В фильме кибер-террористическая группировка массово взламывает компьютеры которые связаны с важной гражданской инфраструктурой, в следствие чего падают самолеты, отключается электроэнергия и интернет, GPS тоже перестает работать. В это время пролетают беспилотники которые разбрасывают листовки на арабском, со словами в духе "Смерть Америке!". Герои узнают что в других регионах были сброшены другие листовки, на китайском (мандаринском) языке.
Однако в фильме также есть подсказки что все не так просто как кажется и возможно тут замешана операция под фальшивым флагом и на самом деле это госпереворот/глубинное государство. При этом всем на Нью-Йорк летит ядерка.
Higher Ground Productions которая продюсировала фильм основана Мишель и Бараком Обамой в 2018 году. Фильм называется Оставить мир позади "Leave the World Behind"
Ранее в США обвинили Иранскую анти-израильскую группировку во взломе водоочистительной инфраструктуры в Пенсильвании
Способ 1) Для этого нужно использовать русско английскую клавиатуру, на ней каждой русской букве соответствует английская практически, есть буквы у которых английской буквы нет потому что русских букв 33 а английских 26.
Так вот придумываем или используется самое привычное для вас слово, своё имя, отчество, фамилию свою или девичью матери или девичью бабушки то есть то что вы хрен уже забудете находясь в добром здравии и доброй памяти.
Например имени Александр будут соответствовать следующие английские буквы русско английской клавиатуры FKTRCFYLH.
Владимир будет русским буквам на клавиатуре соответствовать следующие ангельские DKFLBVBH и так далее
Способ 2) Потребуется десять символов первый вариант это строка из английского алфавита ABCDEFGHIJKL его многие знают наизусть.
Вторая строка это снова клавиатура, первый ряд символов русско английских их ровно десять сколько нам и надо QWERTYUIOP
Теперь любое число мы можем привести в набор символов двумя способами. За нулевой символ разумно использовать последний десятый, иначе если первый то будет менее удобно, всё окажется сдвинутым на единицу, 1 будет соответствовать второй символ и так далее что менее удобно чем если 1 соответствует первый символ буква.
Например
Дата рождения человека предположим 22.11.1987 переводим её в символы по строке алфавита английского BBAAAKJI
по строке клавиатуры первой, которая содержит 10 русско английских букв и находится сразу под цифрами WWQQQOIU
также можно перевести номер своего телефона или телефонов которые вы хорошо знаете.
Способ 3) Каждому символу, букве соответствует номер в алфавите, то есть переводим буквы в их порядковые номера в алфавите, числа, и записываем последовательность это и будет паролем. Алфавиты большинство хорошо помнят, но если даже и подзабыли подучить и вспомнить их совершенно не помешает, или можно иметь картинку с алфавитами английским и русскими по рукой, знать стоит наизусть как английский алфавит так и русский.
Например имя Катя 12(К) 1(А) 20(Т) 33(Я). И можно совместить Катя1212033
и пусть подбирают хакеры эту последовательность.
Способ 4) Написание хорошо известного, любимого вами слова, имени, фамилии, задом наперёд. Например Иванов будет Вонави, Петров будет Вортеп, Сидоров будет Вородис. К получившимся словам неочевидным но легко восстанавливаемым, можно добавить какое нибудь любимое вами число например год вашего рождения и тоже написанное задом наперёд.
Способ 5) Комбинация и букв и чисел. Например придумали вышеприведенным способом себе пароль из букв и добавляем к нему еще и циферки например год своего рождения написанный к примеру тремя способами, обычным 1987 или задом наперед 7891 или перенос пары последних цифр в перёд или двух первых назад даст тот же результат 8719 то есть зная что вы так оперируете своим цифрами года рождения у вас всего три варианта их написания, можно сделать больше при желании. И добавляем к паролю из букв год своего или даты рождения записанного обычно или необычно по приведенным выше или вашим собственным правилам.
Мне кажется такие пароли получаются непростыми для подбора при переборе наиболее распространенных слов например, но в тоже время простыми для восстановления и запоминания. Конечно никакие пароли не защитят от серьезных хакеров поэтому компрометирующую вас информацию лучше не хранить на устройствах подключенных к сети интернет, спиздят и ни здрасть ни до свидания не скажут, в легкую.
ЗЫ Более устойчивы пароли если вы используете больше вариантов символов в пароле, например если мы используем только цифры то каждый символ имеет 10 вариантов, если буквы английские и числа то уже 10+26 = 36 вариантов может иметь каждый символ, если буквы большие, мелкие и цифры то вариантов символа в пароле уже будет 10+26+26 = 62. Поэтому многие сайты просят нас использовать и маленькие буквы и большие и числа и даже специальные знаки чтобы пароль был максимально сложным для подбора. Чем большее число символов используется при составлении (цифры, буквы заглавные и мелкие, спецсимволы) пароля тем сложнее его будет взломать хакерам говнякерам методом перебора.
ЗЫ2 Чтобы проще переводить цифры в буквы и буквы в цифры разумно иметь под рукой, на компьютере алфавиты русский и английский с приписанными каждой букве её порядковым номером, картинкой с клавиатурой русско английской если например её не окажется под рукой, иметь возможность глянуть как шифровать слова и цифры. Можно и написать последовательности две из десяти символов из QWERTYUIOP и ABCDEFGHIJKL с подписанными порядковыми номерами для того чтобы не считать, какой букве соответствует десятизначное число, а глянул и сразу узнал какой букве какой номер соответствует, это упростит шифрацию и дешифрацию букв и цифр.
В этой статье мы создадим инструмент, проверяющий схему базы данных (например, имена столбцов) в поиске ценной информации. Допустим, нам нужно найти пароли, хеши, номера социального страхования и кредитных карт. Вместо написания единой утилиты, добывающей информацию из различных БД, мы создадим раздельные программы — по одной для каждой БД — и задействуем конкретный интерфейс, обеспечивая согласованность между их реализациями. Такая гибкость может оказаться излишней для данного примера, но она дает возможность создать переносимый код, который можно использовать повторно.
