


Вышел новый альбом знаменитого шаноснье-разраба Коляна Макинтоша!
UPD:
Конечно же ШАНСОНЬЕ
Слушать на всех платформах: http://localhost:8080

Показать полностью
2

Музыка для программирования
Нейронная музыка чтобы уйти в программировании и ни на что не отвлекаться или просто вдохновит на написание собственной музыки. Для этого я создал сервис Нейронное радио с открытым исходным кодом сначало для себя и не так давно поделился им с другими. Здесь вы найдете музыкальные треки с вокалом и без них или сможете отвлечься нейронной игрой.
Если вам понравится трек и захочется его скачать или просто удобно слушать на YouTube, для этого я сделал плейлист нейронной музыки с вокалом и без него. И публикую музыкальные треки на русском с клипами, в том, числе и кавера. При этом всё создано нейронными сетями. С наступающим Новым годом!
P.S. Приложение PWA может быть поставлено на телефон или компьютер.

Сможете найти на картинке цифру среди букв?
Справились? Тогда попробуйте пройти нашу новую игру на внимательность. Приз — награда в профиль на Пикабу: https://pikabu.ru/link/-oD8sjtmAi



Ничего сложного
Телеграм - Три мема внутривенно
Показать полностью
1

BeeSynth - плеер для PC-спикера

Хочу представить вам плеер и синтезатор для системного спикера, написанный на Rust.
Поддерживает воспроизведение MP3, WAV, FLAC, трекерной музыки - и вообще всего, что может быть сконвертировано библиотекой ffmpeg в WAV-PCM. Для улучшения качества звука поддерживает обработку звука с помощью фильтров: например, фильтры высоких и низких частот, а также извлечение из сигнала самых значимых гармоник с помощью преобразования Фурье.
Также поддерживается многоканальное воспроизведение собственной музыки, написанной в текстовом виде в специальном формате.
Ссылка на GitHub: https://github.com/HoShiMin/BeeSynth
Как это работает: доступ к спикеру осуществляется с помощью так называемых портов ввода-вывода - специального интерфейса в процессоре, выделенного для работы с чипсетом и периферийными устройствами. Этот интерфейс сводится к двум машинным инструкциям: in и out, которые обычно доступны только в режиме ядра (Ring0) - в привилегированном режиме, к которому у пользовательских программ доступа нет. А значит, нам нужен драйвер, который или откроет для нашей программы доступ к портам в пользовательский режим (юзермод, он же Ring3), или будет служить «мостиком» между Ring3 и Ring0, позволяя юзермоду отправлять запросы в ядро и работать с портами оттуда.
В проекте поддерживаются оба способа при использовании драйвера InpOut:
1. Отправляем ему запросы на работу с портами.
2. С его помощью патчим уровень привилегий, с которым наш поток может работать с портами, с Ring0 на Ring3 - таким образом, поток получает возможность работать с портами из юзермода напрямую - без необходимости запрашивать драйвер.
Научились работать со спикером: теперь необходимо понять, что играть. Самый удобный формат для воспроизведения - WAV, т.к. представляет собой массив сэмплов фиксированной длительности. Каждый сэмпл - амплитуда сигнала в момент времени, соответствующий номеру сэмпла в массиве. Поэтому все музыкальные форматы мы предварительно конвертируем в WAV с помощью библиотеки ffmpeg.
Спикер имеет только два состояния: напряжение приложено (мембрана поднята вверх) и напряжение снято (мембрана опущена). Таким образом, мы можем воспроизводить звук с глубиной дискретизации всего в 1 бит, в отличие от типовых WAV-файлов с глубиной дискретизации в 16 бит, поэтому нужен такой алгоритм ресэмплинга, который позволит добиться приемлемого качества звука. И здесь возможны варианты: можно использовать широтно-импульсную модуляцию (PWM), чтобы научить мембрану занимать промежуточные положения между 0 и 1, настолько быстро подавая и снимая напряжение, чтобы мембрана не успевала доходить до граничных положений, но сделать это очень сложно из-за различий в физических свойствах разных спикеров в разных компьютерах. Поэтому в проекте реализован другой подход: положение переключается на каждый амплитудный пик или на каждую амплитудную впадину в сигнале, что даёт уверенное качество звука и хорошую громкость.
Остался последний штрих: можно улучшить качество звука, отрезав самые низы, которые спикер не воспроизведёт, и верхи, которые приводят к шуму. Сделать это можно, используя фильтры низких и высоких частот.
В итоге мы можем воспроизводить любой звук в относительно хорошем качестве. Технические детали и более подробное описание можно найти в README на страничке проекта на гитхабе.
Показать полностью



