
Мультимодальный RAG: когда контекста недостаточно, чтобы понять документ
Автор: Денис Аветисян
Все давно устали от того, что извлечение осмысленных знаний из сложных, неструктурированных документов остаётся непосильной задачей, тормозящей доступ к информации. Но, когда мы уже думали, что знаем всё о методах улучшения понимания документов, появляется "Scaling Beyond Context: A Survey of Multimodal Retrieval-Augmented Generation for Document Understanding", и внезапно оказывается, что дело не только в масштабировании языковых моделей, но и в умении интегрировать знания из разных источников. И главный вопрос: действительно ли ключ к настоящему пониманию документов лежит в сложном симбиозе текста, изображений и таблиц, или это очередная технологическая иллюзия, приправленная модными словечками?
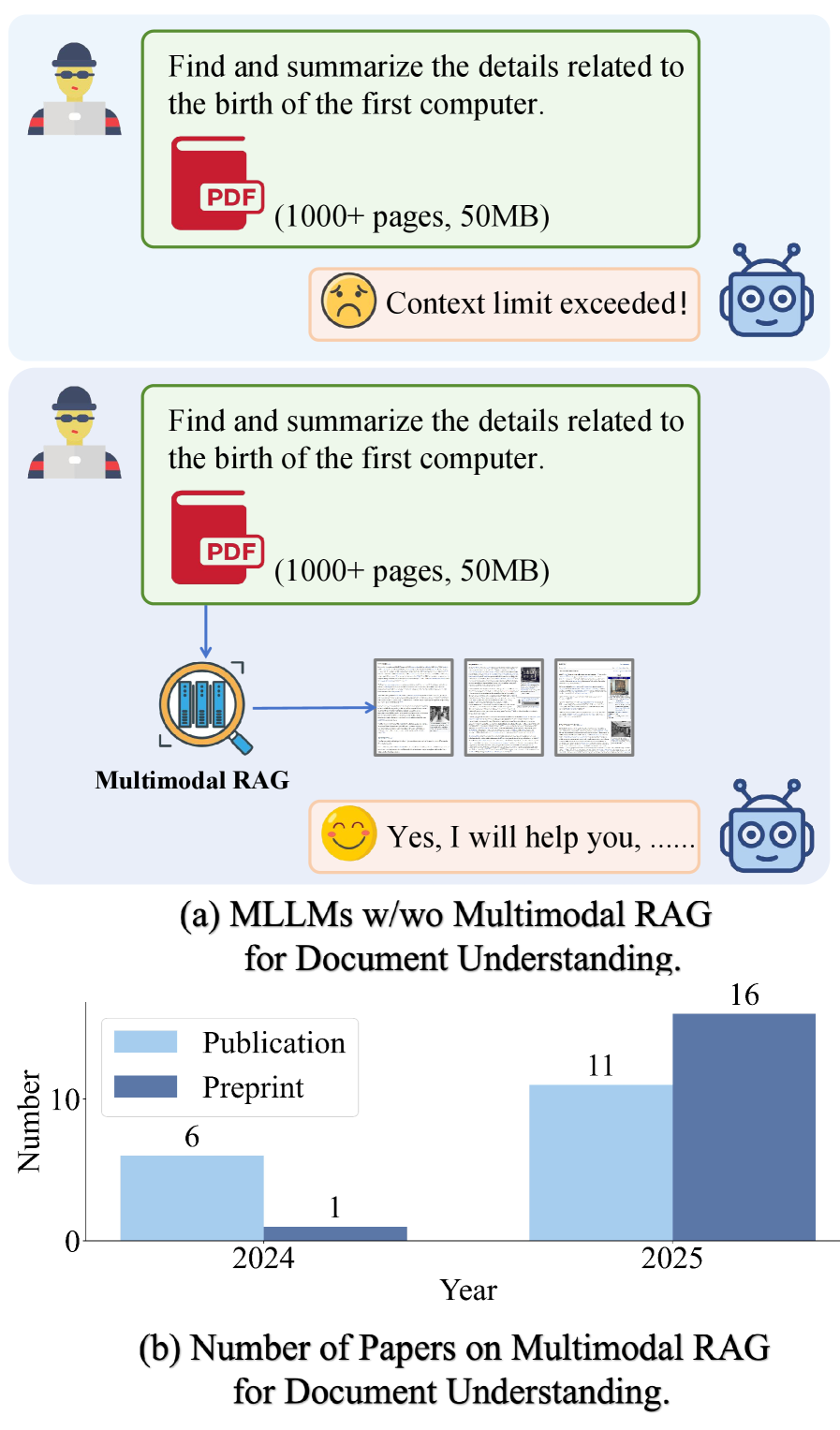
Мультимодальный RAG – пока ещё элегантная теория понимания документов, но уже сейчас видно, как растёт интерес к ней. Судя по количеству публикаций, скоро станет понятно, где эта технология действительно работает, а где – нет.
