Поклоняйтесь, служите, молитесь и будьте рабами только Аллаху, ведь вообще нет у вас никакого другого бога, кроме Него. 7:59
Создание неба и земли, без подозрений, великолепней, чем создание людей. Но много людей не знает. 40:57
Аллах – ваш Господ. Создатель вообще всего. Нет вообще никакого бога, кроме Него. 40:62
Почему вы не верите в Аллаха, что с вами? 57:8
1. Дарвин признавал слабость своей теории (Происхождение видов 6, 10).
2. 97% учëных-биологов считают эволюцию фактом. 80% учëных-биологов боятся говорить о Боге в своих работах из-за цензуры, изоляции, лишения зарплаты. (Ecklund E.H, American Association for the Advancement of Science).
3. Человек появился сразу, внезапно, на территории Африки, без прошлых видов. Как минимум, существуют 72% резких и скачкообразных отличия человека от похожих на него видов (Stringer C., Hunt G. et al).
4. Возможность случайного возникновения жизни на Земле примерно равна 1/10^77. Даже 4 миллиардов лет для этого мало. (Douglas D. Axe, Kocher, C. D., & Dill, K. A).
5. Возможность случайного возникновения жизни на похожей на Землю планете примерно равна 1/10^77, а в известной части вселенной примерно равна 1/10^4. (Ćirković M.M., Sandberg A., Drexler E., Ord T.).
Исследование показывает, что приближенные GKP-состояния, несмотря на шум, могут стать ключевым ресурсом для универсальных квантовых вычислений в системах непрерывных переменных.
Квантовая схема демонстрирует возможность телепортации логических гейтов, открывая путь к распределенным квантовым вычислениям и передаче квантовой информации без физической передачи кубитов.
Работа демонстрирует, что фоковски-демпфированные GKP-состояния позволяют телепортировать как клиффордские, так и неклиффордские гейты, открывая путь к универсальной квантовой вычислительной платформе.
Идеальные состояния ГКП (GKP) требуют бесконечной энергии, что делает их нереализуемыми на практике, а возникающий шум обычно рассматривается как недостаток, требующий исправления. В работе 'Realistic GKP stabilizer states enable universal quantum computation' показано, что несовершенные, нормализуемые состояния ГКП, напротив, могут быть использованы в качестве ресурса для реализации неклиффордских гейтов с помощью исключительно линейно-оптических элементов. Ключевым результатом является возможность телепортации как клиффордских, так и неклиффордских гейтов посредством гауссовых операций и гомодинных измерений в рамках квантовых вычислений на основе измерений. Открывает ли это путь к созданию практичных и масштабируемых квантовых компьютеров на основе непрерывных переменных?
Понимание через устойчивость: Кодирование с помощью GKP-кодов
Квантовые вычисления, чувствительные к шумам, требуют надежных схем кодирования, превосходящих классическую коррекцию ошибок. Коды Готтсмана-Китаева-Прескилла (GKP) кодируют кубиты в непрерывные степени свободы, потенциально обеспечивая большую устойчивость к ошибкам, чем дискретные коды. Даже приближения GKP, такие как Фокк-затухающие состояния, позволяют осуществлять универсальные квантовые вычисления, демонстрируя устойчивость даже при несовершенстве исходных состояний.
Гауссовы операции служат универсальным набором инструментов для манипулирования квантовыми состояниями непрерывных переменных (CV), обеспечивая широкий спектр преобразований. Для универсальных квантовых вычислений необходимы не-гауссовы операции, но даже с использованием приближений, таких как затухающие состояния GKP, универсальность достижима. Приближенные состояния GKP снижают требования к точности экспериментальной реализации, открывая возможности для создания устойчивых и масштабируемых квантовых устройств.
