

Уроки Excel
5 постов
5 постов
Всем привет. Я зумер. Мне 22 года.
Здарова, малая!
Давайте поговорим о такой проблеме как зумеры в офисе. Вы наверное видели эти статьи о том, что зумеры это страх и проблема работодателей.
Не видел, но почему-то догадывался
На самом деле мне смешно и обидно одновременно на это смотреть. Зумеры являются страхом работодателей, потому что зумеры не терпилы.
Обобщение - прекрасный прием, но тут бы нужна легкая конкретизация. Было бы интересно узнать, конкретно ты из Москвы или из Питера? Потому что... Ну в общем я скорее всего угадал, да?
Я много раз слышала от более взрослых людей (40+), что мы ещё маленькие и ничего не понимаем в работе. Надо долго и тяжело работать и тогда возможно ты получишь хорошую денюжку)
В целом это именно так. Возможно, если у тебя выдающиеся способности, то чуть менее долго и чуть менее тяжело, но в среднем принцип такой. Другого пока не придумали, но, видимо, ты расскажешь нам об этом далее
Давайте разберёмся :
Вот, давай
1. Я - зумер. Я не буду ебашить за 20к в месяц. И за 25к и за 30к. Я прекрасно понимаю, что специалист без опыта работы не может получать миллионы. Но и получать копейки за свой труд (на которые ты хер проживёшь с нынешними ценами) я не собираюсь. От 35к уже хорошо. В идеале 45к. Причём чаще всего выходит что ты как раз таки ебашишь как Папа Карло, а получаешь хуй с маслом. Нравится это работодателю?) Я думаю многим это не нравится
Я чуть ранее написал, что хотелось бы узнать, где именно ты живешь. Но даже безотносительно этого - почему у тебя, как у зумера, такой запрос? Вероятно, потому что твои затраты на содержание себя выше, чем у скуфов (ну или там дедов, вставь нужное). Вероятно они выше, потому что ты - как зумер - заслуживаешь большего. Как зумер женского пола, ты тратишь много денег на косметику, утренний оверпрайс кофе в каком нибудь Серфе, у тебя в кармане кредитный Айфон с кучей полезных подписок, ну и передвигаешься ты на такси или самокате, презирая ужасный общественный транспорт. Am I in the ball part or whut?
Я в принципе даже не особо осуждаю - я лишь формулирую мысль, что "хер проживешь" - это твое восприятие реальности, которое, как и твое восприятие труда, может быть несовершенным и со временим измениться. Ударение на третий слог.
2. Я (и многие мои знакомые и друзья моего возраста) не видят смысла просто платить за просиживание штанов. Существуют офисы - и это их смысл, но опять же. Нет работы - нет опыта для юного специалиста, нет развития. Зумеров это не устраивает. Так и опять же. Нет работы - так может я своими делами позанимаюсь?) Вы работодатель - не даёте работу, а сидеть надо. Так может я что то почитаю по теме, в телефончике посижу отдохну пока не найдётся работа? Нет. Мы поставим камеры и будем штрафовать вас за использование телефона. А то, что вам просто делать нечего, нас не ебет. Ну прекрасно же)
Есть одна проблема, которая, судя по всему, просто не ощущается тобой по причине возраста. Когда ты периодически тупишь в телефон, твои внимание рассеивается. Ты не можешь сосредоточиться на работе, и опыт у тебя не накапливается. Даже когда речь идет о каком-нибудь условном рутинном забивании накладных в 1С. Поверь старому начальнику планово-экономического отдела (М,35) - количество ошибок, которые потом за вами, зумерками, нужно выявлять и исправлять, несовместимо с затратами на ваш найм. И это - область, в которой ничего особо страшного не произойдет. А если вас поставить на контроль качества или со взрывоопасным чем-нибудь работать?
3. Зумеры не будут терпеть неуважение к себе. Естественно, никто прям уважать тебя не будет. Ты новый специалист, ты мало чего знаешь, ты новенький. Но ни я, ни мои друзья не потерпят повышения голоса в свой адрес, оскорблений и тд. Да, мы можем косячить, потому что мы только набираемся опыта но это не повод кричать на нас и оскорблять. Мы обязательно выскажем свое недовольство работодателю. Понравится это ему? Мне кажется большинству не нравится такое)
Я лично голос повышать не люблю. Но прекрасно знаю, когда его повышают другие и когда его хочется повысить. Обычно это делается тогда, когда работник повторяет одну и ту же ошибку раз за разом. Существует определенный предел, за которым "накопление опыта" превращается в банальную глупость и безалаберность, которая свойственна людям, которые не особо заинтересованы в своей работе.
И это второй пункт, по которому мне тяжеловато читать твой текст. От него веет абсолютным безразличием и отношением к работе, как к чему-то, что у тебя "все равно будет". Ну не оставят же тебя подыхать на улице, в самом деле! Ну, в крайнем случае ты девочка, у тебя есть писечка, может, тебе вообще не нужно работать? Веселее бы было, если бы твой текст был написан зумером мужского пола. Но это не так. А значит - ценность его довольно мала...
4. Я не буду отвечать на сообщения в рабочем чате и поднимать трубку в свой выходной) меня не волнует что там происходит. У меня выходной. Я не буду задерживаться без доп оплаты. Я не буду сидеть болеть на рабочем месте, я возьму больничный. Я уйду в отпуск когда захочу. (я про ситуации, когда работодатель просто так не хочет отпускать в отпуск) Нравится такое начальникам? Нет
Удивительным образом на большинстве предприятий существует график отпусков. И что такое "просто так" решать однозначно не тебе. Или у тебя есть какой-то опыт составления рабочих календарей? Или ты все-таки набираешься чего-то там? Ах да, тебя же не волнует, что там происходит.
5. Я и мои друзья не понимаем строгий дресс код. Есть гос служба, есть очень важные предприятия так сказать. Но если ты сидишь в офисе, ты не контактируешь с людьми и тебе говорят "у тебя блузка из вискозы (или ещё чего) это не по дресс коду-штраф". Ребят, вы там вообще ахуели? До ткани будем докапываться?
Бляха муха, кто вы с друзьями такие? Где у нас рождаются такие свободные и незамутненные личности, я хочу знать! Никаких правил мы не потерпим! Ууууух, смелые ребята. Только вот неясно - зачем, а главное нахуя?
6. И самое вкусное. Работодателям не нравится, что зумеры хотят быть оформлены официально. С белой зп желательно) Им это очень не нравится)
Этот пункт как то сильно отличается от всех прочих в умную сторону. Как будто его юрист подсказал. Хмммм...
Кто то может сказать вот, разбалованная девка. Не хочет работать, не знает что такое труд. Хочет всего и сразу. Да знаю я, хоть и немного. С 1 по 4 курс я подрабатывала репетором. Не плохо кстати получалось и уровень у меня высокий. Также подрабатывала админом в салоне красоты, пол года без выходных ибо ещё же нельзя учёбу пропускать. Ну и на 4 курсе ещё подрабатывала фотографом в детском центре. 12 часовой рабочий день, весь день на ногах. Активные дети и странные родители).
Именно так. Ты - разбалованная девка, которая привыкла работать на работах, на которых нет никакой ответственности. Я опять же не осуждаю, но это звучит слишком забавно - ты как будто реально не понимаешь, что пишешь примеры, не подкрепляющие твою позицию, а добивающие ее.
Вообще терпение стало заканчиваться ещё у мелиниалов. Но почему то боятся именно зумеров.
Это примерно как термином "гомофобия". Никто не боится гомосексуалов. Ровно также никто из работодателей не боится зумеров. "Боязнь" заключается в том, что сложно вкладывать что-либо в человека, у которого в голове вот это - то, что я цитировал весь пост.

