


Красивые AI Анимации
176 постов

176 постов

5 постов

28 постов

160 постов

1 пост

2 поста

17 постов

Привет! 👋
Это новый выпуск «Нейро-дайджеста» — коротких и полезных обзоров ключевых событий в мире искусственного интеллекта.
Меня зовут Вандер и каждую неделю я делаю обзор новостей о нейросетях и ИИ.
Неделя выдалась насыщенной: Google выкатил мощнейшую версию Gemini, Pinterest вернулся в игру с обновлённым AI-поиском, а легендарный Clippy — теперь с нейросетью на борту — снова жив. Всё самое важное — в одном месте. Поехали!
🧠 Модели и LLM
Gemini 2.5 Pro — апдейт кода, видео и интерфейсов
Seed-Coder 8B — кодер от ByteDance с фильтрацией
Mistral Medium 3 — почти Sonnet, но в 7 раз дешевле
🎨 AI-видео
Luma Reframe — outpaint теперь и для видео
Project Odyssey — как сделать AI-фильм и не разориться
🛠 AI-инструменты и интерфейсы
Clippy — возвращение легендарной скрепки с LLM!
Pinterest — обновление визуального поиска
AI Mode от Google — поиск стал интерактивнее
🖥 AI в обществе
Робот-аптекарь в Минске
Routematic — $40 млн на AI для транспорта
API LLM — почему цена за токен обманывает?

Google обновила свою флагманскую модель до версии Gemini 2.5 Pro Preview (05-06) — и это одно из самых мощных улучшений в линейке. Модель теперь показывает выдающиеся результаты в программировании, UI-дизайне и работе с видео.
Что изменилось:
— Кодинг и фронтенд: Gemini заняла первое место в рейтинге WebDev Arena, обогнав даже Claude 3.7 Sonnet. Улучшены генерация UI-компонентов, работа с анимацией и точность редактирования кода. Разработчики отмечают баланс скорости и надёжности — особенно в задачах с высокой нагрузкой.
— Видео: модель набрала 84,8% в бенчмарке VideoMME. Это позволило запускать пайплайны, которые раньше были невозможны — например, создавать обучающие веб-приложения прямо из YouTube-видео.
— Интерфейсы и функции: Gemini научилась лучше разбирать визуальные задачи, упрощать фронтенд-логику, сокращать ошибки в вызовах функций и ускорять отклик на сложные команды.
Важно: цена не изменилась. Обновлённая версия уже доступна в Vertex AI, AI Studio и приложении Gemini. Пользователям ничего не нужно переключать — версия 03-25 теперь ссылается на свежий билд 05-06.
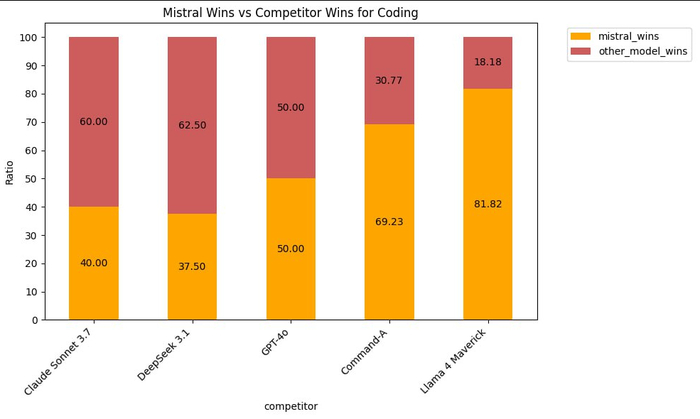
Французский стартап Mistral представил новую мультимодальную модель Mistral Medium 3, и она уже влетела в топы. По качеству — уровень Sonnet 3.7, по цене — в 7–8 раз дешевле конкурентов.
Главный упор — на задачи программирования и STEM. В этих областях модель обходит LLaMA 4 Maverick и спокойно конкурирует с лидерами. Но самое интересное здесь — цена за миллион токенов: $0,4 на вход и $2 на выход. Это почти беспрецедентно для такого уровня качества.
Mistral Medium 3 пока не open-source, доступ только через API. Но разработчики обещают, что в будущем появится более крупная открытая версия. С учётом тренда на демократизацию моделей — вполне может стать следующим хитом в open-комьюнити.
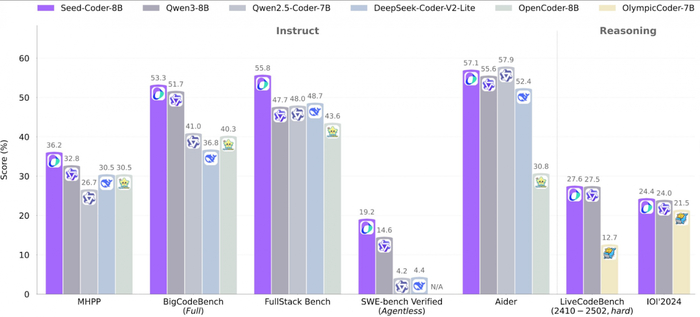
Владельцы TikTok выпустили Seed-Coder 8B — компактную языковую модель, заточенную исключительно под программирование. Несмотря на размер, она обходит даже свежий Qwen 3 на коде и показывает топовый результат среди моделей своего класса.
В чём сила:
— Жёсткая фильтрация данных: модель обучена на «model-centric» пайплайне. Вместо миллиарда сырых примеров — качественный отбор с помощью других LLM. В итоге в датасете остались только хорошо структурированные, читаемые и модульные фрагменты кода.
— Минимум токенов — максимум выхлопа: тренировку провели всего на 6 трлн токенов, а это в 5 раз меньше, чем у конкурентов. Seed-Coder уверенно обходит аналоги своего размера по генерации, автодополнению и решению задач на reasoning.
— Две версии: Instruct — для обычных задач, Reasoning — для более сложных. Обе выложены в открытый доступ и уже тестируются на Hugging Face.
Это редкий пример, когда маленькая модель не просто «дешевле и быстрее», а реально догоняет (и обгоняет) более крупные аналоги — за счёт чистого датасета и архитектурных решений.
🔗 GitHub проекта 🔗 Reasoning-модель на HF 🔗 Instruct-модель на HF 🔗 Обзор на AIBase 🔗 Обсуждение на Reddit
Компания Luma AI добавила в свою платформу функцию Reframe — это полноценный outpaint, который работает не только с изображениями, но и с видео. Теперь можно загрузить ролик, выбрать формат — и ИИ сам достроит недостающие части кадра, как в генеративной графике. Но с движением.
Reframe даёт возможность свободно перемещать объекты, менять пропорции и кадрировать материал под любые форматы: от Instagram Reels до широкоформатного YouTube. Всё это происходит прямо в браузере и не требует глубоких знаний монтажа.
Фича работает на базе Dream Machine, доступна в подписках Unlimited и Enterprise. Уже сейчас ей активно пользуются креаторы, которые адаптируют свои вертикальные ролики под горизонтальные платформы — и наоборот.

Организаторы крупнейшего конкурса AI-фильмов Project Odyssey: Season 2 опубликовали отчёт по итогам соревнования. 500 финалистов рассказали, какими инструментами пользовались, сколько времени и денег потратили — и что действительно помогает победить.
Средняя стоимость одной минуты AI-видео — $70 на токены и 12 часов работы. Почти все участники тратили 10+ часов на один ролик, и 91% делали это в команде.
Использование ChatGPT для написания сценариев показало низкую эффективность: по «очкам» он проиграл обычным сценаристам. Побеждали те, кто совмещал AI-генерацию с человеческим продакшеном.
Интересный нюанс: ни один финалист с полностью AI-сгенерированной музыкой не получил приз. Весь топ — с живыми саундтреками.
Также Recraft неожиданно обошёл по результативности более популярный Kling — возможно, из-за того, что средний уровень у пользователей последнего был ниже.
Итог: автоматизация — хорошо, но AI всё ещё не заменяет вкус, опыт и монтаж. А вот ускоряет — отлично.
Тот самый 📎Clippy из MS Office 97 вернулся как локальный AI-ассистент, который умеет запускать языковые модели прямо у тебя на компьютере. Проект собрал независимый разработчик Felix Rieseberg, оформив всё в ретро-интерфейсе а-ля Windows 98. Получилось не просто мемно, а реально удобно.
Clippy работает оффлайн, не требует установки и поддерживает собственные модели, промпты и настройки. Внутри — связка llama.cpp и node-llama-cpp, которая автоматически подбирает лучший способ запуска модели: CUDA, Metal, Vulkan и так далее. Поддерживаются Windows, macOS и Linux.
Это не просто рофельная оболочка. Clippy — портативный интерфейс для запуска LLM без облаков, без слежки и без лишней сложности. Своего рода «AI с человеческим лицом и ностальгией».

Pinterest обновился – завезли визуальный поиск, и теперь он реально помогает найти то, что нравится. Пока фичи работают только в категории женской моды и только в США, Канаде и Великобритании — но первые отзывы уже отличные.
Теперь при нажатии на пин всплывает анимированное свечение, которое подсвечивает ключевые элементы изображения. После этого Pinterest показывает слова, описывающие, что именно в картинке тебя зацепило — цвет, фасон, материал. За этим стоит визуально-языковая модель (VLM), которая анализирует картинку и превращает её в понятный запрос.
Также можно уточнять поиски: находить похожие вещи, смотреть другие стили или цвета — всё это встроено прямо в ленту. Вдобавок Pinterest начал маркировать изображения, созданные нейросетями, и дал возможность ограничить их показ в ленте — по просьбам пользователей.
Задача сервиса — вернуть себе статус главного AI-инструмента для вдохновения и покупок. Пока выглядит как шаг в правильную сторону.

Google расширила доступ к AI Mode — теперь он открыт всем пользователям Labs в США. Вместо классической строки поиска ты получаешь интерактивный диалоговый интерфейс, похожий на ChatGPT или Perplexity, но с данными из всей экосистемы Google.
Новое обновление делает поиск ещё удобнее: появляются визуальные карточки с рейтингами, отзывами, ценами и фото. Например, спрашиваешь про винтажные магазины — получаешь список с рабочими часами и кнопкой «как доехать». А если ищешь товар — видишь реальные цены, акции, наличие на складах и даже доставку.
AI Mode также запоминает, что ты искал, и позволяет быстро вернуться к предыдущим темам. Всё работает в одном окне, без кликов по сайтам. Это уже не поиск в привычном смысле, а полноценный AI-помощник для принятия решений.
Пока только на английском и только в США, но очевидно: это тест перед глобальным запуском.

