Перенесёмся в 90-е, когда CV только начинало выбираться из лабораторий. И даже тогда, как и в 1970, это всё оставалось чем-то вроде фантастики, и работать приходилось с кучей проблем.
В начале 90-х Ян Лекун, амбициозный молодой учёный в AT&T Bell Labs, разрабатывал нейросети. Он создал первую CNN для распознавания рукописных цифр. И это было круто, хотя многие его коллеги считали это странной затеей. Тогда Ян им доказал, что глубокие нейросети могут решать задачи распознавания образов.
Тем временем в MIT Такэо Канадэ из Университета Карнеги-Меллон разрабатывал алгоритмы для 3D-реконструкции объектов. В 1992 году его команда сделала первую систему, которая могла снимать и создавать 3D-модели объектов. Это открытие стало прорывом для медицины, архитектуры и робототехники.
К середине 90-х Джитендра Малик из Калифорнийского университета в Беркли проделал проделал колоссальную работу по использованию графов для разделения изображения на области. Малик автоматизировал процесс выделения объектов на изображениях, что оказалось важным для медицинской диагностики и автономного вождения.
А к концу 90-х Канаде и его команда создали алгоритм для отслеживания движущихся объектов. Это доказало, что CV может работать в реальном времени.
Тогда же Дэвид Лоу предложил алгоритм Scale-Invariant Feature Transform (SIFT), который стал ключевым для обнаружения и описания локальных особенностей изображений. Теперь SIFT — основа для многих приложений в области CV, включая робототехнику и 3D-моделирование.
В 2000-х компьютерное зрение развивалось ещё быстрее. Появились базы данных изображений, такие как Caltech 101, ставшие стандартом для тестирования алгоритмов. Исследователи начали активно использовать ML для повышения точности и скорости своих моделей.
С появлением интернета и мощного “железа” CV стало внедряться во многие сферы, в которые на тот момент позволяли технологии.
Эти годы стали прорывным временем. И это несмотря на то, какое нелегкое оно тогда было.
Эти годы были настоящей золотой эпохой для компьютерного зрения. Именно тогда были заложены основы многих современных технологий, которые мы используем сегодня.
Представьте себе: огромные компьютеры, зелёные экраны и группа умных людей, которые пытались научить машины видеть мир так же, как это делаем мы.
Одним из ключевых игроков того времени был Дэвид Марр. Он, как и Ларри Лоуренс, задался вопросом: "Как, черт возьми, мы можем научить машину распознавать объекты на изображениях?". Марр решил подойти к проблеме комплексно и предложил свою теорию обработки изображений, разделив её на три этапа.
1 этап — примитивное изображение
На первом этапе компьютер должен был научиться выделять края и контуры. Представьте, что вы смотрите на картину и сначала видите только контуры объектов. Марр и его команда разработали методы, которые помогали компьютеру находить эти границы. Таким методом стал оператор Собела, который до сих пор используется для выделения границ на изображениях.
2 этап — символическое изображение
Следующий шаг — научить компьютер распознавать, что же это за объекты. Это что-то вроде пазла: сначала вы видите отдельные кусочки, а затем пытаетесь собрать из них целое изображение. Так и появилась сегментация, когда контуры объектов соединялись и образовывали узнаваемые формы.
3 этап — интерпретация изображения
Когда объекты на изображении распознаны, компьютер должен не просто увидеть их, но и понять их взаимосвязь и контекст. Это примерно как разглядеть на фотографии людей, стол и еду, и понять, что они не просто сидят за столом, а едят вместе. А раз они едят вместе, возможно, это одна семья, родственники или друзья… И вот у нас уже вырисовывается история, которую и должен распознать компьютер!
Марр и его коллеги также разработали множество алгоритмов, которые сделали революцию в компьютерном зрении. Среди них были методы обнаружения краев, такие как оператор Канни, который до сих пор считается одним из лучших методов для выделения границ объектов. И о котором, кстати, мы поговорим завтра.
