GeForce 900: начало эпохи DirectX 12
GeForce 1000
GeForce 2000: трассировка лучей и DLSS
GeForce 3000
GeForce 4000: технология DLSS 3
GeForce 900: начало эпохи DirectX 12
Основой серии GeForce 900 стала архитектура Maxwell, но первыми ее получили карты предыдущей линейки — GTX750 и GTX750 Ti. Из-за задержек с новым техпроцессом NVIDIA пришлось использовать «старые» 28 нм для производства чипов нового поколения. Поэтому сначала было решено обкатать новую архитектуру на бюджетном чипе GM107.
С точки зрения графических возможностей, первое поколение Maxwell почти не отличается от Kepler. Однако внутреннее устройство чипов значительно переработано. Это позволило добиться увеличения производительности при снижении энергопотребления.
GM107 состоит из одного GPC, внутри которого пять SM. В каждом из них движок Polymorph Engine третьего поколения и 128 SP, поделенных на четыре раздела. У каждого из разделов свой планировщик, буфер инструкций и регистровый файл. Блоки, обслуживающие меньшее количество SP, гораздо проще и занимают меньше места на чипе — именно поэтому такое разделение эффективнее. Чип использует более быстрый тайловый рендеринг, который заключается в разбиении кадра на плитки. Это потребовало значительного увеличения кэша второго уровня.
ГП содержит 16 ROP и 40 TMU, а также 640 SP, производительность которых повысилась примерно на треть по сравнению с Kepler. GTX750 Ti имеет полный чип, GTX750 — урезанный. Карты оснащаются 1 или 2 ГБ 128-битной GDDR5 с полосой пропускания до 86 ГБ/c, но новая архитектура распоряжается ею эффективнее прошлой.
В сентябре 2014 года были выпущены GTX980 и GTX970 на базе архитектуры Maxwell второго поколения. Она принесла поддержку DirectX 12.1 и ряда новых технологий для эффективной работы в VR. Основой карт стал чип GM204, увеличивший потолок частот до 1.2 ГГц при невысоком энергопотреблении — не более 165 Вт.
GM204 имеет четыре GPC, в каждом из которых четыре SM. Полный чип содержит 64 ROP, 128 TMU и 2048 SP. Используется 256-битная шина, пропускная способность которой достигает 224 ГБ/c. Флагманская GTX980 имела полную версию ГП и 4 ГБ памяти. В GTX970 была отключена часть блоков, а шина поделена на 224-битный и 32-битный сегменты, вследствие чего 512 МБ памяти из общего объема в 4 ГБ работали медленнее.
AMD к этому времени подтянула производительность серии R9 290 драйверами, и лишь в июне 2015 года представила «новых» противников картам NVIDIA: R9 390 и R9 390X — переименованные модели старой серии с увеличенным до 8 ГБ объемом памяти. Впрочем, и сами GTX970 и 980 на тот момент недалеко ушли от GTX780 и 780 Ti. Производительности даже прошлых флагманов с лихвой хватало для большинства игровых проектов, за редкими исключениями.
В январе 2015 года увидела свет GTX960. Ее основой стал чип GM206, представляющий собой «половинку» от GM204 со 128-битной шиной. Карта выпускалась в двух вариантах — с 2 и 4 ГБ памяти GDDR5. Спустя полгода была выпущена GTX950 с 2 ГБ памяти, которая растеряла четверть SM от полного чипа.
В марте 2015 года был выпущен новый король 3D-графики — GTX Titan X. Он построен на чипе GM200. Внутреннее строение по сравнению с GM204 не изменилось, но вместо четырех GPC стало шесть. Кратно возросло количество всех блоков — у новинки 96 ROP, 192 TMU, 3072 SP и 384-битная шина памяти с пропускной способностью в 336 ГБ/c.
Объем памяти GTX Titan X достиг 12 ГБ, а энергопотребление — 250 Вт. Спустя три месяца NVIDIA выпускает GTX980 Ti с 6 ГБ памяти, но более доступную по цене. В ее основе — все тот же GM200, но слегка урезанный по блокам. AMD отвечает на это новой моделью R9 Fury X с 4 ГБ памяти. Производительность обоих решений оказывается близка, но из-за малого объема памяти флагман AMD вскоре сдаст свои позиции.
