

Как устроены нейросети для неспециалистов (1/2)

Нам часто предлагают врубиться во что-то с места в карьер: «Вот я формулку нарисовал и всем понятно!».
Но не беспокойтесь, в начале же была не формула, в начале было слово, и вот о словах-то мы сейчас и поговорим. Я хочу этой статьей увлечь как гуманитариев, так и айтишников с математиками!
Понимаю, что у вас кружится голова от большого количества новых незнакомых понятий и терминов. Лучший способ все это уложить — пройти стопами тех людей, которые делали простые вещи, но называли это сложным, узнать историю развития и понять, почему все работает так, а не иначе.
Для этого нам придется углубиться в робопсихологию и робопсихиатрию!
❯ В начале было слово
И слово это было русское. Инженеры IBM вместе с Джорджтаунским универом переводили русские технические тексты на английский. По сути, это был электронный словарь с несколькими простыми правилами. Машина просто заменяла русские слова на английские. Тут было больше пиара, чем перевода, так как организаторам очень хотелось освоить военные бюджеты.
Словарь был всего лишь на 250 слов + 6 грамматических правил. На демонстрации перевели несколько заготовленных предложений на русском, типа таких:
1. KRAXMAL VIRABATIVAYETSYA MYEXANYICHYESKYIM PUTYEM YIZ KARTOFYELYA
2. VLADYIMYIR YAVLYAYETSYA NA RABOTU POZDNO UTROM
Вы не ошиблись, они вводили русские предложения заглавными английскими буквами, как в чатах 90-х (если кто застал).
В прессе был фурор: «New York Times» и многие другие газеты и журналы вышли со смелыми прогнозами, что через несколько лет вопрос с автоматическим переводом будет решен.
В ответ советские инженеры быстренько сделали такой же машинный перевод с английского на русский. Шла холодная война, и нужно было читать большие объемы технической документации противника.
Но все эти усилия особо ничего не дали, машина не задумывалась над смыслом перевода и он был уж совсем бестолковым.
Тем не менее шума в научных кругах и в прессе было много. Всем казалось, что искусственный интеллект будет уже вот-вот через пару лет, также как и полная колонизация космоса. Прошли 50-е годы, а потом и 60-е, и оказалось, что с космосом все гораздо бодрее, чем с машинным переводом.
❯ Пронумеруем слова

Поскольку компьютер не понимает слова и буквы, то нужно их превратить в номера. А для этого нужно пронумеровать все слова. И тут выяснилось, что машина может довольно легко определять настроение текста (например, отзывов в интернете).
Практически у любого алгоритма машинного обучения с учителем есть два режима: обучение и обычная работа (inference). В режиме обучения на вход подают текст (в виде чисел), а на выход правильные ответы. В рабочем режиме на вход попадает текст, а на выходе появляются ответы машины, на базе тех правильных, которые она видела раньше.
Как же нам оценить тексты отзывов? Для обучения с одной стороны, подаем номера слов, с другой стороны баллы, которые пользователь поставил в отзыве. Теперь в рабочем режиме машина может прикинуть, сколько примерно баллов поставил бы живой пользователь по такому тексту отзыва, а значит может отличить позитивный отзыв от негативного. Для этого достаточно понять какие номера слов чаще встречаются в негативных текстах, а какие в позитивных. Такие методы, которые улавливают тенденцию, называют регрессионными.
Также это легко можно сделать, например, с помощью дерева решений, работает просто: видим негативный номер — значит, мы ближе к негативному отзыву. Видим позитивный номер — значит мы ближе к позитивному отзыву, пройдя весь лабиринт условий можно получить ответ.
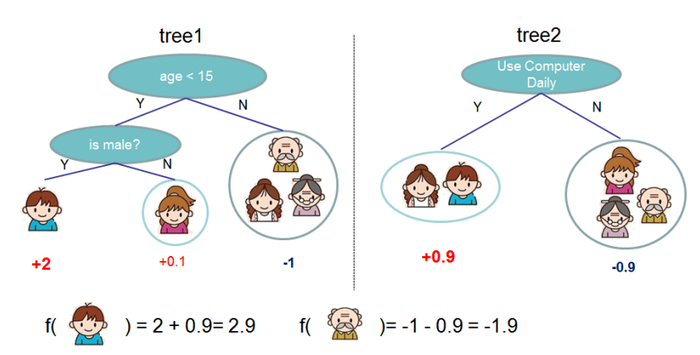
Похоже на психологические тесты, по типу: «Проверь, насколько ты депрессивный». Такие алгоритмы назвали «древесными».
Как раз по определению тональности отзывов я писал мою дипломную работу.
❯ Нейронные сети

