

Ауителбная Группа!
Orbital
Orbital
Автор: TilekSamiev

Первый стадионный концерт состоялся в 1965-м году, когда The Beatles выступили на нью-йоркском Shea Stadium перед 55 000 кричащих фанатов. Этот концерт, на котором «Битлз» заработали более 160 000 долларов за 28 минут работы, стал атрибутом статусности и коммерческой мощи музыкантов. В 1970-е годы стадионы стали основной площадкой для концертных исполнений популярной музыки. От звёзд кантри и рок-музыки до более традиционных певцов, таких как Фрэнк Синатра и Барбра Стрейзанд, популярные исполнители стали привлекать аудиторию от 20 000 до 100 000 человек за один раз.
Музыканты смотрели на стадион как на способ выступить перед наибольшим количеством людей и заработать больше денег, а значит переход к стадионам, как минимум из чисто коммерческих соображений, был неизбежен. Но удерживать внимание 20 000 (или даже более) человек одновременно было серьёзной задачей для тех, кто выступал. И вскоре исполнителей стали сопровождать свои концерты спецэффектами, вроде пиротехники или лазерного светового шоу. Если для небольших клубных выступлений была характерна ламповость, то для стадионных концертов стала характерна зрелищность.
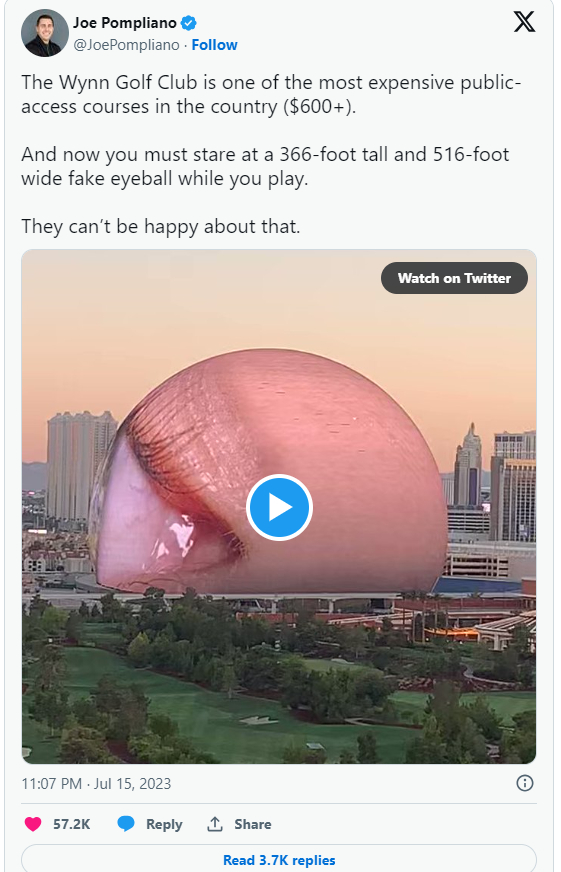
С тех пор такие концерты стали прерогативой самых популярных и успешных музыкантов мира: The Queen, U2, Мадонны, Эминема, Metallica, Майкла Джексона и других. Но концерт на стадионе часто означает плохую видимость и плохой звук для большинства зрителей. Но развитие технологий не могло не коснуться и этой отрасли развлечений. Новая эра живых развлечений начнётся в конце сентября 2023-го года, когда U2 выступят в «Сфере». Геометрическая фигура высотой 112 м и шириной 157 м в Лас-Вегасе попробует полностью переосмыслить стадионные концерты.
Корни Sphere восходят к 2015 году, когда Джеймс Долан, глава Madison Square Garden Entertainment и владелец спортивных команд New York Knicks в НБА и New York Rangers в НХЛ, решил обойти ограничения традиционных концертных площадок и переосмыслить живое выступление. Не задумываясь о том, насколько это будет технологически осуществимо, Долан нарисовал эскиз огромной геометрической структуры, по сути, сферического кинотеатра IMAX на максималке. Основной целью такой арены было бы проведение концертов стадионного масштаба, но который также можно было бы использовать для кинопоказов и спортивных мероприятий.

Когда Долан начал искать инвесторов и высокотехнологичные аудио- и видеокомпании, с которыми он мог бы сотрудничать, Big Tech увлеклись возможностями виртуальной реальности. Марк Цукерберг в то время изменил название компании Facebook на Meta (компания запрещёна на территории РФ), так как был убеждён, что пользователи хотят войти в метавселенную. Идея испытать виртуальную реальность без громоздких головных уборов, из-за которых пользователи смотрятся иногда нелепо, — это то, что действительно вдохновило создание «Сферы».
Не найдя подходящего поставщика аудиооборудования для своего детища, Долан решил инвестировать в Holoplot, небольшой стартап, который получил контракт от правительства Германии на проецирование звука вокруг региональных железнодорожных станций Deutsche Bahn, используя принципы синтеза волнового поля. У них не было ничего концертного, но Долан инвестировал в акционерный капитал стартапа, помогал продвигать их технологии в партнёрстве и те начали создавать для него аудиосистему концертного уровня.
«Сфера» стала самой большой сферической конструкцией в мире, превзойдя Avicii Arena. Она настолько велика, что её легко увидеть из космоса. Сфера была разработана Populous, глобальной архитектурной фирмой, стоящей за многими ведущими спортивными аренами мира. Затраты на строительство, раздутые пандемией, выросли до 2,3 миллиарда долларов — больше, чем у самых дорогих соседей Sphere в Лас-Вегасе, включая Bellagio и Allegiant Stadium.
Более 3000 строителей были задействованы в строительстве сооружения, которое создаст 4500 постоянных рабочих мест после открытия. Строительство началось в 2018 году, как раз тогда, когда Долан начал воображать, как использовать Sphere для турниров по видеоиграм, корпоративных мероприятий, конференций и кинопремьер. Но главным приоритетом новой площадки стало приглашение легендарной рок-группы U2 для открытия. Именно U2 первыми пришли на ум из-за их долгой истории использования новых технологий в своих шоу.


Запатентованная технология Sphere Immersive Sound позволяет излучать звуковые волны в любую точку помещения с высокой точностью. Это позволило бы, например, одной части аудитории слышать фильм на немецком языке, а другой части – на английском, почти как если бы слушатели были в наушниках.
Система состоит из примерно 1600 постоянно установленных и 300 мобильных модулей громкоговорителей HOLOPLOT X1 Matrix Array и включает в себя в общей сложности 167 000 громкоговорителей с индивидуальным усилением. Система использует технологии 3D Audio-Beamforming и Wave Field Synthesis нового поколения HOLOPLOT. Вся звуковая система полностью скрыта за внутренним светодиодным дисплеем Sphere. Любые потери при передаче звука полностью компенсируются алгоритмами HOLOPLOT в механизме оптимизации, в результате чего, по словам разработчиков, получается чистый полнодиапазонный звук практически без окраски.

