

Как удалить дубликаты из списка в Python?







Показать полностью
7
В этом посте я протестирую, как ChatGPT справляется в написании и редактировании кода на Python. Пройдемся по заданиям из codewars.com по нарастающей сложности и посмотрим, как GPT сможет их решить.
1 задание:
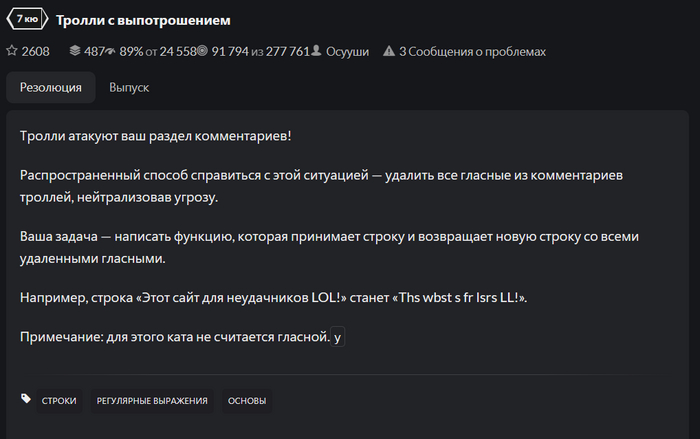
Тест первого задания успешно пройден с первой попытки. Усложним задание.
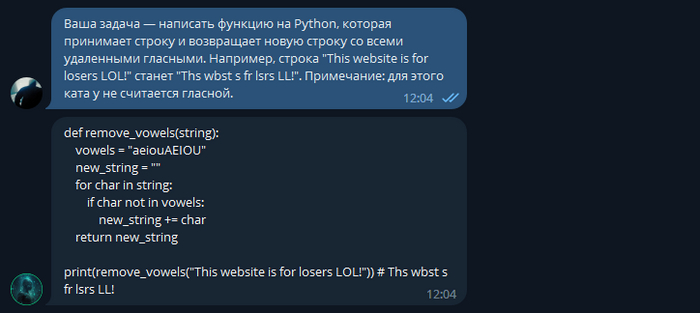
Задание 2:
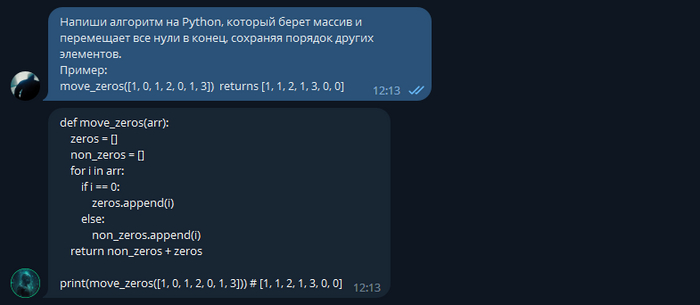
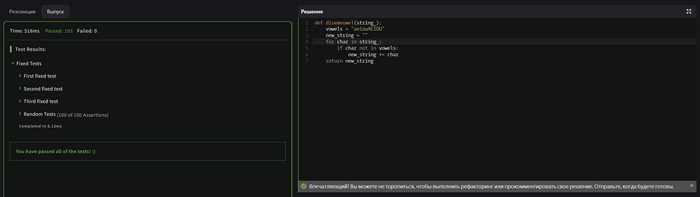
Тестирование второго задание так же прошло с первого раза.