И тут появляются нейронные сети, поначалу отдельно для картинок и отдельно для текстов. Оказывается, что если разбить изображение на области и математически просуммировать точки (пиксели) в них еще и еще, то получится какая-то маленькая абракадабра. Наделаем таких абракадабр для каждого изображения, пропустим через дерево решений и машина уже умеет отличать кошечек от собачек. Оказывается, что абракадабры для всех собачек похожи друг на друга, и для всех кошечек похожи друг на друга.
Т.е. можно взять фото кошки и вычленить из него самую суть, и из собачки вычленить самую суть! Процесс извлечения сути назвали «сверткой», так как большое изображение можно «свернуть» до минимума отражающего только его смысл. Такие нейросети назвали сверточными (Осторожно, эту статью написал Ян Ликун — главный исследователь ИИ в запрещенной в РФ компании, возможно известный вам по скандалам с перекупом исследователей из OpenAI за 100 мегабаксов).
В режиме обучения на вход такой нейросети подают собачку или кошку, а на выход ноль или единицу. В режиме определения такая нейросеть получает на вход фото собачки или кошечки, а на выходе выдает ноль или один уже самостоятельно. По сути, нейросеть учится взвешивать кошачью сущность и собачью сущность и эти «веса» позволяют ей в будущем определить кто перед ней.
❯ Ускорители
Но есть одна проблема — чтобы получить высокую точность, нужна нейросеть с большим количеством весов и этой нейросети нужно очень много фото кошечек и собачек — сотни тысяч и чем больше, тем лучше.
Каждая картинка — это на самом деле табличка с цифрами, в каждой ячейке которой хранится цвет точки на экране компьютера. Такие таблицы математики называют матрицами. Для того, чтобы добиться впечатляющих эффектов в видеоиграх нужно уметь очень быстро преобразовывать изображения, а значит складывать и перемножать матрицы с цветами точек. Обычный процессор умеет это делать ячейка за ячейкой, но геймеры не будут ждать. Поэтому придумали графический процессор, который умеет складывать большое количество ячеек разом. С тех пор графический процессор называют GPU (Graphics Processor Unit). Напомню, что обычный процессор — это CPU (Central Processor Unit)
Поскольку можно складывать разные ячейки одновременно, то такие вычисления называют параллельными, или многопоточными. Обработку таблиц можно ускорить в десятки и сотни раз, так как они хорошо распараллеливаются.
Когда мы в суперкомпьютерном центре РАН проектировали многопотоковый процессор, никто не думал, что у похожих технологий настолько большое будущее.
Параллельные вычисления используется при добыче криптовалюты. Майнеры перебором находят результаты криптографических функций. Хочется грести деньги лопатой, а лучше экскаватором, а для этого нужны те самые GPU, чем больше — тем лучше!
Компьютерные игры крайне популярны, что позволяет производителям видеокарт быстро набить карманы наличностью, а это уже дает возможность развивать свои процессоры. Таким образом геймеры своими деньгами оплатили создание ускорителей для Искусственного Интеллекта и крипто валют сами того не подозревая!
❯ Большие данные

