


Ответ на пост «Продолжаем воскрешать жанр анекдотов»1977
Поюзаем старый шаблон
<Перевод с корейского>
- Сервис недоступен. Infernal server error
- Может "internal"?
- Нет.

Поюзаем старый шаблон
<Перевод с корейского>
- Сервис недоступен. Infernal server error
- Может "internal"?
- Нет.

Аннотация: В современной бизнес-среде серверная комната или дата-центр перестали быть просто техническими помещениями. Они превратились в сложные, динамичные экосистемы, где физические и логические компоненты находятся в постоянном взаимодействии. В данной статье проводится глубокий анализ ключевых аспектов жизни такой экосистемы: энергопотребления и охлаждения, кабельной инфраструктуры, физической безопасности и мониторинга. В противовес описательному подходу, мы предлагаем системный взгляд, основанный на международных и отечественных стандартах (ГОСТ, TIA-942, ISO/IEC 27001). Для каждого аспекта детально разбираются типичные ошибки специалистов, приводятся яркие примеры их катастрофических последствий для бизнеса и предлагаются конкретные, реализуемые на практике варианты решений, направленные на достижение максимальной отказоустойчивости, эффективности и предсказуемости работы всей информационной структуры предприятия.
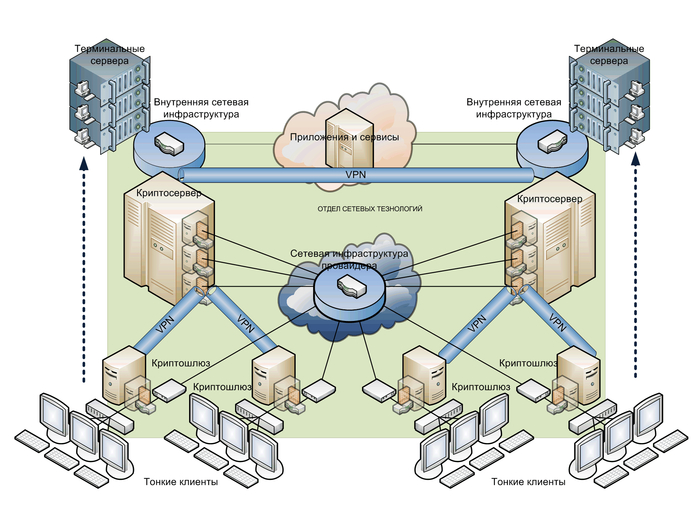
Бродя по просторам «ИНТЕРНЕТА» наткнулся на довольно неплохое чтиво в виде Статьи «Прогулки по серверному парку», которая была опубликована в далеком 2004 году, по моему мнению она была своего рода гидом по terra incognita для многих молодых IT-специалистов того времени которые только начинали свою карьеру. Она фиксировала состояние индустрии, где серверы были громоздкими, а их размещение зачастую напоминало скорее складское хозяйство, чем инженерное сооружение. Прошедшие два десятилетия кардинально изменили ландшафт. Виртуализация, облачные технологии, контейнеризация и экстремальный рост плотности вычислений на единицу площади превратили серверные помещения в критически важные центры жизнеобеспечения бизнеса. Я решил немного обновить и проанализировать ситуацию и обновить «Гайд» для новичков профессии, «Возможно пригодиться»! Старичкам профессии!, буду очень признателен, за комментарии и возможные дополнения, особо ценные обязательно попадут в продолжение, так как планирую в дальнейшем выпустить цикл статей если аудитория заинтересуется.
Понятие «парк» implies нечто пассивное, статичное. Сегодняшняя реальность требует более динамичной метафоры – «экосистема». Это живой, дышащий организм, где изменение одного параметра (например, температуры на одном стойко месте) немедленно сказывается на других (потреблении энергии, шуме вентиляторов, надежности соседнего оборудования). Основной закон термодинамики – энтропия, стремление системы к хаосу – в полной мере применим и к ИТ-инфраструктуре. Без целенаправленных усилий по ее поддержанию и развитию, инфраструктура неуклонно движется к состоянию беспорядка: кабели спутываются, документация устаревает, системы охлаждения не справляются с нагрузкой, а политики безопасности становятся формальностью.
Цель данной статьи – предложить не просто описание лучших практик, а целостную философию управления этой экосистемой. Мы перейдем от вопроса «Что это?» к вопросам «Почему это важно?», «Что будет, если этим пренебречь?» и «Как сделать это правильно, опираясь на мировой опыт?». Анализ будет строиться на сопоставлении хаотичного, «энтропийного» подхода с системным, стандартизированным, основанным на таких документах, как ГОСТ Р 56952-2022 (аналогичный EN 50600 по дата-центрам), серия стандартов ISO/IEC 27000 по безопасности, TIA-942 для телекоммуникационной инфраструктуры и других.
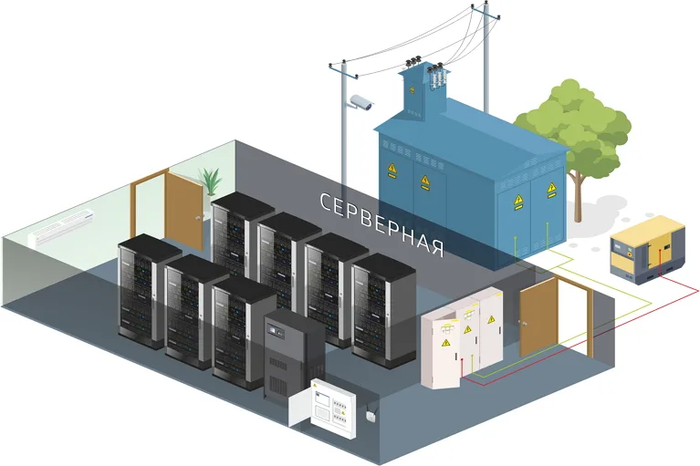
Электричество – это кровь серверной экосистемы. Его качество, бесперебойность и распределение определяют возможность существования всей системы. Тепло – это ее естественный метаболический продукт, который должен быть эффективно отведен. Дисбаланс в этой паре – самая частая причина катастрофических сбоев.
Многие организации, особенно на этапе роста, относятся к энергетике по остаточному принципу. Типичные ошибки включают:
Отсутствие резервирования: Подключение всей критической нагрузки к одной линии электропитания без источника бесперебойного питания (ИБП) или с ИБП, не рассчитанным на длительную работу.
Неправильный расчет мощности: Подключение нового мощного оборудования к уже загруженным электрическим цепям, что приводит к перегрузкам и срабатыванию автоматических выключателей.
Хаотичное размещение оборудования: Установка серверов с высокой тепловой нагрузкой в верхней части стойки, где скапливается горячий воздух, или создание «горячих островков» из-за непродуманной расстановки стоек.
Игнорирование холодных и горячих коридоров: Смешивание потоков холодного и горячего воздуха, приводящее к резкому снижению эффективности системы охлаждения.
1. Внедрение системы бесперебойного питания с многоуровневым резервированием (N+1, 2N).

