1. Определение Целевой Аудитории: Ключевой Элемент При Выборе Названия YouTube Канала
- Анализ Конкурентов:
Изучите каналы с похожей тематикой и аудиторией. Обратите внимание на их названия и то, как они связаны с контентом, который они предлагают. Это может дать вам идеи и помочь избежать повторения уже используемых названий.
- Привязка к Контенту:
Ваше название должно отражать тип контента, который вы будете создавать. Если вы планируете вести образовательный канал, название должно это подчеркивать. Если ваш канал о кулинарии, название должно намекать на это.
- Культурные Особенности:
Если ваша аудитория принадлежит к определенной культуре или региону, учитывайте это при выборе названия. Избегайте слов и выражений, которые могут быть непонятны или оскорбительны для культурных особенностей вашей аудитории.
Помните, что название вашего канала — это первое, что видят потенциальные подписчики. Оно должно мгновенно сообщать им о ценности вашего контента и причинах подписаться именно на вас.
2. Уникальность и запоминаемость: Создание Эффективного Названия для Вашего YouTube Канала
Выбор названия для YouTube канала — это не просто творческий процесс, но и стратегический шаг, который требует продуманного подхода. Вот ключевые моменты, которые помогут сделать ваше название уникальным и запоминающимся:
- Исключительность:
Название должно быть уникальным, чтобы отличаться от множества других каналов. Используйте оригинальные слова или сочетания, которые могут ассоциироваться только с вашим контентом.
- Простота:
Сложные или слишком длинные названия трудно запомнить. Стремитесь к краткости и простоте, чтобы зрители могли легко вспомнить ваш канал и рекомендовать его другим.
- Звучность:
Название должно легко произноситься и звучать приятно. Это облегчит его распространение через устный маркетинг.
- Легкость написания:
Если название вашего канала легко написать после того как его услышали, вероятность того, что зрители найдут ваш канал в поиске, значительно увеличивается.
- Ассоциативность:
Выбранное название yotobe должно вызывать у аудитории правильные ассоциации и эмоции, соответствующие вашему контенту и бренду.
- Визуальная привлекательность:
Подумайте о том, как название будет выглядеть визуально, в том числе в логотипе или в виде текста на превью видео. Оно должно быть привлекательным в любом контексте.
- Проверка Доступности:
Убедитесь, что выбранное название не занято и не защищено авторскими правами. Проверьте доступность в социальных сетях и доменные имена, чтобы обеспечить консистентность бренда в интернете.
Работая над названием вашего YouTube канала, помните, что оно служит не только идентификатором вашего контента, но и мощным инструментом маркетинга, способным привлечь новую аудиторию и сделать ваш бренд узнаваемым.
4. Брендинг и визуальная связь: стратегии для названия YouTube канала
Название вашего YouTube канала является важной частью вашего бренда и должно быть тесно связано с вашим визуальным образом и общей тематикой контента. Вот несколько стратегий, которые помогут убедиться, что ваше название укрепляет ваш бренд и создает сильную визуальную связь с аудиторией:
- Соответствие Бренду:
Название должно отражать тональность и ценности вашего бренда. Если ваш бренд стремится к профессионализму, название должно быть соответствующим образом серьезным и уважительным. Для более неформального бренда подойдет более игривое и творческое название.
- Визуальное Впечатление:
Подумайте о том, как название будет взаимодействовать с логотипом и другими визуальными элементами, такими как цветовая схема и шрифты. Название должно быть легко воспринимаемым и узнаваемым в различных визуальных контекстах.
- Тематическая Согласованность:
Убедитесь, что ваше название соответствует тематике канала. Например, если канал посвящен путешествиям, название должно это отражать и вызывать соответствующие ассоциации.
- Гибкость для Развития:
Ваше название должно быть достаточно гибким, чтобы позволить вашему каналу расти и развиваться. Избегайте слишком узкоспециализированных названий, которые могут ограничить вас в будущем.
- Конкурентное Преимущество:
Подумайте о том, как ваше название может выделить вас среди конкурентов. Название, которое ясно демонстрирует уникальное предложение вашего канала, может стать вашим конкурентным преимуществом.
- Проверка Названия:
Перед окончательным выбором проведите исследование, чтобы убедиться, что название не используется другими брендами и что оно не имеет нежелательных ассоциаций в различных культурах и языках.