Чего только не увидишь в авангарде культуры…
Мне по-доброму интересно - вы вот с этими своими претензиями и закачкой прав - какая ваша объективная ценность? Понятно, что вам не нравится зонтичное отношение к зумерам, но оно не на пустом месте взялось - так-то если, по-честному.
Вы же прекрасно понимаете, что это маятник от крайности к крайности - с одной стороны у нас выдуманные заболевания, с которым зумер просто не способен приходить на работу вовремя (мне лень искать видос, но он легко гуглится), а с другой - реальный беспредел работодателей, которые чего-то там требуют.
Правда же где-то посередине. С одной стороны, вы не достигните ничего, будучи супер-принципиальными в одну сторону. С другой стороны, чего-то достигать, работая на описанной должности в КБ ну наверное вряд ли возможно. С одной стороны, вы тыкаете работодателя в закон, когда он перегибает, с другой - вы же сами не выдержите, если вас реально заставить работать по закону. Неужели вы реально думаете, что все работает только в одну сторону? Это не так.
Почему не качают права какие-нибудь руководители отделов средней руки в крупных компаниях, несмотря на то, что переработок там не меньше, а зачастую значительно больше? Почему постоянно слышится голос именно представителей низкоквалифицированных профессий? Наверное, потому, что вы не воспринимаете эту работу, как нечто, чему вы готовы посвятить свою жизнь и энергию. Это временно и поэтому можно относится к этому соответствующе. И это взаимно.
Я тут какбы в равной степени противник крайностей с обеих сторон. Хотя - уже готов к минусам от простых работяг.
Ну чтож, если вы заждались новый выпуск, то вот он. Сегодня мы будем говорить об одной из самых проблематичных для изучения (по опыту) формул, которая, тем не менее, несет в себе огромный потенциал для работы с данными. Итак...
ВПР() , ГПР()
Да, дорогие друзья, это тот самый легендарный Вэпээр, о котором говорят с придыханием девочки из бухгалтерии. Ладно, давайте к серьезному
Для чего используется? Для поиска данных в массиве по условию.
Звучит крайне криво - как и все околонаучные определения - но в самом Экселе определение еще хуже, так что... Так что давайте традиционно разбирать на конкретных примерах, потому что без этого реально тяжело.
Сначала самый базовый пример. Допустим у вас есть простейшая табличка из трех столбцов, в одном из коротых указана модель ноутбука, в другом - цвет корпуса, а в третьем - диагональ экрана. Ну вот такая:
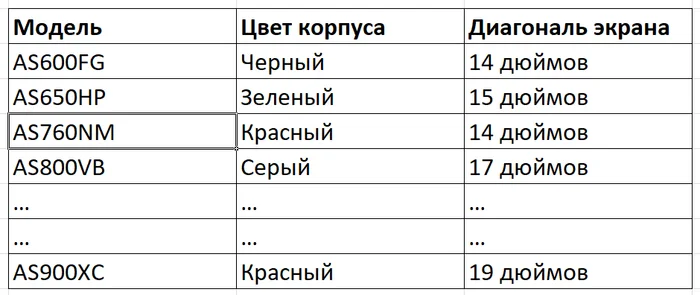
Табл.1
И у вас есть задача сделать что-то типа шаблона ценника, который можно будет быстро распечатать, подставив в него только нужную модель - а все остальные характеристики чтобы подтягивались автоматически. Вот тут вам и пригодится наша сегодняшняя формула ВПР().
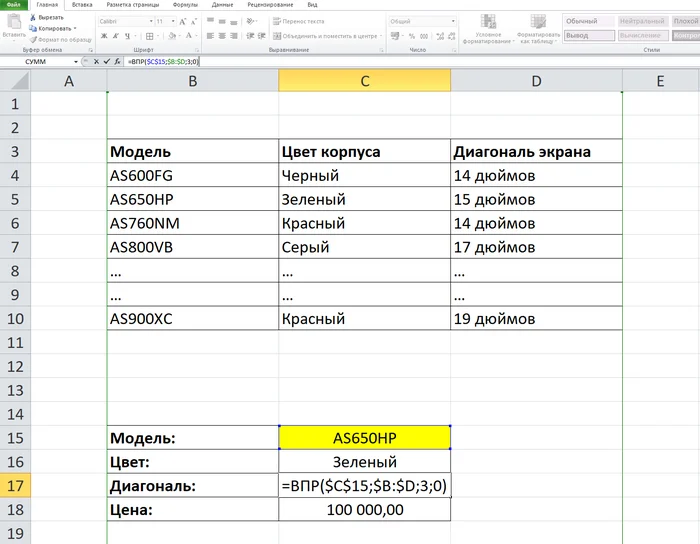
Табл.2 Пишем формулу в ячейке С17
Давайте разберем, как именно пишется ВПР(). В ней четыре блока, разделенных точкой с запятой.
Первый блок - условие, то есть то, что мы будем искать. Обратите внимание, столбец с условием должен быть левее столбцов с теми значениями, которые мы будем подставлять - это крайне важно, потому что иначе формула просто не работает. Только слева-направо!
Второй блок - это массив, в котором мы будем искать данные. Воспринимайте его как набор столбцов в рамках данной формулы, так будет чуть легче. Я рекомендую всегда выбирать массив именно столбцами, не ограничивая себя строками без необходимости. И не забывайте фиксировать массив (знаки $ перед буквами) - это крайне важно в большинстве случаев.