Стандарт: ГОСТ Р МЭК 62040-3-2014 (Системы бесперебойного питания. Часть 3). Определяет методы определения производительности и испытаний.
Решение: Для малых и средних серверных достаточно ИБП с топологией VFI (двойное преобразование), обеспечивающего чистую синусоиду и защиту от всех видов помех в сети. Для ЦОДов корпоративного уровня обязательна схема резервирования 2N (два полностью независимых модуля питания, каждый из которых способен нести полную нагрузку). Это защитит от отказа одного из ИБП, а также позволит проводить его плановое обслуживание без прерывания работы.
2. Проектирование и строгое соблюдение организации холодных и горячих коридоров.
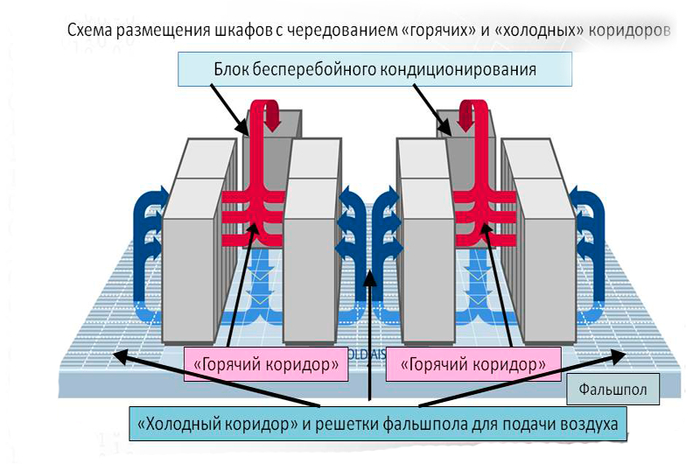
Стандарт: TIA-942-B (Telecommunications Infrastructure Standard for Data Centers). Детально описывает требования к компоновке, включая ширину коридоров, высоту фальшпола, размещение перфорированных плит.
Решение: Стойки должны быть установлены фронтами друг к другу, образуя «горячие» коридоры, где горячий воздух отводится к кондиционерам. Тыльные стороны образуют «холодные» коридоры, откуда оборудование забирает охлажденный воздух. Холодные коридоры должны быть герметизированы (с помощью заглушек на пустых юнитах, боковых панелей на стойках и, в идеале, физических потолков). Это повышает температурный дифференциал и эффективность охлаждения на 15-40%.
3. Внедрение системы мониторинга потребляемой мощности (PDU с измерением) и температуры в режиме реального времени.

Стандарт: ГОСТ Р 56952-2022 (Центры обработки данных. Требования к телекоммуникационной инфраструктуре). Рекомендует мониторинг ключевых параметров среды.
Решение: Использование интеллектуальных блоков распределения питания (PDU), которые предоставляют данные о токе, напряжении и потребляемой мощности на уровне каждой розетки или ветви. Датчики температуры должны размещаться не только на входе кондиционеров, но и на входе в стойки, а также на выходе из серверов (в горячих коридорах). Это позволяет строить тепловые карты и прогнозировать перегревы.

Пример 1: «Эффект домино» из-за перегрузки цепи. В крупном интернет-магазине перед распродажей в стойку с существующим оборудованием был установлен новый мощный сервер СУБД. Инженер не проверил нагрузку на цепи PDU. Во время пиковой нагрузки автоматический выключатель на PDU сработал. Сервер БД отключился, что привело к падению сайта на 4 часа. Прямые убытки от потерянных продаж составили несколько миллионов рублей, а репутационные потери были еще значительнее.
Вывод: Каждое добавление оборудования должно сопровождаться проверкой нагрузки на электрическую цепь. Интеллектуальные PDU с пороговыми предупреждениями могли бы предотвратить инцидент.

Пример 2: Лавинообразный перегрев из-за нарушения циркуляции воздуха. В дата-центре финансовой компании сервер, расположенный в верхней части стойки, вышел из строя из-за перегрева и отключился. Его вентиляторы перестали работать. Этот сервер создавал значительное аэродинамическое сопротивление. После его остановки горячий воздух от нижестоящих серверов изменил поток и начал засасываться ими же на вход, создавая рециркуляцию. В течение 10 минут последовательно перегрелись и отключились еще 5 серверов, что привело к остановке биржевых торговых роботов. Расследование показало, что в стойке отсутствовали blanking-панели (заглушки), усугублявшие проблему.
Вывод: Физическое расположение оборудования и аэродинамика стойки не менее важны, чем работа кондиционеров. Заглушки – это не «косметика», а обязательный элемент системы охлаждения.

Кабельная инфраструктура – это нервная система, связывающая все компоненты экосистемы воедино. Ее состояние напрямую определяет производительность сети, простоту управления и скорость реагирования на изменения.
Анализ текущей ситуации и проблемы

«Кабельный спагетти» – бич многих старых и даже не очень старых серверных. Проблемы возникают из-за:
Отсутствие проекта СКС: Прокладка кабелей «по мере необходимости», без единого плана и цветовой маркировки.
Смешение типов кабелей: Силовые и патч-корды, проложенные в одном лотке, что приводит к электромагнитным помехам.
Игнорирование правил прокладки: Резкие изгибы кабелей, превышающие минимальный радиус, что повреждает жилы и ухудшает характеристики.
Отсутствие документации: После ухода администратора, который «все держал в голове», новый специалист тратит недели на распутывание клубка.
1. Внедрение структурированной кабельной системы (СКС) с четкой иерархией.