Пазл из Обрывков: О Челленджах Понимания Документов
Традиционные методы извлечения знаний из документов, особенно сложных и неструктурированных, неизменно наталкиваются на ограничения. Они как попытки собрать пазл из обрывков, где большая часть деталей утеряна. Знания, запертые в этих документах, остаются недоступными, а потенциал – нереализованным. Это как построить дорогу к сокровищам, но потерять карту.
Большие языковые модели (LLM), несомненно, впечатляют своей мощью, но и они не лишены недостатков. Их способность к интерпретации ограничена отсутствием надлежащего контекста, необходимого для точного и надёжного понимания. Они как блестящие инструменты в руках умельца, но без понимания принципов работы.
Простое увеличение масштаба LLM не решает проблему. Это как пытаться поднять тяжёлый груз, увеличивая количество рук, но не улучшая технику. Требуется более тонкий подход к интеграции знаний, чтобы действительно понять содержание документа. Недостаточно просто обработать текст – нужно понять его смысл, контекст и взаимосвязи.
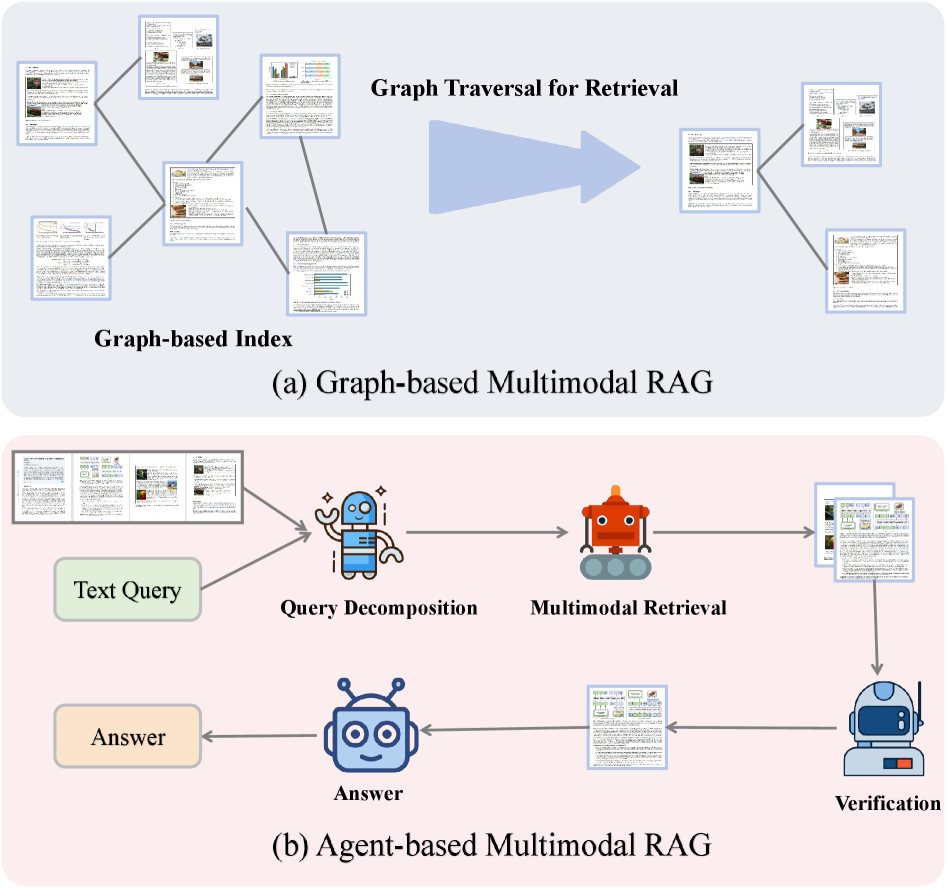
Гибридные улучшения для мультимодального RAG.(a) На основе графов: документы/элементы формируют индекс графа, и поиск осуществляется путём обхода графа для обнаружения соответствующих окрестностей.