Операторы Собела и Канни, как мы писали в предыдущем посте, стали первыми мощными инструментами, сыгравшими огромную роль в развитии CV.
Почему?
Оператор Собела помогает выявить изменения яркости в изображении, что позволяет находить края объектов.
Как это работает? Допустим, у вас есть фотография, и вы хотите найти на ней границы всех объектов. Оператор Собела берет небольшие области изображения (обычно 3x3 пикселя) и проверяет, как меняется яркость в горизонтальном и вертикальном направлениях. Результат получается за счет применения специальных матриц, называемых фильтрами Собела, которые и выделяют эти изменения.
Оператор Канни — это уже более сложный инструмент для выделения границ. Разработанный Джоном Канни в 1986 году, этот метод до сих пор считается одним из лучших для выявления краев на изображениях.
Оператор Канни использует несколько этапов для достижения точного результата:
Фильтрация шума
Первым делом изображение сглаживается с помощью фильтра Гаусса, чтобы уменьшить шум.
Поиск градиентов
Затем вычисляются градиенты изображения, чтобы определить изменения яркости.
Подавление немаксимумов
Далее проверяется, какие из найденных границ являются локальными максимумами.
Двойная пороговая обработка
В конце применяется двойной порог для выделения сильных и слабых границ, а затем проводится соединение краев.
Даже сейчас операторы Собела и Канни остаются важными инструментами в арсенале ML-инженеров. Их эффективность и простота делают их незаменимыми для многих задач, от предварительной обработки изображений до анализа в реальном времени.
А примеры кода на Python для операторов Собела и Канни вы можете посмотреть по этой ссылке.
Для кого-то это умение колонки Алисы выбирать любимую музыку, для других — способность чата GPT помочь в написании курсовых работ, а для третьих — персонажи и боты в видеоиграх.
Тем не менее, современные технологии искусственного интеллекта (ИИ) активно внедряются в повседневную жизнь, в офисах и на производстве. Например, американская компания Amazon применяет искусственный интеллект для улучшения работы своих роботизированных складов, оптимизации процесса доставки заказов, персонализации рекомендаций покупателям и других задач.
Мы с подругой из Высшей школы экономики решили провести исследование по этой теме с целью улучшения рабочего процесса сотрудников.
Наш подход основан на опроснике, содержащем вопросы об использовании ИИ и уровне удовлетворенности сотрудников, чтобы выявить возможные взаимосвязи. Заполнение опросника займет всего 5 минут, и мы будем рады вашему участию)
Как обычно программисту стало скучно, и он решил покопаться в вайпе. Только не простой вейп, а с ЖК-экраном.
После реверс-инжиниринга и анализа Flash-памяти, которой здесь целый мегабайт, автор создал пару пользовательских инструментов: сплиттер и переупаковщик Flash-изображений.
А дальше пошёл полёт фантазии. Полноценный Doom сложно сюда портировать, поэтому автор решил сделать пользовательский интерфейс в стиле Windows NT 4.0 (по сути, корпоративной/профессиональной версии Windows 95). Используя несколько виртуальных машин, инструменты для создания скриншотов и записи, а также Microsoft Paint, он смог воссоздать ностальгический интерфейс Windows 95 на крошечном пространстве 80×160.
Главный экран имеет два окна: окно с батареей (удивительно отображает уровень заряда) и неактивное окно, которое отображает уровень жидкости. (1 окно на превью)
Анимация зарядки сделана на небольшом диалоговом окне Charging с анимированным курсором в виде песочных часов посередине. (2 окно на превью)
И самое красивое — вейп-анимация (парения). Выбор пал на легендарную 3D Pipes — одну из самых известных заставок эпохи Windows 95. (3 окно на превью)
В итоге получился кастомный интерфейс с двумя окнами и ретро-дизайном, вдохновлённый Windows 95. Это, конечно, не Doom, но тоже замечательно
Студенты программисты из Новосибирского государственного технического университета работают над нейросетью, которая уже определяет 8 видов отходов: пластик, стекло, бумага, бытовые отходы и др. В будущем список классов отходов планируют расширить до 30.