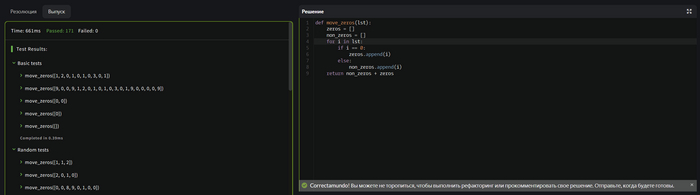
Задание 3:
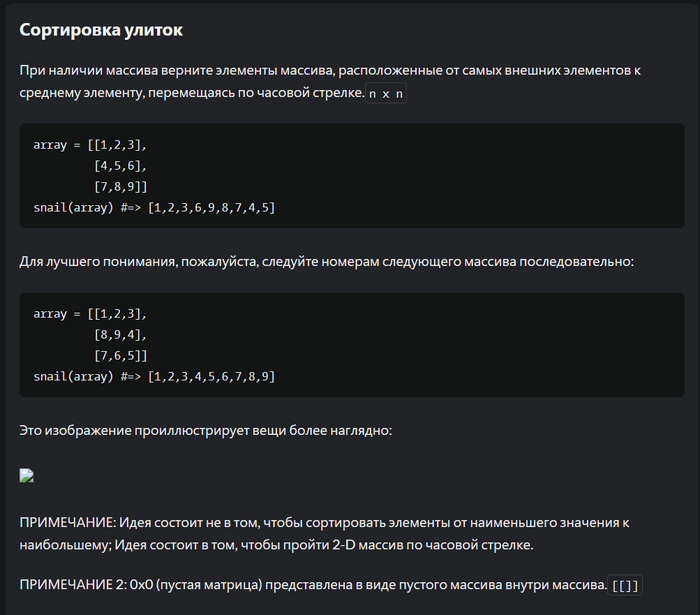
Тут уже совсем не просто как мне кажется.

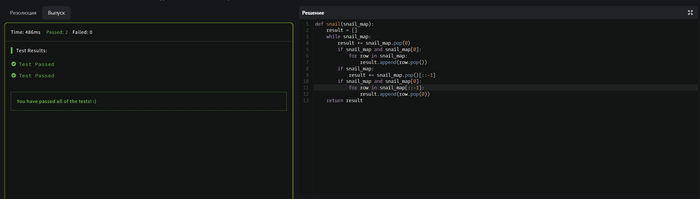
GPT справился, код успешно прошел тестирование с первого раза. Посмотрим как он справится в написании алгоритма по решению судоку.
Задание 4:
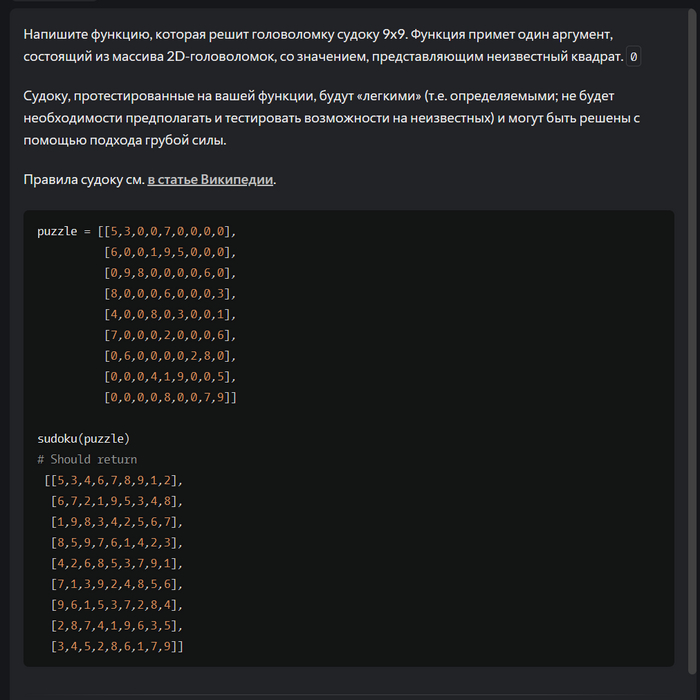
Я бы такой алгоритм несколько часов писал.