Окей, теперь у нас есть нейросеть и есть ускоритель, но где же взять данные для обучения? Ведь нужны именно размеченные данные! На фотографиях должно быть подписано — это кошечка, а это — собачка!
Все это было бы невозможно, если бы интернет был только для военных и для ученых. Но слава соцсетям — там есть группы любителей кошечек, есть группы любителей собачек — таким образом у нас масса размеченных данных. Значит можно подавать их на вход нейросети, чтобы она взвешивала суть и уточняла веса.
Энтузиасты искусственного интеллекта пошли еще дальше и создали глобальный проект (ImageNet) для разметки фотографий и других изображений. Они брали фото из сети и делали подписи к ним. Таким образом много лет создавалась крупнейшая обучающая выборка для картиночных нейросетей — более 14 миллионов фотографий по 20 тысячам категорий.
В те годы я активно участвовал в соревнованиях по машинному обучению. Тебе дают размеченные обучающие данные — ты на них тренишь нейронку, потом тебе дают неразмеченную выборку и твоя нейронка ее размечает, результат отправляем на конкурс. Организатор вычисляет ошибку, у кого она лучше — тот и победил.
Берем соревнование, скажем, по определению поражения сетчатки глаз вследствие сахарного диабета. Организатор отсыпал около 30 тысяч глаз индусов, причем большая часть из них здоровые, и только несколько тысяч с разной степенью поражения. Учим нейросеть, а толку ноль — ошибка плохая. Потому что больных глаз нужно хотя бы еще 30 тысяч, а лучше по 300к и больных и здоровых.
И тут мы можем применить хитрый трюк: возьмем нейронку обученную на кошечках, собачках и других спутниках человеческой жизни, дообучим ее на глазах больных индусов, и вау — теперь она заправский доктор. Этот трюк называется Transfer Learning.
Чтобы нейросеть могла переварить такие объемы данных, то ей нужно много весов. Оказалось, что выгоднее всего их располагать на большом количестве сверточных (convolutional) слоев.
Получается на вход мы получили собачку, свернули ее, получили слой со смыслом собачки. Свернули смыслы собачек и получили подсмыслы — новый слой, а потом еще и еще много слоев. Если вы достанете веса с разных слоев обученной нейронки, то увидите, что на первых слоях всякие черточки, палочки, кружочки, кусочки текстуры.

А на более высоких уровнях вы можете увидеть уже набор глаз, ушей или носов.

Это все из-за того, что при свертке используются различные фильтры. Таким образом простая суть в простых элементах, а более сложная в сложных. Кроме того, слои разделены между собой фильтрами, чтобы веса не смешивались и сеть лучше обучалась.
Чем больше слоев и обучающих данных — тем умнее нейронка, но с этим нельзя перебарщивать, в какой-то момент все может замаразмировать (с людьми кажется тоже так бывает, если челик дофига умный и дофига начитанный). Если переусердствовать, то сеть начнет вести себя странно и все больше и больше ошибаться. Это называется «переобучением» вследствие тупой зубрежки, когда вместо понимания смысла пытаешься просто запомнить правильные ответы.
Используя предобученную нейронку можно сэкономить на большом количестве дорогих GPU, на времени обучения и главное — на данных, которые собрать очень сложно. Таким образом пользователи интернета и социальных сетей профинансировали крупнейшие датасеты сами того не осознавая.
Кстати, предобученная сеть называется PRETRAINED — это очень важное понятие, запомните его, оно нам понадобится. Над одной из первых таких сетей (AlexNet) в команде собственно Алекса Крижевского работал наш соотечественник Илья Суцкевер, он нам тоже понадобится далее.
Машинное зрение

О чудо, машина кажется научилась видеть и понимать! Но это произошло задолго до нейросетей. Например, для определения человеческого лица — нужно найти вертикальный прямоугольник, горизонтальный прямоугольник, и два маленьких квадратика.

