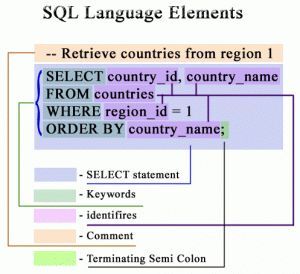
Excel vs Конструктор Интеграм
Excel -- величайшая программа, с помощью него можно править миром. Я использую его ежедневно, и он незаменим для разовых задач, пока...
Пока у вас меньше миллиона записей и в пределах десятка пользователей и не нужно работать с мобилы, и ваши сотрудники не воруют базу, и не нужно делать сложных запросов к данным, и вы не устали клонировать дни/недели/месяцы на разные листы и вам нет необходимости поставить его в локальной сети и он ещё не тормозит от количества вычислений. И так далее.
Предельная унификация конструктора напоминает фракталы: глубже и глубже в детали
Хочу открыть серию постов про альтернативу отечественного производства, которой я пользуюсь для автоматизации рутинной работы и расчетов, с которыми не справляется эксель.
Типичный случай
Например, 400 тысяч сделок по продаже медицинского оборудования, по которым мне надо сделать обзвон клиентов, которые покупали что-то на общую сумму не меньше 5000 рублей от 1 до 2 лет назад и с тех пор ничего не покупали. Разбудить спящих и поднять выручку.
Для эксперта Excel такая задача не кажется сложной, и он выполнит её за пару-тройку часов, из которых большая часть уйдет на нормализацию данных.
Проблема в том, что задача эта повторяющаяся и тут — А-а-а!

Рутинная работа в экселе со временем превращается в кошмар
Разумеется, когда эксперту на следующей неделе сделают следующую выгрузку этих данных со сдвигом в 1 неделю, то он будет всячески отлынивать от этой работы — заново всё нормализовывать, растаскивать формулы, устранять косяки и прочей рутины на несколько часов. Поэтому часто спящие клиенты спят дальше или обзвон идет по неактуальной базе, выбешивая клиентуру, или реализуется иной путь упущения прибыли.
Альтернативы здесь: заказная разработка на языках программирования или суррогаты экселя, которых много и они всё множатся. Например, можно настроить формулы в Airtable или даже Notion, а потом используя винегрет из ноукод-инструментов даже запустить вычисления и перенос данных с помощью make или n8n.
Я рассказываю о ещё одной альтернативе: вся мощь реляционной базы данных с интерфейсом, более-менее привычным пользователю экселя.
Конструктор Интеграм
Что за зверь Интеграм? Это ноукод-конструктор баз данных и приложений, в котором хорошо прокачана первая часть — про базы — и можно делать простые приложения для непритязательного пользователя.
В первый раз я его попробовал будучи совладельцем пары бизнесов, где администраторы присваивали себе часть выручки самыми хитроумными способами, большинство из которых сводилось к оформлению клиентских оплат задним числом.
С тех пор я использую этот инструмент в разных проектах, в том числе для заказной разработки, которой я в своё время активно занимался. Интеграм доступен в виде бесплатного облачного сервиса, где можно начать с чистого листа, как в экселе. Обычно всё и начинается с листа экселя, который я импортирую в сервис.
Если коротко, то процесс программирования такой:
Загружаем эксель в систему универсальным средством импорта
Дорабатываем структуру данных под себя
Настраиваем отчеты для вычисления, сортировки и группировки
Накликиваем формы для отображения данных и графиков
Заводим пользователей и раздаем права
Платформы всё-в-одном
Конструктор Интеграм относится к классу систем всё-в-одном, в котором на сегодня есть всего 3 используемых в России продукта: 1С, bubble.io, coda.io. Первый из них вы наверняка хорошо знаете, а два последних уже недоступны без vpn.
Всё-в-одном означает объединение всех аспектов разработка: фронтенд, бэкенд, база данных (БД) и интеграции. Под фронтендом имеется в виду создание произвольных форм, а не предварительно заготовленные представления и шаблоны.
Как эти ни странно, игроков, у которых есть все эти составляющие, больше нет (если есть, а я мог упустить, буду рад услышать их имена в комментариях):
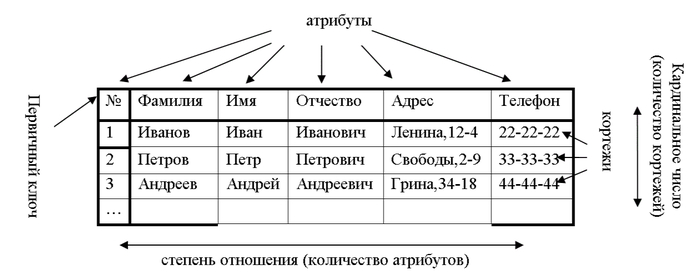
Конструктор произвольной структуры реляционной (со связями) БД
Конструктор запросов к данным и логики их обработки
Конструктор произвольных форм и шаблонов
Есть множество прекрасных систем для создания баз данных, есть конструкторы веб-страниц и форм, но вот связать это всё в единое приложение и оживить пользовательской логикой без программирования больше нигде не удастся. Программировать бэкенд и логику придется на PHP, Javascript, Python или чём-то подобном.
При всей своей внешней неказистости Интеграм дает более продвинутые возможности для обработки данных, чем это доступно в любом конструкторе, и вполне сравнимые по мощности с традиционными средствами разработки. Например, конструктор SQL-запросов дает всю мощь реляционной базы данных, включая вложенные запросы и рекурсию.
Вот примерный порядок работы при создании приложения в конструкторе:
Пока это неизвестный широким массам конструктор, но команда активно занимается его продвижением. Я бы хотел поблагодарить этих людей за огромное количество времени и сил, сэкономленных при использовании конструктора, и могу помочь вам с его освоением бесплатно и даже без партнерской ссылки. Обращайтесь.
Спасибо!