Третий блок - это номер столбца относительно начала массива, из которого будут подставляться данные. То есть в нашем примере "Диагональ экрана" - столбец D - это третий столбец массива, "Цвет корпуса" второй, "Модель" - первый.
Четвертый блок - это "точность" поиска. Если честно, мне не приходилось сильно эксперементировать с этим параметром, поэтому я рекомендую ставить его всегда 0 (ноль). В этом случае формула будет искать точное соответствие. С помощью неточного соответствия (единичка) в теории можно заставить формулу искать похожие значения, но одно "но", о котором я расскажу чуть позже, которое делает данную функцию не слишком полезной.
Важно помнить, что массив, из которого мы будем подставлять данные, должен удовлетворять определенным правилам. Главное из которых - в столбце, который мы выбираем условием (крайний левый) не должно быть дубликатов. Ну то есть теоретически дубликаты в нем могут быть, но тогда значения у этих дубликатов также должны быть одинаковыми.
Поясню все на том же примере - допустим, у вас есть ноутбук модели AS650HP, который кто-то не очень аккуратный занес в табличку дважды и с разными диагоналями. Такого не может быть - ну потому что модель одна, и второго размера экрана у нее не существует. Явная ошибка. Но - формула ВПР() об этом не знает. И она возьмет из таблицы то значение, которое находится выше. То есть в данном случае 16 дюймов, что (допустим) неправильно. Сколько бы ни было строчек с одинаковым условием - формула всегда берет верхнюю.
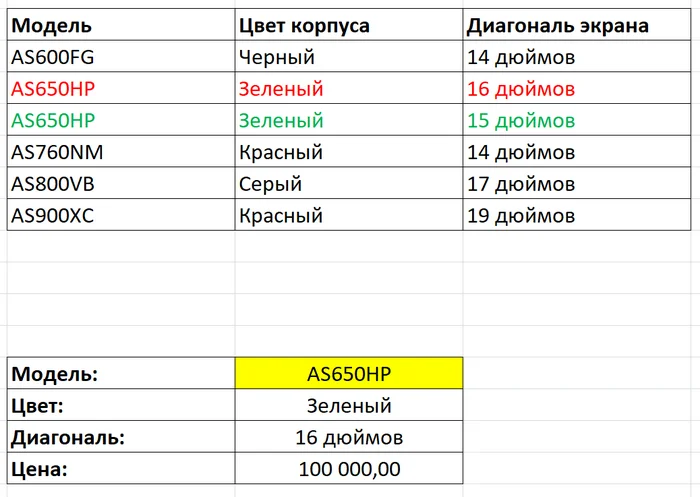
Табл 3
Помните СУММЕСЛИМН() формулу? Вот она адекватно реагирует на повторяющиеся условия, она собственно для этого и создана. ВПР() же создана для вставки одного конкретного значения. И тут мы подходим к основной функции этой формулы - так называемому приему мэппинга.
Что интересного можно сделать с этой формулой?
Итак, о мэппинге. Я так называю процесс простановки некоего соответствующего параметра из одной таблицы в другую, которую необходимо определенным образом упорядочить и обработать. Чаще всего это делается тогда, когда не хочется проставлять около каждой из 100500 строчек какой-то параметр вручную или же в теории он может измениться в будущем.
Давайте придумаем что-нибудь базовое - ну вот например, если дополнить табличку из примера выше пометкой "в наличии", то можно будет рассортировать список заказов на те, которые мы сможем выполнить, и те, которые не сможем. Но чаще всего подобное используется для создания более сложных классификаторов. Например, для переложения бухгалтерского учета в управленческий, если это не автоматизировано в учетной программе, можно написать мэппинг, в котором статье из бухгалтерского учета будет соответствать статья управленческого.
Мэппинги, естественно, можно строить как по одному условию, так и по нескольким. В этом вам поможет ранее изученная формула "СЦЕПИТЬ". Например, представим что покупатель говорит "я хочу красный ноутбук с диагональю 14 дюймов, есть у вас такие?" - и мы, забив в наш шаблон эти два параметра и пробив пару формул отвечаем "да, вот такая модель в наличии".
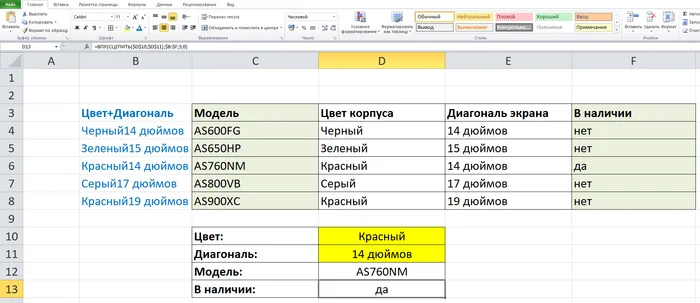
Табл.4
В качестве условия для ВПР() может служить совокупность любых ячеек, которым вы сможете поставить что-либо в соответствие. Главное, чтобы эта совокупность была уникальна.
Важно понимать, что в третьем блоке в качестве номера столбца может также быть заведена формула. Мне не хочется слишком сильно ломать вам голову, но все же - изучим еще одну небольшую формулу. Она называется ПОИСКПОЗ(). Работает следующим образом - выбираем в первом блоке что искать, во втором обозначаем массив, где искать, и далее указываем, как ищем (-1 - самое ранее, 0 - первое, 1 - последнее).