Ответ на пост «Как создать ИИ-кавер с помощью нейросети: генерация несуществующих песен с голосами знаменитых артистов»
Впечатляют способности нейросетей сводить и мэшапить разные трэки. Справляются не хуже ди-джеев местного розлива. Например, витубер-композитор Lord Aethelstan однажды запилил нейро-мэшап из своей самой дегродской песни Boof Pack и песни его не менее упоротой коллеги Acoomer Akuma Nihmune - CPR. Легло практически идеально!
Если вы профи в своем деле — покажите!

Такую задачу поставил Little.Bit пикабушникам. И на его призыв откликнулись PILOTMISHA, MorGott и Lei Radna. Поэтому теперь вы знаете, как сделать игру, скрафтить косплей, написать историю и посадить самолет. А если еще не знаете, то смотрите и учитесь.

Как создать ИИ-кавер с помощью нейросети: генерация несуществующих песен с голосами знаменитых артистов
В социальных сетях стали популярны несуществующие песни, созданные при помощи нейросетей. В апреле этого года пользователь ghostwriter977 загрузил на Spotify трек Heart on My Sleeve, который набрал более миллиона прослушиваний. Звучание песни было похоже на исполнение The Weeknd и Дрейка, но на самом деле её создала нейросеть. Эта история разошлась по миру, но позже трек был удалён по требованию правообладателя Universal.
Тем не менее, в социальных сетях продолжают появляться другие каверы: голосом Фредди Меркьюри была исполнена песня Imagine Dragons, а Канье Уэст "спел" Just The Two of Us. Тренд распространился и на рунет: песни стали перепевать голосами Доры и Элджея. А ИИ-каверы от нейро-Моргенштерна произвели фурор в TikTok.
Если вы тоже хотите создать свой собственный ИИ-кавер, то мы подскажем как это сделать. За полчаса или за 5 минут вы можете создать свою собственную песню, которая будет звучать как исполнение ваших любимых артистов, благодаря нейросети.
В марте 2023 года китайские разработчики выложили на GitHub нейросеть SoftVC VITS Singing Voice Conversion, известную онлайн как so-vits-svc. Эта нейросеть может имитировать певцов и создавать новые песни с их голосами. Алгоритм был разработан энтузиастами и доступен для всех, но чтобы запустить его локально, нужны знания программирования и мощный компьютер.
Чтобы не тратить время на программирование и не заниматься обучением модели, можно воспользоваться нейросетью на Google Collab. За полчаса вы можете создать полностью готовый ИИ-кавер. Процесс генерации песни с голосом исполнителя, чью модель выложили в открытый доступ, не требует специальных знаний.
Как создать трек в нейросети so-vits-svc с помощью Google Collab: генерация ИИ-каверов
Шаг 1. Выберите песню, которую будет исполнять сгенерированный голос, и скачайте её в формате mp3. Для успешной генерации также понадобится инструментал и голос оригинального певца.
Учтите, что музыка защищена авторским правом, поэтому коммерческое использование может привести к удалению вашего сгенерированного трека с платформ. Выбирайте песни, доступные по лицензии Creative Commons.