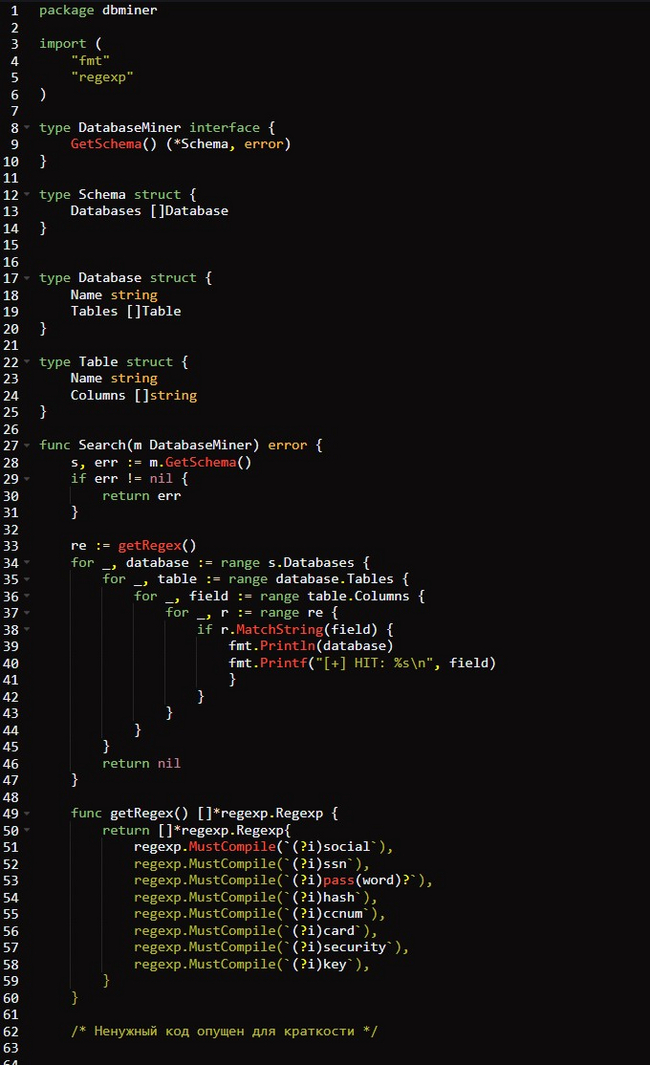
Интерфейс должен быть минимальным, то есть состоять из нескольких базовых типов и функций, требуя реализации всего одного метода для извлечения схемы базы данных. В коде ниже определяется именно такой интерфейс майнера с названием 𝗱𝗯𝗺𝗶𝗻𝗲𝗿.𝗴𝗼.
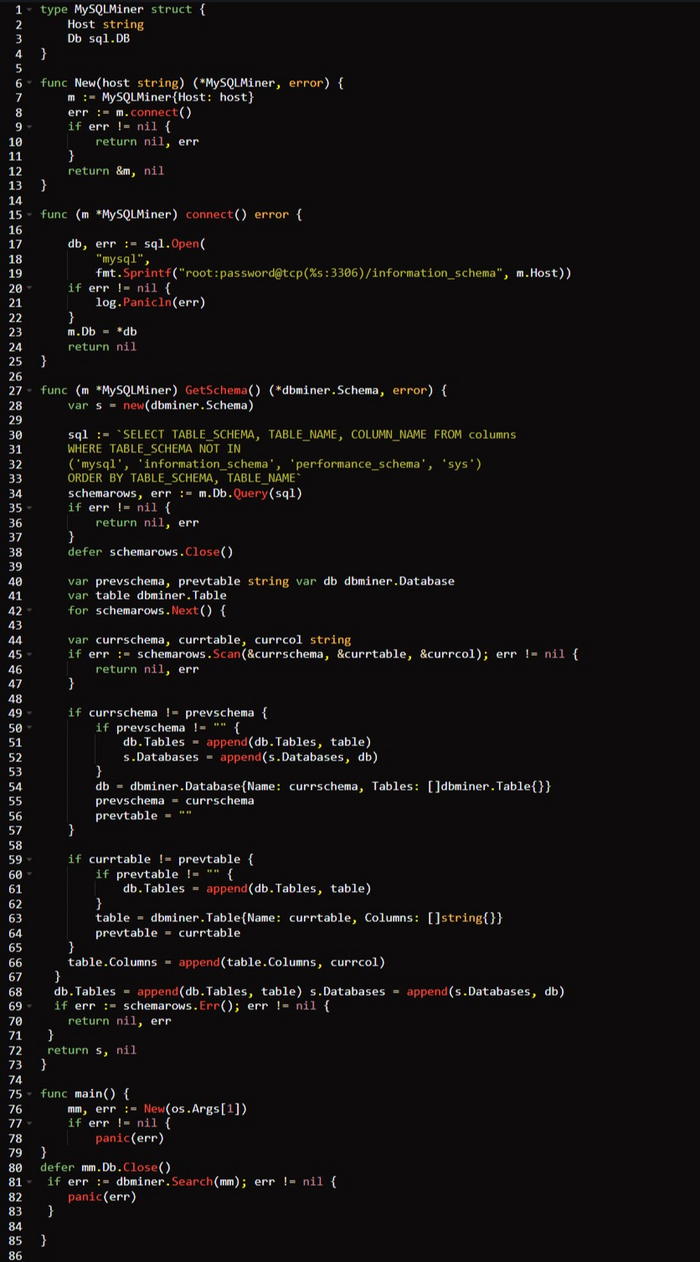
Реализация майнера данных /db/dbminer/dbminer.go
Код начинается с определения интерфейса DatabaseMiner. Для реализующих этот интерфейс типов будет требоваться один-единственный метод — GetSchema(). Поскольку каждая серверная база данных может иметь собственную логику для извлечения данной схемы, подразумевается, что каждая конкретная утилита сможет реализовать эту логику уникальным для используемых БД и драйвера способом.
Далее мы определяем тип 𝗦𝗰𝗵𝗲𝗺𝗮, состоящий из нескольких подтипов, которые определены здесь же. Тип 𝗦𝗰𝗵𝗲𝗺𝗮 задействуется для логического представления схемы БД, то есть баз данных, таблиц и столбцов. Вы могли обратить внимание на то, что функция 𝗚𝗲𝘁𝗦𝗰𝗵𝗲𝗺𝗮() в определении интерфейса ожидает, что реализации вернут *𝗦𝗰𝗵𝗲𝗺𝗮.
Далее идет определение одной функции 𝗦𝗲𝗮𝗿𝗰𝗵() с объемной логикой. Эта функция ожидает передачи экземпляра 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝗠𝗶𝗻𝗲𝗿 и сохраняет значение майнера в переменной 𝗺. Начинается она с вызова 𝗺.𝗚𝗲𝘁𝗦𝗰𝗵𝗲𝗺𝗮() для извлечения схемы. Затем функция перебирает всю эту схему в поиске списка соответствующих значений регулярному выражению (𝗿𝗲𝗴𝗲𝘅). При нахождении соответствий схема базы данных и совпадающие поля выводятся на экран.
