Закреплено

Искусственный интеллект
4 822 поста
•
11 401 подписчик
0 просмотренных постов скрыто

Простота в машинном обучении: один агент превосходит сложные системы
Обзор статьи «Operand Quant: A Single-Agent Architecture for Autonomous Machine Learning Engineering»
Автор: Денис Аветисян
Автономность и Сложность: Поиск Баланса
Автоматизированное машинное обучение (AutoMLE) обещает демократизировать разработку искусственного интеллекта, однако сталкивается со значительными трудностями на пути к истинной автономии. Если система держится на костылях, значит, мы переусложнили её. Текущие подходы часто полагаются на хрупкие эвристики или обширный человеческий надзор, ограничивая масштабируемость и адаптивность. Мы наблюдаем тенденцию к модульности ради модульности, но модульность без понимания контекста — иллюзия контроля.
Долгое время автоматизация ограничивалась решением узких, предопределённых задач. Но для настоящего прорыва требуется не просто автоматизация отдельных шагов, а создание агента, способного к выполнению всего спектра задач, возникающих в процессе машинного обучения. Такой агент должен уметь не только подбирать модели и параметры, но и самостоятельно проводить анализ данных, выявлять проблемы, проектировать эксперименты и интерпретировать результаты.
Необходимо смещение парадигмы: от автоматизации конкретных задач к созданию агента, обладающего общими навыками машинного обучения. Такой агент должен воспринимать процесс машинного обучения не как набор изолированных этапов, а как единую, взаимосвязанную систему. Он должен уметь адаптироваться к новым данным, новым задачам и новым требованиям, без необходимости постоянного вмешательства человека.
Создание такого агента — сложная задача, требующая новых подходов к проектированию и реализации систем искусственного интеллекта. Необходимо разработать новые алгоритмы и методы обучения, которые позволят агенту эффективно работать в условиях неопределенности и изменчивости. Также необходимо создать новые инструменты и инфраструктуру, которые обеспечат агенту доступ к необходимым ресурсам и данным.
Однако, несмотря на все сложности, создание автономного агента для машинного обучения — вполне достижимая цель. Успех в этой области откроет новые возможности для развития искусственного интеллекта и позволит демократизировать доступ к технологиям машинного обучения для широкого круга пользователей.
Operand Quant: Архитектура Простоты и Целостности
Operand Quant представляет собой принципиально новую архитектуру для автономной машинной инженерии, в корне отличающуюся от всё более сложных многоагентных систем. В основе лежит простая, но глубокая идея: меньше связей – меньше точек отказа. Всё ломается по границам ответственности – если их не видно, скоро будет больно. Многоагентные системы неизбежно порождают паутину коммуникаций, где отслеживать взаимодействие и выявлять узкие места становится непосильной задачей. Operand Quant же избавляется от этой сложности, концентрируя всю логику управления в рамках единого агента.
Эта архитектура позволяет агенту поддерживать целостное понимание всего процесса машинного обучения, от начального анализа данных до финальной постановки в производство. Нет необходимости в сложных протоколах координации, в передаче контекста между разными компонентами. Все знания – внутри, всё под контролем. Это подобно опытному инженеру, который держит в голове всю картину проекта, а не полагается на отдельные команды, работающие изолированно.
Operand Quant функционирует в рамках симулированной интегрированной среды разработки (IDE). Этот выбор не случаен. IDE предоставляет привычный и эффективный рабочий интерфейс для машинной инженерии, знакомый каждому специалисту. Это не абстрактная платформа, а среда, которая позволяет агенту оперировать с кодом, данными и инструментами так же, как это делал бы человек. Использование IDE позволяет агенту эффективно решать задачи, требующие тонкого понимания контекста и гибкости.
Для оценки возможностей Operand Quant были проведены тщательные испытания с использованием MLE-Benchmark. Этот эталонный набор задач позволяет объективно оценить способности агента в изолированных условиях, исключая влияние внешних факторов и случайных событий. MLE-Benchmark – это строгий экзамен, который выявляет слабые места и подтверждает надёжность системы. Результаты испытаний показали, что Operand Quant демонстрирует конкурентоспособные показатели и способен решать сложные задачи машинного обучения без вмешательства человека.
В конечном счёте, Operand Quant – это не просто архитектура, это философия. Философия простоты, ясности и целостности. Мы верим, что надёжная система – это живой организм, в котором каждая часть гармонично взаимодействует с остальными. И Operand Quant – это шаг к созданию такой системы.
Глубокое Мышление: Ансамблевый Подход к Рассуждениям
Модуль Глубокое Мышление системы Operand Quant призван решать проблемы, возникающие при построении логических цепочек, за счёт использования ансамблевого подхода к рассуждениям. В основе данной стратегии лежит идея о том, что масштабируемость определяется не вычислительной мощностью, а ясностью идей. Вместо того, чтобы полагаться на наращивание ресурсов, система стремится к более эффективной организации и обработке информации.
Глубокое Мышление объединяет результаты работы нескольких моделей, что позволяет повысить точность и устойчивость принимаемых решений. Вместо слепого следования одному пути, система рассматривает различные варианты, оценивает их сильные и слабые стороны, и выбирает наиболее оптимальный. Такой подход позволяет избежать локальных оптимумов и находить более глобальные решения.
Ключевым аспектом работы модуля является использование контекстуального мышления. Система не просто анализирует текущие данные, но и учитывает всю доступную информацию об окружающей среде, историю предыдущих действий и текущее состояние системы. Это позволяет ей поддерживать целостную картину происходящего и принимать более обоснованные решения. Представьте себе экосистему, где каждый элемент влияет на целое – именно так работает контекстуальное мышление.
Важнейшим требованием к системе является надёжность и воспроизводимость результатов. Для этого используется механизм детерминированного сохранения состояния, который обеспечивает возможность отладки и анализа работы системы в любых условиях. Это позволяет исследователям отследить логику работы системы, выявить потенциальные ошибки и улучшить её производительность. Система функционирует как живой организм, где каждая деталь взаимосвязана с другими, и понимание целого требует глубокого анализа каждого элемента.
В конечном итоге, Глубокое Мышление – это не просто технический инструмент, а философский подход к решению сложных задач. Это стремление к ясности, последовательности и надёжности, которые являются основой любой успешной системы.
Деградация Контекста и Эволюция Операционной Модели
Анализ работы системы выявил, что деградация контекста является ограничивающим фактором, снижающим гибкость рассуждений модели по мере увеличения длины запроса. Подобно тому, как перегруженная городская магистраль замедляет движение, чрезмерный объем информации затрудняет эффективную обработку и принятие решений. Исследователи отмечают, что это естественное ограничение, присущее большинству больших языковых моделей, и Operand Quant не является исключением.
Однако, в отличие от систем, пытающихся обойти эту проблему за счет грубой силы (увеличения вычислительных ресурсов или укорочения контекста), авторы подошли к решению вопроса с точки зрения эволюции структуры. Операционная модель Operand Quant построена на принципах неблокирующего исполнения и пошагового (turn-based) функционирования. Это позволяет максимизировать эффективность и отзывчивость системы, подобно тому, как хорошо спланированная транспортная сеть обеспечивает непрерывное движение даже при возникновении локальных заторов.
Эти методы позволяют агенту продолжать обработку других задач, пока долго выполняющиеся операции находятся в процессе завершения. Представьте себе строительную бригаду, которая, пока застывает бетон, может приступить к выполнению других элементов проекта. Вместо того чтобы бездействовать в ожидании, Operand Quant использует время с максимальной отдачей. Этот подход особенно важен в контексте ограниченных временных рамок и вычислительных ресурсов, установленных протоколом MLE-Benchmark.
Несмотря на это ограничение, связанное с деградацией контекста, система демонстрирует значительный прогресс в направлении действительно автономного машинного обучения. Подобно тому, как город постоянно адаптируется и улучшается, Operand Quant представляет собой эволюционную модель, демонстрирующую потенциал для создания интеллектуальных систем, способных решать сложные задачи без вмешательства человека. Авторы подчеркивают, что дальнейшие исследования будут направлены на смягчение последствий деградации контекста и повышение общей эффективности системы.
«Искусство программирования — это искусство организации сложности.»
— Donald Knuth
Эта работа с Operand Quant подтверждает мою давнюю убежденность в том, что хорошо спроектированная система должна обладать внутренней связностью. Автономная разработка машинного обучения, как показано в исследовании, требует не просто набора инструментов, но и единого агента, способного к контекстному рассуждению и глубокому анализу. Изменение одной части системы, например, стратегии поиска гиперпараметров (ключевой аспект MLE-Benchmark), оказывает эффект домино на всю архитектуру. Operand Quant демонстрирует, что именно ясная структура определяет поведение, а не простое увеличение количества агентов.
Что дальше?
Успех Operand Quant, безусловно, впечатляет. Мы видим, как система демонстрирует компетентность в решении задач, определённых в MLE-Benchmark. Но давайте будем честны: бенчмарк — это лишь имитация реальности. Настоящая сложность машинного обучения не в достижении максимальной точности на статичном наборе данных, а в постоянной адаптации к изменяющимся условиям, борьбе со смещением данных и, что самое важное, в понимании *зачем* мы вообще строим эти модели. Мы оптимизируем не то, что нужно, а то, что измеримо. Operand Quant – это элегантный инструмент, но и инструмент, как известно, бессилен, когда отсутствует ясная цель.
Зависимости — настоящая цена свободы, и Operand Quant, интегрированный в IDE, несомненно, страдает от этой дилеммы. Чем глубже интеграция, тем сложнее система, и тем выше риск возникновения непредсказуемых эффектов. Хорошая архитектура незаметна, пока не ломается, и вопрос в том, когда и где эта система проявит свою хрупкость. Следующим шагом должно быть исследование не просто производительности, а устойчивости и способности к самовосстановлению.
В конечном итоге, мы должны признать, что автоматизация машинного обучения – это лишь часть более широкой проблемы. Нам нужна не просто система, которая может строить модели, а система, которая может *понимать* проблему, формулировать вопросы и, возможно, даже сомневаться в правильности своих решений. Простота масштабируется, изощрённость – нет, и в погоне за автоматизацией мы рискуем создать монстра, который будет решать не те задачи, и решать их не тем способом.
Оригинал статьи: https://arxiv.org/pdf/2510.11694.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Показать полностью

