Давно просили от меня разбор очень популярного в последнее время Sleepwalker от Akiaura, Lonown и STM. В сегодняшнем разборе покажу, как писать такие треки, фишки в сведении, какие я использую плагины и драмкиты, всё по классике.
Видос объёмный, много полезной инфы, поэтому смотрим от начала до конца, всем приятного просмотра! 💜
Пишите в комментарии, если вам нужен проект, отгружу в телегу✨
Ну и конечно не забудьте поставить лайки и плюсики везде, где только дотянетесь, это очень помогает в развитии и радует меня лично💗
Была в году 2021 популярна в видео добавляли и в тик токе тоже слышал. Песня клубная, что то прям навитое каким нибудь "шагом" но в ней есть восточные кажется индийские мотивы. Точно помню что играли скрипки а потом девушка "ах ах ах" пела.
Друзья, всем привет! Сегодня на разборе 2 очень интересных трека, похожие на те, что вы слышите в подборках "Music for focus and concentration". В первом я сделал упор на простоту, покажу в этом проекте пару интересных фишек с вокалом и сведением. Во втором я более детально коснусь драм-партии, покажу, какие паки и плагины я использую и всё это за 17 минут. Как вы уже поняли, я обожаю гараж :D
Приятного просмотра!
Буду рад любой вашей поддержке. Жду вас в своём телеграм канале!
LUXURY ELITE / SAINT PEPSI "Late Night Delight" 2013 З
а воскреснье прослушал альбом более восьми раз.
Я обнаружил, что он идеален для любого времени дня.
Первая половина альбома спродюсирована Luxury Elite, артисткой, за которой я с интересом слежу уже несколько месяцев (лента Lux в Твиттере - большое удовольствие !). "Late Night Delight" открывается с песни «All Night», которая заставляет вас чувствовать, что вы просто настраиваетесь на радиостанцию в поздние часы вечера. Мелодии Люкс излучают задушевные и холодные вибрации и напоминают мне о случае, когда я сел в такси в кромешной тьме и у водителя играл чёткий эмбиентный R&B. Это был прекрасный вариант поездки в ночи. Часть релиза от Lux отправляет слушателя в элегантный кабриолет в элитном районе города, где прохладный ветерок треплет ваши волосы, а звуки города сливаются с вашим радио.
Однако половина "Late Night Delight" от Saint Pepsi (Skylar Spence) излучает, казалось бы, иное атмосферное влияние. «Mac Tonight» - жизнерадостный и энергичный, воплощающий беззаботный образ жизни. С Saint Pepsi вы находитесь на вечеринке или в ночном клубе, развлекаясь под бодрящие и пульсирующие удары тяжёлых басов и тарелок. Завершает альбом мой любимая вещь из всех альбомов этого жанра - «Enjoy Yourself». Между прочим, я наткнулся на эту вещь на "Facebook", что стало поводом для более глубокого изучения жанра. Ссылка была о заводном и милом человеке с полумесяцем вместо головы, сидящем за пианино на облаке и напевающем от души. Изучив историю рекламы "МакДональдса", я обнаружил оригинальные телевизионные ролики и это сразу же меня заинтересовало. Сторона сотрудничества Saint Pepsi наполнена позитивом и желанием повеселиться.
Luxury Elite и Saint Pepsi имеют свой собственный взгляд на ночную жизнь, каждая из которых интересна, а также вызывает ностальгию у тех, кто видел этот вид развлечений только в фильмах. Оба они ведут особую роскошную жизнь, поэтому, будь то круиз по городу или вечеринка по городу, обе стороны оправдывают право на «кайф».
Пару недель назад я захотел сделать кавер с одним определённым голосом на какую-нибудь популярную песню. tl;dr всё получилось и ниже вы узнаете, как повторить такой результат:
Быстрое гугление выдаёт несколько онлайновых сервисов, в которых либо можно выбрать из списка уже обученных моделей, либо это дорого, долго и вне моего контроля над генерацией.
платно
Если допустить немного пердолинга, то есть инструмент для локальной установки с простым веб-интерфейсом и кнопкой "Generate".
