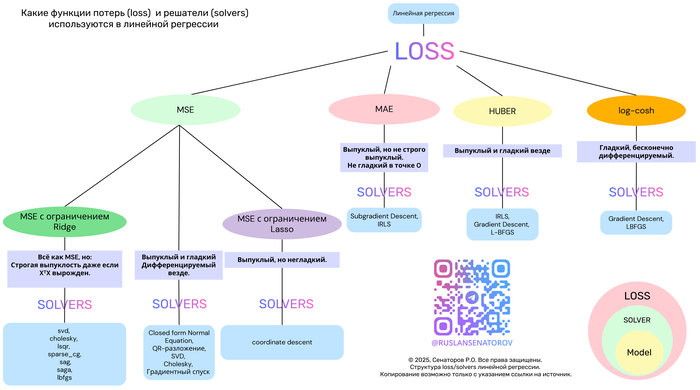
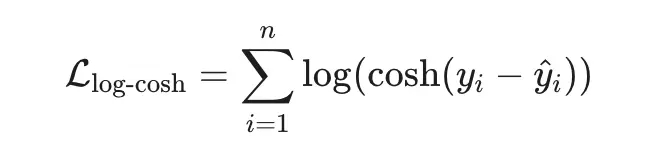Элис ложится в больницу в США. Её лечащий врач и страховая компания имеют доступ к подробной информации о её состоянии, и нередко эти же данные известны и государственным органам штата. Тридцать три штата, владея такими сведениями, не просто хранят их у себя и не всегда ограничивают к ним доступ. Вместо этого они по закону передают или даже продают часть этих данных исследователям. И вот штаты обращаются к вам — как к специалисту по информатике, IT, политике, консультанту или эксперту по конфиденциальности — с вопросом: действительно ли эти данные обезличены? Можно ли по ним узнать конкретного человека? Чаще всего у вас нет чёткого понимания, насколько реален такой риск. В этом тексте рассказывается, как мне удалось сопоставить имена пациентов с «анонимными» медицинскими данными, проданными штатом Вашингтон, и как власти штата отреагировали на это. Подобные исследования помогают улучшать практику обмена данными, уменьшать угрозы для частной жизни и стимулируют разработку более надёжных технических решений.
Если кратко описать результаты: штат Вашингтон продаёт набор медицинских данных о пациентах за 50 долларов. В этом публичном наборе содержалась информация почти обо всех госпитализациях за один конкретный год: демографические характеристики пациентов, диагнозы, выполненные процедуры, имена лечащих врачей, названия больниц, общая стоимость лечения и способ оплаты. Имена и точные адреса пациентов были удалены, оставались только пятизначные почтовые индексы. В то же время в местных газетах за этот год регулярно выходили материалы со словом «госпитализация», где назывались имена людей, указывалось место их проживания и причина попадания в больницу, например авария или нападение. Тщательно проанализировав четыре новостных архива по штату Вашингтон в единой поисковой системе, удалось однозначно сопоставить записи в медицинском наборе данных с 35 из 81 таких газетных статей за 2011 год (то есть с 43 %), фактически привязав имена к конкретным записям пациентов. Все найденные совпадения были проверены и подтверждены независимой третьей стороной.
После того как была продемонстрирована возможность повторной идентификации пациентов, власти штата Вашингтон изменили порядок предоставления этих данных и ввели трёхуровневую систему доступа. Теперь любой желающий может бесплатно скачать только агрегированные статистические таблицы. За 50 долларов и при подписании соглашения об использовании данных можно получить уже сокращённый, частично отредактированный вариант набора. А полный доступ ко всем полям, которые были доступны до этого эксперимента, теперь предоставляется лишь ограниченному кругу заявителей, прошедших проверку.
Введение
Деидентификация — это практика, при которой из персональных данных убирают имя, адрес и другую явно идентифицирующую информацию. Логика проста: если по данным нельзя установить конкретного человека, ими можно делиться, не рискуя ему навредить.
«Повторная идентификация» — это ситуация, когда этот принцип нарушается: по формально обезличенным данным всё-таки удаётся понять, кому они принадлежат.