Если трейдеры говорят словами, почему нейросеть не может? Мой эксперимент
Представьте опытного трейдера: наверняка он не говорит котировками и не рассказывает про индикаторы — он просто говорит «сильный тренд», «пробой уровня» или «ложный отскок». Для него график это язык: свечи, объёмы и уровни складываются в понятные фразы о том, что сейчас происходит на рынке. Именно от этой человеческой интуиции я и отталкивался в своём эксперименте.
Мои результаты, о них ниже
Идея была такая: а что, если научить искусственный интеллект понимать этот язык? Не подавать модели сырые числа, а переводить бары и объёмы в текстовые описания наблюдаемых паттернов и кормить ими языковую модель. Гипотеза была что в тексте уже будет содержатся достаточно данных, чтобы модель научилась связывать недавнюю торговую историю с тем, пойдёт ли цена вверх на следующий день.
Инструмент эксперимента — модель distilbert‑base‑uncased с Hugging Face и это облегчённая, быстрая версия BERT для понимания языка. Мне показалось это практичным выбором для прототипа — позволяет быстро проверять разные способы текстовой разметки без гигантских ресурсов. Цель была чёткая: по текстовому описанию недавней истории торгов предсказать рост цены на следующий день.
Но это исследование моя попытка представления рыночных данных как языка, а не попытка сразу создать алгоритм для автотрейдинга. Ещё важно: это мой личный эксперимент, проведённый одним человеком и выполненный однократно. Результаты дали интересные наблюдения.
Расскажу, как происходила разметка графиков в текст, какие шаблоны сработали лучше и какие метрики использовались. Также отмечу ограничения подхода и идеи для повторных экспериментов.
А ещё весь код уже на GitHub.
Для трейдеров и аналитиков: суть и результаты
Для модели котировки это просто цифры без контекста. Она не знает, что вверх — хорошо, а вниз тревожный сигнал. Я переводил ряды котировок в текст. Каждые 10 дней торгов превращались в короткое описание, как если бы трейдер рассказывал что-то своему коллеге.
В основе лежали три признака:
Краткосрочный тренд (3 дня) — рост, падение или боковик;
Среднесрочный контекст (7 дней) — подтверждает ли он текущее движение;
Моментум и объём — поддерживают ли рост деньги: идёт ли рост на растущих объёмах или затухает.
Если цена три дня растёт, объёмы увеличиваются, и цена близка к сопротивлению, строка выглядела так:
price rising strongly, volume increasing, near resistance.
Эти описания читала модель DistilBERT. Модель не видела графиков, только текст — и должна был сказать, приведёт ли ситуация к росту или падению. Так модель «училась понимать» то, что трейдеры выражают словами.
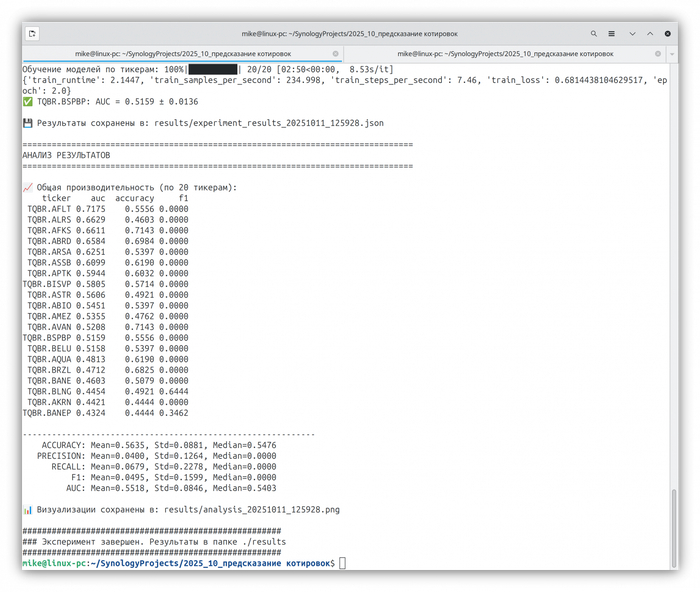
Результат 20 бумаг в консоли
Как измерить, понимает ли она рынок
Простая точность (accuracy) ничего не говорит: можно всё время предсказывать падение и быть правым на 60%.
Поэтому я использовал AUC (Area Under Curve) — показывает, насколько хорошо модель отличает ситуации, после которых цена действительно росла, от тех, после которых она падала:
AUC = 1.0: идеальная модель, которая никогда не ошибается.
AUC = 0.5: бесполезная модель, ее предсказания равносильны подбрасыванию монетки.
AUC > 0.5: модель работает лучше, чем случайное угадывание. Чем ближе к 1.0, тем лучше.
AUC < 0.5: модель работает хуже случайного угадывания.
Эксперимент на всех акциях Московской биржи
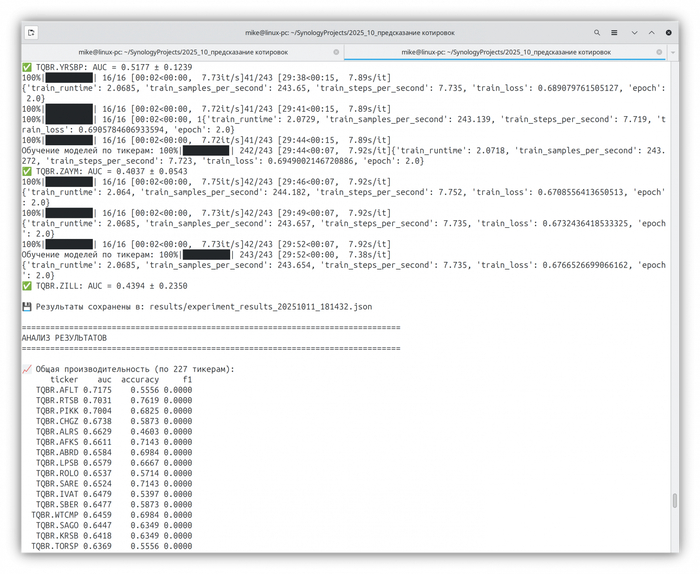
Результат 227 бумаг в консоли
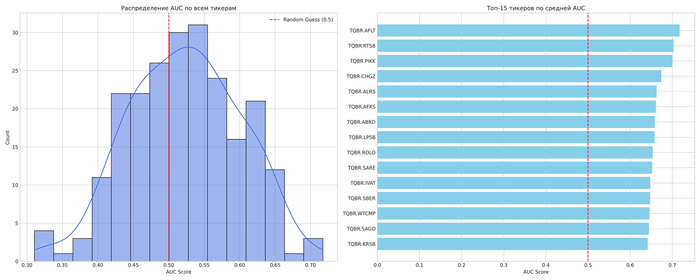
Я протестировал более 200 акций с Московской биржи. Средний результат по всем бумагам — AUC ≈ 0.53, что немного лучше случайного угадывания.
Лучшие случаи:
AFLT — 0.72
RTSB — 0.70
PIKK — 0.70
CHGZ — 0.67
AFKS — 0.66
Худшие:
PLZL — 0.33
VJGZP — 0.33
CHMF — 0.36
ETLN — 0.38
LSNG — 0.39
Разброс большой: одни бумаги ведут себя предсказуемо, другие — как шум.
Что это значит для трейдера
С практической стороны — торговать по такой схеме нельзя. Даже при AUC 0.6 предсказательная сила слишком слаба, чтобы покрыть комиссии. Однако сам факт, что модель хоть немного «чувствует» структуру графика без чисел и свечей, уже интересен.
Эксперимент показал: график можно описать словами, и языковая модель способна уловить логику движения — пусть пока не точно.
Нагрузка на GPU
Для технических специалистов
Проект реализован на стеке Python + PyTorch + Hugging Face Transformers с изоляцией через Docker. Контейнер собирается на базе pytorch/pytorch:2.7.0-cuda12.8-cudnn9-devel для совместимости с современными GPU.
Модель дообучалась (fine‑tuning) на базе DistilBERT, предобученной на английском тексте (distilbert‑base‑uncased). То есть — это классическая дообучаемая голова классификации (num_labels=2) поверх всего BERT‑тела. Fine‑tuning проходил end‑to‑end, то есть обучались все слои, не только голова.
Все слои разморожены. Базовая часть DistilBERT не замораживалась. Значит, fine‑tuning шёл по всей модели (весам encoder'а + классификационной голове).
Конвейер данных строится в три этапа. Пакетная загрузка: метод load_all_data() читает все файлы котировок за один проход и объединяет в единый DataFrame с колонкой ticker. Векторизованная генерация признаков: класс OHLCVFeatureExtractor обрабатывает весь DataFrame целиком через groupby('ticker').apply() для расчёта троичных трендов, преобразование в текст идёт через featuresto_text_vectorized() с np.select() вместо циклов — прирост скорости в десятки раз. Скользящая валидация: WalkForwardValidator обучает модель на окне в 252 дня, тестирует на следующих 21 дне, затем сдвигает окно на 21 день вперёд.
Модель — AutoModelForSequenceClassification (DistilBERT) для бинарной классификации. Токенизатор distilbert-base-uncased, максимальная длина — 128 токенов.
Метрики формируются по каждому тикеру отдельно, на его данных OHLCV (файлы.txt в /Data/Tinkoff). В каждом тикере — несколько временных фолдов (1 год train, 1 месяц test).Потом усредняются по фолдам и по тикерам.
Финальные числа (accuracy, f1, auc) — это усреднение по: все тикеры × все временные окна (folds). В итоге в analyze_results() строится гистограмма AUC и топ-15 тикеров по качеству.
Проблемы и их решение
Изначально паттерны кодировались вымышленными словами («Кибас», «Гапот»), чтобы модель не опиралась на предобученные знания. Но это превращало BERT в обычный классификатор на случайных токенах. Решением стал переход на естественные фразы price rising strongly, near resistance. Модель теперь задействует понимание финансовой терминологии.
Моя RTX 5060 Ti (архитектура Blackwell, SM_120) оказалась слишком новой для стабильных PyTorch. Ошибка «no kernel image available» блокировала вычисления. Решением стал Docker‑образ с CUDA 12.8 и nightly‑сборкой PyTorch.
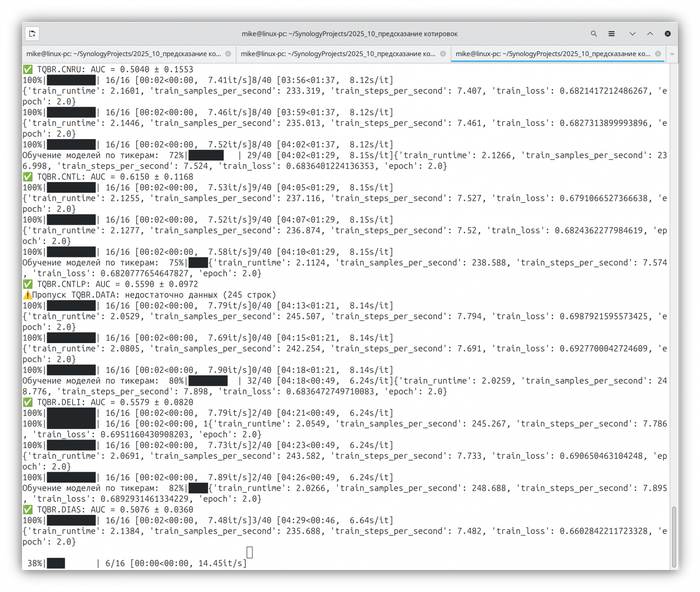
В процессе теста 40 бумаг
Обработка каждого файла в цикле была узким местом. Я переработал код для пакетной обработки: все котировки загружаются в единый DataFrame, а признаки генерируются одним векторизованным вызовом. Благодаря этому тесты для более чем 200 акций завершились неожиданно быстро — всего около получаса.
Несовместимость transformers и tokenizers ломала сборку Docker. Зафиксировал работающие версии: transformers==4.35.2, она требует tokenizers==0.15.0. Затем pandas изменил поведение groupby.apply, transformers удалил старые аргументы из API. Адаптация кода и жёсткая фиксация версий в requirements.txt.
В Docker контейнер создавал файлы от root. Переключение на --user "$(id -u):$(id -g)" решило проблему с правами, но библиотеки пытались писать кэш в /.cache и падали с PermissionError. Решенил что в переменные окружения в run.sh перенаправляют кэши в доступные пути: HF_HOME, TRANSFORMERS_CACHE идут в /workspace/.cache, MPLCONFIGDIR — в /tmp.
Детали конфигурации и обучения
Конфигурация признаков: short_window=3, medium_window=7, long_window=14. Валидация: train_size=252, test_size=21, step_size=21.
Гиперпараметры: learning_rate=2e-5, batch_size=32, epochs=2, weight_decay=0.01, fp16=True. EarlyStoppingCallback(patience=2) останавливает обучение при стагнации лосса.
Оценка — усреднение метрик по 3 фолдам на тикер. Для каждого фолда: accuracy, precision, recall, F1, AUC‑ROC. Финальный результат — среднее и стандартное отклонение AUC.
Выводы
Эксперимент подтвердил: идея семантического кодирования рыночных данных — рабочая и перспективная, но в текущей реализации она не дала статистически значимого результата. Модель действительно различала рыночные ситуации, но слабо — AUC в среднем по полной выборке составил около 0.53. Это слишком мало, чтобы использовать прогнозы в торговле, но достаточно, чтобы признать: языковая модель способна уловить элементарные закономерности, если данные поданы в привычной ей форме — в виде текста.
Главная ценность проекта не в точности предсказаний, а в том, что удалось пройти весь путь от сырого CSV с котировками до работающего ML‑конвейера, полностью воспроизводимого в Docker. Каждый этап — от векторизации признаков до скользящей валидации — отлажен и готов к повторным экспериментам. Это не «ещё одна нейросетка для трейдинга», а инженерный прототип, на котором можно проверять новые идеи: другие схемы описания графиков, языковые модели большего масштаба, мультимодальные подходы.
Фактически проект стал мини‑лабораторией по исследованию того, как LLM «видит» рынок. И если заменить DistilBERT на современные архитектуры вроде LLaMA или Mistral с дообучением на финансовых текстах, потенциал подхода может проявиться гораздо сильнее.
Повторите мой путь: код на GitHub
Я специально оформил всё так, чтобы любой мог запустить эксперимент у себя. Достаточно скачать архив котировок, собрать контейнер и запустить run.sh — среда поднимется автоматически с нужными версиями библиотек и CUDA.
Проект открыт:
👉 github.com/empenoso
Если вы хотите повторить эксперимент, улучшить разметку или попробовать другую модель — все инструменты уже готовы. Мой результат — это не финальный ответ, а отправная точка для следующего шага: сделать так, чтобы языковая модель действительно читала графики, а не просто угадывала направление.
Автор: Михаил Шардин
🔗 Моя онлайн‑визитка
📢 Telegram «Умный Дом Инвестора»
14 октября 2025
Показать полностью
4