Но для полноценной работы ему требуются обученные голосовые модели в формате RVC (об этом ниже), функционала обучения в нём нет.
Ещё немного поисков выдают вариации такого колаба.
Для обучения нужно оплатить подписку Colab Pro, иначе процесс будет прибит сервером с ошибкой "недопустимая инструкция для бесплатного аккаунта".
Этого уже достаточно для создания каверов со своими голосовыми моделями. Первые каверы я делал именно так. Если хотите улучшить качество генерации или оптимизировать сам процесс, то переходите к следующему пункту.
Как это работает
Realistic Voice Cloning (реалистичное копирование голоса) или RVC работает по вполне понимаемому алгоритму.
При обучении:
дорожка с голосом, который нужно скопировать, нарезается на короткие отрезки
эти отрезки сортируются по высоте тона, тембру и эмоциям или настроению (используется нейросетевой инструмент оценки эмоциональности)
результат собирается в базу данных и индексируется
При копировании голоса:
заменяемая звуковая дорожка тоже нарезается на короткие отрезки
эти куски анализируются и подбирается наиболее подходящий аналог из базы данных (модели) обученного голоса
подобранному кусочку меняется высота тона, скорость воспроизведения и, если точного аналога не найдено, накладывается "акцент" для создания похожего звука
результат сшивается в цельную звуковую дорожку
Конечно "под капотом" всё устроено значительно сложнее, но принцип понятен.
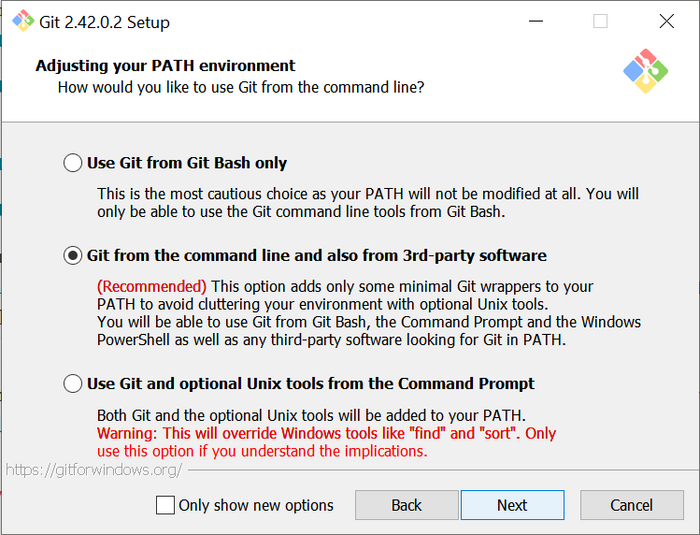
Если умеете пользоваться гитом и командной строкой, то можете сразу перейти к пункту про обучение модели. Ниже будет подробная инструкция по установке.