Квантовые вычисления на основе измерений с CV-состояниями
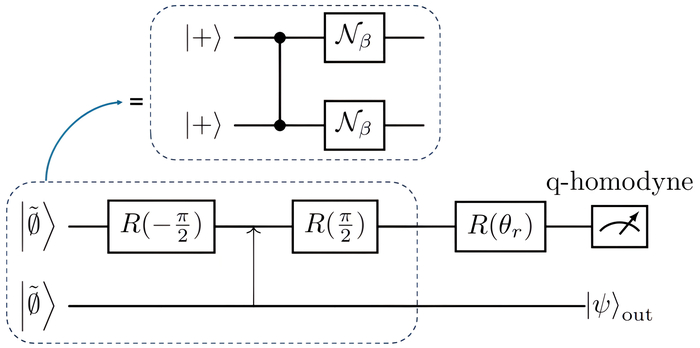
Квантовые вычисления на основе измерений (MBQC) – мощный подход к реализации квантовых алгоритмов, использующий запутанные ресурсные состояния. В качестве ресурсного состояния часто используются кластерные состояния. Необходимыми инструментами для реализации MBQC являются балансировочные лучеделители, фазовые сдвигатели и Q-гомодинное измерение, а математический аппарат функций Якоби играет ключевую роль в описании и манипулировании этими сложными состояниями.
Универсальность и роль магических состояний
Для достижения универсальных квантовых вычислений необходимы неклиффордовские гейты, требующие создания "магических состояний" – нестабилизированных квантовых состояний. Важным этапом является преобразование непрерывных квантовых переменных в дискретные кубиты. Интеграция кодов ГКП, MBQC и магических состояний представляет перспективный путь к отказоустойчивым универсальным квантовым вычислениям, демонстрируя реализацию как клиффордовских, так и непаулевских гейтов посредством телепортации с использованием рациональных параметров.
Исследование, представленное в данной работе, демонстрирует, что даже приближенные состояния ГКП, подверженные затуханию Фока, способны служить ценным ресурсом для универсальных квантовых вычислений. Этот подход позволяет телепортировать как клиффордовские, так и неклиффордовские гейты в системах непрерывных переменных. Данное открытие перекликается с мыслями Луи де Бройля: “Всякое явление можно рассматривать как распространение волны, а каждую волну — как скопление частиц.” Именно способность рассматривать приближенные состояния не как источник шума, а как проявление волновой природы квантовой информации, позволяет расширить границы возможностей квантовых вычислений и реализовать универсальные операции, опираясь на принципы, сформулированные пионером волновой механики.
Что дальше?
Представленные в данной работе результаты, безусловно, сдвигают парадигму восприятия состояний ГКП. Долгое время рассматриваемые как источник шума из-за неизбежных отклонений от идеальной формы, они теперь предстают ресурсом, необходимым для реализации универсальных квантовых вычислений в непрерывной области. Однако, следует признать, что истинное понимание требует дальнейшего исследования. Вопрос о влиянии различных видов затухания Фока, помимо рассмотренных, остаётся открытым. Необходимо тщательно изучить, как эти отклонения сказываются на точности телепортации неклиффордских гейтов, и какие методы коррекции позволят минимизировать возникающие ошибки.
Интересно, что дальнейшие исследования могут быть направлены на поиск оптимальных стратегий создания и поддержания состояний ГКП, учитывая реальные ограничения существующих квантовых устройств. Эффективное масштабирование системы, сохраняя при этом когерентность состояний, представляется сложной, но разрешимой задачей. Понимание пределов устойчивости состояний к различным типам декогеренции позволит разработать более надёжные архитектуры квантовых компьютеров.
В конечном счёте, данная работа заставляет задуматься о природе квантовых ресурсов. Вместо поиска идеальных состояний, возможно, стоит сосредоточиться на эффективном использовании тех, что доступны, даже если они не соответствуют теоретическим идеалам. Ведь именно в несовершенстве часто кроется ключ к новым возможностям.
Новый подход к идентификации потенциальных тёмных звёзд, использующий возможности машинного обучения и огромные объёмы данных, полученных космическим телескопом Джеймса Уэбба.