Тщательно продуманное название канала, которое гармонирует с вашим брендингом и визуальным стилем, не только укрепит вашу брендовую идентичность, но и поможет зрителям лучше запомнить и узнать ваш канал в море других.
5. Гибкость и Масштабируемость: Ключевые Аспекты для Названия YouTube Канала
Выбирая название для вашего YouTube канала, важно учитывать не только текущее положение дел, но и будущие перспективы развития. Вот несколько советов, как обеспечить гибкость и масштабируемость вашего названия:
- Визионерский подход:
Продумайте, как ваш канал может развиваться со временем. Название должно быть достаточно универсальным, чтобы охватывать потенциальное расширение тематик и форматов контента.
- Избегание чрезмерной специфики:
Слишком узкоспециализированные названия могут ограничить вас в будущем. Например, если название канала сильно привязано к определенной технологии или тренду, оно может стать неактуальным, когда тренды изменятся.
- Адаптивность к новым трендам:
Выберите название, которое позволит вам легко адаптироваться к изменениям в интересах аудитории и новым трендам в вашей нише.
- Простота модификации:
Рассмотрите возможность выбора названия, которое можно легко модифицировать или дополнить, если вы решите расширить сферу деятельности канала.
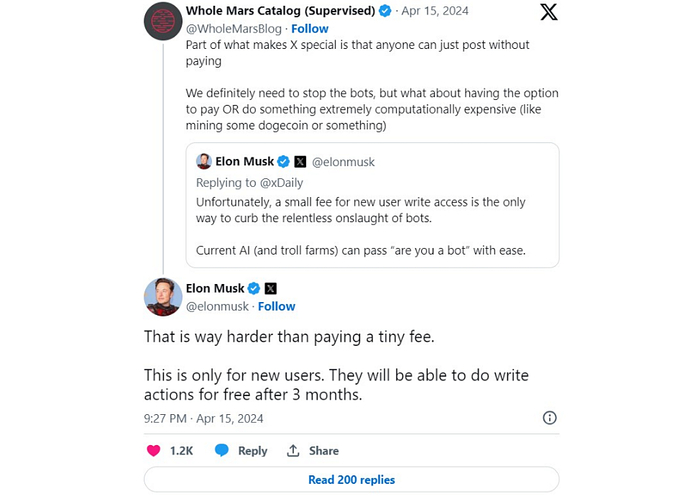
Илон Маск рассказал об очередном нововведении, которое вскоре может стать частью правил использования соцсети X*. Миллиардер намерен взимать небольшую плату с новых пользователей за публикацию постов.
Такое решение, по словам Маска, станет «единственным способом для сдерживания натиска ботов», поскольку инструменты вроде CAPTCHA современные ИИ с лёгкостью обходят. При этом в ответ на вопрос одного из пользователей Илон ответил, что плата будет взиматься не всё время.
Публикации с новых учётных записей станут бесплатными по истечению трёх месяцев с момента их создания. Пока неизвестно, сколько пользователям придётся платить за пост и когда это правило заработает.
Напомним, что в октябре прошлого года для не верифицированных пользователей X* в Новой Зеландии и на Филиппинах была введена комиссия в размере $1 в год за возможность публиковать контент, репостить записи, отвечать, добавлять в закладки и совершать прочие действия.
*Деятельность данной соц сети запрещена в России и признана как экстремистская.
Если вам интересны новости из мира технологий, а также подборка прикольных и интересных изобретений, и гаджетов которые существуют на данный момент то тогда добро пожаловать в сообщество.
А так же оставлю ссылки на другие платформы где тоже много всего интересного:
Взять с собой побольше вкусняшек, запасное колесо и знак аварийной остановки. А что сделать еще — посмотрите в нашем чек-листе. Бонусом — маршруты для отдыха, которые можно проехать даже в плохую погоду.
Кажется, что рекомендательный движок музыкального сервиса - это черный ящик. Берет кучу данных на входе, выплевывает идеальную подборку лично для вас на выходе. В целом это и правда так, но что конкретно делают алгоритмы в недрах музыкальных рекомендаций? Разберем основные подходы и техники, иллюстрируя их конкретными примерами.
