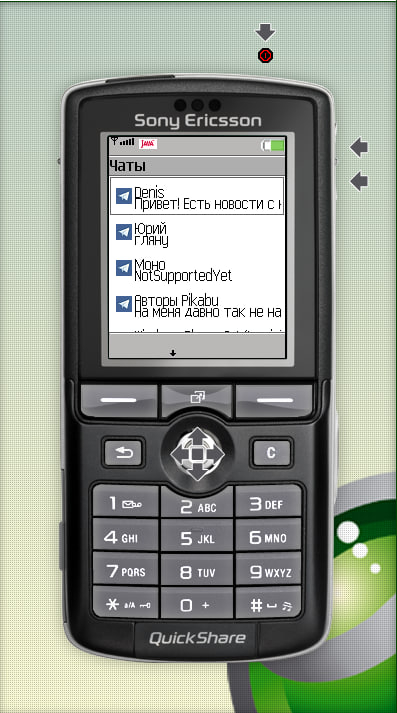
Шустренько, да? А ведь это ультрабюджетник Alcatel OT-916D, один из последних массовых дешевых QWERTY-смартфонов за 5 000 рублей из 2012 года. Кстати, смартфон подарил мне читатель chuvakoff с Хабра!
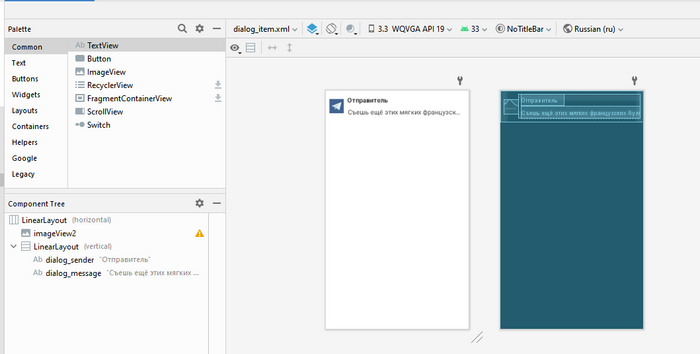
Переходим к окну чата. Основной макет почти такой-же, как и у основного окна: только добавилась панелька для ввода сообщения снизу.
Концептуально, всё тоже самое — запрашиваем данные с сервера, парсим их и загружаем в адаптер, благодаря чему мы сможем листать наш диалог. Однако в сообщения я добавил контекстное меню с стандартными фишками типа копирования, ответа и прочих подобных действий. Поскольку у нас нет ни пушей, ни еще каких-либо средств для поулчения данных о новых сообщениях, я раз в определенный интервал просто получаю сообщения — и если новый датасет отличается от старого — обновляю окошко чата.
Переходим к реализации поля для ввода сообщения. Здесь всё просто — на серверсайде за это отвечает метод SendMessage. Однако для того, чтобы с нашего клиента можно было ответить на другие сообщения, я ввёл также «контекст ответа», в котором запоминается сообщение, на которое мы хотим ответить. Telegram также поддерживает Markdown, однако его полная поддержка пока не реализована.
В остальном же, функционал конечно пока совсем базовый, однако клиент работает очень шустро даже бюджетной X10 Mini Pro и позволяет чатится с моими читателями в Telegram. В будущем хотелось бы допилить:
Поддержка картинок: Сейчас уже есть кривоватый механизм кэширования изображений на стороне сервера, который позволяет загружать аватарки чатов. В будущем, я добавлю поддержку «галерей» с картинками!
Поддержка голосовых сообщений: Не все их любят, но они порой удобны и выручают. Реализую как прослушивание, так и запись!
Подробный просмотр профилей и менеджмент чатов: Удаление сообщений, чатов и прочие фишечки из официальных клиентов.
Казалось бы — до официальных клиентов ещё очень далеко. Но сам факт, чтобы всё это работало достаточно шустро на девайсах, которым уже более 10 лет!
❯ Звучит интересно! Как заюзать твой клиент?
Тут всё очень и очень просто! В первую очередь, нам понадобится ПК с белым IP, роутер (если под него есть сборка dotnet), либо VDS. Виртуальные сервера сейчас стоят копейки, у ТаймВеба есть тариф за 188 рублей в месяц, которого с головой хватит для нашего сервера.
Такая вот рекламная интеграция (к слову, прокси для всех приложений уже более года крутятся именно на мощностях TimeWeb Cloud)!
Программа сначала запросит номер телефона, а затем код подтверждения Telegram. После этого будет создана папка tdlib/, где будут хранится данные вашей сессии, а также файл authkey.txt, где хранится случайный ключ для сессии (md5 phone_number + response code + псевдослучайное число). Не оставляйте его в /var/www/!
Если всё нормально, программа начнёт слушать порт 13377 на всех сетевых интерфейсах, в т.ч и в локальной сети. После этого, ставим уже предварительно собранный, либо собираем сами в Android Studio APK и в окне авторизации пишем адрес ноды и ключ авторизации. Если всё настроено верно — программа запомнит сервер и будет работать без проблем! Вот так всё легко :) Как видите — всё очень и очень просто!