Традиционная технология громкоговорителей в крупных залах может привести к снижению качества звука по мере увеличения расстояния от громкоговорителей из-за неконтролируемого характера распространения звуковых волн. 3D Audio-Beamforming использует интеллектуальные программные алгоритмы для создания контролируемых и более эффективных звуковых волн, чтобы уровни и качество оставались неизменными от точки происхождения до места назначения даже на больших расстояниях.
Технология формирования луча может единовременно и весьма точно отправлять уникальный аудиоконтент в определённые места в зале, создавая возможность для разных секций слышать совершенно разный контент — например, языки, музыку или звуковые эффекты — предлагая возможности для действительно индивидуального звукового погружения.
Sphere также планирует использовать уникальные возможности синтеза волнового поля, технику пространственного рендеринга звука, которая использует виртуальную акустическую среду. При использовании обычных аудиотехнологий воспринимаемым источником звука традиционно является расположение громкоговорителя. Используя синтез волнового поля, звуковые дизайнеры могут создать виртуальную исходную точку, которую затем можно поместить в точное пространственное положение. Это позволяет направить звук на слушателя так, чтобы он звучал близко, даже если источник находится далеко.
Sphere также использует запатентованные 4D-технологии, такие, как инфразвуковые тактильные сиденья, а также различные атмосферные и экологические эффекты, например тёплый бриз, различные ароматы и изменение температуры, для создания мультисенсорных ощущений. Более половины сидений будут оснащены современной технологией Haptic, которая двигается и вибрирует вместе с аудио и визуальными эффектами на дисплее, с изменением температуры и изменением направления ветра.

Выступления на сцене будут казаться карликовыми из-за высокого светодиодного экрана 16K, который охватывает большую часть аудитории и вокруг неё и может дополнить впечатления от концерта триповой анимацией или крупным планом исполнителей. Экран высотой 76 м и площадью 14 860 кв.м. (для сравнения, это почти в три раза больше экрана на Таймс-сквер, который будет установлен в проекте TSX Broadway в Нью-Йорке), который занимает потолок и стены Sphere потребовал от дизайнеров создания совершенно нового типа камеры Big Sky для создания уникального контента. Это самый большой светодиодный экран с самым высоким разрешением в мире. Режиссёр Даррен Аронофски работает над первым фильмом «Открытка с Земли» специально для «Сферы».
Площадка может вместить 17 600 зрителей, 10 000 из которых будут сидеть в специально разработанных креслах со встроенной тактильностью и переменной амплитудой: каждое сиденье по сути представляет собой низкочастотный динамик.


Экзосфера площадью почти 54 000 кв.м состоит из 1,2 миллиона светодиодных ламп размером с хоккейную шайбу, расположенных на расстоянии 8 дюймов друг от друга. Каждая лампа содержит 48 отдельных светодиодов, каждый из которых способен отображать 256 миллионов различных цветов и оттенков. Благодаря этой способности освещения Сфера может создать новую яркую достопримечательность на горизонте Лас-Вегаса, как это было продемонстрировано 4 июля. «Четвертое июля» было только началом для «Экзосферы», поскольку экран будет продолжать демонстрировать разный контент в связи с крупными событиями в Лас-Вегасе.
Экстерьер Сферы будет освещаться каждый день и ночь анимацией и другими изображениями, иногда привязанными к сезону, но в основном, конечно же, рекламой. НБА была первым брендом, который использовал Sphere в течение двух недель. MSG отказалась сообщить, сколько стоит реклама на Сфере, но ставка будет зависеть от времени суток, сезонности, продолжительности мероприятия и масштаба мероприятия. Некоторые люди уже шутят и возмущаются в Твиттере, что огромные динамичные изображения экстерьера Сферы станут причиной дорожно-транспортных происшествий, или что некоторые изображения попросту неэстетичны и безвкусны.

Спектакли, устраиваемые на площадках Лас-Вегаса, тщательно продуманы и ежегодно привлекают в город миллионы посетителей, но MSG Sphere, возможно, возглавит огромный сдвиг в индустрии развлечений. MSG Sphere строится Madison Square Garden Entertainment совместно с Las Vegas Sands Corp, оператором казино, отсюда и нынешнее название — Sphere at The Venetian Resort. Тем не менее скорее всего, ближе к финальному торжественному открытию будет заключена сделка по переименованию.
В этом месте будут проходить различные мероприятия, в том числе спортивные, такие как UFC, бокс, корпоративные мероприятия, награждения, фильмы, запуск продуктов и многое другое. Но главными будут, конечно, концертные мероприятия и живые выступления самых популярных артистов мира.
«Большинство музыкальных площадок — это спортивные площадки. Они созданы для спорта, а не для музыки. Они созданы не для искусства», — сказал Боно, солист U2. Серия концертов U2 всё ещё находятся на стадии производства, но уже известно, что они будут посвящены альбому 1991 года, Achtung Baby. «К сожалению, из-за большого количества времени и затрат на визуальное создание некоторых иммерсивных декораций довольно сложно быть такими же быстрыми и спонтанными, как мы были в других турах», — говорит Эдж, гитарист группы. «Но мы по-прежнему полны решимости, что некоторые части шоу позволят нам импровизировать».
U2 обязались провести 25 концертов в период с 29 сентября по 16 декабря. Затем новый хедлайнер вступит во владение «Сферой». Имена еще не объявлены, так как многие исполнители пока не заинтересованы и отказываются от идеи создавать эффектные визуальные спектакли, которые «могут затмить их музыку и отвлекать слушателей». MSG Sphere Studios открылась в Бербанке, Калифорния, и занимается производством и постпродакшн для Сферы Лас-Вегаса и будущих сфер. MSG Sphere Studios стремится сотрудничать с кинематографистами и музыкантами, чтобы создать часть контента для Сферы. Студия также будет производить контент в связи с Гран-при Лас-Вегаса 2023 года, трасса которой пройдёт мимо Сферы.
Но руководители «Сферы» из MSG утверждают, что музыканты не будут обременены задачей создания визуальных эффектов для собственных шоу. «Мы очень тесно сотрудничаем с сообществом дизайнеров и художников. Главное, расскажите нам о вашем видении шоу и просто передайте нам один терабайтный флэш-накопитель со своим контентом».
Билеты почти на все концерты U2 распроданы (места остались пока только на декабрьские концерты), и уже рассматривается возможность строительства дополнительных Сфер в Лондоне и других городах по всему миру.
Дополнительные фото в источнике материала и комментариях.
Прошлая статья с попыткой собрать что-то наподобие MIDI-модуля, судя по всему, вам понравилась, поэтому держите описание ещё одного модуля — на сей раз голосового синтезатора — с несколько более запутанной историей, более сложным чипом и менее вырвиглазной дыркой вокруг экрана :-)