GeForce 1000
Новая серия карт получила архитектуру Pascal. Она достаточно схожа с Maxwell, но принесла ощутимый рост производительности за счет техпроцесса 16 нм, который помог увеличить количество блоков чипа и достичь более высоких частот. Pascal получила поддержку асинхронных вычислений DirectX 12 и ряд оптимизаций для повышения производительности в VR-режиме.
Первой картой стала GTX1080, выпущенная в мае 2016 года. В ее основе чип GP104, в составе которого четыре GPC. Внутри каждого из них пять кластеров текстурной обработки (TPC), которые содержат по одному SM и блоку Polymorph Engine четвертого поколения. Сами мультипроцессоры кардинальных изменений не получили: как и в случае с Maxwell, они имеют 128 SP, которые поделены на четыре раздела.
Полный GP104 содержит 64 ROP, 160 TMU и 2560 SP. Подсистема памяти 256-битная. Теперь ее формируют восемь 32-битных каналов, а не четыре 64-битных, что позволило использовать новую GDDR5X. Объем памяти составил 8 ГБ, а пропускная способность возросла до 320 ГБ/c. Технология GPU Boost была обновлена до версии 3.0, которая более эффективно увеличивает частоту в зависимости от напряжения. Частота ГП в бусте превысила планку в 1700 МГц. По сравнению с предшественником карта стала быстрее на две трети при чуть более высоком TDP — 180 Вт.
Следом чип GP104 получила и GTX1070, но количество активных SP в ней сократили на четверть. Карта имеет 8 ГБ обычной GDDR5. GTX1070 Ti появилась в 2017 году. Она отличается от предшественницы гораздо менее урезанным чипом. Чуть раньше нее появились запоздалые конкуренты от AMD — карты Vega 64 и Vega 56. При паритете по производительности они обладали более высоким энергопотреблением.
В июле 2016 года свет увидела GTX1060, ставшая популярной картой среднего ценового сегмента. В ее основу лег чип GP106 с 1280 SP и 192-битной шиной памяти. Версия карты с 6 ГБ GDDR5 использует полную версию ГП, а версия с 3 ГБ — урезанную по блокам. Позже появились GTX1060, основанные на отбраковке старшего чипа GP104.
Топовым решением этого поколения стал чип GP102, который превышал возможности GP104 ровно в полтора раза. В его арсенале шесть GPC, 96 ROP, 240 TMU, 3840 SP и 384-битная память GDDR5X. В августе 2016 года был выпущен Titan X Pascal со слегка урезанным чипом и 12 ГБ памяти. В апреле 2017 года появилось еще две карты на основе GP104: Tital XP c полным чипом, и «гражданская» GTX1080 Ti, у которой, помимо чипа, сократили шину памяти и ее объем — до 352 бит и 11 ГБ, соответственно. AMD нечего было противопоставить этой карте вплоть до 2019 года, когда были выпущены Radeon VII и RX5700XT.
Октябрь 2016 года принес новинки на бюджетном чипе GP107, который получил 768 SP и 128-битную шину памяти. Полным чипом оснащалась GTX1050 Ti, урезанным — обычная GTX1050. Кроме этого, карты отличались разным объемом памяти: 4 ГБ у старшей модели, 2 ГБ у младшей. Спустя полтора года линейку дополнила GTX1050 с 3 ГБ памяти. У нее полный чип, но урезанная до 96 бит шина.
В мае 2017 года свет увидела младшая карта новой линейки — GT1030. В ее основу лег чип GP108, «половинка» от GP107 с 64-битной шиной памяти. Изначально использовалась GDDR5, но позже появился второй вид карты с DDR4.