Табл.5
Соответственно в этом примере формула найдем там значение "Модель" в массиве из пяти ячеек, и оно будет равно 2 - потому что это вторая ясейка массива. Как думаете, как можно это применить, чтобы упростить себе задачу в шаблоне из нашего примера?
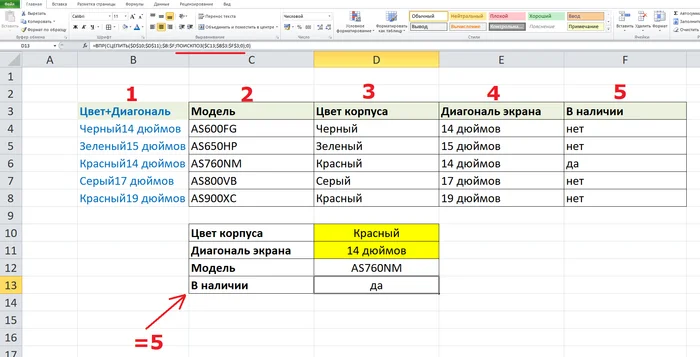
Табл.6
Да вот так - мы просто делаем наименования полей нашего "шаблона ценника" такими же, как наименования столбцов в исходной таблице и далее вставляем ПОИСКПОЗ() в формулу ВПР(), наводясь на (зафиксированный!) массив из пяти ячеек. В каждом случае номер ячейки, которую найдет ПОИСКПОЗ() будет соответствовать номеру столбца для ВПР().
Таким образом например можно формировать всякие заявления, в которых нужна ФИО, должность, табельный номер или еще что-то, если это не автоматизировано.
***
Ну а на этом я с вами прощаюсь. Задавайте вопросы, комментируйте, учитесь, тренируйтесь.
Вот знаете мы все время переживаем за "престиж" учителей, но почему-то забываем про вот эту вот профдеформацию, когда они начинают реально думать, что не могут быть не правы. И извиниться за свои действия не способны просто по факту.
Вот вам история из моей школьной жизни, давно это было, но помню как сегодня. Я болел. Но в школе сказали - всем сдать сочинение. Я написал (на двойном листочке, это было 20 лет назад) и попросил одноклассницу Иванову сдать его за меня, мы не так далеко жили. Выздоравливаю, выхожу, раздают сочинения, у меня стоит "два". Я подхожу и задаю резонный вопрос - почему? Мне ответ - ты списал все у Ивановой. Я разворачиваюсь, закрываю погромче дверь и иду на следующий урок.
Поясню свои действия. Я был отличником. Никогда ни у кого не списывал, списывали у меня. Училка это знала прекрасно, пусть и учила нас что-то около года. Иванова была классическая симпотичная двоечница, очень глупая. Списано сочинение было слово в слово до запятой, только два абзаца поменяны местами - как потом я увидел.
В итоге на перемене побегает ко мне Иванова и говорит "я во всем призналась, Нина Ивановна говорит, чтобы ты подошел, извинился и тогда тебе поставят четверку". Я естественно не подошел. Двойку исправили, не помню уже на что. Училка передо мной не извинилась.
Дык а можно уточнить, дорогой автор, вот представь себе, что исполнители теракта в Беслане были бы изначально известны, и, чтобы их ликвидировать, потребовалось бы, скажем, заминировать их телефоны. Ну вот посовещались серьезные люди и поняли, что так наиболее эффективно.
Вопрос к тебе - ты бы их тоже защищал или как?
Ну то есть я понимаю в целом твою точку зрения, что над преступниками должен быть справедливый суд, доказательства там, адвокаты - я полностью с тобой в этом согласен. Но террористы - это все таки особая категория преступников. Это люди, которые открыто говорят "мы хотим, умеем и будем сеять смерть во имя (вставьте нужное, но обычно слово из шести букв)". И я наивно полагаю, что если ты подобное заявил - ты сам вывел себя за рамки цивилизованного процесса.
Разве нет?
Ну что, рубрику я продолжаю. Уже даже появились два человека, которые "ждут" моих постов - я не знаю, что это за новый функционал, но раз написано, что ждут, я не могу их подвести) Сегодня мы будем говорить об одной из самых важных и нужных формул в Excel. Она поможет вам делать удобные таблицы, анализировать, проверять и многое-многое другое. И имя ей...
СУММЕСЛИ(), СУММЕСЛИМН()
Мне тихонько намекнули под предыдущим постом, что СУММЕСЛИ() - формула устаревшая, и вообще не нужно ее разбирать. Я с этим комментатором согласен, и поэтому немного поменяю концепцию занятия...
Для чего используется? Для суммирования массива числовых значений, обладающих одним или несколькими выбранными признаками.
Звучит несколько кривовато и сложно. И нет, это не определение из мануала, это мое определение. Проще объяснить на практике. Напоминаю, что таблицу в любом примере я рекомендую представлять размерностью в 10.000 строк =)

