

Nemotron Nano V2 VL: Видение и язык в гармонии
Автор: Денис Аветисян
Новая модель объединяет возможности обработки изображений и текста, открывая новые горизонты в мультимодальном искусственном интеллекте.
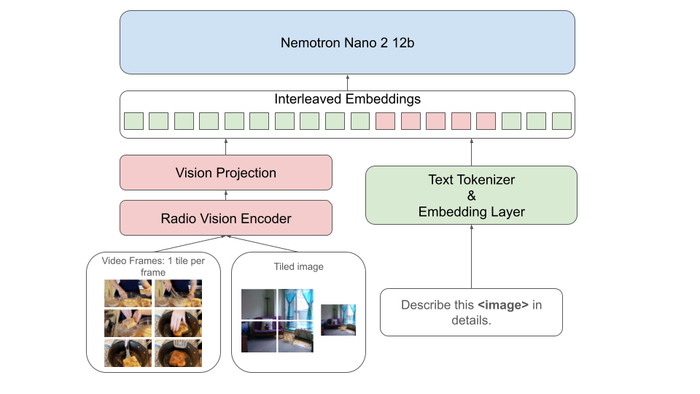
Архитектура обработки визуальной информации использует динамическое разделение изображений и равномерную выборку кадров из видео, приводя их к единому разрешению 512x512 для кодирования посредством RADIO и MLP, после чего визуальные и текстовые представления объединяются и передаются языковой модели Nemotron-Nano-12B-V2 для дальнейшей обработки.
Представлен Nemotron Nano V2 VL – 12-параметровая модель, демонстрирующая улучшенное мультимодальное понимание, рассуждения и эффективность за счет обучения с длинным контекстом, квантования и эффективной выборки видео.
Несмотря на значительный прогресс в области мультимодального обучения, эффективная обработка длинных последовательностей и понимание сложных визуально-текстовых взаимосвязей остается сложной задачей. В данной работе представлена модель 'NVIDIA Nemotron Nano V2 VL', разработанная для улучшения понимания документов, анализа видео и задач логического вывода. Модель, насчитывающая 12 миллиардов параметров, демонстрирует существенные улучшения в понимании мультимодальных данных благодаря использованию архитектуры Mamba-Transformer, техникам квантизации и оптимизированной выборке видеоданных. Какие перспективы открывает Nemotron Nano V2 VL для создания интеллектуальных систем, способных эффективно анализировать и интерпретировать информацию из различных источников?
Синтез Зрения и Языка: Новый Рубеж
Несмотря на значительный прогресс в развитии отдельных модальностей искусственного интеллекта, интеграция зрения и языка остается ключевой проблемой. Существующие системы часто демонстрируют впечатляющие результаты в распознавании объектов или генерации простых описаний, однако испытывают трудности при решении задач, требующих комплексного анализа и сопоставления визуальной и текстовой информации. Отсутствие четко сформулированной задачи порождает лишь шум; любое решение, лишенное строгого определения, обречено на неточность.
Архитектура Nemotron Nano V2 VL: Основы Дизайна
Nemotron Nano V2 VL – мультимодальная языковая модель, основанная на архитектуре Nemotron-Nano-12B-V2. Визуальная информация обрабатывается кодировщиком RADIOv2.5 Vision Encoder, обеспечивающим эффективное преобразование изображений в векторные представления, которые затем интегрируются с текстовыми данными. Ключевым компонентом является архитектура мультимодального слияния, обеспечивающая бесшовную интеграцию данных и повышающая точность выполнения задач.
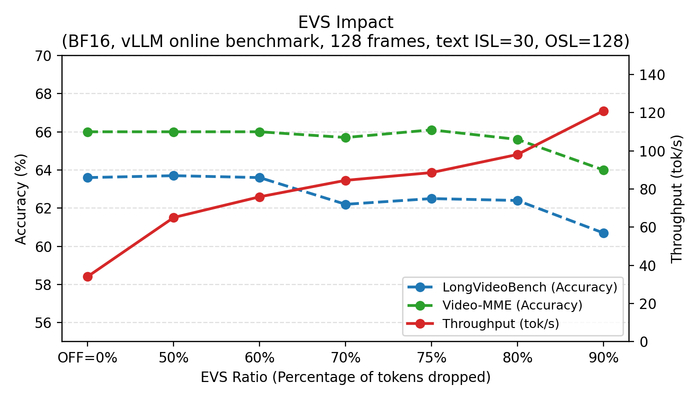
Абляционный анализ EVS, проведенный на RTX 6000 PRO SE с использованием онлайн-бенчмарка vLLM (128 кадров, текстовые параметры ISL=30, OSL=128), демонстрирует, что как результаты в формате BF16, так и FP8, представленные в виде численных таблиц (точность, время TTFT, пропускная способность) и соответствующих визуализаций, позволяют оценить влияние различных конфигураций.