Начнем с того, что современные музыкальные сервисы не просто так называются стриминговыми. Одна из их ключевых способностей - это выдавать бесконечный поток (stream) треков. А значит, список рекомендаций должен пополняться новыми композициями и никогда не заканчиваться. Нет, безусловно, собственноручно найти свои любимые песни и слушать их тоже никто не запрещает. Но задача стримингов именно в том, чтобы помочь юзеру не потеряться среди миллионов треков. Ведь прослушать такое количество композиций самостоятельно просто физически нереально!
Так как они это делают?
Если ваши музыкальные алгоритмы не похожи на это, то даже не предлагайте мне скачивать приложение!
Чтобы сделать годную рекомендацию, сервису нужны три сита…
Первое сито - это так называемые рекомендации на основе знаний (knowledge-based). Это значит, что сервис аккумулирует всю доступную информацию об одном пользователе - что он слушает (например, каких артистов или жанр), как часто, что лайкает, что дослушивает, что проматывает дальше и т.д. Учитываются сотни или даже тысячи факторов. Разумеется, собираемые данные анонимны.
После этого сервис делает рекомендацию. Причем она может даваться безотносительно общих предметных знаний сервиса. Например, если мы видим, что Вася добавил в плейлист Metallica “Nothing Else Matters”, то с большой вероятностью ему понравится и “Unforgiven”. Для такого вывода нам не нужна дополнительная информация.
Помимо прочего, рекомендации на основе знаний помогают решить проблему “холодного старта” (это когда свеженький и тепленький юзер только-только зарегался), предлагая новому пользователю тот контент, который соответствует его требованиям с самого начала использования.
Второе сито - коллаборативная фильтрация. Пожалуй, это самый главный прием и краеугольный камень любого стриминга. Хотя коллаборативная фильтрация и может издалека походить на анализ предпочтений пользователей, на самом деле это совсем другая техника и технология - гораздо более продвинутая и математически точная.
Работает она на следующем допущении:
Пользователи, которые одинаково оценили какие-либо композиции в прошлом, склонны давать похожие оценки другим композициям в будущем.
Давайте разберем на примере, очень упрощенно:
Допустим, у Васи затерты до дыр треки:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Scooter “How much is the fish?”
Валерий Леонтьев “Мой дельтаплан”
Какую закономерность можно выявить на основе этого набора? Да никакую. Просто мешанина из разных жанров, артистов и эпох.
Тем не менее, у сервиса также есть пользователь Петя, чей плейлист по удивительному совпадению похож на Васин, а именно:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Dua Lipa “Swan Song’’
Валерий Леонтьев “Мой дельтаплан”
Все треки одинаковые, кроме одного. У Васи это Scooter, у Пети - Dua Lipa.
По логике коллаборативной фильтрации, есть вероятность, что если Вася и Петя “обменяются” этими песнями, то обоим понравится. Поэтому такие рекомендации и называются “коллаборативными” - пользователи как бы сотрудничают, обмениваясь предпочтениями друг с другом.
Коллаборативная фильтрация in a nutshell.
Понятное дело, что коллаборативная фильтрация работает не на двух пользователях, и даже не на двух тысячах. А вот на паре миллионов юзеров, у которых удается найти критическую массу одинаковых композиций - уже вполне. Также очевидно, что я привожу примеры карикатурно непохожих песен “из разных миров”. Я это делаю намеренно, чтобы подчеркнуть, что подход помогает делать рекомендации на основе данных, в которых, казалось бы, не за что зацепиться в поисках общего паттерна. Понятное дело, что в реальности между прослушанными и рекомендуемыми треками скорее всего будет больше схожести.
Так почему этот способ дает хороший результат, когда между наборами треков может не быть ничего общего?
Ну смотрите. Музыкальные предпочтения зависят от целого множества факторов - ваш вкус в целом, ваше настроение сегодня, работаете вы или же чиллите, болит ли у вас голова, с какой ноги вы сегодня встали, что конкретно на завтрак ели и многое-многое другое. Запихивать все эти переменные в строгое правило с четкими “если Х, то У” - дело неблагодарное. А вот если ИИ эмпирически прошерстит огромную выборку и найдет в ней похожие участки, то это совсем другое дело.