GeForce 2000: трассировка лучей и DLSS
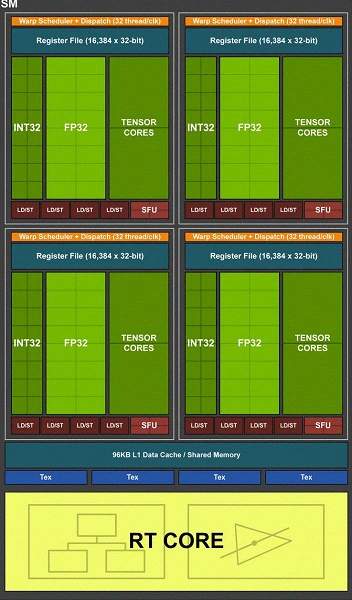
История карт NVIDIA RTX начинается с архитектуры Turing. GeForce 2000 стали первыми картами с поддержкой трассировки лучей и DirectX 12 Ultimate. Для этого потребовалось внести множество изменений во внутреннее устройство ГП, включая новые блоки трассировки лучей и тензорные ядра.
Первой картой серии стала RTX2080, выпущенная в сентябре 2018 года. Она построена на 12 нм чипе TU104, содержащем шесть GPC. В каждом из них четыре кластера TPC. Внутри TPC — блок Polymorph Engine и два SM, поделенные на четыре раздела с собственными блоками управления.
Число SP, выполняющих операции с плавающей запятой (FP32), в одном мультипроцессоре сокращено до 64. Компанию им составляют 64 блока целочисленных операций (INT32). За счет этого SM может производить оба вида расчетов одновременно, тогда как в прошлых архитектурах за раз можно было выполнять лишь одну из операций.
В каждой части SM имеются два тензорных ядра второго поколения. Они обеспечивают шумоподавление при трассировке лучей, а также работу новой технологии масштабирования DLSS (а позже — и DLSS 2). Один SM содержит 64 SP, 8 тензорных ядер и блок RT для трассировки лучей.
Полный чип TU104 содержит 64 ROP, 192 TMU и 3072 SP. Компанию им составляют 48 блоков RT и 384 тензорных ядра. Ширина и организация шины памяти не изменилась с прошлого поколения, но вместо GDDR5X стала применяться GDDR6, увеличившая пропускную способность в полтора раза — до 448 ГБ/c.
RTX2080 имеет немного урезанный по блокам чип. В 2019 году на базе TU104 были выпущены еще две видеокарты: RTX2070 Ti и RTX2080 Super. Первая имеет ГП с еще большим количеством отключенных блоков, а вторая — полную версию чипа. Объединяет все карты одинаковая память — 8 ГБ 256-битной GDDR6.
Конкурент от AMD и в этот раз появился с опозданием — лишь летом 2019 года. Но, в отличие от прошлой задержки, противостояния не получилось: RX5700XT была медленнее RTX2080, не поддерживала трассировку лучей и технологию DLSS. Однако и ее стоимость была куда скромнее.
Трассировкой лучей заинтересовались многие разработчики игр. Первой игрой с ее поддержкой стала Battlefield V, но в ней технология используется лишь для отражений. Metro Exodus, ставшая второй игрой с поддержкой трассировки, использует ее для освещения, в результате чего картинка преображается куда больше.
Через неделю после RTX2080 была представлена топовая карта семейства — RTX2080 Ti на чипе TU102. Этот ГП содержит ровно в полтора раза больше блоков, чем TU104, и имеет 384-битную шину памяти. В основу RTX2080 Ti лег слегка урезанный чип с 352-битной шиной и 11 ГБ памяти.
Полный чип и 12 ГБ памяти спустя три месяца получила карта Titan RTX. Она же стала последней картой серии Titan. Карты на основе TU102 и TU104 получили поддержку NVLink — новой технологии объединения ГП, которая пришла на смену SLI.
Спустя месяц после старших карт свет увидела RTX2070. Ее «сердце» — младший TU106, который получил 2304 SP и 256-битную шину памяти. В январе 2019 года урезанная версия TU106 стала основой RTX2060. Она получила 192-битную шину и 6 ГБ памяти, в отличие 8 ГБ у старшей модели. Выпущенной спустя полгода RTX2060 Super сократили количество отключенных блоков, вернули полную шину и 8 ГБ памяти.
