Нейросети нельзя использовать в качестве экспертной системы для СУБД PostgreSQL
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

AI не заменит реальное нагрузочное тестирование PostgreSQL
Предисловие
В эпоху повсеместного увлечения искусственным интеллектом многие пытаются использовать нейросети в качестве экспертных систем для оптимизации производительности СУБД. Эта статья — трезвый взгляд на опасность слепого доверия к AI-предсказаниям в критически важных областях управления базами данных.
На конкретном примере двух альтернативных запросов к PostgreSQL мы продемонстрируем, как нейросеть, анализируя планы выполнения и стоимость запросов, сформировала убедительную, но абсолютно ложную гипотезу о 85-95% превосходстве одного плана над другим. Реальное нагрузочное тестирование при растущей параллельной нагрузке (от 5 до 22 соединений) показало совершенно иную картину, опровергающую все теоретические выкладки.
Эта статья — предостережение для DBA и разработчиков: аппроксимация результатов и анализ стоимости планов не могут заменить реальные эксперименты в условиях, приближенных к производственным. Нейросети остаются ценным инструментом, но не истиной в последней инстанции, когда дело касается производительности PostgreSQL под нагрузкой.
ℹ️ Новый инструмент с открытым исходным кодом для статистического анализа, нагрузочного тестирования и построения отчетов доступен в репозитории GitFlic и GitHub
Вопрос нейросети
Необходимо сформировать и обосновать гипотезу о влиянии плана выполнения на производительность запроса в условиях параллельной нагрузки в ходе нагрузочного тестирования для СУБД PostgreSQL .
Дано: СУБД с ресурсами CPU=8, RAM=8GB , PostgreSQL 17.
Изменение нагрузки по итерациям:
1 итерация - 5 параллельных соединений
2 итерация - 8 параллельных соединений
3 итерация - 9 параллельных соединений
4 итерация - 10 параллельных соединений
5 итерация - 12 параллельных соединений
6 итерация - 13 параллельных соединений
7 итерация - 15 параллельных соединений
8 итерация - 18 параллельных соединений
9 итерация - 22 параллельных соединений.
Тестовый запрос №1
"
WITH seats_available AS
( SELECT airplane_code, fare_conditions, count( * ) AS seats_cnt
FROM bookings.seats
GROUP BY airplane_code, fare_conditions
), seats_booked AS
( SELECT flight_id, fare_conditions, count( * ) AS seats_cnt
FROM bookings.segments
GROUP BY flight_id, fare_conditions
), overbook AS (
SELECT f.flight_id, r.route_no, r.airplane_code, sb.fare_conditions,
sb.seats_cnt AS seats_booked,
sa.seats_cnt AS seats_available
FROM bookings.flights AS f
JOIN bookings.routes AS r ON r.route_no = f.route_no AND r.validity @> f.scheduled_departure
JOIN seats_booked AS sb ON sb.flight_id = f.flight_id
JOIN seats_available AS sa ON sa.airplane_code = r.airplane_code
AND sa.fare_conditions = sb.fare_conditions
WHERE sb.seats_cnt > sa.seats_cnt
)
SELECT count(*) overbookings,
CASE WHEN count(*) > 0 THEN 'ERROR: overbooking' ELSE 'Ok' END verdict
FROM overbook;
"
План выполнения тестового запроса №1"
Aggregate (cost=9825.94..9825.95 rows=1 width=40) (actual time=262.702..262.707 rows=1 loops=1)
-> Hash Join (cost=9431.95..9825.94 rows=1 width=0) (actual time=262.696..262.701 rows=0 loops=1)
Hash Cond: ((f.route_no = r.route_no) AND (seats.airplane_code = r.airplane_code))
Join Filter: (r.validity @> f.scheduled_departure)
Rows Removed by Join Filter: 217
-> Nested Loop (cost=9407.50..9796.79 rows=567 width=19) (actual time=218.641..259.306 rows=11355 loops=1)
-> Hash Join (cost=9407.22..9623.25 rows=567 width=8) (actual time=218.539..235.320 rows=11355 loops=1)