Здесь примерно та же логика, по которой если нейросетке скормить кучу картинок с котиками, а потом попросить её нарисовать котика, то она скорее всего изобразит туловище, к которому будут приделаны 4 лапы, хвост, шерсть и мордочка с усами и треугольными ушками. То есть нюансы изображения могут различаться, но основные свойства котика (назовем их “котиковость”) будут переданы. А значит, концептуально результат будет верный.
Так же и с рекомендациями в рамках коллаборативной фильтрации. Разве можно рационально объяснить, почему одна группа любителей Slipknot вдруг слушает песни Димы Билана (наверно, чтобы вкус перебить, такой себе имбирь между разными роллами), а другая группа - Леди Гагу? Вряд ли. Однако, если такие два паттерна существуют, то это значит, что слушающим Леди Гагу металлистам можно попробовать включить Билана, а их визави, наоборот, протолкнуть в поток Poker Face или Alejandro. Ведь точный эмпирический анализ большой выборки попадает в яблочко как минимум очень часто.
Наконец, третье сито, которое отлично дополняет первые два. Это рекомендации на основе контента (content-based). Здесь уже анализируется непосредственно сама композиция. Сервис берет песню, разбивает её на куски, отрезки или даже отдельные “квадраты”, после чего анализирует каждый отдельный элемент звука и ищет песни, технически похожие на анализируемую. Есть вероятность, что если Васе нравится песня Х с определенным звучанием и ритмом, то ему понравится и песня Y с похожими музыкальными свойствами.
Здесь есть важный нюанс. Звучание песни анализирует машина по каким-то техническим критериям, которые понятны ей, машине. А вот мы, люди, можем кайфовать от песни иррационально. Например, не только благодаря ритму мелодии, аранжировке или тембру голоса исполнителя, а еще и благодаря вайбу композиции, а то и символическому капиталу вокруг неё (например, если песня культовая или просто трендовая и модная-молодежная).
Поэтому, content-based рекомендации не всегда дают хороший эффект сами по себе, но служат отличным дополнением других способов фильтрации.
Также, такой способ - рабочий вариант для так называемых “холодных треков”. Это композиции, которые только-только выложили на стриминг. Допустим, новая песня известного исполнителя, либо же неизвестный трек совсем нового певца-ноунейма, которому тоже хочется славы. В таком случае плясать от самой композиции - полезное умение. Ведь трека еще нет в плейлистах тысяч и миллионов пользователей, а значит, порекомендовать его с помощью коллаборативной фильтрации или через knowledge-based вряд ли получится.
Резюмирую принципы рекомендательных движков музыкальных стримингов с помощью классического мема.
Итак, мы разобрали три основных техники, с помощью которых стриминги рекомендуют звуковой контент нашим ушкам. Разумеется, современные продвинутые сервисы обычно используют их все (получаются “гибридные рекомендации”), прикручивая к каждому из них свои авторские фишки.
Как конкретно это работает. Разбираю на примере гибридного подхода Яндекс Музыки
Теперь предлагаю показать на практике, как конкретно описанные выше техники работают. Для иллюстрации я буду использовать пример Яндекс Музыки. Потому что сам давно пользуюсь этим сервисом (думаю, уже лет 10), а также по той причине, что недавно у них прошло большое обновление алгоритма, которое внесло важные изменения в механизм рекомендаций. Ну и еще потому что всегда приятнее разбирать глобальные лучшие практики на отечественном сервисе, который в полной мере им соответствует.
Итак:
Базово рекомендательный движок Яндекс Музыки реализован через Мою волну, которая появилась на главной странице сервиса пару-тройку лет назад. По умолчанию этот поток сбалансированный - это значит, что он комбинирует любимые и привычные треки (которые пользователь и так активно слушает) с новыми композициями, причем в комфортной пропорции. По своему опыту скажу, что микс между добавленными и новыми треками по умолчанию примерно 50:50. При этом 30-40% новых я лайкаю, чтобы сохранить к себе. За счет этого алгоритм дообучается и адаптируется.
Однако Мою волну можно дополнительно кастомизировать через настройки. Нажимаем кнопку под плеером и проваливаемся вот в такое меню.