На первом этапе разработки такой функции в базу данных загружались изображения различных отходов, которые анализировались и сохранялись в памяти ИИ. Поначалу нейросеть путалась в большом количестве пластиковых и стеклянных форм бутылок, но на данный момент вероятность распознавания класса отходов составляет практически 100%.
Еще одной полезной опцией для пользователей является то, что нейросеть за вас будет отправлять вторсырье переработчику. В программу вы загружаете фото отходов, ИИ определит тип и объем вторсырья, заполнит за вас заявку на вывоз. Также нейросеть подберет компанию, которая принимает такие отходы, а курьер на машине доставит вторсырье на предприятие
Впервые о том, как будут развиваться технологии в будущем, заговорили ещё во 2 веке нашей эры. И этим человеком считается сирийско-греческий писатель Лукиан Самосатский, написавший роман “Правдивая история”. В романе были описаны путешествие в открытый космос на корабле и межпланетная война за колонизацию Утренней звезды (Венеры).
Вот и как тебе такое, Илон Маск?
И вот уже потом подхватили научную фантастику, как жанр, писатели Жюль Верн, Рэй Брэдбери, Дуглас Адамс и другие. Потом подключились и режиссеры: Дени Вильнев, Ридли Скотт, Джей-Джей Абрамс… Перечислять имена других создателей и восхищаться их произведениями можно долго.
Вот и сегодня мы вспомним, появление каких из современных технологий писатели, режиссеры, исследователи предсказывали чаще всего и что из этого сбылось.
Умный Дом
Как представляли раньше:
Как выглядит сейчас:
В 1980-х годах люди начали говорить о том, что дом может стать "умным" — то есть использовать компьютеры и технологии для автоматизации задач и управления. Один из первых концептов умного дома был представлен в статье Джима Систэнда в журнале "Компьютеры и графика" в 1984 году. На тот момент идея осталась просто концепцией, потому что нужные технологии ещё не были разработаны.
С появлением интернета вещей (IoT) и развитием беспроводных технологий, умные дома стали реальностью в 21 веке. Теперь умный дом — это дом, который использует сенсоры, умные устройства и интернет для автоматизации и контроля. Вы можете управлять освещением, температурой, безопасностью и другими системами в вашем доме с помощью смартфона или голосовых команд.
Такие системы обеспечивают комфорт, безопасность и разумное энергопотребление в доме, делая жизнь более удобной и качественной. Сегодня умные дома становятся всё более доступными и распространёнными, и мы видим, как они интегрируются в повседневную жизнь людей по всему миру.
Летающие автомобили
Как представляли раньше:
Как выглядит сейчас:
Идея создания авто, способных летать, была представлена в научной фантастике ещё в середине 20 века. С развитием технологий авиации и электромобилей в наше время стали разрабатываться прототипы летающих автомобилей, хотя коммерческое использование этой технологии пока остается ограниченным.
Первый прототип летающего автомобиля был разработан компанией "Terrafugia", основанной в 2006 году американским инженером Карлом Дайкстра. Их модель под названием Transition была представлена в 2009 году и была первым автомобилем, способным превращаться из автомобиля в самолёт и обратно. Этот прототип предназначался для личного использования и имел возможность взлетать и приземляться на небольших аэродромах.
Сейчас китайская компания X-Peng Motors готовит к выходу новую модель электромобиля — стильный спорткар, который сможет не только ездить по дорогам, но и летать в воздухе. Предполагаемая стоимость составит около 1 миллиона юаней, что в пересчете по текущему курсу составляет примерно 11,1 миллиона рублей.