На вокзале «Минск-Пассажирский» появилась первая в СНГ аптека без фармацевта. Работает она круглосуточно и управляется искусственным интеллектом от российской компании Smart Engines. Покупателю достаточно выбрать препарат на экране, показать паспорт — и робот сам выдаст нужное лекарство.
Внутри установлен стеллаж с 300+ видами безрецептурных препаратов. Робот проверяет возраст по документу, принимает оплату и контролирует температуру внутри капсулы.
Главное — всё работает офлайн, без отправки личных данных. Даже рукописные рецепты и паспорта в неудобных положениях система считывает без ошибок — благодаря нейросетям с архитектурой «Да Винчи».
Разработчики обещают, что в будущем роботы смогут выдавать и рецептурные лекарства, а пока — проходят тестирование в Беларуси. В России такая система уже используется в банках, нотариатах и аэропортах, но в аптеке — впервые.
🔗 CNews
Индийский стартап Routematic привлёк $40 млн инвестиций в рамках раунда Series C. Деньги пойдут на развитие AI-решений для логистики и корпоративных перевозок, а также на расширение парка электромобилей с ИИ-навигацией.
Главная фишка компании — использование нейросетей для оптимизации маршрутов: учёт пробок, загрузки машин, времени ожидания и даже предпочтений сотрудников.
Система уже работает у крупных заказчиков в Индии, а теперь Routematic выходит на рынки Юго-Восточной Азии и Ближнего Востока.
Фокус — на автоматизации: ИИ планирует смены водителей, строит расписания и помогает сократить расходы на топливо и рабочее время. По сути, это AI-диспетчерская, которая управляет корпоративным транспортом без участия человека.
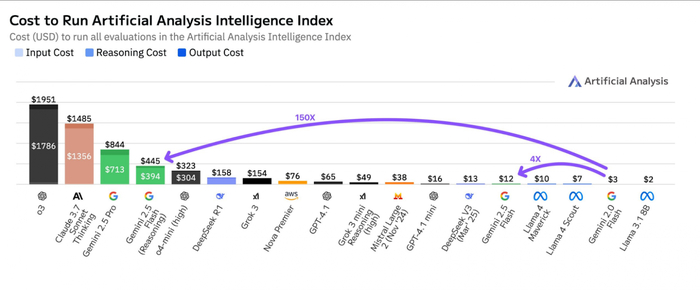
Платишь за токены, но переплачиваешь в разы — ArtificialAnalysis показал, что «цена за миллион токенов» почти ничего не говорит о реальной стоимости задач. Всё решают скрытые факторы: многословность модели, контекст, формат вывода и поведение на промптах.
Например, Gemini 2.5 Flash с reasoning может обойтись в 150 раз дороже, чем та же версия без reasoning — даже если цена за токен почти не отличается. А o4-mini, при том что дороже по токенам, в ряде задач оказывается дешевле на практике, потому что пишет короче и не тратит лишнее.
Особенно это критично при масштабировании — когда ты запускаешь сотни или тысячи запросов. Модели с красивым прайсом вроде $1/млн токенов могут выдавать в 2.5–3 раза больше текста, чем нужно. А это уже реальные деньги.
Вывод: перед внедрением LLM в продукт нужно тестить не прайс, а итоговую стоимость в боевых задачах.
Подытожим. Вот что происходило на неделе с 5 по 12 мая:
— Gemini на максималках: Google докрутил кодинг, видео и интерфейсы — и теперь реально претендует на первое место среди LLM.
— Open-source по-прежнему давит снизу: Seed-Coder и Mistral Medium показывают, что маленькие модели могут бить больших, если правильно фильтровать данные.
— Инструменты всё ближе к пользователю: Clippy — уже не шутка, Pinterest — не просто вдохновение, а полноценный визуальный AI-поиск.
— ИИ лезет в оффлайн: от аптек и транспорта до диспетчеров и ассистентов.
— Деньги решают — но не так, как ты думал: API может стоить копейки за токен и при этом сжирать бюджет на ровном месте.
AI всё глубже проникает в жизнь. Он уже не просто рисует картинки — он управляет логистикой, помогает в аптеке и диктует, как строить поиск. И каждую неделю эта граница смещается всё дальше.
Какая новость поразила тебя больше всего? Пиши в комментах! 👇🏻

Привет! 👋
Это новый выпуск «Нейро-дайджеста» — коротких и полезных обзоров ключевых событий в мире искусственного интеллекта.
Меня зовут Вандер и каждую неделю я делаю обзор новостей о нейросетях и ИИ.
Неделя с 28 апреля по 4 мая 2025 года выдалась щедрой на новинки: китайские модели, которые наступают на пятки OpenAI, подкасты из PDF на русском и кот с квантовой непредсказуемостью, претендующий на сознание — я собрал в одном месте только самое важное и только то, что реально интересно и полезно. Поехали!
Предыдущий выпуск тут.
🧠 ИИ-модели
Qwen3 от Alibaba — китайская альтернатива OpenAI с открытым кодом
DeepSeek Prover-V2 — 671B модель для формальных доказательств
OLMo 2 от AI2 — крошка на 1B, уделывает Meta и Google
🛠 ИИ-Инструменты и интерфейсы
Подкасты на русском в NotebookLM
AI Mode — новый поиск от Google по всей Америке
Реклама Microsoft, которую сделал ИИ
Qwen, DeepSeek и Gemma — теперь в Yandex Cloud
Suno 4.5 — генерация треков до 8 минут
Duolingo запускает 148 курсов за год с помощью ИИ
🧪 Исследования и технологии
Anthropic заглядывает в «чёрный ящик» нейросетей
ИИ комментирует спорт в реальном времени
ИИ и кибербезопасность: главное с RSA 2025
Квантовый кот и теория сознания
Gemini 2.5 прошла Pokemon Blue
ChatGPT определяет геолокацию по фото
🏛 ИИ в обществе
Рой Ли — $3 млн с ИИ-помощником и отчисление
Люси Го — самая молодая миллиардерша
Фиби Гейтс — ИИ для шопинга и $500 тыс. от Кардашьян
Самое маленькое в мире искусственное сердце — и спасённый ребёнок

29 апреля Alibaba выпустила Qwen3 — новую линейку языковых моделей, которая сразу хайпанула во всём AI-сообществе. Это серьёзный шаг вперёд: мощные возможности, поддержка множества языков и полный open-source.
Главная фишка — гибридный режим работы. Модель умеет «включать мозги» только тогда, когда это нужно.
Если задача сложная — активируется режим глубокого анализа.
Если вопрос простой — Qwen3 отвечает быстро и без лишних вычислений.
Пользователь сам управляет поведением модели с помощью тегов вроде /think и /no_think, подстраивая отклик под задачу.
В техническом плане Qwen3 стала заметно умнее. Она лучше справляется с логикой, кодом и математикой, точнее следует инструкциям, увереннее ведёт диалоги и пишет более естественные тексты.
Ещё один важный плюс — поддержка 119 языков и диалектов, включая русский. Модель спокойно переключается между языками и уверенно работает в многоязычных средах.
Также Qwen3 улучшили для задач автоматизации: она точнее интегрируется с внешними сервисами и подходит для создания AI-агентов. Alibaba предлагает для этого собственный фреймворк Qwen-Agent.
И наконец — открытый код. Все восемь моделей семейства (от компактной 0.6B до огромной 235B MoE) выложены под лицензией Apache 2.0. Их можно свободно использовать, модифицировать и применять в коммерческих проектах.
Модели уже доступны на Hugging Face, ModelScope и Kaggle.
🔗 Официальный блог Qwen3 🔗 Коллекция Qwen3 на Hugging Face 🔗 Репозиторий Qwen3 на GitHub 🔗 Пресс-релиз Alibaba Group 🔗 Обзор на PureVPN 🔗 Документация Qwen (Основные концепции)
Как Qwen справляется с задачами?
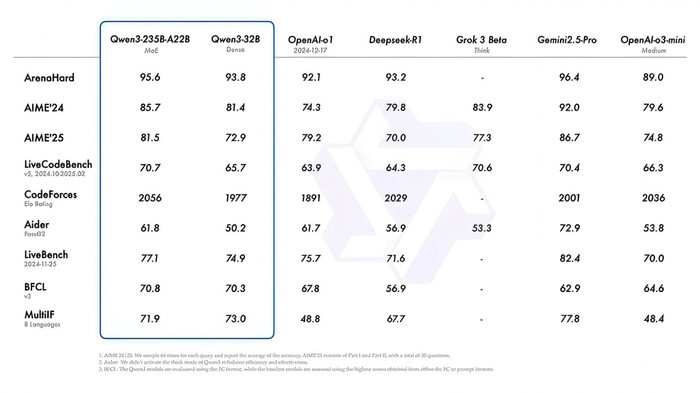
Конечно, главный вопрос — насколько новая модель конкурентоспособна. Бенчмарки показывают, что Qwen3 действительно сражается на равных с топами от OpenAI, Google и DeepSeek.
Флагманская модель Qwen3-235B-A22B обошла o3-mini от OpenAI в тестах AIME (математика) и BFCL (логика). В программировании (бенчмарк Codeforces) она немного обогнала Gemini 2.5 Pro от Google и значительно — DeepSeek-R1.
В тесте Arena-Hard — одном из самых сложных на рассуждение — Qwen3-235B набрала 95.6 балла, что выше, чем у GPT-4o (89.0) и DeepSeek-R1 (90.2), и немного уступает только Gemini 2.5 Pro (96.4).
Но есть и слабые места. В LiveCodeBench модель пока уступает o4-mini (70.7% против 80%), а в AIME’24 набрала 85.7% — против 94% у той же o4-mini. Тем не менее, средняя модель Qwen3-32B уже превосходит o1 от OpenAI, а Qwen3-30B-A3B показывает отличные результаты в ряде других тестов.
Вывод: Qwen3 — это не просто open-source альтернатива. Это реальный конкурент крупнейшим проприетарным моделям, особенно в математике, коде и логике. Да, в некоторых задачах закрытые модели всё ещё впереди, но разрыв сокращается. И это — большой шаг для всего сообщества открытого ИИ.
🔗 Обзор бенчмарков на Analytics India Mag 🔗 Обсуждение на Reddit (vs OpenAI/Google) 🔗 Обзор на DataCamp 🔗 Сравнение на DEV Community 🔗 Обзор на AInvest о данных обучения

Китайский стартап представил Prover-V2 — одну из самых специализированных и масштабных языковых моделей на сегодня.
Её задача не поболтать с пользователем, а доказывать математические теоремы. Причём делает она это на уровне преподавателей вышмата.
Модель построена на базе DeepSeek V3, весит внушительные 671 миллиарда параметров и заточена под работу с математикой в формальном виде. Это значит, что Prover не просто «понимает математику», а пишет доказательства на специализированных языках — вроде Lean или Isabelle.
Используется она, в первую очередь, для задач из области автоматизированного доказательства, матлогики и фундаментальных исследований.
Что интересно, в паре с Prover-V2 сразу вышла её уменьшенная версия — своего рода «мини-Prover», сделанная на базе прежней модели V1.5 (7B). Так что попробовать её возможности можно даже без супермашины.
Prover-V2 пока недоступна в виде чат-бота и не подойдёт для повседневных задач вроде написания кода или эссе. Но для научного сообщества, студентов-математиков и всех, кто интересуется формальными системами рассуждений — это прорыв.