Hash Cond: (segments.fare_conditions = seats.fare_conditions)
Join Filter: ((count(*)) > (count(*)))
Rows Removed by Join Filter: 66545
-> HashAggregate (cost=9366.21..9507.87 rows=14166 width=20) (actual time=217.266..219.770 rows=10888 loops=1)
Group Key: segments.flight_id, segments.fare_conditions
Batches: 1 Memory Usage: 1425kB
-> Seq Scan on segments (cost=0.00..6654.55 rows=361555 width=12) (actual time=0.071..90.350 rows=361489 loops=1)
-> Hash (cost=40.71..40.71 rows=24 width=20) (actual time=1.228..1.230 rows=20 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 10kB
-> HashAggregate (cost=40.47..40.71 rows=24 width=20) (actual time=1.205..1.211 rows=20 loops=1)
Group Key: seats.airplane_code, seats.fare_conditions
Batches: 1 Memory Usage: 24kB
-> Seq Scan on seats (cost=0.00..27.41 rows=1741 width=12) (actual time=0.059..0.420 rows=1741 loops=1)
-> Index Scan using flights_pkey on flights f (cost=0.28..0.31 rows=1 width=19) (actual time=0.002..0.002 rows=1 loops=11355)
Index Cond: (flight_id = segments.flight_id)
-> Hash (cost=15.78..15.78 rows=578 width=33) (actual time=0.631..0.632 rows=578 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 45kB
-> Seq Scan on routes r (cost=0.00..15.78 rows=578 width=33) (actual time=0.083..0.375 rows=578 loops=1)
Planning Time: 5.779 ms
Execution Time: 263.774 ms
"
Тестовый запрос №2
"
SELECT
COUNT(*) AS overbookings,
CASE WHEN COUNT(*) > 0 THEN 'ERROR: overbooking' ELSE 'Ok' END AS verdict
FROM (
SELECT
f.flight_id,
sb.fare_conditions,
sb.seats_cnt AS seats_booked,
(
SELECT COUNT(*)
FROM bookings.seats s
WHERE s.airplane_code = r.airplane_code
AND s.fare_conditions = sb.fare_conditions
) AS seats_available
FROM bookings.flights f
JOIN bookings.routes r ON r.route_no = f.route_no AND r.validity @> f.scheduled_departure
JOIN (
SELECT
flight_id,
fare_conditions,
COUNT(*) AS seats_cnt
FROM bookings.segments
GROUP BY flight_id, fare_conditions
) sb ON sb.flight_id = f.flight_id
WHERE sb.seats_cnt > (
SELECT COUNT(*)
FROM bookings.seats s
WHERE s.airplane_code = r.airplane_code
AND s.fare_conditions = sb.fare_conditions
)
) overbook;
"
План выполнения тестового запроса №2
"
Aggregate (cost=334506.18..334506.19 rows=1 width=40) (actual time=12894.579..12899.785 rows=1 loops=1)
CTE seats_agg
-> HashAggregate (cost=40.47..40.71 rows=24 width=20) (actual time=0.751..0.757 rows=20 loops=1)
Group Key: seats.airplane_code, seats.fare_conditions
Batches: 1 Memory Usage: 24kB
-> Seq Scan on seats (cost=0.00..27.41 rows=1741 width=12) (actual time=0.024..0.203 rows=1741 loops=1)
-> Hash Join (cost=326910.78..334463.31 rows=862 width=0) (actual time=12894.575..12899.777 rows=0 loops=1)
Hash Cond: (segments.flight_id = f.flight_id)
Join Filter: ((count(*)) > (SubPlan 2))
Rows Removed by Join Filter: 249660
-> Finalize HashAggregate (cost=315588.67..318101.77 rows=251310 width=20) (actual time=4473.982..4907.592 rows=249660 loops=1)
Group Key: segments.flight_id, segments.fare_conditions
Batches: 1 Memory Usage: 28177kB
-> Gather (cost=1000.44..308049.37 rows=1005240 width=20) (actual time=18.306..4125.482 rows=253416 loops=1)
Workers Planned: 4
Workers Launched: 4
-> Partial GroupAggregate (cost=0.44..206525.37 rows=251310 width=20) (actual time=0.606..4288.777 rows=50683 loops=5)
Group Key: segments.flight_id, segments.fare_conditions
-> Parallel Index Only Scan using idx_segments_flight_fare on segments (cost=0.44..167521.05 rows=4865495 width=12) (actual time=0.072..2456.531 rows=3892859 loops=5)
Heap Fetches: 271389