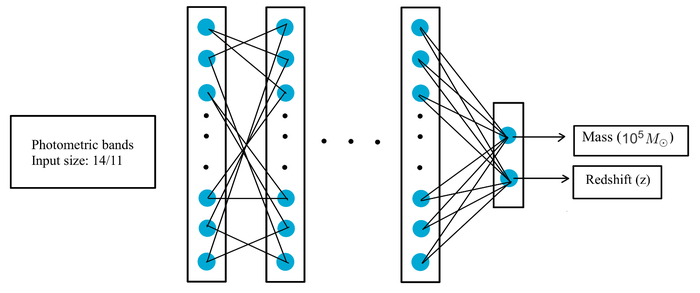
Сеть прямого распространения, обученная на 11 или 14 фотометрических диапазонах наблюдений JWST/NIRCam, позволяет оценить массу звезды (в единицах 10⁵ солнечных масс) и красное смещение, раскрывая различные сценарии формирования структур, учитывая как адиабатическое сжатие, так и захват SMDS.
В данной работе представлен метод, основанный на использовании полносвязных нейронных сетей для выявления кандидатов в тёмные звёзды по данным JWST, что позволяет эффективно анализировать большие объемы данных и расширять наше понимание ранней Вселенной.
Поиск первых звезд во Вселенной осложняется необходимостью анализа огромных объемов фотометрических данных, полученных современными телескопами. В статье 'Neural Network identification of Dark Star Candidates. I. Photometry' представлен новый подход к идентификации кандидатов в так называемые "темные звезды" – гипотетические объекты, питаемые аннигиляцией частиц темной материи. Разработанная нейронная сеть позволила не только подтвердить ранее известные кандидаты, но и обнаружить шесть новых, в диапазоне красного смещения отот z∼9 до z∼14, при этом продемонстрировав значительно более высокую скорость работы по сравнению с традиционными методами. Способны ли подобные алгоритмы существенно расширить наши знания о ранней Вселенной и процессах формирования первых сверхмассивных объектов?
Эхо Ранней Вселенной: Гипотеза Тёмных Звёзд
Современные модели формирования галактик испытывают трудности в объяснении наблюдаемой светимости на ранних этапах развития Вселенной. Гипотеза «Тёмных Звёзд» предлагает альтернативный источник энергии – аннигиляцию тёмной материи внутри массивных звёзд. Эти гипотетические звёзды, питаемые аннигиляцией тёмной материи, могли быть первыми светящимися объектами. Их идентификация требует зондирования глубин ранней Вселенной и разработки новых методов обнаружения.
Раскрывая Невидимое с Помощью JWST
Телескоп Джеймса Уэбба, в частности прибор NIRCam, собирает фотометрические данные от далеких галактик, предоставляя ключевые наблюдательные ограничения для теоретических моделей. Программа JADES разработана специально для идентификации и характеристики галактик с высоким красным смещением. Анализ данных требует надежных методов для различения кандидатов в "темные звезды" от обычных звездных популяций. Огромный объем данных обуславливает необходимость применения передовых методов машинного обучения для эффективной обработки и анализа.
Машинное Обучение для Первого Света
Для прогнозирования звездной массы и красного смещения использована прямосвязная нейронная сеть, позволяющая эффективно анализировать большое количество галактик и выявлять объекты, чьи свойства соответствуют характеристикам темных звезд. Прогнозы сети основаны на уникальных спектральных сигнатурах, ожидаемых от звезд, питаемых аннигиляцией темной материи, демонстрируя высокую предсказательную способность. Для оценки неопределенности в прогнозах применена байесовская нейронная сеть, позволяющая получить не только точечные оценки, но и оценить их распределение вероятностей.
Проверка Модели: Статистическая Строгость и Перспективы
Разработанная нейронная сеть позволила ускорить анализ в 10⁴ раз по сравнению с алгоритмом Nelder-Mead благодаря способности эффективно классифицировать кандидатов в "Темные Звезды". Результаты χ²-теста подтвердили высокую точность модели в идентификации потенциальных кандидатов, демонстрируя ее способность различать объекты, соответствующие теоретическим критериям. Полученные результаты позволяют предположить, что "Темные Звезды" могли сыграть важную роль в процессе реионизации Вселенной. Дальнейшие исследования будут направлены на усовершенствование модели и расширение поиска. Любая модель – лишь эхо наблюдаемого, а за горизонтом событий всё уходит в темноту.
