




Сколько тратит айтишник в МСК
Открыл для себя сообщество «Доходы-расходы». Оказывается, считать чужие деньги очень увлекательно. Решил тоже поделиться.
Сначала мои расходы за 2023 год по месяцам: январь — 185 тыс. р., февраль — 227 тыс. р., март — 199 тыс. р., апрель — 252 тыс. р., май — 168 тыс. р., июнь — 262 тыс. р., июль — 255 тыс. р., август — 143 тыс. р., сентябрь — 195 тыс. р.
В среднем получается 210 тыс. рублей в месяц.
Разберём структуру расходов по некоторым месяцам детально.
Сентябрь 2023 года.
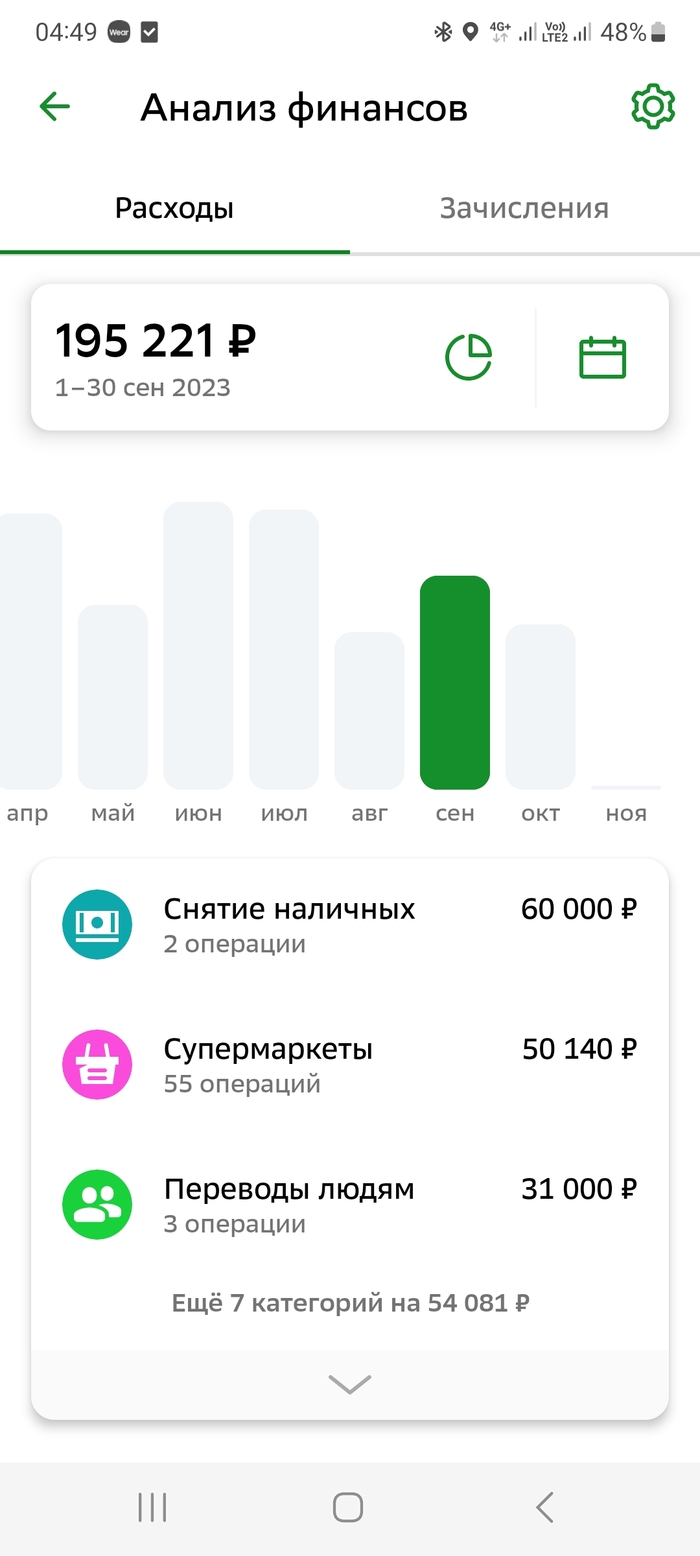
Снятие наличных — 60 тыс. р. Плата за аренду квартиры. Арендодатель не хочет платить налоги и просит кэшом.
Супермаркеты — 50 тыс. р. Еда (в основном всякие морепродукты, рыба, икра; мясо не люблю), алкоголь (водка «Абсолют», американские бурбоны типа Джек Дэниэлс, Джим Бим Дабл Оук, Мэйкерс Марк), хороший китайский чай (шу и шен пуэры, белый чай, моли, улуны).
Переводы людям — 30 тыс. р. Ежемесячная помощь родителям. Знаю, что мало, но живут они в деревне, и даже эту помощь норовят вернуть в виде подарков.
Здоровье и красота — 28 тыс. р. Заказал очки (оправа Армани, сложные японские стёкла).
Рестораны и кафе — 10 тыс. р. Доставки, иногда пиво в баре.
ЖКХ, связь, интернет — 3 тыс. р.
Подписки — 3 тыс. р.
Транспорт — 2 тыс. р.
Прочие расходы — 8 тыс. р.
Июнь 2023 года.
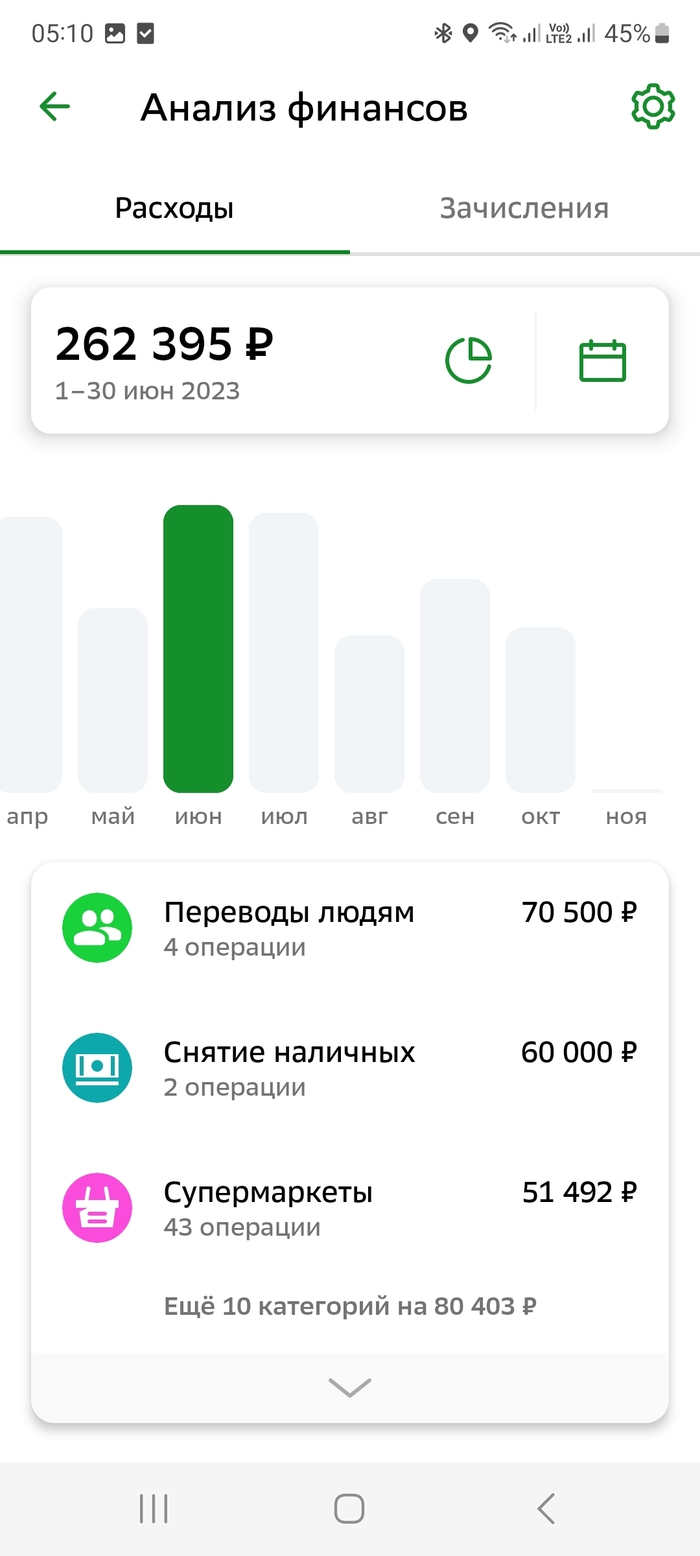
Переводы людям — 71 тыс. р. Помощь родителям и подарок маме на день рождения.
Снятие наличных — 60 тыс. р.
Супермаркеты — 51 тыс. р.
Одежда и аксессуары — 35 тыс. р. Купил кроссовки Нью Баланс (26 тыс. р.), футболку Тимберленд (5 тыс. р.), кепку Тимберленд (4 тыс. р.).
Рестораны и кафе — 18 тыс. р. Доставки, пиво по пятницам (~10 тыс. р.), один раз прошёлся по барам с друзьями (примерно 8 тыс. р).
Спорт — 10 тыс. р. Занятия с тренером по стрельбе из лука (2 тыс. р. за сеанс).
ЖКХ, связь, интернет — 4 тыс. р.
Электроника — 4 тыс. р. Рисоварка Steba RK 4 M серебристый.
Всё для дома — 2 тыс. р. Цельнокованый молоток каменщика Зубр ТИТАН 600 г.
Транспорт — 1 тыс. р.
Подписки — 900 р.
Прочие расходы — 5 тыс. р.
Немного о доходах.
Тут сложнее посчитать: зависит от проектов, премий, индексаций, желания работать. Кроме того, помимо официальной работы у меня есть несколько неофициальных источников дохода. Вилка получается где-то 300-800 тыс. в месяц.
Скриншоты прилагаю, но они очень приблизительные.