Начнём со сжатого экскурса в историю.
После того, как люди научились синтезировать произвольные звуки, инженеры всего мира постоянно предпринимали попытки сделать его похожим на человеческий голос. Обыкновенный TTS, вполне пригодный для чтения текстов, существовал ещё в середине прошлого века, однако же заставить его именно петь не удавалось.
Всё изменилось с началом исследовательского проекта в Университете имени Пумпеу Фабра в Испании, возглавленного Хидеки Кенмоти и профинансированного компанией Yamaha. Результаты этого исследования впоследствии вылились в коммерческую технологию под названием Vocaloid.
Первые вокалоиды звучали довольно примитивно. По сравнению со всеми прошлыми технологиями это был прорыв, но оглушительным успехом назвать их было сложно. Ровно до тех пор, пока компания Crypton Future Media в 2007 году, взяв за основу движок Vocaloid 2, не выпустила то, что впоследствии совершило фурор в концепции гострайтинга: Хацуне Мику.
Секретом успеха стал не только и не столько удачный голос, сколько то, что это по сути была «поп-звезда в коробке»: при покупке вы получали не только саму программу для синтеза голоса, но ещё и возможность использовать самого персонажа по Creative Commons CC-BY-NC.
Миловидный персонаж с новым для многих голосом лёг на благодатную почву активно развивавшегося тогда культурного сегмента японского интернета. Эпоху удачнее придумать было нельзя — активный бум User-Generated Media, параллельно с переползанием от Shockwave Flash к видеоконтенту на тогда ещё совсем молодом видеохостинге Nico-Nico Douga. Но главным плюсом было даже не это — ведь в отличие от настоящей, живой поп-звезды, Мику просто физически не могла отказаться спеть то, что вы ей там понаписали.
Это породило множество споров и дебатов, а также западающих в душу песен. Среди прочих отличился, например, deadballP — запаковывая в свои песни с лютейшим джазовым вайбом абсолютно неожиданные слова. Порой настолько неожиданные, что сам Nicovideo композитора неоднократно банил за «нарушение общественного порядка». Для примера, предлагаю читателям ознакомиться с его джазовой импровизацией с лейтмотивом «вот ты выпей молоко — сиськи будут о-го-го!» :-)
Бум user generated content подкрепился выходом игры Project DIVA на PSP, куда взяли самые популярные песни, разбавив 3D-графикой для видеоклипов, до кучи добавив возможность создавать свои клипы и карты из произвольных MP3-файлов.
Таким образом, разработчики получили не только дико популярную франшизу, но и неиссякаемый поток заведомо успешного готового контента для неё.
А популярность была на внутреннем рынке просто невообразимая! Первая версия игры побила все топы продаж в свой сезон, и разлеталась как горячие пирожки.
Вот, например, было подразделение SEGA AM2 — то самое, которое подарило нам такую классику, как Shenmue, Out Run, Virtua Fighter или Daytona USA. Его на тот момент возглавлял Макото Осаки — и даже ему не удалось получить копию игры по внутренним каналам, пришлось покупать в обычном магазине.
Впрочем, игра ему нужна была не для того, чтобы отдохнуть в свободное время, а ради того, чтобы внутри своей команды изобразить порт её на движок Virtua Fighter.
И вот когда порт был уже готов, и Осаки было уже пошёл к продюсеру Уцуми Хироши с идеей сделать аркадную версию Project DIVA — другой сотрудник AM2, Ясуси Ямасита, предложил: «А почему бы нам эти наработки не использовать для создания живого концерта?»
Идея менеджменту понравилась, за каких-то два месяца кранчей они подготовили революционный ивент — Miku Fes 2009. (Обо всей хронологии — как-нибудь в другой раз :-) Концерт собрал аншлаг, начало было положено — Мику и по сей день выступает с концертами чуть ли не каждые полгода, собирая огромные залы.
(Один из самых любимых концертных треков последних лет. До сих пор не верится, что мне выпала честь слушать его прямо из первого ряда!)
А писать для неё песни, в отличие от какой-нибудь Бритни Спирс и иже с ними, могла не только лишь конкретная команда шведов, а любой человек с мало-мальски развитым слухом и каким-никаким компьютером — прямо таки народное творчество во всей красе.
Возможность создавать записи, конечно, весьма хороша, но ведь музыку зачастую принято исполнять живьём. В наше время Ямаха выпускает что-то наподобие клавитары на базе своей платформы от обычных цифровых клавиатур:

(к сожалению, на выставке разобрать и сфоткать процессор и разводку платы не разрешают :-))
Однако среди всего многообразия способов извлечения звуков из Мику и Ко. примерно 11 лет назад проскакивал такой интересный прототип, который и запал мне в душу:
Известно о нём было только то, что рабочие название технологии — eVOCALOID (Embedded Vocaloid). Впоследствии вышел пресс-релиз, в котором анонсировали микросхему с его поддержкой — YMW820-S.
Судя по даташиту и параметрам, мне думается, что это какая-то переработка старых чипов из серии Mobile Audio — из тех, что стояли в корейских телефонах с синтезом голоса для уведомлений.
Самым известным устройством на базе этого чипа был Pocket Miku — стилофон от Gakken из серии журналов «Otona no Kagaku».
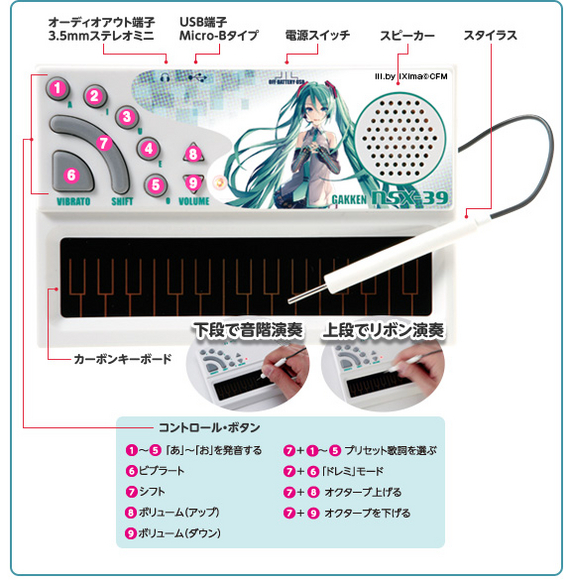
[via]
Сколько-то лет назад я покупал такой на Yahoo! Auctions, чтобы переслать другу, и стоил он очень недорого. Тогда я ещё удивился, что оно умеет работать как USB-MIDI синтезатор.
Поэтому, когда в этом году полез во всю эту MIDI-тему, то подумал — MIDI-to-USB-host адаптеры штука обыденная, а стилофон стоит копейки, можно бы что-то и сделать! Но тут меня ждал облом — ценник на эти штуки за последние пару лет вырос примерно на порядок с лишним.
Однако вдумчивое чтение пресс-релиза навело на ещё один вектор — некий шилд для ардуины eVY1 Shield, выпускавшийся компанией AIDES.
Более того, он выпускался и в виде готового устройства eVY1 BOX, но и дизайн и цена (¥27,500 = примерно $250) оставляли желать лучшего.