Юристы сегодня придерживаются двух противоположных взглядов на реальный риск повторной идентификации, и эти позиции важны и для специалистов по компьютерным наукам, и для ИТ-практиков, и для самих пациентов.
Пол Ом, профессор права из Джорджтауна, утверждает, что в современном мире с обилием данных сделать их действительно анонимными невозможно. Если это верно, логичный вывод — отказаться полагаться на технические методы защиты и искать нетехнические решения. Его оппонентка, Джейн Яковиц из юридического факультета Университета Аризоны, заявляет, что достоверных случаев повторной идентификации не было, а те, о которых говорили раньше, преувеличены или неправильно интерпретированы. Если права она, значит, текущие «кустарные» подходы к деидентификации уже достаточны и не требуют новых технологий или изменений в политике.
Хотя эти позиции противоречат друг другу, обе по факту тормозят развитие технологий защиты. Дифференциальная конфиденциальность, которая даёт формальные гарантии того, насколько ограничена возможность повторной идентификации, стала одним из ключевых направлений исследований в компьютерной конфиденциальности. Но даже если бы такие инструменты уже были широко доступны, ни одна из описанных юридических позиций не подталкивала бы к их активному внедрению. Чтобы новые технологии защиты конфиденциальности действительно начали применять, нужно донести до общества реалистичное представление о рисках и возможном вреде.
В качестве примера рассмотрим общедоступные данные о госпитализациях. Иногда информация о лечении выглядит совершенно безобидной — сломал руку, наложили гипс. Но бывают и другие случаи: например, после ДТП человека экстренно привозят в больницу, и там выявляют алкогольную или наркотическую зависимость. Понятно, что разглашение таких сведений может серьёзно задеть человека, поэтому к публикации данных о пациентах нужно относиться очень осторожно.
Несколько лет назад многие штаты США приняли законы, обязывающие больницы передавать информацию о каждом пациенте, госпитализированном в стационар. Большинство этих штатов затем широко распространяют копии этих данных для разных целей. Фактически любой желающий может получить открытую версию базы, где есть демография пациентов, диагнозы и проведённые процедуры, список лечащих врачей, структура платежей и сведения о том, каким образом оплачивался каждый случай госпитализации. Имена пациентов при этом убираются, но нередко сохраняются почтовые индексы.
Такие базы на уровне штатов существуют много лет и активно используются. Если бы с ними были серьёзные проблемы, можно было бы ожидать множество выявленных инцидентов. На момент написания текста автор не нашёл сообщений о нарушениях конфиденциальности, связанных именно с этими базами, хотя непонятно даже, куда и как о таких нарушениях можно сообщать. К тому же большинство людей вообще не знают о существовании этих государственных баз, поэтому, даже столкнувшись с утечкой или злоупотреблением, вряд ли свяжут её именно с открытыми данными штата.
С другой стороны, есть тревожные, хотя и не подтверждённые факты. В 1996 году в опросе компаний из списка Fortune 500 треть из 84 респондентов заявили, что используют медицинские данные сотрудников при решении вопросов найма, увольнения и продвижения. Неясно, насколько это соответствует действительности, но теоретически это возможно, и в условиях непрозрачного обмена данными выявить подобные злоупотребления почти нереально, хотя последствия могут быть крайне тяжёлыми. Поэтому необходим наглядный, конкретный пример того, как можно идентифицировать пациентов по таким данным.
Представим, что вы знаете, что некий человек обращался в больницу, а также примерно понимаете причину обращения и/или знаете его возраст, пол и почтовый индекс. Сможете ли вы найти его запись в государственной медицинской базе?
На первый взгляд, задача сопоставления пациентов с общедоступными медицинскими базами кажется академическим упражнением или праздным любопытством. Но на практике возможность пользоваться такими базами позволяет работодателям проверять здоровье сотрудников, банкам — учитывать медицинские сведения при оценке кредитоспособности, компаниям по анализу данных — строить личные медицинские профили, журналистам — узнавать о болезнях публичных фигур, а обычным людям — следить за состоянием здоровья друзей, родственников или соседей. Все эти акторы вполне могут знать, когда человек попадал в больницу, и иметь в распоряжении достаточно дополнительных сведений, чтобы найти его запись в открытой базе госпитализаций.
