Наверное, это будет самый сложный пост в моей жизни, так как я никогда ранее не вел блог или что-то подобное. Я хочу начать серию постов, которая будет содержать реальные проекты по программированию на фрилансе. Зачем это? Просто хочется делиться любым опытом с сообществом. Возможно кому-то даже удастся помочь или просто обсудить проект.
Сразу скажу, я не профессиональный программист. Все, что я знаю - черпал в разное время из книг и Youtube. Да, когда-то начинал по книге изучать Delphi, а с помощью форумов и HTML писал для себя простенькие сайты. Прошло довольно много времени, изучение было успешно отложено. Около года назад снова заинтересовало написание кода, выбор пал на распиаренный Python. В общем сейчас владею небольшим багажом знаний по Python, HTML верстке с CSS, JavaScript и немного C# (На C# имеется опыт в написании плагинов для игры Rust).
В данный момент есть огромное желание практиковаться, сталкиваться с трудностями и искать решения. Именно поэтому подался на фриланс. Конечно, я не буду рекламировать площадки при публикации проектов.
Ну и чтобы завершить данный поток написанных слов, расскажу о своем первом опыте на фрилансе. Как и ожидалось мной, опыт был негативным в силу моего доверия к людям. Мне удалось взять задание по редактированию шаблона сайта на Joomla. Ранее я уже сталкивался с этой CMS и базовые принципы работы имелись. Как это обычно бывает, заказчику потребовалось больше, чем было указано в описании задания. Я согласился, так как хотелось получить опыт в реальном заказе. Сейчас я не буду описывать в чем конкретно заключалась задача и ее многочисленные подзадачи в виде "мелких" правок и какова была реализация. Скажу только итог - я выполнил всю работу и не получил за свою работу ни копейки. Да, таков был первый опыт.
Я очень надеюсь, что найдутся те, кому это будет интересно. Надеюсь, что найдутся и те, кто будет тоже делиться своими знаниями. В общем, Пикабу, не кидай камни)
Что такое random_state в машинном обучении? Зачем нужен этот парметр и как его выбрать? А что вообще общего у числа 42 с культовой книгой “Автостопом по галактике”? И разве случайности не случайны?..
Что такое random_state и как его настройка влияет на обучение моделей?
Возможно, многие из вас уже слышали о параметре random_state, особенно если вы сейчас погружаетесь в ML-разработку. Или вы уже пробовали работать с этим параметром, разбивая набор данных на обучающую и тестовую выборки.
Если же забыли или сейчас столкнулись с randome_state впервые, рассказываем, что это такое.
Параметр `random_state` в ML-разработке обычно используется для установки начального состояния генератора случайных чисел. Этот параметр часто встречается в алгоритмах машинного обучения, которые включают случайные элементы. Например, инициализация весов модели, разделение данных на обучающий и тестовый наборы, случайная инициализация параметров и т. д.
Представьте, что вы выполняете задание, в котором нужно использовать случайные числа. Например, вы разделяете данные на обучающую и тестовую выборки, и вам нужно случайным образом выбрать часть данных для обучения и часть для тестирования модели.
`random_state` — это как начальное число, которое указывает компьютеру, как начать генерацию случайных чисел. Если вы каждый раз используете одно и то же значение `random_state`, то каждый раз, когда вы запускаете эксперимент, вы будете получать те же самые случайные числа. Это помогает сделать ваше исследование воспроизводимым. То есть каждый раз, когда вы запускаете эксперимент с одним и тем же `random_state`, вы получаете те же самые результаты.
Почему это важно?
Предположим, что у вас есть модель, которая дает вам хорошие результаты на определенном наборе данных. Вы хотите сравнить ее с другой моделью или настройками. Если вы используете один и тот же `random_state`, то обе модели будут тестироваться на тех же самых данных, что позволит вам честно сравнивать их результаты.
random_state = 0 or 42 or none
Чаще всего люди устанавливают значение random_state на 0 или 42. Но вы знаете, почему это так?
Простота запоминания
Числа 0 и 42 довольно легко запомнить, поэтому они часто используются как стандартные значения для `random_state`.
