

Доброе утро!
Как настроение?




Нейронные сети научились удалять людей с видео
Пару лет назад довольно активно обсуждалась тема deep fake. Технологии, позволяющей заменять лица одних людей на видео другими. Но в том время технология была сырая, даже невооружённым взглядом можно было заметить неестественность изображения. Плавающие контуры лица, искажения пропорций, неестественная мимика и многое другое. Некоторым людям доводилось сделать довольно реалистичные deep fake на небольших отрезках видео, но в какой то момент всё равно вылезала неестественность.

Никаких резких скачков в этой области долгое время не было, поэтому разговоры понемногу сошли на нет. Но данное направление никто не забрасывал и различные группы исследователей и инженеров продолжали работу в этом направлении. И вот в этом году группа исследователей из Оксфорда, Института Вейцмана и Google Research представили систему ансамбля нейронных сетей, способных определять на видео не просто контуры отдельных объектов, но и последствия любых контактов этих объектов с окружающим миром. Поднятую пыль, тени, задетые объекты, даже поднятую рябь на воде. И этот ансамбль нейросетей способен не только всё это определять, но и удалять с видео. Ниже прикрепляю оригинальное видео, представленное авторами разработки.
Поскольку оригинальное видео полностью на английском и в нём описываются лишь базовые особенности работы нейросетей, я также записал видео на русском. В нём я подробнее и простым языком постарался разобрать как саму разработку, так и те принципы, по которым работают нейросети, входящие в ансамбль.
При этом стоит заметить, что данная нейросеть работает абсолютно автономно. И обрабатывать различные видео она способна в "промышленных" масштабах. Есть у неё конечно и ряд ограничений, так что не стоит бояться, что уже завтра можно будет удалить кого угодно с любого видео.
С другой стороны, от появления сетей, которые могли очень криво заменять лица людей, до появления систем, способных практически бесследно удалить любой движущийся объект с видео прошло всего пару лет. И кто знает, чему научатся сети ещё лет через 5-10.
Показать полностью
2

Ответ на пост «Мошенники теперь звонят с номеров из контактов»
и ещё эту долбаную социальную инженерию развели
Она была всегда. Просто некоторое время назад было проще взломать пароль. Теперь из-за роста сложности взлома паролей проще взломать человеков. Во времена до этих ваших интернетов тоже любили взламывать человеков -- кто с помощью индульгенций, кто с помощью паяльников, третьи использовали топоры. Кто во что горазд.
Один из древнейших способов социальной инженерии -- это создание секты. Вначале выбирают внушаемых. Со временем доходят и до тех, кто невнушаем, их тогда ломают и силой заталкивают, сопротивляющихся устраняют физически. Как и за выход из секты.
Мало того. Появились разработчики ИИ, которые берут типовые диалоги из соцсетей, потом обучают нейросеть на эти диалоги и запускают общаться с реальными людьми.
Была статья, как разработчики ИИ натаскали нейросеть клянчить интимные фотки у девушек на примере соответствующих диалогов. Даже если 1% девушек согласится прислать свои интимные фотки, то на выборке в 100 тыс девушек это около тысячи девушек! Нейросеть не устанет и готова впахивать 24/7! Тысячи девушек, которые готовы прислать свои интимные фотки! В автоматическом режиме!!!
Вот что Data Sience животворящий делает! А обучиться на специалиста по Data Sience можно у нас нах... Блин, такая интеграция пропала)))
Другие разработчики сделали ИИ, который цыганит/клянчит примерно 1$. И такой ИИ нацыганил у пользователей сети больше 1 тыс $ !
Будущее -- это где роботы будут разводить людей 24/7. Благодаря DeepFake будет в режиме реального времени генерироваться голос, мимика и внешность любого человека. То есть даже любого родственника! И виртуальный двойник по видеосвязи будет делать вид, что он -- настоящий, копируя все, до чего сможет дотянуться...
И будущее уже наступило:
"Цифровой двойник Дженсена Хуанга провел часть презентации Nvidia"
https://habr.com/ru/news/t/572916/
Пока что требуется очень много вычислительных мощностей. Но они растут + облачные сервисы...
"Киберпанк, который мы заслужили"...
Показать полностью

Как работает нейросеть для deepfake на основе deepfacelab?
Делюсь своим опытом по созданию нейросети для работы с deepfake и faceswap. За основу взят проект deepfacelab.