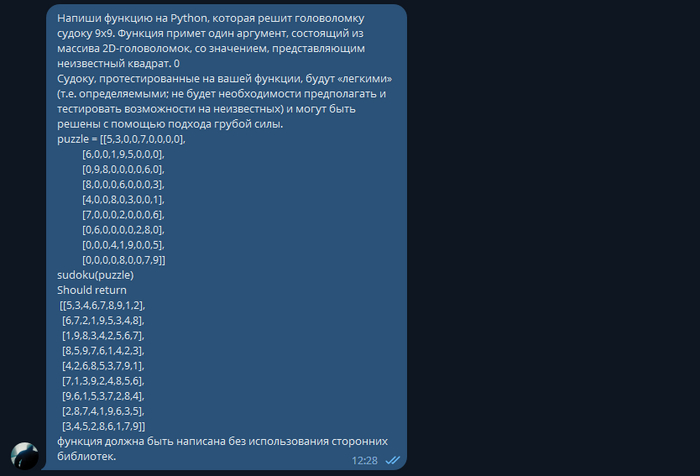
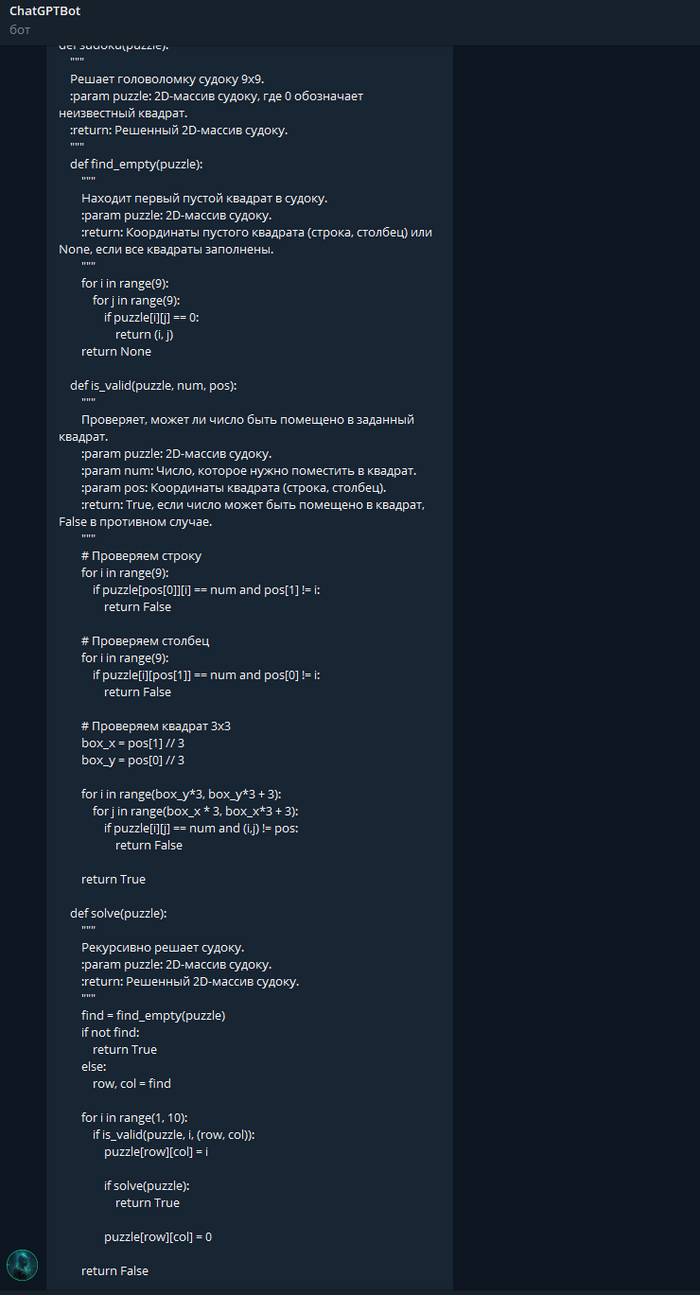
Вот такой получился код. Запустим тестирование.
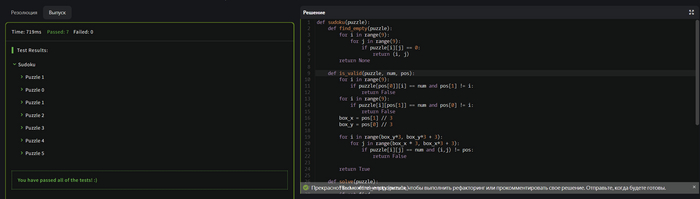
Прошел с первого раза. Впечатляет.
Перейдем к самому сложному.