Стандарты: ISO/IEC 11801 (Information technology — Generic cabling for customer premises), TIA-942. ГОСТ Р 53245-2008 (Информационная технология. Структурированные кабельные системы. Монтаж и приемка основных узлов).
Решение: СКС должна быть спроектирована с выделением главного кроссового поля (MC), кроссовых полей оборудования (EC) и горизонтальных кроссов (HC). Использование патч-панелей вместо прямого подключения кабелей к коммутаторам. Это создает точку стабильности (стенд с патч-панелями) и точку изменений (патч-корды). Все кабели должны быть промаркированы с двух сторон в соответствии с единой схемой именования.
2. Разделение силовых и слаботочных кабельных трасс.

Стандарт: ГОСТ Р 53246-2008 (Информационная технология. Проектирование основных узлов систем...). Прямо указывает на необходимость разделения трасс или обеспечения расстояния не менее 30 см между силовыми и информационными кабелями при параллельной прокладке.
Решение: Использование раздельных лотков для силовых кабелей и кабелей СКС. Если разделение невозможно, следует использовать экранированные кабели (F/UTP, S/FTP) и заземлять экран. Пересечение трасс должно осуществляться строго под прямым углом.
3. Применение систем управления кабелями (кабельные органайзеры, направляющие).

Стандарт: Рекомендации производителей телекоммуникационных шкафов (например, APC, Rittal) и лучшие практики, описанные в TIA-942.
Решение: Установка вертикальных и горизонтальных кабельных органайзеров на стойках. Использование патч-кордов фиксированной длины (0.5м, 1м, 2м). Это исключает образование свисающих петель и избыточного запаса, которые мешают циркуляции воздуха и доступу к оборудованию.
Пример 1: Случайный обрыв критического соединения. В колокейшн-центре технический специалист, пытаясь добавить новый сервер, зацепился ногой за клубок неорганизованных кабелей. Это привело к выдергиванию патч-корда из коммутатора агрегатного уровня. Этим кабелем обеспечивалась связь между основным и резервным центром обработки данных. Сработал механизм репликации, который, столкнувшись с потерей связи, перевел систему в аварийный режим, ошибочно зафиксировав катастрофу в основном ЦОДе. Начался неплановый переход на резервный сайт, который занял 30 минут и привел к недоступности критичных приложений для сотен клиентов.
Вывод: Аккуратная кабельная разводка – это не эстетика, а вопрос отказоустойчивости. Вероятность случайного повреждения правильно организованных кабелей стремится к нулю.
Пример 2: Тайная деградация производительности сети. Компания жаловалась на периодические «зависания» сети хранения данных (SAN) в ночное время, во время выполнения задач резервного копирования. Логи серверов и коммутаторов не показывали явных ошибок. После многомесячного расследования приглашенный эксперт с помощью рефлектометра обнаружил, что один из волоконно-оптических кабелей, проложенных с резким изгибом за стойкой, имел микротрещины. Под нагрузкой (интенсивный трафик бэкапов) оптический сигнал деградировал, вызывая рост количества ошибок и повторных передач, что и проявлялось как «зависание». Проблема была решена заменой кабеля, проложенного с соблюдением минимального радиуса изгиба.
Вывод: Физические дефекты кабеля могут вызывать прерывистые и трудно диагностируемые проблемы. Соблюдение правил монтажа с самого начала сэкономило бы компании десятки тысяч рублей на диагностике и простое.
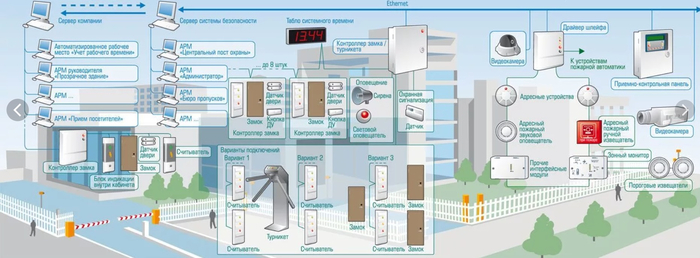
Серверная комната – это сейф, где хранится самый ценный актив компании – ее данные. Физическая безопасность является фундаментом, на котором строится вся кибербезопасность.
Ошибки в этой области часто происходят из-за недооценки человеческого фактора:
Упрощенный контроль доступа: Ключ от серверной, который хранится в незапертом ящике, или единый код на двери, известный десяткам людей.
Отсутствие аудита и сегрегации обязанностей: Один и тот же специалист имеет неограниченный физический доступ ко всему оборудованию, может самостоятельно вносить изменения без согласования.
Пренебрежение видеонаблюдением: Отсутствие архивов записей, фиксирующих кто, когда и что делал в помещении.
1. Внедрение многофакторной системы контроля доступа.
Стандарт: ISO/IEC 27001:2022 (Информационная безопасность, кибербезопасность и защита конфиденциальности — Системы менеджмента информационной безопасности — Требования). Контроль A.7.3 «Физический доступ в зоны безопасности».
Решение: Отказ от механических ключей в пользу электронных систем (карты доступа, брелоки). Обязательное использование двухфакторной аутентификации для доступа в зоны повышенной критичности (например, карта + PIN-код или биометрия). Система должна вести детальный журнал всех событий входа/выхода.