Требования к железу:
компьютер с Windows или Linux
дискретная видеокарта с 8 ГБ памяти или больше (поддерживаются NVIDIA, AMD и Intel)
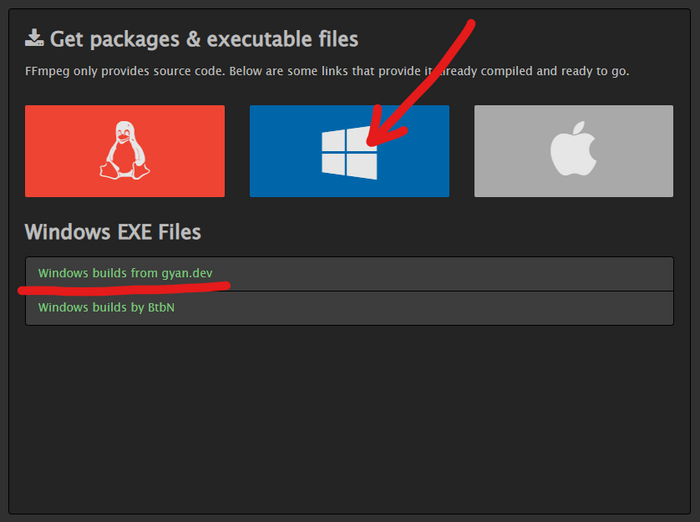
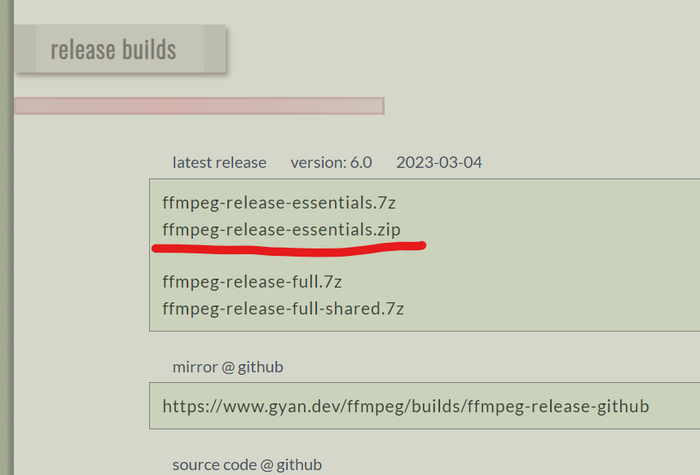
И распаковываем в любую папку. В моём случае C:\ffmpeg и файл ffmpeg.exe находится по адресу C:\ffmpeg\bin\ffmpeg.exe
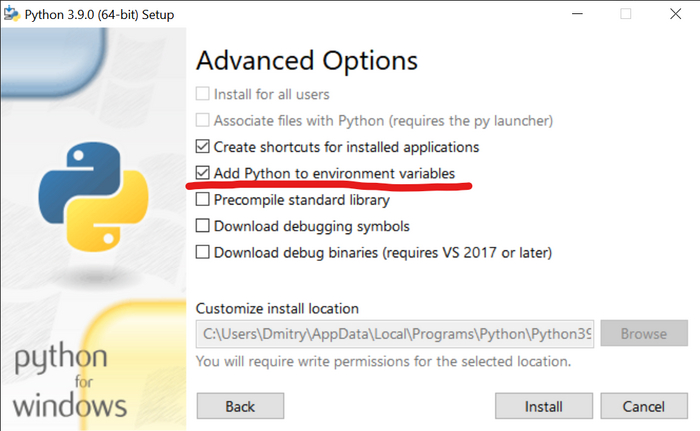
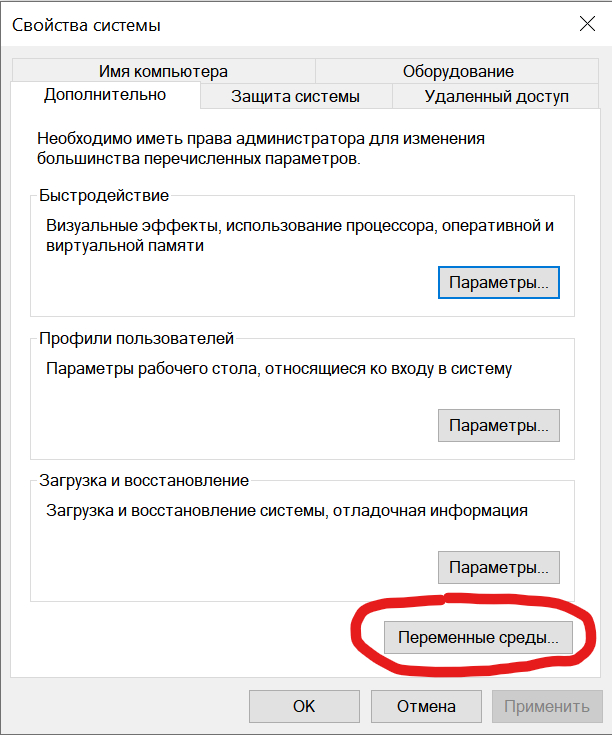
Почти готово, нужно только добавить путь к ffmpeg в переменную path.
