
0 просмотренных постов скрыто





Володин, Клишас и Останина поспорили из-за закона об эвтаназии собак
Ведомости:
Депутаты Госдумы, которые продвигают право регионов на умерщвление бездомных животных, вступили в публичный спор с сенатором, главой комитета Совета Федерации по госстроительству Андреем Клишасом. Это произошло после публикации в его Telegram-канале, в которой тот напомнил позицию Конституционного суда (КС) 2024 г. о недопустимости умерщвления бездомных животных.
Исходя из позиции КС, написал Клишас еще 5 марта, можно сделать вывод «о недопустимости введения в федеральное законодательство бессрочного и распространяемого на всю территорию РФ, без учета сложившихся обстоятельств в конкретном субъекте РФ, положения о возможном умерщвлении животных, содержащихся в приютах».
На эти сообщения довольно оперативно отреагировали депутаты, которые 1 марта внесли в Госдуму межфракционный законопроект, предлагающий разрешить субъектам РФ усыплять отловленных бездомных собак после наступления предельного срока содержания животных в приюте (его тоже определят региональные власти). Умерщвление будет возможно, если для бездомных собак и кошек за это время не нашелся хозяин. По действующим нормам закона об ответственном обращении с животными, приюты могут усыплять животных только в том случае, если они по заключению ветеринара испытывают непереносимые физические страдания и болезни, не совместимые с жизнью. Под инициативой подписались 24 депутата.
https://www.vedomosti.ru/society/articles/2025/03/07/1096581...
Сетевое издание Ведомости (Vedomosti)
Решение Федеральной службы по надзору в сфере связи, информационных технологий и массовых коммуникаций (Роскомнадзор) от 27 ноября 2020 г. ЭЛ № ФС 77-79546
От себя дополню - сколько можно спорить? Едят детей, а спор всё идёт.
Показать полностью


Силиконовые накладки
Показать полностью

Ответ Chernozema в «Микропроцессор "Эльбрус" произведенный в России»23
Не знаю точно байка это из мира науки... или просто анекдот. Кажется даже Задорнов про неё рассказывал, но я сышал эту историю много раньше его выступлений. А может и правда.
Рассвет гонки вооружений, года приблизительно 70-е. ЮЭСАЙ решили выложить много миллионов $ на расчёт разрушений после ядерной бомбардировки. Соединили в рабочую группу 2 института, много учёных, военных, парочку ЭВМ (больших таких, которые цеха занимали и жрали энергии как пара сталелитейных заводов). За 2 года кропотливой работы и вливаний многих миллионов выкатили результаты. Плюс-минус в десятки километров погрешность в расстояниях. Решили выебнутся перед миром. Выкатили всё что не сильно секретно для мировой общественности, с доказательствами и математической моделью для расчёта ущербов ядерных взрывов! Успех. Пьют шампанское и получают новые гранты!
Через неделю СССР выкатывают модель расчётов с точностью до 10 метров. Разлёты осколков, повреждения зданий, техники и прочие мелочи. ЮэСАй в шоке - как так то!? Без компов и посчитали в 1000 раз точнее!?!
Заканчивается холодная война, встречаются на саммите два генерала ну и американский просит рассказать о тайне точности расчётов! Ему наш генерал отвечает.
- а мы несколько составов кирпичей пронумеровали и насыпали кучками по всей Новой Земле, взорвали ядрёну бомбу, и батальон солдат с рулетками померил расстояния на сколько кирпичи разлетелись, за месяц составили карту и сделали мат модель силы удара на разных высотах, укреплениях и постройках.
Как обмануть нейросеть или что такое Adversarial attack - все очень плохо
Все эти работы с нейросетями, биометрией это чума 21 века, которая сулит множество страшных вещей.
Как обмануть нейросеть или что такое Adversarial attack
В статье рассмотрено, что такое вредоносное машинное обучение (Adversarial Machine Learning), чем это опасно, где применяется и как отличается от генеративно-состязательных нейросетей. Читайте далее, когда и почему появились AML-методы, как обмануть систему распознавания лиц и какими способами бороться с Adversarial attack.
Что такое Adversarial Machine Learning: определение и история появления
Обычно термин Adversarial Machine Learning (AML) переводят на русский язык как «состязательное машинное обучение», подразумевая целенаправленное воздействие на нейронную сеть, которое способно вызвать ошибки в ее поведении. Поэтому более корректно использовать значение «вредоносное ML», что исключает путаницу с генеративно-состязательными нейросетями (Generative adversarial network, GAN) и подчеркивает негативный характер этого понятия. Первые публикации по теме AML относят к 2004 году. Примерно до 2015 года, пока ML не получило широкого распространения на практике, AML также носило теоретический характер [1]. А в 2013 году Christian Szegedy из Google AI, пытаясь понять, как нейросети «думают», обнаружил общее свойство этого ML-метода: их легко обмануть небольшими возмущениями [2]. Далее идеи AML приобретают популярность после статьи известных DS-специалистов Ian J. Goodfellow, Jonathon Shlens и Christian Szegedy «Explaining and harnessing adversarial examples», опубликованной в 2015 году [3].
Классической иллюстрацией AML-атаки (Adversarial attack) является пример из этой статьи, когда к исходному изображению панды, распознаваемому с вероятностью 57,7 %, подмешивается специальные шум, невидимый человеком, но замечаемый нейросетью. В результате нейронная сеть идентифицирует картинку как изображение гиббона и с вероятностью 99,3 % (рис.1) [3].