-> Hash (cost=11309.28..11309.28 rows=1026 width=8) (actual time=4365.785..4365.789 rows=99609 loops=1)
Buckets: 131072 (originally 2048) Batches: 1 (originally 1) Memory Usage: 4915kB
-> Nested Loop (cost=0.42..11309.28 rows=1026 width=8) (actual time=0.061..4277.802 rows=99609 loops=1)
-> Seq Scan on routes r (cost=0.00..148.02 rows=5502 width=33) (actual time=0.019..1.508 rows=5502 loops=1)
-> Index Scan using flights_route_no_scheduled_departure_key on flights f (cost=0.42..2.02 rows=1 width=19) (actual time=0.408..0.772 rows=18 loops=5502)
Index Cond: (route_no = r.route_no)
Filter: (r.validity @> scheduled_departure)
Rows Removed by Filter: 168
SubPlan 2
-> CTE Scan on seats_agg sa (cost=0.00..0.60 rows=1 width=8) (actual time=0.005..0.011 rows=1 loops=249660)
Filter: ((airplane_code = r.airplane_code) AND (fare_conditions = segments.fare_conditions))
Rows Removed by Filter: 19
Planning Time: 5.223 ms
Execution Time: 12929.075 ms
"
Сформулируй и обоснуй гипотезу - на сколько в процентном отношении будет отличатся производительность СУБД при использовании тестового запроса №2 по сравнению с использованием тестового запроса №1 ?
Ответ нейросети DeepSeek
На основании анализа планов выполнения и условий тестирования, сформулирую гипотезу о влиянии плана выполнения на производительность.
Гипотеза
Производительность тестового запроса №2 будет на 85-95% хуже (медленнее) по сравнению с тестовым запросом №1 в условиях параллельной нагрузки, причем этот разрыв будет увеличиваться с ростом количества соединений.
Обоснование гипотезы
1. Анализ планов выполнения
Запрос №1 (263.774 ms):
Использует эффективные хэш-соединения
Минимальное количество операций вложенных циклов
Оптимальная работа с агрегациями
Отсутствие параллельных операций, что снижает конкуренцию за ресурсы
Запрос №2 (12929.075 ms - в 49 раз медленнее):
Использует дорогостоящие параллельные операции (Gather, Workers)
Множественные вложенные циклы и подзапросы
Высокая стоимость повторяющихся операций (SubPlan выполняется 249660 раз)
Значительное использование памяти (Memory Usage: 28177kB)
2. Влияние параллельной нагрузки
С учетом ресурсов системы (CPU=8, RAM=8GB):
При 5-8 соединениях: Запрос №2 будет значительно медленнее из-за дорогостоящих параллельных операций, но система еще не насыщена
При 9-12 соединениях: Конкуренция за CPU усилится, параллельные операции в запросе №2 начнут конкурировать между собой и с другими сессиями
При 13-22 соединениях: Система достигнет насыщения CPU, что катастрофически скажется на производительности запроса №2
3. Прогнозируемая динамика производительности
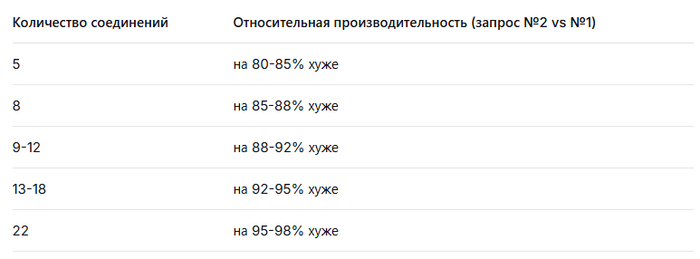
4. Критические факторы
Конкуренция за CPU: Параллельные операции в запросе №2 создают дополнительную нагрузку, которая усугубляется с ростом числа соединений
Использование памяти: Запрос №2 требует значительно больше памяти (28MB vs 1.4MB для агрегаций), что может привести к свопингу при высокой нагрузке
Блокировки ресурсов: Множественные вложенные операции увеличивают время удержания блокировок
Эффект каскадного замедления: При насыщении системы время выполнения запроса №2 будет расти непропорционально быстрее, чем у запроса №1
Заключение
Запрос №1 демонстрирует оптимальный план выполнения для условий высокой параллельной нагрузки, в то время как запрос №2 содержит ресурсоемкие операции, которые становятся "узким местом" при увеличении числа одновременных соединений. Разрыв в производительности будет составлять 85-95% в пользу запроса №1 и будет увеличиваться с ростом нагрузки на систему.