2. Реализация принципа минимальных привилегий и сегрегации обязанностей.
Стандарт: Требованиям отечественного Федерального закона № 152-ФЗ «О персональных данных» (для обработчиков ПДн) и внутренним политикам безопасности.
Решение: Разграничение зон доступа. Например, специалист по сетевым оборудованием имеет доступ только к стойкам с коммутаторами, а администратор СУБД – только к стойкам с серверами баз данных. Физический доступ к ленточным библиотекам с архивными бэкапами должен быть предоставлен крайне ограниченному кругу лиц. Любое изменение в коммутациях (переключение патч-корда) должно фиксироваться в системе заявок.
3. Организация круглосуточного видеонаблюдения с архивом.
Стандарт: Лучшие отраслевые практики, часто требуются стандартами PCI DSS (для платежных систем) и др.
Решение: Установка камер высокого разрешения с охватом всех критических зон: вход, коридоры, лицевые и тыльные стороны стоек. Видеоархив должен храниться не менее 90 дней. Камеры должны быть интегрированы с системой контроля доступа, чтобы событие доступа сразу привязывалось к видеофрагменту.
Пример 1: Кража данных уволенным сотрудником. Сотрудник, уволенный из IT-отдела крупного ритейлера, воспользовался тем, что его карта доступа была деактивирована с задержкой в один день. Ночью он прошел в серверную, к которой имел доступ, и, зная пароли (которые не были изменены вовремя), подключился к серверу, скопировал базу данных с персональными данными и платежными реквизитами нескольких сотен тысяч клиентов. Эти данные были затем проданы на черном рынке. Компании пришлось уведомлять клиентов, менять платежные системы и заплатить многомиллионный штраф по 152-ФЗ.
Вывод: Процедура увольнения должна включать мгновенное отключение всех видов доступа – физического и логического. Журналы контроля доступа должны проверяться регулярно.
Пример 2: Саботаж и вывод из строя оборудования. В рамках корпоративного конфликта недовольный системный администратор, имеющий единоличный доступ в серверную, в выходной день отключил питание на нескольких стойках, вызвав остановку производственного конвейера на 12 часов. Убытки от простоя исчислялись десятками миллионов рублей. Так как видеонаблюдение велось только на входе, а журнал доступа не анализировался, доказать умысел сразу не удалось. Только косвенные улики и последующая исповедь самого администратора позволили установить истину.
Вывод: Отсутствие сегрегации обязанностей и полноценного наблюдения внутри помещения создает колоссальные операционные риски. Ни один сотрудник не должен обладать неконтролируемой властью над всей инфраструктурой.
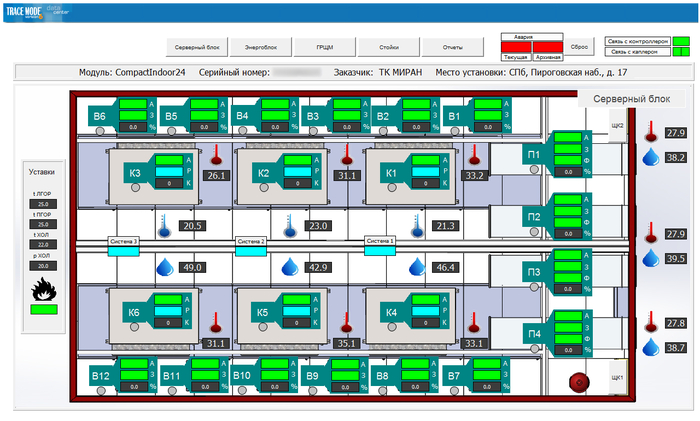
Способность экосистемы к самодиагностике, прогнозированию и планированию – признак ее зрелости. Это достигается за счет комплексного мониторинга и безупречного ведения документации.
Самая распространенная болезнь – «выгорание» процессов документирования:
Документация отстает от реальности: Схемы, нарисованные пять лет назад, не соответствуют текущему состоянию.
Мониторинг «всего подряд» без реакции: Система генерирует тысячи событий, но большая часть из них игнорируется, так как не настроены пороги и приоритеты.
Отсутствие реестра активов и их жизненного цикла: Компания продолжает эксплуатировать сервер, гарантия на который истекла 3 года назад, и узнает об этом только в момент его отказа.
1. Внедрение системы централизованного мониторинга и управления событиями (SIEM).
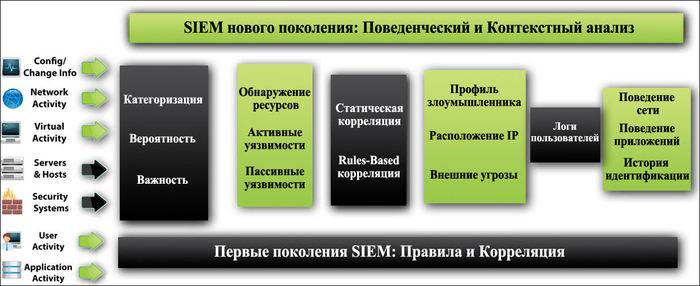
Стандарт: ISO/IEC 27035 (Управление инцидентами информационной безопасности).
Решение: Использование систем типа Zabbix, Prometheus, Nagios для сбора метрик (температура, загрузка CPU, свободное место на дисках) и систем типа ELK Stack (Elasticsearch, Logstash, Kibana) или коммерческих SIEM-решений для агрегации и корреляции логов. Настройка правил, чтобы критичные события (например, отказ диска в RAID-массиве, срабатывание пожарной сигнализации) немедленно вызывали реакцию (уведомление по SMS, email, в мессенджер).
2. Ведение единого реестра активов (CMDB - Configuration Management Database).
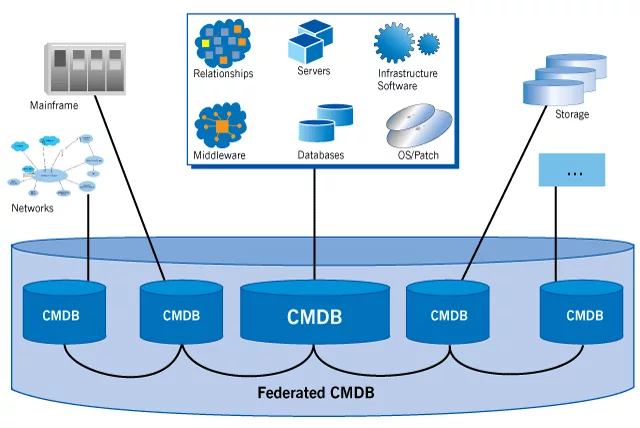
Стандарт: ITIL 4 (библиотека инфраструктуры IT). Практика «Управление активами и конфигурациями».
Решение: Создание базы данных, где каждый актив (сервер, коммутатор, ИБП) имеет свою запись с указанием производителя, модели, серийного номера, даты ввода в эксплуатацию, гарантийного срока, ответственного, связей с другими активами (какой сервер на каком коммутаторе висит). CMDB должна быть «единственным источником истины».
3. Автоматизация документирования изменений.

