Программа с открытым кодом для извлечения вокала из трека
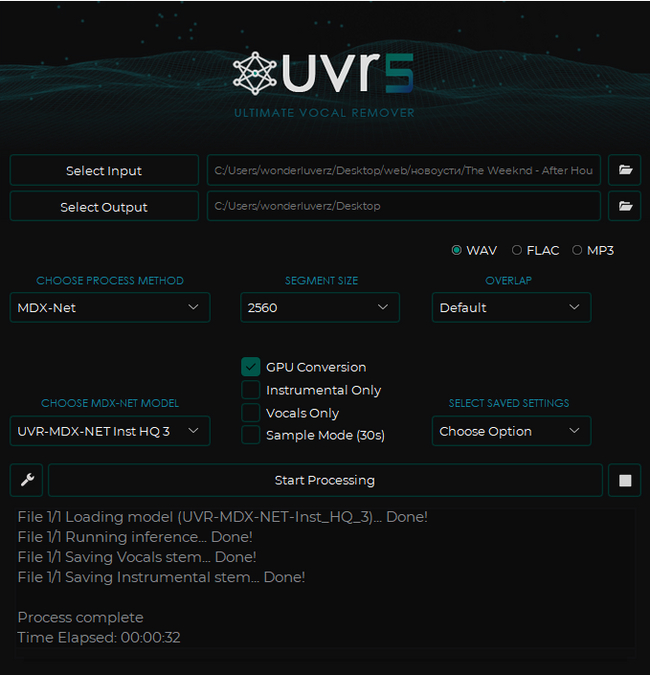
Всем привет! Сегодня Ultimate Vocal Remover GUI у нас на обзоре. Программа доступна на GitHub и установщиком, давайте посмотрим, на что она способна!
Я возьму три трека для пробы
DJ BoBo - Let The Dream Come True
Junior Caldera - Can't Fight This Feeling
The Weeknd - After Hours
Покажу работу на двух моделях, которые мне понравились больше всего - MDX-Net - очень качественно отделяет голос и Demucs - имеет возможность сплитнуть трек на 4 дороги - бас, ударные, мелодия и голос. Каждая хороша под свои задачи и как по мне эта программа справляется лучше онлайн-сервисов AI Splitter'a и Vocal Remover'а с их одной бесплатной попыткой. Кстати, пройдёмся по кнопкам и крутилкам внутри программы:

В окне Select Input выбираем файл с компьютера, с которым будем работать. Output соответственно выбираем куда сохранять
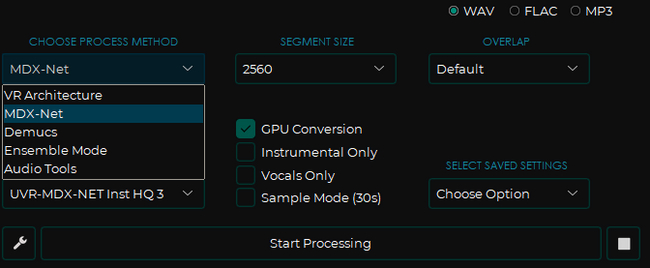
Choose process method - выбор модели. Вы можете поэкспериментировать, но, как я уже сказал, мне приглянулись две модели из этого списка.
В правом верхнем углу выбираем формат в который будем экспортировать.
Segment Size - вот тут сложнее. Как я понимаю - это что-то типа объёма буфера, что напрямую влияет на качество генерации. Я выставил 2560, но думаю можно и больше, но мне показалось этого более чем достаточно.
GPU Coversion - использовать графический процессор для более быстрого результат
Instrumentals/Vocal only - сохранить только вокал либо только инструментал
Sample Mode - для тех, кто хочет найти для себя лучшую модель - вместо полного трека демонстрирует 30-секундные отрывки с отделенным голосом
Overlap я поставил дефолтный. Вот кстати мои настройки для модели Demucs:
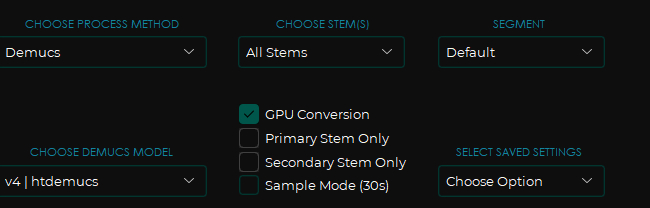
Давайте посмотрим на результат:
MDX-Net очень круто справилась с задачей, я думаю если выставить в Demucs буфер побольше то результат будет покруче!
До новых встреч, ждите новые гайды на классные нейросетевые штуки!
Интересна тема генерации музыки с помощью нейросетей? Добро пожаловать в Нейро-Звук🔉
Понравилось? Тогда милости прошу в мой телеграм канал, буду ждать тебя там!🔥