Производство чипов с блоками трассировки лучей и тензорными ядрами было достаточно дорого из-за крупных кристаллов. Поэтому NVIDIA решила исключить их из ГП для бюджетных карт: результатом стали чипы TU116 и TU117. Карты Turing без поддержки трассировки лучей вошли в серию GeForce 16xx.
ГП TU116 имеет получил 1536 SP вкупе с 192-битной шиной. Первой картой на основе полного чипа стала GTX1660 Ti, выпущенная в феврале 2019 года. За ней последовала обычная GTX1660 с частью отключенных блоков и памятью GDDR5. В октябре свет увидела GTX1660 Super, отличающаяся от обычной версии памятью GDDR6. Последней картой стала GTX1650 Super, которая получила еще более урезанный чип, 128-битную шину и всего 4 ГБ памяти против 6 ГБ у старших «сестер».
Младший TU117 имеет 896 SP и 128-битную шину. Полная версия чипа использовалась в GTX1650, у которой также есть две версии — с памятью GDDR5 и GDDR6. Урезанный чип попал в GTX1630. Обе карты имеют 4 ГБ памяти.
GeForce 3000
Линейка GeForce 3000 построена на архитектуре Ampere, которая основана на предшествующей Turing, но имеет пару важных отличий для достижения более высокой производительности. Несмотря на более современный техпроцесс 8 нм, частоты выросли ненамного. Модели новой линейки поддерживают интерфейс PCI-E 4.0, в очередной раз удваивающий пропускную способность между картами и системой.
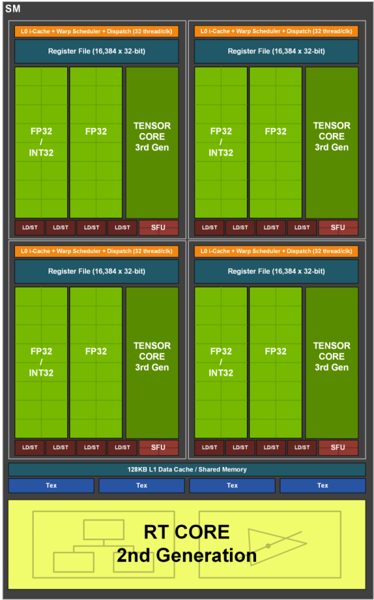
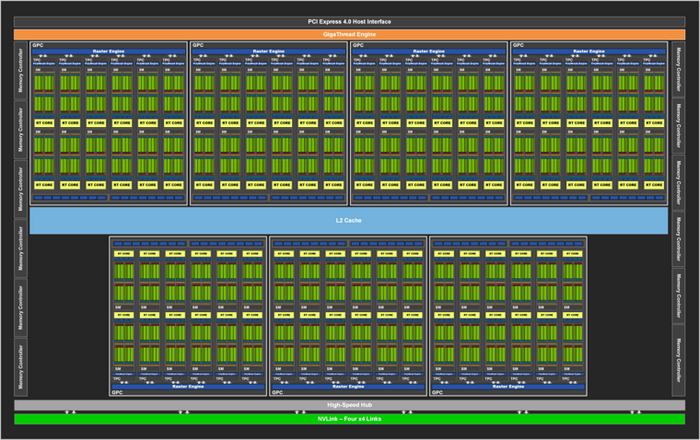
В сентябре 2020 года были представлены RTX3080 и RTX3090, в основу которых лег чип GA102. У него семь GPC, в каждом из которых по шесть блоков TPC. Внутри каждого GPC два мультипроцессора, которые подверглись переработке. В их составе блок RT второго поколения, который ускорился вдвое, и 128 SP двух видов: одна половина работает над вычислениями с плавающей запятой (FP32), а другая дополнительно поддерживает и целочисленные (INT32).