В завершение мы определяем функцию 𝗴𝗲𝘁𝗥𝗲𝗴𝗲𝘅(). Она компилирует строки регулярных выражений с помощью пакета 𝗚𝗼 𝗿𝗲𝗴𝗲𝘅𝗽 и возвращает срез их значений. Список 𝗿𝗲𝗴𝗲𝘅 состоит из нечувствительных к регистру строк, которые сопоставляются со стандартными или интересующими нас именами полей, например 𝗰𝗰𝗻𝘂𝗺, 𝘀𝘀𝗻 и 𝗽𝗮𝘀𝘀𝘄𝗼𝗿𝗱.
Теперь, имея в распоряжении интерфейс добытчика, можно создать особые реализации утилит. Начнем с добытчика данных из 𝗠𝗼𝗻𝗴𝗼𝗗𝗕.
Реализация майнера данных из MongoDB:
Утилита для работы с MongoDB, показанная в коде ниже, реализует интерфейс из кода Реализации майнера данных, а также интегрирует код подключения к базе данных, который я написал в предыдущем посте (Подключение к базе данных MongoDB).
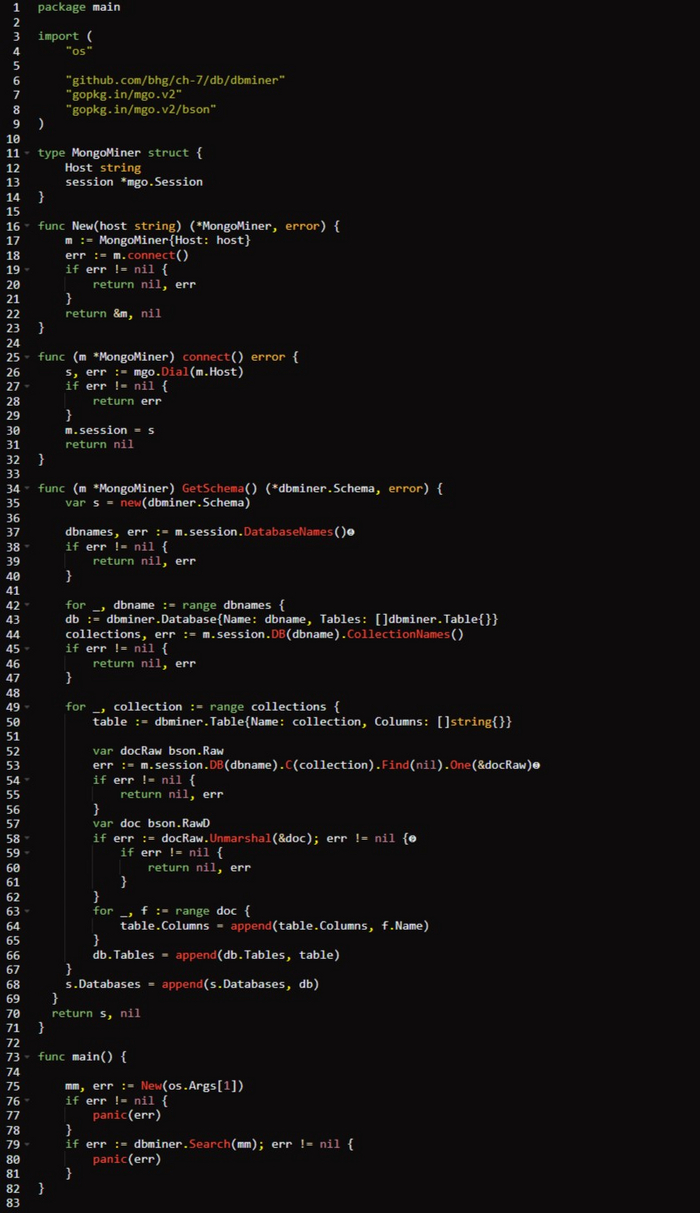
Создание майнера для MongoDB /db/mongo/main.go
Вначале мы импортируем пакет 𝗱𝗯𝗺𝗶𝗻𝗲𝗿, определяющий интерфейс 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝗠𝗶𝗻𝗲𝗿. Затем прописываем тип 𝗠𝗼𝗻𝗴𝗼𝗠𝗶𝗻𝗲𝗿, который будет использоваться для реализации этого интерфейса. Для удобства также реализуется функция 𝗡𝗲𝘄(), создающая новый экземпляр типа 𝗠𝗼𝗻𝗴𝗼𝗠𝗶𝗻𝗲𝗿, вызывая метод 𝗰𝗼𝗻𝗻𝗲𝗰𝘁(), который устанавливает подключение к базе данных. В совокупности эта логика производит начальную загрузку кода, выполняя подключение к базе данных аналогичным рассмотренному в листинге 𝟳.𝟲 способом.
Самая интересная часть кода содержится в реализации метода интерфейса 𝗚𝗲𝘁𝗦𝗰𝗵𝗲𝗺𝗮(). В отличие от примера кода 𝗠𝗼𝗻𝗴𝗼𝗗𝗕 из кода (Предыдущий Пост) Подключение к базе данных MongoDB и запрос данных , теперь мы проверяем метаданные 𝗠𝗼𝗻𝗴𝗼𝗗𝗕, сначала извлекая имена баз данных, а затем перебирая эти базы данных для получения имен коллекции каждой. В завершение эта функция получает сырой документ, который, в отличие от типичного запроса 𝗠𝗼𝗻𝗴𝗼𝗗𝗕, использует отложенный демаршалинг. Это позволяет явно демаршалировать запись в общую структуру и проверить имена полей. Если бы не возможность такого отложенного демаршалинга, пришлось бы определять явный тип, скорее всего, использующий атрибуты тега 𝗯𝘀𝗼𝗻, инструктируя программу о порядке демаршалинга данных в определенную нами структуру. В этом случае мы не знаем о типах полей или структуре (или нам все равно), нам просто нужны имена полей (не данные) — именно так можно демаршалировать структурированные данные, не зная структуры заранее.