Стандарт: Внутренние регламенты компании, интегрированные с ITSM-системами (ServiceNow, Jira Service Desk).
Решение: Любое изменение в инфраструктуре (добавление сервера, смена патч-корда) должно инициироваться через заявку на изменение (Request for Change, RFC). После выполнения изменения ответственный специалист обязан обновить соответствующие схемы в CMDB или системе документооборота. Это делает процесс необременительным и частью рабочего потока.
Последствия ошибок: Яркие примеры
Пример 1: Многочасовой простой из-за отсутствия актуальной схемы. В результате аварии на коммутаторе агрегатного уровня отключилась половина серверов. Команда администрирования начала восстановление, но столкнулась с тем, что схема сетевых подключений была устаревшей. Физическое распутывание кабелей, чтобы понять, какой сервер куда подключен, заняло 4 часа. Вместо потенциально быстрого восстановления путем переключения на резервный коммутатор, простой критически важных систем длился более 6 часов, что привело к остановке онлайн-торговли и срыву сроков по ключевым проектам.
Вывод: Актуальная документация – это не отчет для начальства, а инструмент для аварийного восстановления. Ее стоимость несопоставима со стоимостью простоя.
Пример 2: Цепная реакция отказов из-за пропущенных предупреждений мониторинга. Система мониторинга в течение двух недель генерировала предупреждения о постепенном снижении емкости аккумуляторных батарей в ИБП. Однако эти предупреждения имели низкий приоритет («Warning») и терялись среди сотен других сообщений. Никто на них не отреагировал. Во время плановых работ в городской электросети произошло короткое отключение питания. ИБП должен был обеспечить работу на 15 минут, но батареи отработали менее 2 минут. Серверы аварийно отключились, что привело к повреждению файловых систем на нескольких виртуальных машинах. Их восстановление из бэкапа заняло сутки.
Вывод: Мониторинг без настройки правил эскалации и реакции бесполезен. Критичные для инфраструктуры компоненты (ИБП, охлаждение) должны мониториться с высочайшим приоритетом.

Серверная экосистема современного предприятия – это сложный организм, требующий не сиюминутных «латаний дыр», а продуманной стратегии управления, основанной на международных и отечественных стандартах. Каждый рассмотренный аспект – энергетика, кабельная система, безопасность, мониторинг – является неотъемлемым звеном в цепи надежности.
Ошибки на любом из этих этапов, как показали примеры, имеют далеко идущие последствия: от прямых финансовых потерь и репутационного ущерба до полной остановки бизнес-процессов. Стратегия, построенная на стандартах (ГОСТ, TIA-942, ISO/IEC 27001, ITIL), – это не бюрократия, а практический инструмент, позволяющий перевести инфраструктуру из состояния непредсказуемого хаоса в состояние управляемой, предсказуемой и надежной системы.
Ключевой вывод заключается в том, что инвестиции в порядок и стандартизацию «железного» уровня многократно окупаются за счет снижения рисков, уменьшения времени простоя и упрощения масштабирования. Борьба с энтропией информационной инфраструктуры – это непрерывный процесс, но именно он позволяет бизнесу не просто выживать, а уверенно развиваться в цифровую эпоху.

Upd:
Что, сразу ответ писать?
Upd2:
На самом деле, это мог бы быть пост про то, как я пришёл к клиенту, ужаснулся, и уже начал смотреть что куда втыкается, но потом увидел этот или похожий, но очень характерный экран, нажал энтер и всё заработало. И да, уже навели порядок.

Меня зовут Александр, я CTO компании AppFox. Мы более 10 лет занимаемся заказной разработкой и также имеем собственные продукты.
В этой статье мы рассмотрим, что такое Kubernetes, в каких случаях его использование оправдано, и разберем вопросы, которые вы можете встретить на собеседованиях.

Что такое Kubernetes простыми словами?
Разберем на примере интернет-магазина с тремя серверами:
Сервер №1 – основной (принимает заказы).
Сервер №2 – база данных (хранит товары и пользователей).
Сервер №3 – бекенд для API (обрабатывает платежи).
Проблема:
В Чёрную пятницу приходит в 10 раз больше покупателей. В результате, сервера №1 и №3 падают от нагрузки, магазин "висит".
Сервер №2 (база данных) ломается, а все заказы теряются.
Чтобы добавить новые сервера, админ вручную копирует настройки, что занимает часы.
Решение при помощи Kubernetes.
Те же 3 сервера, но теперь они управляются Kubernetes.
Автомасштабирование
При наплыве покупателей Kubernetes автоматически запускает дополнительные копии серверов №1 и №3.
Когда нагрузка падает – лишние сервера отключаются.
Отказоустойчивость
Если сервер №2 (база данных) упал, Kubernetes сразу переключает нагрузку на его резервную копию.
Покупатели даже не замечают проблемы.
Гибкие обновления
Вы хотите обновить API (сервер №3).
Kubernetes делает это без downtime:
Запускает новые версии API, переключает трафик на них и останавливает старые.
Экономия денег
Ночью, когда магазин почти не используют, Kubernetes отключает часть серверов.
Утром – снова включает.
Что это даёт бизнесу?
Магазин не "падает" в пиковые нагрузки (Чёрная пятница, распродажи).
Нет потери заказов – если что-то сломалось, система сама всё починит.
Быстрые обновления – можно выпускать новые фичи без остановки магазина.
Экономия на серверах – не нужно держать "лишние" мощности.
Kubernetes — это система оркестрации контейнеров, которая помогает управлять масштабируемыми и отказоустойчивыми приложениями.
Термин k8s является синонимом Kubernetes и означает 8 букв между первой и последней буквой. Да, программисты любят сокращения :)
Примерно с 2018 года мы наблюдаем устойчивый тренд: Kubernetes стал синонимом «правильной» продакшн-инфраструктуры. И это не случайно. Он действительно решает множество проблем, связанных с управлением микросервисами, масштабированием, отказоустойчивостью и обновлением без простоев.
Когда Kubernetes оправдан:
Микросервисная архитектура с большим количеством сервисов.
Необходимость автоматического масштабирования под нагрузку.
Высокие требования к отказоустойчивости.
Гибкость деплоя (Canary, Blue-Green, A/B-тестирование).
Когда Kubernetes — избыточное решение:
Монолитное приложение с низкой нагрузкой.
Маленькие проекты без потребности в масштабировании.
Стартапы с ограниченным бюджетом.
Проект для демо или MVP, в которых планируется масштабирования только после получения инвестиций
Команда не готова к сложности k8s (обучение и поддержка требуют ресурсов).
В компании AppFox мы используем Kubernetes при построения кластеров для мультиплеерных игр и проектов со сложной микросервисной архитектурой. В частности, мы его использовали при разработке решений для СберБанка и Банка ВТБ.
Основные понятия Kubernetes
Pod — минимальная единица развертывания (может содержать один или несколько контейнеров).
Deployment — декларативное описание желаемого состояния приложения.
Service — абстракция для доступа к подам (ClusterIP, NodePort, LoadBalancer).
Ingress — управление внешним трафиком (роутинг, SSL).
ConfigMap & Secret — хранение конфигураций и чувствительных данных.
PersistentVolume (PV) & PersistentVolumeClaim (PVC) — работа с постоянным хранилищем.
Helm — менеджер пакетов для k8s (чарты).
Теперь самое интересное — какие вопросы задают кандидатам в зависимости от их уровня.
Что такое контейнер и зачем нужен Docker?
Контейнер - это изолированное окружение для запуска приложений со всеми зависимостями.
Docker - платформа для создания и управления контейнерами.
Разница между Docker и Kubernetes
Docker создает контейнеры
Kubernetes управляет множеством контейнеров на разных серверах.
Как работает kubectl get pods? Что выведет эта команда?
Команда показывает список подов (pods) - минимальных единиц развертывания в k8s. Вывод включает имя пода, статус, количество рестартов и возраст.
Что такое Deployment и зачем он нужен?
Это объект k8s для декларативного управления подами. Позволяет:
Разворачивать приложения
Обновлять их (rolling update)
Возвращаться к предыдущим версиям (rollback)
Масштабировать количество реплик
Как приложение в k8s получает конфигурацию (ConfigMap, Secrets)?
ConfigMap хранит конфигурации (например, настройки приложения)
Secrets - чувствительные данные (пароли, токены). Они монтируются в поды как файлы или переменные окружения.
Что такое Pod, Deployment и Service?
Pod — это минимальная единица в Kubernetes
Deployment управляет жизненным циклом Pod'ов
Service предоставляет сетевой доступ.
Как подать переменные окружения в Pod?
Через env, envFrom, ConfigMap, Secret.
Что произойдет, если Pod упал?
Kubernetes сам его перезапустит — важно понимать работу контроллеров.
Как создать под с помощью kubectl?