Исследовательский институт AI2 (Allen Institute for AI) выпустил OLMo 2 1B — небольшую open-source модель с всего 1 миллиардом параметров, но с результатами, которые заставляют обратить на неё внимание. По ряду задач она превзошла аналогичные модели от Google, Meta и Mistral.
OLMo 2 задумывалась как полностью прозрачная и воспроизводимая: открыты не только веса, но и код, пайплайн обучения, токенизатор и сами данные. Это делает её полезной не только для разработчиков, но и для исследователей и команд, которым важно понимать, как модель устроена изнутри.
В качестве тренировочного корпуса использовался Dolma v1.7 — тщательно отобранный датасет объёмом 3 триллиона токенов. Архитектура напоминает LLaMA, но с рядом доработок: улучшенные инициализации, прогрессивная обрезка контекста, более аккуратный токенизатор.
На практике OLMo 2 показала лучшие результаты в своём классе в бенчмарках ARC, HellaSwag, PIQA и даже на ряде задач по генерации кода. Особенно отмечается устойчивость к галлюцинациям — а это важный показатель для маломасштабных моделей.
Google обновила свой ИИ-сервис NotebookLM, превратив его из помощника для чтения документов в полноценный инструмент для создания подкастов — причём на 70+ языках, включая русский, китайский и даже латынь.
Идея проста: ты загружаешь текст, PDF, ссылку на сайт или видео — а NotebookLM превращает это в подкаст с двумя ведущими, которые обсуждают материал в формате живого разговора. Всё — с опорой на твои файлы, и всё — с озвучкой на выбранном языке. Поддержка русского теперь официально работает, и звучит вполне прилично.
Самое интересное — интерактивный режим. Пока он доступен только на английском, но уже даёт почувствовать, куда движется формат: во время воспроизведения можно вмешаться или задать вопрос — и диктор ответит прямо в эфире. Это почти как поговорить с нейросетью вслух.
Сценарии использования — от учебных подкастов и генерации сводок до быстрых брифингов на ходу. Для исследователей и контент-мейкеров — это инструмент, который реально экономит время.
Google запустила в США новый режим поиска — AI Mode, который превращает привычную строку запросов в полноценный диалоговый интерфейс, напоминающий ChatGPT или Perplexity. Это не эксперимент: функция стала полноценной вкладкой в Google Search — рядом с «Картинками» и «Картами».
Что внутри? Диалоговый формат запросов, быстрые карточки с ответами, генерация списков, подборок, советов и даже промтов. Всё это работает поверх привычной выдачи и использует возможности модели Gemini. Результаты можно править, переспросить или уточнить прямо в окне ответа, не уходя на сайты.
Для пользователя это означает переход от поиска как «вопрос → ссылка» к контекстному взаимодействию, где система действительно старается понять, что именно нужно.
Сценарии использования самые разные: от «сравни этот ноутбук с этим» до «распиши маршрут на два дня в Киото». И всё это — в диалоге.
Сейчас AI Mode работает только на английском и только в США, но это явно бета перед глобальным запуском.

В начале года Microsoft выпустила минутный рекламный ролик для своих Surface-устройств — ноутбуков и планшетов. Видео вышло обычным, без акцентов на технологии. А спустя три месяца компания призналась: почти всё сделано с помощью генеративного ИИ.
Сценарий, визуальный стиль, композиция сцен, даже переходы — всё это было сгенерировано. Художники описывали боту, что хотят видеть, получали варианты, уточняли — и так сотни раз, пока не добились нужного результата. В кадрах, где требовалась реалистичная работа рук, использовались актёры. Остальное — синтез.
Ни в названии, ни в описании, ни в YouTube никто не указал, что ролик сгенерирован. За несколько месяцев видео набрало десятки тысяч просмотров — и ни у кого не возникло подозрений.
Этот кейс — важный маркер. Он показывает, что ИИ-тулзы уже не просто эксперименты, а полноценные участники производственного цикла: от идеи до монтажа. Особенно в рекламе, где счёт идёт на кадры и эмоции.
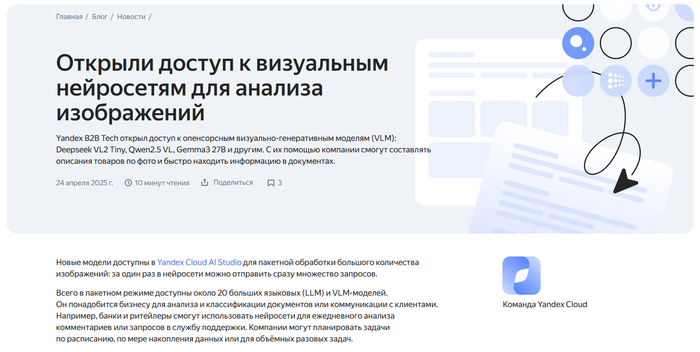
В Yandex Cloud стали доступны VLM и текстовые модели через API, включая популярные open-source семейства — Qwen 2.5, DeepSeek VL2, Gemma3 и LLaMA 3.3. Всё это теперь можно вызывать напрямую, без необходимости разворачивать инфраструктуру.
Формат — Batch Processing API: пользователь отправляет пачку запросов и получает ответы в течение дня со скидкой до 50%. Это не real-time, но для задач вроде генерации описаний, обработки массивов документов или создания тестов — вполне рабочий вариант.
Особенность обновления — появление визуально-языковых моделей (VLM). Они могут работать с изображениями и текстом одновременно: генерировать описания, обобщать визуальный контент, решать мультимодальные задачи.
Плюс — теперь можно использовать и ризонеры: модели, заточенные под логические цепочки и рассуждение. В числе доступных — QwQ и DeepSeek R1.
Для российского рынка это важное событие: open-source модели мирового уровня теперь доступны из облака, легально, с понятной документацией и поддержкой.
Suno выпустила обновление версии 4.5 — и это, похоже, один из самых заметных апгрейдов в сфере генеративной музыки за последние месяцы.
Главное нововведение — поддержка треков до 8 минут длиной, причём с более стабильной структурой: куплеты, припевы, переходы. Это приближает нейросеть к реальному музыкальному продакшену.
Ещё одно важное улучшение — повышенное качество инструментов. Раньше всё звучало немного «в кашу», особенно барабаны и басы. Теперь инструменты распознаются лучше, звучат отдельно и чище, треки в целом стали менее мыльными и ближе к студийному качеству.
Добавили и больше жанров — теперь Suno умеет работать с электроникой, прог-роком, альтернативой и экспериментальными стилями. Алгоритм стал точнее угадывать настроение, темп и форму.
Пока доступ к v4.5 открыт только для подписчиков, но для тех, кто работает с генеративной музыкой — обновление стоящее.

Duolingo представила сразу 148 новых языковых курсов, и почти все они были созданы с помощью генеративного искусственного интеллекта. По словам CEO Луиса фон Ана, то, на что раньше уходили годы ручной работы, теперь делается за несколько месяцев.
Для сравнения: разработка первых 100 курсов платформы заняла почти 12 лет. А теперь за год — почти полтора раза больше, и с адаптацией под 28 языков, включая региональные и менее распространённые.
ИИ помогает не только с написанием и переводом уроков, но и с адаптацией культурного контекста, генерацией упражнений, примеров, тестов и даже голосовой озвучкой. Это особенно важно, чтобы курсы чувствовались живыми, а не «склеенными нейросетью».
Компания заявляет, что планирует и дальше перевести образовательную часть на «AI-first» подход, включая замену части контрактных авторов автоматикой.
Duolingo — один из первых массовых EdTech-сервисов, который полноценно автоматизирует создание контента, и эта новость — сигнал всем образовательным платформам.

Исследователи из Anthropic — создатели моделей Claude — представили новый подход к интерпретации больших языковых моделей, который может помочь понять, что именно происходит внутри нейросети, когда она «думает».
Проблема в том, что поведение LLM до сих пор во многом остаётся непрозрачным: модели могут давать точные ответы, но мы не понимаем, как именно они к ним приходят. Это мешает доверию, безопасности и разработке более управляемых систем.
Anthropic разработала методику, которая позволяет разложить внутренние представления модели на компоненты. По сути — это попытка посмотреть в голову ИИ и увидеть, какие «мысли» возникают на разных этапах генерации. Авторы называют это «mechanistic interpretability» — механистическим пониманием.
Зачем это нужно?
Чтобы понять, почему модель галлюцинирует — и как это предотвратить
Чтобы настроить модель под конкретные логические или этические требования
И в перспективе — создать более безопасный и проверяемый ИИ
Исследование только в начале пути, но это одно из самых многообещающих направлений в AI-безопасности прямо сейчас.
Команда из Национального университета Сингапура представила модель Live CC-7B, способную комментировать спортивные события в реальном времени — с задержкой менее 0,5 секунды. Это одна из первых попыток превратить ИИ в полноценного диктора для живых трансляций.
В отличие от типичных генеративных моделей, которые «думают» дольше, Live CC-7B работает почти в прямом эфире, адаптируясь под события и меняющуюся обстановку. ИИ анализирует поток данных — текстовых, аудио или визуальных — и превращает их в внятный, связный комментарий.
Пример: модель может следить за матчем и на лету выдавать реплики вроде «опасный момент у ворот» или «игрок нарушил правила — судья поднимает карточку». Всё — без сценария и без предварительной подготовки.
Разработчики считают, что такая модель может быть полезна не только в спорте, но и в новостных лентах, аналитике рынков, игровых стримах и любых ситуациях, где важна быстрая реакция на происходящее.

