Таблицы в базах данных: где чаще всего "горит"
Когда мы слышим слова таблица, то сразу идет ассоциация со строками и столбцами. Но в базе данных - это не просто строки и столбцы, это мини вселенная со своими правилами и требованиями.
В своем канале На связи: SQL я рассказываю об особенностях языка SQL. Разбираю аналитические запросы и подходы работы с данными. Канал создала недавно с нулем подписчиков, но там уже есть интересная информация для работы аналитиков. Подписывайся!
И для формирования таблиц в БД есть свои требования, нюансы и особенности.
Очень часто аналитики сталкиваются со следующими проблемами при работе с данными:
Слишком много столбцов
Иногда пытаются «запихнуть всё» в одну таблицу. Получается «широкая простыня» с сотнями колонок.
Такой подход приводит к тому, что становится неудобно работать, запросы тормозят, а половина столбцов вообще пустая.
В этом случае необходимо прибегать к нормализации данных — разносить данные по отдельным связанным таблицам.
Грубо говоря, нормализация - это способ организации данных. Что именно хранится, где именно хранится и как все, что хранится, связано между собой.
Дублирование данных
В таблице могут храниться одни и те же данные по 100 раз (например, имя клиента в каждом заказе).
Это приводит к сложности обновления — изменил телефон в одном месте, а в другом он остался старым; объем БД растет, что требует увеличения ресурсов для работы с данными.
В этом случае необходимо выносить повторяющиеся данные в отдельные таблицы и связывать ключами.
И это тоже про нормализацию данных.
Пустые ячейки (NULL)
Есть поле, но оно ничем не заполнено. И тогда аналитик задается вопросом: что это значит? Что данных просто нет (их никто не вносит), данные вносят, но они потерялись при загрузке в таблицу, либо эти данные необходимо воспринимать как равные нулю...
В этом случае необходимо сначала посмотреть требования к источнику данных, есть ли там обязательность их заполнения. Если данные обязательны к заполнению, то стоит рассмотреть ETL (Extract Transform Load - извлечение, преобразование и загрузка) процесс данных.
И от полученных результатов принимать решение как расценивать NULL данные.
Неправильный тип данных
Телефон хранят как INT, даты — как текст, деньги — как FLOAT.
Такой подход приводит к тому, что в телефоне «съедается» +7, даты не сортируются, а деньги теряют копейки.
И аналитик не может корректно обрабатывать данные, что приводит либо к ошибкам в результатах, либо к увеличению этапа обработки данных для выполнения какой-либо аналитики.
В этом случае: только правильное использование типов данных.
Нет ключей и индексов
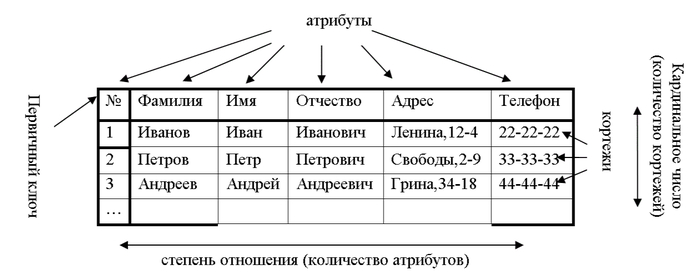
Ключи нам нужны, чтобы однозначно идентифицировать данные и связывать таблицы между собой.
Есть первичный ключ (Primary Key) и внешний ключ (Foreign Key)
Первичный ключ - это уникальный идентификатор. Например есть два Ивановых Ивана Ивановича, но у них будут разные ID. Этот ID будет однозначно идентифицировать каждого из них.
Внешний ключ - это ссылка на другую таблицу. Например есть таблица заказов и в ней есть поле client_id. Это поле будет ссылаться на ID нашего Иванова Ивана Ивановича в таблице с персональными данными.
Индексы нам нужны для ускорения поиска.
Представь, у тебя есть огромная книга (миллионы строк в таблице). Если ты ищешь слово вручную — придётся листать страницу за страницей.
Но если есть алфавитный указатель (индекс) — ты сразу находишь нужное слово.
Примеры:
Поиск клиента по номеру телефона
Поиск заказов по дате
Поиск товаров по категории
Индексы ускоряют запросы в разы, но требуют памяти и времени на обновление (поэтому ими злоупотреблять тоже не стоит).
Слияние «всего подряд»
Если таблицу использовать как свалку — складывать туда и клиентов, и товары, и заказы — это как в одной кастрюле сварить борщ, компот и макароны.
Итог: никто не понимает, что с этим есть.
А в канале На связи: SQL уже первые посты про структуры запросов и JOIN ждут тебя.
Если тебе нужна поддержка и мотивация или просто сопутствующие слова для твоего развития, то приходи в канала Сила слов. Там каждое утро тебя ждет мотивационное и поддерживающее послание.