Закон HIPAA не распространяется на штаты
Закон о переносимости и подотчётности медицинского страхования (HIPAA) — федеральный закон США 1996 года, который регулирует обмен медицинскими данными: кто и при каких условиях врачи, больницы и страховые компании могут делиться информацией о пациентах. Однако государственные (штатные) базы медицинских данных под действие HIPAA не попадают. Когда штат выступает как сборщик и распространитель данных, он не считается «субъектом HIPAA». Кроме того, штат имеет право передавать данные так, как это разрешено законами самого штата и в том формате, который он сочтёт допустимым. Возникает вопрос: чем подход штатов отличается от требований HIPAA?
В Правилах конфиденциальности HIPAA есть положение «Безопасная гавань» (Safe Harbor), которое описывает, как можно публиковать медицинские данные. Там установлены конкретные ограничения:
в датах можно указывать только год, без месяца и дня;
почтовый индекс можно публиковать только по первым трём цифрам и только в том случае, если суммарное население всех индексов с такими первыми тремя цифрами превышает 20 000 человек;
если население меньше 20 000, вместо реального индекса указывается 00000;
из данных нужно убрать явные идентификаторы — имена, номера социального страхования, точные адреса и т.п.
Теперь сравним с практикой штатов. Среди тех, кто публикует данные о госпитализациях на уровне штата, лишь три штата делают это по стандартам HIPAA; остальные 30 этим стандартам не следуют. Многие из них включают более детальные сведения — например, указывают не только год рождения пациента, но и месяц. Другие, наоборот, дополнительно обобщают данные по сравнению с HIPAA: используют возрастные интервалы вместо точного возраста и/или публикуют диапазоны почтовых индексов, а не конкретные значения.
Предыстория
Под «повторной идентификацией» медицинских данных понимают ситуацию, когда удаётся точно и однозначно связать конкретного человека с его медицинской записью. Такие эксперименты уже проводились и раньше.
В 1997 году я узнала, что медицинская информация о госслужащих станет доступна довольно широкому кругу лиц. Владельцы данных убрали явные идентификаторы — имя, адрес и т.п. — в соответствии с тогдашними стандартами деидентификации. Однако в базе остались дата рождения, пол и пятизначный почтовый индекс. Простые прикидки заставили задуматься: в году 365 дней, пол — один из двух, средняя продолжительность жизни ~78 лет. Если перемножить, получается около 56 940 возможных комбинаций. При этом в среднем в одном пятизначном почтовом индексе проживает всего около 25 000 человек. Значит, многие комбинации «дата рождения + пол + индекс» будут уникальными.
Чтобы проверить гипотезу, нужно было найти конкретного человека в базе. Тогдашний губернатор Массачусетса Уильям Уэлд был идеальным примером: его дата рождения и домашний адрес в Кембридже были в открытом доступе. За 20 долларов я купила список избирателей Кембриджа, где для 54 805 зарегистрированных избирателей были указаны имя, адрес, дата рождения, пол и история голосования. Оказалось, что сочетание «дата рождения + пол + почтовый индекс» Уэлда уникально и в списке избирателей, и в медицинской базе, что позволило однозначно сопоставить его личность с записью в формально обезличенном файле о госслужащих.
История быстро дошла до Вашингтона, округ Колумбия, где как раз обсуждались вопросы конфиденциальности в здравоохранении в рамках будущего закона HIPAA. Этот эксперимент по повторной идентификации заметно повлиял на формирование правил конфиденциальности HIPAA, и меня упомянули в преамбуле. Обсуждение случая Уэлда также привело к усилению защиты демографических данных в регулировании по всему миру.