Табл.1 Есть условный реестр данных - сколько продано товара в каждом городе за некий период времени, с дополнительной разбивкой на две категории - фрукты и овощи
Например, нам нужно быстро просуммировать, на какую сумму было продано каждого конкретного продукта. Не вопрос, пишем формулу...

Табл.2 Сложновато на первый взгляд? Сейчас уточним
Итак, формула СУММЕСЛИМН() состоит из нескольких блоков, разделенных точкой с запятой. В данном случае их три, может быть больше, но меньше быть не может - дальше станет понятнее, почему. Итак, первая составляющая - это так называемый диапазон суммирования, то есть наш массив числовых значений. Вторая составляющая - диапазон условия - или тот массив, в котором мы будем искать данные, совпадающие с условием. В нашем случае это наименование товара. Ну и третья составляющая - собственно, условие - это то, что мы будем искать в диапазоне условия. Условие может быть прописано ссылкой или вручную - по традиции, текст в кавычках, числа просто так.
Диапазоны условия и суммирования должны быть равны по размеру - это критично, иначе не сработает ничего. Принцип работы примерно следующий: допустим, мы ищем Яблоки. Формула пробегает по диапазону условия и выбирает из диапазона суммирования значение, которое стоит в соответствующей строчке (или столбце). Эти столбцы не обязательно должны быть смежными. Для примера сделаем то же самое, но по Категории товара:

Табл 3. То же самое, но столбцы не смежные. Можно то же самое сделать и для строк, если у вас таблица горизонтальная
В качестве небольшого лирического отступления скажу, что вот в таком формате - с одним условием - формула СУММЕСЛИМН() функционально полностью идентична СУММЕСЛИ(). Последняя может быть описана как упрощенная ее версия, содержащая в себе только одно условие. Ну и составляющие в ней будут в другом порядке. Не запоминайте - все равно она устарела.
А теперь перейдем к самому интересному - к тому, что и превращает сегодняшнюю функцию в мощнейший инструмент для работы. Указав одно условие, вы можете продолжить писать формулу, добавляя еще условия. Честно - не уверен, сколько можно сделать максимально, но десяток можно точно. Не думаю, что вам потребуется столько. Как это работает? Да вот так:

Табл.4 Два условия.
Логика формулы будет проста - если она одновременно находит в одном диапазоне Саратов, а во втором - Фрукты, то значение из этой строки отправляется в сумму. Учтите, что условия равнозначны и должны выполняться одновременно. То есть формула не будет сначала проверять на первое условие, а затем на второе, в отличие от нескольких ЕСЛИ().
Что интересного можно сделать с этой формулой?
Ну например в качестве условия можно использовать значения больше/меньше. Для этого мне придется испортить столбец "Категория" и проставить в нем какие-то цифры для примера - ничего лучше я не придумал.