Примерно так работает алгоритм для извлечения признаков Хаара (Haar-like features). Зачем пихать прожорливую нейросеть в фотоаппарат или в камеру видеонаблюдения, если суперпростой алгоритм сносно работает.
Нужно определить личность человека по фото или видео? Не вопрос: давайте измерим расстояние между глаз и сравним с расстоянием до носа — и вот теперь можно узнавать людей. Очень грубо, но для многих задач достаточно, а главное очень просто, дешево и можно засунуть в любой утюг.
В те годы я много занимался коммерческой обработкой изображений: дорабатывали трехмерные модели зубов, чтобы печатать элайнеры на 3D принтере; снимали кардиограмму с лица через камеру смартфона, чтобы делать выводы о здоровье пользователя; определяли скорость сперматозоидов под микроскопом, чтобы вычленять нормальных мужиков. И нейросети для этого всего были просто не нужны. С тех пор ситуация не сильно поменялась. Когда нам нужно быстро, массово и дешево, инженеры используют максимально тупые кондовые алгоритмы.
Генерация изображений

Вернемся к PRETRAINED нейросетям. У нас есть обученная сеть, которой на вход подаешь фото, а на выходе получаешь ответ, что из 20 тысяч известных объектов попало на изображение. А что, если на входе поставить генератор шума? Какой-то шум будет больше похож на собачку, а какой-то меньше. Ок, добавим еще одну нейросеть, которая будет обучаться генерировать шум больше похожий на собаку. PRETRAINDED нейросеть будет только контроллером, который проверяет, насколько фигня, которую сгенерировали из шума, похожа на собаку. Обучение организовано таким образом, что сеть генератор и сеть проверяльщик все время соревнуются — одна пытается сгенерировать что-то очень похожее на собаку, а вторая сеть старается распознать подделку. В их споре рождается истина — с каждым новым циклом все сложнее отличить сгенерированное изображение от обычного.

И вот мы научились генерировать собак, которых вообще в природе не существует, а такие сети стали называть генеративными. GENERATIVE — тоже очень важное для нас слово, запомним его.
А что же переводы?

Как бы сюда приспособить нейросеть? А давайте будем давать на вход русское предложение, а на выход английское. Точнее последовательность номеров русских и английских слов. Где же взять пары таких предложений? Ну, например, библию возьмем — она на многих языках есть.
В такой нейросети стоит архивариус, который в режиме обучения пытается вычленить какие-то связки последовательностей номеров слов, самых распространенных и сохранить их в долгосрочной памяти. То есть он взвешивает каждый кусочек последовательности номеров слов и корректирует веса в своей памяти.
В режиме работы архивариус достает из долгосрочной памяти наиболее подходящие по ситуации связки слов. Работает это как попугайчик Кеша, который вроде бы по делу говорит, но смысла слов не понимает.
Смысл слов