Как посмотреть логи пода?

Как работает Service? Какие типы сервисов знаете?
Абстракция для доступа к набору подов. Типы:
ClusterIP (внутренний IP)
NodePort (порт на каждой ноде)
LoadBalancer (внешний балансировщик)
ExternalName (CNAME-запись)
Как обновить приложение в k8s (стратегии деплоя)?
RollingUpdate (постепенная замена подов)
Recreate (удаление всех старых перед созданием новых)
Что делает kubelet и kube-proxy?
kubelet - агент на нодах, запускает и контролирует контейнеры
kube-proxy - обеспечивает сетевую связность между сервисами
Как создать кластер Kubernetes?

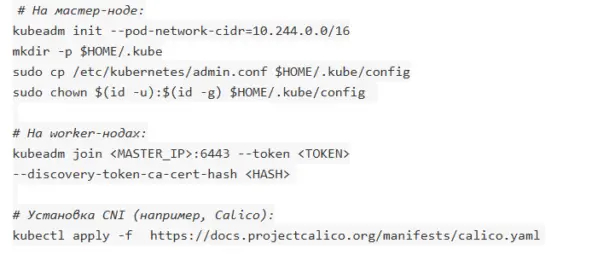

Как подключить volume к Pod'у?
Volume (том) в Kubernetes позволяет сохранять данные между перезапусками Pod'ов. Есть несколько типов томов, но для постоянного хранения данных используются PersistentVolume (PV) и PersistentVolumeClaim (PVC).
PersistentVolume — это ресурс в кластере, представляющий физическое хранилище (например, диск в облаке или NFS-шару). PV создаётся администратором кластера и существует независимо от Pod'ов.
PersistentVolumeClaim — запрос Pod'а на выделение PV. PVC связывается с подходящим PV (или динамически создаёт его, если настроен StorageClass). PVC монтируется в Pod как volume. Если не хочется создавать PV вручную, можно использовать StorageClass для автоматического создания томов.
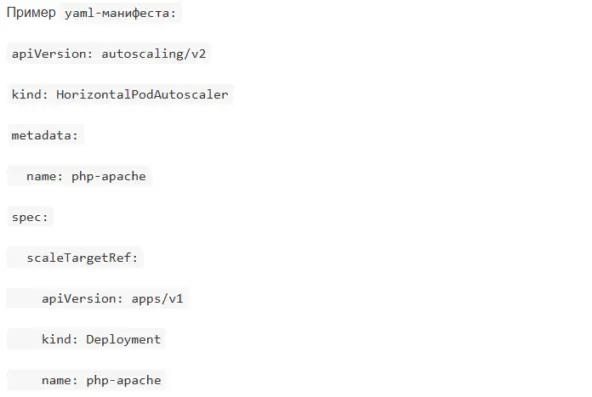
Чем отличается Horizontal Pod Autoscaler от Vertical Pod Autoscaler?
HPA масштабирует количество Pod'ов на основе метрик нагрузки (увеличивает или уменьшает число реплик (replicas) Deployment'а в зависимости от, например, CPU или памяти, т.е., нагрузка выросла — добавили ещё Pod'ов).
VPA изменяет ресурсы (CPU, память) у контейнеров внутри Pod'а
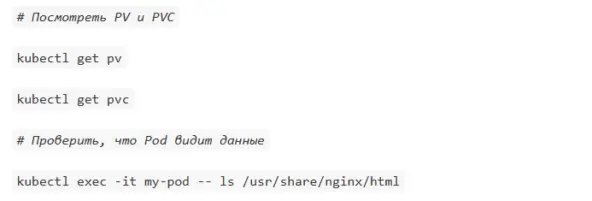
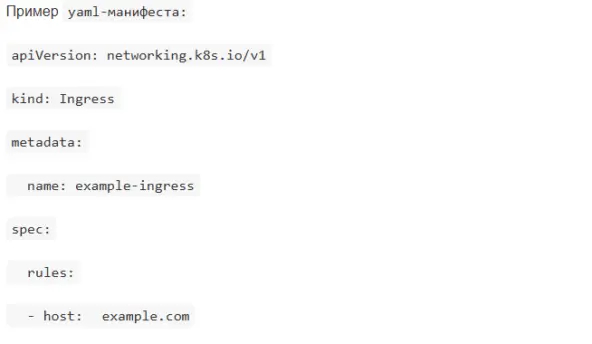
Как настроить Ingress для доступа к сервису?
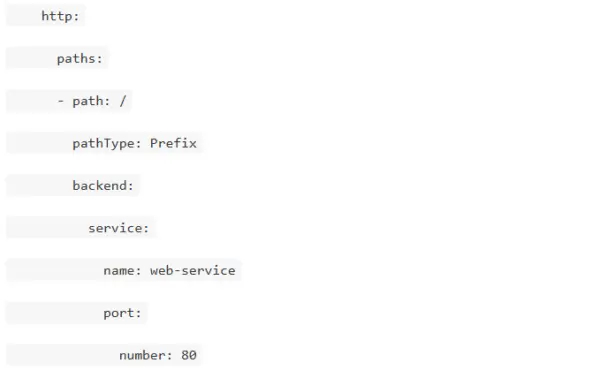
Как сделать Horizontal Pod Autoscaler (HPA)?