Распространенность
Эти числа стали популярными благодаря их частому использованию в примерах и обучающих материалах. Честно говоря, многие останавливаются на этих значениях, даже если они не понимают их смысла.
Теперь давайте рассмотрим каждое число отдельно:
- 0 — часто используемое значение, потому что оно приводит к одинаковым результатам при каждом запуске программы, что удобно для проверки и воспроизводимости экспериментов.
- 42 — это число стало популярным после того, как стало известно, что автор Дуглас Адамс использовал его в своей книге "Автостопом по галактике" как ответ на вопрос о смысле жизни, вселенной и всего такого. В итоге эта сцена стала культовой, поэтому теперь это число часто используется в качестве самого простого способа установить `random_state`.
Таким образом, когда люди говорят о том, что чаще всего используют числа 0 или 42 для `random_state`, они обычно имеют в виду, что это стандартные значения, которые многие выбирают из привычки, не всегда понимая, почему именно эти числа используются.
Что такое random_state?
В библиотеке Scikit-learn этот параметр управляет перетасовкой данных перед их разделением. Мы используем его в функции train_test_split для разделения данных на обучающую и тестовую выборки.
Он может принимать следующие значения:
1. Нет (по умолчанию). Если не указано значение, то используется глобальный экземпляр случайного состояния из библиотеки numpy.random. Если мы вызываем функцию с random_state=None, то каждый раз получаем разные результаты.
2. Целое число. Установка любого значения из целого числа для random_state дает один и тот же результат при каждом выполнении программы. Изменение значения random_state приведет к изменению результата.
Важно помнить, что random_state не может быть отрицательным числом!
Как это работает?
Допустим, у нас есть набор из 10 чисел, от 1 до 10. Теперь, когда мы хотим его разделить на обучающую и тестовую выборки, мы решаем, что размер тестовой выборки должен составить 20% от всего набора данных.
Получается, что в обучающем наборе будет 8 чисел, а в тестовом — 2. Это важно для того, чтобы каждый раз получать одинаковые результаты при запуске кода. Если мы не перетасуем данные, то каждый раз будем получать разные выборки. А это может некачественно сказаться на обучении модели.
Немного подробнее: когда мы устанавливаем значение `random_state` для наших случайных процессов, мы фактически фиксируем начальное состояние генератора случайных чисел. Это гарантирует, что каждый раз, когда мы запускаем наш код с тем же значением `random_state`, то получаем одинаковый набор случайных чисел. И в нашем случае, когда мы используем этот `random_state` для разделения данных на обучающий и тестовый наборы, мы получаем одинаковое разделение каждый раз, когда запускаем код.
На картинке ниже показано, как это работает:
Давайте разберемся в одном важном моменте. Многие люди используют значение random_state = 42. На изображении выше видно, что при установке random_state равным 42, мы получаем один и тот же фиксированный набор данных, который был перетасован. Это означает, что каждый раз, когда мы устанавливаем random_state равным 42, мы получаем один и тот же перетасованный набор данных.
Таким образом, число 42 не обладает особым значением для random_state.
Давайте посмотрим, как это можно использовать для разделения набора данных
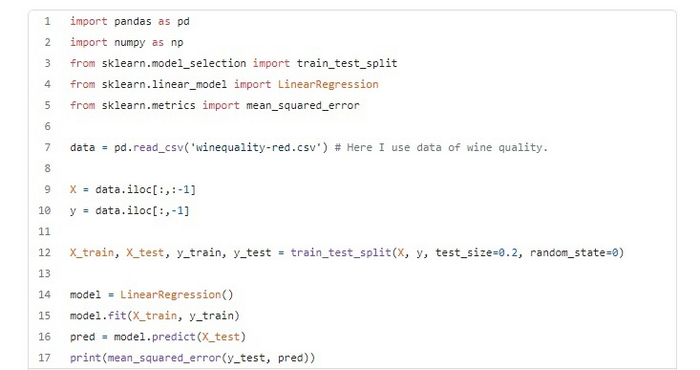
Здесь мы используем набор данных о качестве вина и модель линейной регрессии. Делаем просто, потому что наша основная цель — это random_state, а не точность.