3D-принтеры
Как представляли раньше:
Как выглядит сейчас:
История 3D-принтеров началась в 1980-х годах. Одним из первых пионеров в этой области была компания 3D Systems, основанная Чаком Халлом. Они создали первый коммерчески доступный 3D-принтер под названием "Аппарат для производства трехмерных объектов методом стереолитографии" (SLA) в 1986 году. Затем в 1992 году компания Stratasys выпустила первый прототип фьюзорной депозиционной моделировочной (FDM) технологии 3D-печати.
Сейчас 3D-принтеры применяются везде: прототипирование, производство, медицина, архитектура и даже космическая индустрия! Они позволяют создавать сложные детали, индивидуальные изделия и прототипы быстро и сравнительно недорого.
Технология 3D-печати продолжает развиваться, и с каждым годом появляются новые материалы, методы и применения, что делает ее одной из наиболее захватывающих и перспективных областей в мире инженерии и дизайна.
Нейросети и Машинное Обучение
Как представляли раньше:
Как выглядит сейчас:
Истоки нейросетей и технологий ML восходят к 1943 году, когда Уоррен Маккаллок и Уолтер Питтс представили модель искусственного нейрона, которая послужила основой для развития нейронных сетей. В 1957 году Фрэнк Розенблатт создал перцептрон, одну из первых моделей нейронной сети, способную обучаться на основе обратной связи.
Сегодня нейросети и ML находятся в центре внимания в IT-индустрии. С развитием вычислительных мощностей и больших объемов данных они стали доступны для решения широкого спектра задач: от распознавания образов и обработки естественного языка до управления автономными системами и принятия решений в реальном времени. ML-инженеры, специализирующиеся на разработке и применении алгоритмов машинного обучения, в настоящее время являются одними из самых востребованных специалистов в IT-сфере. Их работа позволяет создавать инновационные продукты и решения, которые изменят нашу жизнь и бизнес-процессы в любой отрасли.
Virtual Reality (VR)
Как представляли раньше:
Как выглядит сейчас:
Идея виртуальной реальности (VR) зародилась еще в середине 20 века. Разработки были, но самого термина не существовало. Наиболее значительный вклад в ее развитие внес Джарон Ланье в начале 1980-х годов. Он создал термин "виртуальная реальность" и разработал первые системы виртуальной реальности, такие как манипулятор DataGlove и первый коммерческий VR-шлем EyePhone. Эти устройства позволяли пользователям взаимодействовать с виртуальным миром через сенсорные и визуальные интерфейсы.
Сегодня VR-технология является актуальной благодаря своему потенциалу в различных областях. В играх это открывает новые возможности для иммерсивного гейминга и виртуального туризма. В образовании VR может быть использована для создания интерактивных учебных сред, позволяющих студентам исследовать сложные концепции в более увлекательной форме. В медицине — для тренировки хирургов, реабилитации пациентов и даже лечения фобий.
Также VR используется в архитектуре, дизайне, военной симуляции и многих других областях. Перспективы развития связаны с улучшением технологий визуализации, созданием более доступных и удобных устройств виртуальной реальности, а также расширением ее применения в новые сферы, где она может значительно улучшить опыт человека.
AI-дроны
Как представляли раньше:
Как выглядит сейчас:
Идея дронов с искусственным интеллектом присутствовала в научной фантастике и концепциях инженерии уже давно. Хотя 100 лет назад конкретно о такой технологии, как AI-дроны, не говорили, но в истории аэрокосмической индустрии существовали предпосылки для развития этой идеи. К примеру, в работах пионеров авиации, таких как Никола Тесла и Леонардо да Винчи, можно найти прототипы беспилотных летательных аппаратов.
Зато сейчас ИИ-дроны становятся все более актуальными и развитыми. Искусственный интеллект позволяет дронам принимать решения на основе анализа данных с датчиков и камер, обучаться на ходу, улучшать свою производительность и даже взаимодействовать с окружающей средой и другими дронами. Это делает их более автономными и эффективными в выполнении различных задач, таких как доставка грузов, наблюдение и патрулирование, аэрофотосъемка и даже поиск и спасение людей.