Функция 𝗺𝗮𝗶𝗻() ожидает 𝗜𝗣-адрес экземпляра 𝗠𝗼𝗻𝗴𝗼𝗗𝗕 в качестве единственного аргумента, вызывает функцию 𝗡𝗲𝘄() для начальной загрузки всего, после чего вызывает 𝗱𝗯𝗺𝗶𝗻𝗲𝗿.𝗦𝗲𝗮𝗿𝗰𝗵(), передавая ему экземпляр 𝗠𝗼𝗻𝗴𝗼𝗠𝗶𝗻𝗲𝗿. Напомним, что 𝗱𝗯𝗺𝗶𝗻𝗲𝗿.𝗦𝗲𝗮𝗿𝗰𝗵() вызывает 𝗚𝗲𝘁𝗦𝗰𝗵𝗲𝗺𝗮() в полученном экземпляре 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝗠𝗶𝗻𝗲𝗿. Таким образом происходит вызов реализации функции 𝗠𝗼𝗻𝗴𝗼𝗠𝗶𝗻𝗲𝗿, что приводит к созданию 𝗱𝗯𝗺𝗶𝗻𝗲𝗿.𝗦𝗰𝗵𝗲𝗺𝗮, которая затем просматривается на соответствие списку 𝗿𝗲𝗴𝗲𝘅 из кода Реализация майнера данных.
Совпадение найдено! Выглядит она не очень аккуратно, но работу выполняет исправно — успешно обнаруживает коллекцию базы данных, содержащую поле ccnum.
Разобравшись с реализацией для MongoDB, в следующем разделе сделаем то же самое для серверной базы данных MySQL.
Реализация майнера для MySQL
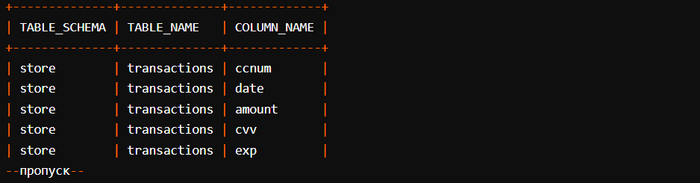
Чтобы реализация 𝗠𝘆𝗦𝗤𝗟 заработала, мы будем проверять таблицу 𝗶𝗻𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝗼𝗻_𝘀𝗰𝗵𝗲𝗺𝗮.𝗰𝗼𝗹𝘂𝗺𝗻𝘀. Она содержит метаданные обо всех базах данных и их структурах, включая таблицы и имена столбцов. Чтобы максимально упростить потребление данных, используйте приведенный далее 𝗦𝗤𝗟-запрос. Он удалит информацию о некоторых из встроенных БД 𝗠𝘆𝗦𝗤𝗟, не имеющих для нас значения:
В результате данного запроса вы получите примерно такие результаты:
Несмотря на то что использовать этот запрос для извлечения информации схемы довольно просто, сложность кода обусловливается стремлением логически дифференцировать и категоризировать каждую строку при определении функции GetSchema(). Например, последовательные строки вывода могут принадлежать или не принадлежать одной базе данных/таблице, поэтому ассоциирование строк с правильными экземплярами dbminer.Database и dbminer.Table становится несколько запутанным.
В коде снизу показана реализация:
Создание майнера для MySQL /db/mysql/main.go/
Бегло просмотрев код, вы можете заметить, что большая его часть очень похожа на пример для MongoDB из предыдущего раздела. В частности, идентична функция main().
Функции начальной загрузки также очень похожи — изменяется лишь логика на взаимодействие с MySQL, а не MongoDB. Обратите внимание на то, что эта логика подключается к базе данных information.schema, позволяя проинспектировать схему базы данных.
Основная сложность этого кода заключена в реализации 𝗚𝗲𝘁𝗦𝗰𝗵𝗲𝗺𝗮(). Несмотря на то что мы можем извлечь информацию схемы, используя один запрос к БД, после приходится перебирать результаты, просматривая каждую строку с целью определения присутствующих баз данных, их таблиц и строк этих таблиц. В отличие от реализации для 𝗠𝗼𝗻𝗴𝗼𝗗𝗕, у нас нет преимущества 𝗝𝗦𝗢𝗡/𝗕𝗦𝗢𝗡 с тегами атрибутов для маршалинга и демаршалинга данных в сложные структуры. Мы используем переменные для отслеживания информации в текущей строке и сравниваем ее с данными из предыдущей строки, чтобы понять, когда встретим новую базу данных или таблицу. Не самое изящное решение, но с задачей справляется.
Далее идет проверка соответствия имен баз данных текущей и предыдущей строк. Если они совпадают, создается новый экземпляр 𝗺𝗶𝗻𝗲𝗿.𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲. Если это не первая итерация цикла, таблица и база данных добавляются в экземпляр 𝗺𝗶𝗻𝗲𝗿.𝗦𝗰𝗵𝗲𝗺𝗮. С помощью аналогичной логики мы отслеживаем и добавляем экземпляры 𝗺𝗶𝗻𝗲𝗿.𝗧𝗮𝗯𝗹𝗲 в текущую 𝗺𝗶𝗻𝗲𝗿𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲. В завершение каждый столбец добавляется в 𝗺𝗶𝗻𝗲𝗿.𝗧𝗮𝗯𝗹𝗲.
Теперь запустите готовую программу в отношении экземпляра 𝗗𝗼𝗰𝗸𝗲𝗿 𝗠𝘆𝗦𝗤𝗟, чтобы убедиться в корректности ее работы:
Вывод должен получиться практически идентичным выводу для 𝗠𝗼𝗻𝗴𝗼𝗗𝗕. Причина в том, что 𝗱𝗯𝗺𝗶𝗻𝗲𝗿.𝗦𝗰𝗵𝗲𝗺𝗮 не производит никакого вывода — это делает функция 𝗱𝗯𝗺𝗶𝗻𝗲𝗿.𝗦𝗲𝗮𝗿𝗰𝗵(). В этом заключается сила интерфейсов. Можно использовать конкретные реализации ключевых возможностей, задействуя при этом одну стандартную функцию для обработки данных прогнозируемым эффективным способом. В следующем разделе мы отойдем от БД и рассмотрим кражу данных из файловых систем.
Получение данных из файловых систем:
В этом разделе мы создадим утилиту, рекурсивно обходящую предоставленный пользователем путь файловой системы, сопоставляя ее содержимое со списком имен файлов, интересующих нас в процессе постэксплуатации. Эти файлы могут содержать помимо прочего личную информацию, имена пользователей, пароли и логины системы.
Данная утилита просматривает именно имена файлов, а не их содержимое. При этом скрипт существенно упрощается тем, что пакет Go path/filepath предоставляет стандартную функциональность, с помощью которой можно эффективно обходить структуру каталогов. Сама утилита приведена в коде ниже.