Как видим, параметров кастомизации вроде бы немного, но при этом изменения могут быть весьма существенными. К тому же, из скриншота видно, что настройки потока можно включать и отключать в разных комбинациях. Используя свои знания наивысшей математики, я перемножил 5 (Занятия) на 3 (Характер) на 4 (Настроение) и на 3 (Языки) и получил примерно 180. Ну ладно, пришлось использовать калькулятор, подловили…
Так что, внутри одной Моей волны на самом деле сидят очень много разных Моих волн.
Остановимся детальнее на настройке под названием “Характер”. Можно попросить движок делать больше акцента на моих залайканных треках (“Любимое”), или же наоборот чуть абстрагироваться от знаний о пользователе и поддаться общим трендам (“Популярное”).
Но поскольку статья все же о рекомендательном функционале, то остановимся подробнее на настройке “Незнакомое”. Ведь именно глядя на способность подбирать релевантные треки из всего внешнего многообразия можно оценить движок. Итак, если включить “Незнакомое”, то алгоритм сделает серьезный крен в сторону ранее незнакомых композиций.
Кстати, недавнее обновление касалось именно этой настройки. “Незнакомое” получила новый ранжирующий алгоритм, благодаря чему стала более смело предлагать новые композиции, которые, тем не менее, должны соответствовать музыкальным вкусам пользователя.
С обновленной настройкой юзер получает новый аудиоконтент, при этом не ощущая особенно сильных скачков и перепадов. То есть, даже если алгоритм решит выйти за пределы рекомендационного пузыря, дабы расширить музыкальные горизонты пользователя, то он все равно будет оставаться в рамках его предпочтений и смежных жанров. Проще говоря, несмотря на экспериментирование, подбрасывание неактуальной музыки будет сведено к минимуму.
Уважаемые газеты пишут, что теперь пользователи сервиса добавляют к себе в “Коллекцию” примерно на 20% больше новых треков. Для артистов (в том числе молодых и начинающих) это тоже важный ништяк, поскольку повышается вероятность, что их творчество распространится и взлетит среди новой аудитории.
Так вот, для поиска этих самых новых композиций сервис как раз и применяет гибридный подход, объединяющий коллаборативную фильтрацию, анализ контента и фильтрацию на основе знаний о пользователе. Поговорим о нем детальнее.
Начнем с пользователя
Для начала, машина кушает все “долгосрочные” (очень условно их так назову, дорогие технари, не ругайтесь) данные о пользователе. Какие жанры и исполнителей он указывал как любимых, когда регистрировался? Что у него лежит в плейлисте? Что там лежит давно, а что недавно? Что удалялось? Что из лежащего давно он слушает регулярно или иногда, а что лежит мертвым балластом? И еще 100500 факторов и паттернов.
На эти “долгосрочные” знания о юзере накладываются конкретные действия.
Например, обычно Вася слушает треки в одной последовательности, а вчера решил включить в другой. Алгоритм тоже это примет к сведению. Возможно, учтет сразу, а, может быть, посмотрит на динамику последовательности при парочке ближайших использований (кто ж знает, как эта “черная коробка” решит там у себя внутри).
Не забываем, что алгоритмом все-таки заведует продвинутая ML-моделька, которая любит сама себя дообучать и всячески развивать. Так что, хотя человеки и знают принципы её мироустройства, точно предсказать результаты из “черного ящика” решительно нельзя.
Разумеется, движок учитывает, дослушал ли песню наш лирический герой, смахнул её или вовсе влепил ей лайк.
Далее - анализ контента
Вторая составляющая годной рекомендации - это анализ самой композиции. Для этого сервис преобразует трек в специальный формат - цифровой аудиовектор.
Для этого сервис разворачивает трек во времени и раскладывает его на частотные диапазоны, получая спектрограмму. Она передается специальной аудиомодели с нейросетью-энкодером, которая сворачивает спектрограмму в аудиовектор, или аудиоэмбеддинг (это когда сервис прячет в аудиофайле специальные метки - о песне, исполнителе, жанре и т.д.).
У похожих по звучанию треков такие векторы расположены близко друг к другу в многомерном векторном пространстве. У разных треков, соответственно, наоборот.
За счет таких манипуляций алгоритм может разложить трек буквально на атомы, чтобы потом сравнить каждую “элементарную музыкальную частицу” с аналогичными частицами других композиций.
Алгоритм сервиса преобразует трек в аудиовектор, расщепляя его на мельчайшие музыкальные элементы, чтобы проанализировать каждый из них. Вижу так.