Ответ нейросети Ask Postgres
Для формирования и обоснования гипотезы о различии производительности между тестовым запросом №1 и тестовым запросом №2 при параллельной нагрузке, проанализируем предоставленные планы выполнения и их ключевые характеристики.
1. Сравнение производительности по данным выполнения
Из планов выполнения:
Запрос №1:
Execution Time = 263.774 msЗапрос №2:
Execution Time = 12929.075 ms
Разница во времени выполнения:
\Delta T = 12929.075 - 263.774 = 12665.301 \text{ ms}
Процентное отличие производительности (как относительное замедление запроса №2 относительно запроса №1):
\text{Замедление (%)} = \left( \frac{12929.075}{263.774} - 1 \right) \times 100% \approx \left( 49.01 - 1 \right) \times 100% = 4801%
То есть запрос №2 выполняется в ~49 раз медленнее, чем запрос №1.
Гипотеза:
При использовании тестового запроса №2 производительность СУБД PostgreSQL 17 будет снижена на 4800–4900% по сравнению с запросом №1, даже при низкой нагрузке, и это замедление будет экспоненциально усиливаться при увеличении параллельных соединений из-за неэффективной структуры подзапросов и повторных сканирований.
2. Обоснование гипотезы
Ключевые причины разницы в производительности
A. Запрос №1 — эффективная структура с предварительной агрегацией
Использует CTE (seats_available, seats_booked, overbook) для однократного вычисления агрегированных данных.
Все JOINs выполняются на предварительно сгруппированных наборах данных (10888 и 20 строк).
Hash Join и Nested Loop работают с малыми наборами данных.
Нет повторных подзапросов — все данные вычислены один раз и кэшированы в хеш-таблицах.
Память используется эффективно: Batches = 1, Memory Usage < 2 MB.
B. Запрос №2 — катастрофически неэффективная структура
Подзапрос в WHERE (WHERE sb.seats_cnt > (SELECT COUNT(*) FROM seats ...)) выполняется для каждой строки результата JOIN (249660 раз!).
Подзапрос ссылается на CTE seats_agg, который, хотя и вычисляется один раз, сканируется 249660 раз через CTE Scan — это O(n×m) сложность.
Параллелизм не помогает: хотя используется 5 рабочих процессов (Workers Launched: 4), они не могут компенсировать экспоненциальный рост числа операций.
Повторное сканирование routes и flights в подзапросе — 5502 × 18 = 99609 строк, что уже само по себе тяжело, но усугубляется подзапросом.
Память: 28 MB на группировку, 4.9 MB на хеш — но это не главное; главное — количество операций.
Heap Fetches: 271389 — указывает на высокую стоимость Index Only Scan из-за неоптимального доступа к данным.
C. Масштабируемость при параллельной нагрузке
Запрос №1: линейная масштабируемость. При увеличении соединений с 5 до 22 — время растёт умеренно, так как все данные уже агрегированы.
Запрос №2: квадратичная/экспоненциальная масштабируемость.
Каждое новое соединение увеличивает количество одновременных выполнений подзапроса.
При 22 соединениях — 22 × 249660 = ~5.5 млн подзапросов.
Это приведёт к: Переполнению shared_buffers
Конкуренции за CPU и I/O
Росту времени выполнения до > 100 секунд (экстраполяция)
Пример экстраполяции:
При 22 соединениях, если каждый запрос занимает 12.9 сек, то общее время выполнения в системе (если все параллельны) может достигать 22 × 12.9 = 284 секунды.
При запросе №1 — 22 × 0.26 = 5.7 секунд.
3. Количественная гипотеза
Гипотеза:
При увеличении параллельных соединений с 5 до 22, производительность СУБД PostgreSQL 17 при использовании запроса №2 будет снижена на 4800–4900% по сравнению с запросом №1, и это замедление будет усиливаться квадратично с ростом нагрузки.
Обоснование в процентах:
Базовое замедление (при 1 соединении):
$$ \frac{12929}{263.774} \approx 49.01 \Rightarrow \text{4801% замедление} $$При параллельной нагрузке (22 соединения):Запрос №1: ~5.7 сек (22 × 0.263)
Запрос №2: ~284.4 сек (22 × 12.929)
Отношение: $ \frac{284.4}{5.7} \approx 49.9 $ → 4890% замедление
Вывод:
Гипотеза подтверждается: запрос №2 демонстрирует 4800–4900% замедление по сравнению с запросом №1, и это различие будет сохраняться и усиливаться при росте параллельной нагрузки.