Использование random_state при разделении
В представленном выше коде для random_state равного 0, mean_squared_error составила 0.384471197820124. Если мы попробуем разные значения для random_state, то каждый раз получим разные ошибки.
Для random_state = 1, mean_squared_error равна 0.38307198158142.
Для random_state = 69, mean_squared_error равна 0.47013897077423.
Для random_state = 143, mean_squared_error равна 0.42062134425032.
Сколько вообще возможных случайных состояний бывает?
Проведем эксперимент, чтобы определить, сколько различных комбинаций данных мы можем получить, переставляя исходный набор.
1. Мы берем набор из 5 чисел от 1 до 5.
2. Далее разделяем этот набор данных на обучающие и тестовые данные 2000 раз, используя значения random_state от 1 до 2000. Каждое значение random_state создает новую случайную последовательность разделения данных.
В итоге у нас будет список из 2000 перетасованных наборов данных, каждый полученный с использованием разного значения random_state.
Из всех этих перетасованных наборов данных только 120 окажутся уникальными. Это означает, что при использовании исходного набора данных из 5 чисел мы можем получить всего 120 различных комбинаций, переставляя их.
Установка значения random_state в диапазоне от 0 до 119 позволит нам получить одну из этих 120 уникальных комбинаций данных при каждом запуске алгоритма.
Эти выводы можно объяснить так:
Короче говоря, это про факториалы. При использовании набора данных из 5 чисел и их перестановкой, мы фактически создаем комбинации, а количество уникальных комбинаций, как можно заметить, равно факториалу числа 5, то есть 5! = 5 × 4 × 3 × 2 × 1 = 120.
Использование параметра `random_state` в этом контексте подобно выбору одной из 120 уникальных комбинаций данных. Каждое значение `random_state` соответствует одной из перестановок чисел, и они будут однозначно связаны с числами от 0 до 119, что совпадает с индексами возможных комбинаций факториала числа 5.
Этот эксперимент помогает нам понять, как параметр `random_state` влияет на разделение данных и на результаты моделирования в машинном обучении, потому что он определяет начальное состояние генератора псевдослучайных чисел. При разделении данных на обучающий и тестовый наборы с использованием `random_state` мы фиксируем последовательность случайных чисел, которая влияет на способ разделения данных.
Этот параметр важен, потому что он обеспечивает воспроизводимость результатов: при одном и том же значении `random_state` мы получаем одинаковую разбивку данных, что позволяет повторно воспроизвести эксперимент и проверить результаты моделирования. И именно таким образом, понимание того, как работает `random_state`, помогает нам контролировать случайность в нашем анализе данных и сделать его более надежным и воспроизводимым.
Зачем нам это нужно?
Давайте разберемся с random_state в контексте прогнозирования цен на жилье. Представьте, у нас есть данные о жилье, и по мере движения сверху вниз по этим данным, у нас становится либо больше комнат, либо увеличивается площадь квартир. Это то, что мы называем данными о смещении.
Теперь, если мы просто разделим наши данные без перетасовки, это даст нам неплохую производительность при обучении, но когда дело доходит до тестирования, она может быть не очень. Поэтому мы и используем перетасовку данных. Вот где random_state приходит на помощь!
Когда мы делим данные, то хотим, чтобы результаты каждый раз были одинаковыми. То есть, если мы перезапустим код, мы получим те же самые данные для обучения и тестирования, что и раньше.
Разные значения random_state могут дать нам разную производительность.
Например, разные значения random_state дают разные значения mean_squared_error.
Это означает, что если вы выберете случайное значение random_state, и вам повезет, то вы сможете свести к минимуму количество ошибок для этого значения.
Да и в других аспектах машинного обучения random_state пригодится. Например:
KMeans
В алгоритме KMeans параметр random_state определяет, как генерируются случайные числа для инициализации центроидов. Мы можем использовать целое число для того, чтобы сделать процесс генерации случайных чисел предсказуемым. Это полезно, когда нам нужно создавать одинаковые кластеры каждый раз.
Случайный лес
В классификаторе случайного леса и в модели регрессии параметр random_state контролирует начальное случайное состояние выборок, используемых при построении деревьев, и выборку объектов, учитываемых при поиске наилучшего разделения в каждом узле.