Необходим более глубокий анализ, учитывающий структуру документа, взаимосвязи между его элементами и контекст, в котором он был создан. Это не просто задача обработки естественного языка, а комплексная проблема, требующая междисциплинарного подхода. Иначе говоря, мы не просто автоматизируем чтение – мы пытаемся воссоздать процесс понимания.
Иногда кажется, что все эти новые технологии – лишь способ усложнить и без того сложную задачу. Но, возможно, именно в этой сложности и кроется ключ к решению. В конце концов, идеальных решений не бывает. Всегда приходится идти на компромисс. И, как показывает опыт, архитектура – это не схема, а компромисс, переживший деплой.
RAG: Шпаргалка для LLM или Реальный Прорыв?
Идея Retrieval-Augmented Generation (RAG) – это, конечно, не откровение. Просто способ заставить большие языковые модели (LLM) меньше гадать и больше опираться на проверенные факты. Вместо того, чтобы хранить все знания внутри параметров модели (что, как мы все знаем, быстро становится невозможным), RAG позволяет LLM "подглядывать" в внешние базы данных. Это как дать студенту шпаргалку – снижает зависимость от памяти, но повышает шанс выдать правильный ответ. В сущности, RAG дополняет параметрическую память LLM, предоставляя доступ к актуальной информации и улучшая точность и фактическую согласованность ответов.
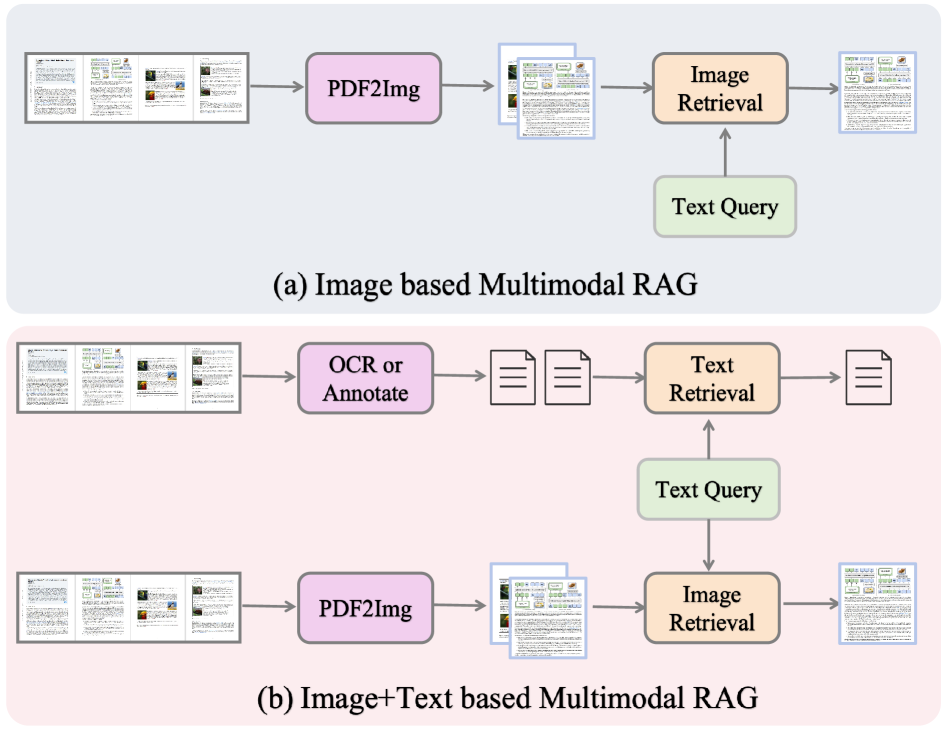
(a) поиск на основе изображений извлекает информацию исключительно из изображений страниц, предлагая эффективность, но ограниченные текстовые детали; (b) поиск на основе изображений и текста интегрирует OCR/аннотации с визуальными функциями
Однако, если копнуть глубже, то стандартные подходы RAG часто рассматривают документы как монолитные блоки текста. Игнорируется потенциал мультимодальных данных – таблиц, графиков, изображений. Это как пытаться понять финансовый отчет, читая только сплошной текст – можно упустить важные детали. Авторы, конечно, уверяют, что это "революционный подход", но мы-то знаем, что всё уже было в 2012-м, только называлось иначе. Важно понимать, что простое добавление OCR – это лишь первый шаг. Нужно научиться извлекать смысл из структуры документа, а это, поверьте, задача нетривиальная.