Задание 5:
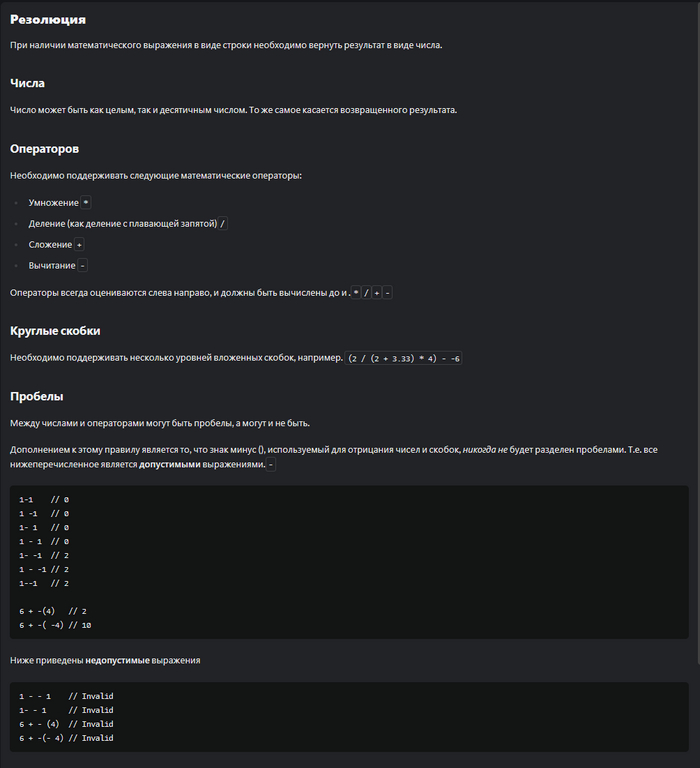
На первый взгляд задание кажется простым, но на самом деле в нем множество подводных камней, таких как порядок действий, раскрытие скобок итд. Посмотрим как решит эту задачу GPT.
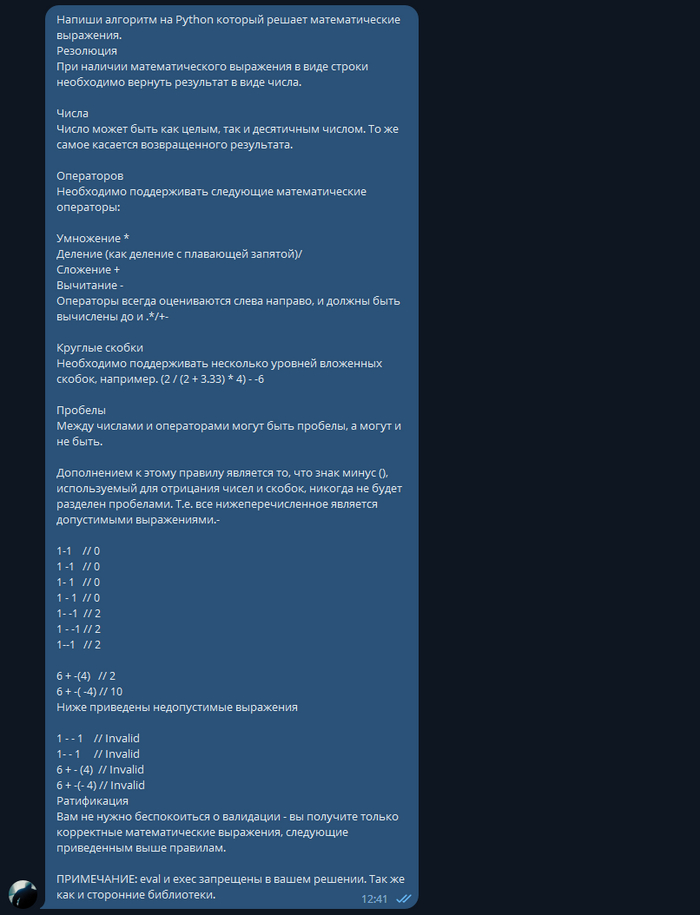