Табл.5 К слову, диапазон условия может совпадать с диапазоном суммирования. Например, таким же образом можно просуммировать все значения больше или меньше определенного уровня выручки
Единственная проблема в этом случае будет в том, что условие нужно будет либо указывать в кавычках, аналогично тексту в формуле СЦЕПИТЬ() из предыдущего урока, либо делать ссылки на ячейку, в которой будет написано ">=10" без кавычек. Это тоже работает.
Еще в качестве условия можно использовать маску, либо количество символов. Маска - это часть слова или кода с любым количеством символов с одной или с двух сторон, которые обозначаются знаком *. Например, маска *волк* найдет и "самоволку" и "волкодава". Количество символов можно задать с использованием вопросительного знака. Например ????? будет означать слово или код из пяти символов. Эти приемы можно комбинировать, например *???* будет искать значение минимум из трех символов.

Табл.6 Пример работы маски "минимум три символа". Ёж в сделку не входил
Ну или вот ближе к нашему примеру исходному - если бы у нас были Москва и Московская область, например, то их можно было бы просуммировать как-то так:

Табл.7
Таким образом можно создавать продвинутые отчеты, которые будут "таскать" вам в удобном формате данные из какого-нибудь массива - например, из оборотки 1С, которую необходимо каждый месяц выгружать и показывать динамику продаж или еще что-нибудь. При появлении новых позиций вам не придется наводить на них ссылки вручную - достаточно будет всего лишь добавить новое условие и скопировать формулу.
Лирическое отступление номер два. Обратите внимание на закрепление диапазонов в большинстве моих примеров. Не забывайте, что если вы хотите таскать данные из единого массива, то его нужно зафиксировать. То же самое касается и диапазона условий. А вот если вы ссылаетесь на ячейки со значениями условий - тут уже думайте сами, необходимо вам фиксировать что-то или нет. Бывают ситуации, когда диапазон суммирования будет "плавающий" - например, у вас матрица выручки помесячно, и вы хотите подвести итог внизу по категориям. Тогда вы будете фиксировать диапазон суммирования только по вертикали.
***
А на этом я с вами прощаюсь до следующего выпуска. Сегодня формула была одна - но зато какая! Вы будете удивлены, какое количество людей не умеет правильно пользоваться подобными инструментами. На самом деле конечно ни прочтение поста, ни прохождение курсов не сделает вас мастером Экселя. Главное - использовать изученное в ежедневной работе или хобби. Без этого смысла не будет. Учтите этот банальный момент.
ну и как всегда - пишите комментарии, предлагайте, о чем еще написать, пишите задачки, может чего подскажу
Ну что ж, в предыдущем выпуске мы говорили про довольно простые формулы, а в этом... Мы будем продолжать говорить про простые формулы. Тут конечно же стоит уточнить, что все относительно. В этот раз мне хотелось бы немного коснуться темы форматирования в Экселе и различных формул, которые позволяют доставать и/или добавлять ту или иную информацию.
=ДЕНЬ(), МЕСЯЦ(), ГОД(), ДАТА()
В моей работе частенько приходится сталкиваться с необходимостью оценки тех или иных показателей в динамике. К сожалению, разные программы содержат в себе очень разные форматы предоставления данных, и такая простая штука, как дата, зачастую присутствует либо в текстовом формате, либо в чем-нибудь похуже. Так что давайте потренируемся, что можно делать с датами.
Для начала хочу напомнить, что 0 (ноль) в формате даты в Эксель будет выглядеть следующим образом: 00.01.1900 - то есть "нулевое января 1900-го года". Соответственно, любая дата будет представлять собой в числовом формате количество дней от этой даты. Вбейте 05.01.1900 и переведите в числовой формат, чтобы проверить, что я вас не обманываю.
Для чего применяется? Обозначенные выше формулы - например, ДЕНЬ() - позволяют "вытащить" из даты, записанной в любом формате, необходимое значение.
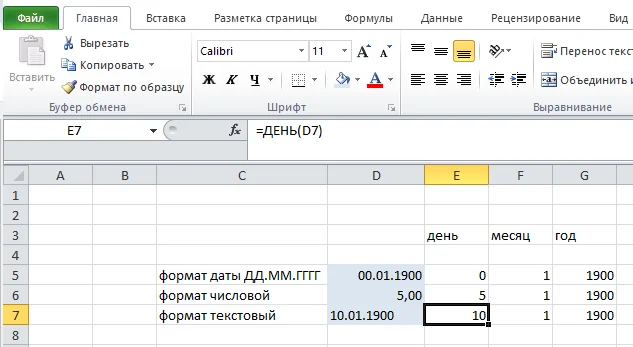
Вот несколько примеров по-разному записанных дат, на которые вполне себе работают формулы ДЕНЬ(), МЕСЯЦ(), ГОД()
К слову, то же самое будет актуально для формул ЧАС(), МИНУТЫ() и СЕКУНДЫ(). Не будем останавливаться на том, как они работают.
Что интересного можно сделать с этой формулой?
"Развернутую" на месяц, день, год дату можно "свернуть" с помощью функции ДАТА(), указав последовательно год, месяц и день.