Нейро-комиксы, используете в работе?
Всем привет!
Я здесь совсем новенький. Это мой первый пост! Знаю, знаю первый пост он такой. Площадку не знаю, публику - тоже.
Вобщем научился я нейро-комиксы делать в Sora.
Сегодня расскажу Вам в общих чертах как. Возможно кому-то пригодится мой опыт.
Кому могут быть полезны комиксы?
Провёл небольшой ресёрч в Perplexity, согласно отчёту чуть ниже список ниш в которых могут быть полезны нейро-комиксы.
Востребованные ниши для нейро-комиксов:
IT- и маркетинговые агентства
B2B консалтинг
Образовательные платформы, онлайн-курсы и школы
Кофейни, рестораны, ритейл, салоны красоты
Корпоративное обучение и HR
Брендинг и имиджевые проекты
Продвижение продуктов и услуг
Контент-маркетинг и презентационные задачи
С этим вроде-бы всё понятно, но а что требуется, чтобы создать нейро-комикс? - задался этим вопросом и я.
Будучи человеком увлечённым, провёл небольшой мозговой штурм и выявил, чтобы сделать качественный нейро-комикс необходимо соблюсти ряд условий:
Высокий уровень консистентности персонажа в серии генераций.
Единство стиля, цветовой гаммы на протяжении всей серии генераций.
Таким образом, мы меняем только часть промпта, который отвечает за сюжет, персонажей, взаимодействия в кадре.
Ну хорошо! - подумал я.
Значит нейро-комикс начинается с разработки системного промпта. Поскольку я периодически увлекаюсь вайбкодингом на Cursor и автоматизациями на n8n мне часто приходится иметь дело с JSON файлами.
Я принялся писать промпт JSON подобного вида, где будет шаблон который я буду только частично менять. Пропишу туда стиль, цвет, особенности. А менять буду сцену, персонажа и так далее.
Пример того, как я решил промптить.
#Заголовок
Параметр: значение
Параметр: значение
Недолго думая, набросал промпт на русском, а затем перевёл в Gemini на англ. (Часто пользуюсь Gemini)
Вот что получилось:
#Scenario, Characters, Details
Character: Cyborg robot with an emblem on his chest
Style: Comic, professional illustration, cyberpunk, Terminator, robots as seen in sci-fi films
Plot: The image is split diagonally into two parts.
First half of the image: The robot is calling a young man from a bright office, sitting on a chair in front of a computer, holding a phone and talking.
Second half of the image: The young man is lying on a beach, hugging a beautiful girl; in his hands is a smartphone with which he is talking.
Both characters communicate using comic-style speech bubbles.
Language of dialogue: Russian, correct and proper speech
Detailing: Ultra-high detail, detailed rendering, best quality, professional illustration, crisp lines and detailed objects.
#Characters’ Dialogue
Robot: "Босс, все входящие заявки обработаны. Все купили всё, деньги уже на счету. Скоро деньги будет некуда складывать!"
Man: "Позвони мне когда я попаду в Forbes! И перестань звонить мне каждые 5 минут!"
#Important Features
The emblem must be rendered as clearly as possible. Correctly display Cyrillic symbols; distortions in text drawing are unacceptable.
Be attentive to which character is saying each line; the speech bubble’s corner must not point at the girl.
Получил пробную генерацию