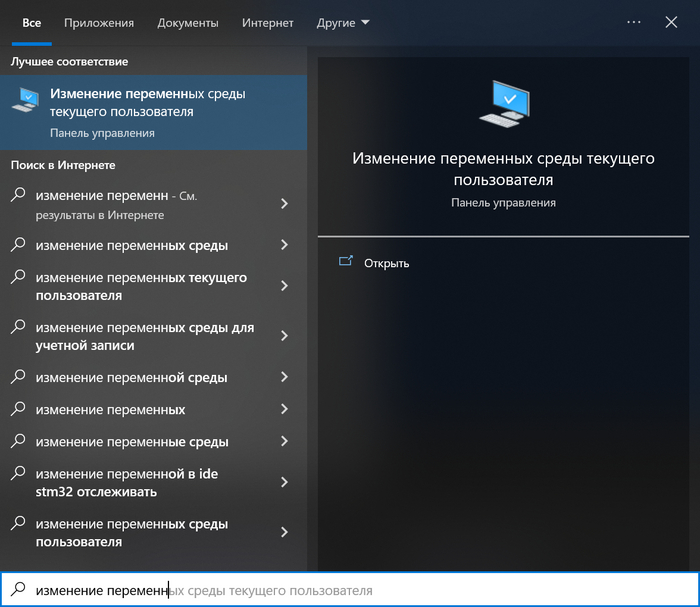
Нажимаем Win и начинаем вводить "изменение переменных среды":
выбираем этот пункт
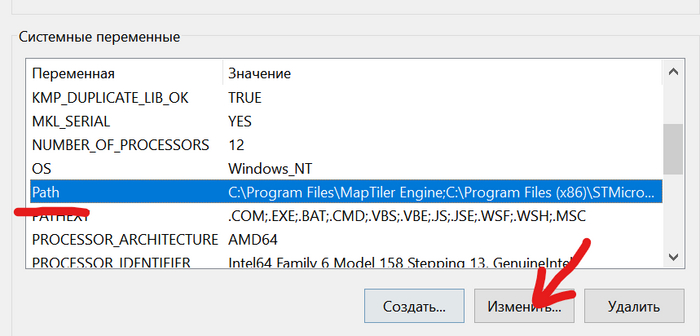
В системных переменных выбираем Path и нажимаем "Изменить..."
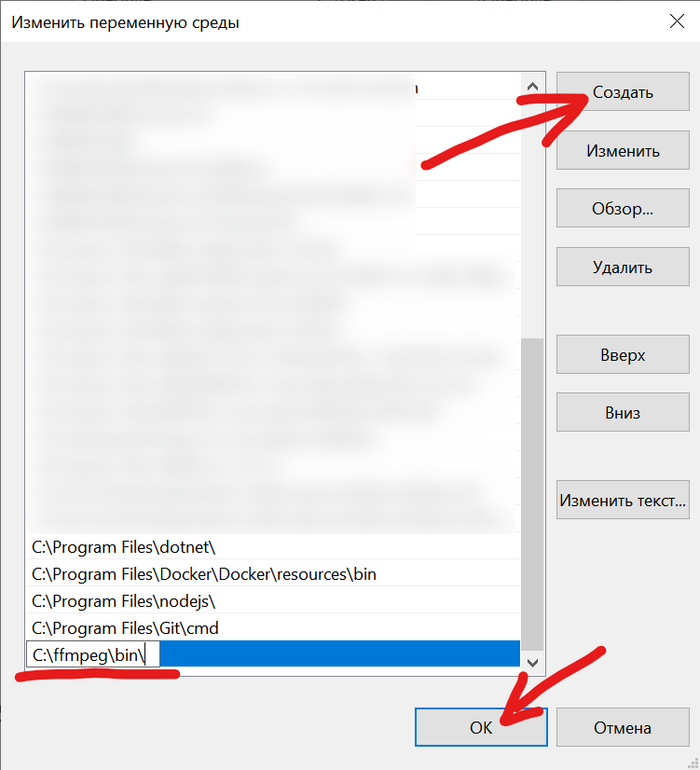
Создаём новую переменную с путём до файла ffmpeg.exe
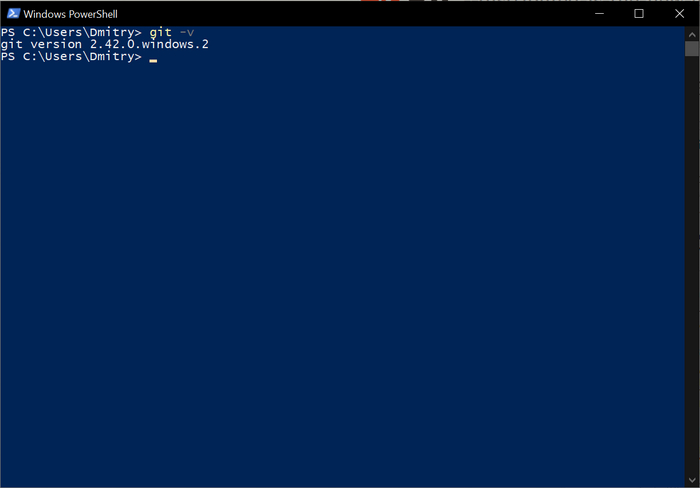