В итоге, задача состоит не только в том, чтобы найти релевантную информацию, но и в том, чтобы представить её в формате, понятном для LLM. Иначе, всё это превращается в ещё один источник шума. Если тесты зелёные – значит, они ничего не проверяют. Нужно искать способы повысить эффективность и точность мультимодального поиска, и тогда, возможно, мы сможем приблизиться к действительно разумной системе.
Мультимодальный RAG: Больше, чем Просто Объединение Текста и Изображений?
Разумеется, авторы утверждают, что мультимодальный RAG открывает новые горизонты в понимании документов. Что ж, посмотрим, как долго продлится этот оптимизм, прежде чем столкнёмся с реальными ограничениями масштабируемости. В целом, идея проста: объединить текст и изображения, чтобы получить более полное представление о содержании и структуре документа. Звучит красиво, но всегда есть нюансы.
Они описывают, как кодирование изображений и текста создаёт единые векторные представления, улавливающие связи между визуальными и текстовыми элементами. Единые векторные представления… Как будто это решит все проблемы. В реальности, получение этих представлений требует ресурсов, а поддержка их актуальности – постоянных усилий. Но, ладно, предположим, что это работает.
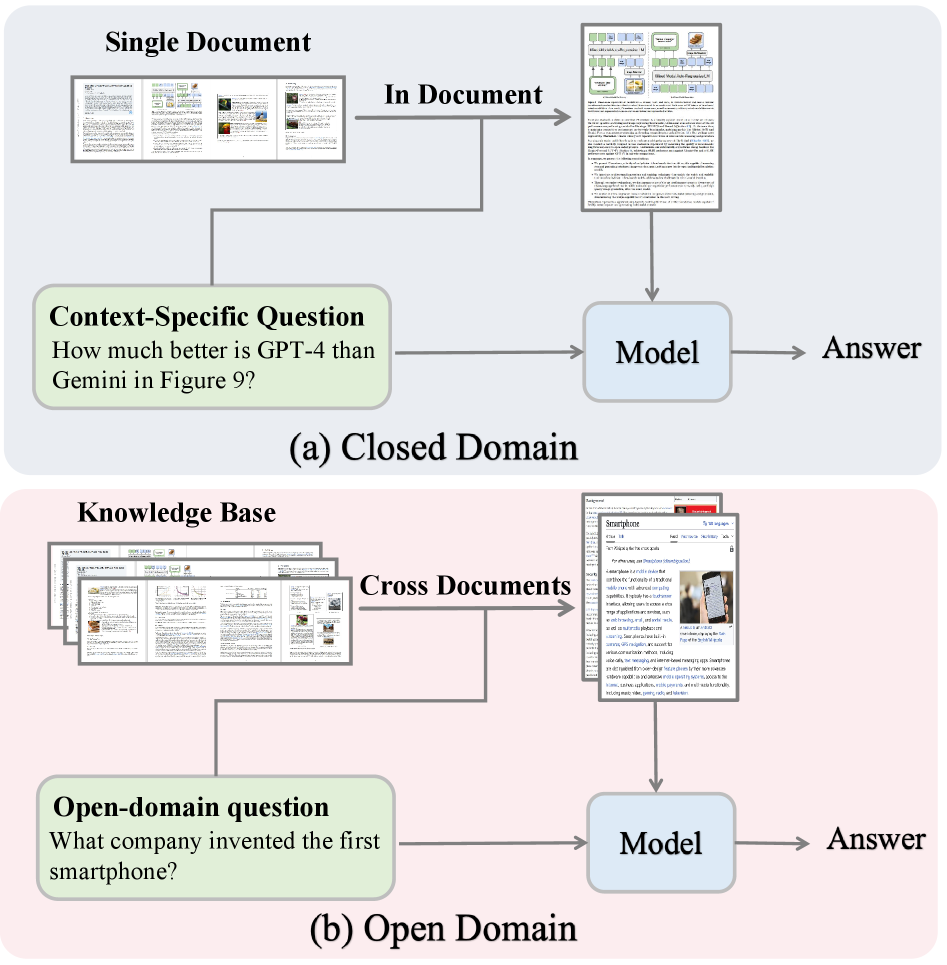
(a) В закрытом домене модель использует извлечение документов из одного документа для ответа на вопросы (b) В открытом домене модель полагается на извлечение документов из нескольких документов для ответа на вопросы с открытым концом
Авторы утверждают, что такой подход значительно улучшает производительность в задачах визуального вопросно-ответного анализа (VQA) и комплексного анализа документов. VQA… ещё один модный термин, который, вероятно, станет бесполезным через год. Тем не менее, если это действительно работает, это может быть полезно, хотя бы временно. Они приводят примеры, как их система может отвечать на вопросы о сложных диаграммах и таблицах, которые раньше были недоступны для автоматического анализа. Обычно, такие системы либо терпят неудачу, либо выдают нелепые ответы. Но, видимо, в этот раз что-то получилось.