Оптимизация Производительности: Методы для Надежности и Эффективности
Nemotron Nano V2 VL поддерживает два режима функционирования: Reasoning-On и Reasoning-Off, позволяя варьировать баланс между точностью и скоростью вычислений. Для обработки изображений различного разрешения реализована стратегия разбиения на тайлы, вдохновленная архитектурой InternVL. Обучение проводилось с использованием фреймворка Megatron и 8-битной точностью (FP8), с применением методов Context Parallelism и Long Context Extension для увеличения длины контекста с 16K до 128K.
Продемонстрированные Возможности: Бенчмарки и Сравнительный Анализ
Nemotron Nano V2 VL демонстрирует передовую точность на OCRBench v2 и высокую производительность на Video-MME, подтверждая способность к анализу визуальной информации и пониманию видеоконтента. В сравнении с Llama-3.1-Nemotron-Nano-VL-8B, модель демонстрирует превосходство, подтверждая обоснованность принятых решений. Модель обучалась на обширном наборе данных Nemotron VLM Dataset V2 и была доработана с использованием NVPDFTex для обеспечения высококачественной основы для оптического распознавания символов.
Если результат не может быть воспроизведен, то сама ткань понимания начинает распадаться.
Направления Развития: Расширение Горизонтов Мультимодального Интеллекта
Будущие исследования будут сосредоточены на изучении более продвинутых методов мультимодального объединения данных для дальнейшего повышения возможностей логического вывода. Планируется масштабирование модели до еще больших размеров и использование более крупных наборов данных. Изучение применения Nemotron Nano V2 VL к решению реальных задач, таких как понимание документов и автоматическое создание кратких обзоров видеоматериалов, является одним из приоритетных направлений работы, а также разработка эффективных методов квантования, таких как NVFP4 и BF16.
Исследование, представленное в статье о Nemotron Nano V2 VL, подчеркивает значимость математической дисциплины в обработке данных. Модель, демонстрируя улучшенные возможности мультимодального понимания и рассуждения, опирается на точные алгоритмы и эффективные методы квантизации и выборки видео. Как однажды заметил Карл Фридрих Гаусс: «Если бы я должен был выбирать между тем, чтобы быть великим математиком или великим политиком, я бы без колебаний выбрал первое». Эта цитата отражает суть подхода, представленного в статье – стремление к математической чистоте и доказуемости алгоритмов, а не просто к их работоспособности на тестовых данных. В хаосе данных спасает только математическая дисциплина, и Nemotron Nano V2 VL служит ярким подтверждением этого принципа.
Что дальше?
Представленная работа, демонстрируя возможности модели Nemotron Nano V2 VL, лишь подчёркивает фундаментальную нерешенность задачи истинного мультимодального понимания. Улучшение способности к рассуждениям, безусловно, важно, однако, следует помнить: корректная работа на тестовых примерах – не гарантия внутренней логической непротиворечивости. Если решение кажется магией – значит, не раскрыт инвариант. Необходимо углубленное исследование не просто способности модели "видеть" и "говорить", но и способности к построению доказанных, формально верифицируемых выводов.
Особое внимание заслуживает проблема масштабируемости. Уменьшение размера модели до 12 миллиардов параметров – шаг в верном направлении, но истинная элегантность заключается в достижении сопоставимых результатов с использованием принципиально меньшего числа параметров, возможно, через более эффективные алгоритмы обучения и представления знаний. Квантование и эффективная выборка видео – полезные инструменты, однако, они лишь смягчают симптомы, а не устраняют корень проблемы – вычислительную сложность.
В будущем, вероятно, потребуется отход от простого увеличения размера моделей и сосредоточение на разработке архитектур, способных к абстрактному мышлению и построению причинно-следственных связей. Истинное понимание не сводится к статистической корреляции; оно требует построения внутренней модели мира, способной к предсказанию и объяснению наблюдаемых явлений. А пока, каждая новая модель – лишь очередная иллюстрация того, как много ещё предстоит сделать.
Оригинал статьи: denisavetisyan.com
Связаться с автором: linkedin.com/in/avetisyan