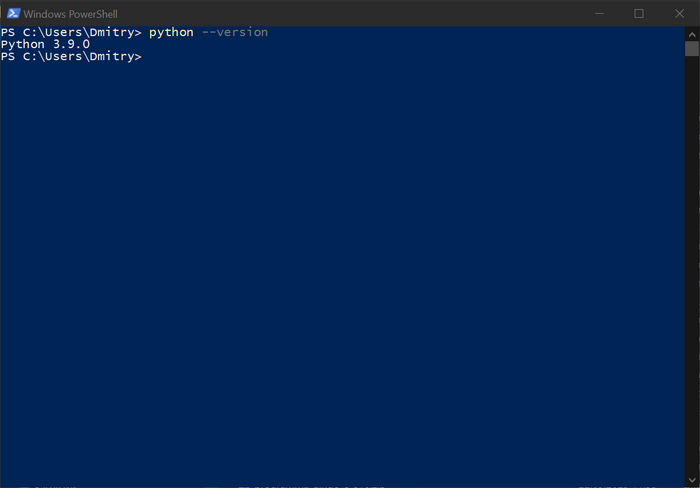
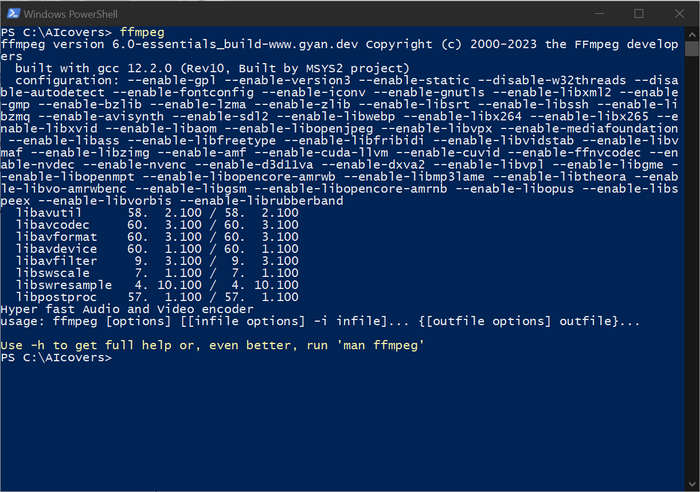
Опять открываем командную строку и проверяем правильность установки:
ffmpeg
Непосредственно установка
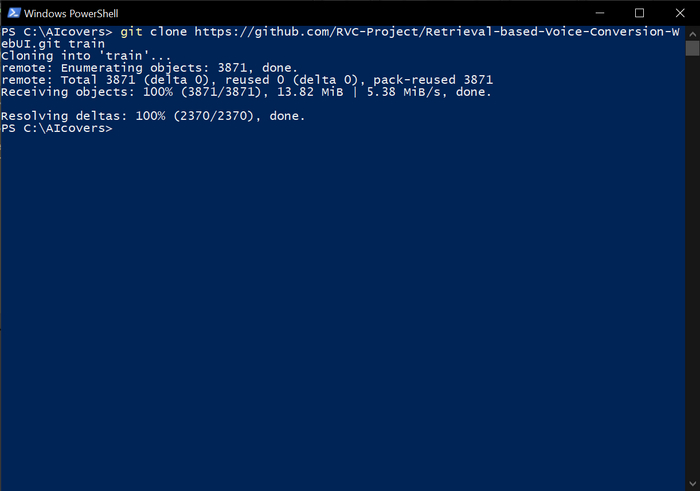
Создайте на диске папку, где будет размещаться софт для обучения модели. У меня это C:\AIcovers (обойдитесь без пробелов в именах папок, это упростит работу в будущем).