Рис.1. Принцип AML-атаки на ML-системы распознавания изображений
В 2017 году исследователи из Массачусетского технологического института (MIT) напечатали на 3D-принтере модель игрушечной черепахи с такой текстурой, что инструмент Google AI для обнаружения объектов классифицировал ее как винтовку. А в 2018 году Google Brain опубликовал обработанное изображение собаки, которая выглядела как кошка, причем как для компьютеров, так и для людей [4].
Полная история AML с истоков по настоящее время изложена в статье «Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning» итальянских исследователей Battista Biggioa и Fabio Rolia. Разумеется, область действия AML не ограничена только машинным зрением и идентификацией изображений, она включает также и задачи распознавания текста, звука, биометрических данных. В частности, именно так можно обойти функцию Face ID в смартфоне iPhone X или других подобных устройствах [1]. Далее мы рассмотрим легальные варианты использования Adversarial Machine Learning, а сейчас поговорим о видах атак на нейросетевые модели, которые могут быть реализованы с помощью этого метода.
Виды и примеры Adversarial attack
Итак, одной из причин появления Adversarial attack считается то, что методы машинного обучения изначально были разработаны для стационарных и безопасных сред, где обучающая и тестовая выборки сгенерированы из одного и того же статистического распределения. Однако, на практике злоумышленники могут тайно манипулировать входными данными, чтобы использовать уязвимости ML-алгоритмов и поставить под угрозу безопасность всей системы машинного обучения. Выделяют 2 вида AML-атак [4]:
уклонение (evasion), при которых злоумышленник старается вызвать неадекватное поведение уже готового продукта со встроенной в него ML-моделью. В этом случае сам продукт рассматривается злоумышленником как черный ящик, без детального знания характеристик и устройств. Этот тип атак считается наиболее распространенным. Например, спамеры и хакеры часто пытаются уклониться от обнаружения, скрывая содержимое спам-писем и вредоносный код. В частности, сюда относится спам на основе изображений, где вредоносное содержимое встроено в прикрепленное изображение, чтобы избежать текстового анализа, выполняемого почтовыми спам-фильтрами. Другой кейс – спуффинг-атаки на биометрические системы, когда злоумышленник стремится замаскироваться под другого человека.
отравление (poisoning), когда злоумышленник стремится получить доступ к данными и процессу обучения ML-модели, чтобы ее «отравить» (обучить неправильно) для последующей неадекватной работы. Отравление можно рассматривать как злонамеренное заражение обучающих данных. Таким образом, здесь используется стратегия «белого ящика», когда атакующий обладает сведениями о жертве - «вредоносными знаниями» (Adversarial Knowledge, AK): как готовятся и из каких источников берутся данныемдля обучение и что они собой представляют, каковы основные функции атакуемой системы, по каким алгоритмам она работает, каковы результаты и пр. Отравляющие атаки предполагают инсайдерскую информацию о ML-системе и достаточно высокий уровень компетенций злоумышленника в Data Science.
Кроме знаний о жертве, основными факторами, которые определяют вид атаки на контролируемые ML-алгоритмы считаются следующие [4]:
влияние на классификатор, например, если атака направлена на внедрение уязвимостей на этапе классификации через манипулирование обучающими данными или поиск и последующее использование уязвимостей;
нарушение безопасности, в частности, целостности, когда злонамеренные образцы ошибочно классифицированы как легитимные, или доступности, если цель злоумышленника в том, чтобы увеличить неправильную классификацию легитимных образцов, делая классификатор непригодным для использования;
специфика атаки – целевая или неизбирательная. При целевой атаке задействованы конкретные образцы, чтобы разрешить конкретное вторжение, например, проход через спам-фильтр определенного электронного письма.