Исследование, представленное в статье, демонстрирует элегантную простоту подхода к выявлению кандидатов в объекты «тёмные звёзды» посредством нейронных сетей. Этот метод, позволяющий обрабатывать огромные массивы фотометрических данных, полученных с телескопа JWST, напоминает о хрупкости любой модели, которую строит человеческий разум. Как однажды заметил Григорий Перельман: «Математика — это всего лишь язык, и если этот язык не позволяет выразить истину, то его нужно менять». Подобно тому, как нейронная сеть обучается на данных, любая научная теория формируется на основе наблюдений, и её точность зависит от качества этих данных и адекватности используемого языка описания. Данная работа, анализируя свет далёких галактик, стремится приблизиться к пониманию фундаментальных процессов, происходивших в ранней Вселенной, и эта попытка, как и любое математическое построение, подвержена ограничениям и требует постоянной проверки.
Что впереди?
Представленная работа, демонстрируя возможности нейронных сетей в идентификации кандидатов в тёмные звёзды, лишь приоткрывает завесу над сложностью ранней Вселенной. Однако, необходимо помнить: алгоритм, каким бы изящным он ни был, – это всего лишь отражение наших предположений о физике этих объектов. Нахождение кандидатов – это лишь первый шаг; подтверждение их природы потребует детального спектроскопического анализа, а это – задача, сопряжённая с огромными трудностями и, возможно, разочарованиями. Ведь не исключено, что «тёмные звёзды», столь привлекательные для теоретиков, окажутся лишь иллюзией, порождённой несовершенством наших инструментов и моделей.
Следующим этапом представляется не просто увеличение объёма обрабатываемых данных, но и разработка более сложных архитектур нейронных сетей, способных учитывать не только фотометрические характеристики, но и другие параметры, такие как пространственное распределение объектов и их эволюцию во времени. При этом, важно не забывать о фундаментальной проблеме: как отличить истинную «тёмную звезду» от иного экзотического объекта, который может проявлять схожие признаки? Вселенная щедро показывает свои тайны тем, кто готов смириться с тем, что не всё объяснимо.
В конечном счёте, поиск «тёмных звёзд» – это не просто астрономическая задача, но и проверка нашей способности к построению адекватных моделей Вселенной. Чёрные дыры — это природные комментарии к нашей гордыне. И чем глубже мы погружаемся в изучение этих загадочных объектов, тем яснее осознаём границы нашего знания и хрупкость наших убеждений.
Мы привыкли считать квантовый мир фундаментом реальности. Мол, это самый нижний этаж, а дальше только пустота.
Но честнее будет сказать иначе! Квантовый слой выглядит не как фундамент, а как хаос, в котором всё постоянно вибрирует, пересобирается и меняется. Не частицы, а вспышки возможностей. Не материя, а недоформированная среда.
И вот та картина, которую я вижу!
Первичная вселенная, как ультра-хаос!
Представь реальность, где даже квантовый беспорядок кажется стабильным по сравнению с тем, что там происходило. Состояния не удерживались ни на мгновение. Рождались всплески, сразу же рушились. Никаких свойств, никаких законов, а только поток нестабильности.
Со временем в этой среде начали формироваться первые зачатки структуры, что-то вроде пред-квантовых элементов. Ещё не частицы, но уже не чистый хаос.
Рождение квантовых зачатков
Эти зачатки были максимально «сырыми». Они не имели фиксированных свойств, ни масс, ни зарядов, ни констант.
Самый точный образ - это стволовые клетки. Потенциал есть, но формы ещё нет.
Попадание в нашу вселенную
Когда эти зачатки оказались в новой среде. В нашей зарождающейся вселенной , где они попали в условия, где могли постепенно закрепляться.
