

Долгосрочное мышление LLM: Где заканчивается разум, а начинается случайность?
Обзор статьи «R-Horizon: How Far Can Your Large Reasoning Model Really Go in Breadth and Depth?»
Автор: Денис Аветисян
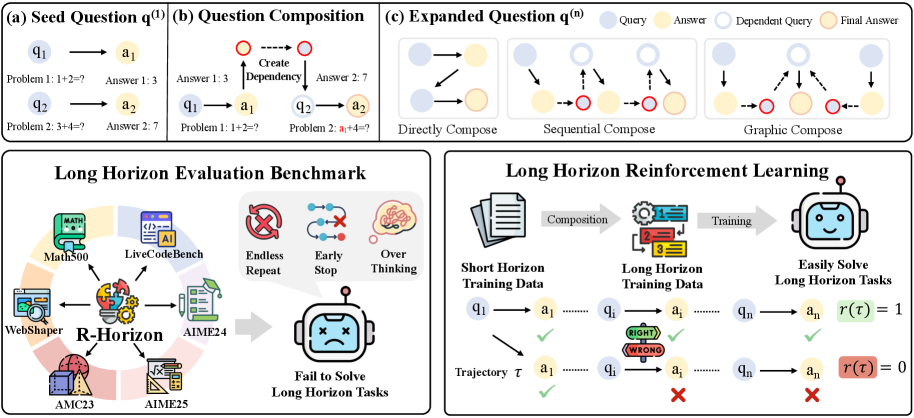
Поток данных R-Horizon. Мы собрали данные для шести задач, чтобы проверить, как долго наши алгоритмы смогут выдерживать нагрузку.
Иллюзия Многоходового Мышления
Традиционные методы оценки, основанные на задачах с единичным горизонтом, дают неполную картину истинных способностей к рассуждению. Они словно измеряют пиковую мощность двигателя, не учитывая, сколько он сможет проехать на одном баке. Эти подходы не способны зафиксировать сложности многошаговых проблем, где предыдущие этапы влияют на последующие. Модель может блестяще решить изолированную задачу, но споткнуться, когда ей потребуется выстроить последовательность действий. Это не просто недостаток — это фундаментальное ограничение, которое мешает прогрессу в создании ИИ-систем, способных к устойчивому и связному мышлению.
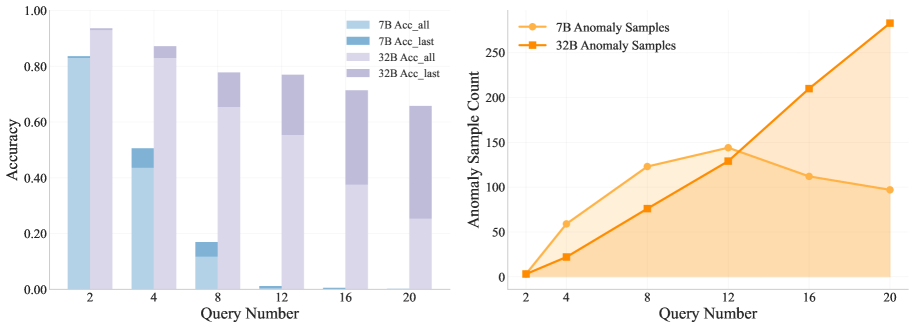
Модели R1-Qwen демонстрируют аномальное поведение при последовательном рассуждении.
Исследователи часто упускают из виду, что ‘архитектура — это не схема, а компромисс, переживший деплой’. Модель, оптимизированная для быстрого решения отдельных задач, может оказаться неэффективной в долгосрочной перспективе. Она словно спортсмен, специализирующийся на спринте, которого заставляют участвовать в марафоне. Мы не просто оцениваем скорость решения — мы оцениваем способность поддерживать последовательность мысли. И когда эта последовательность нарушается, когда модель начинает ‘оптимизировать’ процесс мышления в ущерб его связности, мы сталкиваемся с серьезными проблемами.
Это не просто вопрос улучшения алгоритмов или увеличения вычислительных ресурсов. Это вопрос понимания того, как работает мышление, и как можно создать ИИ-систему, способную к устойчивому и связному рассуждению. И пока мы не научимся оценивать эти способности, мы будем обречены на повторение одних и тех же ошибок. Мы будем строить все более сложные модели, которые будут блестяще решать изолированные задачи, но будут спотыкаться, когда им потребуется выстроить последовательность действий. Мы будем ‘рефакторить код’, но не будем ‘реанимировать надежду’ на создание действительно разумной машины.
R-Horizon: Декомпозиция или Искусственный Интеллект?