Откройте командную строку и перейдите в только что созданную папку.
cd C:\AIcovers
Клонируем этот репозиторий в папку train командой:
Осталось скачать предобученные модели для обработки звука. В основном репозитории нет скрипта для автоматического скачивания этих файлов, поэтому я набросал нечто корявое, но рабочее и отправил PR в основной репозиторий. После мержа курсивный текст будет неактуален.
Скачайте и сохраните у себя файл download_models.py в папке train/tools, куда мы клонировали репозиторий. Затем выполните команду:
И у нас автоматически должно открыться окно браузера с интерфейсом
Если видите это — поздравляю, вы всё сделали правильно. Читайте дальше, чтобы понять, как этим пользоваться.
Обучаем голосовую модель
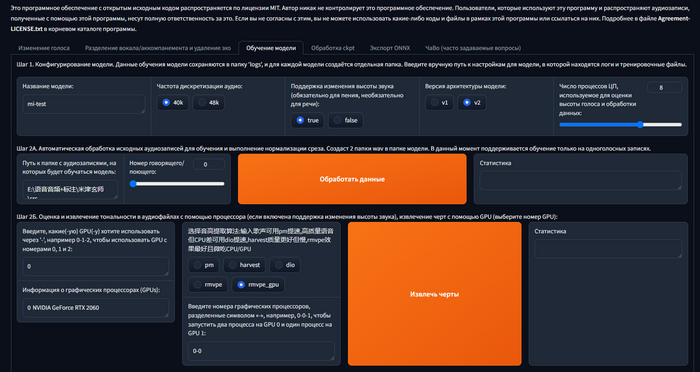
В интерфейсе переходим на вкладку "Обучение модели":
Нужно подготовить данные для обучения модели.
Задайте название для модели голоса в соответствующем поле.
Создайте на диске папку и положите в неё один или несколько файлов с записью голоса. Это должны быть аудиофайлы почти в любом формате. Точно поддерживаются wav, mp3 и m4a.
Голос должен быть максимально очищен от шумов и фоновой музыки. Не должно быть посторонних звуков, которые человек не может издавать ртом.
Для редактирования звука можно воспользоваться бесплатным редактором Audacity.
Введите адрес к папке с аудиозаписями в это поле:
Если в пути к этой папке есть пробелы, то добавьте кавычки.
Нажмите кнопку "Обработать данные" и дождитесь сообщения "end preprocess" в поле справа от кнопки.
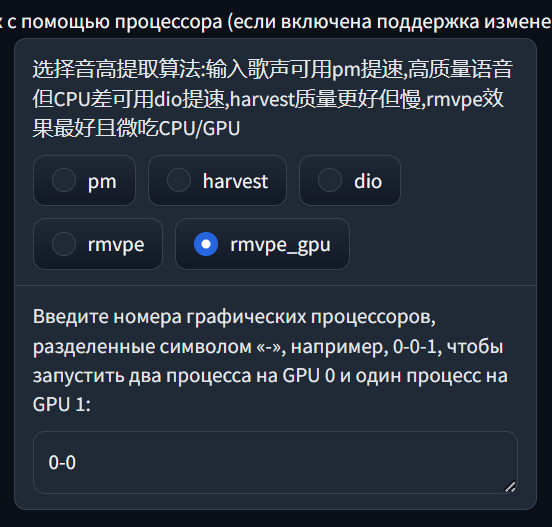
Следующая операция выполняется немного дольше. Сперва выберите алгоритм обработки данных (извлечения черт):
Лучшее качество дают rmvpe и rmvpe_gpu. Они по-разному нагружают видеокарту и центральный процессор. Я так и не понял, какой лучше, поэтому выбираю второй.