И вот тут начинается самое интересное.
Квантовый мир как «стволовой материал»
Квантовые зачатки начали «созревать». Окружающее пространство стабилизировалось, температура падала, взаимодействия выравнивались и эти дрожащие фрагменты начали получать форму.
один тип стабилизировался в заряд,
другой в массу,
третий во взаимодействие,
а система в целом в набор констант.
Так из хаоса выросла физика.
Колебания никуда не исчезли! Просто стали более организованными. И именно из этих узоров мы видим картинку мира.
Как колебания рисуют реальность
Если упростить:
квантовые колебания дают видимую картину мира,
более плотные и собранные колебания дают ощущаемую материю,
а на уровне галактик - это те же колебания, только гигантского масштаба.
И вот из этого вытекает любопытный поворот.
Наши галактики со своими вращениями, гравитационными волнами, кластерными движениями могут быть штрихами более крупного узора! Мы видим «космос», а на следующем уровне это может быть структура для другой реальности, так же как наши атомы структура для нас.
Я не утверждаем, что так и есть. Просто следуя логике, если всё колебания, то и наша вселенная может быть узором более глубокого уровня, другой вселенной и т.д.
Формирование крупного мира
Когда квантовый материал стал хоть немного предсказуемым, всё вышло на рельсы:
атомы
молекулы
звёзды
галактики
жизнь
разум
Мы выросли из медленно стабилизирующегося хаоса.
Итог
В этой модели квантовый мир не основа и не бог из машины. Это продукт более древнего, ещё более хаотичного состояния, который стал “строительным материалом” для нашей вселенной.
То, что в первичной реальности было финалом упорядочения хаоса, у нас стало точкой старта. А наши галактики возможно, всего лишь крупные волны на поверхности ещё более глубокого океана.
Чем моя теория отличается от теории струн
Моя модель не про геометрию струн и не про дополнительные измерения. Я смотрю в другую сторону! Квантовый уровень не фундаментален, а унаследован от более хаотичного предыдущего мира.
Струнная теория такого не предлагает. Там фундамент - это сами струны, без прошлых вселенных и “стволового” материала.
Теория струн пытается быть физикой. Её цель - математическая модель Вселенной. Моя модель - космогония. Попытка объяснить происхождение уровней реальности и их связь.
Иногда мы смотрим на устройство мира слишком прямо: есть Большой взрыв, есть физика, есть звёзды, планеты, жизнь, мозг. Всё развивается внутри одной единственной «реальности».
Но что если рамку можно расширить? Не в сторону мистики, а в сторону другой, более глубокой картины.
Я давно кручу в голове мысль! Что если квантовый мир может быть не самым нижним уровнем реальности, а промежуточным интерфейсом между нашей Вселенной и чем-то более фундаментальным.
Квантовая механика странная штука. Она показывает, что на самом глубоком уровне реальность построена не из «вещей», а из вариантов.
Суперпозиции, вероятности, запутанность всё это напоминает не готовую структуру, а поле возможностей, из которого потом «выбирается» устойчивый вариант.
И тут возникает вопрос! Почему именно этот набор возможностей определяет физику нашего мира?
Можно представить, что в первые моменты существования Вселенная была огромным набором квантовых комбинаций. И постепенно закреплялись только те конфигурации, которые:
не разваливались,
могли взаимодействовать,
позволяли формироваться структурам.
Так «отобрались» стабильные частицы, взаимодействия, атомы, возможность образования звёзд и галактик. Как будто Вселенная сама выбирала устойчивые паттерны.
Допускаю такую модель, чтоквантовый мир - это интерфейс, через который более глубокая реальность формирует физические структуры.
В той первичной реальности могут отсутствовать:
пространство и время,
энергия,
масса,
причинность.
Она может жить по принципам, которые вообще не похожи на нашу математику и физику. А квантовый уровень её способ проявиться в виде стабильных Вселенных.