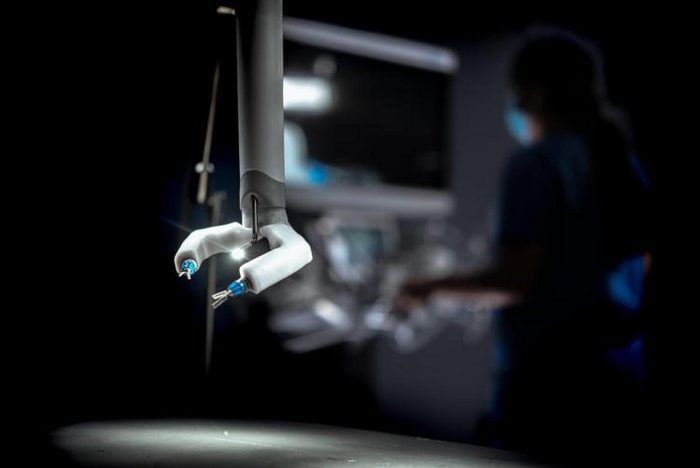
Роботы-хирурги
Как представляли раньше:
Как выглядит сейчас:
Идея использования роботов в хирургии впервые пришла в начале 20-го века, когда были разработаны первые прототипы медицинских роботов. Но их реальное внедрение началось лишь в конце 20-го — начале 21-го века благодаря совершенствованию технологий робототехники и искусственного интеллекта.
Один из первых успешных примеров роботизированной хирургии — это система Da Vinci, разработанная компанией Intuitive Surgical в начале 2000-х годов.
В 2024 году NASA планирует отправить робота-хирурга MIRA на МКС. MIRA — робот для внутренних операций, созданный в Virtual Incision совместно с Университетом Небраски. Под руководством профессора Фарритора его разрабатывали более 20 лет. В 2023 году он использовался при операции на толстой кишке через один разрез.
В ходе предстоящего полёта на орбиту инженеры хотят изучить особенности работы машины в условиях невесомости. В перспективе — через 50 или 100 лет — роботы вроде MIRA должны войти в стандартную комплектацию космического корабля на тот случай, если, к примеру, у одного из членов экипажа начнётся аппендицит.
Нейрокомпьютерные интерфейсы
Как представляли раньше:
Как выглядит сейчас:
В научной фантастике часто рассказывали о технологиях, позволяющих управлять компьютером только силой мысли. Сегодня такие интерфейсы уже существуют и используются, в основном, в медицине и исследованиях.
В 2024 году Neuralink впервые вживила в мозг человека специальное устройство, позволяющее управлять компьютером с помощью мыслей. Операция прошла успешна, ведь на данный момент первый испытуемый чувствует себя отлично, играя в игры действительно силой мысли.
В ходе исследования Neuralink применяет робота, который хирургическим путем вводит устройство интерфейса "мозг-компьютер" в участок мозга, ответственный за движения.
Домашние роботы
Как представляли раньше:
Как выглядит сейчас:
В 1960-е годы в фильмах можно было увидеть различные идеи роботов и автоматизации, но роботы-помощники в домашнем хозяйстве не были столь распространены. Некоторые фильмы того времени, такие как "Метрополис" (1927) Фрица Ланга или "Запретная планета" (1956) Фреда М. Уилкокса, изображали роботов. Правда, в ином контексте: они выполняли другие функции, не связанные с помощью в бытовых делах.
Первым коммерчески доступным роботом-помощником по дому был Unimate, созданный компанией Unimation в 1961 году. Этот робот был предназначен для выполнения задач на производстве, таких как поднятие и перемещение тяжелых предметов. Он не был таким, как современные роботы-помощники по дому, но его появление заложило основу для развития этой технологии в дальнейшем.
Сначала ты носишь свой код в коробках и борешься с коллегами за возможность сесть за клавиатуру (одну на всех), а потом ты просто говоришь машине, что делать. Или всё не так просто? Если присмотреться, то так ли много изменилось? Меняют ли что-то сегодня нейросети в работе, например, джуна или синьора?