Авторы, похоже, снова изобрели велосипед, но на этот раз обмазали его нейронными сетями. В общем, суть их подхода, названного R-Horizon, в том, чтобы собрать сложные задачи из простых, связав их последовательными зависимостями. Звучит как обычная декомпозиция, но теперь это ‘искусственный интеллект’ и можно просить инвестиции. Впрочем, идея не нова – когда-то и мы так отладчивали сложные скрипты, только использовали bash и grep.
R-Horizon конструирует задачи, выстраивая цепочку из одношаговых проблем, где результат предыдущей становится входными данными для следующей. Это позволяет создать испытания, требующие не просто кратковременного всплеска ‘рассуждений’, а способности поддерживать логическую нить на протяжении нескольких шагов. Честно говоря, удивляет, что до этого никто не додумался – видимо, все были слишком заняты оптимизацией скорости inference.
Ключевой момент здесь – именно построение зависимостей. R-Horizon не просто склеивает задачи вместе, а обеспечивает, чтобы каждый шаг опирался на результаты предыдущего. Это как в старом анекдоте про программиста, который сначала написал документацию, а потом код – логика должна быть последовательной, иначе весь проект превратится в хаос. Начинаю подозревать, что они просто повторяют модные слова, но если это работает – ладно.
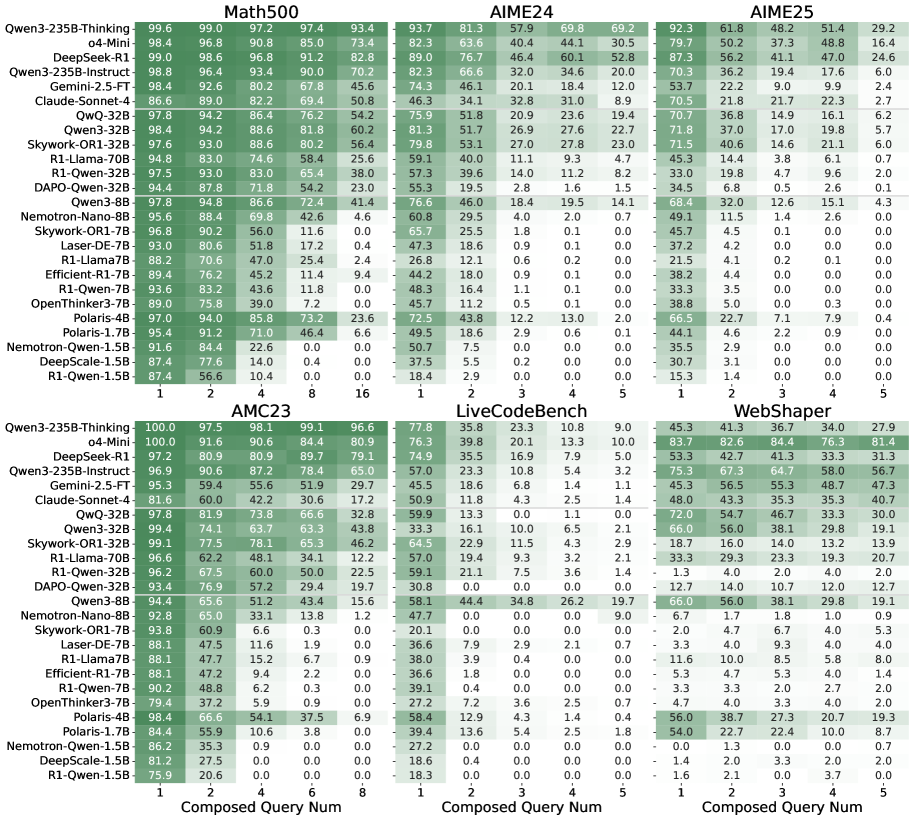
Результаты оценки R-Horizon Benchmark.
В общем, авторы пытаются создать ‘сложные’ задачи для тестирования моделей. Что из этого выйдет – посмотрим. Документация, как обычно, врёт, но если хоть что-то получится – будем считать это небольшим успехом. Технический долг – это просто эмоциональный долг с коммитами, и эту проблему не решить магией нейронных сетей.
Оптимизация Рассуждений: Не Количество, а Качество
Исследования показали, что простое увеличение масштаба модели не является панацеей для достижения многоходового рассуждения. Это как пытаться вытянуть кота за усы – может и получится, но результат будет далёк от желаемого. Мы наблюдаем феномен, который условно можно назвать ‘передумыванием’ – модели генерируют чрезмерно длинные цепочки рассуждений, не приводящие к соответствующему увеличению точности. Это как если бы инженер пытался исправить баг, добавляя всё больше и больше кода, вместо того, чтобы найти элегантное решение. Итог предсказуем: код становится ещё более запутанным, а баг остаётся на месте.