Зарядник от макбука словил кризис среднего возраста и решил податься в музыку
Поэтому я ухватил один из каким-то чудом оставшихся шести «сырых» модулей на амазоне безо всякой обвязки и решил скрафтить свою коробочку. И вот через пару дней у меня в руках самая дорогая микросхема в моей жизни:

С обратной стороны видим уже знакомый по Pocket Miku процессор GPEL3101A и SPI-флешку — то есть в теории оно должно суметь запустить и голос от Pocket Miku!

Быстренько раскидываем на макетке:

Для минимального включения достаточно лишь пары разъёмов и 10кОм-резистора с VBus на USB_SENSE
И да, оно поёт! Правда тихо и шумно, ведь единственный близкий к линейному выход — «наушниковый», использующий ЦАП внутри процессора GPEL, который и дудок, и жнец, и вообще — трындец, в смысле сочетает в себе полный ящик переферии от флеш-контроллеров и прочих USB до генератора вторичных напряжений питания и ЦАП/АЦП :-)
Поёт этот модуль голосом VY1, также известным как MIZKI — собственный голос от Ямахи. Что, в принципе, логично, ведь Мику для этого модуля не лицензировали. Но хотел-то я чиптюн именно с Мику!
Копание в различных слоях интернета приводит к домашней страничке некоего Hummtaro, который переделал программу-программатор от eVY1 в утилиту для сохранения и прошивки ПЗУ целиком (а я уже за прищепкой на алик бежать хотел...). Также он заботливо забыл удалить оттуда копию ПЗУ своего Pocket Miku :-)
До кучи у него же на канале есть видео, где он наоборот прошивает голос VY1 в Pocket Miku.
Поэтому качаем тулзы, дампим ПЗУ и смотрим, сходства и отличия.
Кажется, где-то тут и начинаются голосовые сэмплы:
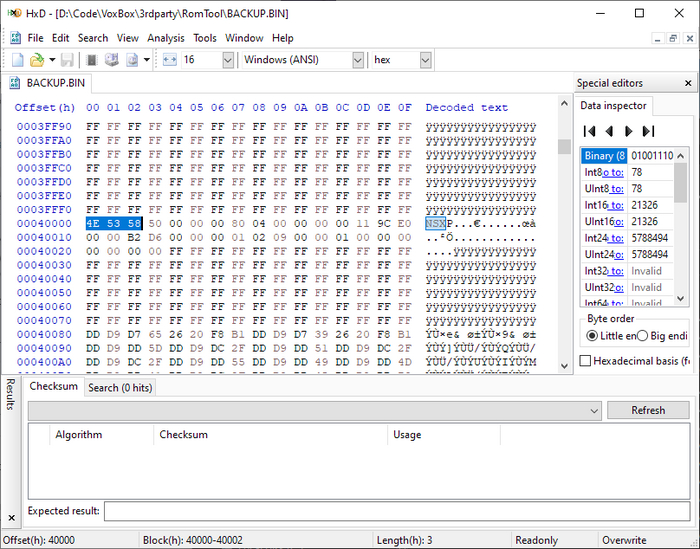
Сразу в глаза бросается большой блок данных на #40000h, который, судя по всему, и есть войсбанк. О, ну значит всё так просто! Удаляем из дампа ПЗУ родной блок данных, вставляем таковой из Pocket Miku — впритык, но поместилось. Прошиваем!
И первой композицией, которой мы насладимся в исполнении аппаратной Мику, будет 4'33" Джона Кейджа!
Пытаясь исполнить эту композицию на пианино, мой брат сломал обе ноги и руку:

Всё потому что на выходе ноль. Зеро. Ни-че-го. Ни откликов на ноты, ни даже на SysEx, который должен показать версию прошивки.
Значит, пришло время доставать драконоголовую змею и разбираться, что же там в прошивке. Но вот беда — есть бинарный блоб, который ни по какому адресу грузить непонятно, ни какая у него структура в целом неясно. Всё, что известно о процессоре — это то, что внутри ARMv7-ядро.
Эксперимента ради грузим прошивку от Pocket Miku. Ожидаемо, не работает, но на одном из пинов модуля, отмеченном как «UNUSED», появляется сигнал, подозрительно напоминающий UART. Цепляемся туда консолькой и, о чудо, там логи!
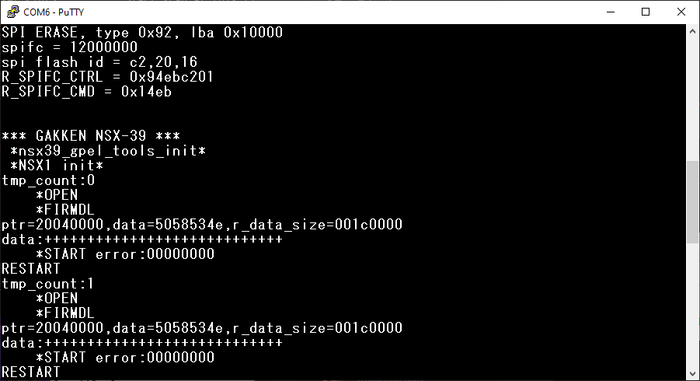
Фраза ptr=20040000 как бы намекает нам, что наш блоб прошивки в адресном пространстве процессора попадает на адрес #20000000h, но как убедиться, что это не отдельный раздел, и исполняемый код находится в том же блоке адресов?
Просто находим в блобе текст ptr=%x,data=%x,r_data_size=%x… и дописываем к нему .%08x%08x%08x %)
Всё развалилось, но не до конца:
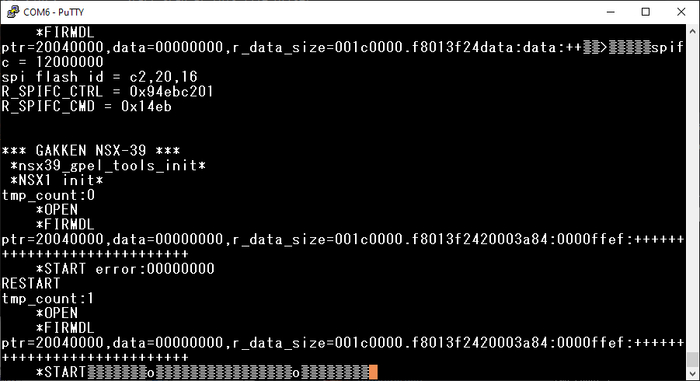
После строки логов видим ещё два 32-битных числа — первое является чем-то непонятным, а вот второе — #20003a84h — явно адрес того кода, который вызвал функцию логирования.
Как это работает? Очень просто: каждый следующий аргумент для формирования строки через printf берётся со стека, поэтому если мы возьмём оттуда больше, чем было заложено разработчиком — например, добавив ещё токенов форматирования — то напечатается то, что было на стеке дальше. В нашем случае там был и адрес возврата, который указывал на инструкцию, следующую за той, которая вызвала печать этой строки.
Грузим файл в гидру по адресу #20000000h, прыгаем на смещение #3a84h, жмём Disassemble — и всё взрывается, как попкорн в микроволновке.
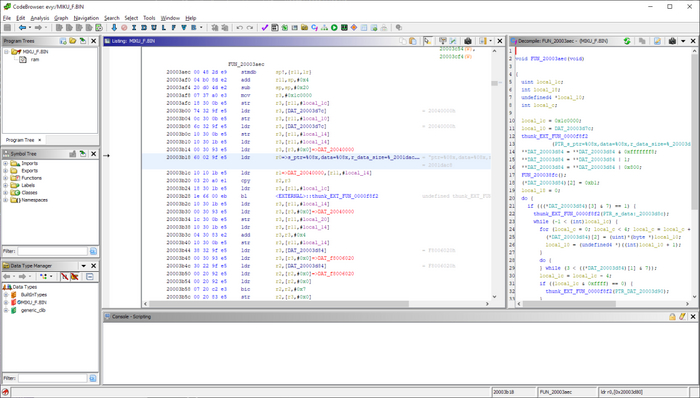
Дальше идёт полторы недели медитации над листингом с постоянными попытками перетащить куски инициализации DSP из прошивки Pocket Miku в прошивку eVY1, на случай если просто-напросто не выделяется достаточно памяти перед заливкой войсбанка в него. Но всё тщетно.
В какой-то момент от безысходности я начинаю просто рандомно обрезать войсбанк Мику и прошивать его — и замечаю, что если обрезать его по размеру родного голоса, но сохранив последние 4 байта как в оригинале, то частично всё начинает работать. Ну, пока не попытаешься воспроизвести фонему, которая в прошивку не попала :-)
Постепенно увеличивая блок данных, бинарным поиском прихожу к тому, что всё ломается на превышении прошивкой размера в #1CFE00h байт. Не, ну если бы хотя бы #1D0000h, я бы подумал, что контроллеру флешки не выделяется окно достаточного размера, а так это выглядит как какой-то глупый баг.
Беру родное ПЗУ, добавляю по подозрительному адресу 16 байт мусора — не работает, хотя ту часть памяти мы вообще читать не должны, ведь родной войсбанк существенно короче!
И почти тут же натыкаюсь на странный кусок кода, которого в прошивке Pocket Miku не было. Судя по всему, он проверяет, есть ли по этому самому подозрительному адресу какие-то данные, и если есть — инициализирует USB и вешает систему.
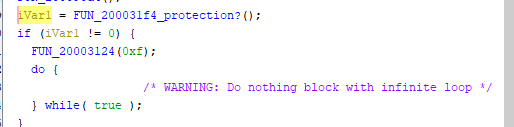
С учётом, что у нас одно ядро и один поток — где-то тут всё и закончится
Обидно, могли бы хоть рядом пасхалочку оставить :-(

Патчим эту проверку и ещё пару похожих, заложенных по разным адресам в разных функциях — и ура, играет, работает!
Во-первых, раз уж у нас теперь есть два голоса, почему бы не иметь возможность их переключать? Благо, это делается очень просто — так как линия Chip Select у флешки инвертированная (активна при лог. «0»), то достаточно лишь двух элементов ИЛИ и одного инвертера, чтобы получить схему, переключающую флешки по необходимости:
Сигнал ALT_ROM выбирает, используется основное или дополнительное ПЗУ, а остальные идут напрямую на шину самого модуля:

После переключения ПЗУ просто дёргаем RESET у модуля и он после перезагрузки начнёт петь другим голосом.
Во-вторых повесим на GPIO модуля светодиоды, раз уж они были на родном шилде. Правда не то в даташите ошибка, не то я криво читал — выходы GPIO там Active Low, поэтому в моём включении они постоянно горят и периодически гаснут, а не наоборот.
Так делать не надо, делать надо не так!

Добавляем операционник для того, чтоб привести звук хоть немного к линейному уровню, обыкновенную схему MIDI-входа как в прошлый раз (заменяя каждый логический буфер на пару инверторов, благо их у нас тут в достатке), и ардуину с экранчиком чтобы ловить SysEx'ы переключения ПЗУ и заодно отображать находящиеся в данный момент в ОЗУ фонемы.
Охапку дров, и плов готов!
Раскидываем на макетке, раунд 2:

Кажется, стоило наконец уже зарегистрироваться на JLC PCB...

Без аудиофильских конденсаторов звучать будет точно так же, но радости никакой не принесёт
В прошлый раз в корпусе осталось много свободного места, поэтому на сей раз я взял корпус на размер меньше. Конечно же, теперь его не хватило и всё пришлось сильно утрамбовывать! Также в этот раз взял вместо клавишного выключателя тумблер, так как с клавишным ощутимо проседает напряжение в зависимости от везения.

До кучи добавился USB-хаб, чтобы можно было прошивать оба чипа без разборки устройства
И вуаля, готово!