Кроме того, буквально за пару дней до публикации статьи я сел вечерком из интереса что-нить под Java-телефоны попилить… и, как и обещал, реализовал Proof of Concept возможности работы Telegram даже на сонериках, которым скоро 20 лет стукнет! А ведь если ещё чуть заморочится, можно запустить приложение даже на преусловутых монохромных сименсах!
❯ Заключение
Вот такой у нас получился проект с реализацией лёгкого, примитивного, но тем не менее рабочего клиента Telegram, который на клиентской части вообще не использует никаких зависимостей. Вес собранного APK в release-версии — всего 54 килобайта! Понятное дело что с ростом функционала, вес программы будет увеличиваться, но я обещаю — больше 1Мб он не вырастет :)
Ну а вам, моим читателям, надеюсь было интересно прочитать такой «двойной материал» не только о разработке сетевой части без использования Apache/nginx/IIS, но и UI-фронтэнда для Android-смартфонов, которым уже более 10 лет! Исходный код проекта можно найти на моём GitHub: как приложения, так и сервера, а также убедиться в отсутствии каких либо закладок и, если совсем не доверяете, собрать бинарники сами! Для сборки понадобится VS2017 или свежее, а также Android Studio 2.3.2 (если собираете для Android 2.1 и ниже).
Друзья! Сейчас на Хабре опросы сломаны, поэтому если у вас есть желание, вы можете проголосовать в комментариях: какой стиль статей вам больше нравится — где больше конкретики и кода с пояснением как конкретно работает та или иная часть программы, или наоборот стиль ближе к научпопу, где фрагментов кода нет, или их значительно меньше? Пишите своё мнение о проекте в комментариях!
Кроме того, у меня есть канал в Telegram, куда я публикую бэкстейдж статей, ссылки на новый материал, свои наработки, а также посты о ремонте девайсов и различные мысли.
Статья подготовлена при поддержке TimeWeb Cloud. Подписывайтесь на меня и @Timeweb.Cloud, чтобы не пропускать новые статьи каждую неделю!
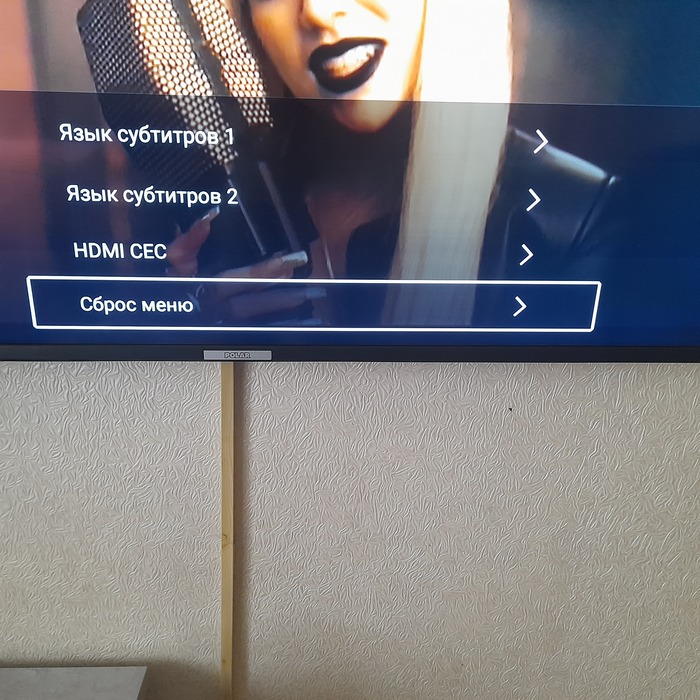
Добрые люди, помогите советом, телевизор Polar, на андроиде, хочу попасть в стандартные настройки андроида, но нигде не нашёл как это сделать. Скажите, возможно ли это или прошивка так урезана, что их просто нет?
Из главного экрана можно попасть в настройки
Вот собственно сами настройки
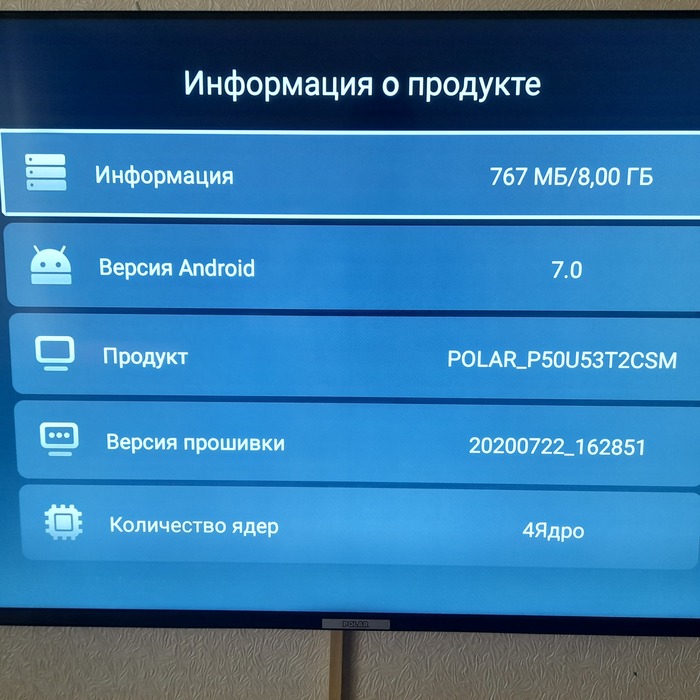
И информация о телевизоре
Из режима тв тоже есть меню, в котором значок шестерёнки, но тут ещё более скудно
Неделю назад я создал ПО, которое массово генерирует btc кошельки и проверяет, использовались ли они до этого в блокчейне.