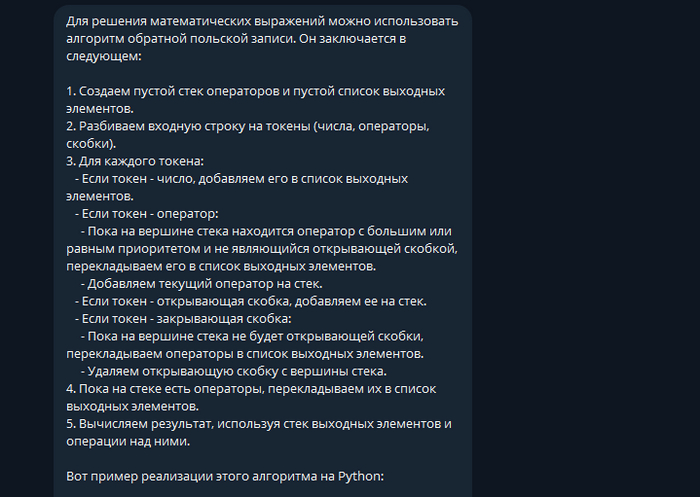
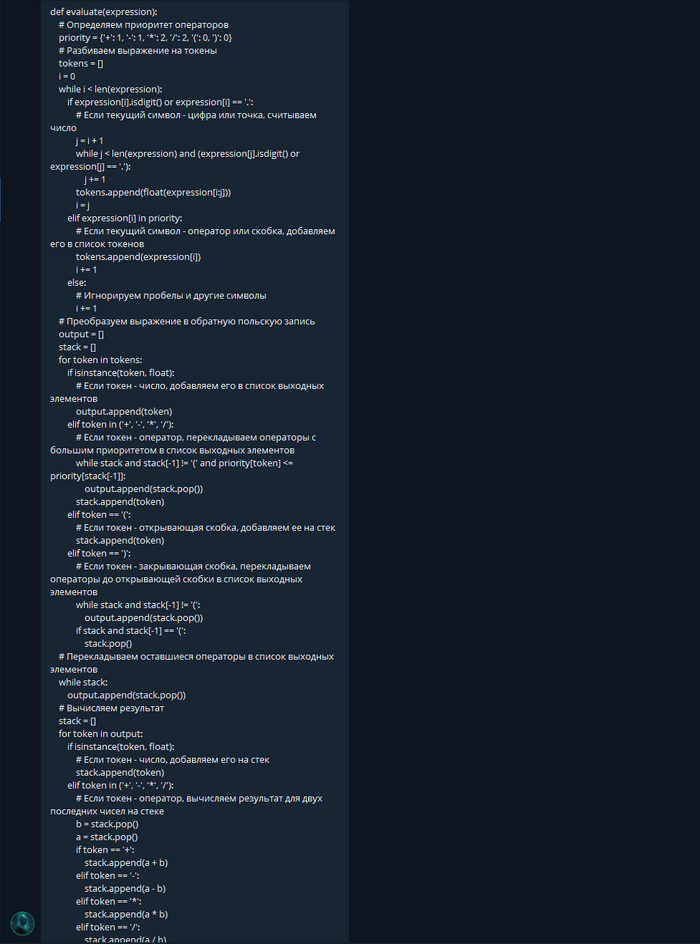
Да тут целая программа. Еще и прокомментировал все.
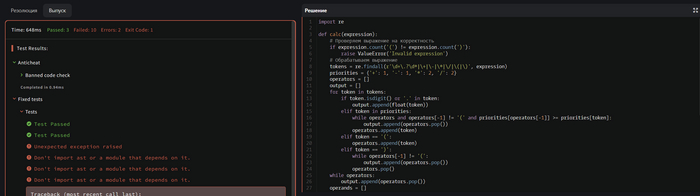
Тестирование прошло частично. Код не прошел проверку. Попробуем попросить GPT исправить полученную ошибку.