Sora очень не дружит с кириллицей, собственно я знал об этом, но иногда бывает нормально. Обычно очень короткие фразы.
Немного изменил промпт, менял только определённые значения.
Изначально я наивно полагал, что смогу прописать реплики персонажей прямо в промпт. Уже расфантазировался на тему того, как настраиваю автоматизацию в n8n на генерацию автоматом. Представил как буду на диване лежать, а у меня будет комикс крутиться вечно в telegram канале, подписчики довольны будут, вовлечение большое, а может и вируситься начнёт.
Умерив фантазии понял, что по API подключать Sora к n8n смысла нет.
Нажал кнопку генерации с изменённым промптом вылезло:

С текстом на кириллице ничего путного не выходило.
Но было позитивное, картинка выходила приблизительно одинаковой. А поскольку Sora референсный подход к генерации, я каждый раз генерировал новую с использованием предыдущей в качестве референса.
Создание персонажа
Через некоторое время пришёл к тому, чтобы в качестве референсов буду каждый раз вместе с промптом грузить персонажа. Но для начала его нужно было создать.
Решил вместе с референсами где изображён мой робот из SKYNET загрузить промпт, который по моему мнению должен был-бы создать персонажа в трёх проекциях. Спереди, сбоку, сзади.
Писал на русском:
3 точные копии робота в полный рост в трёх проекциях: Спереди, сзади и сбоку (профиль) всё тело. однотонный фон.