Эта статья состоит из трех частей. Первая и вторая написаны по воспоминаниям программистов из Швеции и СССР: Марианны Эрнерфельд и Владимира Николаевича Орлова. И третья — из опыта работы с нейросетями.
Первые коды для дейтинга и железной дороги
Интервью с Марианной Эрнерфельд было опубликовано в июле 2019 в блоге ее сына. Оно более полное, особенно версия на шведском языке.
Девушка решила стать программистом в 1965 году. Тогда не было ни одного университета, обучающего программированию, но существовал годовой курс в Сольне (коммунна в Швеции), и на него могли выдать студенческий займ.
В то же время SJ (шведская государственная железнодорожная компания, на то время монополист) рекламировала годовую программу стажёрства, на которой можно было учиться работе в разных отделах компании. У SJ был компьютерный отдел, поэтому Марианна подала заявление и в эту программу, надеясь оказаться в нем.
На каждое место было по 14 кандидатов, а компания не хотела нанимать соискателей женского пола, но у Марианны (и нескольких других женщин) получилось успешно пройти все тесты.
Во время обучения студенты обучались всему: от поездов и путей и до того, как работали электрические и телефонные линии. В 1969 году SJ начинает программу внутреннего обучения программированию, и Марианна попадает в нее.
Компьютерный отдел SJ состоял примерно из 40 программистов и системных инженеров. Больше никаким другим образом научиться программированию в Швеции было нельзя — совершенно новая профессия. Некоторые из программистов раньше были машинистами локомотивов, и у большинства даже не было аттестатов о полном среднем образовании.
Обучение началось с объяснения, что такое компьютеры. Затем они прошли курсы в IBM, у которой в огромном здании в Стокгольме находилась «машина для обучения».
Одновременно на одном курсе было примерно 50-100 человек, но нас разделили, так что в каждом кабинете присутствовало по 8 студентов. Там мы смотрели на телеэкраны в передней части класса. Преподаватель и его доска транслировались на экраны из другого кабинета. У каждого преподавателя было примерно по 10 кабинетов со студентами, и каждый кабинет мог задавать вопросы при помощи микрофона, обращая на себя внимание нажатием кнопки. Это было сверхсовременно!
Сначала студенты узнали об IBM OS, а затем изучили собственный язык программирования IBM под названием PL/I. Это была более современная версия Кобола, обладавшая возможностями, которых у Кобола пока не было (но они появятся позже), например, создание таблиц и запросов.
После первого курса IBM Марианна вернулась в SJ для выполнения своих первых практических программ. Она и трое обучающихся создали программу для дейтинга — оператор вводит данные мужчин и женщин, их черты, а затем генерирует пары между ними при помощи изобретённого алгоритма. Позже программистка прошла ещё несколько курсов, например, изучала ассемблер (язык программирования).
Как же тогда кодили? Сначала рисовали блок-схемы, а затем писали карандашом код. Его передавали в отдел перфорирования, где код вбивали в перфокарты. Перфокарты состояли из 80 столбцов (72 под программу и 8 для последовательности), поэтому строка кода не могла содержать больше 72 символов.
Программисты должны были писать код чётко, чтобы работавшие на перфораторе женщины могли его читать. Спустя несколько лет работы в SJ им выделили человека для чтения кода. В остальном они по большей мере перфорировали карты данных: отчёты об отработанных часах в SJ, пробег каждого железнодорожного вагона (чтобы их можно было отправлять на обслуживание). Перфоратор выглядел как обычная печатная машинка, пробивающая отверстия с картах. Кроме того, над каждым столбцом она печатала обычным текстом букву.