В общем, они описывают некий “прорыв”, который, по их мнению, изменит мир. Посмотрим, как это всё будет выглядеть в реальности. В любом случае, это ещё один шаг на пути к автоматизации анализа документов. И, если честно, это хоть какая-то надежда в этом потоке бесполезных инноваций.
Уточнение и Расширение Мультимодального RAG: Теория или Практика?
Развернутые исследования в области Multimodal RAG не остались без внимания к практической применимости. Методы, такие как Closed-Domain RAG и Open-Domain RAG, расширяют возможности применения к как отдельным документам, так и к крупным корпусам. Это, конечно, не решает всех проблем, но позволяет хотя бы попытаться выжать хоть какую-то пользу из существующих данных.
Дальнейшее развитие не обошлось без попыток усложнить архитектуру. Graph-Based Retrieval и Agent-Based RAG призваны улучшить процесс поиска, обеспечивая более эффективное обнаружение знаний и рассуждения. В теории – да, звучит неплохо. На практике же, часто это приводит лишь к увеличению кодовой базы и усложнению отладки. Но, как говорится, попытка не пытка.
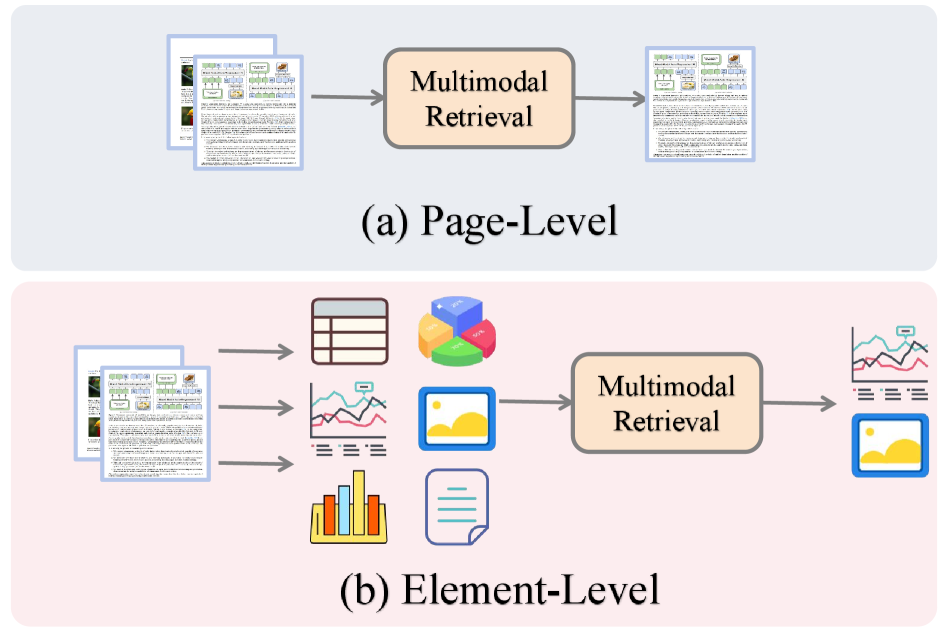
(a) Уровень страницы: целые страницы кодируются и ранжируются как единые целые. (b) Уровень элемента: страницы декомпозируются на таблицы, диаграммы, изображения и текстовые блоки
Однако, реальная проблема, как обычно, кроется в деталях. Решение таких задач, как обработка длинных документов, снижение вероятности галлюцинаций и обеспечение детального представления документов, остаются критически важными для развертывания надежных и эффективных систем RAG. Каждая "революционная" технология рано или поздно становится техническим долгом. Мы не нуждаемся в большем количестве микросервисов — нам нужно меньше иллюзий. В конечном счете, необходимо помнить, что даже самая изящная архитектура станет анекдотом, если её не поддерживать и не адаптировать к реальным условиям эксплуатации.