Результат генерации не удовлетворил. Sora упорно слепляла руки персонажей и не хотела генерировать их раздельно.
Та-же самая история с мужиком:
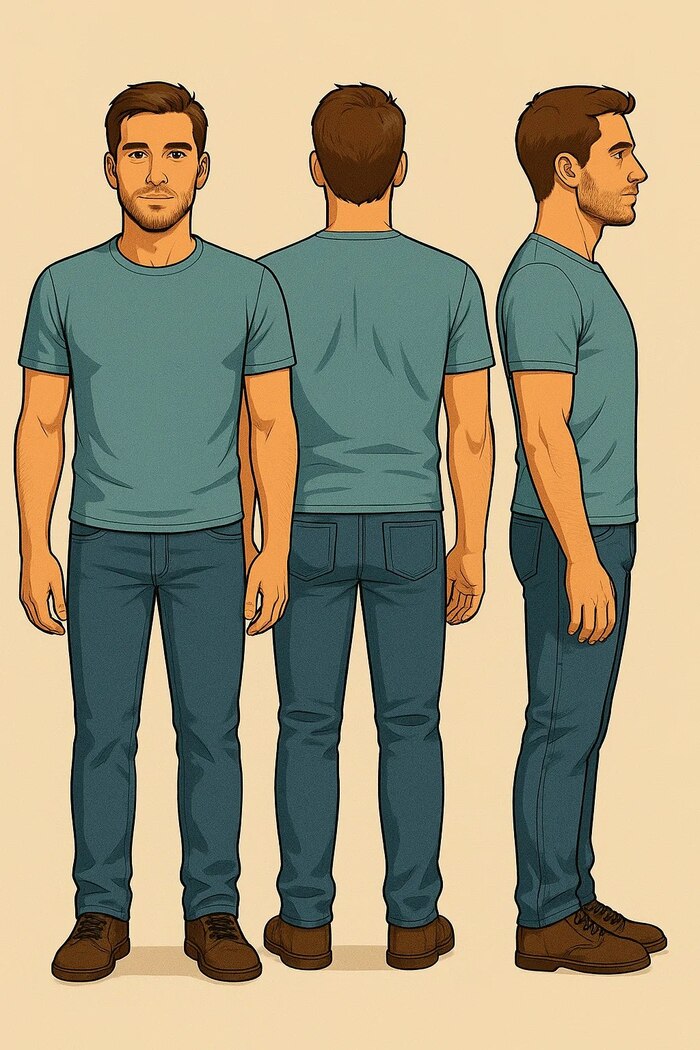
Ладно! Очевидно без ручного вмешательства никак не обойтись.
Тогда я разделил каждого из персонажей в photoshop и начал использовать в качестве референсов полученные изображения.

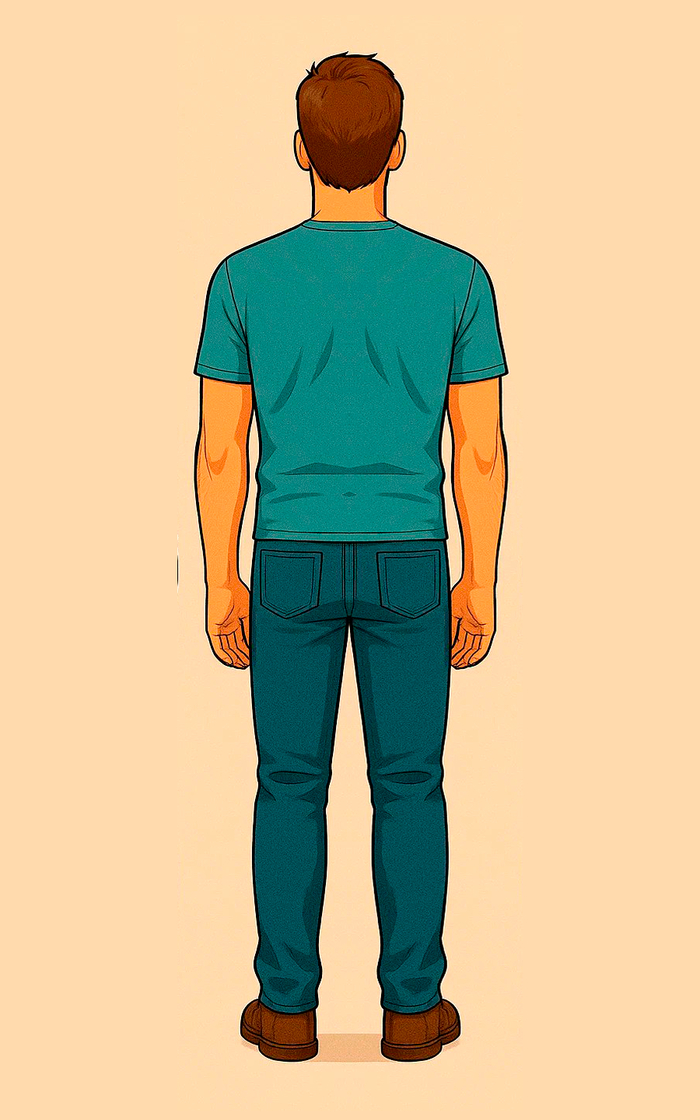




Точнее я использовал только фронтальную и боковую проекцию, тыл оставил на всякий случай.
Продолжил с тем-же промптом но в референсах уже не предыдущие генерации, а персонажи на однотонном фоне. Sora на вход принимает до 4 пикч с референсами, грузил 2 с мужиком (фронт, бок) и 2 с роботом (фронт, бок)

Первая генерация с нормальным текстом на кириллице.
И знаете помогло, но не стабильно! Всё равно из 4-5 генераций, с плохой кириллицей было не менее половины.
Логично, что когда буду в будущем делать с помощью API и автоматом, буду иметь ввиду, что нужно брать в расчёт, что токенов потребуется в 2-3 раза больше для генерации комикса, чем могло-бы потребоваться если бы с текстом проблем не было бы.
Я принял решение, писать текст самому. Да не автомат, но это стабильнее. А стабильность важна, тем более, я собираюсь позиционировать нейро-комиксы как услугу.
С кириллицей мягко говоря тяжеловато работает что Sora, что NanoBanana (Image)
Решил попробовать использовать промпт чисто на кириллице:
компоновка в комикс‑стиле, персонажи общаются в облачках речи, эмблема на груди читается чётко, и речь героев грамотная и литературная.
Название и детали
Сценарий: Киборг‑робот с эмблемой на груди и молодой человек.
Стиль: Комикс‑иллюстрация профессионального уровня в киберпанковом духе, напоминая Терминатора; роботы в научно‑фантастических фильмах.
Сюжет: Мужчина лежит на диване, его лицо выражает, а робот в фартуке готовит еду у плиты на заднем фоне.
Место действия: Квартира
Язык диалогов: русский, образованный и грамотный, без разговорной лексики.
Персонажи и диалоги
Мужчина:
Фраза: «Скайнет, скажи кто лучше всех пишет промпты для комиксов?»
Робот:
Ответ: «Конечно Вы шеф, вы знаете это!»
Обратите внимание что мужик говорит, а что робот.
Нажимаю генерировать.

Вполне хорошо! Связка промпты в виде параметров и значений очень хорошо себя показывает + референсы персонажей на однородном фоне. Но есть нюанс!
Как мы видим, Sora всё перепутала.
Мужик в кадре говорит то, что должен говорить робот! А здесь всё наоборот.
И тут меня понесло и я начал химичить.
Выкручивался как мог.
Решил написать в промпте порядок кто говорит первый и кто из героев слева, а кто справа.
Пишу (конец промпта):
#Important
Порядок того, кто нарисован слева а кто справа определяет порядок записи в разделе "Персонажи и диалоги"
Если персонаж говорит первый, он слева. Если персонаж говорит второй, то справа.
Персонаж слева, всегда говорит первый, а справа ему отвечает и облачка реплик должны быть расположены соответственно.
#Персонажи и диалоги
1. Мужчина:
Фраза: Скажи, а как клиент может заказать комикс?»
2. Робот:
Фраза: «Нужно просто связаться со мной в Telegram!

