*** Стр.02 Что такое ручной сканер. Зачем и кому нужен ручной сканер. Цена. Основные характеристики. Как у меня появился ручной сканер и что я им сделал в первую очередь. ***
Ручной сканер - немного странный девайс, результат скрещивания обычного планшетного сканера и смартфона.
Отличается низкой ценой около 3700 рублей по состоянию на 27.01.2024 и маленькими размерами (его длина заточена под ширину стандартного листка бумаги и равна примерно 31см).
Портативный ручной сканер PhotoScan будет полезен для мобильных людей, работающих с бумажными документами, и нежелающих использовать свой смартфон для фотографирования документов.
Тип сканера - Портативный мобильный сканер; ручной
Тип датчика сканера - CIS
Страна производства - Китай
Разрешение сканера - 900x900 dpi
Автоподача оригиналов для сканирования - нет
Одной из особенностей модели PhotoScan 01 является возможность работать автономно без подключения к компьютеру или смартфону.
В чехле сканер похож на элегантный маленький дамский зонтик или на маленькую дамскую полицейскую дубинку.
Приобрести этот аппарат меня сподвигло желание попробовать что-то принципиально новенькое - это да, ручной сканер принципиально отличается от планшетных.
*** Стр.03 Комплект поставки. Что там есть. Чего там нет, но требуется. ***
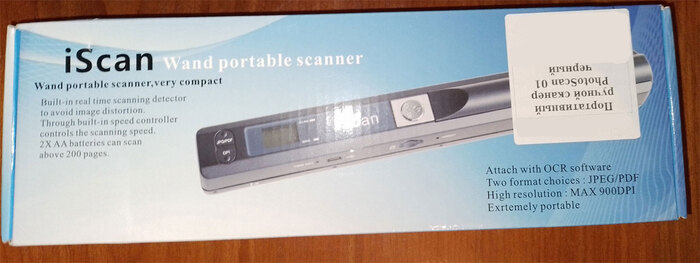
На коробке поставки следующий текст.
Портативный сканер в виде волшебной палочки, очень компактный
Встроенный детектор сканирования в реальном времени, чтобы избежать искажения изображения.
Через встроенный регулятор скорости можно контролировать скорость сканирования.
Две батарейки АА позволяют сканировать более 200 страниц.
Прилагается программное обеспечение оптического распознавания текстов.
Два варианта формата: JPEG/PDF.
Высокое разрешение: МАКС. 900 точек на дюйм.
После того, как поверхностно разобрались с текстами на коробке, откроем ее и посмотрим внутрь.
Помимо самого девайса (который мы посмотрели выше) и короткой инсрукции (ее по разберем пошагово далее) здесь мы найдем следующие вещи.
Калибровочная карточка - плотная картонка с инструкцией, как проводить эту самую калибровку.
Диск с софтом для распознавания текстов - софт OCR ABBYY FineReader 11. Сразу важное примечание - предупреждение. Сама версия софта бесплатная. Но есть ловушка. Программа предложит произвести обновление. Этого делать не надо. Обновленная версия запросит провести оплату.
Кабель - для соединения с компьютером.
Чехол - для хранения и переноски.
Салфетка - для протирки от пыли и грязи.
Предметы, которых нет в поставке, но которые нужно иметь.
2 батарейки АА - именно от этих батереек дефайс берет энергию. Но в комплект батарейки не входят, видимо из опасения, что они успеют разрядиться прежде чем достигнут покупателя.
Карта памяти 32ГБ - точнее, не более 32-х ГБ.
Тупая иголка - дырки, в которые надо тыкать в девайсе есть, а вот самой тупой иглы почему-то нет. Даю ее изображение, чтобы было совсем понятно, о чем речь. Обычно входит в состав поставки смартфонов. Эта тупая иголка понадобиться для установки времени (1 Time set - Установить время) и форматирования карты (4 Format Button - Кнопка "Формат").