Этот прием дополнительно повышает точность рекомендаций.
Наконец, коллаборативная фильтрация
Залезть в глубинные сущности этой техники конкретного сервиса непросто. Но каждый уважающий себя продвинутый стриминг старается довести эту технологию до высокого уровня.
За основу берется принцип, который я описал в первой части статьи. Но реализуется он, само собой, на предпочтениях миллионов слушателей. Алгоритм анализирует обезличенные данные массы пользователей, после чего прогнозирует музыкальные интересы конкретного человека, добиваясь максимально точных попаданий. В основе всего этого движа лежит матрица взаимодействия, составленная из различных оценок пользователей. Если упрощенно, то это такая табличка (ооочень большая), где отображаются все взаимодействия юзера с сервисом. Потом с матрицей работают алгоритмы машинного обучения - они уже обрабатывают данные и передают их в обобщенную модель, которая и отвечает за рекомендации.
Три типа фильтрации в итоге объединяются в единый machine-learning алгоритм под названием CatBoost, который уже генерирует для каждого юзера персональную последовательность треков с учетом множества вышеописанных факторов.
В итоге в алгоритмическом магическом котле заваривается тот самый вуншпунш, который мы готовы потреблять ушами в течение часов и дней, поддерживая свой энергичный рабочий настрой, умиротворенный расслабленный вайб либо же вызывая внезапный эмоциональный порыв. Подчеркнуть нужное в зависимости от ваших текущих целей, настроения и самочувствия.
Теперь вы знаете чуть больше про рекомендательные системы стриминга, особенно музыкального. Надеюсь, было интересно и полезно. Есть что добавить или с чем поспорить? Пишите в комменты.
Если вам понравилось, то подписывайтесь на мои тг-каналы. На основном канале - Дизрапторе - я простым человечьим языком и с юмором разбираю разные интересные штуки из мира бизнеса, инноваций и технологических новшеств (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили). А на втором канале под названием Фичизм я регулярно пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.
Это ИИ-модель для роботов, которая позволит им понимать человеческий язык и подражать движениям людей, обучаясь на ходу. Вместе с этим анонсировали Jetson Thor — компактный суперкомпьютер для роботов.
Шутки шутками, а они уже заколлабились с Boston Dynamics и Figure AI.
Хромакей, или "зеленый экран",позволяет создавать сцены, которые были бы невозможны или экономически нецелесообразны для реализации в реальной жизни. Это открывает двери для неограниченных творческих возможностей, включая интеграцию изображений знаменитостей в различные сценарии.
Мадонна демонстрирует экраны хромакей
Интеграция знаменитостей в рекламные кампании
С помощью хромакея бренды могут "пригласить" знаменитостей в свои рекламные ролики, даже если они физически не могут присутствовать на съемках. Это не только снижает затраты на производство, но и позволяет использовать образ известных личностей для усиления доверия и узнаваемости бренда.
Madonna green screen
Виртуальные события и встречи
Хромакей также может быть использован для создания виртуальных событий, где знаменитости могут взаимодействовать с аудиторией в реальном времени. Это создает иллюзию непосредственного общения и может значительно увеличить вовлеченность и интерес к мероприятию.
Will Smith green screen
Обучающий и развлекательный контент
Образовательные платформы и развлекательные каналы могут использовать хромакей МОКАПЫ со знаменитостями для создания уникального и запоминающегося контента. Такие техники могут улучшить обучающий опыт и сделать процесс более интерактивным и привлекательным.
Will Smith со смартфоном хромакей
Персонализация клиентского опыта
Бренды могут использовать хромакей для создания персонализированных рекламных материалов, где клиенты могут "взаимодействовать" со знаменитостями. Это может усилить эмоциональную связь между потребителем и продуктом или услугой.
Will Smiht и хромакей экран
Mona Lisa со смартфоном хромакей
Девушка с хромакей смартфоном
Девушка с хромакей экраном
Девушка демонстрирует экран смартфона хромакей
Green screen Footage
Рука со смартфоном хромакей
Разрешено использовать изображения для своих фото и видео съёмок
У кого-то может возникнуть вопрос: а что же такое – эти нейросвязки? Давайте разберем.