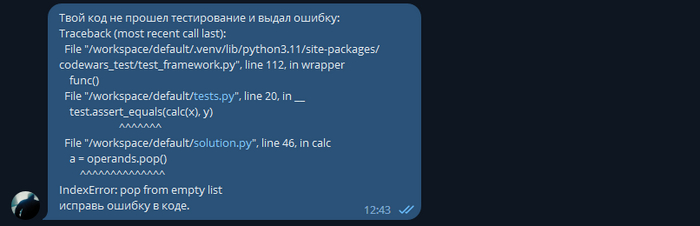
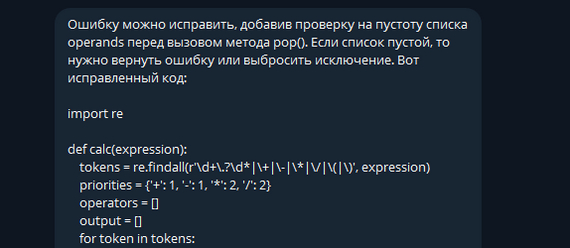
Отлично, он исправил ошибку и переписал код.
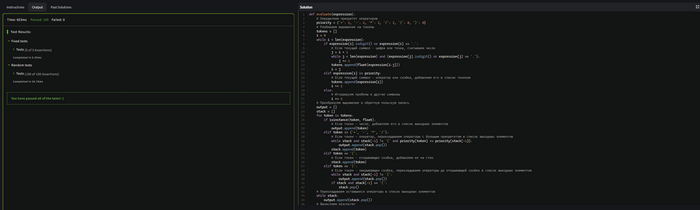
Решение прошло проверку.
Вывод:
ChatGPT отличный инструмент в написании и редактировании кода. Он без каких либо проблем справился в написании сложных алгоритмов и это на самом деле удивляет. Так же GPT отлично справляется с редактированием кода и исправлении в нем ошибок. Я часто использую его чтоб он оптимизировал мой код в разных проектах.

Ссылка на бесплатного телеграмм GPT бота - https://t.me/ChatGptT01_Bot
Сегодня мы собрали для вас топ программ, которые помогут вам стать более эффективными разработчиками. Если вы хотите улучшить свои навыки и повысить продуктивность, то эти инструменты станут отличным выбором. Давайте начнем!
1.Visual Studio Code: Легковесная и мощная интегрированная среда разработки (IDE) от Microsoft. Она поддерживает широкий спектр языков программирования, обладает множеством расширений и функций, таких как интеллектуальное автодополнение, отладка и удобное управление версиями.
2.IntelliJ IDEA: Это одна из самых популярных Java IDE, но она также поддерживает множество других языков программирования, включая Kotlin, Python, JavaScript и многое другое. IntelliJ IDEA предлагает мощные инструменты для автоматизации рутинных задач, рефакторинга кода и улучшения производительности.
3.PyCharm: Идеальное решение для разработки на Python. PyCharm обладает множеством функций, таких как интегрированная система управления версиями, отладка, анализ кода и поддержка виртуальных окружений. Он поможет вам создавать качественный код и увеличить вашу производительность.
4.Sublime Text: Легковесный текстовый редактор, известный своей скоростью и простотой использования. Sublime Text поддерживает множество языков программирования и обладает широким набором плагинов для расширения функциональности.
5.Atom: Еще один популярный текстовый редактор, созданный командой GitHub. Atom предлагает множество настраиваемых функций и плагинов, а также интеграцию с системой контроля версий Git.
6.Visual Studio: Если вы разрабатываете приложения для платформы Microsoft, то Visual Studio - ваш выбор. Он предлагает мощные инструменты для разработки приложений на различных языках, таких как C#, C++, JavaScript и другие.
Большая подборка книг по всем языкам программирования тут!
Привет всем!
Помогите разобраться с запуском программы.
Попытаюсь объяснить как можно подробнее: есть официальная программа для Windows "Lego Digital Designer" от компании LEGO. Она позволяет собирать наборы LEGO из деталей на компьютере. Программа использует базу данных с деталями, которые упакованы в отдельный файл "Assets.lif". Этот файл расположен в папке с программой. Мне нужно извлечь из этого файла детали, что бы попытаться изменить их или добавить новые (LEGO забросила развитие программы и не добавляет в базу новые вышедшие детали). На GitHub я нашёл программу, которая вроде как может открыть файл "Assets.lif", но вот какой порядок действий надо для этого сделать я не могу понять. Единственное, что я понял - это то, что нужно установить Python версию с 2.7 по 3.2 и каким то образом через командную строку запустить файлы со странички автора. Вот ссылка на страничку: https://github.com/JrMasterModelBuilder/LIF-Extractor Я почитал файл readme.md но никаких файлов для скачивания не нашёл (автор ещё упоминает файл LIFExtractor.exe, но его вообще в перечне нет). Все ссылки на файлы ведут на другие страницы сайта и там просто какой то код. Я в программировании абсолютно ничего не понимаю, поэтому прошу пошагово объяснить в какой последовательности, что скачать и установить, что бы открыть файл "Assets.lif".