Теперь нужно написать хотя бы один MIDI-файл, чтобы на этом всём слушать. Из всего обширного списка дополнительных команд нас интересуют только несколько:
F0 43 79 09 10 07 00 aa bb cc F7: отключение звука для определённых каналов:
Биты в позициях aa, bb, cc отключают воспроизведение части каналов
Например, паттерн 7E 7F 7F оставит только первый канал, что нам и нужно для использования модуля чисто для синтеза голоса без остальных MIDI-инструментов.
F0 43 79 09 01 01 00 F7: перезагружает модуль (например, после переключения ПЗУ).
F0 43 79 09 10 04 nn F7: выставляет режим работы GPIO:
nn = 00: выключить
nn = 01: ритм-визуализатор (вокал, бочка, средний, тарелки)
nn = 02: реакция на note-on/note-off в 1-4 каналах
nn = 03: визуализатор первого канала по нотам
nn = 04: ручная установка в виде битовой маски командой F0 43 79 09 03 00 xx F7
F0 43 79 09 00 50 10 dd dd ... F7: установить список фонем (слова песни):
Где dd: байты null-терминированной CSV-строки с фонемами в ASCII
Фонемы можно найти в документации по системе команд YMW820 на 34 странице
Их можно загружать и через NRPN-сообщения, но пока что обойдёмся без этого
В остальном по эффектам и прочему модуль по большому счёту совместим с системой команд Yamaha XG.
У первого MIDI-канала нельзя сменить инструмент — именно там и находится вокал. После задания фонем через SysEx-команду, каждое Note On событие в первом канале сдвигает указатель в буфере фонем на следующую, а после последней — перематывает его на начало. Проще говоря, одна нота — один слог, и так в цикле, пока не загрузишь новую строку в память :-)
Воспользуемся этим, чтобы отлавливать команды установки фонем ардуиной и отображать скроллер со «словами» на дисплее. До кучи добавим и пару своих команд:
F0 7B 7F F7: «жёсткий» сброс чипа, на случай если тот зависнет :-)
F0 7B 00 0r F7: выбор ПЗУ голоса:
r=0 — основной, r=1 — вторичный
F0 7B 01 F7: установить текущий голос по умолчанию.
F0 7B 02 tt dd dd... 00 [xx xx xx ... 00] F7: показать сообщение на экране:
tt — время в секундах
dd dd… 00 — нуль-терминированная верхняя строка экрана
xx xx… 00 — опциональная нуль-терминированная нижняя строка экрана
После пары часов мучений (и двух-трёх месяцев спровоцированной ими прокрастинации) выяснилось, что ноты, написанные в стиле караоке, уж совсем не совпадают с количеством фонем в песне, а выравнивать их, не видя, на каком месте строка ломается, практически невозможно.
Поэтому берём поллитру, вспоминаем MFC и патчим такой замечательный редактор, как Sekaiju, на отрисовку слогов под нотами:
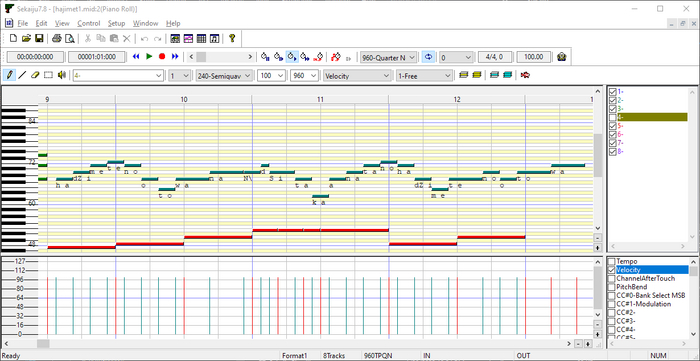
Если разваливается, то хотя бы сразу видно, где
Дорисовываем остаток совы… В смысле, дописываем аранжировку в Sekaiju, и потом доводим эффектами в Yamaha XGWorks. Попутно я докинул ещё пару партий в формате AYYMIDI (из прошлой статьи), написав их в ProTracker.
Помимо прочего, нашлось ещё несколько подводных камней:
Как и обещал производитель, поёт NSX-1 ну очень медленно. Даже в такой медленной песне есть места, где приходилось делать рокировочки таймингов десятки раз, чтобы получить более-менее вменяемый саунд. Какой-нибудь Intense Voice уж точно по битрейту не пролезет, разве что интерливом в несколько чипов через управляемый микшер :-)
По ощущениям, использование NSX-1 для всех инструментов ещё сильнее замедляет воспроизведение голоса, поэтому лучше использовать его чисто для вокала, даром что по качеству звучания его даже Yamaha MU50 уделывает с лихвой. Сделать это можно последовательностью команд:
F0 43 79 09 10 07 00 7E 7F 7F F7: NSX Channel Mute, оставляем только 1 канал.
GM Volume Ch1 = 127: выставляем громкость вокала на максимум.
XG Volume Ch1 = 0: отключаем первый канал на MU50. За счёт того, что NSX игнорирует многие XG команды на первом канале, его громкость останется на 127.
Из-за того, что Vendor ID у NSX и у серии MU совпадает, использовать тот же MU50 как RS232-MIDI интерфейс не получилось — слишком сильно задерживаются SysEx'ы задания фонем и слова начинают съезжать относительно нот.
Воспроизведение отдельных нот напоминает скорее чтение текста, чем пение, поэтому Note Off каждой ноты вокала лучше ставить чуть дальше, чем Note On следующей за ней:
Это создаёт проблемы, когда несколько слогов идут одним тоном, что нужно учитывать при написании аранжировки.
Однако, эту особенность можно использовать для реализации удвоения (っ、напр. в демо-песне для этой статьи слово わらった [waratta] чаще всего записано путём двух «наложенных» нот [wa] [ra], затем Note Off второй, и только после этого «впритык» Note On для [ta].
Ни сам чип, ни генератор команд eVo Phonetic не поддерживают удвоение согласных, поэтому единственный другой способ — продублировать слог целиком, но обрезать ноту так, чтобы чип «не успел» дойти до гласной. Иногда это работает, но часто звучит странно и упирается в проблему скорости из п. 1.
Ударения как такового в японском языке нет, но лучше всё равно добавлять экспрессии и подрезать редуцирующиеся звуки через Velocity.
Для конвертации файлов под аппаратные плееры многие пользуются программной MIDI Formatter — оказалось, она перемешивает местами каналы, поэтому для композиций написанных под NSX-1 её использовать нельзя. Впрочем, конвертировать файлы в SMF0 можно через диалог «Сохранить как» в программе XGWorks.
Не буду погружать во все остальные тонкости написания MIDI-аранжировок, ведь статья получилась и так слишком длинной — лучше дам послушать итоговый результат :-)
Первым делом, конечно же, была запрограммирована классика жанра: malo — Hajimete no Oto (The First Sound)
Казалось бы, одним треком можно было и ограничиться — голос слышно, вроде как будто даже поёт, всё хорошо. Но хотелось всё-таки выжать из конструкции побольше музыкальности, а не просто мелодию в трёх дорожках… Поэтому статья была отложена больше чем на полгода, пока я допишу аранжировку той самой песни Shabon — как дань уважения всей этой культуре, на удивление тёплоламповому вопреки всем событиям 2020 году, да и в целом, потому что душа просила что-то поинтереснее :-)
Впрочем, чип оказался всё же слишком сложным, поэтому звучания прямо один к одному не вышло.
Увы, код в этот раз слишком простой и никаких особых лайфхаков не содержит, а схема паялась в основном по наитию из головы.
Если вдруг кто-то имеет такой чип и захочет повторить конструкцию — могу, конечно, причесать всё и расшарить, но пока что вот так ¯\_(ツ)_/¯

Союз 113 Стерео - катушечный магнитофон 1 класса.
Модель в серию не пошла, выпущена в 1988 году на Брянским Электромеханическим заводе.