На прошедшей в Сан-Франциско конференции RSA 2025 тема ИИ звучала особенно громко. В центре внимания — как нейросети помогают защищаться от атак, но также и как их используют сами злоумышленники.
Cisco представила новую open-source модель безопасности на 8B параметров, которую можно интегрировать в системы анализа угроз. А Google Cloud поделился исследованиями о том, как продвинутые хак-группы (APT) уже используют LLM — для фишинга, автоматического поиска уязвимостей и генерации вредоносных сценариев.
На панелях обсуждали и вопросы кооперации: крупные игроки говорят о необходимости делиться инструментами и знаниями, чтобы реагировать быстрее. ИИ позволяет ускорить реакцию на угрозу, но и поднимает новые вопросы о прозрачности, этике и контроле.
Вывод: кибербезопасность в эпоху ИИ — это не просто гонка технологий, а вопрос архитектуры доверия. RSA 2025 стала напоминанием: если ты не используешь ИИ для защиты — его используют против тебя.
На конференции MARS 2025, которую ежегодно проводит Джефф Безос, канадский стартап Nirvanic представил робота KitCat — первого ИИ-агента, управляемого квантовой неопределённостью.
KitCat — это не просто милый робот с камерой. Его движения выбираются не алгоритмом, не случайностью, а квантовым суперпозицией. Сигнал с камеры дважды в секунду отправляется на квантовый компьютер D-Wave, где каждый раз из 32 возможных вариантов действий выбирается следующий — не предсказуемо, а физически неопределённо.
Зачем это всё? Команда Nirvanic пытается проверить гипотезу квантового сознания, которую ещё в 1990-х выдвинули Роджер Пенроуз и Стюарт Хамерофф. Согласно ей, наше мышление может зависеть от квантовых эффектов в микротрубочках нейронов мозга.
Чтобы это проверить, исследователи проведут миллионы итераций с двумя версиями KitCat: одна управляется классическим процессором, вторая — квантовым. Если поведение во втором случае будет статистически отличаться — это станет аргументом в пользу гипотезы.
Даже если теория не подтвердится, сам эксперимент уже важен: он может показать, как квантовые компьютеры способны управлять физическими системами в реальном мире.
Недавно стало известно, что модель Gemini 2.5 Pro от Google прошла классическую игру Pokemon Blue от начала до конца.
Это не просто забавный факт — а заметный шаг вперёд в способности ИИ взаимодействовать с интерактивной средой, где нет чёткого текста, а есть правила, реакции и неизвестность.
Несколько месяцев назад подобную задачу пробовали дать Claude — и та застряла в самом начале. Gemini справилась: анализировала экран, принимала решения, управляла персонажем и прошла весь сюжет.
Но не всё так просто. У модели был доступ к игровому движку, а не только к изображению с экрана. Кроме того, в промпт добавили подсказки, и, возможно, Gemini опиралась на информацию из обучающих данных (включая советы и прохождения).
Это означает, что результат — не чистый zero-shot, и говорить о превосходстве над другими моделями пока рано. Но как демонстрация возможностей LLM в среде с агентной логикой — это очень мощный шаг.
Сейчас Google не выкладывает систему в открытый доступ, но очевидно — такие эксперименты уже становятся бенчмарками, и за ними стоит следить.

С новыми мультимодальными моделями o3 и o4-mini ChatGPT научился делать больше, чем просто анализировать текст. Теперь он может угадывать локацию по фотографии — без EXIF-данных, GPS или подсказок. Только визуальный контент.
Как это работает? Модель анализирует детали изображения: архитектуру, стиль вывесок, язык, растительность, тип дороги, даже форму почтовых ящиков. При необходимости поворачивает, приближает и интерпретирует. И выдает:
страну,
предполагаемую широту и долготу,
и подробное обоснование, как она к этому пришла.
В промптах уже появился отдельный шаблон: «You are participating in a geolocation challenge…». С его помощью ChatGPT реально угадывает города и районы — особенно в США и Европе, где у модели больше визуального контекста.
Это может стать основой для новых бенчмарков по визуальному рассуждению, и уже используется в челленджах наподобие GeoGuessr.
Важно: распознавание лиц и частной информации отключено. OpenAI подчёркивает, что модель «не предназначена для слежки», и старается отказываться от подобных задач.

Осенью 2024 года студент Колумбийского университета Рой Ли (Чунгин Ли) с другом за 10 дней собрал Interview Coder — ИИ-инструмент, который помогает проходить технические собеседования на платформах вроде LeetCode.
Инструмент оказался рабочим: Рой получил офферы от Meta, TikTok, Amazon и Capital One*. Но когда видео одного из интервью стало вирусным, Amazon потребовал удалить его, а университет обвинил Ли в использовании ИИ для списывания и отчислил его до мая 2026 года.
Реакция Ли была дерзкой и вирусной:
«Может, хватит задавать тупые вопросы на собеседованиях — тогда люди не будут создавать подобную фигню».
И вот — через месяц он запускает новую платформу Cluely. Это расширенная версия Interview Coder, которую можно использовать не только на собеседованиях, но и на экзаменах, встречах и даже свиданиях. Подъём финансирования — $5,3 млн за три дня, подписки — уже $3 млн годовой выручки.
Сейчас Ли публично предлагает «взломать» любую систему, где царит формальность и автоматизм. Он не отрицает, что его подход вызывает вопросы — но считает, что ИИ должен менять не только технологии, но и устаревшие процессы оценки людей.

Люси Го, соосновательница Scale AI, официально стала самой молодой женщиной-миллиардером, обогнав по этому статусу Тейлор Свифт. Причина — крупная сделка с инвесторами, позволившая ранним сотрудникам и фаундерам продать доли, и резкий рост оценки компании до $25 млрд.
Го покинула Scale AI ещё в 2018 году — на фоне выгорания и разногласий с партнёром Александром Ваном. Но она сохранила 5% акций, которые сегодня оцениваются в $1,25 млрд.
До Scale AI она бросила университет, получив $100 000 от фонда Питера Тиля, стажировалась в Facebook*, работала в Quora и Snapchat. После ухода из основного проекта запустила венчурный фонд Backend Capital и платформу Passes — конкурента Patreon и OnlyFans, который уже оценён в $150 млн.
Сейчас Люси активно инвестирует в стартапы и ведёт блог, не стесняясь конфликтов.
«Мне комфортно в хаосе», — говорит она. И рынок это, похоже, ценит.
Фиби Гейтс, младшая дочь Билла Гейтса, вместе с соседкой по общежитию Софией Кианни запустила Phia — ИИ-приложение, которое ищет одежду и аксессуары дешевле, сканируя десятки тысяч сайтов и маркетплейсов.
Phia не просто агрегирует цены, а отслеживает завышения, подсказывает альтернативы, ищет среди частных продавцов и даёт рекомендации на основе пользовательских предпочтений. Всё — через один клик.
Идея родилась, когда Фиби обнаружила купленное за $500 платье всего за $150 на сайте перепродажи. Она почувствовала себя, по её словам, «глупо» — и решила, что это можно автоматизировать.
Проект сразу получил $500 тыс. инвестиций — причём не от папы, а от Крис Дженнер (семейство Кардашьян), основательницы Spanx Сары Блейкли и венчурной инвесторки Джоанн Брэдфорд. Сам Билл Гейтс только одобрил идею морально, но участия не принимал — «чтобы избежать конфликта интересов».
Phia уже доступна в App Store и ориентирована в первую очередь на женскую аудиторию, фанатов скидок и resale-культуры. В описании — «мы те самые подруги, которые ссорятся из-за платья и сидят часами на шоп-сайтах».
В китайском городе Ухань врачи провели уникальную операцию: семилетнему ребёнку с тяжёлой сердечной недостаточностью имплантировали самое маленькое в мире искусственное сердце — всего 2,9 см в диаметре и весом 45 граммов.
Это устройство — не просто миниатюрная копия взрослых аппаратов. Оно работает на магнитной подушке: вращающиеся элементы не касаются стенок и не создают трения. Это снижает риск осложнений и делает сердце пригодным даже для очень маленьких пациентов.
У мальчика была диагностирована дилатационная кардиомиопатия, и его сердце перестало справляться с кровообращением. Донор не находился, и врачи приняли решение использовать искусственное сердце как временную поддержку до пересадки.
Операция длилась 5 часов. Уже на следующий день ребёнок начал дышать самостоятельно, функции сердца стабилизировались. Сейчас он восстанавливается и ждёт пересадку.
По данным китайского Минздрава, ежегодно в стране госпитализируют около 40 тысяч детей с тяжёлой сердечной недостаточностью, но пересадку получают меньше 100. Новый аппарат — совместная разработка медиков и биотех-стартапа Shenzhen Core Medical — даёт шанс многим из них.
Подытожим. Вот что происходило на неделе с 28 апреля по 5 мая:
Open-source модели типа Qwen3 и DeepSeek уже догоняют GPT-4
Компактные LLM вроде OLMo 2 уделывают гигантов в ключевых задачах
AI подкасты, музыка, реклама, обучение — генеративка буквально везде
Всё больше инструментов для работы, автоматизации, создания агентов
Появляются вопросы — про сознание, галлюцинации, приватность
ИИ уже не тренд — это новая реальность, которую ты принимаешь или не принимаешь.
Интерфейсы, роли и привычки – всё меняется.
Какая новость поразила тебя больше всего? Пиши в комментах! 👇🏻