Нажмите кнопку "Извлечь черты" и дождитесь сообщения "all-feature-done" в поле справа от кнопки.
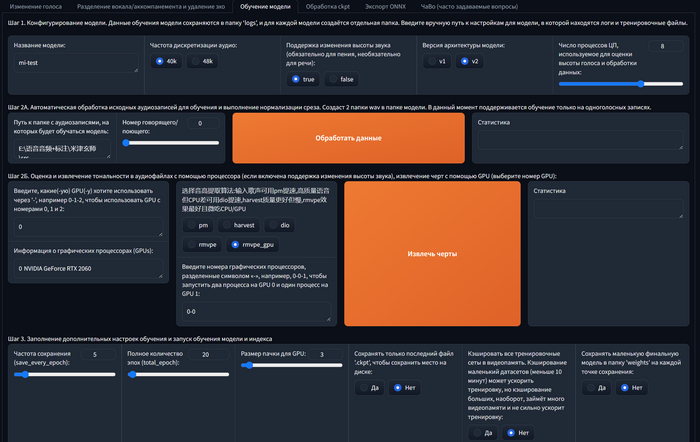
• 20-30 для исходника низкого качества с высоким уровнем шума, большее число не улучшит качества обучения
• ~200 для датасета высокого качества, с низким уровнем фонового шума и достаточной продолжительностью (10 минут и более)
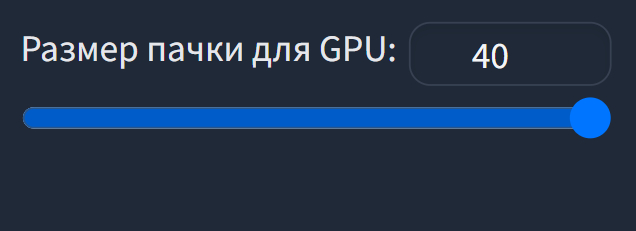
Этот параметр влияет на использование видеопамяти:
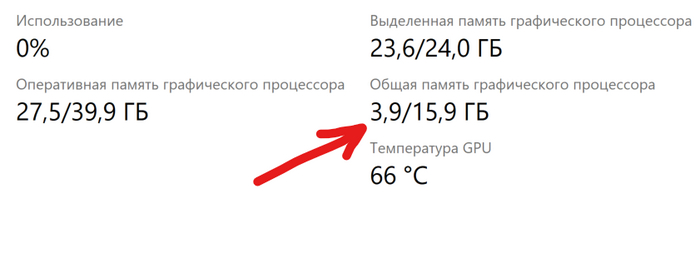
Рекомендаций по оптимальному значению не дам, подбирайте экспериментально для каждого датасета, чтобы расход видеопамяти не вылезал за общий её объём, иначе будет использована системная ОЗУ (та самая DDR на материнской плате) и вместо ускорения обучения вы получите замедление.
использовано 3.9 ГБ более медленной системной памяти
Нажимайте кнопку "Обучить модель" и ждите окончания процесса. Как и в предыдущих этапах в правом поле будет отображаться результат. В консоли можете следить за ходом процесса.