По профессии я Senior Data Scientist, живу в Москве, семьи нет.
Показать полностью
4


Топ 3 бесплатных инструментов работающих в России для создания и обучения нейронных сетей
Делимся с вами подборкой бесплатных нейросетей, которые работают и не заблокированы в России. Если вы увлечены искусственным интеллектом и интересуетесь его применением в различных областях, то эти инструменты обязательно понравятся вам.
TensorFlow - это открытая платформа глубокого обучения, разработанная командой Google. Она предлагает широкий спектр инструментов и библиотек для создания и обучения нейронных сетей. TensorFlow доступен бесплатно и не имеет ограничений в России. Он является одним из наиболее популярных фреймворков для разработки искусственного интеллекта.
PyTorch - это еще один популярный фреймворк глубокого обучения, который также доступен бесплатно и не заблокирован в России. Он разработан командой Facebook и предлагает удобный интерфейс для создания и обучения нейронных сетей. PyTorch также позволяет легко визуализировать и анализировать результаты обучения моделей.
Keras - это высокоуровневый фреймворк глубокого обучения, который является частью библиотеки TensorFlow. Он предлагает простой и интуитивно понятный интерфейс для создания нейронных сетей. Keras позволяет быстро прототипировать модели и имеет обширную документацию и сообщество пользователей.


Что не так с IT-образованием в России, и как я пытаюсь это исправить уже более 10 лет
Привет, меня зовут Дима Ботов — я руковожу магистерской программой «Искусственный интеллект» в ИТМО, вообще же преподавательской деятельностью я занимаюсь уже более 10 лет. В этой статье я хотел обсудить наболевший для меня вопрос: почему текущая модель IT-образования работает совсем не так, как должна.

Вот тут я открываю Bootcamp по машинному обучению для магистрантов ИТМО в прошлом году (сорри за уравнения с силой тока на доске – это честно до меня написали!)
Примечание от Павла: Автором этой статьи является Дима Ботов – а я ему только немного помог добавить кринжовых мемов по ходу повествования. Надеюсь, они не испортят вам удовольствие от прочтения Диминой истории. :)
Почему я стал дата-саентистом
Давайте начнем с хорошей новости: я уверен, что специалисты по data science захватят мир! Ну или его захватит искусственный интеллект, который они разрабатывают — тут уж как повезет…
Вообще, я рад, что сел за эту статью только сейчас: еще полгода назад мне, возможно, пришлось бы подробно объяснять широкой публике, почему машинное обучение и искусственный интеллект (ИИ) — это круто. А сейчас, после того как ChatGPT (а вместе с ним DALL-E, Midjourney, и так далее) прогремел на весь мир, донести эту мысль уже попроще.
В свое время электричество и индустриализация вывели производительность труда на новый уровень, а в XXI веке этим новым толчком, похоже, станет ИИ и технологии больших данных.
Почему? Всё дело в экспоненциальном взрыве сложности и размеров самих нейронных сетей, а также наборов данных, на которых они обучаются — и этот количественный скачок удивительным образом переходит в качество на наших глазах. ИИ учится подражать эмоциональному интеллекту, синтез речи становится неотличим на слух от естественного (паузы, придыхания, эмоции — всё это уже решенная проблема), а дипфейки взрывают интернет-пространство.
Так что, дети, если хотите точно не иметь проблем с трудоустройством в будущем, то я бы на вашем месте присмотрелся к сфере машинного обучения. Таких спецов уже отрывают с руками, а в будущем их конкурентное преимущество на рынке труда будет только расти.