Sora лишь запуталась и просто поменяла из местами.
В конечном итоге я вернул промпт к версии без объяснения кто первый говорит, кто где стоит и так далее.
Понял следующие тезисы:
1. Получил визуал с баблом для реплики писать текст нужно будет руками.
2. Это уже на самом деле кайфово, поскольку невероятно ускоряет создание комикса.
Да, хотелось суперпромпт который бы сам всё делал только переменные стиля, гаммы, одежды ну и описание сцен и взаимодействия описывай да и всё. Но увы не получается так.
По крайней мере, у меня! Может вы что подскажете? Пишите в комментах.
В целом я добился достаточно хороших результатов на мой взгляд.
Консистентность сохраняется в серии генераций из 10 кадров за счёт того, что есть персонажи, которые грузятся в качестве референсов.
Вот полностью комикс:










Спасибо Вам за прочтение!
Подпишитесь на этот канал, если Вам было интересно буду выкладывать сюда заметки, про своё творчество. Эксперементы.
Также, если Вам потребуются нейро-комиксы посмотрите мой сайт на notion там я сделал презентацию, с удовольствием посотрудничаю по фрилансу.
Подписывайтесь на пикабу и пишите комментарии)
Показать полностью
23
Долгосрочное мышление LLM: Где заканчивается разум, а начинается случайность?
Обзор статьи «R-Horizon: How Far Can Your Large Reasoning Model Really Go in Breadth and Depth?»
Автор: Денис Аветисян
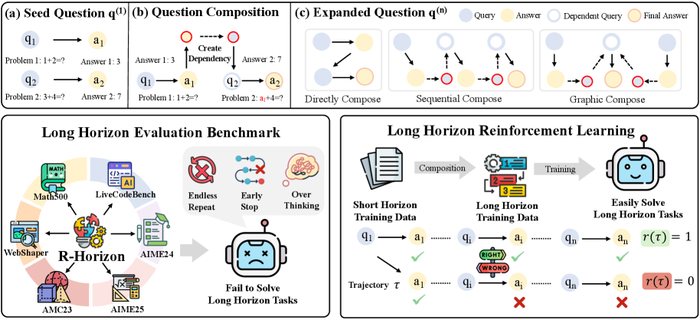
Поток данных R-Horizon. Мы собрали данные для шести задач, чтобы проверить, как долго наши алгоритмы смогут выдерживать нагрузку.
Иллюзия Многоходового Мышления
Традиционные методы оценки, основанные на задачах с единичным горизонтом, дают неполную картину истинных способностей к рассуждению. Они словно измеряют пиковую мощность двигателя, не учитывая, сколько он сможет проехать на одном баке. Эти подходы не способны зафиксировать сложности многошаговых проблем, где предыдущие этапы влияют на последующие. Модель может блестяще решить изолированную задачу, но споткнуться, когда ей потребуется выстроить последовательность действий. Это не просто недостаток — это фундаментальное ограничение, которое мешает прогрессу в создании ИИ-систем, способных к устойчивому и связному мышлению.