После этого было проведено ещё несколько экспериментов по повторной идентификации. Сразу после истории с Уэлдом я сделала множество подобных проектов, но страх, шок, непонимание и отсутствие финансирования привели к тому, что результаты так и не были опубликованы. Например, в деле «Университет Южного Иллинойса против Департамента здравоохранения» сам Департамент признал, что я успешно повторно идентифицировала детей по комбинации {тип рака, почтовый индекс, дата постановки диагноза}. Суд в решении похвалил мой профессионализм, адвокаты называли меня «богиней повторной идентификации», но одновременно суд засекретил детали методики и запретил её публикацию. То же самое произошло и с другими ранними работами по повторной идентификации данных опросов и фармацевтических исследований.
В тех немногих случаях десять лет назад, когда эксперименты удавалось довести до публикации, журналы всё равно часто отказывали — и не из-за качества науки. Издания по информатике не хотели публиковать работы, где описывалась только атака с повторной идентификацией, без готового технического «лекарства», хотя авторы и утверждали, что сами такие атаки должны стимулировать создание новых технологий защиты. Журналы по политике в области здравоохранения, напротив, боялись, что публикация таких результатов нанесёт удар по существующей практике обмена данными, хотя именно рост масштабов обмена за счёт технологий требует их пересмотра. В итоге даже пример с Уэлдом и анализ демографической уникальности, которые позже повлияли на глобальное регулирование конфиденциальности, были первоначально отклонены более чем 20 научными журналами.
Финансирование тоже давали неохотно. Десять лет назад гранты на эксперименты по повторной идентификации обычно выдавали только при условии, что результаты покажут отсутствие риска или что все проблемы можно будет «закрыть» некой модной теоретической технологией, находящейся в разработке. Если ожидался неудобный результат о реальных рисках, деньги, как правило, не выделялись — а без них трудно провести систематические исследования.
Отсутствие опубликованных данных сыграло на руку критикам, которые стремились убедить общество, что рисков почти нет (иногда, доходя до сильных искажений фактических сведений о повторной идентификации).
Спустя десять лет Эль Эмам и соавторы провели обзор литературы и нашли всего 14 опубликованных атак с повторной идентификацией. Из них 11 они исключили, посчитав, что это лишь демонстрационные или оценочные атаки исследователей, а не «реальные» повторные идентификации, проверяемые на практике. В эту группу они, например, отнесли работу Нараянана и Шматикова, которые показали, как можно повторно идентифицировать пользователей по набору анонимизированных историй просмотров Netflix, сопоставляя их с публичными (идентифицированными) отзывами о фильмах. Хотя Эль Эмам и коллеги в своём обзоре фактически «отмахнулись» от этого эксперимента, он вылился в расследование Федеральной торговой комиссии США и судебный иск, который Netflix затем урегулировал.
Из трёх оставшихся, признанных «реальными» повторными идентификациями, две Эль Эмам и соавторы отвергают как не соответствующие стандартам HIPAA. Оставшееся исследование они, напротив, представляют как выполненное по требованиям HIPAA и демонстрирующее очень низкий риск повторной идентификации. Однако в этом эксперименте авторы по сути только заново воспроизвели мой старый эксперимент времён до HIPAA, но уже на данных, отредактированных по HIPAA. Работа была чрезмерно зациклена на одном конкретном сценарии и не учитывала другие возможные стратегии атак, которые могли бы оказаться успешнее. Это серьёзный недостаток, который Эль Эмам и коллеги не учитывают. Тем не менее их обзор подчёркивает: нам по-прежнему не хватает целостного понимания реальных рисков повторной идентификации.
Такое бедное состояние науки о рисках повторной идентификации в мире, где объём данных и их доступность постоянно растут, сегодня вызывает ещё больше тревоги, чем десять лет назад. Отсюда логичный вопрос: можно ли сейчас, при текущем уровне технологий и открытости данных, повторно идентифицировать пациентов по медицинским данным штатов?
Это была только вводная часть
В премиум-версии материала показан сам эксперимент: как новости, ZIP-коды и дата рождения превратились в имена и диагнозы, что ответили пациенты по телефону и почему после этого штаты срочно переписывали законы о конфиденциальности.