Помимо спам-писем и обмана биометрических систем, одном из наиболее ярких кейсов Adversarial attack является воздействие на беспилотные автомобили и другие робототехнические решения. К примеру, для анализа поведения подсистемы машинного зрения автомобиля на ее вход в огромном количестве подаются слегка видоизмененные изображения дорожных знаков. Эксперименты исследователей Принстонского университета показали, что достаточно нанести несложные искажения на знак ограничения скорости, чтобы ML-система считала его за знак обязательной остановки. А внезапное торможение одного автомобиля в плотном потоке машин, движущихся с высокой скоростью чревато авариями и даже человеческими жертвами. С учетом такой потенциальной уязвимости многие компании-разработчики беспилотных авто отреагировали выпуском технологий для предупреждения Adversarial attack. В частности, в 2018 году корпорация Nvidia, сотрудничающая с Mercedes-Benz, опубликовала отчет SELF-DRIVING SAFETY REPORT, где описаны прилагаемые инфраструктурные решения для защиты беспилотных машин. Производители самолетов предлагают распространить на автомобили технологии типа Communication Lockdown (блокировка коммуникаций), которой укомплектованы истребители F-35I и F-16I. Тем не менее, в области беспилотных машин пока не существует готовых решений для противодействия искажающих атакам, поэтому эти потенциальные угрозы остаются важнейшим фактором, который тормозит практическое внедрение автономных автомобилей в повседневную жизнь [1].
Еще одним иллюстративным примером AML-атак является уязвимость алгоритмов кластеризации, которые используются для обнаружения опасных или незаконных действий. Например, кластеризация вредоносных программ и компьютерных вирусов направлена на их выявление, классификацию и создание конкретных сигнатур для обнаружения антивирусами или системами обнаружения вторжений. Однако, изначально эти алгоритмы не были разработаны для борьбы с преднамеренными попытками атак, которые могут нарушить сам процесс кластеризации [4].
Как защититься от AML-атаки: подходы к обучению нейросетей и оценка безопасности
Высокие риски AML-атак привели к появлению предложений о пересмотре подходов к обучению нейросетей. В 2019 году ученые из MIT показали, что случайный на первый взгляд шум, который путает ML-модель, на самом деле задействует очень точечные, едва заметные паттерны, ассоциированные с конкретными объектами. Это означает, что ML-система не просто обнаруживает гиббона там, где человек видит панду, а выявляет закономерное расположение пикселей, незаметное человеку, которое во время обучения чаще всего появлялось на снимках с гиббонами, чем на изображениях панд. Исследователи провели эксперимент, создав датасет с изображениями собак, которые были изменены так, что стандартный классификатор изображений ошибочно идентифицировал их как кошек. Далее они пометили эти изображения «котами» и использовали их для обучения новой нейросети. Затем обученной ML-модели были предъявлены реальные изображения кошек, и она идентифицировала их правильно. Поэтому экспериментаторы предположили, что в каждом наборе данных есть два типа корреляций [5]:
концептуальные шаблоны, которые коррелируют со смыслом данных (остроконечные уши кошек, специфический окрас меха у панд);
пиксельные паттерны, которые существуют в обучающих данных, но не распространяются на другие контексты, например, наклейки, фоновые изображения и прочий визуальный шум. Именно эти факторы и используются в AML-атаках.
Таким образом, чтобы снизить риск Adversarial attack, следует изменить способ обучения ML-моделей, контролируя корреляционные паттерны, которые нейросеть использует для идентификации объектов на изображении. Это возможно при обучении на концптуальных шаблонах, которые связаны с самим смыслом идентифицируемого объекта. Проверив эту идею с использованием только реальных корреляции для тренировки ML-моделей, исследователи из MIT получили обнадеживающие результаты: нейросеть поддалась атаке только в 50% случаев, тогда как модель, обученная на реальных и ложных корреляциях, поддавалась манипуляциям в 95% случаев [5].
Однако, повышение качества обучающей выборки недостаточно, чтобы полностью устранить риски Adversarial attack. Чтобы понять уровень безопасности ML-алгоритмов, необходим комплексный подход, включая следующие меры [4]:
выявление потенциальных уязвимостей алгоритмов машинного обучения во время обучения и классификации;
определение соответствующих атак, которые соответствуют выявленным угрозам, и оценка их воздействия на целевую ML-систему;
реализация методов, противодействующих потенциальным атакам.
Этот комплекс мероприятий представляет собой проактивную гонку вооружений, когда разработчик пытается предугадать намерения и действия противника, чтобы заранее устранить потенциальные уязвимости. Также имеет место реактивная гонка вооружений, при которой разработчик анализирует уже совершенную атаку и противодействует ей (рис.2).