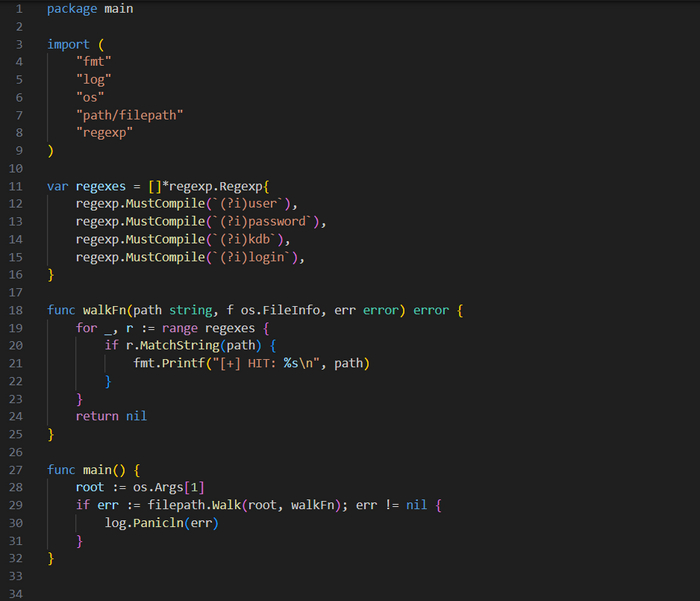
Обход файловой системы /filesystem/main.go
В отличие от реализации майнеров данных из БД, настройка и логика инструмента для кражи информации из файловой системы могут показаться слишком простыми. Аналогично тому, как мы создавали реализации для баз данных, вы определяете список для определения интересующих имен файлов. Чтобы максимально сократить код, мы ограничили этот список всего несколькими элементами, но его вполне можно расширить, чтобы он стал более практичным.
Далее идет определение функции walkFn(), которая принимает путь файла и ряд дополнительных параметров. Эта функция перебирает список регулярных выражений в поиске совпадений, которые выводит в stdout. Функция walkFn() используется в функции main() и передается в качестве параметра в filepath.Walk(). Walk() ожидает два параметра — корневой путь и функцию (в данном случае walkFn()) — и рекурсивно обходит структуру каталогов, начиная с переданного корневого пути и попутно вызывая walkFn() для каждого встречающегося каталога и файла.
Написав утилиту, перейдите на рабочий стол и создайте следующую структуру каталогов:
Выполнение утилиты в отношении той же папки targetpath производит следующий вывод, подтверждая, что код работает исправно:
Вот и все, что касается данной темы. Вы можете улучшить этот образец кода, включив в него дополнительные регулярные выражения. Я также посоветую вам доработать его, применив проверку regex только для имен файлов, но не каталогов. Помимо этого, рекомендую найти и отметить конкретные файлы с недавним временем доступа или внесения изменений. Эти метаданные могут привести к более важному содержимому, включая файлы, используемые в значимых бизнес-процессах.
Несмотря на наличие прекрасного стандартного 𝗦𝗤𝗟-пакета, 𝗚𝗼 не поддерживает аналогичный пакет для работы с базами данных 𝗡𝗼𝗦𝗤𝗟. Для этого вам придется использовать сторонние инструменты. Вместо изучения реализации каждого такого стороннего пакета мы сосредоточимся исключительно на 𝗠𝗼𝗻𝗴𝗼𝗗𝗕. Для этого будем применять драйвер 𝗺𝗴𝗼 (произносится «манго»). Начните с установки 𝗺𝗴𝗼:
Теперь можно установить подключение и запросить коллекцию 𝘀𝘁𝗼𝗿𝗲 (эквивалент таблицы), для чего потребуется еще меньше кода, чем в примере с 𝗦𝗤𝗟, который мы создадим чуть позже.
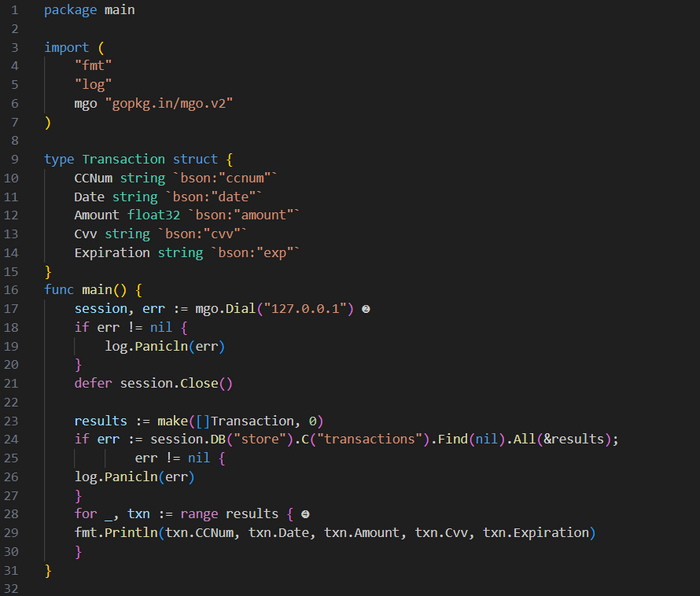
Подключение к базе данных MongoDB и запрос данных
Сначала идет определение типа 𝗧𝗿𝗮𝗻𝘀𝗮𝗰𝘁𝗶𝗼𝗻, который будет представлять один документ из коллекции 𝘀𝘁𝗼𝗿𝗲. Внутренний механизм представления данных в 𝗠𝗼𝗻𝗴𝗼𝗗𝗕 — это двоичный 𝗝𝗦𝗢𝗡. По этой причине для определения любых директив маршалинга используются теги. В этом случае с их помощью мы явно определяем имена элементов для применения в двоичных данных 𝗝𝗦𝗢𝗡.