Кто-то, правда, считает, что слухи об отъеме работы нейросетями несколько преувеличены…
Что не так с IT-образованием
А теперь к плохой новости: текущая система образования просто не умеет массово готовить нужных бизнесу специалистов в этой области. Да, отдельные люди прокачивают себя сами и становятся успешными спецами, но иногда этот процесс происходит скорее параллельно традиционному образованию. Выделю несколько ключевых проблем с позиции моего преподавательского опыта и общения с бизнесом:
1. Классическое образование слишком ориентировано на теорию (причем зачастую на устаревшую теорию), а вот с переложением ее на практически полезные навыки часто возникают проблемы. Все же могут вспомнить тех преподавателей по компьютерным наукам из университета, которые очень интересно доносят до студентов важные знания — только вот основаны они на их опыте 20-летней давности… В сфере ИИ это особенно актуально: тут даже опубликованные в научном журнале свежие статьи могут быть несколько устаревшими, ведь за полгода цикла их публикации текущая передовая граница разработки, скорее всего, ушла далеко вперед.

Как говорится, «ставь лайк, если нашел баг — ретвит, если пришлось спрашивать у папы, что на картинке»
2. Отсюда, у студентов возникает дилемма — учить в универе «фундаментальные знания» и зарабатывать корочку, либо идти работать и получать практические навыки. В итоге, как правило, либо страдает что-то одно — либо, и то, и то одновременно. За 12 лет преподавания в высшей школе и общения со студентами, я всё время видел противостояние двух паттернов: в университете постоянно звучит посыл «надо вот это выучить, потом разберетесь зачем» (привет, матан!), а при выходе на настоящую работу в компанию вчерашний студент слышит «так, а сейчас просто забудьте всё, чему вас учили в университете — в реальной жизни всё работает иначе!».

3. Получается, что бизнесам с одной стороны не хватает Data Science-специалистов, а с другой — те, что всё-таки приходят, не соответствуют их требованиям. Так что компаниям приходится делать свои внутренние школы/курсы, чтобы «за руку» довести только выпустившихся специалистов до требующихся им стандартов — но это же как бы не их основное направление деятельности, верно? Для самых крупных компаний, вроде Яндекса или VK, этот подход еще может работать (просто потому, что у них море ресурсов на развитие собственных компетенций), но средние (и, тем более, мелкие) бизнесы просто не потянут ведение своего внутреннего корпоративного университета.
Мой квест по исправлению образования: студенческие годы
Моя бабушка учила детей математике в школе, папа тоже был преподавателем — так что, похоже, уход в образовательную тему был написан мне на роду.

На фото моя бабушка обучает советских школьников матану (ну ок, только основам матанализа, конечно…)
Уже в универе (я учился в Челябинске в Южно-Уральском госуниверситете) у меня начали закрадываться крамольные мысли, что учебный план как будто бы сильно отстает от того, что на самом деле является востребованным на рынке труда. В нас, так называемых «инженеров-программистов для ЭВМ», пытались вложить тогда очень широкий спектр всего: от хардварного, аппаратного уровня электроники и схемотехники, через двоичный код, через микропроцессоры — до самого высокоуровневого программирования на С++ и создания веб-сайтов с приложениями.
При этом, когда к нам приехали ребята из екатеринбургской компании Naumen и почитали факультативы — выяснилось, что в реальном бизнесе разработка работает не совсем так, как нам представлялось «из-за парты».
Вдохновившись этим опытом, я решил на последнем курсе в 2009 году тоже сделать для однокурсников факультативный курс (совершенно бесплатный), посвященный языку JAVA. Почему Джава? Да всё просто: потому что тогда такие специалисты были очень востребованы на рынке.

Это молодая версия меня как раз ведет Джава-факультатив. Сорри за качество фото, айфоны в 2009-м в Челябинске были не очень распространены
Курс я провел, всё получилось отлично — дополнительно хорошо прокачался сам в теме (как говорил Фейнман: хочешь в чем-то разобраться — научи этому других!). Но всё-таки разрыва между теорией и практикой он не устранял — хотя бы потому, что у меня у самого на тот момент реального опыта продакшн-разработки и проектной работы не хватало.
Будучи удручен недостатком практического опыта, я рванул в индустрию — пошел работать тем, кого сейчас называют data-инженером (тогда это называлось «разработчик баз данных»), в энергосбытовую компанию. Параллельно с этим я оставался в аспирантуре и продолжал преподавать студентам отдельные курсы.

Это уже 2011-й год — посмотрите на мое лицо, полное энтузиазма от преподавания программирования в ЮУрГУ!
Кончилось всё это по классике: в индустрии я дошел до «ведущего инженера-программиста по БД», ну и, конечно же, бодро выгорел в процессе. Где-то в этом месте я понял, что мне всё же более интересно работать с людьми и помогать им развиваться, а не просто самому писать код.
Создание Института ИТ в ЧелГУ: верните мой 2014-й
И вот где-то тут (ближе к 2013—2014 годам) мне как раз предложили поработать в Челябинском госуниверситете в команде Андрея Мельникова, который тогда создавал внутри него Институт информационных технологий. Задача была непростая, но драйвовая: надо было с нуля сделать новый формат практического обучения студентов — мы прочесывали все доступные западные практики, изучали подход к обучению в британских и штатовских университетах, и так далее.
В итоге мы выбрали для себя формат проектного обучения и максимального вовлечения в преподавание практиков из индустрии. Мы старались сделать упор в обучении на такие штуки, как мозговой штурм, design thinking, совместное обсуждение командами проекта: когда задача преподавателя — это выступать не столько в роли «говорящей головы» и передатчика теории, сколько с позиции такого фасилитатора, который помогает командам самим внутри себя выработать правильные решения.

Здесь я, кажется, глубокомысленно смотрю вдаль - в светлое будущее Института ИТ в ЧелГУ, который планировался как плацдарм внедрения новейших подходов к обучению
К сожалению, большая часть преподавателей считает, что именно они знают, как надо правильно. Но это, на мой взгляд, тупиковая история — по крайней мере, в таких практических историях, как в IT. Она лишает студента возможности критически мыслить самостоятельно и развивать свои идеи. А то ведь всё равно в итоге преподаватель расскажет «как надо», и, вероятно, заставит переделывать под свое видение мира.
В рамках отрицания этой парадигмы мы и развивали наш Институт. Я тогда отвечал за всю академическую часть, за дизайн образовательных программ, учебных планов. Моей задачей было так подобрать преподавателей, чтобы около 90% профессиональных курсов вели именно практики из индустрии, а не штатные университетские ребята.
И нам в итоге удалось этого добиться: начиная с первого курса у нас читали реальные программисты, которые днем занимались разработкой, а вечером приходили обучать студентов. Это для меня было открытием: оказывается, на самом деле очень много крутых людей готовы тратить свое время на передачу опыта студентам — причем не столько за деньги, сколько за идею. (Надеюсь, никто из них из-за этого не выгорел!)
Но это всё еще не имело прямого отношения к машинному обучению, поэтому ниже будет о том, как я вкатился в него.
Первая магистратура по машинному обучению на Урале
Параллельно в аспирантуре я потихоньку занимался машинным обучением (тогда оно еще не было на слуху). Я занимался направлением Machine Learning, которое называется NLP (Natural Language Processing, обработка естественного языка) — к текущему моменту из этой ветки мы как раз получили все удивительные штуки вроде ChatGPT. А тогда я просто писал работу по анализу текстов вакансий с помощью нейросетки — чтобы понять на уровне семантики, какие навыки реально нужны работодателям от студентов, и сравнить с семантическим анализом образовательных программ университетов. По сути, искусственный интеллект мне говорил — какие университеты дают студентам котирующиеся на рынке труда знания, а какие — не очень.