Таким образом, в одном SM теперь вдвое больше блоков, работающих с вычислениями FP32. Учитывая большее количество SM в чипе, вычислительная мощность GA102 в два с половиной раза превосходит таковую у TU102. Тензорные ядра третьего поколения стали вдвое быстрее, но теперь их вдвое меньше — по одному в каждой части SM. Ядра получили оптимизации, ускоряющие их работу в определенных режимах.
GA102 содержит 112 ROP, 336 TMU, 10752 SP, а также 84 RT-блока и 336 тензорных ядер. Чип имеет 384-битную шину. К ней подключается память GDDR6X, достигающая пропускной способности в 1 ТБ/c.
Первая версия RTX3080 получила урезанную версию GA102 с 320-битной шиной и 10 ГБ памяти. Старшая RTX 3090 оснащается менее урезанным чипом, полной шиной и 24 ГБ памяти — эта карта призвана занять место Titan.
Спустя полтора года на базе GA102 появляются еще три видеокарты: обновленная RTX3080 с 12 ГБ памяти и полной шиной, RTX3080 Ti с таким же объемом и менее урезанным чипом, и RTX 3090 Ti — обновление RTX3090 со всеми активными блоками в чипе. Пара RTX3090 единственная из новых карт получила поддержку NVLink. Карты на GA102 способны потреблять свыше 350 Вт.
AMD спустя два месяца ответила новой серией RX6000. Топовые RX6800XT и RX6900XT обладают сравнимой производительностью с RTX3080 и RTX3090, за исключением трассировки лучей, в которой продукты AMD медленнее. К тому же, преимуществом карт NVIDIA была технология DLSS 2, тогда как AMD полагалась на менее качественную технологию масштабирования FSR. Но, как и обычно, карты AMD были дешевле, а недостаток в виде отсутствия DLSS 2 год спустя компенсировало появление сравнимой по качеству FSR 2.
Вслед за «большим» Ampere был выпущен более скромный GA104. Шина памяти сокращена до 256 бит, а количество SP — до 6144. В конце 2020 года носителем урезанного чипа стали RTX3070 и RTX3060 Ti с 8 ГБ памяти GDDR6. Спустя полгода свет увидела RTX3070 Ti на базе полного чипа и с более быстрой GDDR6X, а в 2022 году с такой памятью появилась и разновидность RTX3060 Ti.
В феврале 2021 выходит RTX3060 с 12 ГБ памяти. В ее основе слегка урезанная версия чипа GA106, имеющего 3840 SP и 192-битную шину памяти. В 2022 году чип становится основой еще двух карт: RTX3050 и RTX3060 с 8 ГБ памяти. У обеих 128-битная шина, а в RTX3050 чип «пострадал» еще больше — активными остались всего две трети блоков. К тому же, младшая карта получила урезанный интерфейс PCI-E 4.0 x8.
В конце 2022 года был выпущен младший GA107. Чип имеет две трети блоков GA106, и предназначен для очередной версии RTX3050.
GeForce 4000: технология DLSS 3
Карты этой серии основаны на архитектуре Ada Lovelace, в которой сразу видны «корни» Ampere. Перенос на техпроцесс 5 нм позволил разместить в чипах больше блоков, а также поднять их частоты. Первая карта серии была выпущена в октябре 2022 года. Ей стала RTX4090, основанная на чипе AD102.
AD102 по внутреннему устройству достаточно схож с GA102. Главное отличие — 12 GPC против семи у предшественника. Остальные уровни организации SP не претерпели изменений.
Отличия — внутри. Тензорные процессоры относятся к четвертому поколению, а блок трассировки — к третьему. Его работа вновь ускорилась вдвое, и теперь выполняется эффективнее благодаря двум новым блокам: движку микрокарты непрозрачности и движку смещенной микросетки.
Еще одной новинкой стал обновленный движок ускорения оптического потока. Благодаря ему ГП получил поддержку нового вида масштабирования DLSS 3. К тому же, значительно возрос размер кэша L2. При этом подсистема памяти не изменилась: все те же 24 ГБ 384-битной GDDR6X с пропускной способностью в районе 1 ТБ/c.