«А ещё мы носили на перфокартах пирожные, так что они были довольно удобны»
Когда Марианна только начинала работу, программы были маленькими, но позже каждая могла занимать несколько коробок длиной по метру. Одна строка кода превращалась в одну перфокарту. Отдел перфорирования возвращал готовую программу (тысячи карт). Кроме того, приходилось создавать «контрольные карты», в которых кодировалось: должны ли перфокарты компилироваться или исполняться, на каком языке они были написаны и т.д. Контрольные карты имели собственный цвет. Первая карта была рабочей картой с именем на ней, чтобы отдел знал, кому их возвращать.
Еще карты возвращались вместе с «пижамной бумагой», содержащей списки кодов ошибок и номеров строк. У сотрудников был доступ к паре дыроколов, они могли вносить небольшие изменения самостоятельно.
Пижамная бумага с ошибками
Затем создавали тестовые файлы и смотрели, даёт ли программа ожидаемый результат. Если нет, то начинали «настольное тестирование» (с карандашом и бумагой), пытаясь разобраться, в чём ошибка. Для создания правильной программы требовалось много времени.
В машинном зале было примерно 10 операторов машин. Все они носили белые халаты, работали с ленточными накопителями, дисками и вставляли перфокарты. На входе висела табличка «Магазин закрыт», а программистам редко разрешалось посещать огромный машинный зал. Первые машины (IBM 1400) занимали 10-20 квадратных метров, а более новые были размером с холодильник.
Изначально у железнодорожной компании имелась IBM 360, а также более старые машины. Позже они получили IBM 370.
Ближе к концу 70-х появились терминалы. Все работали в общем зале с терминалами. Когда нужно было внести изменения в программу, приходилось сражаться за терминальное время. В компании пользовались жёлто-коричневыми терминалами Alfaskop. До самого увольнения из SJ в 1979 году у Марианны не было персонального терминала.
Alfaskop
Системные инженеры в основном работали со спецификациями, входными и выходными данными программ. Программисты были решателями задач, рисовали блок-схемы и думали, как выполнять задачи.
Какие коды писали? Например, онлайн-бронирование SG, работавшее 24/7. Это было современно по тем временам, а система целиком была написана на ассемблере. Благодаря этому SJ выделялась — ни одна другая компания в Швеции к этому и близко не стояла. Программисты создавали коды, а после завершения и тестирования отдавали их другим отделам. Их поддержкой занимались другие, отдел Марианны только писал новые.
В блоге Владимира Николаевича Орлова есть порядка 7 частей (и несколько отступлений) его автобиографичного рассказа о советском программировании. Дальше наш пересказ одного отрывка.
В 1976 году Владимир служил в Латвийском военном городе Вентспилс-8. Он был в числе первых, кто прошёл полный курс обучения по специальности «военный инженер-программист». Подготовка специалистов по ЭВМ и программированию велась с 1956 года.
Учились тогда прикладному программированию. Из студентов готовили IT-специалистов широкого профиля со знанием теории построения операционных систем, систем программирования, информационно-поисковых систем.
Обучение программированию начиналось с посещения машинного зала ЭВМ М-220.
За пультом ЭВМ М-220 старший лейтенант.
В те годы неотъемлемым атрибутом любого машинного зала (а для размещения ЭВМ М-220 требовалось не менее 100 квадратных метра) было присутствие в нем на стене портрета Джоконды (вспомните кинофильм «Служебный роман»):
Тогда Владимиру и другим обучающимся показали, как рождается портрет. В устройство для чтения перфокарт поставили колоду перфокарт, набрали команду на пульте управления ЭВМ и на АЦПУ стал появляться портрет Джоконды.
«Я окончательно понял, что поступил правильно, выбрав специальность программиста, а ЭВМ М-220 на ближайшие 7 лет стала моей рабочей лошадкой»
Это не означает, что Орлов не работал на других ЭВМ : к концу обучения в академии он был «на ты» с М-220, Минск-32, ЭВМ «Весна», СПЭМ-80, а также имел навыки работы на ЕС ЭВМ. Но главной машиной до 1979 года в Советском Союзе оставалась ЭВМ М-220.