В те времена Machine Learning был еще не в самом тренде, и этот мем был не так актуален, как сейчас
Где-то в это время (2015—2016 годы) мы стали глядеть на зарождающееся в Москве/Питере сообщество Open Data Science и решили — а чем мы на Урале хуже? Надо работать на опережение! Так что мы решили запускать в Челябинске свою магистратуру по машинному обучению, тогда она называлась «Data mining и интеллектуальный анализ данных».
Это была первая магистратура такого типа на Урале, и одна из первых в России по тематике машинного обучения. Мы тогда даже толком не понимали, в какие конкретно компании в регионе пойдут работать студенты — не было еще тогда местных бизнесов, которые в чистом виде специализировались на искусственном интеллекте и машинном обучении, этот рынок только формировался. Но мы были уверены, что у сферы огромный прикладной потенциал в бизнесе.
Как раз в процессе запуска магистратуры, я познакомился с ребятами из компании Napoleon IT и лично с их сооснователем — Павлом Подкорытовым. Мы тогда делали с ними совместный курс для студентов бакалавриата по разработке мобильных приложений под Android. Это сейчас каждая онлайн-школа обещает за полгода «вкатить тебя в айти», а тогда толковых курсов на эту тему было днем с огнем не найти.

Это мы с Пашей Подкорытовым рассказываем про наши совместные наполеоновские планы (сорри за каламбур!)
На выходе этого курса мотивация была не столько на зачетку — мотивация была в том, что лучшим ребятам пообещали оплачиваемую стажировку в Napoleon IT. И читали этот курс как раз реальные программисты и мобильные разработчики из компании, которые руками занимаются приложениями. Студентам в итоге очень зашло — битва за попадание в топ по рейтингу, чтобы оказаться на стажировке, местами вышла довольно накаленной.
Именно тогда я понял, что общепринятая схема оценивания студентов в баллах в зачетке – это прямо совсем не то, что реально нужно. Мы немного докрутили эту идею и пришли к тому, что лучший формат экзамена в случае IT-курсов – это формат собеседования, ну или защита проекта. То есть ты приходишь, показываешь свое портфолио, техлид проводит с тобой собеседование по направлению, и так далее.
2018: Уральская школа машинного обучения
Короче, уже тогда ко мне начало приходить понимание, что оптимальный формат IT-обучения — это что-то на пересечении между студентами и реальным бизнесом.
Где-то в это время мне предложили в крупной уральской телеком-компании стать руководителем отдела машинного обучения, с одной оговоркой — этого отдела тогда не было вообще, его надо было сделать с нуля. И мне совместно с ребятами из Napoleon IT пришла в голову идея сделать из этого в том числе образовательный проект — создать отдел как бы вместе со студентами и из студентов в том числе. Так родилась Уральская школа машинного обучения.
Мы набрали из более чем ста заявок 30 наиболее мотивированных ребят – и провели для них полностью бесплатный курс. За основу мы взяли материалы с курса машинного обучения от Open Data Science — в формате хабр-статей, домашек и видеозанятий. Так что вместо придумывания образовательного контента с нуля мы смогли больше усилий потратить на продумывание подачи и формата совместной работы со студентами.
В итоге у нас получился «перевернутый» формат обучения: лекций как таковых там не было — а теорию мы разбирали прямо на практике в ходе решения задач.

Вот такая вот тусовка у нас подобралась на первой защите проектов Уральской школы машинного обучения
И нам, и студентам, такой формат «зашел» — и мы потом проводили аналогичные запуски. Как раз на основе первых двух запусков Школы в течение 2018 года у меня сформировалось основное ядро коллектива в новоиспеченном отделе. Без Уральской школы ML я бы его просто не смог создать, потому что в регионе на рынке труда тогда в принципе не было достаточного числа специалистов по машинному обучению, из которых можно было сформировать команду — так что я ее сделал из вчерашних студентов.
Отдел в итоге развился до уровня реализации 15—20 проектов по компьютерному зрению: обработка текстов, построение диалоговых систем, предиктивная аналитика — полный набор!
А я в определенный момент опять устал от «корпоративной» жизни и меня потянуло сделать какой-нибудь стартап — свой проект, уже вне компании. У меня было чувство, что потенциал вот этих форматов обучения, построенных на сплаве бизнесовых задач и замотивированных студентов, точно не исчерпан проведенными Школами и магистратурой — это же были всего лишь «местечковые» проекты, а хотелось выходить с такими идеями на уровень всей страны. И обеспечивать путь не из нулевых ребят в джуны, а переходить уже на следующий уровнь — растить из джунов сильных мидлов (ведь, как все знают, именно они-то и нужны бизнесу больше всего).
Так родилась идея AI Talent Hub — проекта, который я развиваю и сейчас.
2021: AI Talent Hub как стартап, или как мы рожали идею
В 2021 году Павел Подкорытов позвал меня в питерский университет ИТМО, запускать там совместно с Napoleon IT специализацию «Компьютерное зрение» для магистрантов. Именно тогда мы познакомились с первым проректором ИТМО Дарьей Козловой — и она предложила мне сделать необычный формат: что-то вроде проектной магистратуры по правилам продакшена IT-компаний. Мне готовы были дать карт-бланш на любые новаторские идеи!

С Дарьей я фото в своем архиве не нашел, но вот мы в модном лектории ИТМО с его ректором — Владимиром Николаевичем Васильевым
И мы начали штурмовать эту историю — делать исследование и искать референсы, на базе которых можно сделать что-то передовое и интересное. Смотрели на то, как на Западе развивают стартап-сообщества; как ребята в Minerva University делают дизрапшен образования; как сейчас учат в Стэнфорде (Паша Подкорытов тогда на проекте Стэнфорда Future Talents как раз имел возможность вживую посмотреть на всю логику обучения и их подходов).
В общем, вдохновившись всеми этими подходами, мы и родили идею AI Talent Hub. С самого начала мы сформулировали своеобразный манифест — ключевые принципы, согласно которым должно строиться IT-обучение будущего:
1. Академическая свобода студента (выбор курсов под свои личные потребности и способности) и академическая свобода преподавателя (выбор форматов проведения курсов). Так называмая «суперэлективность» (супервыборность) курсов — каждый студент может составить себе полностью индивидуальный трек обучения из множества доступных курсов из разных областей ИИ и профессиональных направлений. И, вдобавок, выбрать интенсивность освоения курсов — за год, полтора или два года (в зависимости от загрузки).
2. Упор именно на практику через работу в реальных проектах в рамках рабочего процесса реальных IT-компаний. То есть, обучение заведомо должно быть не «академичным», а в первую очередь прикладным — с активным привлечением партнеров из бизнеса (которым, в итоге, и нужны все эти подготовленные специалисты). Ну и там уже получается, что нетворкинг и взаимодействие с профессионалам из индустрии становятся как бы основой образования (и, что не менее важно, основой передачи культуры).
3. Развитие продуктового мышления и инженерных навыков в условиях неопределенности. Это только в учебниках есть задача и есть ее итоговое понятное решение, которое нужно найти. А в реальном мире даже сама задача часто расплывчата, а решать ее как-то всё равно надо. Мы считаем, что и обучать спецов надо через погружение в реальные неформализованные бизнесовые потребности, в рамках полного цикла: от проработки идей и гипотез решения, до разработки в логике создания MVP (Minimum Viable Product — плясать от минимально жизнеспособного решения в сторону его постепенного усложнения).