Модели R1-Qwen демонстрируют аномальное поведение при последовательном рассуждении.
Исследователи часто упускают из виду, что ‘архитектура — это не схема, а компромисс, переживший деплой’. Модель, оптимизированная для быстрого решения отдельных задач, может оказаться неэффективной в долгосрочной перспективе. Она словно спортсмен, специализирующийся на спринте, которого заставляют участвовать в марафоне. Мы не просто оцениваем скорость решения — мы оцениваем способность поддерживать последовательность мысли. И когда эта последовательность нарушается, когда модель начинает ‘оптимизировать’ процесс мышления в ущерб его связности, мы сталкиваемся с серьезными проблемами.
Это не просто вопрос улучшения алгоритмов или увеличения вычислительных ресурсов. Это вопрос понимания того, как работает мышление, и как можно создать ИИ-систему, способную к устойчивому и связному рассуждению. И пока мы не научимся оценивать эти способности, мы будем обречены на повторение одних и тех же ошибок. Мы будем строить все более сложные модели, которые будут блестяще решать изолированные задачи, но будут спотыкаться, когда им потребуется выстроить последовательность действий. Мы будем ‘рефакторить код’, но не будем ‘реанимировать надежду’ на создание действительно разумной машины.
R-Horizon: Декомпозиция или Искусственный Интеллект?
Авторы, похоже, снова изобрели велосипед, но на этот раз обмазали его нейронными сетями. В общем, суть их подхода, названного R-Horizon, в том, чтобы собрать сложные задачи из простых, связав их последовательными зависимостями. Звучит как обычная декомпозиция, но теперь это ‘искусственный интеллект’ и можно просить инвестиции. Впрочем, идея не нова – когда-то и мы так отладчивали сложные скрипты, только использовали bash и grep.
R-Horizon конструирует задачи, выстраивая цепочку из одношаговых проблем, где результат предыдущей становится входными данными для следующей. Это позволяет создать испытания, требующие не просто кратковременного всплеска ‘рассуждений’, а способности поддерживать логическую нить на протяжении нескольких шагов. Честно говоря, удивляет, что до этого никто не додумался – видимо, все были слишком заняты оптимизацией скорости inference.
Ключевой момент здесь – именно построение зависимостей. R-Horizon не просто склеивает задачи вместе, а обеспечивает, чтобы каждый шаг опирался на результаты предыдущего. Это как в старом анекдоте про программиста, который сначала написал документацию, а потом код – логика должна быть последовательной, иначе весь проект превратится в хаос. Начинаю подозревать, что они просто повторяют модные слова, но если это работает – ладно.
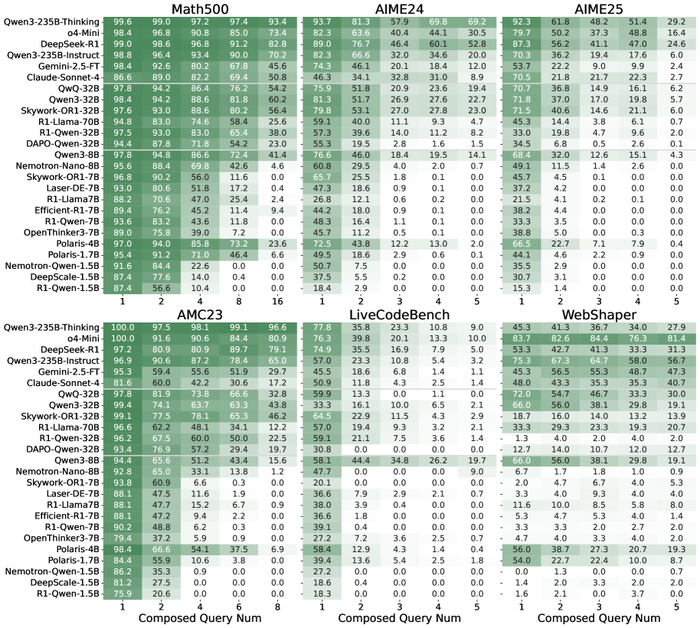
Результаты оценки R-Horizon Benchmark.
В общем, авторы пытаются создать ‘сложные’ задачи для тестирования моделей. Что из этого выйдет – посмотрим. Документация, как обычно, врёт, но если хоть что-то получится – будем считать это небольшим успехом. Технический долг – это просто эмоциональный долг с коммитами, и эту проблему не решить магией нейронных сетей.
Оптимизация Рассуждений: Не Количество, а Качество
Исследования показали, что простое увеличение масштаба модели не является панацеей для достижения многоходового рассуждения. Это как пытаться вытянуть кота за усы – может и получится, но результат будет далёк от желаемого. Мы наблюдаем феномен, который условно можно назвать ‘передумыванием’ – модели генерируют чрезмерно длинные цепочки рассуждений, не приводящие к соответствующему увеличению точности. Это как если бы инженер пытался исправить баг, добавляя всё больше и больше кода, вместо того, чтобы найти элегантное решение. Итог предсказуем: код становится ещё более запутанным, а баг остаётся на месте.
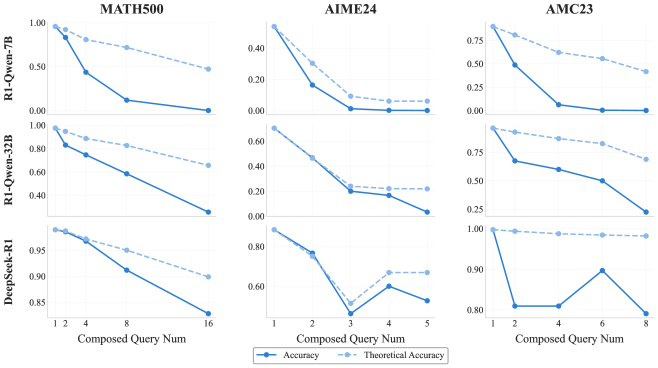
Фактическая и теоретическая точность моделей серии R1 на наборах данных R-Horizon.
Ключевым становится не количество вычислительных ресурсов, а их разумное распределение. Представьте себе систему с ограниченным бюджетом: лучше инвестировать в оптимизацию существующего кода, чем пытаться построить новый, ещё более сложный. Определение эффективной длины рассуждений – точки, после которой производительность начинает ухудшаться – критически важно для оптимизации использования ресурсов. Это как настройка времени ожидания запроса к базе данных: слишком короткое время – ошибка, слишком долгое – пользователь уйдёт. Идеальный баланс – залог успеха. В конечном счете, продакшен всегда найдёт способ сломать даже самую элегантную теорию, поэтому важно не просто строить сложные модели, а понимать их ограничения.
Применение R-Horizon позволило выявить, что модели склонны к избыточному рассуждению. Это как если бы инженер зациклился на решении тривиальной задачи, игнорируя более важные проблемы. Оптимизация должна быть направлена на то, чтобы модели научились быстро и эффективно решать задачи, не тратя ресурсы на излишние рассуждения. В противном случае, мы получим лишь иллюзию прогресса. Всё новое – это старое, только с другим именем и теми же багами.
Обучение с Подкреплением и Бюджет Мышления: Новая Надежда или Очередной Технический Долг?
Всё это, конечно, звучит красиво в статьях, но давайте посмотрим правде в глаза: большинство ‘революционных’ подходов к обучению моделей в конечном итоге превращаются в очередной уровень технического долга. Тем не менее, исследователи предприняли интересную попытку улучшить процесс рассуждений за счёт использования обучения с подкреплением (Reinforcement Learning from Verifiable Rewards, RLVR). Идея проста: награждать модель не просто за правильный ответ, а за правильные шаги, ведущие к этому ответу. Как будто мы пытаемся научить её думать, а не просто заучивать. Не уверен, что это сработает в долгосрочной перспективе, но подход, безусловно, заслуживает внимания.
Но и этого, разумеется, недостаточно. Просто научить модель делать правильные шаги — это всё равно что построить дорогу без указателей. Необходимо ещё и правильно распределить ресурсы. Здесь в игру вступает концепция ‘бюджета мышления’ — стратегического распределения вычислительных ресурсов между различными этапами рассуждений. Представьте себе, что у вас есть ограниченное количество энергии, и вам нужно решить, куда её направить: на анализ исходных данных, на построение гипотез или на проверку результатов. Правильное распределение ресурсов может значительно повысить эффективность процесса рассуждений.
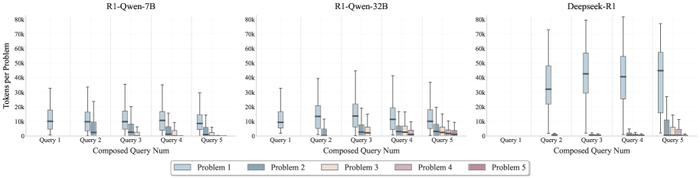
Распределение бюджета мышления для различных конфигураций запросов (1-5) на наборе данных AIME24 для моделей R1-Qwen-7B, R1-Qwen-32B и Deepseek-R1.
Сочетание RLVR с бюджетом мышления, по словам исследователей, позволяет моделям рассуждать более эффективно и достигать улучшенной точности при решении сложных, многошаговых задач. Звучит логично, но, как всегда, дьявол кроется в деталях. Не уверен, что это действительно ‘революционный’ прорыв, но это, безусловно, шаг в правильном направлении. Хотя, будем честны, большинство ‘прорывов’ в конечном итоге оказываются просто очередным уровнем сложности в нашей инфраструктуре. Иногда лучше монолит, чем сто микросервисов, каждый из которых врёт.
Впрочем, поживем — увидим. В любом случае, это еще один пример того, как исследователи пытаются научить машины думать. И, несмотря на всю мою скептичность, я не могу не восхищаться их упорством. Хотя, возможно, они просто не видели достаточно проблем в продакшене.
Простота — это высшая степень совершенства.
— Brian Kernighan
Мы постоянно гонимся за «глубоким» reasoning, за моделями, способными выстраивать сложные цепочки зависимостей (Dependency Reasoning). Но, глядя на результаты R-Horizon, понимаешь, что даже самые крупные модели спотыкаются на длинных цепочках. Кажется, что «совершенство» — это не бесконечное наращивание сложности, а умение решать задачу простыми, надёжными шагами. В конечном счёте, мы не деплоим сложные системы — мы отпускаем в продакшен потенциальные баги, и чем сложнее система, тем больше «дневник боли» нам предстоит вести.
Что дальше?
Итак, мы построили очередную методику для измерения глубины рассуждений больших языковых моделей. Отлично. И что мы выяснили? Что они, как и следовало ожидать, плохо рассуждают, когда цепочка становится длиннее. Удивительно, правда? Впрочем, это не недостаток моделей, а скорее закономерность. Каждая «революционная» архитектура неизбежно упирается в предел длины контекста, а все эти разговоры о «бесконечной масштабируемости» — просто эхо 2012-го, переименованное в новую аббревиатуру. Мы усложнили задачу, и модель сломалась. Это не провал, это ожидаемый результат.
Более того, «композиционные» задачи, безусловно, полезны, но давайте будем честны: продакшен найдёт способ сломать и их. Достаточно добавить немного шума, немного неявностей, немного реальных данных — и все красивые диаграммы снова покажут нам плоскую линию. Если тесты зелёные — значит, они ничего не проверяют. Интересно, сколько ещё метрик нам потребуется, чтобы построить иллюзию прогресса?
В конечном счете, возможно, стоит переключиться с попыток построить идеальную «рассуждающую» машину на более приземленные задачи. Например, научить модель хотя бы последовательно выполнять простые действия, не забывая, что она сделала пять шагов назад. Иначе, мы просто построим ещё один сложный монолит, который рано или поздно потребует переписывания.
Оригинал статьи: https://arxiv.org/pdf/2510.08189.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Показать полностью
4