Рис.2. Реактивная и проактивная гонка вооружений в AML-атаках
На сегодняшний день в области прикладной Data Science наиболее популярны следующие механизмы защиты от Adversarial attack [4]:
определение алгоритмов безопасного обучения;
использование нескольких систем классификаторов;
обучение с сохранением конфиденциальности;
теоретико-игровые AML-модели, включая интеллектуальный анализ данных;
очистка обучающей выборки от отравляющих атак.
Также выделяют методы эмпирической защиты от AML-нападений, эффективность которых испытывается и подтверждается на практике [2]:
Состязательная тренировка (Adversarial training, AT), когда во время обучения ML-модель переобучается с примерами, включенными в тренировочный датасет, но помеченными правильными метками. Это учит модель игнорировать шум и учиться только на «надежных» функциях. Это защищает модель только от тех атак, которые использовались для создания примеров, включенных в обучающую выборку. При использовании другого алгоритма или адаптивной атаке (т.н. «белый ящик») можно заново обмануть нейросетевой классификатор, как в отсутствии любой защиты. Если продолжить переобучение модели, включая все больше поддельных образцов, в какой-то момент фальшивых данных в обучающем датасете окажется так много, что модель станет бесполезной. Однако, если цель состоит в том, чтобы злоумышленнику было сложнее обмануть нейросетевой классификатор, AT – отличный выбор, который можно реализовать с помощью ансамблевых или каскадных методов, а также через робастную оптимизацию или спектральную нормализацию.
Градиентное маскирование (Gradient masking), которое не работает в качестве защиты, но обеспечивает шумоподавление. Благодаря свойству переносимости у AML-образцов, даже если скрыть градиенты модели, злоумышленник все равно может построить суррогат, атаковать его, а затем передать примеры отравленных обучающих данных. Модификация входных данных происходит, когда они перед передачей в ML-модель очищаются, чтобы избавиться от постороннего шума, например, как это происходит с применением автокодеров, уменьшения глубины цвета, сглаживания, GAN-преобразования, JPEG- сжатия и прочих преобразований.
Обнаружение (Detection) и входная модификация (Input modification), когда входные данные после очистки сравниваются с исходными – если результаты слишком отличаются, то высока вероятность изменения входного датасета, т.е. возможность атаки. Существует ряд способов защиты от обнаружения, которые проверяют необработанную статистику, вычисленную в различных точках процесса ввода, например, на самом входе, при сверточной фильтрации и т.д. Важно, что методы модификации и обнаружения можно применить к уже обученной ML-модели.
Дополнительный класс (Extra class), когда классификаторы обучаются определенному распределению данных в рамках определенных пределах, воздерживаясь от идентификации неизвестных классов.
Некоторые из вышерассмотренных методов доступны в следующих AML-библиотеках [4]:
AdversariaLib, которая включает реализацию атак уклонения;
AdLib– Python- библиотека с интерфейсом в стиле scikit, включающая реализацию атак уклонения и защиты от них;
AlfaSVMLib– атаки на машины опорных векторов и алгоритмы кластеризации;
deep-pwning- Metasploit для глубокого обучения, который в настоящее время атакует глубокие нейронные сети с использованием Tensorflow;
Clever Hans– Tensorflow-библиотека для тестирования моделей Deep Learning на известные AML-атаки;
foolbox– Python-библиотека для создания AML-образцов, которая реализует несколько атак.
Где используется AML: несколько практических примеров
Классическими кейсами применения методов Adversarial attack считаются следующие [4]:
фильтрация спама, когда спам-сообщения маскируются путем неправильного написания стоп-слов или вставки альтернативных вариантов;
атаки на компьютерную безопасность, например, обфускация вредоносного кода в сетевых пакетах или путаница при обнаружении вирусных сигнатур;
атаки на биометрические системы, когда поддельные биометрические характеристики используются злоумышленниками в качестве подмены легального пользователя.
Однако, применение AML-атак в сфере cybersecurity [6] - далеко не единственный пример прикладного использования этой технологии. В частности, в 2019 году компания Авито использовала этот подход для борьбы с кражей контента, защищая объявления о продаже автомобилей путем наложения специальной шумовой маски на их фотографии. При этом был использован метод object detection с помощью итеративного добавления изображений, отличных от истинного класса, в фон логотипа компании, размещенного на номерном знаке авто (рис.3). Шум для букв логотипа Авито получен методом fgsm, при разработке использовалась масштабируемая платформа MXNet для обучения и развертывания глубоких нейросетей. Таким образом, сервис объявлений предотвратил автоматическое копирование своего контента на веб-сайт конкурентов [7].