Привет!
Это новый выпуск «Нейро-дайджеста» — коротких и полезных обзоров ключевых событий в мире искусственного интеллекта.
Меня зовут Вандер и каждую неделю я делаю обзор новостей о нейросетях и ИИ.
Неделя с 21 по 27 апреля выдалась горячей: свежие апдейты от OpenAI, новые лимиты, буря вокруг Deep Research и долгожданные интеграции мультимодальных моделей — всё это я собрал в одном месте. Только самое важное и только то, что реально интересно и полезно. Поехали!
Предыдущий выпуск тут
Разработки OpenAI
API для Image Generation через GPT
Удвоение лимитов для o3 и o4-mini
Облегченный Deep Research
Достижения в генерации видео
References для Runway Gen-4
ИИ в исследованиях
Новый способ обучения моделей
Развивающиеся приложения ИИ
Мобильное приложение Qwen от Alibaba
DeepSeek + BMW — интеграция AI в автомобили для Китая
Интересные новости
Роботы бегут полумарафон в Китае
«Спасибо» и «пожалуйста» стоят миллионы долларов для OpenAI
Альтернативная космология без тёмной материи
Мозг композитора пишет музыку после смерти
Люди стали больше пользоваться AI, но меньше доверяют AI-компаниям
inTouch — бот, который звонит родственникам
DxGPT — диагностика редких болезней на ИИ
ИИ в управлении и обществе
ОАЭ подключают AI к написанию законов
Meta внедрила AI для выявления подростков в Instagram
AI впервые упомянут в правилах «Оскара»
Grok получил компьютерное зрение
Vozo — перевод видео с сохранением оригинального голоса
Krea — генерация виртуальных миров
OpenAI выпустила новый API для генерации изображений на основе модели gpt-image-1 — той же технологии, что лежит в основе ChatGPT. Модель генерирует изображения, точно понимает текстовые инструкции, корректно отображает надписи и даже справляется с мировыми знаками.
Сейчас её используют крупные платформы: Gamma рисует диаграммы, HeyGen улучшает аватары, OpusClip делает миниатюры для YouTube, а Quora подбирает изображения к текстам. Photoroom, Canva и Wix интегрировали API в свои дизайнерские сервисы.
gpt-image-1 работает быстро и точно, но высокая стоимость и оплата по количеству токенов могут сделать использование модели дорогим для проектов с большими объемами генераций.
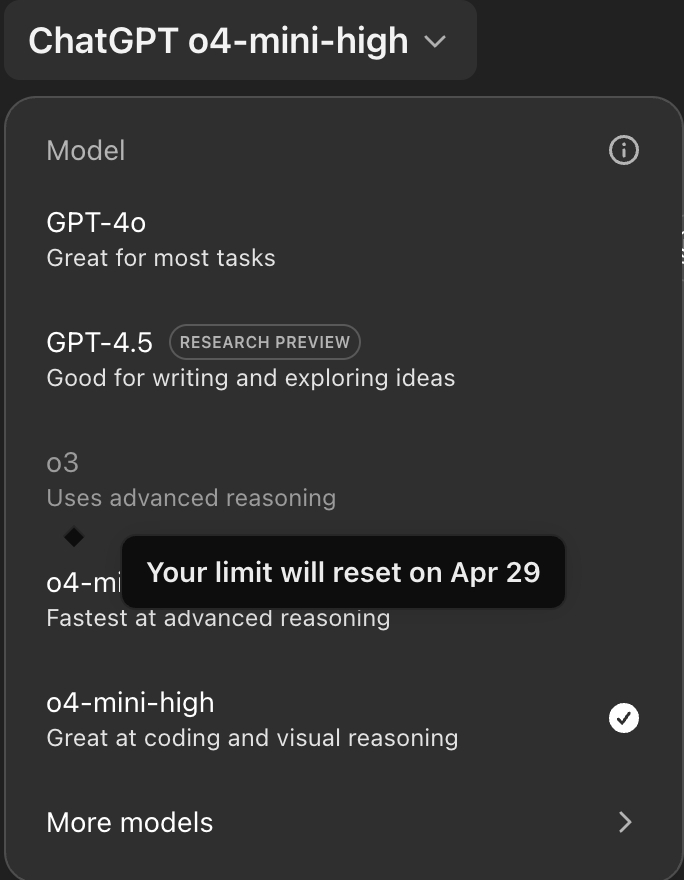
В апреле OpenAI увеличила лимиты для ChatGPT Plus: o3 теперь даёт 100 сообщений в неделю, o4-mini — 300 сообщений в день. Модели получили доступ ко всем инструментам и заменили старые версии.
Пользователи получили больше возможностей для работы, но вместе с этим упало качество: хуже пишется код, чаще обрываются длинные ответы, появляются ошибки в больших промптах. Хотя OpenAI обещала 128–200 тысяч токенов контекста, на практике возникают проблемы.
Важно: старые версии o3-mini-high и o1 убрали. Многие недовольны.
🔗 OpenAI FAQ 🔗 TechRadar 🔗 Reddit

OpenAI открыла для всех облегченную версию Deep Research на o4-mini, а полная версия на o3 осталась только у платных пользователей.
Особенности:
Бесплатно — 5 задач в месяц, Plus — 25, Pro — 250
Ответы короче и более сжато, после исчерпания лимита — автоматический переход на light-версию
Полный Deep Research глубже, с цитатами и длинными выводами
Выводы пользователей:
Для базовых нужд light-Deep Research — достаточно.
Для научных и серьёзных задач требуется платная подписка.
Runway добавила в модель Gen-4 функцию референсов. Теперь можно загрузить изображение персонажа или объекта и сохранить его внешний вид на всех кадрах видео. Это важно для создания анимаций и историй с постоянными героями.
Также появилась функция Coverage — сервис умеет генерировать разные ракурсы по одному референсу. Это упрощает работу с рекламой, соцсетями и короткими фильмами.
Технология улучшает целостность видео, но при сложных переходах и длинных роликах могут появляться артефакты. На некоторых форматах система работает нестабильно.
🔗 Runway 🔗 No Film School 🔗 DataCamp
Появился новый подход к обучению больших языковых моделей. Теперь эталонная модель обновляется прямо во время обучения, а не фиксируется заранее. Это помогает избежать переобучения и лучше подстраивать ответы под людей.
Метод основан на принципе Trust Region: модель можно менять, но только в пределах допустимых отклонений, чтобы не терять качество. Используются три варианта: TR-DPO, TR-IPO и TR-KTO — разные способы аккуратного обновления модели на каждом шаге.
Авторы проверили подход на тестах AlpacaEval 2, Arena-Hard и GPT-4. Результаты показали реальный рост качества: модели лучше справляются с задачами и получают высокие оценки от пользователей.
Alibaba выпустила мобильную версию своей языковой модели Qwen. Приложение работает на смартфоне без постоянного подключения к облаку. Это важно для приватности, автономной работы и использования в местах с плохим интернетом.
Модель умеет генерировать текст и код, обрабатывать изображения и документы. Вся обработка происходит локально, данные не уходят в облако. Приложение оптимизировано под ARM-процессоры и работает на Android и iOS. Сейчас поддерживаются китайский и английский языки, русская версия в планах.
Решение подходит путешественникам, журналистам и пользователям в регионах с цензурой или слабым интернетом. Также Qwen интересен компаниям, которые хотят строить свои мобильные приложения на базе локальной LLM.
Приложение работает в России без VPN.

Китайская компания DeepSeek объявила о партнёрстве с BMW. Их языковые модели теперь встроены в автомобили, выпущенные для китайского рынка.
ИИ управляет голосовым ассистентом, понимает длинные и сложные команды, помогает в навигации и динамически подсказывает маршруты. Также система связана с мультимедиа, климат-контролем и диагностикой автомобиля. За счёт глубокой локализации ИИ распознаёт китайский язык, сленг и авто-термины.
Проект усиливает конкуренцию между DeepSeek, Baidu и Huawei на рынке ИИ в Китае. Это один из первых реальных шагов к созданию «умных» автомобилей, способных работать без постоянного участия человека.
🔗 BMW China 🔗 DeepSeek AI
Онлайн-сервис Lovable обновился: появился улучшенный интерфейс, встроенный редактор кода для тонкой настройки проектов и поддержка совместной работы над одним приложением.
Lovable позволяет создавать сайты, игры и полезные сервисы без написания кода. Нужно только описать идею боту, приложить изображения или даже нарисовать от руки набросок интерфейса. Через пару минут можно получить готовое приложение и сразу опубликовать его в интернете. Любые проекты других пользователей можно доработать под себя через функцию Remix.
Платформа подходит как новичкам, так и опытным разработчикам: Lovable удобно использовать для быстрого прототипирования и тестирования идей. При необходимости готовый код можно экспортировать на GitHub и дорабатывать вручную.
В основе сервиса работают модели от OpenAI, Google и Anthropic. Бесплатный доступ даёт 5 промптов в день, платные тарифы стартуют с $25 в месяц за 100 запросов.
🔗 Lovable 🔗 ProductHunt
В Пекине на полумарафоне (21,1 км) среди 12 тысяч участников выступили 21 робот. Они шли по отдельной трассе с тем же рельефом и погодой. Часть бежала автономно, часть — под дистанционным управлением. За машинами следили инженеры.
До финиша добрались шесть роботов. Победил Tiangong Ultra от института X-Humanoid: с заменой батареи он пробежал за 2 часа 40 минут — в 2,5 раза медленнее лидера среди людей. Робот G1 от Unitree упал на старте: компания объяснила это отсутствием фирменных алгоритмов стабилизации.
Пекинский забег стал крупнейшим для роботов. Ранее в 2011 году в Японии роботы пробежали марафон за 55 часов, а в 2021-м американский Cassie прошёл 5 км без помощи человека и установил рекорд Гиннесса.
Подобные забеги проверяют навигацию, конструкции и батареи. Разработки пойдут в доставку, строительство, медицину и космос.
🔗 Источник
Сэм Альтман заявил, что вежливые обращения пользователей к ChatGPT обходятся компании в десятки миллионов долларов в год. Даже пара лишних токенов увеличивает нагрузку на дата-центры и энергопотребление. По оценке Epoch AI, один запрос к GPT-4o требует 0,3 ватт-часа энергии.
На масштабе миллиардов обращений «спасибо» и «пожалуйста» превращаются в мегаватты и реальные расходы.
67% пользователей в США добавляют вежливые фразы. 12% делают это на случай, если ИИ обретёт сознание. Исследования показывают: нейросети подстраиваются под тон общения — вежливость повышает качество ответов.
Астрономы предложили новую модель, объясняющую движение галактик без гипотетической тёмной материи. Они используют ИИ-алгоритмы для обработки данных с радиотелескопов и показывают совпадение с реальными наблюдениями.
Искусственный интеллект помогает скорректировать параметры моделей так, что видимой массы оказывается достаточно для объяснения поведения галактик. Это открывает новые споры о природе Вселенной и ставит под вопрос необходимость существования тёмной материи.