Полный AD102 имеет 192 ROP, 576 TMU и 18432 SP. У ГП 144 RT-блока и 576 тензорных ядер. В RTX4090 часть блоков отключена, но вкупе с возросшей на треть частотой чипа, рост производительности по сравнению с предшественницей достиг двукратного. При этом значительно возросло TDP карты. Оно достигло 450 Вт, что потребовало установки нового разъема 12VHPWR для подвода питания.
RTX4080 получила собственный чип AD103. Он имеет 10240 SP и 256-битную шину памяти, но в карте также отключена часть блоков. Модель имеет 16 ГБ памяти GDDR6X. В декабре 2022 года AMD запускает новую линейку RX7000, топовой моделью которой становится RX7900XTX. Карта противопоставляется RTX4080, что соответствует действительности — RTX4080 и RX7900XTX близки друг другу, не учитывая трассировку лучей, которая у AMD все так же медленнее.
Впрочем, RX7900XTX стоит дешевле — ведь модель NVIDIA с индексом xx80 впервые получила четырехзначный долларовый ценник. Однако у RTX4080 есть козырь в виде DLSS 3: с ее распространением разрыв производительности в новых играх может стать намного выше, пока свет не увидит конкурентная технология FSR3.
Январь 2023 года принес с собой RTX4070 Ti — первую карту на AD104. В составе чипа 7680 SP и 192-битная шина памяти. Спустя три месяца появилась и обычная RTX4070. Она, в отличие от старшей модели, использует неполный чип c четвертью отключенных блоков. Обе карты оснащаются 12 ГБ GDDR6X.
Запущенная в мае 2023 года RTX4060Ti основывается на ГП AD106. Он имеет 4608 SP и 128-битную шину памяти, но в карте используется слегка урезанная версия чипа. В отличие от старших «сестер», здесь используется обычная GDDR6 объемом 8 или 16 ГБ. К тому же, чип ограничен интерфейсом PCI-E 4.0 x8, как это уже было в случае с RTX3050.
В конце июня готовится к запуску обычная RTX4060 на другом чипе — AD107. Как и у AD106, у него 128-битная шина памяти и интерфейс PCI-E 4.0 x8, но в полтора раза меньше SP. RTX4060 получит полную версию чипа, а версия с частью отключенных блоков найдет применение в будущей RTX4050.
Nvidia представила новые графические адаптеры в рамках стратегии развития AI PC. Три новые модели выпущены в рамках линейки GeForce RTX™ 40 SUPER Series, это GeForce RTX 4080 SUPER, GeForce RTX 4070 Ti SUPER и GeForce RTX 4070 SUPER. В начале января на выставке CES в Лас-Вегасе компания сообщила о том, что новые технологии помогут геймерам, дизайнерам и другим категориям пользователей эффективнее использовать возможности искусственного интеллекта на персональных компьютерах, не прибегая к помощи облачных сервисов.
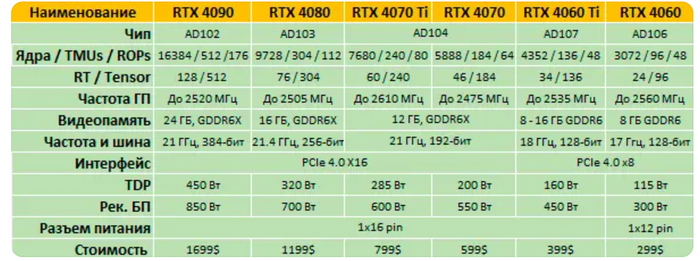
Характеристики
Итак, для начала таблица всех известных на текущий момент моделей RTX 40 вышедших и не очень:
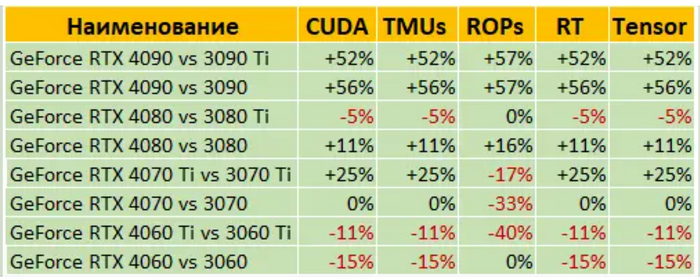
Блоки ядра и RT
Интересная ситуация в новом поколении видеокарт NVIDIA оказалось и с блоками ядра. После изучения и сопоставления этих данных, некоторые даже называли единственной новой картой RTX 4090. И вот почему:
Если сравнить количество блоков в старых и новых видеокартах, мы увидим, что и тут «не все так однозначно». Идеально показывает себя RTX 4090, только у нее неоспоримое и весомое преимущество над предшественницей (причем, как обычной RTX 3090 так и RTX 3090 Ti) более 50% в любом из типов блоков. Новая мощная карта RTX 4080 показала незначительное преимущество блоков над RTX 3080, а все прочие устройства в линейке были наделены меньшим числом блоков, хотя бы в одной из дисциплин.