Предназначен для записи звука с его дальнейшим воспроизведением через внешнюю АС или наушники.
В конструкции применены: 3х моторный ЛПМ с электронным управлением и контролем за натяжением ленты.
Предусмотрена возможность; выполнения трюковых записей совмещением звука с микрофона и другого источника; "автостоп"; контроль записи-воспроизведения по стрелочным индикаторам, перегрузки - по индикаторам пиковых перегрузок; светодиодная подсветка режимов работ; авто-отключение АС при неисправности НЧ усилителя : работа магнитофона в режиме "Усилитель"; управление с помощью ПДУ "Эврика", не входящего в комплект.
Наличие раздельных магнитных головок дает возможность прослушать записанный звук во время записи.
Наличие 4 декадного счетчика расхода ленты с кнопкой сброса, позволяющей находить необходимые записи и определять расход ленты.
В состав комплекта входят 2 катушки (одна с лентой).
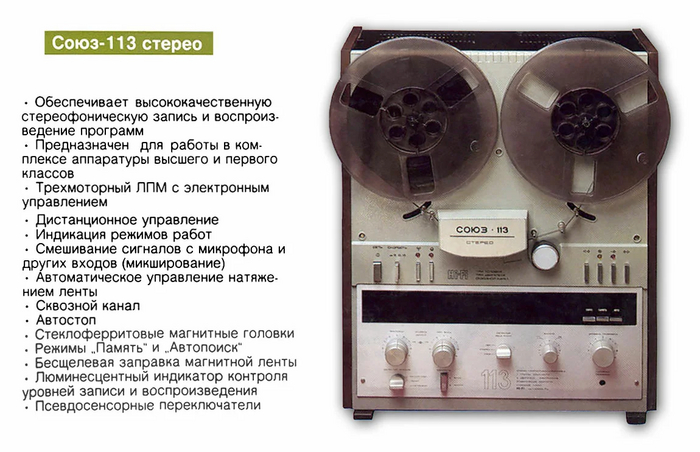
Технические данные:
- Скорость протяжки магнитной ленты - 19,05 и 9,53 см/с;
- Частоты - 25-25000 Гц;
- Коэффициент детонации - 0,15 %;
- Максимальная выходная мощность - 2x70;
- Потребляемая мощность - 90 Вт.
Размеры: 510x420x234 мм;
Вес: 20 кг.

🔥 Hi-Fi плеер xDuoo X2S
📌 Aliexpress
🏷 6065 руб
Hi-Fi плеер начального уровня в алюминиевом корпусе. В обзорах этой модели поют дифирамбы, и, за свою стоимость, плеер действительно неплох. Hi-Fi плеер штука очень нишевая, и подойдет не каждому. Это про качество звука.
Характеристики
• Кодек: Actions Semiconductor ATJ2167
• Усилитель: RICORE RT6863
• Разрешение звука: до 192 кГц/24 бита, DSD128
• Выходная мощность: 250 мВт на 32 Ома
• Диапазон частот: 20 Гц – 20 кГц
• Аккумулятор: 900 мАч (более 10 часов работы)
• Поддержка форматов: DFF, DSF, WAV, FLAC, APE, AIFF, AAC, MP3, WMA, OGG
• Дисплей: 0.96" OLED
• Входы: Type C
• Выходы: линейный 3.5 мм.
• MicroSD: до 128 Гб.
• Размеры: 64 x 40 x 15 мм
• Вес: 50 г
P.S.: Мой Телеграм-канал. Публикую ссылки на интересные скидки на электронику, иногда провожу розыгрыши. Буду рад каждому
В соответствии с неподтвержденной и не опровергнутой легендой, зам. министра среднего машиностроения СССР Александр Николаевич Усанов был заядлым меломаном. В одной из командировок за рубежом он был впечатлен OTTO SX-P1 и вернулся в СССР с двумя комплектами этой акустики.
100 АС-060 «Электроника»

Чиновник загорелся идеей подарить советским людям аналогичное устройство. Через несколько лет Московскому оборонному НПО “Торий” поставили задачу скопировать устройство, привезенное с “загнивающего запада”. Легенда эта очень похожа на множество прочих. Возможно, потому что такая история была типовой для СССР, или это всего-навсего красивый миф.
Существует мнение, что оборонным предприятиям ставили задачи по разработке подобной техники исключительно потому, что остальные были не способны производить что-то сколько-нибудь годное, однако это не совсем так. Сотрудники НПО “Торий” вспоминали, что ещё до начала горбачевской перестройки количество оборонных заказов стало уменьшаться, а бюджеты урезаться и гражданские устройства разрабатывались как раз для того, чтобы увеличить финансовую эффективность деятельности организации.
Один из образцов, переданный в “Торий”, был разобран до винтика и скрупулезно изучен. В результате, за 2 года советские инженеры разгадали и смогли повторить в условиях НПО практически все технологические процессы, использованные для создания этой акустики.
OTTO SX-P1 была скопирована почти полностью. Лишь некоторые решения были признаны не совсем рациональными. Так советский вариант 100АС-060:
не получил трехслойного композита в СЧ динамике (ограничились просто оксидом алюминия);

динамики оснащались магнитами с меньшей плотностью потока, что сказалось на чувствительности;
при одинаковой схемотехнике существенно отличалось качество элементов, использованных для фильтра;
для корпуса не стали разрабатывать специальной ДСП и ограничились имевшейся в наличии, толщину также уменьшили до 29 мм;
для подвесов диффузоров НЧ-динамиков вместо пропитанной ткани использовали поролон, что сделало их крайне недолговечными;
для ВЧ-динамика не стали использовать оксид алюминия, ограничившись пищевой фольгой высокотемпературного прессования, в связи с чем на высокой громкости в ВЧ-спектре субъективно можно различить малозаметные, но характерные металлические призвуки.