Как тогда кодили? Программирование на М-220 серьёзно отличается от сегодняшнего программирования. Нужно обязательно знать машинные команды. Хотя бы те, которые позволяли загрузить программу с перфокарт, магнитных ленты и барабана в память машины и передать ей управление, чтобы она начала выполняться.
После Вентспилса я на всю жизнь запомнил команды ЭВМ М-220 для работы с внешними устройствами – 50 и 70. Все программы, которые я в итоге напишу в Вентспилсе, будут написаны в машинных кодах, никаких языков высокого уровня или даже автокода.
Одним из рабочих заданий была автоматизация кассы взаимопомощи.
Сначала информация по новым членам кассы взаимопомощи записывалась на бумажные бланки. С бланков данные набивались на перфокарты. Затем перфокарты вручную сортировались. Запускалась небольшая программа, которая данные с перфокарт записывала на магнитную ленту. После всего этого начинался процесс добавления новых членов в базу данных кассы взаимопомощи.
Для этого в лентопротяжки ставились три бобины, одна с новыми данными, вторая с данными, подготовленными ранее или текущей базой данных, и чистая, на которую переносилась информация, получаемая слиянием.
Неочевидное обучение программированию
Спустя 55 лет развития сферы программирования писать код можно даже не своими пальцами. Не работать на громоздких и медленных машинах, не запоминать команды. Можно и читерить: искусственный интеллект уже хорошо справляется со многими задачами. Вот модель GPT 4 — стандарт по умолчанию для создания контента, анализа, машинного перевода и, конечно, для решения задач.
GPT 4 можно использовать и для обучения программированию. Скормите чату условие своей задачки, а на выходе будет код программы на требуемом языке, часто еще и с объяснениями основных моментов в коде. Так можно создать себе персонального учителя.
Как можно использовать нейронку? Например, отправить в чат фрагмент или готовый код программы и промпт к нему:
расскажи, какую задачу решает код
объясни код по строкам
добавь комментарии в код
найди в коде синтаксические ошибки
найди в коде логические ошибки
оптимизируй код (уменьши расход памяти или ускорь выполнение)
уменьши сложность алгоритма
Не всегда, правда, код без глюков, а решения полные :( Главная проблема ИИ типа ChatGPT в том, что многие считают их универсальными. Из-за этого нередко либо результат не устраивает (завышенные ожидания), либо понимаешь, что проще и быстрее сделать самому.Чтобы апгрейднуть результат и сэкономить время, достаточно сделать очевидное: для каждой задачи использовать профильную нейронку.
В рамках API ограничения по получению ответа у GPT-4 составляет 4096 токенов, а у Claude 3 Opus около 128к токенов, в связи с этим и ответ получаемый от Claude 3 Opus будет больше. Плюс модели Claude 3 показывают себя более вдумчивыми.
Так мы справились с громоздкой задачей по программированию, сохранив себе пару часов для отдыха или другой задачи. Возьмем за пример задание из типовых курсов по программированию: написать мобильное приложение для сети клиник.
Возьмем эту задачу и декомпозируем ее. Разбить на более легкие шаги — это заведомо хорошая стратегия, чтобы нейронка не разваливалась и не отвлекалась.
У нас вышли такие шаги:
Составь функциональные требования, основанные на следующем описании: [полное описание из задания].
Теперь распиши полученные функциональные требования в виде User stories.
На основе полученных данных (Функциональных требований и user stories) составь сущности и атрибуты к ним с выделением первичных ключей.
Теперь на основе полученной информации составь plantUML.
Теперь составь BPMN TO-BE в виде кода.
Теперь составь полную спецификацию требований к этому ПО.
Теперь распиши каждый пункт спецификации подробнее, мне нужна готовая заполненная спецификация.
Составь документацию API с описанием всех методов системы на базе swagger.
И на все у Opus был ответ. Теперь проверим, исправим баги, если они есть — и готово! Конечно, не все так легко, как здесь читается, но работа над этими 8 пунктами своими руками была бы дольше в много-много раз.