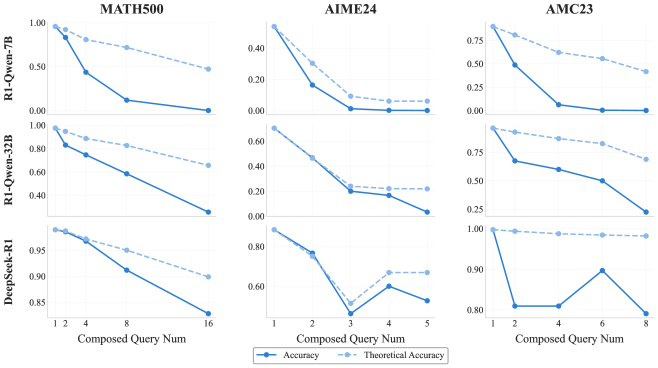
Фактическая и теоретическая точность моделей серии R1 на наборах данных R-Horizon.
Ключевым становится не количество вычислительных ресурсов, а их разумное распределение. Представьте себе систему с ограниченным бюджетом: лучше инвестировать в оптимизацию существующего кода, чем пытаться построить новый, ещё более сложный. Определение эффективной длины рассуждений – точки, после которой производительность начинает ухудшаться – критически важно для оптимизации использования ресурсов. Это как настройка времени ожидания запроса к базе данных: слишком короткое время – ошибка, слишком долгое – пользователь уйдёт. Идеальный баланс – залог успеха. В конечном счете, продакшен всегда найдёт способ сломать даже самую элегантную теорию, поэтому важно не просто строить сложные модели, а понимать их ограничения.
Применение R-Horizon позволило выявить, что модели склонны к избыточному рассуждению. Это как если бы инженер зациклился на решении тривиальной задачи, игнорируя более важные проблемы. Оптимизация должна быть направлена на то, чтобы модели научились быстро и эффективно решать задачи, не тратя ресурсы на излишние рассуждения. В противном случае, мы получим лишь иллюзию прогресса. Всё новое – это старое, только с другим именем и теми же багами.
Обучение с Подкреплением и Бюджет Мышления: Новая Надежда или Очередной Технический Долг?
Всё это, конечно, звучит красиво в статьях, но давайте посмотрим правде в глаза: большинство ‘революционных’ подходов к обучению моделей в конечном итоге превращаются в очередной уровень технического долга. Тем не менее, исследователи предприняли интересную попытку улучшить процесс рассуждений за счёт использования обучения с подкреплением (Reinforcement Learning from Verifiable Rewards, RLVR). Идея проста: награждать модель не просто за правильный ответ, а за правильные шаги, ведущие к этому ответу. Как будто мы пытаемся научить её думать, а не просто заучивать. Не уверен, что это сработает в долгосрочной перспективе, но подход, безусловно, заслуживает внимания.
Но и этого, разумеется, недостаточно. Просто научить модель делать правильные шаги — это всё равно что построить дорогу без указателей. Необходимо ещё и правильно распределить ресурсы. Здесь в игру вступает концепция ‘бюджета мышления’ — стратегического распределения вычислительных ресурсов между различными этапами рассуждений. Представьте себе, что у вас есть ограниченное количество энергии, и вам нужно решить, куда её направить: на анализ исходных данных, на построение гипотез или на проверку результатов. Правильное распределение ресурсов может значительно повысить эффективность процесса рассуждений.
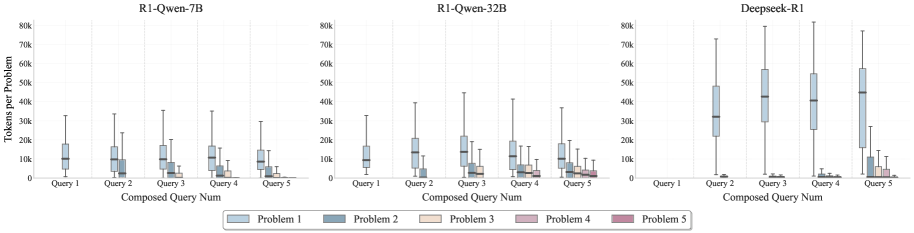
Распределение бюджета мышления для различных конфигураций запросов (1-5) на наборе данных AIME24 для моделей R1-Qwen-7B, R1-Qwen-32B и Deepseek-R1.