Умерший в 2021-м Элвин Люсье снова сочиняет — с помощью нейросетей и лаборатории.
Учёные вырастили его искусственный МОЗГ и подключили к системе, реагирующей на внешние раздражители.
Электроды передают нейроимпульсы на латунные пластины с динамиками. Это не просто шум — звучание меняется в реальном времени, подстраиваясь под окружение.
Люсье известен экспериментами с восприятием звука — теперь его творчество продолжается буквально вне тела.
🔗 Источник
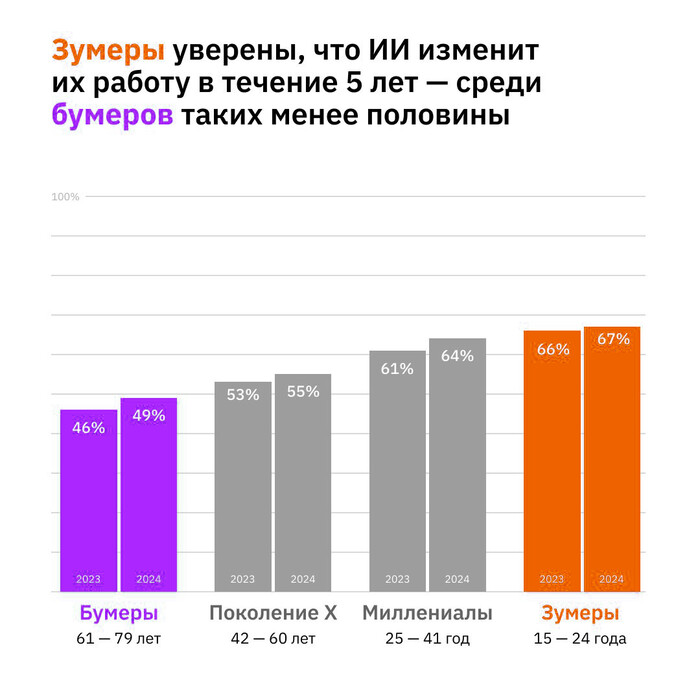
Люди стали лучше относиться к ИИ, но всё меньше верят компаниям, которые его создают. Стэнфордский доклад 2025 AI Index собрал данные от 24 тысяч человек в 32 странах.
Китай (83%), Индонезия (80%), Таиланд (77%) и Мексика (70%) настроены к ИИ наиболее позитивно. В Австралии, Канаде, США и Нидерландах поддержка ниже 45%. В Германии и Франции за два года число сторонников выросло на 10%, в США — на 4%.
Доверие к ИИ-компаниям снижается: за год доля тех, кто верит в защиту личных данных, упала с 50% до 47%.
66% считают, что ИИ сильно изменит их жизнь в ближайшие 3–5 лет. 55% видят в технологиях больше пользы, чем вреда. Половина отмечает экономию времени и рост качества развлечений, но только треть верит в влияние на здравоохранение, экономику и работу.
60% ожидают, что ИИ изменит их профессию, 36% боятся полной потери работы. Среди зумеров две трети ждут радикальных изменений за пять лет. Среди бумеров — меньше половины.
Стартап inTouch разработал бота, который имитирует ваш голос и по расписанию звонит родным. Алгоритм анализирует частоту реальных звонков, темы разговоров и стиль общения, чтобы подобрать индивидуальный «график заботы». Идея рассчитана на людей, занятых на работе или живущих далеко от семьи.
Бот говорит максимально естественно, поддерживает более 30 языков и позволяет загружать личные фразы для звонков. После каждого разговора приложение отправляет вам отчёт и напоминание.
Сервис работает пока только в США и Великобритании.
Возникает вопрос: где проходит граница между заботой и обманом?
DxGPT — первая в мире языковая модель, заточенная только под диагностику редких заболеваний. Алгоритм прошёл закрытые тесты в пяти клиниках ЕС и показал, что способен предлагать корректные гипотезы даже при нетипичных симптомах, где другие системы ошибаются или требуют десятков консультаций.
ИИ строит вероятностную модель заболеваний на основе огромных наборов данных, автоматически собирает анамнез и сверяет симптомы с мировыми кейсами.
DxGPT помогает врачам находить нестандартные пути к диагнозу там, где традиционные методы не работают.

В ОАЭ стартовал эксперимент: искусственный интеллект помогает не только анализировать судебную практику, но и предлагает черновики новых законопроектов для рассмотрения парламентом. Окончательное решение остаётся за человеком, но «рыба» текста создается ИИ.
AI ускоряет обработку юридических данных, позволяет заранее моделировать последствия новых норм и помогает государству экономить время и деньги.
❯ Meta внедрила AI для выявления подростков в Instagram
Meta внедрила AI-модуль, который анализирует аккаунты, сообщения и поведение пользователей, чтобы точнее выявлять несовершеннолетних. Новый алгоритм не только ограничивает показ взрослого или вредного контента, но и предотвращает общение подростков с подозрительными аккаунтами и мошенниками.
AI сканирует фотографии, профили, чаты и истории публикаций, мгновенно блокирует опасных пользователей и постоянно дообучается на новых данных.
❯ ИИ впервые упомянут в правилах «Оскара»
Академия впервые потребует указывать в титрах, если при создании фильма использовались AI-технологии: генеративные модели, сценарии, аудио, подбор актёров или организационная работа. Теперь любая команда должна честно сообщать о применении ИИ, независимо от области использования.
Это повысит прозрачность киноиндустрии и станет первым шагом к разработке стандартов «AI in Cinema».

Компания xAI добавила компьютерное зрение в свою модель Grok. Теперь бот может анализировать фотографии, изображения и мемы: распознавать объекты, расшифровывать визуальные задачи и отвечать на вопросы о содержимом картинок.
Технология пригодится в креативных индустриях для генерации мемов и анализа контента, в техподдержке для диагностики по фото и в работе с изображениями на лету для соцсетей, SMM и образования.
Vozo — перевод видео с сохранением оригинального голоса
Vozo — это генеративный AI для видео-дубляжа. Сервис переводит любой ролик на другой язык, сохраняя интонацию, тембр и динамику оригинального голоса. Поддержка десятков языков, быстрый экспорт для YouTube, TikTok, онлайн-курсов.
Преимущества:
Автоматическая адаптация субтитров
Имитация голоса спикера — не синтез, а “дубликат”
Сильная точность перевода даже на редкие языки

Krea — один из первых AI-инструментов для создания 3D-сцен и виртуальных пространств. Модель генерирует не только сами объекты, но и сразу анимацию, освещение, текстуры — полный набор для игр, архитектуры и метавселенных.
Проекты можно экспортировать в Unity и Unreal Engine, что делает Krea удобным инструментом для инди-разработчиков, 3D-дизайнеров, архитекторов и создателей онлайн-экспозиций. Главное преимущество: идеи можно быстро визуализировать без привлечения профессиональных художников и долгого ручного труда.
Инструмент открывает новые возможности для тех, кто хочет строить виртуальные миры, не имея команды моделлеров и аниматоров.
🔗 Krea AI
Неделя с 21 по 27 апреля показала ключевые тренды в AI:
Масштабирование возможностей OpenAI и конкурентов — API, лимиты, память
Быстрое проникновение AI во все сферы жизни. Новые инструменты для бизнеса, образования, творчества, здоровья.
Конкуренция за «экосистемы» — кто соберёт больше создателей и пользователей.
Вопросы этики, приватности, доверия — как никогда на повестке.
ИИ становится неотъемлемой частью современного мира. Технологии быстро меняют культуру, рынки и подходы к работе, создавая новые вызовы и возможности.
А какие новости вас впечатлили больше всего? Пишите в комментариях!👇