Вообще, очущается странный и стойкий закос под старину. Тут и диск вместо флешки (а у Вас есть устройство для чтения ДВД дисков?), и жесткое ограничение по памяти для карты. Хорошо еще, что пока такие карты есть в продаже.
Итак, теперь нам понятно, что нас ждет в поставке, что надо иметь, можно двигаться дальше.
*** Стр.04 - Стр.10 Инструкция вложенная. ***
Здесь и далее мы будем сканировать инструкцию этим сканером, затем предлагаемым софтом будем производить распознавание текста. И, до кучи, переведем это все на русский.
***** Руководство по портативному сканеру *****
НОВЫЙ и ПРАКТИЧНЫЙ — цифровой портативный сканер.
Разрешение сканирования: 300/600/900 точек на дюйм.
Сохраняет файл JPG или PDF на карту microSD.
Поддерживает карту Micro SD до 32 ГБ.
Примечание. Для MS Windows 10 установка драйвера не требуется. Вообще, сканер работает как самостоятельный дефайс вообще без подключения к компьютеру. Подключение к компьютеру по USB требуется в момент передачи созданных файлов на компьютер.
1 Установить время Нажмите эту кнопку, чтобы войти в режим установки времени
2 USB-порт Порт USB 2.0, высокоскоростной
3 SD Card Карта памяти MicroSD
4 Кнопка "Формат" Нажмите эту кнопку, чтобы отформатировать карту Micro SD.
5 Форматы хранения Выберите форматы хранения. На ЖК-дисплее будет отображаться JPG/PDF.
6 Светодиодный индикатор сканирования Сканирование готово: светодиодный индикатор горит зеленым светом.
7 Питание/Сканирование Включение/выключение питания: удерживайте эту кнопку в течение 2 секунд, затем включите питание или выключите питание. После включения питания нажмите эту кнопку для сканирования. Затем нажмите эту кнопку, чтобы остановить сканирование.
8 Источник питания 2 батарейки АА
9 Разрешение На ЖК-дисплее отобразится значок режима высокого/среднего/низкого разрешения 900/600/300 точек на дюйм.
10 ЖК-дисплей Отображение статуса сканирования
11 Светодиодный индикатор корректности сканирования При превышении скорости: светодиодный индикатор горит красным.
1 Инструкции по SD-карте SD CardФотографии (отсканированные изображения) будут храниться на карте Micro SD.
2 Индикатор заряда батареи
Power adequate - Мощность достаточная
Battery low - Низкий заряд батареи
3 Режим JPG/PDF Могут быть созданы файлы JPG или PDF
4 Счетчик Отображение номера файла на карте Micro SD
5 Выбор разрешения Высокое:900DPI / Среднее:600DPI / Низкое:300DPI
*** 3. Как использовать этот сканер ***
1. Открыть дверцу батарейного отсека
Для этого надо выполнить 2 движения:
Сдвинуть дверцу (крышку) батарейного отсека на 7 мм.
Поднять дверцу (крышку) батарейного отсека вверх.
2. Поместите 2 щелочные батарейки типа АА в батарейный отсек.
3. Удерживайте кнопку питания/сканирования нажатой в течение 2 секунд, чтобы включить девайс.
3.2 Вставьте карту MicroSD
3.3 Установить время (год, месяц, день, часы, минуты)
1. нажмите кнопку TIME SET для перехода в режим установки времени.
2.1 xx отобразиться на ЖК-дисплее, нажатием кнопок JPG/PDF и DPl меняем значение.
3. Нажмите кнопку SCAN, чтобы подтвердить установку времени (точнее, текущего параметра: 1-год, 2-месяц, 3-день, 4-часы, 5-минуты).
4. Переход к настройкам следующего режима (имеется ввиду 1-год, 2-месяц, 3-день, 4-часы, 5-минуты) на ЖК-дисплее, см. ниже:
5. После установки всей информации нажмите TIME SET, чтобы выйти.