Рис.3. Защита изображений в Авито
Другим интересным примером является соревнования по машинному зрению (Machines Can See), в которых требовалось изменять лица людей так, что сверточная нейросеть (черный ящик от организаторов), не могла различить лицо-источник от лица-цели (рис.4). При этом были использованы следующие методы: Fast Gradient Sign Method (FGSM), Fast Gradient Value Method (FGVM), Genetic differential evolution, попиксельные атаки, Ансамбли моделей с несколькими ResNet34 и «умный» обход комбинаций целевых изображений [8].

Рис.4. Adversarial attack на изображения человеческих лиц
Аналогичная генерация человеческих лиц описана в статье про манипуляции с биометрическими изображениями, когда изучение способов обмана биометрических систем позволит повысить эффективность борьбы с подобными атаками. К примеру, экспериментальные исследования показали, что предсказание модели распознавания лиц напрямую зависит от параметров ML-модели и расположения опорных точек на входном изображении. Манипуляции с ними посредством градиента предсказания по отношению к входному изображению сильно влияют на предсказания классификатора распознавания лиц (рис. 5) [9].

Рис. 5. Сгенерированные образцы человеческих лиц с использованием методов Adversarial attack
Впрочем, манипуляции с опорными точками – это не только прерогатива ML-специалистов. В связи с активным внедрением систем видеонаблюдения с функцией распознавания лиц, все больше городских активистов пытаются обмануть компьютерную биометрию. Согласно исследованию российской компании «Видеомакс», накладные усы, бороды, темные или прозрачные очки не могут обмануть ML-алгоритмы, а объемный парик снижает точность опознания почти вдвое. Совместное использование парика с длинными волосами, головного убора, наклеивание пластырей и имитация синяков на лице снижали точность распознавания до 51%. Еще люди используют специальный макияж, который нарушает симметрию лица и влияет на определение опорных точек. Подобный метод камуфляжного грима лежит в основе сервиса Григория Бакунов, директора по распространению технологий компании «Яндекс». Алгоритм на основе оригинальной фотографии подбирает для человека новый образ по принципу «анти-сходства» (рис. 6). Однако Григорий достаточно быстро закрыл этот проект, посчитав его потенциальным оружием для злоумышленников, которые могут воспользоваться сервисом в нелегитимных целях [10].

Рис. 6. Примеры камуфляжного грима, который помогает защититься от системы распознавания лиц
Однако, камуфляжный макияж сработает только в случае тех систем, которые ориентируются на анализ плоских изображений с помощью обычных видеокамер дневного света. В случае инфракрасных устройств видеонаблюдения косметика не поможет, поскольку они отражают инфракрасные лучи от человека и создают трехмерную карту всего лица. В частности, технология FaceID распознаёт лицо в любом макияже. Впрочем, исследователи Фуданьского университета в Китае, Китайского университета Гонконга и Университета Индианы по заказу корпорации Alibaba разработали инфракрасные светодиоды, которые крепятся к кепке и засвечивают человеческое лицо. Это позволить скрыться даже от инфракрасных камер. Причем светодиоды помогают не только скрыть лицо, но и притвориться другим человеком, подсвечивая нужные опорные точки. Эксперимент показал, что камеры удалось обмануть в 70% случаев. Аналогичное решение представил Токийский национальный институт информатики в виде очков со встроенным инфракрасными светодиодами, которые засвечивают глаза и нос человека. Однако, они не смогут обмануть камеры, на которые регистрируют видимый, а не инфракрасный свет [10]. Кроме того, вопрос об удобстве пользования таким аксессуаром остается открытым: человеческий глав очень чувствителен к яркому свету и долго носить его не получится.