Шаг 2. Разделите трек на а капеллу и минус. Для этого загрузите mp3-файл на сайт x-minus. Зеленая дорожка будет содержать а капеллу, а синяя - минус. Скачайте полученные файлы и переименуйте их для удобства.
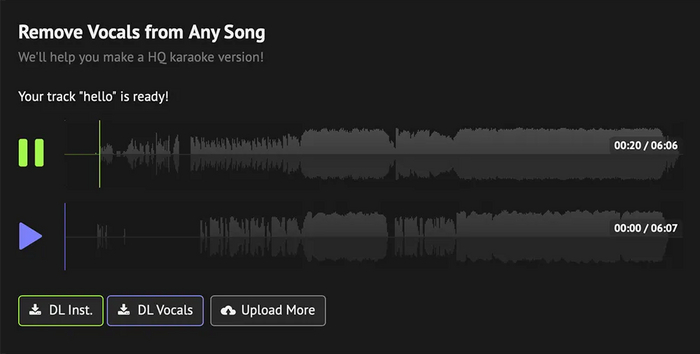
Шаг 3. Конвертируйте файл с а капеллой из формата mp3 в wav. Это можно сделать с помощью бесплатной программы Audacity или онлайн-конвертера cloudconvert.
Шаг 4. Перейдите по ссылке на so-vits-svc, веб-интерфейс нейросети, запускаемый на Google Collab. Этот сервис позволяет бесплатно запускать код на вычислительных мощностях других пользователей, но при этом есть ограничения: каждый раз нужно ждать загрузки библиотек и моделей.
Вы также можете использовать другие интерфейсы, но мы не можем гарантировать, что они будут работать так же хорошо. Эта инструкция написана для so-vits-svc, поэтому в других веб-интерфейсах порядок действий может отличаться.
Шаг 5. Для того чтобы записать песню с использованием нейросети, необходимо выполнить ряд предварительных действий. Войдите в свой аккаунт Google или создайте новый, так как для работы с Google Collab требуется авторизация.
Шаг 6. Последовательно запустите следующие ячейки: Check GPU, Setup 1, Setup 2, Download ContentVec, и Setup HF Downloads. Нажмите на кнопку "Play" рядом с каждым заголовком для запуска кода. Когда загрузка завершится, появится зеленая галочка около названия ячейки. Следующую ячейку нужно запускать только после полной загрузки предыдущей - если пропустить одну из строк, программа не сработает.
Наибольшее время занимает загрузка Setup 1, которая может занять до 10 минут. Остальные ячейки загружаются за несколько секунд. Загружать код для каждого трека не нужно - достаточно сделать это один раз. Обратите внимание, что через 2 часа код автоматически сбросится, и все действия придется повторить.
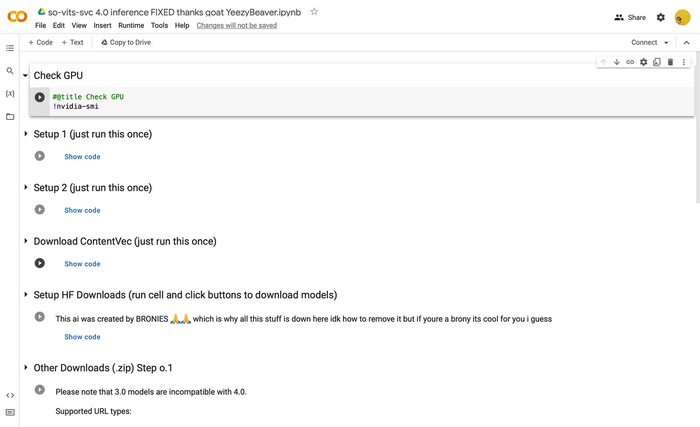
Шаг 7. Выберите голос, который будет использоваться для создания песни. Для этого найдите поле model_url под заголовком Other Downloads (.zip) Step o.1 и добавьте в него ссылку на папку с моделью голоса. Вы можете выбрать голос из списка доступных в этой же ячейке, например, Канье Вест, Кендрик Ламар или Дрейк. Также можно использовать библиотеку голосов на huggingface и скопировать ссылку на нужную папку оттуда. Доступны голоса российских исполнителей, таких как Oxxxymiron или Моргенштерн. Обратите внимание, что Мирон Федоров, выступающий под именем Oxxxymiron, и Алишер Моргенштерн внесены Минюстом в реестр иноагентов. Нейросеть поддерживает ссылки на любые заархивированные папки с Google Drive, MEGA, huggingface и других ресурсов. Вы можете использовать любую модель, которую найдете в интернете.

Шаг 8. Запустите еще одну ячейку с кодом - Extract.zip Downloads - Step o.2. Дождитесь завершения загрузки.