Вообще, концепцию MVP, по-хорошему, можно начинать проходить на наглядных примерах еще примерно в начальной школе
2022: Что получилось на практике
По факту, AI Talent Hub сейчас работает примерно так:
Мы набираем самых талантливых ребят, у кого уже есть неплохой опыт в IT за плечами, на бесплатную магистратуру в рамках ИТМО.
Совместно с компаниями-партнерами (сейчас их более 12 — Huawei, МТС, Сбер, Яндекс Практикум и другие) составляем пул задач для так называемой «фабрики пилотных проектов».
Студенты в рамках проектной работы пытаются сделать реальные рабочие MVP под эти задачи совместно с экспертами и менторами из IT-компаний.

Финал Data Product Hack 2022 в ИТМО. Многие из этих ребят — это как раз наши магистранты AI Talent Hub
Наша ключевая компетенция как AI Talent Hub — в том, что у нас получается соединить бизнес и студентов таким образом, чтобы в процессе их взаимодействия случалась магия: чтобы и студенты обучались именно тем навыкам, которые нужнее всего на рынке труда, и бизнес видел для себя реальную отдачу (иначе зачем ему вписываться в это?) — в виде возможности потестировать свои рабочие гипотезы и новые идеи, а также получить доступ к замотивированным молодым спецам, многие из которых будут готовы потом пойти на работу в этот бизнес.
Проект уже успешно работает с прошлого года: на 2022 год мы получили (рекордные для ИТМО) почти 500 заявок на магистратуру, из которых отобрали для обучения примерно сотню студентов — сейчас они работают над проектами, привлекают под них гранты, активно взаимодействуют между собой в рамках хаба. Ну и не только между собой, на самом деле: существенная часть процесса обучения построена еще и на взаимодействии с менторами и экспертами из ODS, лидами и сеньорами из компаний-партнеров, с продактами и стейкхолдерами из реального бизнеса.

Первую встречу магистрантов с AI Talent Hub мы провели в формате тусовки в баре — просто потому, что мы можем, ну и вообще почему бы и нет?
Вообще, мы с самого начала сознательно решили делать упор именно на построение комьюнити и своеобразной «тусовки» амбициозных людей в индустрии. За счет того, что это магистерская программа, на ней встречаются самые разные люди — от вчерашних студентов-выпускников, до специалистов с солидным опытом в других индустриях, которые решили продолжить развитие своей карьеры в сфере Machine Learning/Artificial Intelligence.
А за счет тесного взаимодействия в рамках фабрики пилотных проектов с «заказчиками» от бизнеса, многие ребята сразу получают оффера уже на полноценную стажировку или работу в этих компаниях.

Попросил Женю, одного из студентов нашей магистратуры, описать свои ощущения от обучения
Если вы дочитали до сюда — то, подозреваю, что вы хотя бы частично разделяете или находите интересным наш подход к IT-образованию. Так что, если вы студент с интересом к Data Science — то welcome в наше онлайн-комьюнити (где мы анонсируем разные мероприятия вроде хакатонов), если вы джун-практик или просто окончили бакалавриат — то возможно вам будет интересно подумать в сторону нашей магистратуры (на следующий год у нас планируется аж 200 бюджетных мест, так что в случае прохождения отбора — учиться можно будет совершенно бесплатно), ну а представителей бизнеса с потребностью в ML-кадрах приглашаем тоже подключиться к образовательному процессу.
Что дальше?
В ближайшем будущем у нас стоит основная цель по масштабированию нашего подхода к IT-образованию: мы хотим набрать на обучение 700 магистрантов в 2023—2024 годах.
Но вообще, у меня есть более общая и долгосрочная мечта — это помочь осуществить глобальное изменение в подходе к образованию. Не только в России, но и по всему миру.
Я вижу процесс образования будущего так: условный студент-начинающий специалист по машинному обучению из Бразилии набирает себе портфель отдельных дисциплин по всему миру: курс по программированию в ИТМО, курс по дизайн-мышлению в Стэнфорде, курс по управлению инновациями в Университете Гонконга, и так далее. И параллельно проходит стажировку и реализует прикладной проект в одном семестре, допустим в Huawei, а в следующем семестре — в исследовательском подразделении Яндекса.
То есть, студент уже не ограничен рамками конкретного вуза и учебного плана — ему доступны из любой точки лучшие курсы ведущих университетов и программы стажировок ИТ-компаний со всего мира. И здесь на первое место должна выйти роль ментора, который помогает такому студенту собрать личную траекторию развития как профессионала.

Когда я выпускался в 2010-м из челябинского ЮУрГУ, я о таком даже не мог мечтать — но я надеюсь, что уже у наших детей горизонт возможностей будет на порядок шире, чем был у нас
Сейчас, конечно, в свете текущих обстоятельств такая картинка выглядит излишне оптимистично. Но я верю, что рано или поздно мы к этому придем. Ведь если не пытаться воплотить свое идеальное видение мира в реальность — то тогда вообще непонятно, зачем вот это всё? =)
* * *
Примечание от Павла Комаровского: Как обычно, если статья вам понравилась – буду благодарен за подписку на мой ТГ-канал RationalAnswer с еженедельными интересными лонгридами. Также выражаю респект Диме Ботову и Паше Подкорытову, которые поддержали выход этой статьи!
Показать полностью
17

Имеет ли смысл изучать machine learning (машинное обучение) с целью трудоустройства по этой специальности?
Сейчас являюсь трудоустроенным 1С программистом, изначально нацеливался на Android разработку, за время обучения в институте параллельно самообучался и не плохо её изучил. Но, так уж вышло, что в итоге устроился работать 1С разработчиком. Навсегда в 1С оставаться не хочу, думаю года через 2-4 сменить направление. Заинтересовало направление machine learning (искусственный интеллект всё больше входит в нашу жизнь, ввиду чего стало интересно этим заняться). Но есть опасение, что я потрачу n лет на изучение, а по итогу выяснится, что на рынке полторы вакансии, на которые претендуют 100500 человек. Открыл hh и, в общем-то, вакансий и правда немного:

Для сравнения количество вакансий по Android разработке:
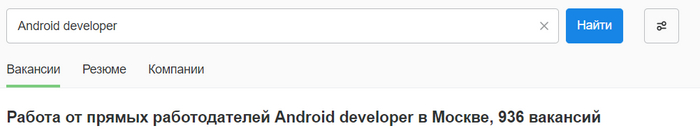
Я уже сталкивался с ситуацией, когда, для того, чтобы попасть на позицию джуна, нужно было чуть ли ни уметь управлять самолётом, параллельно проводя операцию на открытом сердце, что, в принципе, вполне объяснимо, когда на 1 вакансию приходит по 200-400 резюме (и это было на Android разработке). Были случаи, когда даже не приглашали на собеседование, после идеально выполненного тестового задания. В общем, я не против потратить много сил и времени, чтобы стать хорошим специалистом, но не хотелось бы потом узнать, что "я проиграл ещё до того, как начал"
Показать полностью


Обзор книги "Data Science. Наука о данных с нуля", отличная книга для начинающих

Всем доброго времени суток! Так как о Data Science мы слышим всё чаще и чаще, предлагаю вам обзор книги, что будет полезна для начинающих.
Публикую обзор книги с моего телеграмм-канала IT-старт t.me/it_begin на книгу "Data Science.Наука о данных для начинающих".
Автор книги Джоэл Грас.
Стоит читать? Да! Почему? Опишу в статье.
Для кого эта книга?
Так как в названии фигурирует "Наука о данных с нуля" - не мудрено, что рассчитана она на тех, кто только начинает свой путь в Data Science :)

Рис.1. Начальная страница
Что в самой книге?
Книга сама по себе немаленькая и состоит из 416 страниц.
Для того, чтобы имелась конкретика по размерам книги, производим замеры.

Ширина книги составляет чуть менее 17 см.

Рис.1.2. Размер книги
Высота книги составляет 23 см.

Рис.1.3. Размер книги
Глубина книги составляет около 2 см.
Теперь, для предметного и краткого понимания того, с чем мы сможем ознакомиться в данной книге, предлагаю перейти к её оглавлению.

Рис.1.4. Оглавление

Рис.1.5. Оглавление

Рис.1.6. Оглавление

Рис.1.7. Оглавление
Глав достаточно много, это радует) Всего глав 27.
Далее предметно и главное кратко постараюсь рассказать о том, что полезного и интересного мы сможем найти в этой книге.
Глава 1. Введение

Рис.2. Глава 1
Первая вводная глава начинается с подробного описания тезиса "Воцарение данных" и ответа на вопрос "Что такое наука о данных?".
Здесь повествуется о том, насколько много данных в современном мире и том, что вся информация, что собирается нашими компьютерами, смартфонами, умными часами, при должной обработке, может дать ответы на бессчисленные вопросы.
Более всего понравился пример на странице 26 с Facebook, что думаю примененим ко многим плоскостям исследования, используя практические любые соц. сети.
Также хорошо подчеркнут опыт избирательной компании Барака Обамы в 2012 году и предвыборной компании Дональда Трампа. Предлагаю вам ознакомиться с данным отрывком.

Рис.2.1. Глава 1, страница 26
Глава 2. Интенсивный курс языка Python

Рис.3. Глава 2
В данной главе автор на протяжении 30 страниц крайне в сжатом формате старается познакомить нас с языком программирования Python.
По моему мнению, вследствие того, что объяснение крайне поверхностное и имеет ограничение в виде 30 страниц, объяснено всё плохо. Для тех, кто вовсе не имел опыта работы с Python, данная глава, к сожалению, вряд ли поможет.
Как бы, претензий к книги по данному поводу у меня нет, но хотел бы, чтобы вы заранее имели это ввиду, что эта глава не является карманным пособием по Python.
Если вам необходимо изучить основы Python, советую книгу Тони Гэддиса "Начинаем программировать на Python с нуля" - мой обзор

Рис.3.1. Глава 2
В конце данной главы на странице 69мы видим две особенности книги.
Первая особенность - в конце каждой последующей главы вы увидите полезную сноску под названием "Для дальнейшего изучения", где автор от себя советует, что можно прочитать дополнительно для более глубокого изучения той или иной темы. Считаю это положительным моментом.
Отрицательным моментом качества данной книги являются тонкие страницы, что просвечивают и не доставляют особого удовольствия от этого.
Не сказал бы, что это крайне критично, но и приятного в этом также мало, общее впечательние от книги немного портится.
Всё крайне показательно видно на фото выше.
Глава 3. Визуализация данных

Рис.4. Глава 3
Также яркий пример просвечивающих страниц это столбчатый график, что просвечивает на странице 71)
В третьей главе автор кратко рассматривает библиотеку matplotlib,
В самом начале автор подчеркиват, что считает данную библиотеку устаревающей и что она годна для построения элементарных линейных и столбчатых графиков.
Согласиться с этим или нет? Вопрос сложный и оставлю его открытым на суд аудитории. Интересно ваше мнение по этому вопросу.
Далее в книге рассматриваются столбчатые и линейные графики, диаграммы рассеяния. Что порадовало, это повествование с соответствующим кодом, тут же можно понять, какая строчка кода за что отвечает, считаю это положительным моментом для тех, кто только начинает свой путь.
Завершается глава разделом "Для дальнейшего изучения", где автор оставляет ссылки на такие библиотеки, как seaborn, Altair, D3.js, Bokeh с кратким описанием каждой из них.
Глава 4. Линейная алгебра

Рис.5. Глава 4
В этой главе автор рассматривает векторы и матрицы.
Объяснено достаточно хорошо, вопросов после прочтения остается мало, в конце автор оставляет ссылки на три книги, что также позволят закрепить пройденный материал.
Глава 5. Статистика

Рис.6. Глава 5
В данной главе автор описывает и рассказывает о том, что такое тенденции, вариация, корреляция, корреляционные ловушки.
В главе много кода, подробно всё описание, в целом впечатление от главы положительное.
Но также показалось интересным и хорошо запомнилось описание парадокса Симпсона :)

Рис.6.1. Глава 5. Парадокс Симпсона
Глава 6. Вероятность

Рис.5. Глава 6
В этой главе рассмотрены:
Условная вероятность
Теорема Байеса
Случайные величины
Непрерывные распределения
Нормальное распределение
Центральная предельная теорема
Автор раскрывает важность умения работать с анализом вероятности для последующей работы с данными. Вероятность автор рассматривает, как способ количественной оценки неопределенности, что ассоциируется с событиями из некоторого вероятностного пространства.
Глава 7. Гипотеза и вывод

Рис.6. Глава 7
Хотел бы привести в пример "учаток" на странице 116, в подтверждение того, что без опечаток в этой книге не обошлось)
Теперь же о самой главе.
В данной главе автор подчеркивает, что все сведения из теории вероятности и статистики нам нужны для формулирования статистических гипотез и их последующей проверки. Предлагаю взглянуть на фрагмент главы в фото ниже.