Дерево решений
В классификаторе дерева решений или регрессии, когда мы ищем наилучшие признаки для разделения узлов, тоже стоит задать параметр random_state. Этот определяет структуру дерева и гарантирует воспроизводимость результатов.
Ну, вот и всё, что вам нужно знать о random_state!
Продолжаем серию видеоподкастов, посвященных социокультурным особенностям российских IT-специалистов. В этой части продолжаем говорить об образе российского "айтишника" у иностранцев
Схема Peer-to-Peer предполагает прямую связь между двумя компонентами без необходимости в центральном координаторе.
🔹API Gateway
API-шлюз выступает в качестве единой точки входа для всех клиентских запросов к внутренним сервисам приложения.
🔹Pub-Sub
Шаблон Pub-Sub отделяет производителей сообщений (издателей) от потребителей сообщений (подписчиков) с помощью брокера сообщений.
🔹Request-Response
Это один из самых фундаментальных паттернов интеграции, когда клиент отправляет запрос на сервер и ждет ответа.
🔹Event Sourcing
Event Sourcing предполагает хранение изменений состояния приложения в виде последовательности событий.
🔹ETL
ETL - это схема интеграции данных, используемая для сбора данных из различных источников, преобразования их в структурированный формат и загрузки в конечную базу данных.
🔹Batching
Пакетирование подразумевает накопление данных за определенный период или до достижения определенного порога, после чего они обрабатываются как единая группа.
🔹Streaming Processing
Потоковая обработка позволяет непрерывно получать, обрабатывать и анализировать потоки данных в режиме реального времени.
🔹Orchestration
Оркестровка подразумевает наличие центрального координатора (оркестранта), управляющего взаимодействием между распределенными компонентами или сервисами для реализации рабочего процесса или бизнес-процесса.
Столько всего было рассказано и показано про ИИ, но очень редко обсуждается, каких он бывает видов… Поэтому сегодня поговорим об этом подробнее!
Неважно, насколько вы знакомы с темой, здесь точно найдется что-то новое. От реактивных машин, которые просто реагируют на окружающую среду, до искусственного сверхразума, способного превзойти человеческий интеллект.
Реактивные машины
Смысл этого ИИ следует из названия — реагировать на текущую ситуацию. Самой первой такой машиной стала Deep Blue, которая в 1997 году выиграла у чемпиона мира по шахматам, Гарри Каспарова. Она могла анализировать текущее состояние шахматной доски и делать ходы на основе этой информации, но не могла использовать предыдущие игры для обучения и принятия решений.
Автомобили с автопилотом — еще один пример. Они используют датчики для анализа окружающей среды и принятия решений на дороге. Но, как и Deep Blue, они не могут учитывать прошлый опыт.
Несмотря на возраст, такой ИИ будет полезен и сейчас: для управления простыми роботами в реальном времени, в авиабезопасности для быстрого обнаружения и реагирования на потенциальные угрозы или аварийные ситуации. Да и в целом, везде, где важна реакция, а не память.
ИИ с ограниченной памятью
Этот ИИ учитывает, что было раньше, когда принимает решения. Например, система умного дома помнит, какие настройки климата предпочитают жильцы, и регулирует их соответственно.
Другой пример — это рекомендательная система на YouTube. Она подкидывает вам видео, исходя из того, что вы смотрели раньше. Другие видео последнего просмотренного блогера, другие видео по той же тематике — всё то, что может вас заинтересовать. То же самое касается и reels в запрещенной соцсети.
Этот ИИ старается делать свою работу лучше, основываясь на прошлом опыте. Но он не может использовать этот опыт для того, чтобы узнать что-то новое или понять, почему происходят определенные события.
Теория разума
Сокращенно можно называть ТоМ. Он уже более продвинутый, потому что понимает намерения, убеждения и эмоции человека. Другими словами, если мы “вживим” этот ИИ в тело робота, то такой робот будет “считывать” эмоции человека по его лицу. Или понимать, как чувствует себя человек, исходят из положения его тела.