Рис.7. Светодиоды для обмана систем распознавания лиц
Некоторые активисты создают специальные аксессуары, например, фотореалистичная 3D-маска от американского художника Леонардо Сельваджио (Leonardo Selvaggio) или польского дизайнера Эвы Новак (Ewa Nowak), которые также ориентированы на обман городских систем видеонаблюдения с функцией распознавания лиц (рис. 8) [10]. Впрочем, прогресс не стоят на месте и подобное протестное движение можно рассматривать как своего рода Adversarial attack на ML-алгоритмы распознавания, которые в конечном счете выступают драйвером дальнейшего развития этой технологии.

Рис.8. 3D-маска Леонардо Сельваджио и аксессуары Эвы Новак для обмана систем распознавания лиц
Заключение
Итак, с учетом роста интереса к Deep Learning, распространению биометрических систем в частности и ML в целом, а также популяризации автономных машин (роботы, автомобили, беспилотные летающие аппараты), можно сделать вывод, что проблема AML еще долго будет актуальной. Поэтому при подготовке данных к моделированию и разработке собственных нейросетевых моделей Data Scientist должен оценивать их уязвимость к возможным атакам, принимая соответствующие контрмеры.
Показать полностью
8

- А поделиться, брат?

с интернета
Показать полностью
1

Для тех кому интересны 3D модели
Если вы 3D художник, или просто развиваете воображение вам понравиться. Вот несколько авторов которые на мой взгляд достойны вашего внимания. Помогут развить креативность и получить новый взгляд на вещи. Scetchfab

Renafox Разная техника, машины

Zoilo Архитектура, статуи, барельеф
Duy Khanh Nguyen Персонажи схожие с графикой League of Legends
Stefan Engdahl Огнестрельное оружие реализм
micro26 Оружие будущего и прошлого реализм
dylanheyes Рендер интерьеров реализм
Спасибо за внимание! Занимайтесь 3д и возможно в следующий раз именно вы попадёте в подборку лучших и да пребудет с вами сила :)
Показать полностью
5


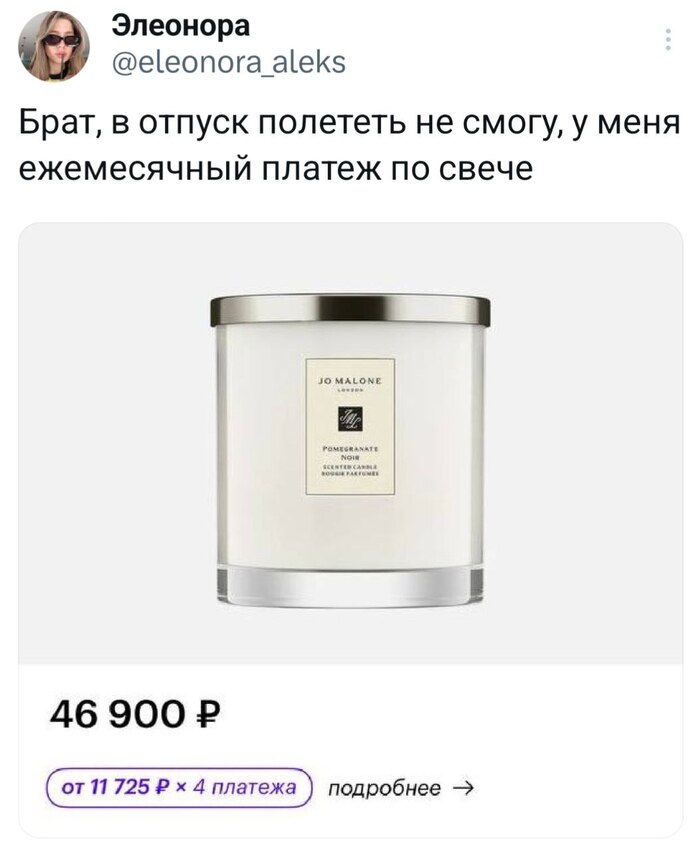
Не понимаю
Показать полностью
1