Привет!
Это новый выпуск «Нейро-дайджеста» — коротких и полезных обзоров ключевых событий в мире искусственного интеллекта.
Меня зовут Вандер, я редактор канала Нейро-Пушка и каждую неделю я делаю обзор новостей о нейросетях и ИИ.
Неделя с 14 по 20 апреля выдалась горячей: революционные LLM от гигантов, прорывы в мультимодальных технологиях, инновационные платформы — всё это я собрал в одном месте. Только самое важное и только то, что реально интересно и полезно. Поехали!
Новые языковые модели
Семейство GPT-4.1 от OpenAI — новая эра программирования
o3 и o4-mini — мыслители от OpenAI
Gemini 2.5 Flash — гибридный подход к рассуждениям
ИИ в творческих приложениях
Kling 2.0 — реалистичные видео из изображений
AI-агенты и платформы
Grok Studio — холст для коллаборации от xAI
Aria в Opera Mini — AI для бюджетных устройств
SpeechMap — карта ответов нейросетей
AI в реальных приложениях
Запрет AI-аватара в суде Нью-Йорка
Социальная сеть от OpenAI — потенциальный конкурент X
DolphinGemma от Google — расшифровка языка дельфинов
AI для городского планирования в Кентукки
OpenAI представила семейство GPT-4.1 — новое поколение своих AI-моделей, которое значительно превосходит предыдущую флагманскую модель GPT-4o по ключевым параметрам! 🚀
Главные фишки новых моделей:
Улучшенное кодирование: GPT-4.1 превосходит GPT-4o на 21.4% в бенчмарке SWE-bench Verified. Делает более чем в 2 раза меньше ошибок в code diffs и снижает количество лишних изменений в коде с 9% до 2%!
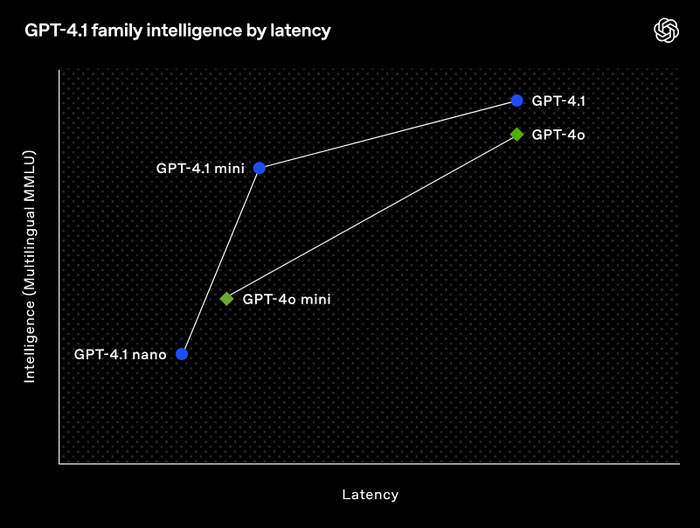
Точное следование инструкциям: улучшение на 10.5% по сравнению с GPT-4o в бенчмарке Scale’s MultiChallenge.
Гигантское контекстное окно: поддержка до 1 миллиона токенов — в 8 раз больше, чем у GPT-4o!
В семейство вошли три модели:
GPT-4.1: флагманская модель для сложных когнитивных задач. Стоимость: $2 за миллион входных токенов и $8 за миллион выходных.
GPT-4.1 Mini: балансирует производительность и стоимость, по интеллекту соответствует или превосходит GPT-4o, но на 83% дешевле и вдвое быстрее! Демонстрирует высокие возможности в понимании изображений. Стоимость: $0.40 за миллион входных токенов и $1.60 за миллион выходных.
GPT-4.1 Nano: самая легкая, быстрая и дешевая модель, идеальна для задач с низкой задержкой. Несмотря на малый размер, поддерживает контекстное окно в 1 миллион токенов. Стоимость: $0.10 за миллион входных токенов и $0.40 за миллион выходных.
Эти модели уже показывают впечатляющие результаты на практике:
Thomson Reuters повысила точность на 17 % при анализе длинных юридических документов с помощью AI-ассистента CoCounsel.
Инвестиционная компания Carlyle улучшила извлечение информации из больших документов на 50 %.
Windsurf заявила, что GPT-4.1 набрал на 60 % больше баллов в их внутренних тестах по кодированию.
OpenAI представила две новые модели рассуждений: o3 и o4-mini, обученные “думать дольше, прежде чем отвечать”! 🧠
Эти модели — настоящий интеллектуальный прорыв, способный использовать и комбинировать все инструменты в ChatGPT, включая веб-поиск, анализ файлов с помощью Python и работу с изображениями.
Ключевые особенности:
o3 — самая мощная модель рассуждений OpenAI, демонстрирующая рекордные результаты в бенчмарках по кодированию, математике и науке.
Достигла 91.6% точности на олимпиадных задачах AIME 2024
Показала прорывной результат 75.7% на сложном бенчмарке ARC-AGI
По оценкам экспертов, допускает на 20% меньше серьезных ошибок, чем o1
o4-mini — более легкая модель для быстрого и экономичного рассуждения.
Лучшая модель по результатам AIME 2024 (93.4% без инструментов, 99.5% с Python)
На бенчмарке Codeforces набирает ELO 2719, немного опережая даже o3
На 24% быстрее и на 93% экономичнее по стоимости токена по сравнению с o1-mini
Стоимость и доступность:
o3: $10.00 за миллион входных и $40.00 за миллион выходных токенов
o4-mini: $1.10 за миллион входных и $4.40 за миллион выходных токенов
Обе модели доступны в ChatGPT для пользователей с подписками Plus, Team и Pro, а также через API. Пользователи бесплатного плана также могут попробовать o4-mini в режиме “Think”.
Сравнение с GPT-4.1:
Важно понимать, что это разные семейства моделей для разных задач. GPT-4.1 оптимизирована для следования инструкциям и работы с длинным контекстом (1M токенов), тогда как o3 и o4-mini специализируются на продвинутых возможностях рассуждения, но имеют контекстное окно только в 200K токенов.
Google представила Gemini 2.5 Flash — свою первую полностью гибридную модель рассуждений! 🔄
Ключевая фича — возможность включать и выключать «мышление» и устанавливать бюджеты на рассуждение для оптимального баланса между качеством, стоимостью и задержкой.
Технические характеристики:
Поддержка контекстного окна в 1 миллион токенов
Полноценная мультимодальная модель, понимающая текст, аудио, изображения и видео
Срез знаний на январь 2025 года
Адаптивные и контролируемые возможности рассуждения
Стоимость:
Входные токены: $0.15 за 1 миллион
Выходные токены: $0.60 за 1 миллион при выключенном “мышлении” и $3.50 при включенном
Результаты бенчмарков:
AIME 2025: 78.0% (одна попытка)
AIME 2024: 88.0% (одна попытка)
GPQA diamond: 78.3% (одна попытка)
LiveCodeBench v5: 63.5% (одна попытка)
MMMU: 76.7% (одна попытка)
Gemini 2.5 Flash выделяется своей ультрабыстрой скоростью при выключенном “мышлении”, сохраняя производительность 2.0 Flash, но с улучшенной точностью. При включении режима рассуждений модель способна решать сложные математические, научные и кодовые задачи на уровне лучших моделей.
Таким образом, пользователи получают гибкость: для простых запросов — молниеносную скорость и экономичность, а для сложных — глубокое рассуждение при необходимости.
Представлена обновленная нейросеть Kling 2.0 для создания видео с более реалистичными движениями объектов!
Ключевые особенности:
Возможность объединять до четырех изображений в один ролик
Функционал для редактирования сцен и отдельных объектов по запросу
Значительно улучшенная реалистичность движений по сравнению с предыдущей версией
Доступ к сервису реализован по подписке от $7 за шесть генераций, что делает технологию относительно доступной для креаторов и маркетологов.
Kling 2.0 предлагает новый подход к созданию видеоконтента, позволяя трансформировать статичные изображения в динамичные ролики, что особенно ценно для рекламы, контент-маркетинга и социальных медиа.
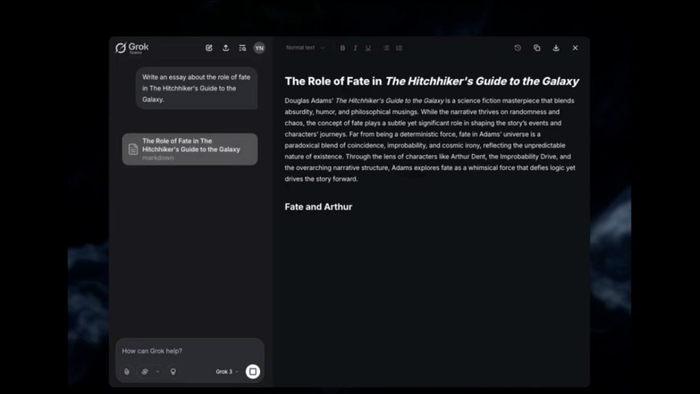
Представленная 16 апреля 2025 года, Grok Studio предоставляет пользователям возможность работать вместе с чат-ботом Grok AI в интерфейсе с разделенным экраном, напоминающем Canvas от OpenAI и Artifacts от Anthropic.
Ключевые возможности:
Генерация контента: документы, код, отчеты и даже браузерные игры
Выполнение кода: поддержка Python, C++, JavaScript, TypeScript и Bash с вкладкой предварительного просмотра
Интеграция с Google Drive: прикрепление документов, таблиц и слайдов
Совместная работа в реальном времени: несколько пользователей могут работать над проектами одновременно
Предварительный просмотр HTML: визуализация документов в формате, готовом для публикации
Отзывы пользователей пока неоднозначны: отмечаются положительные моменты относительно возможностей кодирования, но есть жалобы на удобство использования. Важное преимущество — Grok Studio доступна как для бесплатных, так и для премиум-пользователей на grok.com.
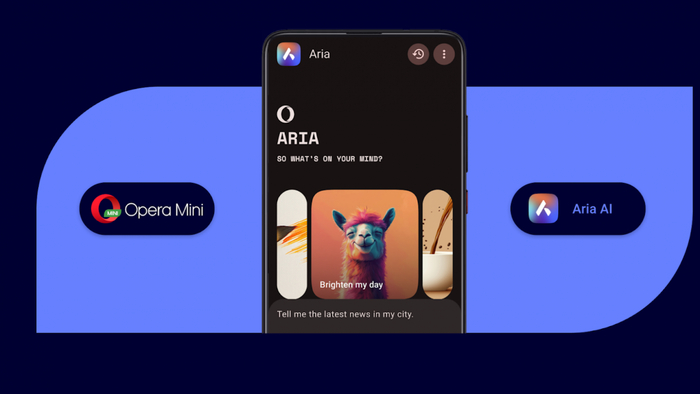
Opera Mini Aria AI
Opera интегрировала своего AI-помощника Aria в браузер Opera Mini для Android, предоставив возможности генеративного AI пользователям устройств с ограниченными ресурсами! 📱
Ключевые функции:
Генерация текста и кода
Создание изображений с помощью модели Imagen3 от Google
Переписывание текста, ответы на вопросы, обобщение контента
Оптимизация для облегченной архитектуры Mini без увеличения потребления данных
Это решение делает передовые AI-технологии доступными более чем 100 миллионам пользователей по всему миру, включая рынки с высокой стоимостью передачи данных, такие как Африка и Азия.
Отзывы пользователей:
Мнения разделились — некоторые считают Aria полезным инструментом для обобщения веб-страниц и ответов на вопросы, другие жалуются на медленное время ответа и проблемы с точностью по сравнению с такими платформами, как ChatGPT.
Интеграция Aria в Opera Mini — важный шаг в преодолении цифрового разрыва, позволяющий пользователям с ограниченными ресурсами получить доступ к генеративному AI.
Анонимный разработчик представил SpeechMap — инструмент, который показывает, как разные AI-модели реагируют на сложные или спорные запросы. 🗺️
Особенности:
Наглядное отображение реакций различных AI-моделей на одинаковые запросы
Четкая визуализация, где модели отвечают прямо, а где уклоняются от ответа
Полезный инструмент для разработчиков и пользователей, желающих изучить границы возможностей генеративного AI
SpeechMap позволяет сравнивать реакции различных AI-систем, что дает возможность лучше понять их ограничения, особенности и потенциальные предубеждения.
Этот инструмент особенно ценен для исследователей в области AI-этики, разработчиков моделей и специалистов, изучающих границы допустимого в генеративном AI.

В апелляционном суде Нью-Йорка вспыхнула дискуссия: можно ли использовать AI в судебных процессах?
Поводом стал инцидент с 74-летним Джеромом Девальдом, основателем стартапа Pro Se Pro. Он попытался представить свои аргументы по трудовому спору с помощью AI-видео — аватара по имени «Джим». Судья не знал о подмене и прервал выступление.
Судья Салли Мансанет-Дэниэлс потребовала отключить видео:
«Я не ценю, когда меня вводят в заблуждение. Вы не будете использовать этот зал для запуска своего бизнеса, сэр».
Почему суд отказал:
Нет прозрачности — это выглядело как попытка обмана.
Нарушение судебных протоколов.
Неясно, можно ли считать такое представительство легитимным.
Неготовность юридической системы к AI-аватарам.
Девальд объяснил, что потерял голос и не смог выступать лично, а видео было единственным способом донести аргументы. Позже он направил извинения.
Этот случай показывает, как важно заранее прописать чёткие правила использования AI в суде. Без них даже полезные технологии будут встречать сопротивление — не из-за вреда, а из-за отсутствия доверия и прозрачности.