Как управлять ресурсами (requests/limits)?

Как настроить PersistentVolume для stateful-приложения?

Как диагностировать проблему с CrashLoopBackOff?
Посмотреть логи пода
Проверить readiness/liveness пробы
Убедиться, что контейнеру хватает ресурсов
Проверить монтирование томов
Изучить события кластера:kubectl describe pod <pod-name>kubectl get events
Как настроить NetworkPolicy для изоляции подов?

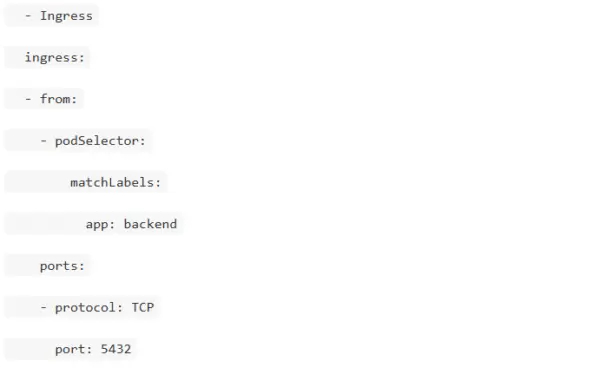
Как работает etcd и что делать при его проблемах?
Распределенное key-value хранилище - "мозг" Kubernetes. Проблемы и решения:
Недостаток места: регулярная дефрагментация
Высокая задержка: оптимизация сети
Потеря кворума: восстановление из бэкапа
Как настроить мониторинг (Prometheus + Grafana)?
Установка Prometheus Operator
Настройка ServiceMonitor для сбора метрик
Создание Grafana дашбордов
Настройка алертов через Alertmanager
Как организовать multi-cluster управление?
Варианты:
Kubefed (Federation v2)
Cluster API
Коммерческие решения (GKE Anthos, EKS Anywhere)
Основные задачи: синхронизация ресурсов, единая аутентификация, централизованное логирование.
Как оптимизировать costs в облачном k8s (автоскейлинг нод)?
Использование spot-инстансов
Автомасштабирование нод (Cluster Autoscaler)
Вертикальное масштабирование подов (VPA)
Планирование подов на дешевые ноды (node affinity/taints)
Использование serverless-решений (AWS Fargate, GCP Cloud Run)
Заключение: Kubernetes — мощный инструмент, но не панацея
Kubernetes действительно стал стандартом для оркестрации контейнеров в современных облачных и гибридных средах. Он решает ключевые задачи: масштабируемость, отказоустойчивость и автоматизацию деплоя. Однако его внедрение требует взвешенного подхода — не каждый проект нуждается в такой сложности.
Главный совет:
Если у вас микросервисы, высокая нагрузка или требовательная инфраструктура — Kubernetes может стать вашим решением.
Если проект небольшой или монолитный — начните с простых решений (Docker Compose, managed-сервисов) и масштабируйтесь постепенно.
Попробуйте Kubernetes в действии:
Разверните локальный кластер через minikube или kind.
Поэкспериментируйте с Helm-чартами и автоскейлингом.
Изучите managed-решения (GKE/EKS/AKS), чтобы оценить их преимущества.
Сразу говорю. Панамка развёрнута невероятных размеров, потому напихивайте.
Итак. На пикабу я пришёл давно, но не регистрировался. Зарегиться меня заставила история Бублика о доме в 700+ квадратов. Не то, чтоб прямо заставила, но появилось желание пописать и о своей авантюре-долгострое, почитать можно здесь Авантюра-дом, или записки самостройщика.
Немного расскажу о своей работе. Это скромная компания с 2,5 сотрудниками, которая куёт IT металл =) Занимаюсь проектированием, закупом, сборкой, монтажом, настройкой, запуском и обслуживанием сетей и серверных для различных оргагизаций. Ещё, понемногу, и видеонаблюдением/скудом/ip телефонией с интеграцией этого всего в 1С.
Как раз на прошлой неделе допинал долгострой. Организацию веду очень давно, растёт она весьма быстро, потому железки предыдущие ещё годны, замены не требуют, но их не хватает по мощностям. Денег, как и всегда, нет, крутись как хошь =)
Отсюда всплыло решение вот такое. Совмещённая коммуникационно-серверная в шкафах старых с частично новым железом - свитчи от невротика. Смысл здесь весь в переходе на оптику между зданиями (в каждом своя коммуникационная), этот процесс наконец то завершился.

В нижнем шкафу не хватает места немного, патч-паннель надо бы разжать. Да некуда. Придумаю ещё.
В верхнем шкафу - прикол. Над упсом висит динрейка с бп на 48 вольт и двумя пое бескорпусными. А они дешевле сильно =)
Провода вертикальные не заплёл - будет ещё добавка с ремонтируемых офисов первого этажа, лотки по периметру прикрутил, не всё ещё туда засунул по той-же причине.
Ну и веду "войну" по выбиванию сюда хоть какого нить кондиционера, а то сервера жарят знатно, а помещение маленькое.
Поговорим о трех проблемах, связанных с работой дата-центров. Посмотрим, какие решения могут предложить технологические стартапы.