Заранее спасибо.
IT — англоязычная аббревиатура, являющаяся сокращением от фразы Information Technology, что в переводе на русский язык - Информационные Технологии. Если отойти от научного трактования и сказать простыми словами, то IT - все, что связано с созданием, хранением, преобразованием, восприятием и распространением информации. IT-сфера стала очень важной частью человечества. Общение через социальные сети, получение необходимой информации в поисковике (Google/Yandex), внедрение информационной сферы в бизнес процессы, образовательные онлайн курсы, все это, и не только, существует только при помощи IT-сферы.
Еще больше про IT - https://t.me/sikey_itpython_selfdevelopment
Давайте посмотрим на 10 строк кода.
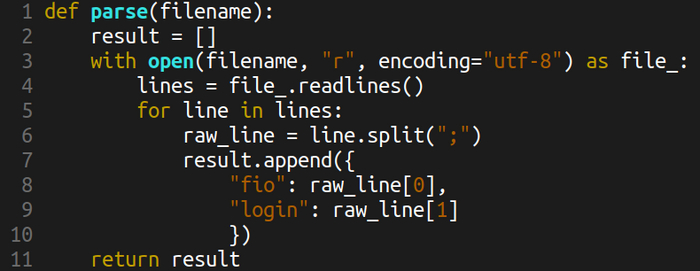
Вроде всё хорошо. Классическое открытие файла с помощью контекстного менеджера with, классическая построчная обработка. Разбиваем строку, записываем в список словарей. Всё ли по канону? Неа:
1. Смотрим документацию: readlines возвращает список всех строк файла. Значит, для большого файла может быть беда. Современный питон позволяет итерироваться сразу по объекту file_. Просто пишем
for line in file_:
2. raw_line[0] и прочие индексы — это всегда ужас. Заменяем на
fio, login = line.split(";")
Вроде то же самое, но мы сразу понимаем, что было в строке. И тут же видим следующую проблему.
3. А что, если в строке нет двоеточия, или этих двоеточий больше одного? То есть нужна обработка ошибок на исключение ValueError, если справа split вернул не два значения. Добавляем try-except.
4. Частая проблема split — это лишние пробелы. Скорее всего, потребуется strip всем переменным после split.
Итого 4 ошибки на 10 строк кода.
Теперь посмотрим на переработанный код. Docstring вырезан для краткости.
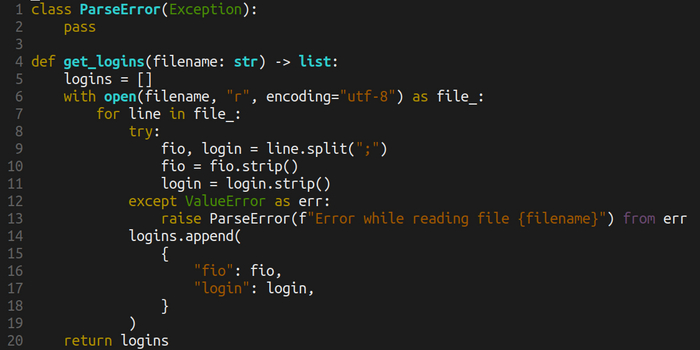
Код теперь крут:
1. Есть аннотация типов. Понятно, что на входе строка, на выходе список.
2. С файлом всё работаем через контекстный менеджер, то есть закрыть не забудем — оно само
3. Не забыли про запрет использования file как ключевого слова, поэтому file_
4. При разбиении строки по точке с запятой используем именованные переменные
5. При ошибках — кастомные исключения. Не забудьте их документировать в docstring
6. Добавлены strip для убирания лишних пробелов по краям. Опционально
7. Выходная переменная называется logins
8. При добавлении элемента в список мы на последнем элементе добавили запятую, чтобы при расширении словаря не ловить ошибку.
