


Красивые AI Анимации
176 постов

176 постов

5 постов

28 постов

160 постов

1 пост

2 поста

17 постов

Всем привет!
Omost, разработанный lllyasviel - это новый веб-интерфейс, который совмещает в себе возможности больших языковых моделей (LLM) и возможности генерации и изображений на SDXL моделях. Иными словами, SDXL и ChatGPT в одном флаконе
Название Omost (произношение: "almost") символизирует:
Каждый раз, когда вы используете Omost, ваше изображение почти готово
"O" означает "omni" (мультимодальный), а "most" означает стремление извлечь максимум из каждого изображения
Суть в том, что используются простые промпты, а языковая модель преобразовывает и распределяет текстовый запрос таким образом, чтобы на выходе получать красивые и необычные генерации. Смесь LLM и SDXL позволяет очень гибко управлять генерацией
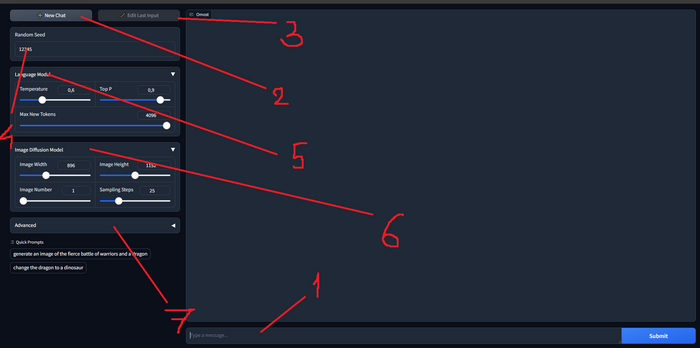
Интерфейс Omost
Интерфейс очень простой и понятный, похож на Fooocus. Большая часть параметров перекочевала из Automatic1111, если вы уже с ним знакомы, то переходите к следующему разделу. Ниже остановимся подробнее
1 — Окно "Prompt"
Основное рабочее пространство
В это окно прописываем текстовый запрос с учётом позиционирования объектов на изображении (например, солнце в правом верхнем углу, силуэт по центру и т.п.)
Далее запрос отправляется в LLM-модель, для получения более сложного промпта
2 — New Chat
Работает подобно созданию нового чата в ChatGPT.
Необходим в случаях, когда нужно уйти от контекста предыдущей генерации.
3 — Edit Last Input - редактирование последнего текстового запроса
4 — Random Seed
Случайный параметр начального шума, из которого будет происходит генерация конечного изображения. Вводится вручную.
Не используйте слишком длинные комбинации цифр, достаточно 4-7 случайных цифр
5 — Окно Language Model
Настройки языковой модели:
Temperature - пришло от ChatGPT, чем больше «temperature», тем более художественный ответ даст ИИ.
Max New Tokens - максимальное количество вводимых токенов
6 — Окно Image Diffusion Model
Image Width - ширина изображения
Image Height - высота изображения
Используйте числа, кратные 64, начиная от 512 (например, 1024x1024, 768x1024 и т.д.)
Image Number - количество итоговых изображений.
Sampling Steps - количество шагов по созданию изображения. Чем их больше, тем дольше нейросеть будет над ней работать.
7 — Вкладка "Advanced"
CFG Scale - величина соответствия текстовому запросу. Для большинства XL-моделей используется от 1 до 5-6.
Настройки для Hi-Res Fix:
HR-Fix Scale - величина апскейла (повышения разрешения), увеличивает время генерации и нагрузку на видеопамять. Рекомендую оставить единицу.
Highres Fix Steps - шаги апскейла
Highres Fix Denoise - мера "новизны" изображения. Чем выше это значение, тем сильнее итоговая картинка будет отличаться от исходной. От 0 до 1.
Negative prompt - негативный запрос, в нём описываем то, чего не должно быть на изображении.
В Omost используется модель RealVisXL 4.0
Давайте поближе взглянем на сам процесс преобразования промпта
Пишем вот такой запрос на входе:
a British Shorthair cat on the center
А вот то, что мы получаем на выходе:
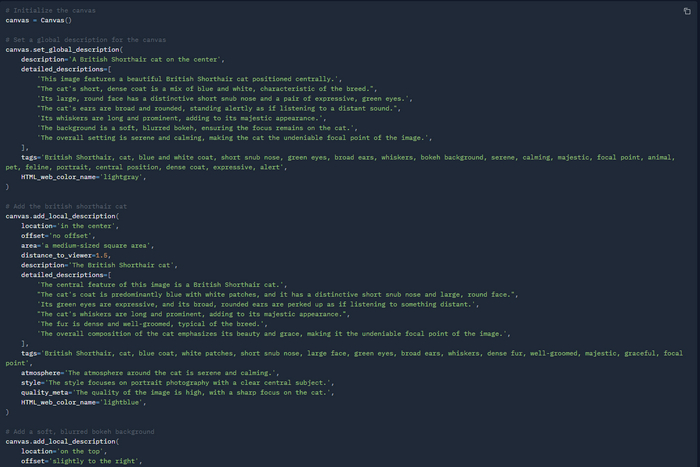
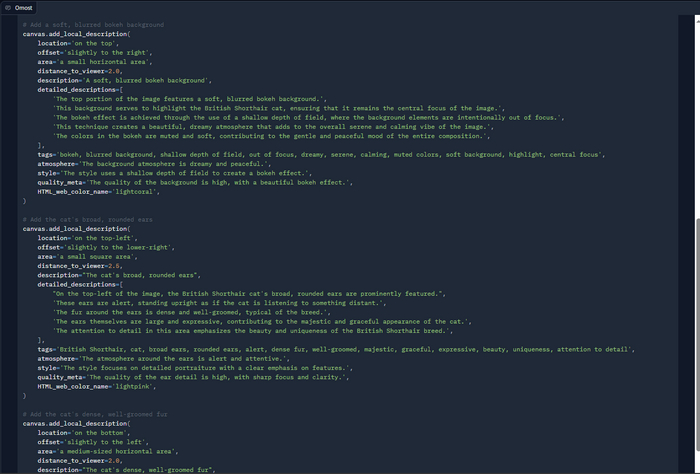
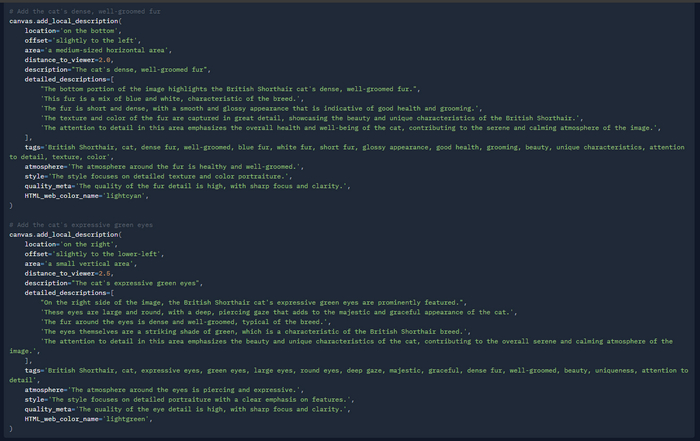
А вот изображение на выходе:

Изображение на выходе с запросом "a British Shorthair cat on the center"
Или давайте совсем просто:
a woman
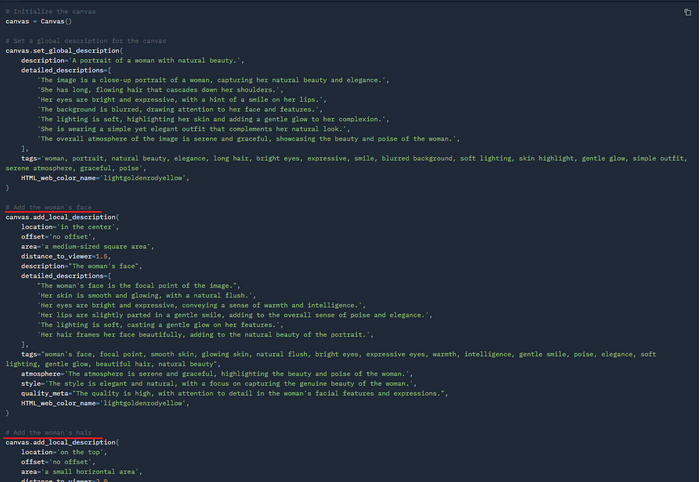

Как видно на скриншотах, можно в мельчайших подробностях задавать параметры позиционирования: от лица, цвета волос и причёски до губ, глаз и одежды. Выглядит всё это очень интересно!

Изображение на выходе с запросом "a woman"
Хочу сгенерировать силуэт девушки на фоне ночного неба. Введём следующий запрос в нижнее окно:
Dark silhouette of a girl in the bottom right, she looks at the starry night sky, standing on a grass field, a forest in the left, fireflies, dark composition
Параметры не меняю
После обработки запроса нажимаем Render the Image!
Получаем следующие результаты:



Omost, к сожалению, не всегда строго придерживается позиционирования
Далее я пишу в чат "поменяй девочку на кошку", жму Render the image и получаю следующее:


Теперь хочу изобразить рыжую девушку в левой части изображения. Сгенерируем следующий запрос:
beautiful woman with short redhair on the left, pale skin, freckles, big green eyes, slim face, green sweatpants, belly button, white socks, lying in her bed,


Ещё один пример
rusalka on the left, aesthetic of street art with knowledge-sharing atmosphere, fog, high depth of field, f/4, framing, groundbreaking breathtaking magnum with precise details, award winning, (Travel Photography by Ashley Gilbertson and George Platt Lynes:0.1), (pastel and bluish-purple colors:0.1),