В функции 𝗺𝗮𝗶𝗻() вызов 𝗺𝗴𝗼.𝗗𝗶𝗮𝗹() создает сессию, устанавливая подключение к базе данных, выполняя тестирование на наличие ошибок и реализуя отложенный вызов для закрытия сессии. После этого с помощью переменной 𝘀𝗲𝘀𝘀𝗶𝗼𝗻 запрашивается база данных 𝘀𝘁𝗼𝗿𝗲, откуда извлекаются все записи коллекции 𝘁𝗿𝗮𝗻𝘀𝗮𝗰𝘁𝗶𝗼𝗻𝘀. Результаты мы сохраняем в срезе 𝗧𝗿𝗮𝗻𝘀𝗮𝗰𝘁𝗶𝗼𝗻 под названием 𝗿𝗲𝘀𝘂𝗹𝘁𝘀. Теги структуры используются для демаршалинга двоичного 𝗝𝗦𝗢𝗡 в определенный нами тип. В завершение выполняется перебор результатов и их вывод на экран. И в этом случае, и в примере с 𝗦𝗤𝗟 из следующего раздела вывод должен выглядеть так:
Обращение к базам данных SQL:
𝗚𝗼 содержит стандартный пакет 𝗱𝗮𝘁𝗮𝗯𝗮𝘀𝗲/𝘀𝗾𝗹, который определяет интерфейс для взаимодействия с базами данных 𝗦𝗤𝗟 и их аналогами. Базовая реализация автоматически включает такую функциональность, как пул подключений и поддержка транзакций. Драйверы базы данных, соответствующие этому интерфейсу, автоматически наследуют эти возможности и, по сути, являются взаимозаменяемыми, поскольку 𝗔𝗣𝗜 между ними остается согласованным. Вызовы функций и реализация в коде идентичны независимо от того, используете вы 𝗣𝗼𝘀𝘁𝗴𝗿𝗲𝘀, 𝗠𝗦𝗦𝗤𝗟, 𝗠𝘆𝗦𝗤𝗟 или другой драйвер. В результате этого удобно менять серверные базы данных при минимальном изменении кода клиента. Конечно же, эти драйверы могут реализовывать специфичные для БД возможности и задействовать различный 𝗦𝗤𝗟-синтаксис, но вызовы функций при этом практически одинаковы. Поэтому мы покажем, как подключать всего одну базу данных 𝗦𝗤𝗟 — 𝗠𝘆𝗦𝗤𝗟, а остальные БД 𝗦𝗤𝗟 оставим в качестве самостоятельного упражнения. Начнем с установки драйвера:
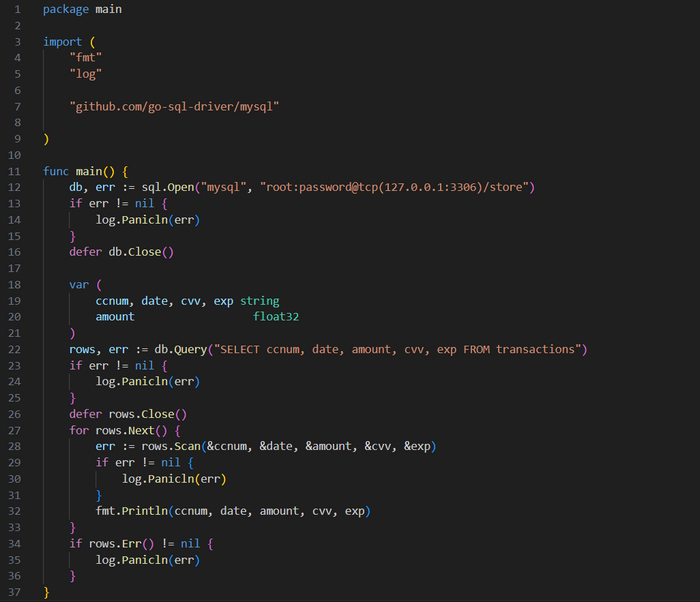
Далее создадим простой клиент, который подключается к этой базе данных и извлекает информацию из таблицы transactions, как показано в коде ниже.
Код начинается с импорта пакета 𝗚𝗼 𝗱𝗮𝘁𝗮𝗯𝗮𝘀𝗲/𝘀𝗾𝗹. Это позволяет реализовать взаимодействие с базой данных через удобный интерфейс стандартной библиотеки 𝗦𝗤𝗟. Кроме того, мы импортируем драйвер базы данных. Начальное подчеркивание указывает на то, что она импортируется анонимно, то есть ее экспортируемые типы не включаются, но драйвер регистрируется пакетом 𝘀𝗾𝗹, и в результате драйвер 𝗠𝘆𝗦𝗤𝗟 сам обрабатывает вызовы функций.
Далее идет вызов 𝘀𝗾𝗹.𝗢𝗽𝗲𝗻() для установки подключения к базе данных. Первый параметр указывает, какой драйвер использовать — в данном случае это 𝗺𝘆𝘀𝗾𝗹, а второй определяет строку подключения. Затем мы обращаемся к базе данных, передавая инструкцию 𝗦𝗤𝗟 для выбора всех строк из таблицы 𝘁𝗿𝗮𝗻𝘀𝗮𝗰𝘁𝗶𝗼𝗻𝘀, после чего перебираем эти строки, последовательно считывая данные в переменные и выводя значения.
Это все, что необходимо для запроса данных из 𝗠𝘆𝗦𝗤𝗟. Для использования другой серверной БД потребуется внести в код лишь минимальные изменения:
импортировать подходящий драйвер базы данных;
изменить передаваемые в sql.Open() параметры;
скорректировать SQL-синтаксис в соответствии с требованиями серверной базы данных.
Среди нескольких доступных драйверов баз данных часть написаны на чистом 𝗚𝗼. А некоторые другие используют 𝗰𝗴𝗼 для ряда внутренних взаимодействий. Полный список доступных драйверов можно найти здесь: 𝗵𝘁𝘁𝗽𝘀://𝗴𝗶𝘁𝗵𝘂𝗯.𝗰𝗼𝗺/𝗴𝗼𝗹𝗮𝗻𝗴/𝗴𝗼/𝘄𝗶𝗸𝗶/𝗦𝗤𝗟𝗗𝗿𝗶𝘃𝗲𝗿𝘀/.
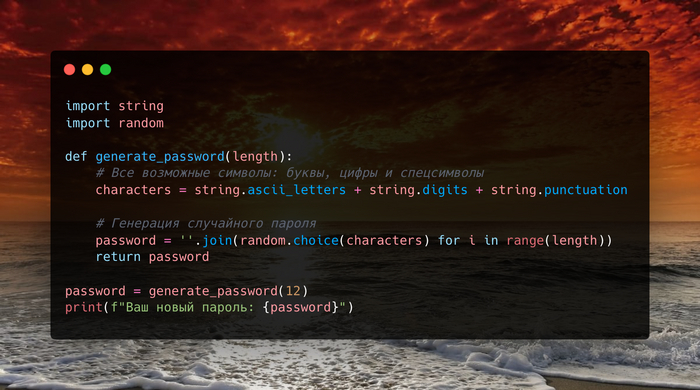
Привет, друзья Pikabu! Сегодня мы поговорим о том, как можно использовать Python для создания чего-то полезного и интересного. Мы напишем простой генератор паролей, который поможет вам создавать безопасные пароли для ваших аккаунтов.