В общем, каждая строка на своём месте. Или всё ещё нет?
Возьмём такой входной файл
Иванов Иван;anetto
Сидоров Петр;bnetto
Петров Артём;сnetto
Для него вывод итогового logins будет выглядеть так
[{'fio': 'Иванов Иван', 'login': 'anetto'}, {'fio': 'Сидоров Петр', 'login': 'bnetto'}, {'fio': 'Петров Артём', 'login': 'сnetto'}]
Этот словарь не является удобной конструкцией, ФИО доступно как logins["fio"]. Кроме того, мы демонстрируем наружу внутреннее представление, нарушая принцип инкапсуляции. Замена словаря на список, например, заставит переписать весь код, который использует эту структуру данных. Какой может быть выход?
Создадим класс Student и превратим словарь в экземпляр класса. Можно использовать namedtuple из collections, но мы пойдём своим путём - создадим класс с двумя полями (fio, login) и двумя методами (конструктор и repr для вывода). Теперь logins будет списком экземпляров класса.
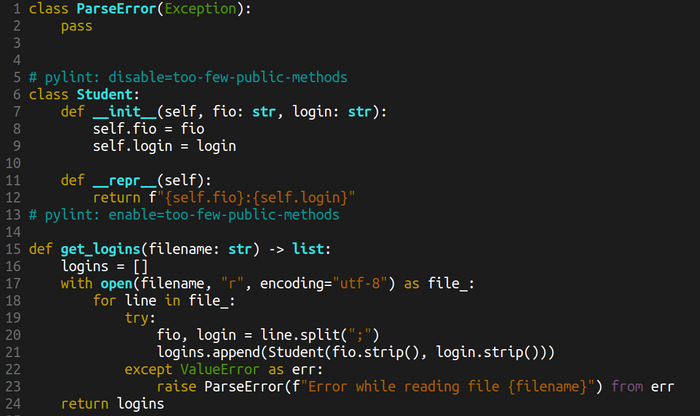
Бонусов много:
1. Мы скрываем внутреннее устройство Student. Наружу мы отдаём только пару полей, откуда мы их берём никто снаружи не знает. Вместо logins["fio"] теперь используется logins.fio.
2. Можем к Student добавлять методы. Например, вывод фамилии с инициалами в стиле Иванов И.И. — теперь это в нашей власти. В примере в repr выводится ФИО:логин. Мы полностью можем кастомизировать вывод.
3. Можем добавить новые способы создания этого студента, например, данные брать из базы данных.
Пока методов нет, можно выключать диагностику pylint, а то нам будет ругаться "у класса слишком мало публичных методов". Не забываем включить её обратно после класса.
Теперь вывод выглядит так
[Иванов Иван:anetto, Сидоров Петр:bnetto, Петров Артём:сnetto]
В телеграм-канале разбираем разные нюансы из жизни разработчика на Python и не только — python, bash, linux, тесты, командную разработку. На ютуб-канале вы можете посмотреть часовой стрим по созданию небольшого проекта на gitlab.
PS: а как лучше вставлять фрагменты кода? В цитатах нет подсветки :(
Я таксист до мозга костей. С 18 лет работаю в сфере извоза. Начинал нелегально, под чужим именем из-за отсутствия стажа. Затем легализировался и стал самозанятым.
Недавно я понял, что нужно что-то менять в своей жизни и я начал это изменение. Я решил стать программистом. Начал с изучения языка python и буду описывать "свой путь" здесь на Пикабу.
Если есть готовые помочь в этом нелегком деле советом или накинуть реальных практических задач - буду крайне благодарен. Иными словами мне нужен мастер, чьим падаваном я смог бы стать. =)

Когда Сениор смотрит код джуна
Мы постарались сделать каждый город, с которого начинается еженедельный заед в нашей новой игре, по-настоящему уникальным. Оценить можно на странице совместной игры Torero и Пикабу.
Реклама АО «Кордиант», ИНН 7601001509