Чтобы стало совсем понятно, посмотрим конкретный пример.
Допустим, нам следует установить следующие значения даты-времени: 26.01.2024 18:44
1 :: 24 - устанавливаем год 2024
2 :: 01 - устанавливаем месяц 01 - январь
3 :: 26 - устанавливаем день 26
4 :: 18 - устанавливаем час 18
5 :: 44 - устанавливаем минуты 44
С установленной датой и временем будут создаваться файлы с отсканированным изображением.
3.4 Отформатируйте карту MicroSD
1. Вставьте новую карту MicroSD в сканер, затем откройте (имеется в виду "включите") сканер.
2. Нажмите кнопку формата, на ЖК-дисплее отобразится "F".
3. Нажмите кнопку питания/сканирования (главная большая кнопка), чтобы отформатировать карту MicroSD.
4. Индикатор SD-карты будет мигать до завершения форматирования карты MicroSD.
По факту процесс форматирования карты MicroSD занял несколько секунд, после чего карта успешно работала без видимых проблем.
3.5 Установить разрешение:
Нажмите кнопку DPI, чтобы выбрать Высокое разрешение/Среднее разрешение/Низкое разрешение.
На ЖК-дисплее отобразится значок высокого разрешения/среднего разрешения/низкого разрешения.
Примечание. Я далее работал только с высоким разрешением. Не уловил, какой смысл работать со средним или с низким разрешением.
3.6 Установить цветовой режим сканирования
Нажмите кнопку JPG/PDF и выберите формат JPG/PDF.
На ЖК-дисплее отобразится значок режима JPG/PDF.
Сканирование одной рукой:
Установите правильное положение сканера на сканируемых объектах.
Удерживая сканер, нажмите кнопку SCAN (СКАНИРОВАНИЕ).
Двигая медленно сканер, ваша рука должна оставаться устойчивой, чтобы получить изображение высокого качества.
Нажмите кнопку питания/SCAN, чтобы остановить сканирование.
Примечание. Качество сканирования зависит в основном от правильности движения сканера. А это зависит от твердости вашей руки и от опыта сканирования. Все листы инструкции сделаны с помощью этого сканера. Этой мой первый опыт ручного сканирования. Как вы заметили, качество не очень высокое.
Первые 5 файлов, созданных при помощи этого сканера.
26.01.2024 19:10 525 732 IMAG0003.JPG
26.01.2024 19:07 493 004 IMAG0002.JPG
26.01.2024 19:02 648 931 IMAG0005.JPG
26.01.2024 19:02 90 661 IMAG0004.JPG
26.01.2024 18:49 1 576 408 IMAG0001.JPG
Обратите внимание на маленький размер одного из файлов из этой первой пятерки. Это признак того, что файл получился с некачественным изображением.
Вообще, я думаю, не стоит расстраиваться если у меня или у вас первые файлы получатся с не слишком качественными изображениями. В отличие от привычного планшетного сканера, здесь важное значение имеет твердость руки, т.к. протяжка производится вручную. Нужна тренировка кисти руки!
*** 4. Инструкции по светодиодным сигналам ***
"зеленый" Сигнал включен – сканирование в процессе.
"зеленый" Сигнал выключен - сканирование завершено.
"красный" Сигнал включен - сканирование слишком быстро. Перезапускаем, снова сканируем.
"красный" Сигнал выключен - сканирование нормальное. Продолжайте процесс сканирования.
*** Итоги. Выводы. Пожелания. ***
Если вы любите необычные девайсы, вам нравится процесс сканирования, а рука ваша тверда, то купите этот гаджет хотя бы просто для развлечения.
Если вам предстоит большая работа по сканированию большого количества разных документов, то полагаться на этот маленький сканер не стоит. Лучше приобрести обычный планшетный сканер.
Желаю успеха в сканировании!
Бесплатно, без СМС, без регистрации.