Взаимодействие с нейросетями не ограничивается использованием чат-ботов в стиле «вопрос-ответ». Чтобы получить реальную выгоду от применения искусственного интеллекта, нужен комплексный подход, включающий, зачастую, несколько инструментов.
Допустим, вы отправляете языковой модели (скажем, ChatGPT) запрос о написании некоего текста или контент-плана. На выходе получаете ответ от нейросети.
Какие бывают нейросвязки?
Существует три типа специалистов, использующих нейросети в своей работе. Их легко разделить по типу задач, которые они решают. И для каждого из них есть наиболее подходящие нейросвязки.
Первый тип – это нейроспециалист, работающий на основной работе или фрилансер, применяющий возможности нейросетей для повышения эффективности собственной деятельности.
Второй тип – нейроэксперт, получающий доход от создаваемого контента. Поскольку нейросеть представляет собой, по сути, фабрику по массовому производству качественного контента, для таких специалистов формируется отдельный набор нейросвязок.
Третий тип – нейропродюсер и нейропредприниматель, использующие особые нейросвязки для масштабирования и повышения эффективности бизнеса.
Вот кстати пример вакансий связанных с нейронкой:
Что дают нейросвязки?
Итак, у нас есть у нас три типа людей, использующих в работе искусственный интеллект: специалист, эксперт, и нейропредприниматель или нейропродюсер. Что они выигрывают, используя нейросвязки?
Специалист, за счет применения нейросвязок, увеличивает скорость, продуктивность своей работы.
Эксперт увеличивает количество и качество создаваемого контента. И, как результат, растет его заработок.
А нейропродюсеру и нейропредпринимателю нейросвязки помогают увеличить эффективность бизнеса.
Кстати, кто такой этот нейропродюсер?
Это тот, кого приглашают, чтобы внедрить нейросети в работу компаний. И за это он получает деньги!
Какие задачи можно поручить нейросетям?
Нейроспециалист может поручить выполнения каких-то заказов, рабочих задач. Например, делать карточки товаров для маркетплейсов. Писать тексты, посты, делать дизайн, переводы, создавать иллюстрации и т.д.
Нужны ли рынку нейропродюсеры?
Самый впечатляющий факт, касающийся специалистов, разбирающихся в нейросетях и нейропродюсеров в частности: за последний год спрос на таких профессионалов вырос аж в 10 раз! Ни в одной другой нише – будь то программирование, веб-дизайн или что угодно еще – не наблюдалось столь стремительного рывка.
Это означает, что компании готовы искать нужных людей где угодно. Остро востребованы те, кто разбирается в нейросетях и умеет создавать выгодные нейросвязки – цепочки взаимодействия нейросетей для решения конкретных бизнес-задач.
Так что, профессия нейропродюсера является, пожалуй, самой перспективной на данный момент. Если вы хотите идти в ногу со временем, стоит обратить внимание на эту сферу и изучить навыки эффективной работы с нейросетями и построения прибыльных нейросвязок. Это то, что может кардинально изменить вашу карьеру и финансовое положение.
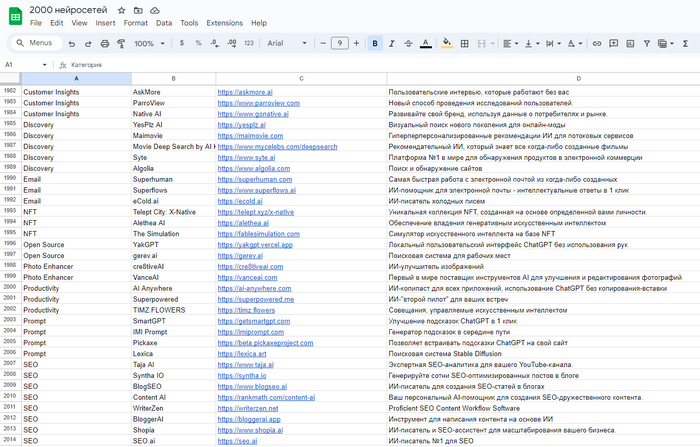
Также я собрал базу данных (если это так можно назвать), где собраны 2000 нейросетей на все случаи жизни, от простых текстовых до SEO-специалистов.
Это лишь малая часть)
Список этих нейронок я выложил у себя в ТГ канале, буду признателен за обратную связь.