Сочетание RLVR с бюджетом мышления, по словам исследователей, позволяет моделям рассуждать более эффективно и достигать улучшенной точности при решении сложных, многошаговых задач. Звучит логично, но, как всегда, дьявол кроется в деталях. Не уверен, что это действительно ‘революционный’ прорыв, но это, безусловно, шаг в правильном направлении. Хотя, будем честны, большинство ‘прорывов’ в конечном итоге оказываются просто очередным уровнем сложности в нашей инфраструктуре. Иногда лучше монолит, чем сто микросервисов, каждый из которых врёт.
Впрочем, поживем — увидим. В любом случае, это еще один пример того, как исследователи пытаются научить машины думать. И, несмотря на всю мою скептичность, я не могу не восхищаться их упорством. Хотя, возможно, они просто не видели достаточно проблем в продакшене.
Простота — это высшая степень совершенства.
— Brian Kernighan
Мы постоянно гонимся за «глубоким» reasoning, за моделями, способными выстраивать сложные цепочки зависимостей (Dependency Reasoning). Но, глядя на результаты R-Horizon, понимаешь, что даже самые крупные модели спотыкаются на длинных цепочках. Кажется, что «совершенство» — это не бесконечное наращивание сложности, а умение решать задачу простыми, надёжными шагами. В конечном счёте, мы не деплоим сложные системы — мы отпускаем в продакшен потенциальные баги, и чем сложнее система, тем больше «дневник боли» нам предстоит вести.
Что дальше?
Итак, мы построили очередную методику для измерения глубины рассуждений больших языковых моделей. Отлично. И что мы выяснили? Что они, как и следовало ожидать, плохо рассуждают, когда цепочка становится длиннее. Удивительно, правда? Впрочем, это не недостаток моделей, а скорее закономерность. Каждая «революционная» архитектура неизбежно упирается в предел длины контекста, а все эти разговоры о «бесконечной масштабируемости» — просто эхо 2012-го, переименованное в новую аббревиатуру. Мы усложнили задачу, и модель сломалась. Это не провал, это ожидаемый результат.
Более того, «композиционные» задачи, безусловно, полезны, но давайте будем честны: продакшен найдёт способ сломать и их. Достаточно добавить немного шума, немного неявностей, немного реальных данных — и все красивые диаграммы снова покажут нам плоскую линию. Если тесты зелёные — значит, они ничего не проверяют. Интересно, сколько ещё метрик нам потребуется, чтобы построить иллюзию прогресса?
В конечном счете, возможно, стоит переключиться с попыток построить идеальную «рассуждающую» машину на более приземленные задачи. Например, научить модель хотя бы последовательно выполнять простые действия, не забывая, что она сделала пять шагов назад. Иначе, мы просто построим ещё один сложный монолит, который рано или поздно потребует переписывания.
Оригинал статьи: https://arxiv.org/pdf/2510.08189.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Искусственный интеллект
5.1K пост11.5K подписчиков
Правила сообщества
ВНИМАНИЕ! В сообществе запрещена публикация генеративного контента без детального описания промтов и процесса получения публикуемого результата.
Разрешено:
- Делиться вопросами, мыслями, гипотезами, юмором на эту тему.
- Делиться статьями, понятными большинству аудитории Пикабу.
- Делиться опытом создания моделей машинного обучения.
- Рассказывать, как работает та или иная фиговина в анализе данных.
- Век жить, век учиться.
Запрещено:
I) Невостребованный контент
I.1) Создавать контент, сложный для понимания. Такие посты уйдут в минуса лишь потому, что большинству неинтересно пробрасывать градиенты в каждом тензоре реккурентной сетки с AdaGrad оптимизатором.
I.2) Создавать контент на "олбанском языке" / нарочно игнорируя правила РЯ даже в шутку. Это ведет к нечитаемости контента.
I.3) Добавлять посты, которые содержат лишь генеративный контент или нейросетевой Арт без какой-то дополнительной полезной или интересной информации по теме, без промтов или описания методик создания и т.д.
II) Нетематический контент
II.1) Создавать контент, несвязанный с Data Science, математикой, программированием.
II.2) Создавать контент, входящий в противоречие существующей базе теорем математики. Например, "Земля плоская" или "Любое действительное число представимо в виде дроби двух целых".
II.3) Создавать контент, входящий в противоречие с правилами Пикабу.
III) Непотребный контент
III.1) Эротика, порнография (даже с NSFW).
III.2) Жесть.
За нарушение I - предупреждение
За нарушение II - предупреждение и перемещение поста в общую ленту
За нарушение III - бан