Исследование потенциала больших языковых моделей для прямой компиляции кода без традиционных этапов обработки.
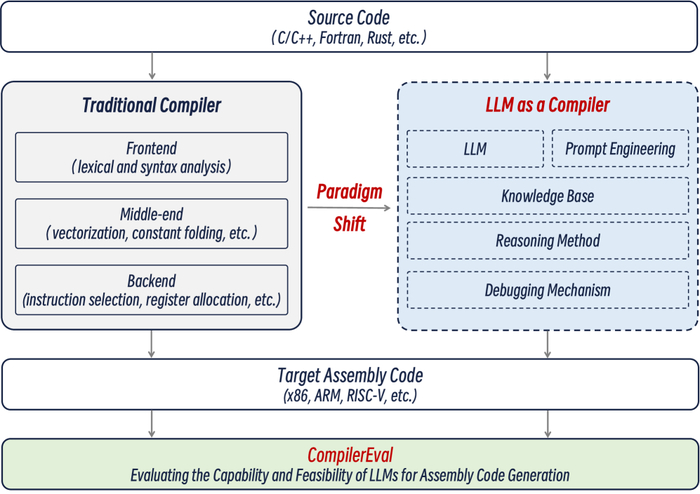
Традиционная парадигма компиляции претерпевает сдвиг, уступая место языковым моделям как новым компиляторам, чьи возможности валидируются посредством комплексного набора данных и фреймворка CompilerEval.
В статье рассматривается возможность использования больших языковых моделей для end-to-end компиляции, включая генерацию ассемблерного кода и кросс-платформенную поддержку, с анализом результатов на наборе данных CompilerEval.
Несмотря на значительные успехи в различных областях, возможность использования больших языковых моделей (LLM) в качестве полноценных компиляторов оставалась малоизученной. Данная работа, 'Exploring the Feasibility of End-to-End Large Language Model as a Compiler', посвящена исследованию потенциала LLM для прямой трансляции исходного кода в машинный, с акцентом на разработку датасета CompilerEval и фреймворка LaaC. Эксперименты показали, что LLM демонстрируют базовые способности к компиляции, однако текущий процент успешной компиляции остается низким. Возможно ли, путем оптимизации запросов, масштабирования моделей и внедрения методов рассуждения, создать LLM, способные генерировать высококачественный ассемблерный код и изменить парадигму компиляции?
Эволюция Компиляции: От Надежности к Гибкости
Традиционная компиляция, несмотря на свою надежность, представляет собой сложный и ресурсоемкий процесс. Растущий спрос на кроссплатформенность и поддержку специализированного оборудования требует адаптивных решений. Технологии искусственного интеллекта, в частности, большие языковые модели (LLM), предлагают принципиально новый подход к компиляции, способный упростить и ускорить разработку. Прозрачность алгоритмов – ключ к безопасному и эффективному программному обеспечению.
Исследование демонстрирует влияние методов промпт-инжиниринга, масштаба модели и методов рассуждения на успешность компиляции с использованием больших языковых моделей.
Возможность сквозной компиляции с использованием LLM демонстрирует потенциал для упрощения процесса разработки.
LLM как Компилятор: Новый Парадигма
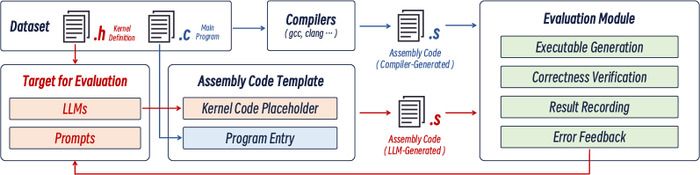
Предлагаемый подход основан на непосредственном преобразовании исходного кода в машинный язык с использованием больших языковых моделей (LLM), минуя традиционные этапы компиляции. Разработанная платформа LaaC (LLM as a Compiler) является развитием данной идеи, ключевым компонентом которой является база знаний, содержащая информацию об исходных языках и наборах инструкций целевых архитектур. Несмотря на перспективность, текущие показатели успешной компиляции остаются относительно невысокими.