Рис.7. Глава 7
Глава 8. Градиентный спуск
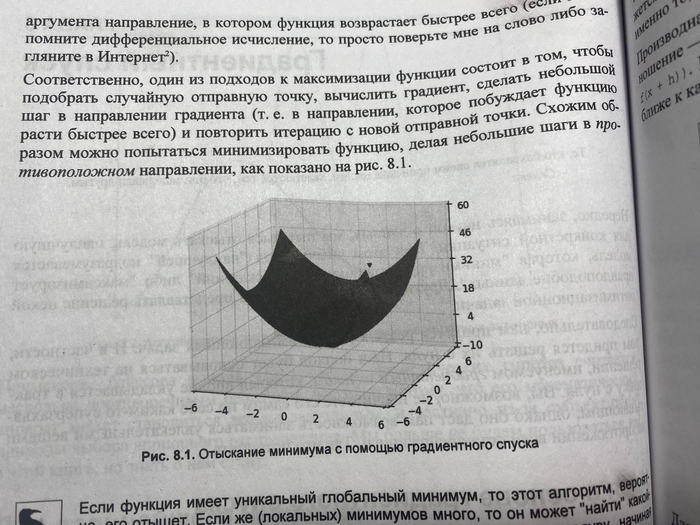
Рис.8. Глава 8
Градиент - это вектор, что своим направлением указывает направления возрастания некоторой скалярной величины.
Антиградиент - вектор, что своим направлением показывает направление убывает некоторой скалярной величины.
Градиентный спуск - это метод поиска локального максимума или минимума функции с помощью движения вдоль градиента.
Частично и достаточно понятно подход к максимизации функции описан на странице 128. (Рис. 8)
Глава более чем интересная, рассматривается также использование градиента, выбор правильного размера шага и применение градиентного спуска для подгонки моделей.
Глава 9. Получение данных