Управлять сетевой инфраструктурой дата-центра сложно. На то есть несколько причин: высокая плотность размещения серверов и систем хранения данных и чуть ли не «доисторические» способы оценки состояния инфраструктуры. Одним из самых популярных инструментов для управления ЦОД по-прежнему остаются таблицы Excel, в которых администраторы отслеживают, какую железку нужно настроить или заменить.
Подобное «ручное управление» приводит к сбоям. По статистике, в 80% сбоев сетевой инфраструктуры виноват человек. В среднем, такая ошибка обходится в 140 тыс. долларов. Восстановление — это еще и время.
По этим причинам IT-индустрия старается автоматизировать настройку сетей и исключить человеческий фактор. В этой области есть много различных разработок. Одной из них является технология intent-based networking (IBN). В переводе это означает «сети, управляемые на основе намерений».
«Намерения» — это модель поведения сети (шаблон), которую задает системный администратор. Она формулируется в виде бизнес-требований, а сеть самостоятельно определяет, что нужно делать. Например, если дать системе установку: «Нужно расширить базу данных для приложения», то она сама выделит и подключит дополнительные вычислительные мощности в дата-центре. Если сказать: «Нужно развернуть приложение для обеспечения безопасности», система составит правила для файрвола и маршрутизаторов.
Одним из первых разрабатывать IBN-системы стал стартап Apstra. Их сервис называется Apstra Operating System (AOS). Администратор задает количество серверов, прописывает политики доступа, число компьютеров в сети и другие требования. После сервис сам строит схему инфраструктуры, в которой назначает устройствам в сети роли, например сервер или роутер. Сисадмину остается лишь утвердить её — настройка произойдет автоматически.
Похожий IBN-сервис разработан и ИТ-гигантом Cisco — система называется DNA Center. Один из кейсов использования — сеть в детском госпитале Лос-Анджелеса. Система ускорила настройку сетевой инфраструктуры на 50–90% и вполовину снизила количество сбоев в работе IT-инфраструктуры больницы. На основе таких показателей аналитики Gartner прогнозируют, что IBN-технологиями будут пользоваться тысячи компаний по всему миру.
Ранее на долю ЦОД приходились 2% всей потребляемой электроэнергии в мире. Ожидается, что к 2020 году эта цифра «скакнет» до 5%, а к 2025 уже достигнет небывалых 10%. Вместе с этим вырастет количество выбросов CO2 в атмосферу. Ухудшающаяся экология и увеличивающиеся счета за электричество — два главных драйвера появления «зеленых» технологий в дата-центрах.
Компании, которые работают в этой сфере, стремятся оптимизировать процессы управления электропитанием в ЦОД также за счет автоматизации. Одну из таких систем предлагает стартап Virtual Power Systems (VPS). Он помогает перераспределять энергию между оборудованием в дата-центре.
Решение компании состоит из аккумуляторов, датчиков, собирающих информацию о расходе электричества, и ПО для анализа данных — ICE Console. Когда система обнаруживает, что какому-то серверу требуется большая мощность (например, на него выросла нагрузка), она задействует доп. аккумуляторы. Если же сервер находится в «режиме ожидания», то его энергопотребление снижается. ICE повышает процент эффективного использования электричества до 80%. Обычно он составляет лишь 20–50%.
Отметим, что такие решения окажутся неэффективны, если при выборе «железа» дата-центр допустил серьёзные просчеты. Например, было куплено слишком мощное железо или недостаточное количество блоков питания. По статистике почти 80% компаний не знает, сколько потребляют их серверы, потому нерационально использует электроэнергию.

Есть и более «разумные» системы управления электропитанием, работа которых базируется на машинном обучении (МО). Такими системами чаще всего занимаются IT-гиганты вроде Google. Например, они запустили интеллектуальную систему для управления кондиционированием в ЦОД.
IT-инфраструктуру компании мониторит несколько тысяч сенсоров. Они учитывают множество параметров: начиная от нагрузки на серверы и заканчивая скоростью ветра на улице. Все эти данные поступают на вход системы искусственного интеллекта, которую компания размещает в облаке.
Эта система составляет список действий (например, ускорить вентиляторы кондиционера или перенаправить потоки воздуха), которые повлияют на энергопотребление. Затем выбирает из них наиболее эффективное.
Однажды алгоритм МО сам «догадался», что холодный воздух с улицы в зимнее время эффективнее охлаждает помещение и использовал это знание, чтобы на треть сократить энергозатраты на системы кондиционирования.

По данным экспертов, объемы информации в мире достигнут 163 зеттабайт к 2025 году. Свой вклад в это вносит развивающаяся индустрия интернета вещей (IoT). Ожидается, что число умных гаджетов к тому же 2025 году вырастет до 75 млрд. Сейчас их число едва превышает 23 млрд.
Чтобы смарт-гаджеты работали в режиме реального времени эффективнее, компании разрабатывают системы, которые бы «перенесли» вычислительные возможности ЦОД ближе к конечному пользователю.
Одним из таких стартапов является Vapor IO. Дата-центры компании — небольшие контейнеры с оборудованием, которые устанавливаются в основании вышек сотовой связи и подключаются к мобильной сети.
Каждый такой дата-центр способен принять и обработать данные от пользователей в радиусе 10–20 километров. ЦОД соединены в единую структуру, и при сбоях в одном из них трафик перераспределяется между «соседями». Американские компании воспользуются технологией уже скоро: к 2020 году Vapor IO планирует развернуть сеть в 20 крупных городах США.
Подобные технологии должны помочь компаниям не отставать от прогресса в области строительства дата-центров и обеспечить подключение для грядущей флотилии дронов и автономных роботов. Они подтолкнут развитие всех сфер деятельности: начиная от беспилотных автомобилей и заканчивая медициной с умными девайсами для мониторинга здоровья пациентов.
Строительство:
Сервера перед установкой:
Монтаж в стойки:
Рабочие коридоры:
ОЖИДАНИЕ





Суровая Реальность