Поиграем в бизнесменов?
Одна вакансия, два кандидата. Сможете выбрать лучшего? И так пять раз.


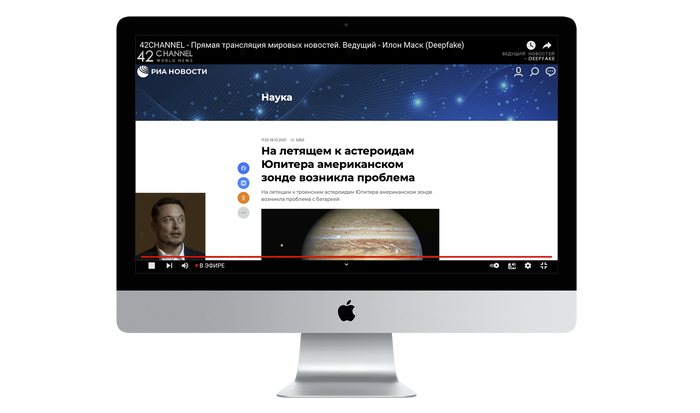
История о том, как Илон Маск бросил все дела ради работы новостным ведущим в России
А ещё выучил русский язык и переехал в РФ, чтобы работать на YouTube канале 42CHANNEL. А теперь расскажу, чего можно добиться с помощью доступных DeepFake технологий.
Введение
Deepfake — конкатенация слов «глубинное обучение» и «подделка», методика синтеза изображения, основанная на искусственном интеллекте. Она используется для соединения и наложения существующих изображений и видео на исходные изображения или видеоролики. Как гласит Википедия.
Ещё одна полезная технология современного мира - стриминг видео контента.
И наконец, синтез речи - программная конвертация печатного текста в «неотличимый от человеческого» речевой сигнал.
Закинув все это в блендер и залив контентом в виде новостей, я получил:
42CHANNEL - YouTube канал, круглосуточно транслирующий самые актуальные мировые новости, с Илоном Маском в роли ведущего.
Переходите на трансляцию и смотрите, что из этого вышло своими глазами:
https://www.youtube.com/channel/UCKn3nIsbXSbOxvmiDfCYLmg/live
История
Если вкратце - замысел был беспощадно «украден» у Никиты Колмогорова, а реализация кровожадно сперта у десятка разработчиков по всему миру.
Так как все нужные мне технологии уже были разработаны, мне оставалось их соединить воедино. Сейчас опишу используемые инструменты, так что можете переходить к следующей части статьи.
Для создания дипфейк видео взял Wav2Lip, который довольно прост в использовании, но ввиду кривизны моих рук, пришлось изрядно попотеть, чтобы установить зависимости на моём ПК.
Демонстрация работы Wav2Lip.
Путем множественных тестов, для синтеза речи был выбран SOVA TTS. А итоговое видео создается через FFmpeg и через него же транслируется на YouTube.
Часть кода, отвечающая за генерацию видео, крутится на моём стационарном ПК с видеокартой 2060 Super. Подходящий сервер с GPU неоправданно дорогой для текущей стадии.
Кому это нужно?
Кому это нужно?
Хотелось бы верить, что вообще всем. Моя задача - создать и предложить, остально дело за зрителями. С другой стороны, кто откажется под кружечку чая смотреть, как Илон рассказывает о мировых проблемах.
Какие есть проблемы?
Самая главная проблема - кривое произношение, иногда сложно понять, что сказал ведущий, особенно на аббревиатурах.
Кроме того, на текущем этапе разнообразие происходящего на трансляции оставляет желать лучшего. В планах добавить больше динамики, разные ракурсы ведущего и видео вставки.
Заключение
На самом деле, моя главная цель - вдохновить крупные компани автоматизировать все процессы в мире, лишить людей работы, устроить кризис на рынке труда и подорвать экономику. Ведь, как мы все прекрасно понимаем, с этого момента ведущие больше не нужны. Как вариант, компания Яндекс может взять проект за основу и развить его до чего-то революционного и не имеющего аналогов в мире.
И ещё кое что. Если трансляция прервется по техническим причинам, ссылка на неё изменится, поэтому, чтобы не утратить стрим, вы можете либо подписаться на канал, либо сохранить постоянную ссылку, которую я указал выше.
С любовью, tgaru.
Показать полностью
1