Описанный, несмотря на эти различия, результат превзошел ожидания разработчиков. Прототипы обладали недосягаемыми для советской акустики характеристиками:
Диапазон частот: 31,5 – 25000 Гц;Чувствительность: 88 дБ;Неравномерность АЧХ звукового давления в диапазоне частот 100 – 8000 Гц относительно уровня среднего звукового давления в диапазоне 50 – 20000 Гц: ± 4 дБ;Направленность под углами к акустической оси:в вертикальной плоскости ± 7°: ± 4 дБ;в горизонтальной плоскости ±25°: ± 4 дБ;Коэффициент гармоник в диапазоне частот:63 – 1000 Гц (при звуковом давлении 96 дБ): 2%;1000 – 2000 Гц (при звуковом давлении 93 дБ): 1,6%;2000 – 8000 Гц (при звуковом давлении 90 дБ): 1,4%;Сопротивление: 8 Ом;Минимальное значения импеданса: 6,4 Ом;Паспортная мощность: 100 Вт;Вес: 51 кг;Размеры (ВхШхГ): 915х455х475 мм.
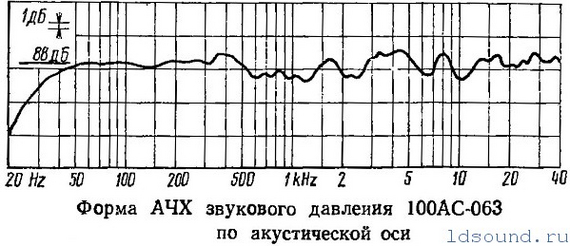
Несоблюдение некоторых технологических норм на производстве снижали верность воспроизведения и «повторяемость» у серийных образцов. Но даже не смотря на это «Электроника 100АС60» могла тягаться с любым советским аналогом и многими западными образцами.
100АС-060 удалось повторить большинство значимых конкурентных преимуществ OTTO SX-P1, в частности, пористый никель, металлические динамики и уникальное акустическое оформление, фазолинейность, превосходное демпфирование.
Сегодня рынок и интересы производителей диктуют свои условия, люди хотят дешевую акустику, а производители больше заработать, потратив меньше ресурсов. Профит. Это приводит к тому, что, казалось бы, не слишком сложные для настоящего времени, но более дорогие технологии остаются в прошлом, уступая место более утилитарным.
Источники:
Рассказ о технологиях начнем с НЧ диффузора. Он сделан не из “какого-то вспененного металла” (я не встречал такой термин нигде, кроме баек про эту акустику). На самом деле материал НЧ-диффузора — композитный, состоящий из объемно-пористого никеля и алюминиевой фольги.
Такой материал был выбран для того, чтобы совместить высокую жесткость диффузора, что позволило динамику работать в поршневом режиме и качественно новые характеристики звукопоглощения, дабы обеспечить демпфирование отраженных волн. Технология поставила точку в вопросе компромисса между демпфированием и импульсными характеристиками, решив обе задачи сразу.
Мне представляется интересным и то, как удалось получить пористый никель. Технология была следующей:
Пенополиуретан (он же поролон) кубической формы обрабатывался при помощи контролируемого взрыва в специальной ретикуляционной камере. В результате получали открытоячеистый ППУ.
Накаленной струной поролон нарезали на тонкие пластины, получая заготовки.
Заготовки обезжиривались в хмических ваннах при помощи тринатрийфосфата и промывались.
Потом эти заготовки проходили химическое осаждение солями олова и меднение.
На последнем этапе методом матового гальванического никелирования на поролон наносили никель, после чего в водородной печи выжигалась основа и одновременно производился отжиг.
структура обработанного поролона практически идентична структуре пористого металла:

После прохождения этого сложного процесса объемно-пористый никель приклеивался к алюминиевой фольгированной основе, и затем композитный материал использовался в качестве диффузора.
структура вспененного никеля:

Сапфиры в СЧ-динамике — это такой же миф, как “вспененный металл”. Нет никакого подтверждения сведениям о том, что использовались кристаллы сапфира. Кроме очень редкого и дорого декора в вычурном дизайне, сапфиры для производства акустики не использовались и не используются (нигде, никогда, совсем, хотя бы потому, что незачем).
В некоторых источниках, как например приведенном выше видео, говорится о “методе осаждения”. На самом деле этот метод применяется не для покрытия чего-либо слоем кристаллов, а для производства искусственных сапфиров и имеет название Метод Вернейля. Применение 3-х слойной диафрагмы, на 80 % состоящей из оксида алюминия, было вполне достаточно для реализации поставленных задач в СЧ-диапазоне, никаких сапфиров там просто не нужно. Это уже не говоря об астрономическом повышении себестоимости.
С твитерами тоже не все гладко. Так концентрические прорези на гофре пищалки якобы сделаны лазером. Однако, умные люди рассказали мне о том, что в 70-х в Японии, вероятно, не было 50-70 ваттных лазеров. Их в мире с подобной мощностью в то время можно было пересчитать по пальцам.
Кроме того, для создания таких прорезей лазером, требовался координатный станок для управления резкой, который не существовал ни в то время, ни 10 лет после этого. И это далеко не все проблемы, которые появились бы при попытке использовать лазеры. Иначе говоря, теоретически это было возможно, но стоило бы безумных денег и лишало смысла производство.
Ответ оказался простым. Как пишут люди, участвовавшие в копировании легенды в СССР, для прорезей использовался метод электроэрозионной обработки. Т.е. просто подавалось напряжение, достаточное для образования пробоя, и разряд в виде проводящего столба с крайне высокой температурой прожигал отверстия в алюминиевой гофре лучше любого лазера.
Конструкция АС заслуживает отдельного внимания. У колонок достаточно большой объем — 110 литров, что соответствует аксиоме: хорошая акустика — большая акустика”. Корпус обладал достаточно толстыми (30 мм) стенками и был выполнен из специального, акустически рассчитанного ДСП.
Инженеры SANYO внимательно подошли и к акустическому оформлению. Они сделали корпус фазолинейным, разделив его панелью акустического сопротивления (ПАС) на два отсека, один из которых выполняет роль резонатора, а второй (НЧ-секция) снабжен двумя фазоинверторами, отверстия которых выходят на переднюю панель.
Характерной особенностью конструкции является отсутствие турбулентных призвуков, характерных для практически всех фазоинверторных АС. Это происходит за счет небольшого хода динамика даже на высокой громкости и использования ПАС.
Помимо мифологизированных композитных материалов есть множество особенностей в конструкции динамиков. Так 30-см НЧ динамик был снабжен магнитом 1.4 кг с плотностью потока 11000 Гаус. Подвесы (в отличие от поздних советских копий) были сделаны тканевыми, гарантировало им долговечность.
Высокой оценки заслуживают фильтры, которые получили высококачественные комплектующие. Коллекционеры, владеющие этой акустикой, отмечают, что параметры элементов соответствуют номинальным значениям даже спустя 30 лет и почти никогда не требуют замены. Впоследствии оригинальная схема фильтра была полностью скопирована в советском варианте и адаптирована под отечественную элементную базу.