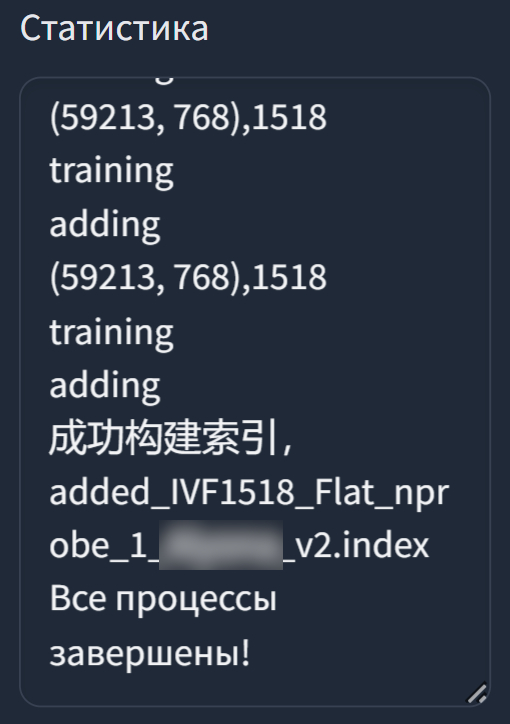
Дожидаемся окончания обучения и нажимаем кнопку "Обучить индекс черт" и ждём ещё немного.
Заходим в папку с нажим скриптом и по пути assets\weights находим файл *имя-модели*.pth (в моём случае my-voice.pth) и копируем его в отдельную папку.
Теперь по пути logs\*имя-модели* (в моём случае logs\my-voice) находим файл с именем формата added_IVFxxx_Flat_nprobe_1_*имя-модели*_v2.index (у меня это added_IVF2050_Flat_nprobe_1_my-voice_v2.index) и копируем его в папку к файлу .pth из предыдущего пункта.
Запакуйте оба файла в архив zip с любым именем. Можно использовать встроенный инструмент Windows из контекстного меню Отправить > Сжатая zip-папка.
Поздравляю, этот архив и есть нужная голосовая модель в формате RVC.
В этом места закончился лимит на картинки. Все иллюстрации можете посмотреть в статье на телеграфе.
Замена голоса в треках
Предыдущий инструмент, который мы использовали для тренировки модели, вполне подходит для генерации новых треков, но удобство использования у него на очень низком уровне. Обещаю внести свой вклад в исправление этого недостатка. А пока установим намного более дружелюбный инструмент.
В консоли после запуска будет ссылка, по которой открывается веб-интерфейс.
Для задания другого сетевого порта добавьте параметр --listen-port *номер порта*, а для доступности интерфейса с других компьютеров в локальной сети добавьте параметр --listen.
Для доступности из интернета можно добавить параметр --share.
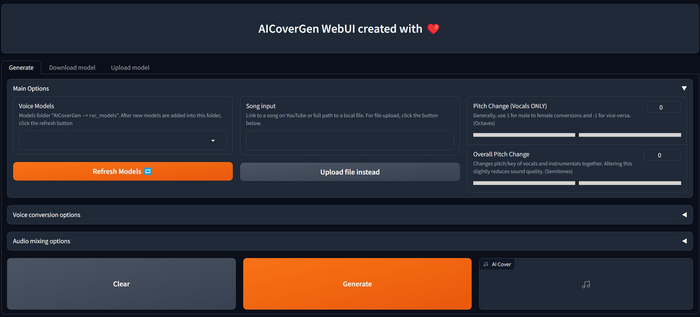
Использование
Откроем интерфейс и перейдём на вкладку "Upload model", чтобы добавить обученную на предыдущем этапе модель голоса.
Выберите файл для загрузки, задайте имя модели в поле "Model name" и нажмите кнопку "Upload model".
Если всё правильно, то в поле "Output message" вы увидите сообщение "model successfully uploaded!".
Теперь переходите на вкладку "Generate" и нажимайте кнопку "Refresh models". В списке "Voice models" появится загруженная вами модель. Выберите её.
В поле "Song input" можно либо вставить ссылку на ролик на YouTube, либо загрузить файл, выбрать вариант "Upload file instead". Рекомендую начать эксперименты с песни Джонни Кэша, у неё хорошо отделяется вокал и достаточно разборчивый голос для замены.
Нажимайте кнопку "Generate" и ждите результата. Подбирайте параметры, пока не получится что-то хорошее. Делитесь получившимися шедеврами.
Если будут вопросы, то можете задать их мне в телеграме.
Подписывайтесь на канал, ставьте лайки, жмите на колокольчик и всё такое. Всех люблю и обнимаю.