Шаг 1: Импорт необходимых библиотек Для начала нам понадобятся две библиотеки: string и random. Библиотека string содержит полезные константы, такие как буквы и цифры, а random поможет нам выбирать символы случайным образом.
Шаг 2: Создание функции для генерации пароля Теперь давайте создадим функцию, которая будет генерировать пароль. Эта функция будет принимать один параметр: длину пароля.
Шаг 3: Использование функции Теперь мы можем использовать эту функцию для генерации пароля. Давайте создадим пароль длиной в 12 символов.
И вот мы создали простой, но эффективный генератор паролей на Python! Этот скрипт можно доработать, добавив в него дополнительные функции, например, проверку сложности пароля. Надеюсь, вам понравился этот мини-проект. Делитесь в комментариях, какие еще интересные вещи вы создавали с помощью Python!
Предыстория, один клиент в компании попросил проверить пк сотрудника после упадка продаж, он реально думал что сливали заказы копированием или как то доступом через crm в общем упадок был, а понять как и отследить было сложно. Так для тех кто в теме, скрипт я переделал под exe прятался он под pdf прайсом. а в диспетчере скрыт. И пост не для программистов.
Попросили меня проверить, результат порадовал, но причастность доказать нереально кто из менеджеров запустил данный софт. Схема проста, покупается зарубежный виртуальный номер на который регистрируется аккаунт телеграмм и через которого создаётся бот.
Рекомендую всем проверять отправки на порты телеги возможно вы тот самый за кем шпионит жена, муж, начальник или конкурент.
Находку я немного переписал, потому что она была зашита под файлом но выполняла почто такой же функционал как на видео.
Кто такие “White hats - Белы шляпы” ?
“White hats - Белы шляпы” - это термин, используемый для обозначения этичных хакеров, которые используют свои навыки для улучшения кибербезопасности.
Они работают на благо общества, помогая организациям обнаруживать и устранять уязвимости в их системах безопасности.
Белые шляпы проводят тестирование на проникновение и другие проверки безопасности, чтобы обнаружить потенциальные угрозы.
В отличие от “Black hats”, белые шляпы действуют законно и с разрешения владельцев систем.
Работа белых шляп важна для поддержания безопасности в интернете и защиты данных пользователей от злоумышленников. Всё тестировалось в среде на виртуальных машинах и ведео не в коем образом не пропагандирует взлом или как то его рекламирует. Видео несёт информационный характер в сфере Pentest. Tg@Windall
В этой статье мы установим различные системы баз данных, а затем заполним их информацией, которую сами же и будем красть в последующих примерах. Везде, где возможно, используем 𝗗𝗼𝗰𝗸𝗲𝗿 из-под виртуальной машины 𝗨𝗯𝘂𝗻𝘁𝘂 𝟭𝟴.𝟬𝟰. 𝗗𝗼𝗰𝗸𝗲𝗿 — это платформа создания контейнеров ПО, упрощающая развертывание приложений и управление ими. Она дает возможность связывать программы упрощающим развертывание способом. При этом контейнер остается отделенным от операционной системы, что предотвращает «загрязнение» хостовой машины. Это очень классная штука.
Для данной главы мы задействуем несколько предварительно настроенных образов 𝗗𝗼𝗰𝗸𝗲𝗿 для баз данных, с которыми будем работать. Если 𝗗𝗼𝗰𝗸𝗲𝗿 у вас еще не установлен, то инструкции по его установке в 𝗨𝗯𝘂𝗻𝘁𝘂 вы найдете здесь: 𝗵𝘁𝘁𝗽𝘀://𝗱𝗼𝗰𝘀.𝗱𝗼𝗰𝗸𝗲𝗿.𝗰𝗼𝗺/𝗶𝗻𝘀𝘁𝗮𝗹𝗹/𝗹𝗶𝗻𝘂𝘅/𝗱𝗼𝗰𝗸𝗲𝗿-𝗰𝗲/𝘂𝗯𝘂𝗻𝘁𝘂/
Мы намеренно опустили детали настройки экземпляра Oracle. Несмотря на то что Oracle предоставляет образы виртуальных машин, которые можно скачать и использовать для создания тестовой БД, мы посчитали, что знакомить вас со всеми этими действиями необязательно, поскольку они аналогичны приводимым далее примерам с MySQL. Поэтому реализация версий программы с применением Oracle остается для вас домашним заданием.
Установка и заполнение MongoDB:
𝗠𝗼𝗻𝗴𝗼𝗗𝗕 — это единственная база данных 𝗡𝗼𝗦𝗤𝗟, с которой мы будем работать в этой главе. В отличие от традиционных реляционных БД, она не взаимодействует посредством 𝗦𝗤𝗟. Вместо этого 𝗠𝗼𝗻𝗴𝗼𝗗𝗕 для извлечения данных и управления ими использует понятный синтаксис 𝗝𝗦𝗢𝗡. Этому виду баз данных посвящены целые книги, и ее подробное рассмотрение выходит за рамки изучения нашего материала. На данном этапе мы с вами установим образ 𝗗𝗼𝗰𝗸𝗲𝗿 и заполним его фиктивными данными.
В отличие от стандартных баз данных 𝗦𝗤𝗟, 𝗠𝗼𝗻𝗴𝗼𝗗𝗕 не имеет схемы, то есть не придерживается предопределенной жесткой системы организации табличных данных. Это объясняет, почему в коде Внедрение транзакций в коллекцию MongoDB вы видите только команды 𝗶𝗻𝘀𝗲𝗿𝘁 без каких-либо определений схем. Начнем с установки образа 𝗗𝗼𝗰𝗸𝗲𝗿 𝗠𝗼𝗻𝗴𝗼𝗗𝗕:
Эта команда скачает образ 𝗺𝗼𝗻𝗴𝗼 из репозитория 𝗗𝗼𝗰𝗸𝗲𝗿, запустит новый экземпляр 𝘀𝗼𝗺𝗲-𝗺𝗼𝗻𝗴𝗼 (имя можете дать любое) и сопоставит локальный порт 𝟮𝟳𝟬𝟭𝟳 с портом контейнера 𝟮𝟳𝟬𝟭𝟳. Сопоставление портов необходимо, поскольку так мы получаем возможность обращаться к экземпляру базы данных непосредственно из операционной системы. Иначе он был бы недоступен. Проверьте, запустился ли контейнер автоматически, сделав вывод всех выполняющихся контейнеров:
Если автоматически он не запускается, выполните:
Команда 𝘀𝘁𝗮𝗿𝘁 должна запустить контейнер.