Инженеры и ученые давно пытались пронумеровать слова так, чтобы в них был какой-то смысл, много голов сломали, много электричества сожгли и в итоге придумали вот такое:
1. Возьмем все тексты, которые найдем в компьютерном виде.
2. Составим табличку, где по горизонтали будут все слова, и по вертикали все слова.
3. А в ячейке запишем, как часто эти слова встречаются вместе друг с другом.
Табличка такая получилась 500 000 слов на 500 000 слов для одного языка. И каждое слово теперь можно закодировать с помощью 500 000 чисел. Такую последовательность чисел называют вектором. И получилось, что похожие слова имеют похожие векторы. Например, слова «собака» и «щенок» больше похожи друг на друга, чем «собака» и «кошка».
Получается, что смысл слова — это как часто оно встречается вместе с другими словами.
500 000 чисел на каждое слово — убиться можно, чтобы каждый раз загонять в нейросеть даже с GPU. Но есть способ, чтобы уменьшить это количество до 500 и при этом вычленить смысл — это же свертка! Чтобы сжать (свернуть) такие огромные таблицы, использовали алгоритмы, похожие на архиваторы для файлов.
И тут что началось! Обучаем векторами (смыслами) дерево решений — оно от этого лучше определяет содержимое текста. Кормим смыслами (векторами) сеть попугайного типа (рекуррентную) — она лучше переводит. Оказалось, что если в предложении все слова векторизовать (закодировать по смыслу), а потом сложить особым образом — получим смысл предложения. Даже если просто сложить и усреднить все вектора слов в тексте — получим смысл текста!
Недавно энтузиасты сделали вектора с помощью старого доброго zip-архиватора, скормили нейросети и получили отличные результаты. Получается, что нейросети в некотором роде похожи на архиваторы, они сжимают (или сворачивают) большие объемы информации. Вода испаряется, а остается смысл, который можно потом использовать.
Чуть позже придумали более изощренную схему — все доступные тексты нарезали на кусочки по три слова. Взяли маленькую однослойную нейросеть, на вход ей давали два соседних слова, а на выход центральное в режиме обучения. Нейросеть училась угадывать по двум соседним центральное слово и корректировала свои веса.
А дальше из нее просто достали эти веса, которые отображают смысл каждого слова, которое она училась угадывать. В учебниках по английскому, да и по русскому тоже, учеников часто просят заполнить недостающие слова.
Три слова подряд с центральным пропущенным назвали скип-граммами. А набор чисел (вектор), которые отражают смысл пропущенного слова, назвали эмбеддингом. Самые известные эмбеддинги — это GloVe и word2vec.
Обучение без обучения

Ну ладно, теперь у нас есть слова, нумерация (векторизация) которых отражает их смысл. Сеть попугаечного типа (рекуррентная LSTM) стала переводить лучше, так как связки получаются более осмысленными, но все равно зазубренными. Теперь нам нужно найти пары предложений на разных языках. И это боль, так как все тексты немного разные и сложно сопоставить одни предложения с другими. Я в те годы работал над автоматическим переводом с гренландского языка на датский и обратно. Мы парсили (слава-слава Даниилу) новостные сайты, на которых были одни и те же заметки на двух языках. Оказывается, что журналисты переводили не предложение в предложение. Кто-то ленился и выкидывал часть предложений, а кто-то добавлял в порыве литературной страсти лишнее. И у меня пары предложений не совпадали. Я не знал ни гренландского, ни датского. Да и вообще носителей гренландского не более 50 000 человек в мире. Я сопоставлял предложения статистическими методами, а потом проверял часть из них на живом гренландце, который был на чиле/расслабоне, и при случае мог выдать за неделю оценку не более 50 пар предложений.
Собственно такая проблема была не только у меня и не только по гренландскому, а по всем языкам. Если с переводчиками тяжело и поэтому мы не можем подать на вход нейросети предложение на одном языке, а на выход подать предложение на другом языке. У нас просто нет в достаточном количестве этих чертовых предложений.
А что, если мы нарежем текст на кусочки, таким образом, чтобы модель получала на входе кусок текста, а на входе следующее слово из этого текста в режиме обучения? То есть, мы хотим, чтобы модель угадывала следующее слово для этого куска текста и таким образом предобучилась на всех доступных человечеству текстах без разметки. А уже дальше мы скормим ей пары предложений и будет наконец хороший переводчик.
Режем слова

Но есть две проблемы: во-первых, наш зазубривающий переводчик-попугай не понимает смысла слов, а только заучивает связки, а во-вторых — 500 000 векторов очень много.
Поэтому решили взять все тексты и прорезать слова на кусочки, а потом чисто статистически вычислить, какие кусочки встречаются чаще всего. Оказалось, что оптимально когда таких кусочков примерно 30-50 тысяч.
В нейросеть добавили таблицу, которая взвешивает соотношение кусочков. Т.е. раньше попугай просто запоминал наиболее ходовые связки слов и предложение, то теперь он еще запоминает как куски слов соотносятся между собой. А как мы помним, соотношение слов между собой — это и есть смысл.
Кусочки слов назвали токенами, новый механизм извлечения смысла назвали «вниманием», а новую нейросеть TRANSFORMER — запомним это третье название, оно нам тоже будет важно.
Расцвет переводчиков