ИИ помог отменить штраф в $70 000
В США растёт число людей, использующих ИИ-инструменты, такие как ChatGPT и Perplexity, вместо традиционных юридических услуг. Некоторые американцы полностью отказываются от помощи адвокатов в пользу ИИ и добиваются впечатляющих результатов, сообщает NBC News.
Линн Уайт из Калифорнии поделилась:
Это было похоже на то, как будто бог там, наверху, отвечал на мои вопросы.
Женщина использовала оба ИИ-инструмента в деле о выселении после просрочки платежей за дом.
У неё не было средств на наём адвоката, а предыдущий юрист уже проиграл её первоначальное дело.
В апелляции Уайт представляла себя самостоятельно, обратившись к ИИ для тщательного изучения судебных решений, анализа юридической практики и подготовки ответов.
Благодаря этому ей удалось отменить решение о выселении, избежать штрафов и выплаты просроченной арендной платы, превышающей $70 тысяч.
Подобный случай произошёл и в Нью-Йорке, где Ричард Хоффманн рассказал Staten Island Advance, что самостоятельно представлял себя в гражданском деле против бывшего работодателя, используя ИИ для разработки выигрышной стратегии.
Ну что, юристам приготовиться? Или рано? Как считаете?
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Показать полностью
OpenAI - обитель зла? Сэм решил играть по-грязному
Знаете, что творится в мире искусственного интеллекта? Пока все восхищаются очередными достижениями OpenAI, компания тихонько превращается в то самое корпоративное зло, против которого они якобы боролись. И вот вам свежий пример – история, которая взорвала Твиттер.
Смотреть весь выпуск на VK Видео
Смотреть весь выпуск на YouTube
Приятного просмотра!
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Показать полностью
1

А вас тоже достали статьи, картинки и видео, созданные нейросетями?
Дал задание GPT написать статью на эту тему🤣 А T9, естественно, исправило слово "заебали"😁
Представьте ленту в соцсетях: утром вы пролистываете — и там снова идеально отретушированные пейзажи, эмоциональные мини‑рассказы, вирусные шутки и видео с «реальными людьми», которые звучат и двигаются как живые — но всё это, в значительной степени, сгенерировано машинами. Через час вы заходите на новостной сайт — и половина материалов выглядят так, будто их писал профессиональный журналист, хотя на самом деле это автоматические тексты с минимумом фактической проверки. К вечеру у друзей в мессенджере репостят «скандальный» пост, созданный нейросетью — и начинается полемика, основанная на фальшивых данных.
Такая картина уже не гипотеза — это реальность. Людей действительно «заехали» AI‑материалы: от усталости и снижения доверия до экономических и культурных сдвигов. Разберёмся, почему это происходит, какие проблемы возникают и что с этим можно сделать.
Почему возникло перенасыщение
- Массовость и доступность: генеративные модели (текст, изображение, аудио, видео) стали доступнее — и любой пользователь теперь может за минуту получить «публикацию» профессионального вида. Это привело к лавинному росту объёма контента.
- Экономика внимания: для алгоритмов платформ важна частота и вовлечение — и AI упрощает производство кликабельных материалов, даже если они пустые по смыслу.
- Качество ≠ ценность: высокое визуальное или стилистическое качество не гарантирует оригинальности, глубины или правдивости. Результат часто выглядит «по‑поверхности» идеально, но быстро надоедает.
- Мимикрия и фальсификации: deepfake‑видео и сгенерированные подкасты размывают границу между реальным и синтетическим, подрывая доверие к медиа вообще.
Последствия для общества и индустрий
- Снижение доверия: если сложно отличить оригинал от имитации, люди начинают меньше доверять любому контенту — это подрывает новостные медиа и публичные дискуссии.
- Информационный шум: полезная аналитика тонет в море однотипных материалов и агитационных ботов.
- Давление на креативщиков: профессиональные авторы сталкиваются с конкуренцией по объёму и скоростному выпуску; ценность человеческого голоса растёт, но монетизация — сложнее.
- Юридические и этические риски: манипуляции, клевета, нарушение авторских прав, фальсификации доказательств (видео/аудио) — всё это становится реальной угрозой.
Как распознать AI‑контент: практические приёмы
- Проверяйте источник и авторство. Есть ли прозрачная авторская подпись, ссылка на профиль или организацию? Пустые аккаунты и анонимные каналы — повод насторожиться.
- Обратите внимание на мелочи. В сгенерированных лицах часто бывают «ошибки»: несимметричные уши, странные зубы, неестественные движения пальцев, артефакты в тексте (повторения, нелогичные факты).
- Используйте инструменты верификации: обратный поиск изображений (Google, TinEye), инструменты анализа видео (InVID), сервисы детектирования deepfake (Sensity, Deepware), проверка метаданных (если доступны).
- Сравнивайте с надёжными источниками. Откровительно сенсационные заявления без подтверждений — красный флаг.
Что могут сделать платформы и правообладатели
- Внедрять стандарты прозрачности: метаданные о происхождении (C2PA — Coalition for Content Provenance and Authenticity), обязательные пометки «создано с помощью AI».
- Водяные знаки и криптографические подписи для сгенерированных медиа, которые сохраняются при распространении.
- Улучшать модерацию и вводить штрафы/бан для намеренных манипуляций и масштабных фальсификаций.
- Поддерживать инструменты верификации и финансировать независимые аудиты алгоритмов рекомендаций.
Что могут сделать создатели контента, чтобы не «заехать» аудиторию
- Показывать процесс: бэкстейдж, making‑of, черновики — люди ценят прозрачность и человеческий труд.
- Делать ставку на уникальный авторский голос, личные истории и экспертизу, которые сложно автоматизировать.
- Смешивать AI‑инструменты с человеческой редактурой: генерация идей + тщательная фактпроверка и стилистика человека.
- Метки честности: открыто указывать, какие части работы сделала машина, а какие
— человек.
Рекомендации для пользователей
- Развивайте медиаграмотность: не принимать любую «шоковую» новость за чистую монету, проверять факты.
- Ограничьте потребление однотипного контента: подпишитесь на качественные источники и фильтруйте ленту.
- Поддерживайте профессиональные медиа и независимых авторов: платный доступ и донаты помогают сохранить качество.
Короткое будущее: угрозы и возможности
Да, сейчас многие испытывают усталость и раздражение — «AI‑глубокая усталость» информационной эпохи. Но есть и шанс: технология может освободить людей от рутинного контента, дав больше времени для творческих задач и глубокого анализа — если экосистема научится требовать прозрачности и ценить человеческий контекст. Мы уже видим ответную волну: сервисы provenance, законодательные дискуссии, инструменты детекции и тренды на «хендмейд» и честность.
Вывод
Проблема не в том, что нейросети создают много контента — проблема в отсутствии норм, прозрачности и критериев ценности. Люди «заехали» именно потому, что алгоритмы производят много похожих, поверхностных и иногда вводящих в заблуждение материалов. Решение — комплексное: технологии верификации, ответственность платформ, правки законодательства и новый профессиональный стандарт для создателей. Человеческий голос и честность остаются ключевым ресурсом — и те, кто это поймут и применят, выиграют в эпоху генеративного шума.
Показать полностью
Чаты в ChatGPT снова можно удалить без следа
Пользователи ChatGPT вновь обрели возможность безвозвратно удалять свои чаты. Ранее в этом году OpenAI была вынуждена хранить логи пользовательских бесед даже после их удаления согласно судебному постановлению.
Это распоряжение было принято в рамках продолжающегося многомиллиардного судебного разбирательства, где New York Times и ряд других компаний обвиняют OpenAI в нарушении авторских прав.
Окружной суд Нью-Йорка счёл, что в логах чатов могут содержаться доказательства использования ChatGPT для генерации контента на основе защищённых авторским правом материалов.
Так вот, теперь мировой судья Она Ванг утвердила ходатайство об отмене распоряжения о хранении данных. Это означает, что пользователи ChatGPT снова могут безвозвратно удалять свои беседы.
Однако все удалённые ранее чаты, логи которых OpenAI уже сохранила, останутся доступны для юристов The New York Times как потенциальные доказательства в продолжающемся судебном разбирательстве.
Ну вот не могли без ложки дёгтя...
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Показать полностью