На общем фоне, хуже всего себя показали RTX 4060 Ti и RTX 4060, в которых оказалось на 11-15% меньше блоков, чем у карт предыдущего поколения. Некоторые даже ждали, что они окажутся медленнее серий прошлого поколения. Разумеется, этого не могло произойти, количество блоков компенсировалось изменениями в частотах и новой архитектурой.
Компания NVIDIA остановила производство почти всех графических процессоров из линейки GeForce RTX 40, за исключением RTX 4050 и 4060.
NVIDIA полностью закрыла производственную линию видеочипа AD106, утверждают источники. Компания перераспределила все свои мощности на выпуск графических процессоров для видеокарт из линейки RTX 50. Производственная линия чипов AD107 для RTX 4050 и 4060 временно продолжает работать.
CES 2025 в Лас-Вегасе NVIDIA представила новые видеокарты серии GeForce RTX 50
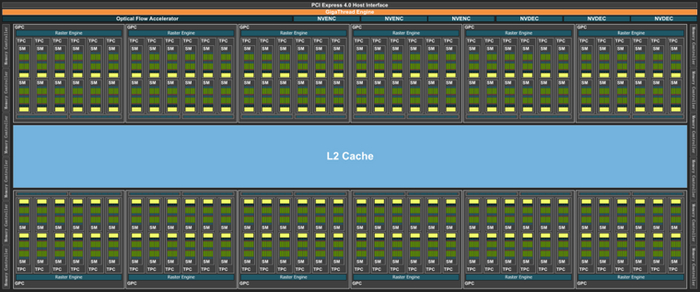
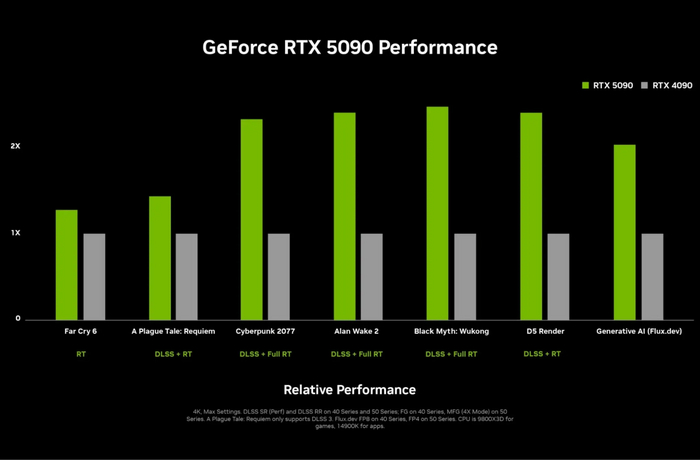
NVIDIA официально представила свою новую флагманскую видеокарту GeForce RTX 5090, которая стала первым потребительским ускорителем с 32 ГБ памяти GDDR7 и частотой 30 ГГц. В основе устройства лежит GPU GB202-300-A1 с 21 760 ядрами CUDA и TBP 575 Вт. Видеокарта поддерживает PCIe Gen 5.0 и DisplayPort 2.1b UHBR20 (8K 165 Гц).