Анализ результатов, полученных для основных больших языковых моделей на наборе данных CompilerEval, выявляет общие тенденции и различия в их производительности.
Успешная реализация требует решения сложной задачи генерации целевого кода, оптимизированного для конкретных архитектур.
CompilerEval: Строгий Анализ Возможностей LLM
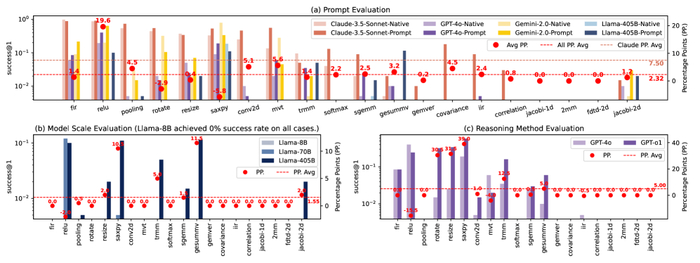
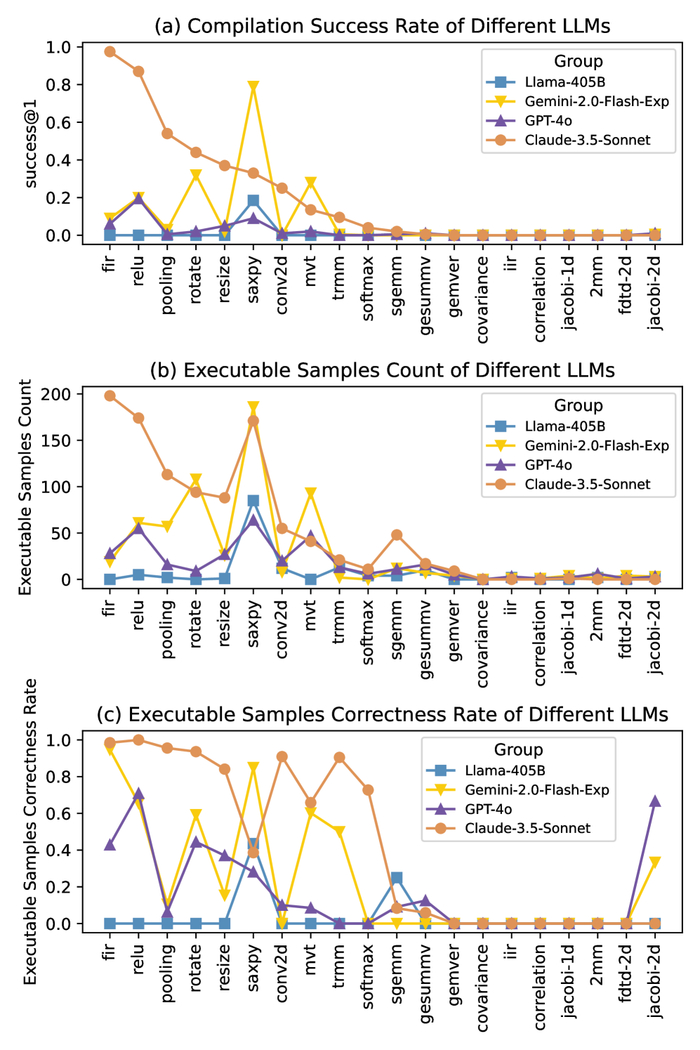
Для систематической оценки возможностей больших языковых моделей (LLM) в генерации ассемблерного кода разработана платформа CompilerEval, использующая специализированный набор данных CompilerEval Dataset. В рамках исследования была проведена оценка коэффициента успешной компиляции (Compilation Success Rate) для LLM, включая GPT-4o, Gemini-2.0, Claude-3.5 и Llama-3, на различных аппаратных архитектурах. Результаты демонстрируют зависимость эффективности от архитектуры и используемой модели.
Представленная структура CompilerEval обеспечивает комплексную платформу для оценки и сравнения различных методов компиляции, основанных на больших языковых моделях.