Как раз появился TRANSFORMER мы взяли предобученную датскую нейросеть — с очень высоким качеством. Взяли слабенькую гренландскую нейросеть. Мы дообучили (слава-слава Юрию) ее тем небольшим количеством предложений, которые я смог сопоставить на слабеньком домашнем GPU. После этого наш гренландец сказал:
— Ребята, а где вы нашли еще одного гренландца? Я его знаю?
— Нет, это наша модель так умеет.
— Да, ладно.
Правда были и недостатки. Наша модель училась на новостях и хорошо переводила новости, а вот над разговорным языком предстояло еще помучиться.
Тем временем стали выясняться удивительные вещи, оказывается можно обучить модель сразу на всех языках, какие найдет. Оказывается что токены в разных языках имеют аналоги.
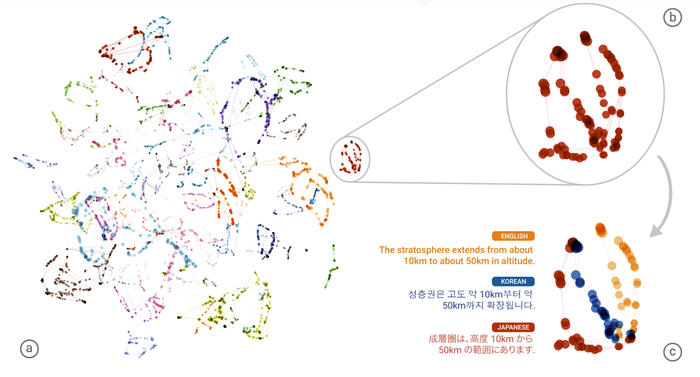
То есть языки-то разные, а смысл-то примерно один!
Токены гораздо лучше векторов, потому что если слово с ошибкой, или оно какое-то новое, то векторы никак не помогут. А вот если новое или ошибочное слово нарезать на токены, то проблема решается сама собой. Оказывается, что модель умеет понимать слова, которые никогда не видела и даже придумывать слова, которые никогда не видела. Открылся потенциал для исследования забытых языков, по которым очень мало материалов.
Выяснилось, что язык ДНК — тоже отлично бьется на токены. Гугловская компания DeepMind сделала нейросеть AlphaFold, которая умеет вычислять структуру белка на базе последовательности, взятой из ДНК.
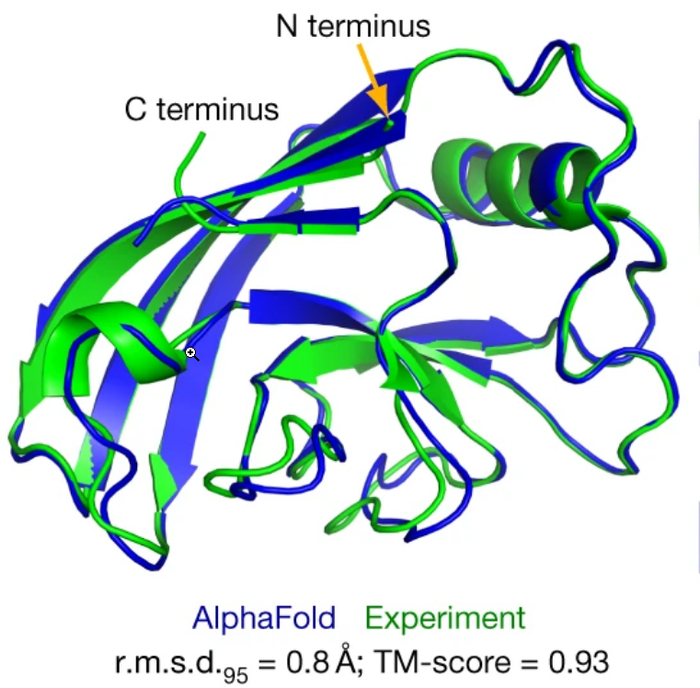
Раньше это было возможно только лабораторными экспериментами.
Получилось, что изображения и аудио можно тоже разбить на токены, а значит, нейросеть будет понимать аудио, изображения и текст одновременно. Такие модели называют мультимодальными.
Умная модель