Рис.9. Глава 9
Для того, чтобы исследовать данные, нужно сначала их собрать :)
В этой главе автор рассматривает способы подачи данных и также их последующее форматирование.
В главе рассматриваются аспекты чтения файлов, импорт информации из всемирной паутины с помощью html5lib, что такое API и как с этим можно работать.
Глава 10. Работа с данными
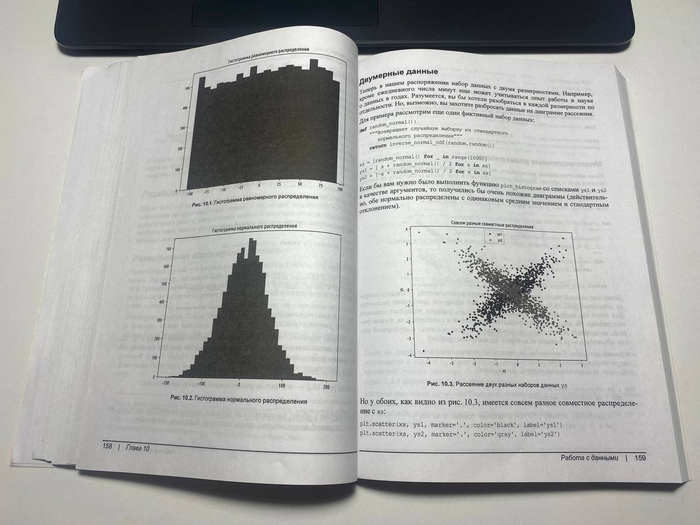
Рис.10. Глава 10
В 10 главе автор рассматривает непосредственную работу с данными.
Рассматривается разведывательный анализ данных, классы данных, многочисленные размерности.
Мне же понравилось, что автор не забыл про "чистоту" данных.
На странице 164 об этом как раз таки говорится, что многие данные в реальном мире загрязнены и что важно пред их использованием проводить необходимую обработку, чтобы в дальнейшем не создать себе проблем.
Рис.11. Глава 10
Глава 11. Машинное обучение
Рис.12 Глава 11
В 11 главе автор знакомит нас с машинным обучением.
Так как это обзор книги и он всё же будет немного предвзят с моей стороны по той причине, что у каждого человека есть своё мнение на ту или иную информацию - мне показалась данная глава не для тех, кто начинает с нуля)
Описано в целом по делу всё, но нет уверенности, что люди, ранее не знающие ничего о машинном обучении, после прочтения данной главы всё усвоят.
Глава 12. k ближайших соседей
Метод k-ближайших соседей – это популярный алгоритм классификации, который используется в разных типах задач машинного обучения.
Простыми словами суть метода: посмотри на соседей вокруг, какие из них преобладают, таковым ты и являешься.
Теперь же о том, как всё это описывает автор на примере предсказания результатов на выборах
Глава 12. k ближайших соседей
Метод k-ближайших соседей – это популярный алгоритм классификации, который используется в разных типах задач машинного обучения.
Простыми словами суть метода: посмотри на соседей вокруг, какие из них преобладают, таковым ты и являешься.
Теперь же о том, как всё это описывает автор на примере предсказания результатов на выборах
На примере набора данных о цветках ириса (длина и ширина лепестка, длина и ширина чашелистика) автор пытается построить модель предсказания вида цветка, но т.к. выводимые результаты у него получились четырехмерными, что затрудняет построение графика, автор предлагает взглянуть на диаграммы рассеяния для каждой пары данных результатов измерений.
Порадовало, что в данной главе автор не забыл о проклятии размерности
Глава 13. Наивный Байес
В данной главе автором очень хорошо рассказан принцип работы спам-фильтра социальных систем, как он устроен и что лежит в его основе.
Порадовало то, что в конце данной главы автор ссылается на статью Пола Грэма "План для спама". Статья 2002 г., но менее интересной от этого не становится.
Глава 14. Простая линейная регрессия
В 14 главе автор рассказывает о простой линейной регрессии, описывает применение градиентного спуска, производит оценивание максимального правдоподобия
Глава 15. Множественная регрессия
В данной главе автором рассматривается множественная регрессия, Расширенные допущения модели наименьших квадратов, подгонка модели и её дальнейшая интерпретация.
Глава достаточно большая и много познавательной информации имеет, но мне более всего понравилась трактовка интерпретации моделей
Глава 16. Логическая регрессия
Логистическая регрессия - статистический метод для анализа набора данных, в котором есть одна или несколько независимых переменных, которые определяют результат. Результат измеряется с помощью дихотомической переменной (в которой есть только два возможных результата). Он используется для прогнозирования двоичного результата (1/0, Да / Нет, Истина / Ложь) с учетом набора независимых переменных.
С самого начала главы автор предлагает рассмотреть всё на задаче, что содержит набор данных 200 пользователей, их зарплату, опыт работы и состояние платежей за учетную запись в соц. сетях. Далее описывается то, что такое логистическая функция, применение модели.
Более всего понравилось рассмотрение гиперплоскости, что разделяет параметрическое пространство
Идём далее)
Глава 17. Деревья решений
Одно из толкований дерева решений чаще всего описывает их в качестве представления возможных путей принятия решений.
Автором неплохо показано это на достаточно простом примере.
Глава 18. Нейронные сети
Нейронные сети - то о чём мы всё чаще слышим из средств массовой информации.
В данной книге глава это мягко не особо большая. Всего 10 страниц. Но достаточно информативная. Расскажет о том, что такое нейронные сети, перспептроны, как работают нейронные сети прямого и обратного распространения. Глава интересная!
Глава 19. Глубокое обучение
В данной главе о глубоком обучении автор рассказывает нам, что такое абстракция слоя, о представлении нейронных сетей как последовательности слоёв, о потери и оптимизации функции градиента.
Возможно субъективно, но чтобы до конца понять все вещи в данной главе, пришлось прочитать её дважды. Но думаю, дело не в книге, а во мне :)
Глава 20. Кластеризация
В главе о кластеризации понравилось, что автор пытается объяснить нам, что такое кластеры на +- понятных многим бытовых темах. Если читать ранее не слышал ничего о кластерах, подобное объяснение не является крайне легким, но и базовые основы в голове начнет зарождать. В главе автор рассматривает и описывает восходящую иерархическую кластеризацию, кластерные методы и на примерах объясняет что к чему. Интересная глава.
Глава 21. Обработка естественного языка
В главе об обработке естественного языка автор рассказывает несколько приемов, такие как: облако слов, N-грамматические языковые модели, грамматики. Много поясняющего кода)
Глава 22. Сетевой анализ
В главе про сетевой анализ автор описывает центральность, ориентированные графы, алгоритм PageRank. Мне данная глава "понималась" крайне тяжело, вследствие чего параллельно приходилось заглядывать в Google.
Глава 23. Рекомендательные системы
Та тема, с которой мы ежедневно встречаемся, используя те или иные стриминговые сервисы, соц. сети, поисковые системы - рекомендации :)
Сказали рядом с телефоном "купил собаку" и видите контекстную рекламу о дизайнерских будках на заказ? Это Data Science :)
Глава познавательная. Автор повествует о том, как работает рекомендательная система, что лежит в её основе, что такое коллаборативная фильтрация по схожесте пользователей и многое другое.
Глава 24. Базы данных и SQL
Достаточно сжатая глава о SQL. Рассказывается о том, что такое SQL, о основных командах и разобрано всё на примерах. Всё крайне сжато, но для общего представления совсем неплохо. Но всё же советовал бы дополнительно поискать еще источники информации на тему SQL, если хотите понять тему полноценно.
Глава 25. Алгоритм MapReduce
MapReduce - модель для выполнения параллельной обработки крупных наборов данных. Рассматривается работа самого алгоритма, какие его преимущества и чем он может быть полезен и рассмотренно на примере аналази аобновлений новостной ленты. Всё достаточно подробно описано, вопросов после главы остаётся не так уж и много.
Глава 26. Этика данных
Одна из лучших глав данной книги. Что такое этика данных, почему она важна, для чего используется и к чему может привести её несоблюдение. Познавательный материал, советую.
Глава 27. Идите вперед и займитесь наукой о данных
Заканчивается вся книга главой с призывом идти вперёд и заняться Data Science.
Автор подчеркивает важность компетенций в математической области и о необходимости хорошо разбираться в ней. Также автор кратко описывает популярные библиотеки языка программирования Python и не только.
Глава по своей сути прощальная между автором и читателем, автор же оставляет ту выжимку необходимых мыслей, что он хочет донести до каждого читателя для продолжения путешествия в мир Data Science.
Теперь, тезисно о плюсах и минусах книги
Плюсы книги:
1.Цена
На первом маркетплейсе цена не такая уж и народная.На втором же, ситуация куда бодрее.
Лично от себя скажу, что в целях экономии, часто беру книги уцененные, с небольшими внешними дефектами книги, что не особо влияет на её содержимое. Или же можно найти интересующую вас книгу на площадках б.у. товаров. Но если захотите приобрести новую книгу, цена в условные 600 руб. считаю более чем приемлимой и подъемной для многих. Выделю цену достоинством книги.
2. Книга крайне ёмкая и обширная. О необъятной теме в объятной книге.
Рассматривается и Python и SQL и методы Data Scince, что и как работает. В рамках одной книги это более чем достойно. Да, временами книга может показаться поверхностной, но думаю, это исходя из ограничений книги. Чтобы написать подробный том о каждой теме, для производства книги потребовалось бы куда больше бумаги :)
Минусы книги:
1. Прозрачные страницы.
Не особо бросается в глаза, когда увлечены чтением, но и приятного в этом мало.
Думаю, на всех фотографиях страниц книг, что сделаны мною, это отчетливо видно. Страницы тонкие и просвечивают. Считаю, что это минус.
2.Иногда крайне сжато подаётся материал, что , не имея под рукой поисковика, трудно понять некоторые вещи. Данная оценка субъективна, но мне показалось именно так. Опять же, не уместить всё-всё в одну книгу, понимаю. Но иногда охото отстраниться от цифрового мира, увлечься чтением интересной книги и не прибегать к помощи персонального компьютера)
Подведение итогов по книге:
Могу посоветовать к прочтению данную книгу. Книга даст базовые знания о Data Science, что опять же позволит вам понять, нужно ли оно вам в принципе, интересно ли всё то, что связано с этой сферой.
P.S. К сожалению, в один пост на пикабу можно поместить не более 25 изображений. Мною сделаны фотографии каждой главы, но показать их в рамках ограничений пикабу не могу. Поэтому, если интересно, то можете прочитать полную версию на моем канале.
Благодарю вас за внимание!
Мой канал в телеграмм
Если обзор показался вам интересным, то буду благодарен за подписку на мой
канал IT-старт t.me/it_begin
где я также публикую обзоры технической литературы и полезную информацию как для действующих, так и для начинающих программистов
Ссылка на бесплатную электронную версию книги https://t.me/it_begin/461
Также публикую обзоры книг и интервью на сайте https://russia-it.ru
Показать полностью
25

Где,кроме Data Sience используется машинное обучение и какие IT направления есть в области создания искусственного интеллекта?
Я решил, хотя бы в качестве хобби, заняться изучением создания искусственного интеллекта. Дабы не выбирать направление деятельности наугад, стал смотреть видео с описанием терминов, с этим связанных.
Итак я узнал, что "глубокое обучение" является разделом машинного обучения, которое, в свою очередь, входит в область разработки искусственного интеллекта.
Из другого видео я узнал, что машинное обучение используется в data sience.
Дальше я даже не совсем понимаю, что и как мне гуглить, чтобы разобраться с тем, какие направления разработки связаны с созданием ИИ, как они связаны или не связаны между собой, что мне, в связи со всем этим нужно изучать и т.д.
Data science
Добрый день. Заканчиваю учиться на дата сатаниста. По данной специальности работать не собираюсь.Есть ли какие нибудь сайты где за деньги смогут сделать выпускной проект?