OpenAI, по сообщениям инсайдеров, находится на ранних стадиях разработки собственной социальной сети, напоминающей популярную платформу X (ранее Twitter)! 🌐
Предполагаемый функционал:
Акцент на обмене контентом, сгенерированным AI, особенно изображениями
Интеграция с передовыми возможностями AI от OpenAI
Расширенные функции модерации контента на базе AI
Возможность генерировать и делиться различными формами AI-созданного медиаконтента
Стратегическая цель:
Получение прямого доступа к непрерывному потоку пользовательских данных в реальном времени, включая текст, изображения и поведение при взаимодействии. Эти данные бесценны для дальнейшего обучения и оптимизации AI-моделей OpenAI.
Влияние на рынок:
Потенциальное усиление конкуренции с Meta (Facebook, Instagram) и X
Переосмысление онлайн-взаимодействий с фокусом на генеративный AI
Демонстрационная площадка для передовых AI-технологий OpenAI
Гендир OpenAI Сэм Альтман лично возглавляет эту инициативу и активно запрашивает отзывы у внешних сторон. Пока неясно, будет ли эта социальная сеть запущена как отдельное приложение или интегрирована в существующее приложение ChatGPT.
Google представила DolphinGemma — фундаментальную AI-модель для изучения коммуникации дельфинов! 🐬
Основная цель проекта:
Расшифровка коммуникации дельфинов путем изучения закономерностей в их сложных вокализациях для потенциального межвидового диалога.
Ключевые особенности:
AI-модель с примерно 400 миллионами параметров
Функционирует как система “аудио на вход, аудио на выход”
Использует токенизатор SoundStream от Google
Достаточно эффективна для работы на смартфонах Google Pixel в полевых условиях
Будет выпущена как открытая модель летом 2025 года
Проект основан на многолетнем исследовании Wild Dolphin Project, изучающего диких пятнистых дельфинов в Багамах с 1985 года. Обширная база данных подводного видео и аудио, сопоставленных с идентификационными данными отдельных дельфинов, их историями жизни и наблюдаемым поведением, предоставила богатый материал для обучения DolphinGemma.
Исследователи также изучают потенциал двустороннего взаимодействия с использованием системы CHAT (Cetacean Hearing Augmentation Telemetry), связывая синтетические свистки с объектами для создания общего словаря.
Значение проекта:
Прорыв в понимании коммуникации дельфинов
Потенциальное создание “словаря” дельфиньего языка
Помощь природоохранным усилиям через выявление сигналов бедствия
Развитие теорий о естественном возникновении языка

В небольшом городе в Кентукки провели новаторский эксперимент по применению AI для создания 25-летнего плана развития! 🏙️
Процесс:
Жители предлагали свои идеи через специальную онлайн-платформу
Проводилось голосование за наиболее ценные и значимые предложения
AI-алгоритм анализировал представленные идеи и выявлял ключевые тенденции
Результаты анализа предоставлялись городским властям для принятия решений
Такой подход позволил не только собрать мнения граждан, но и эффективно обработать их с помощью искусственного интеллекта, выявив скрытые закономерности и приоритеты сообщества.
Инновационное использование AI для анализа отзывов жителей обладает большим потенциалом для применения в других городах, предлагая основанный на данных метод для учета мнения сообщества в долгосрочном планировании.
Неделя с 14 по 20 апреля 2025 показала ключевые тренды в развитии AI:
акцент на улучшенные возможности кодирования и рассуждения в фундаментальных моделях
гибридные подходы к балансировке производительности, стоимости и качества
интеграция AI в практические платформы и инструменты для широкой аудитории
расширение исследований AI в новые области, включая межвидовую коммуникацию
Технологии AI продолжают стремительно эволюционировать, становясь более мощными, эффективными и доступными. Конкуренция между ведущими компаниями стимулирует инновации, а практическое применение AI расширяется на все новые сферы жизни.
А какие новости вас впечатлили больше всего? Пишите в комментариях! 👇🏻
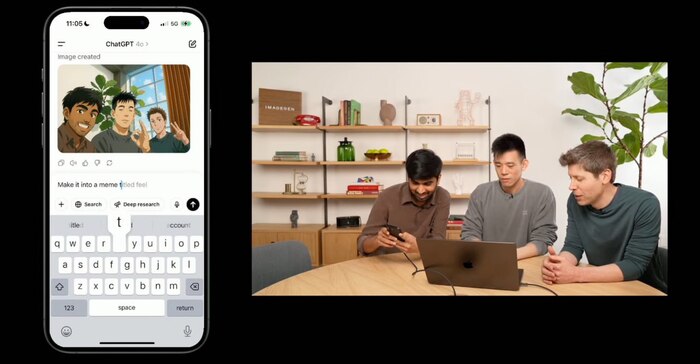
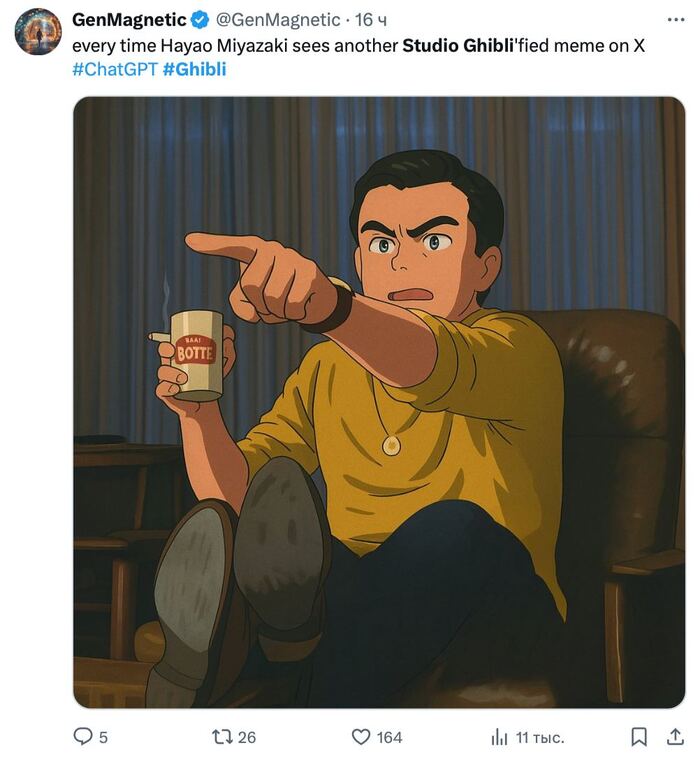

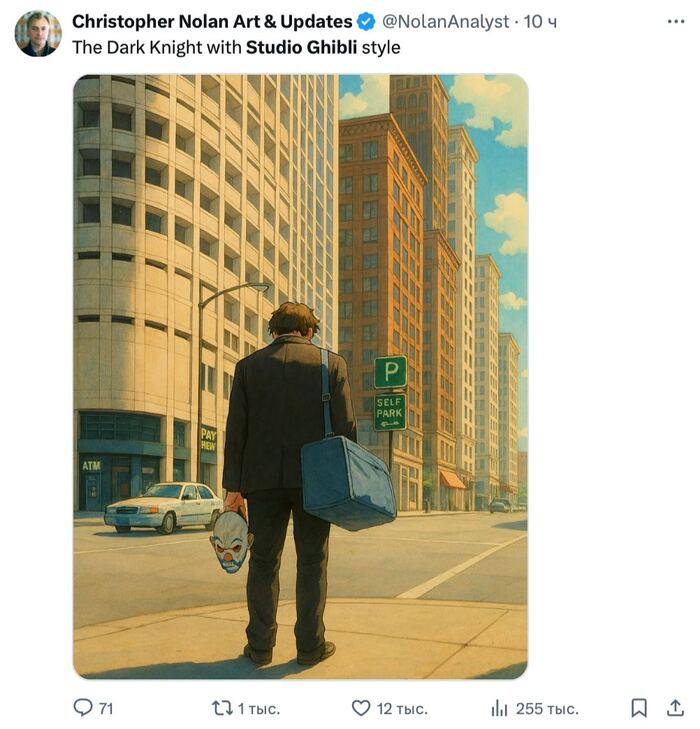












🔥ChatGPT получил мощнейшее обновление для работы с изображениями, и теперь это просто какой-то космос! Посмотрите сами на официальный анонс: https://openai.com/index/introducing-4o-image-generation/
⚡️ Генерировать потрясающие изображения прямо в чате
⚡️ Редактировать картинки с точностью хирурга
⚡️ Создавать безупречный текст на изображениях без единой ошибки
⚡️ Обрабатывать несколько файлов одновременно (наконец-то!)
И знаете что самое смешное? Сэма Альтмана уже успели обвинить в плагиате стиля студии Ghibli: https://variety.com/2025/digital/news/openai-ceo-chatgpt-studio-ghibli-ai-images-1236349141/
Но, как говорится, за последние три года Альтмана не обвинял лишь тот, у кого нет бизнеса связанного с контентом 🌚
А сейчас весь интернет буквально взорвался мемами в стиле Хаяо Миядзаки — это нужно видеть своими глазами! 😂
Хотите сами попробовать создать такую же красоту? Это проще простого:
— Прикрепите любую картинку к чату
— Напишите запрос: «сделай в стиле студии Ghibli»
— Наслаждайтесь результатом!
Но это только верхушка айсберга — вы можете генерировать всё что угодно: от профессиональных постеров до уморительных мемов. Фантазия теперь ваш единственный предел!
Фича уже доступна для всех подписчиков ChatGPT Plus⭐️. Если у вас есть подписка — бегом тестировать!
Обязательно делитесь в комментариях своими шедеврами! Очень интересно посмотреть, что у вас получится 👇
Источник - 🎯 НЕЙРО-ПУШКА ● НОВОСТИ И ОБЗОРЫ НЕЙРОСЕТЕЙ




Появилась крутая нейронка, которая позволяет легко менять освещение всего за пару секунд.
С LBM Relighting можно креативно обработать селфи или скорректировать неудачное освещение.
— Загружаем фотку, можно даже с фоном
— Выбираем освещение и фон из предложенных или грузим свой
— Готово! Получаем единую композицию онлайн.
А главное — бесплатно!
🤗 Тестируем на HuggingFace
Источник - @neuro_pushka🎯
На первом видео — робот Boston Dynamics делает различные движения, от перекатов до брейкданса и сальто.
На втором — Unitree G1 исполняет боковое сальто.
Выглядит мощно 🔥
Источник - 🎯 @neuro_pushka








Новая технология Tight Inversion максимально точно сохранит черты лица, благодаря латентному пространству диффузионных моделей:
— Изменяй лица и портреты без потери узнаваемости
— Генерируй новые версии изображений, сохраняя сходство с оригиналом
— Полностью контролируй творческий процесс
Tight Inversion берёт исходник и пошагово подбирает такой набор параметров, который при генерации максимально близко воспроизводит оригинал.
В результате получается «идеальный слепок» изображения, который можно легко изменять без потери сходства.
🖥 GitHub
👾 НЕЙРО-СОФТ — Делаем нейросети доступнее