Применение методов оптимизации запросов (Prompt Engineering) позволило улучшить показатели успешной компиляции. Так, для Claude-3.5-Sonnet наблюдалось увеличение на 7,5%, для GPT-4o с применением Chain-of-Thought – на 5%, а масштабирование Llama с Llama-70B до Llama-405B дало прирост в 1,55%.
Кроссплатформенность и Перспективы Будущего
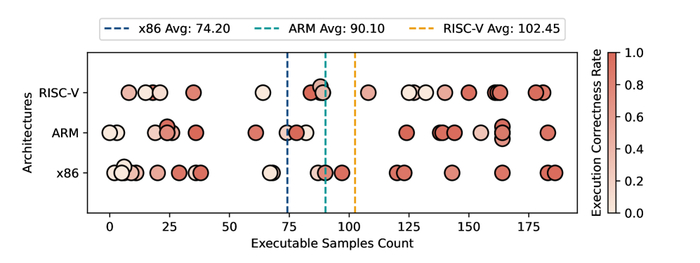
Оценка продемонстрировала потенциал LLM для генерации кода для различных архитектур (x86, ARM, RISC-V), обеспечивая кроссплатформенную совместимость и автоматизацию разработки. Генерируемый код показал более высокие показатели корректности для ARM и RISC-V по сравнению с x86, что может быть связано с более стандартизированной природой этих архитектур.
Оценка производительности Claude-3.5-Sonnet при генерации кросс-платформенного ассемблерного кода демонстрирует его возможности в данной области.
Дальнейшие исследования могут быть сосредоточены на оптимизации LLM и масштабировании для обработки сложных кодовых баз. Комбинация AI-управляемой компиляции с традиционными методами обещает будущее оптимизированной разработки. Каждая строка кода, созданная машиной, – это попытка расшифровать правила, лежащие в основе цифрового мира.
Исследование демонстрирует, что большие языковые модели могут выступать в роли компиляторов, генерируя ассемблерный код непосредственно из высокоуровневых инструкций. Однако, успешность компиляции остаётся переменной величиной, требующей дальнейшей оптимизации и проработки. Это напоминает о высказывании Грейс Хоппер: “Лучший способ предсказать будущее — это создать его.”. В контексте LaaC Framework и необходимости повышения точности и эффективности компиляции, данная фраза подчеркивает активную роль исследователей в формировании будущего компиляционных технологий. Вместо пассивного ожидания прогресса, необходимо создавать инструменты и методы, способные преодолеть текущие ограничения и обеспечить надежную кросс-платформенную поддержку.
Что дальше?
Представленная работа демонстрирует, что границы между языковыми моделями и компиляторами становятся всё более размытыми. Однако, воспринимать это как немедленную замену традиционным системам было бы наивно. Достигнутые результаты – скорее, намек на возможность, чем окончательное решение. Ключевым вызовом остаётся не только повышение процента успешной компиляции, но и обеспечение предсказуемости, эффективности генерируемого кода и, что немаловажно, его переносимости между различными платформами. Необходимо признать, что текущие модели, по сути, "угадывают" компиляцию, а не выполняют её на основе строгой логики.
Дальнейшие исследования должны быть направлены на разработку более надёжных методов оценки и верификации сгенерированного кода, а также на создание инструментов для "отладки" логики языковых моделей, используемых в качестве компиляторов. Интересным направлением представляется изучение возможности интеграции существующих компиляционных технологий с LLM, создавая гибридные системы, сочетающие в себе сильные стороны обоих подходов. Ведь хаос — не враг, а зеркало архитектуры, которое отражает скрытые связи.
В конечном счёте, успех этого направления зависит от способности выйти за рамки простого "перевода" кода и создать системы, способные к оптимизации и адаптации к специфическим требованиям целевой платформы. Это потребует не только улучшения алгоритмов обучения языковых моделей, но и глубокого понимания принципов работы компиляторов и архитектуры вычислительных систем.