Согласно данным NVIDIA, GeForce RTX 5090 в два раза быстрее GeForce RTX 4090 при использовании DLSS 4 в таких играх, как Cyberpunk 2077, Alan Wake 2 и Black Myth Wukong. В Far Cry 6, даже без DLSS, производительность увеличивается на 30–40%. Технология DLSS 4, основанная на Tensor Core, снижает задержку и улучшает качество изображения, а DLSS Multi Frame Generation позволяет генерировать до трёх дополнительных кадров на каждый честно отрендеренный кадр, увеличивая FPS до 8 раз.
Обновление DLSS 4 включает крупнейшие изменения в ИИ-моделях с момента выхода DLSS 2.0 в 2020 году. Новые функции, такие как DLSS Ray Reconstruction, суперразрешение DLSS и DLAA, основаны на архитектуре «трансформеров», подобной GPT и Gemini. Это значительно улучшает стабильность и детализацию, снижая количество ореолов.
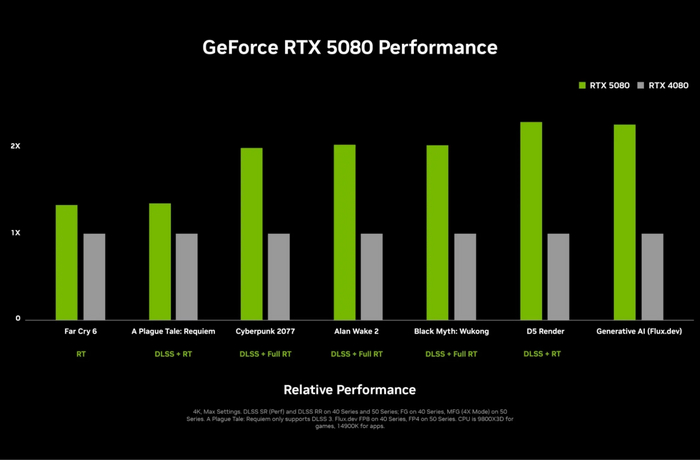
GeForce RTX 5090 отличается компактным размером: Founders Edition занимает два слота и имеет длину 304 мм. Её стоимость составила $2000. GeForce RTX 5080 построена на GPU GB203-400-A1 с 10 752 ядрами CUDA и 16 ГБ памяти GDDR7. Пропускная способность памяти составляет 960 ГБ/с, TBP — 360 Вт, а цена — 1000 долларов, что на 200 долларов меньше цены GeForce RTX 4080 на старте продаж.
GeForce RTX 5070 Ti оснащена 16 ГБ памяти GDDR7 и 8960 ядрами CUDA, её стоимость 750 долларов. Эта модель построена на урезанном GPU GB203 с пропускной способностью памяти 896 ГБ/с и максимальной частотой GPU 2,45 ГГц. Производительность, с учётом DLSS, в два раза выше, чем у GeForce RTX 4070 Ti.
GeForce RTX 5070, самая доступная видеокарта в линейке, стоит 550 долларов. Она построена на GPU GB205 с 6144 ядрами CUDA и 12 ГБ памяти GDDR7 с частотой 28 ГГц и шириной шины памяти 192 бита. TBP составляет 250 Вт. NVIDIA утверждает, что GeForce RTX 5070 быстрее RTX 4090 при использовании DLSS 4.
В плане производительности при работе с искусственным интеллектом, GeForce RTX 5090 предоставляет 3352 триллионов операций в секунду (3352 AI TOPS), а GeForce RTX 5080 — 1801 AI TOPS. Модели RTX 5070 Ti и RTX 5070 предлагают 1406 AI TOPS и 988 AI TOPS соответственно.
На этом история развития графики NVIDIA заканчивается. Более чем за 30-летнюю историю компании сменилось более 20 поколений графических процессоров, каждое из которых радовало увеличенной производительностью и приносило какие-то новшества. Этого игроки будут ждать и от следующих поколений RTX........!
СПАСИБО ВСЕМ КТО ДОЧИТАЛ ДО КОНЦА!!!