Только вот здесь значения должны быть уже четко в числовом формате. Если нечаянно попадется текст, содержащий лишние символы (например пробел), то результатом будет ошибка.
Учтите, что даты в любом формате можно вычитать друг из друга, дабы получить продолжительность периода между ними. Он будет всегда в днях. Даже если вы решите отформатировать ячейки так, чтобы в них был только месяц и год.

Ну вот в ячейках D10 и D9 внесены даты и отформатированы именно таким образом. Только в одной это 10.01.1900, а во второй 15.01.1900. И все равно формула считает дни, в не месяцы
Учтите, что даты формата 00.ХХ.ХХХХ и ХХ.00.ХХХХ Эксель не воспринимает при занесении вручную и выдает ошибки при попытке "вытащить" из них что-либо. Так что для того, чтобы поставить 00.01.1900 мне пришлось внести в ячейку именно 0, а потом сменить формат на "Дата". Только так.
Существует также ленивая функция ДАТАЗНАЧ(), которая может помочь вам в быстром преобразовании криво занесенных дат - в основном, в текстовом формате. Для работы с этой формулой не нужно никаких дополнительных условий - просто наведите на нужную ячейку, и возможно произойдет волшебство. Но я бы сильно на результат не рассчитывал.
Самое интересное, что с помощью простого знака "+" можно совместить дату и время. Вы знали о таком? Я узнал совсем недавно.

Это просто и прекрасно
=СЦЕПИТЬ()
Мы подходим к одной из самых полезных формул для многих видов задач. И я настоятельно рекомендую отнестись серьезно к этой части "урока". Не болтать на задней парте!
Для чего применяется? Для объединения нескольких значений в одно.

Слева - наш, "отечественный" вариант сцепки через слово "СЦЕПИТЬ" и далее поля перечисляются через точку с запятой. Справа - иностранный вариант, через значок "&". Если вам не лень переключать раскладку клавиатуры - используйте его. Разницы никакой.
Что интересного можно сделать с этой формулой?
Ну, для начала, помимо сцепки значений из ячеек, в формуле можно прописать вручную дополнительные значения. Например, запятые или пробелы.

А лучше - запятые с пробелом!
Если вы хотите добавить в сцепку текст, пишите его в кавычках. Если числовые значения - то без кавычек. Помните, что дату вы просто так не добавите.

Почему такой результат? Читаем выше. Еще выше.
Вы спросите - а как же добавить дату в "нормальном" формате? С помощью функции ТЕКСТ(), которая позволяет переформатировать все что угодно во все что угодно. Буквально. С ее помощью можно добавлять и убирать знаки после запятой, промежутки между разрядами и так далее.

Ну вот так. ДД.ММ.ГГГГ - это собственно формат вывода данных. Его написание можно "подсмотреть" в меню "Формат ячеек" > "(все форматы)"
Вариантов применения данной формулы - на самом деле великое множество. Вот некоторые идеи:
- Создание шаблонов текстов с изменяющимся ФИО ("Я, <ячейка с ФИО>, находясь в здравом уме и трезвой...")
- Создание уникальных кодов для мэппинга (часто используется с формулами ГПР() и СУММЕСЛИ(), о которых мы будем говорить позднее)
- Создание адресов и/или ссылок на файлы и папки
***
На этом я с вами прощаюсь. Перегрузки информацией не будет. Все посты по Эксель я объединил в серию, чтобы вам было удобнее читать (наверно).