После этого подключитесь к экземпляру 𝗠𝗼𝗻𝗴𝗼𝗗𝗕 с помощью команды 𝗿𝘂𝗻, передав ему клиент 𝗠𝗼𝗻𝗴𝗼𝗗𝗕. Таким образом вы можете взаимодействовать с БД для заполнения ее данными:
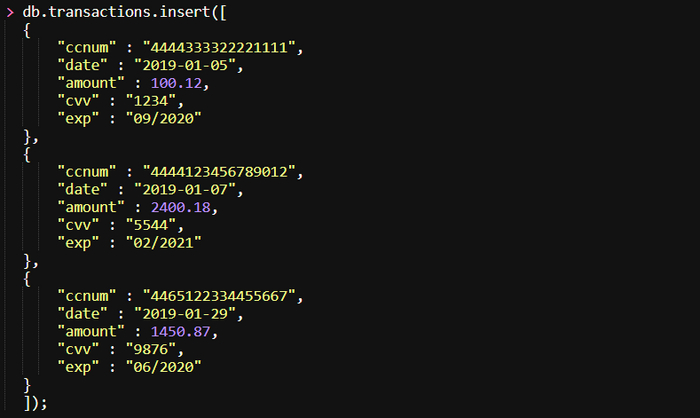
Эта волшебная команда запускает второй, теперь уже одноразовый, контейнер 𝗗𝗼𝗰𝗸𝗲𝗿, в котором установлен исполняемый файл клиента 𝗠𝗼𝗻𝗴𝗼𝗗𝗕 (то есть устанавливать его в систему хоста уже не нужно), и задействует этот контейнер для подключения к экземпляру 𝗠𝗼𝗻𝗴𝗼𝗗𝗕 𝗗𝗼𝗰𝗸𝗲𝗿 контейнера 𝘀𝗼𝗺𝗲-𝗺𝗼𝗻𝗴𝗼. В этом примере выполняется подключение к БД 𝘀𝘁𝗼𝗿𝗲.
В коде ниже мы вставляем массив документов в коллекцию 𝘁𝗿𝗮𝗻𝘀𝗮𝗰𝘁𝗶𝗼𝗻𝘀. (Все листинги кода находятся в корне /𝗲𝘅𝗶𝘀𝘁 репозитория 𝗵𝘁𝘁𝗽𝘀://𝗴𝗶𝘁𝗵𝘂𝗯.𝗰𝗼𝗺/𝗯𝗹𝗮𝗰𝗸𝗵𝗮𝘁-𝗴𝗼/𝗯𝗵𝗴/.)
Вот и все! Таким образом вы создали экземпляр базы данных 𝗠𝗼𝗻𝗴𝗼𝗗𝗕 и заполнили его коллекцией 𝘁𝗿𝗮𝗻𝘀𝗮𝗰𝘁𝗶𝗼𝗻𝘀, которая содержит три фиктивных документа для запросов, чем мы вскоре и займемся. Но сначала вам нужно узнать, как устанавливать и заполнять традиционные базы данных 𝗦𝗤𝗟.
Установка и заполнение баз данных PostgreSQL и MySQL:
𝗣𝗼𝘀𝘁𝗴𝗿𝗲𝗦𝗤𝗟 (также называемая 𝗣𝗼𝘀𝘁𝗴𝗿𝗲𝘀) и 𝗠𝘆𝗦𝗤𝗟 — вероятно, наиболее распространенные и хорошо известные корпоративные реляционные системы баз данных с открытым исходным кодом. При этом официальные образы 𝗗𝗼𝗰𝗸𝗲𝗿 существуют для обеих. Из-за их сходства и в основном одинакового процесса установки мы объединили здесь соответствующие инструкции.
Во-первых, как и в примере с 𝗠𝗼𝗻𝗴𝗼𝗗𝗕, сначала нужно скачать и установить подходящий образ 𝗗𝗼𝗰𝗸𝗲𝗿:
После сборки контейнеров убедитесь, что они работают. Если же нет, их можно запустить с помощью команды 𝗱𝗼𝗰𝗸𝗲𝗿 𝘀𝘁𝗮𝗿𝘁 𝗻𝗮𝗺𝗲. Далее можно подключиться к этим контейнерам из подходящего клиента, опять же используя образ 𝗗𝗼𝗰𝗸𝗲𝗿, чтобы избежать установки дополнительных файлов на хосте, и продолжить создавать, а затем заполнять базу данных. В коде ниже прописана логика 𝗠𝘆𝗦𝗤𝗟.
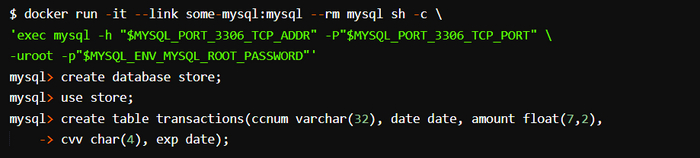
Создание и инициализация базы данных MySQL
Этот листинг, как и последующий, начинается с одноразовой оболочки 𝗗𝗼𝗰𝗸𝗲𝗿, выполняющей соответствующий двоичный файл клиента. Она генерирует базу данных 𝘀𝘁𝗼𝗿𝗲 и подключается к ней, после чего создает таблицу 𝘁𝗿𝗮𝗻𝘀𝗮𝗰𝘁𝗶𝗼𝗻𝘀. Эти два листинга идентичны, за исключением того, что связаны с разными системами БД.
В коде ниже прописана логика 𝗣𝗼𝘀𝘁𝗴𝗿𝗲𝘀, которая немного отличается синтаксисом от 𝗠𝘆𝗦𝗤𝗟.
Создание и инициализация базы данных Postgres
В 𝗠𝘆𝗦𝗤𝗟 и 𝗣𝗼𝘀𝘁𝗴𝗿𝗲𝘀 синтаксис для внедрения транзакций идентичен. Например, в коде ниже указано, как вставить три документа в коллекцию 𝘁𝗿𝗮𝗻𝘀𝗮𝗰𝘁𝗶𝗼𝗻𝘀 𝗠𝘆𝗦𝗤𝗟.
Вставка транзакций в базы данных MySQL
Попробуйте вставить те же три документа в свою БД Postgres.