Над ТоМ’ом ещё ведутся разработки. Искусственный интеллект с развитым эмоциональным интеллектом, который будет понимать юмор и сарказм — это, конечно, мощно… Но первые наработки уже имеются.
Компания Hume AI в конце марта этого года представила новую систему под названием Empathic Voice Interface (EVI). Этот ИИ может анализировать голос человека и определять его эмоциональное состояние. Он улавливает не только слова, но и интонации, позволяя понять контекст разговора. При этом EVI даже может изменять свой собственный голос, чтобы лучше соответствовать настроению собеседника.
У Hume AI есть и другие продукты с похожим функционалом. Они могут анализировать выражения лица, движения человека и его реакции на окружающее.
Искусственный Узкий Интеллект (ИУИ)
Он считается слабым, потому что не справляется с несколькими сложными задачами сразу. Но, несмотря на это, такой ИИ — один самых востребованных.
Он может быть обучен распознавать лица на фотографиях или автоматизировать процесс обработки текстов, но он не может справиться с задачами, которые требуют широкого спектра знаний и навыков.
В медицине ИУИ может помогать в диагностике заболеваний по медицинским изображениям или анализировать данные о состоянии пациентов для выявления рисковых факторов. Такие системы, пусть и не могут заменить человеческий интеллект, все же значительно облегчают рутинные задачи и улучшают эффективность работы в практически в любой сфере.
Сильный Искусственный Интеллект (СИИ)
Сильный искусственный интеллект (СИИ) — это такой ИИ, который умеет решать много разных задач, подобно человеку. Он не только умеет решать задачи, но и может учиться на своих ошибках, адаптироваться к новым ситуациям и принимать решения на основе сложной информации.
Например, система автономного вождения — это СИИ. Она может самостоятельно управлять автомобилем, принимать решения и адаптироваться к разным ситуациям на дороге. Эта система учится на опыте и становится лучше с каждой новой поездкой.
Другой пример — IBM Watson. Она умеет анализировать большие объемы информации, понимать тексты и давать рекомендации на основе этой информации. Watson используется в медицине, финансах и других областях для принятия важных решений на основе данных.
Всем известные LLM и GPT также относятся к СИИ.
Самосознание
ИИ, который осознает и понимает собственное существование.
Если вы спросите у GPT, осознает ли он, что является искусственным интеллектом, он ответит, что да, и его предназначение — это помощь людям. Но стоит переиначить вопрос, спросив напрямую: “Есть ли у тебя самосознание?”, он ответит, что является всего лишь программным алгоритмом.
Но почему в ответе на первый вопрос чат-бот сказал, что “осознает”? Он запрограммирован на этот ответ, вот и всё.
На данный момент ИИОН (Искусственный Интеллект Общего Назначения), у которого было бы самосознание, как у человека, ещё не разработан. И видели мы его лишь в фантастике.
AGI
AGI — это своего рода святой грааль в области ИИ, который представляет собой высший уровень развития искусственного интеллекта, приближенный к человеческому.
Отличие AGI от сильного ИИ в том, что сильный ИИ обладает мощной способностью решать сложные задачи, но он ограничен в том, что делает, и может работать только в определенной области. AGI же способен заниматься разными видами деятельности, самосовершенствоваться, делать выводы, но, как бы то ни было, брать отвественность за свои действия он не сможет.
Именно AGI намерены разработать OpenAI, Google и Anthropic в ближайшие годы.
Супер Искусственный Интеллект
Супер-ИИ — также, как и Самосознание и AGI, находится пока в гипотезе, но предполагается, что он будет превосходить возможности человеческого разума во всех аспектах.
Это концепция идеального ИИ, который способен на самообучение, саморазвитие, самосознание и создание новых технологий и знаний в неограниченном объёме.
HAL из фильма Кубрика “2001 год: Космическая одиссея”, Матрица, которая превзошла человеческий интеллект и контролирует весь мир, как реальный, так и виртуальный, Гарант, господствующий над Kepler-22b, из сериала “Воспитанные волками” — эти и подобные примеры существуют только в реализованной фантазии писателей и режиссеров, но не в жизни. К сожалению это или к счастью.