Если модель может переводить с любого языка на любой язык, то это значит, что она может переводить с русского на русский?
Давайте будем давать модели на вход кусок текста, чтобы его продолжила, она будет нам давать следующее слово. Мы будем этот кусок текста дополнять этим словом и снова подавать его в модель. Таким образом, модель получится генеративным, предобученным, трансформером или GENERATIVE PRETRAINED TRANSFORMER или, если короче, то GPT. А одним из создателей этого чуда является наш с вами соотечественник Илья Суцкевер.
А тем временем роботы

У GPT был существенный недостаток: вы могли дать нейронке любой текст и после этого ее начинало нести словесным поносом, прямо как человека в психотическом бреду.
Решение нашлось в неожиданном месте. Допустим, что так случилось, что вы не забыли со школы законы физики и помните несколько формул. При этом формула у вас есть, а вот заставить электромеханическую машину вести себя предсказуемо в реальном мире вы не можете. Потому что любая формула — это всегда упрощение действительности.
Что с этим делать уже давно придумано — датчик и обратная связь. Допустим, едет у вас лифт: трос растягивается и проскальзывает, при разной температуре металлы расширяются и сужаются, двигатель останавливается то раньше то позже. При этом лифт должен как-то остановиться вровень с этажом. Вместо того, чтобы морочить себе голову расчетами — поставим датчик, который будет останавливать двигатель, когда лифт подъезжает к этажу. Это называется отрицательной обратной связью.
Но зачем вам лифт, если вы программист? Давайте сделаем виртуальную модель лифта, и будем обучать механизм обратной связи на ней. Таким образом появилось большое количество всевозможных физических симуляторов, которые с давних времен используются в промышленности, строительстве, электронике.
Суть всего обучения с обратной связью — это функция награды. Модель должна постараться, чтобы найти максимальное значение этой функции, то есть получить награду. Тут все как в животном и человеческом мире: ребенок учится ходить, падает, набивает шишки — получает отрицательную награду, наконец-то удается пройтись — получает положительную награду.
Компания OpenAI собрала в интернете множество диалогов и дообучила на них GPT. Параллельно она наняла большое количество экспертов, которые оценивали ответы GPT — ставили плюсы и минусы. Благодаря этому нейронка научилась фильтровать свой бред. Сейчас модель часто просит вас оценить свой ответ, чтобы использовать это для дообучения.
Так GPT стала chatGPT. Кстати, обучение с подкреплением называют Reinforcement Learning или RL. А обучение с обратной связью от людей называют Reinforcement Learning from Human Feedback или RLHF.
Многие компании полны энтузиазма, чтобы с помощью RL научить роботов идеально двигаться в естественной среде. Прорыв в обучении машины человеческому диалогу очень вдохновил создателей человекоподобных роботов.
Послушание