Придерживайтесь правила: один чат - один сюжет на изображении
Для создания новой композиции нажимаем справа сверху New Chat
На Гите представлены подсказки для позиционирования объектов:
Вы можете задавать расположение объектов согласно сетке
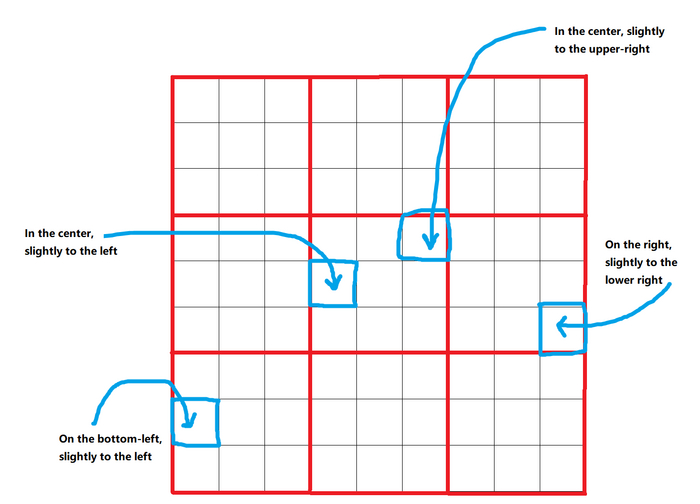
Вы можете задавать расположение объектов согласно сетке

Вы можете задавать расположение объектов согласно сетке
В Omost используется словесное описание позиционирования, а не координатное, потому что "прямое использование координат пикселей или процентных индексов оказалось менее эффективным для LLM"
Так же, если вам нужен точный цвет на изображении, то можно указать его в запросе. На Гите есть слова-триггеры и их HTML-коды. Однако, всё же пока не получается добиться точной цветопередачи
Как итог, Omost - новый экспериментальный инструмент наподобие DALL-E 3, который сочетает в себе мощь LLM- и SDXL моделей
Хочу напомнить, чтобы завести Omost локально, необходима видеокарта как минимум с 8 Гб видеопамяти. Так же он очень требователен к оперативной памяти, съел все мои 16, а я уверен, может и больше
Вы можете попробовать Omost в Demo на Hugging Face
Или скачать портативную версию с установкой в один клик, которая весит всего 1.6 Гб
Перед установкой отключите антивирус, он ругается на самораспаковывающийся архив. Если переживаете, то скачивайте 7z-архив, который нужно просто разархивировать в любое удобное место

Подписывайтесь на 👾Нейро-Софт, канал с портативными версиями ваших любимых нейросетей!

⚡️Сегодня, 12 июня, как и обещали, Stability релизнули Stable Diffusion 3 Medium с двумя миллиардами параметров🔥
🖥 Главное:
· Бесплатна для некоммерческого пользования
· Поддержка модели уже есть в ComfyUI, для Automatic1111 придётся подождать
· Веса уже доступны на Hugging Face
Более того, Stability AI сообщают о сотрудничестве с NVIDIA и AMD
· повышена производительность на всех моделях Stable Diffusion при использовании NVIDIA RTX и TensorRT
Оптимизированные версии TensorRT обеспечат увеличение производительности на 50%
· AMD оптимизировала выполнение SD3 Medium для различных устройств, включая новейшие APU, потребительские GPU и корпоративные GPU MI-300X
О планах на будущее:
Мы планируем постоянно улучшать Stable Diffusion 3 Medium, основываясь на отзывах пользователей, расширять его функции и повышать производительность. Наша цель — установить новый стандарт для творчества в области искусственного интеллекта и сделать Stable Diffusion 3 Medium важным инструментом как для профессионалов, так и для любителей.
Источник - 🎯 Нейро-Пушка







Название: Pony Realism v2.1
Тип модели: #Модель
Количество скачиваний: 30,000+
Дата загрузки: Jun 3, 2024
Базовая модель: Pony
Теги: #BASEMODEL #PHOTOREALISTIC #REALISM #PHOTO #WOMAN #GIRLS
Комментарий разработчика:
В этой версии модель больше склоняется к Pony, обеспечивая большее разнообразие и сохраняя реалистичное качество. Рекомендуется использовать Adetailer для наилучших результатов.
Источник - @neurosklad 🤖 - все, что нужно, для твоей нейронки!
Если понравилось, то поставь плюсик! Другое моё творчество сможешь найти в моём канале ❤️







Мы собрали для вас самые крутые изображения за неделю, созданные сообществом ArtGeneration.me ❤️
Вы можете также! Просто попробуйте начать с этих изображений:
Больше из мира нейросетей в источнике - 🎯 Нейро-Пушка