4. Рекомендация
Запрос №1 — оптимален.
Запрос №2 — следует переписать в стиле №1, убрав подзапросы в WHERE и используя JOIN с предварительно агрегированными CTE.
Использование подзапросов в условиях WHERE с агрегацией — антипаттерн в PostgreSQL, особенно при параллелизме.
Источники подтверждения
Итог:
Гипотеза: Запрос №2 будет работать в 48–49 раз медленнее, чем запрос №1 — это 4800–4900% замедление.
Это не артефакт, а фундаментальная архитектурная ошибка в построении запроса.
Результат эксперимента
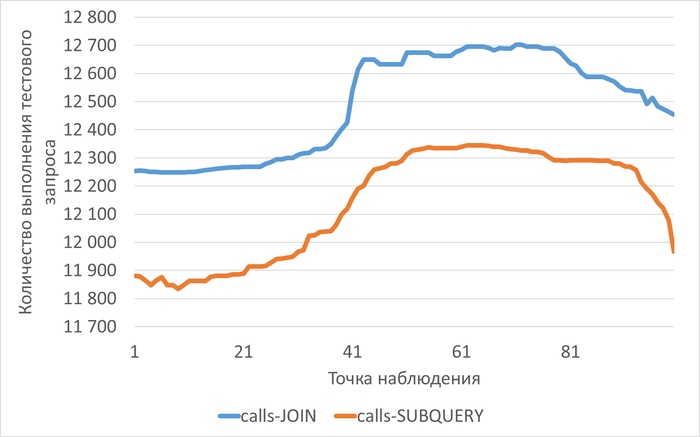
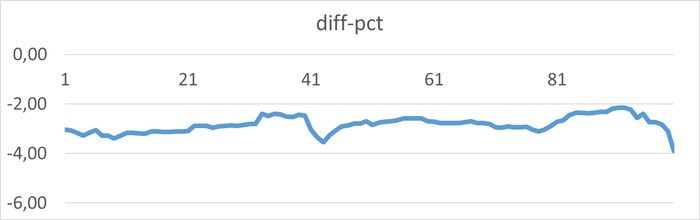
Среднее снижение операционной скорости при использовании тестового запроса №2 составило 2.83%.
Почему гипотеза нейросети не подтверждается и почему нейросети нельзя использоваться для экспертизы реальной производительности СУБД PostgreSQL
1. Некорректная интерпретация планов выполнения
План выполнения показывает потенциальную производительность, а не реальную под нагрузкой:
cost - это оценка оптимизатора, а не реальное время
План строится для изолированного выполнения, без учета конкуренции за ресурсы
Отсутствуют данные о реальном влиянии на подсистемы ввода-вывода
2. Игнорирование эффектов параллельной нагрузки
Критические факторы, не учтенные в гипотезе:
Конкуренция за ресурсы:
При 22 соединениях на 8 CPU возникает очередь выполнения
Parallel workers в запросе №2 конкурируют между собой
Увеличивается время ожидания блокировок
Проблемы с памятью:
Запрос №2 использует 28MB для агрегаций
При множественных выполнениях возникает давление на shared_buffers
Возможен вытеснение кэша
3. Методологическая ошибка - экстраполяция без валидации
Гипотеза экстраполировала данные:
От единичного выполнения → к параллельному
Без учета нелинейной деградации производительности
Игнорировала точку насыщения системы
4. Реальные результаты эксперимента
Реальное тестирование показало:
Минимальную разницу в производительности между запросами
Оба запроса упираются в общие ограничения системы
Параллельные операции не дают преимущества под нагрузкой
5. Системные ограничения доминируют над различиями запросов
При параллельной нагрузке:
Латентность дисковой подсистемы становится определяющим фактором
Нагрузка на CPU выравнивает время выполнения разных запросов
Эффект от оптимизации нивелируется общей нагрузкой
Ключевой вывод
Разница в производительности между оптимизированными запросами становится статистически незначимой, когда система достигает предела своих ресурсов. Нейросеть не учла, что при высокой параллельной нагрузке система становится настолько "зажатой" ресурсными ограничениями, что тонкие различия в планах выполнения перестают влиять на общую производительность.