Шаг 9. Нажмите на иконку папки и перетащите в нее аудиофайл с а капеллой в формате wav, который вы подготовили на третьем шаге. Загрузка файла может занять несколько минут - длительность зависит от длины файла. Когда загрузка завершится, запустите код.
Шаг 10. Нажмите на кнопку "Convert". После этого появится плеер со сгенерированным голосом. Скачайте готовый трек, нажав правой кнопкой мыши на плеере. Если плеер не появился, то загрузите последний файл в папке слева. Обратите внимание, что на этом этапе могут возникнуть ошибки. Их причиной может быть выбор нерабочей модели или использование слишком длинной а капеллы. Проверьте правильность ввода текста и настройки языка, а также убедитесь в стабильности интернет-соединения.
Шаг 11. После того, как вы получили готовый трек, откройте любой аудиоредактор, например, бесплатную программу Audacity или онлайн-сервис veed.io. Совместите минус со сгенерированной а капеллой. При этом могут пригодиться навыки мастеринга и сведения музыки, если они у вас есть.
Как создать трек на сайте musicfy: простой способ без использования Google Collab
Этот метод гораздо проще, чем использование Google Collab, однако есть определенные ограничения. На сайте musicfy доступны только готовые пресеты голосов, поэтому добавить свой голос туда не получится.
Чтобы создать трек на сайте musicfy, выполните следующие шаги:
Шаг 1. Скачайте песню в формате mp3.
Шаг 2. Разделите трек на капеллу и минус. Для этого перейдите на сайт x-minus, загрузите там mp3 файл и скачайте полученные аудиофайлы.
Шаг 3. Перейдите на сайт musicfy. Войдите через свой Google-аккаунт и нажмите кнопку "Create a song". Загрузите в поле mp3-файл с капеллой или запишите свой голос.
Если файл не загружается, прокрутите страницу вниз, возможно появится сообщение об ошибке "Audio file is corrupted, please try uploading another file". Попробуйте загрузить файл еще раз.
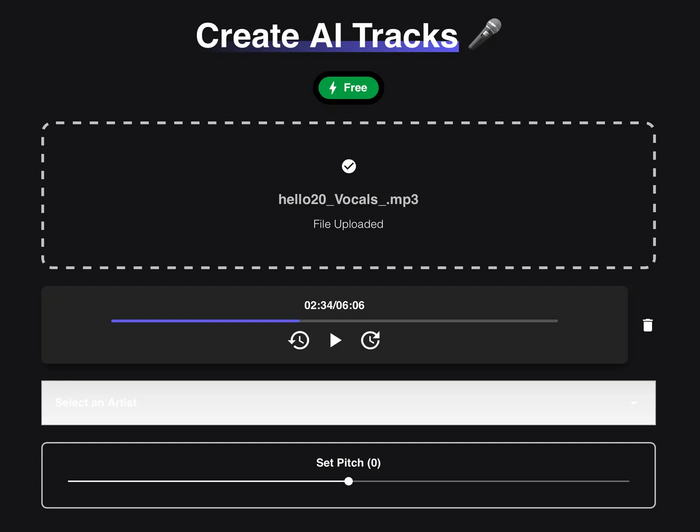
Шаг 4. Выберите один из готовых голосов. На сайте доступны вокалы множества исполнителей, например, Арианы Гранде, Дрейка, Граймса, Канье Уэста, Трэвиса Скотта и других. Также можно выбрать персонажей мультфильмов, таких как Губка Боб Квадратные Штаны или Питер Гриффин. Все эти голоса могут использоваться для записи русскоязычного текста.
Шаг 5. Нажмите кнопку "Convert". После обработки скачайте готовый файл. Если появляется ошибка, попробуйте еще раз.
Шаг 6. Совместите минус и сгенерированную капеллу в любом аудиоредакторе, например, бесплатной программе Audacity или онлайн-сервисе veed.io. Сохраните получившийся трек и наслаждайтесь своим творением!
Как выбрать способ генерации трека?
Один из вариантов - использование нейросети в Google Collab, которая позволяет создавать треки сотней голосов пользователей. Однако, этот метод затратен по времени и может выдавать ошибки, при этом не предоставляя ясной информации о причинах возникновения проблем. Чтобы их решить, иногда нужно искать помощь на форумах или видео-ресурсах, что может занять много времени.
В отличие от этого, Musicfy позволяет легко генерировать треки без запуска кода и вероятности ошибок, а также без необходимости конвертирования аудиофайлов. Однако, на сайте доступен только ограниченный выбор голосов.
Подпишитесь на мой телеграм, там я рассказываю про нейронные сети и обучаю вас их использовать.
И еще парочка AI каверов, в качестве бонусного трека
Показать полностью
6
3