Попытки решить эти проблемы, безусловно, важны, но не стоит забывать о здравом смысле. В конечном итоге, успех любой системы зависит не от сложности её архитектуры, а от её способности решать реальные задачи в реальных условиях. И, как обычно, самое сложное – это не написать код, а заставить его работать в продакшене.
Вся эта история с Multimodal RAG напоминает старый анекдот. Мы строим сложные системы, чтобы LLM "помнили" больше, но забываем, что продакшен всегда найдёт способ всё сломать. Как говорил Блез Паскаль: “Все великие дела требуют времени”. Только в нашем случае, “время” – это скорость, с которой появляется новый техдолг, связанный с обслуживанием этих самых “великих” систем для визуального понимания документов. Мы не просто извлекаем информацию, мы создаём новую сложность, которую потом будем героически рефакторить… то есть, реанимировать надежду.
Что дальше?
Итак, мы построили красивые мосты из LLM и визуальных документов. И что? Каждая «революционная» техника RAG рано или поздно столкнётся с реальностью продакшена. Бумажные сканеры будут давать косяки, OCR — галлюцинировать, а пользователи — задавать вопросы, которые эти системы просто не смогут обработать. Это не критика, это… закономерность. Всё, что можно задеплоить — однажды упадёт.
Настоящий вызов – не в увеличении точности на benchmark-ах, а в создании систем, которые изящно обрабатывают неопределенность. Нужны методы, позволяющие моделям не просто "находить" информацию, а понимать, что они её не знают, и уметь корректно отвечать: «Извините, я не уверен». И, конечно, любая абстракция умирает от продакшена, поэтому нас ждёт бесконечная гонка за устойчивостью к шуму и искажениям реальных документов.
Агентские системы и графы знаний – это, конечно, интересно, но давайте признаем: это просто попытки усложнить проблему, чтобы хоть как-то её контролировать. В конечном счёте, успех будет зависеть от того, насколько хорошо мы сможем смириться с несовершенством и научим модели красиво умирать. Но зато красиво умирает.
Искусственный интеллект
4.8K постов11.4K подписчик
Правила сообщества
ВНИМАНИЕ! В сообществе запрещена публикация генеративного контента без детального описания промтов и процесса получения публикуемого результата.
Разрешено:
- Делиться вопросами, мыслями, гипотезами, юмором на эту тему.
- Делиться статьями, понятными большинству аудитории Пикабу.
- Делиться опытом создания моделей машинного обучения.
- Рассказывать, как работает та или иная фиговина в анализе данных.
- Век жить, век учиться.
Запрещено:
I) Невостребованный контент
I.1) Создавать контент, сложный для понимания. Такие посты уйдут в минуса лишь потому, что большинству неинтересно пробрасывать градиенты в каждом тензоре реккурентной сетки с AdaGrad оптимизатором.
I.2) Создавать контент на "олбанском языке" / нарочно игнорируя правила РЯ даже в шутку. Это ведет к нечитаемости контента.
I.3) Добавлять посты, которые содержат лишь генеративный контент или нейросетевой Арт без какой-то дополнительной полезной или интересной информации по теме, без промтов или описания методик создания и т.д.
II) Нетематический контент
II.1) Создавать контент, несвязанный с Data Science, математикой, программированием.
II.2) Создавать контент, входящий в противоречие существующей базе теорем математики. Например, "Земля плоская" или "Любое действительное число представимо в виде дроби двух целых".
II.3) Создавать контент, входящий в противоречие с правилами Пикабу.
III) Непотребный контент
III.1) Эротика, порнография (даже с NSFW).
III.2) Жесть.
За нарушение I - предупреждение
За нарушение II - предупреждение и перемещение поста в общую ленту
За нарушение III - бан