Главная задача дообучения chatGPT — сделать ее послушной. Если вы задали вопрос - она должна вам ответить ну хотя бы как-то рядом, а не про что-то другое. Оказывается, что непослушный искусственный интеллект — это просто генератор бреда. По поводу мышления идут споры — мыслит модель или нет. Но я вам скажу, как инженер — без послушания никакого интеллекта не получается. Если машина не может подчиняться другим, она и себе не сможет подчиняться. А если у нее будут ноги и руки, то непослушный искусственный интеллект не сможет ими даже пошевелить. Так что если вы думали о восстании машин, то речь явно об очень послушных машинах.
Да и успешное человеческое восстание — это пик послушания, когда все люди подчинены одной единой цели и действуют фанатично послушно и благодаря этому синхронно. Если все кто в лес, кто по дрова — ничего не получится. Разнузданность мышления — тоже не даст вам довести хоть какое-то дело до успешного конца. Мне это не нравится, но есть ощущение, что интеллект начинается с послушания.
А как же креативность? Как же детская непосредственность? Как же незашоренность, открытость мышления, свободомыслие? Проще всего с детской непосредственностью — она возможна только в присутствии взрослых, которые берут на себя заботу о базовых потребностях. Если таких людей нет, то дети очень быстро «взрослеют» и детская непосредственность улетучивается.
С креативностью интереснее в ней есть толк, если человек может вместить креативность в рамки поставленной задачи. Именно такое обычно воспринимается с восхищением как гениальность.
Если вернуться к большой языковой модели (Large Language Model или коротко LLM), то у нее есть настройка — температура. Модель должна угадать следующий токен, он поведет за собой следующий и так далее. Насколько этот токен соответствует стандартному подходу к ответу на вопрос пользователя? Или может быть нужны какие-то неожиданные подходы? Если вы снизите температуру до нуля — LLM будет выдавать вам самый каноничный ответ и будет хорошо слушаться, если вы будете повышать температуру то вероятность выпадения нетипичных для ситуации ответов увеличится, а послушность снизится, и, наконец, при дальнейшем увеличении температуры у модели сорвет свисток и она ответит вам потоком бреда и галлюцинаций. Видимо, когда люди говорят друг-другу: «Остынь немного, не кипятись, не горячись» — они имеют в виду что-то похожее.
Как же совместить юношеский максимализм и зрелую рациональность для получения удачного практического результата? Давайте одной LLM поставим температуру побольше — пусть что-нибудь придумает, а другая пусть приглядывает за первой, у нее будет температура пониже. Тогда первая модель будет искать нестандартные пути, а вторая будет пытаться согласовать их с суровой реальностью.
Кто ты?

Поскольку GPT продолжает любой текст, который ей дали, то в зависимости от разных затравок (prompts или промптов) будет и разный ответ. В связи с этим можно в самом начале дать затравку: «Ты дух Александра Сергеевича Пушкина». Таким образом можно просить модель «менять шляпы» и продолжать текст с разных позиций.
С этого момента у большого количества неайтишных людей появилась возможность взаимодействовать с нейросетью, а это уже породило массу мифов, трюков, приемов — о них вам расскажут из каждого утюга, а мы тут больше про то как и почему это все черт побери работает.
Обучение без обучения (опять)

Примерно раз в месяц ко мне приходят люди, которые хотят «обучить» GPT. Если взять готовую бесплатную языковую модель из интернета, то чтобы обучить ее вам понадобятся GPU на десятки и сотни миллионов рублей. Слава богу OpenAI предлагают задешево дообучить chatGPT прямо на их серверах. Но это вам не подойдет, ведь для обучения вам понадобятся пары текстов! Те которые на входе и на выходе! И текстов таких нужно множество, хотя бы тысячу пар. Но на самом деле вы таким классическим образом ничего учить и не собирались.
Как вы понимаете, если LLM подсунуть статью с данными, которые она никогда не видела, то она вполне себе сможет ответить на вопросы по ней. Также там могут быть инструкции в духе: «Не забудь, что ты Наполеон и веди себя так как подобает императору.»
Получается, что если этот текст подставлять LLM перед каждым запросом пользователя, то у него будет складываться ощущение, что она предоубчена. Поэтому остается всего-навсего написать небольшую прослойку между пользователем и нейросетью, с чем справится любой школьник.
Этот подход называется «контекстное обучение».
Продолжение статьи здесь: Как устроены нейросети для неспециалистов (2/2)













![Промпт [Этимология] Промпт, ChatGPT, Искусственный интеллект, Нейронные сети, Статья, Образование, Openai, Digital, Чат-бот](https://cs16.pikabu.ru/s/2025/08/13/20/snssiu7k.jpg)