Вчера я его (ПО) опубликовал для того, чтобы каждый смог проверить, а сегодня публикую результаты своего исследования.
Но для начала, немного теории:
Btc кошелёк защищён последовательностью из 12 слов, которые находятся в особом списке bip39, состоящем из 2048 слов. Имеют смысл не только сами слова из списка, но и последовательность положения этих слов в фразе. Саму фразу называют мнемонической фразой.
Общее количество комбинаций слов составляет 2048 ^ 12, и равно приблизительно 5,44 × 10^39, то есть 5,44 дуодециллионов. Для понимая - 1 дуодецеллион - это приблизительно суммарная мощность излучения 250 000 звёзд как наше Солнце в одну секунду. Наше же число равно мощности 1 375 000 звезд. Много, правда? Но давайте продолжать исследование.
Давайте чуть чуть упростим наше понимание. Пусть btc кошелёк будет замком, а мнемоник фраза - ключом. Итак, вероятность того, что случайный ключ подойдёт к определённому замку равно единице, поделенной на эти самые дуодециллионы, или же как пишут математики - 1 / 5,44 × 10^39, или же примерно 1,84 × 10^-40, то есть 0 целых, далее идет 39 нулей и 184. То есть 184 дуодецелионных доли. А вот вероятность неудачи равна 1 - 1,84 x 10^-40, то есть 0,9999.....9999816, и по сути, стремится к единице, то есть 100%.
Идём дальше.
На текущий момент, согласно исследованием, имеется всего 19 миллионов созданных адресов. Это у нас 19 × 10^6 замков.
Далее воспользуемся формулой комбинирования вероятностей.
Исходя из неё, вероятность неудачи для любого из 19 млн замков равна (1 - 1,84 x 10^-40)^19 x 10^6, что приближается к значению в 1 000 000.
А вот уже шанс удачи равен 1 - (1 - 1,84 x 10^-40)^19 x 10^6, что чуть меньше чем -999 999.
То есть, теоретически, это невозможно.
Давайте теперь перейдём к практической проверке.
Отправные точки - программа работала неделю на 10 пк приблизительно с одинаковой скоростью, и не смогла найти ни одного адреса.
Она делала 2 запроса к блокчейну в секунду. Умножаем на 30 потоков, на которых она стабильно работала, и получаем 60 запросов. То есть в сутки она проверяла 60 × 86 400 = 5 184 000 адресов. Умножаем на 10 ПК и получаем 51 840 000 адресов в сутки.
Если учесть, что всего в сети биткойн может быть создано приблизительно 2^160 адресов, то для того чтобы перебрать абсолютно все адреса мне понадобилось бы примерно 2,87 x 10^41 дней, или же 7.83×10^38 лет. Это в несколько раз превышает ожидаемую продолжительность жизни вселенной и на порядки больше, чем возраст вселенной.
Продолжаем
Как говорилось в теоретической части, общее количество зарегистрированных адресов примерно равно 19 миллионам. Это составляет (19x10^6/2^160) x100, и равно примерно 1.3x10^-39., т.е. 0,000..00013 (всего 39 нулей после запятой) процента.
Для упрощения будем считать, что количество зарегистрированных адресов неизменно. Иначе совсем голову сломать можно будет.
Давайте теперь расчитаем вероятность случайно натолкнуться хотябы на один зарегистрированный адрес за адекватный период, возьмём например 10 лет непрерывной работы.
Количество дней в 10 годах: 10×365=3650 дней.
Общее количество адресов, которые можем проверить за 10 лет: (51×10^6)x3650
Вероятность того, что наш поиск не обнаружит ни одного зарегистрированного адреса равна ( 1 - (1.3×10^-39 / 2^160) ) ^ ((51x10^6)x3650).
Вычислив данное уравнение мы получим результат, стремящийся к единице, то есть к 100%.
Это означает, что практическая вероятность случайного подбора "правильного" ключа таким алгоритмом крайне мала. Что близко соответствует теоретическим изысканиям. Даже для относительно "слабой" 12-ти словной мнемонической фразы.
Выводы:
Вам нужно быть ну просто невероятно удачливым, чтоб подобрать таким образом правильную мнемоническую фразу для хоть одного реально существующего адреса.
Шанс того, что в вас в течении жизни попадёт молния пять раз подряд значительно больше.
Их есть у нас! Красивая карта, целых три уровня и много жителей, которых надо осчастливить быстрым интернетом. Для этого придется немножко подумать, но оно того стоит: ведь тем, кто дойдет до конца, выдадим красивую награду в профиль!